






我们都知道数组和链表是两种最基础的数据结构,几乎所有的数据结构都是通过这两种基础的结构进一步增强以及实现的。之前我们讲得哈希表,其实就是数组和链表两种结构复合而来的一种结构,它的目的是充分利用两者的优势,让数据的增删改查效率达到最理想化。
今天我们接着哈希表的思想,讲一种全新的数据结构,也就是树结构,树结构的出现是针对数组和链表这两种极端的数据结构做了协调。它不再是线性表,它能够保证咱们的增删改查效率都能够达到很好的效果。
接下来了,我们针对针对树这种数据结构,进行一个详细的讲解。
一、什么是树?
相比之前我们讲过的数组、链表等结构,树作为一种全新的数据结构,不再是简单、单一的线性结构,而是一种比线性表更为复杂的非线性结构,这就意味着树的学习会比前面的知识增加些许难度。
树这种结构的出现主要是因为链表和数组这两种结构的两极化太严重,这两种结构各自的优缺点太极端。对于数据而言,我们往往希望增删改查操作效率都能达到比较良好的性能。让咱们的数据读写操作保持一个比较稳定的状态,树正好是一种比较完美的数据结构,论查询,肯定比不上数组按照地址定位数据,论增删,同样比不过链表通过指针操作结点。它最突出的优点就是一种能够将读写操作控制到一个比较平衡且性能高效的状态,下面就这种结构,我们进一步进行讲解。
二、树的常用术语
咱们在讲树的常用术语之前,先来看看树的内存模型图:
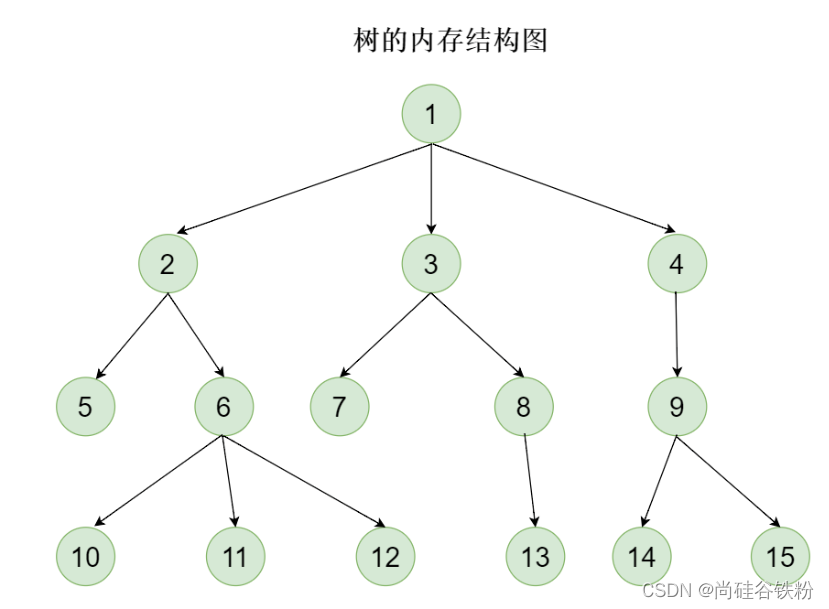
结点
在树结构中,最小的构成单元叫做树中的结点,例如在如上图中,1-15对应着树中的每一个结点。
父结点
在树结构中,一个结点可以衍生出若干个子树,而这个结点咱们成为对应子树的父结点,比如2号结点,衍生出2棵子树。即5号子树以及6号子树。我们称2号结点为5号子树以及6号子树的父结点。同理6号结点称之为10、11、12号子树的父结点。
