






正常情况下,join操作都会执行shuffle过程,并且执行的是reduce join,也就是先将所有相同的key和对应的value汇聚到一个reduce task中,然后再进行join。普通join的过程如下图所示:
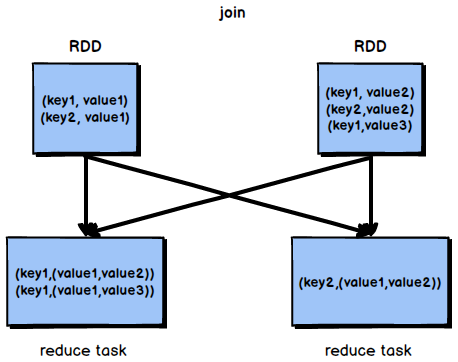
图3-2 普通join过程
普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。
(注意,RDD是并不能进行广播的,只能将RDD内部的数据通过collect拉取到Driver内存然后再进行广播)
- 核心思路:
不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
根据上述思路,根本不会发生shuffle操作,从根本上杜绝了join操作可能导致的数据倾斜问题。
当join操作有数据倾斜问题并且其中一个RDD的数据量较小时,可以优先考虑这种方式,效果非常好。map join的过程如图3-3所示:
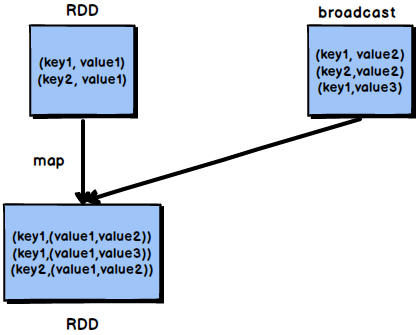
图3-3 map join过程
- 不适用场景分析:
由于Spark的广播变量是在每个Executor中保存一个副本,如果两个RDD数据量都比较大,那么如果将一个数据量比较大的 RDD做成广播变量,那么很有可能会造成内存溢出。















 3583
3583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