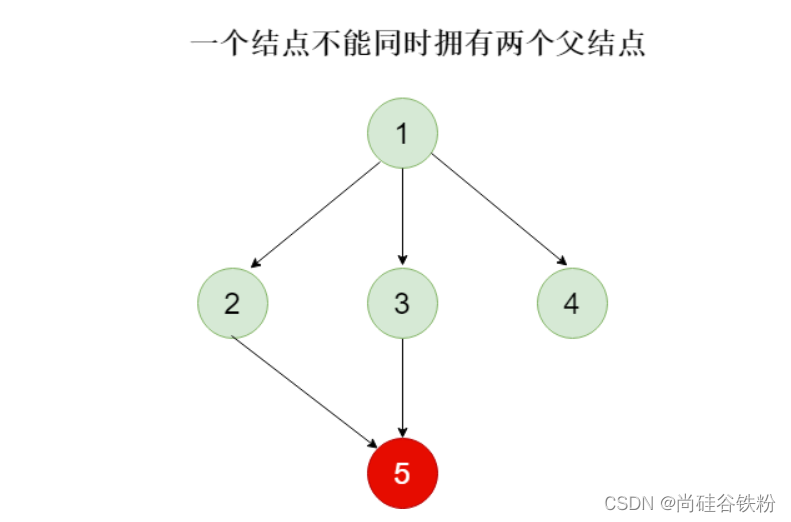
值得注意的是,一个子树只能有一个父结点,就像咱们Java继承时只允许只有一个父类一般。咱们5号子树的父结点为2,就不能再有父结点了。例如:下面的情况就是错误的:
叶子结点
没有子树的结点,咱们称之为叶子结点,表示咱们当前这个结点已经衍生到头了,例如:在咱们1-15号结点中,5号、7号、10-15号结点没有其对应的子树了,所以呢,这些结点也被称作叶子结点。
子树
一棵树,大多时候是由N多个子树组合起来的,就像我们生活中实际存在的树一般,一个树由很多枝干,每个枝干也可以繁衍出不同的树结构出来,我们可以将树的枝干理解成相应的一棵棵子树。在咱们树的内存模型图中,首先1-15号结点整体组成一棵树,但是对2号结点本身而言,我们忽略它的父结点1号结点时,它本身也是一棵树,我们换个角度,同样可以把咱们的2、5、6、10、11、12号结点看成一棵以2号结点为根结点进而组合而成的树,同理9、14、15号结点也可以看作以9号结点作为根结点的树,像咱们15号结点,只有一个结点,同样可以看作以15号结点作为根结点且没有任何其它结点的树。对它们各自的父结点来说,这些新的树又叫做父结点的子树,比如:2、5、6、10、11、12号结点构成的树叫做1号结点的一颗子树,9、14、15号结点构成的树叫做4号结点的一颗子树。
结点的度
介绍完子树的概念过后,我们可以清楚地知道一棵树可以看作是由多个子树组合起来的。我们将一个结点含有子树的个数称作当前结点的度。例如:比如根结点1号含有3棵子树,分别为以2号作为根结点的子树、以3号结点作为根结点的子树以及以4号结点作为根结点的子树。我们就说1号结点的度为3。2号结点含有2棵子树,我们就说2号结点的度为2。同理15号结点作为叶子结点,没有子树了,那么15号结点的度就为0。
树的度
说完了结点的度后,咱们来讲一下什么是树的度,树的度就是取结点度的最大值,我们往往用具有最大度的结点来描述咱们树的度。比如咱们1-15号结点中,1号节点有3棵子树,6号结点也具有3棵子树,我们就说咱们树的度为3。
结点的层次
从根结点开始,其层次为1,以后每衍生出一代分支,我们就让其对应的层次自增。比如1号结点对应的层次为1,2、3、4号结点所在的层次为2,5-9号结点所在的层次为3,10-15号结点所在的层次为4。
树的高度
和树的度类似,树的高度就是最大的结点层次,在咱们的这棵树中,树的高度为4。
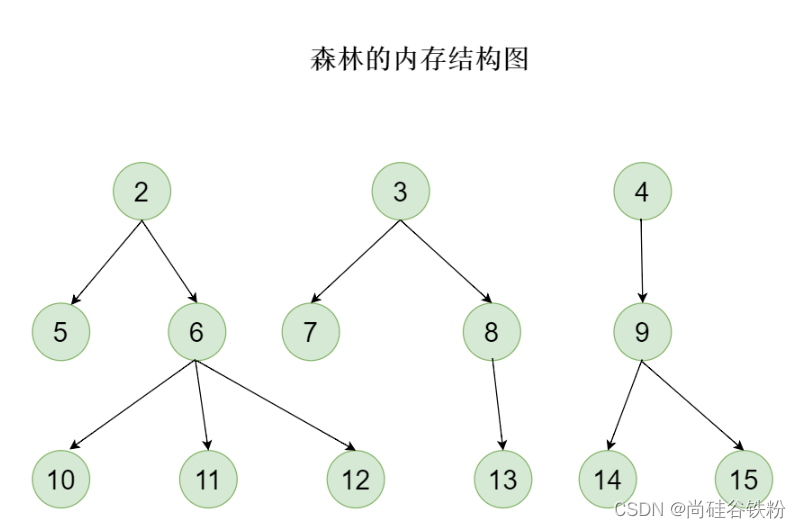
森林
对咱们这棵树,剔除根结点后,就构成了3棵独立的树,这3棵树就形成了一个森林,所以呢,森林就是多棵树的集合。如下图所示:
三、二叉树
说完了树的一些相关术语外,可以看出咱们的树结构还是比较复杂的,一次肯定讲不完,那么今天咱们先从最简单的一种树说起,那就是咱们今天的核心重点二叉树,那么什么是二叉树呢?咱们不妨接着往下看:
概念
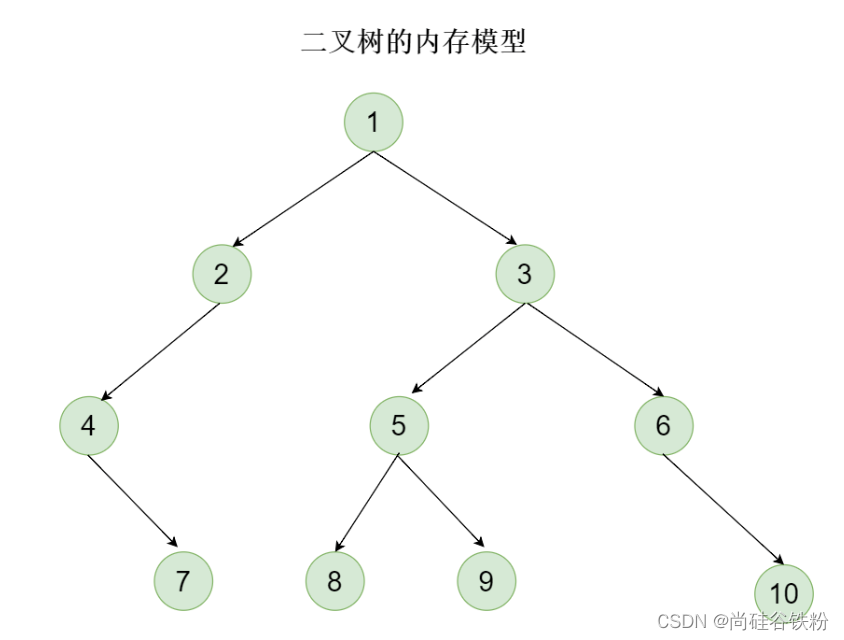
满足每个结点的度不超过2的树咱们称之为二叉树,也就是一个结点最大只能有两棵子树,其中一个结点的两棵子树又分别叫做其父结点的左子树和右子树。如下图所示:
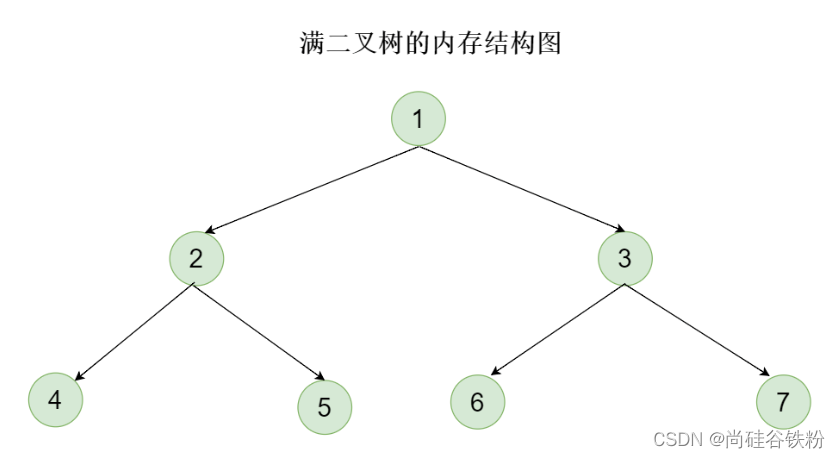
满二叉树
每个结点的度都能达到2的二叉树咱们称之为满二叉树,对于满二叉树,我们设层次为n,那么它每一层对应的结点个数很轻松的可以算出为2^(n-1)。满二叉树的内存模型图如下:
完全二叉树
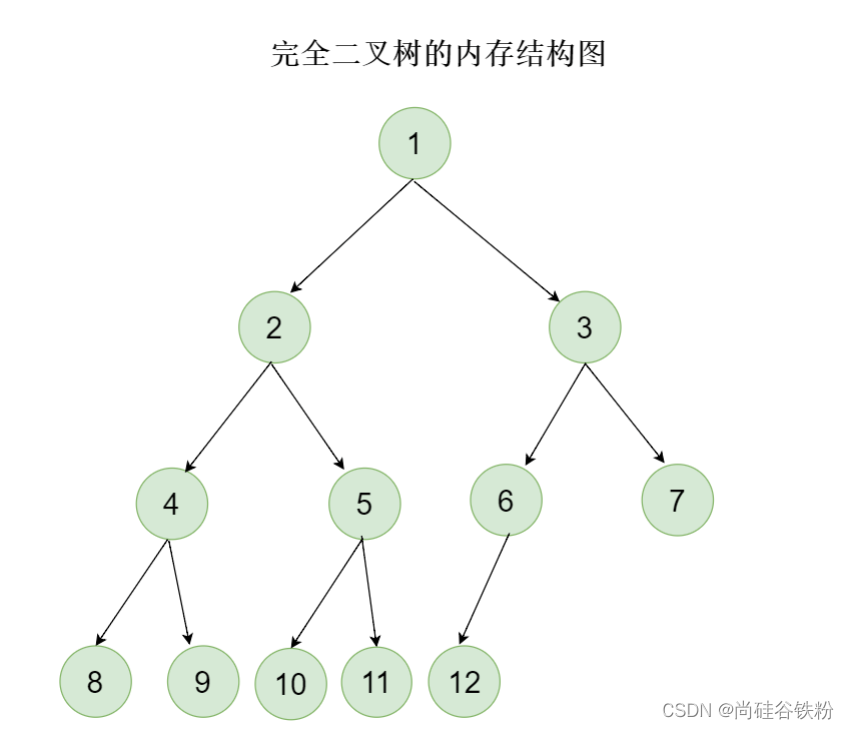
叶子结点只能出现在最下层以及次下层,并且最下层的叶子结点都位于若干个左子树上,满足这种情况的二叉树咱们又可以成为完全二叉树。可能完全二叉树的概念有点难理解,咱们通过下面的图进一步理解:
完全二叉树不要求每个结点的度数都达到2,但是一定是满足前面的结点都放满了,后面的结点才能添加,比如下面的就不是一棵完全二叉树。
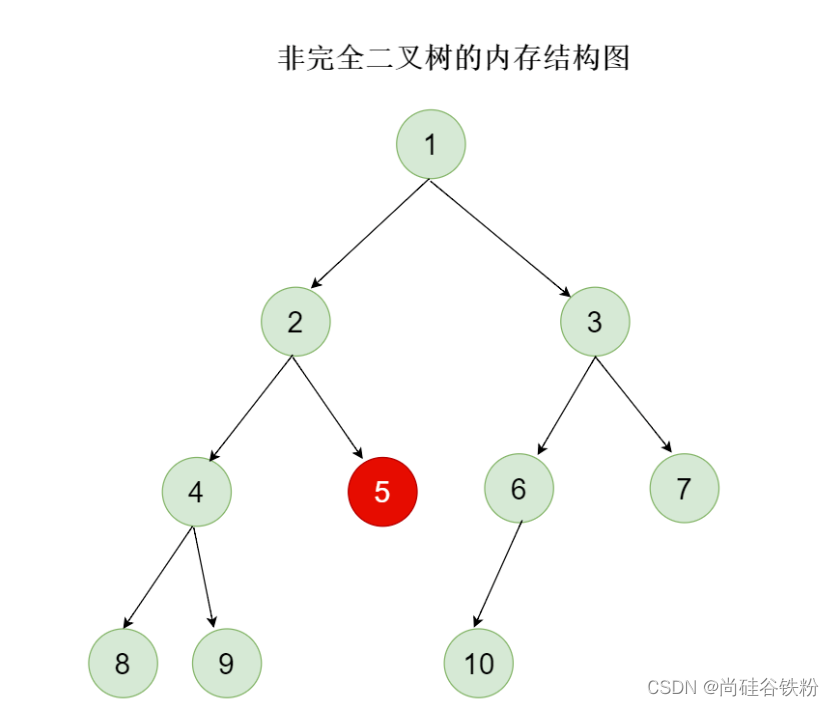
为什么下面的这棵二叉不能称作完全二叉树呢,因为前面的结点5号结点都没有放满子树,就添加到6号结点了,咱们的完全二叉树一定是先放满前面才能添加后面,并不一定要求每个结点的度都达到最大值2。
四、二叉树实现
4.1结点类
下面了,我们通过链表来实现二叉树,和链表类似,在咱们二叉树中,最小的组成单位为结点:
package com.ignorance.tree.node;
/**
* @ClassName Node
* @Description 二叉树结点类
* @Author ignorance
* @Version 1.0
**/
public class Node<K extends Comparable<K>,V> {
private K key;
private V value;
public Node<K,V> left;//左子树指针
public Node<K,V> right;//右子树指针
public Node(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
@Override
public String toString() {
return "Node{" +
"key=" + key +
", value=" + value +
'}';
}
}
在Node类中,我们主要定义了4个成员变量,我们需要通过键来查询其对应的值,所以在Node类中定义了key-value键值对,left表示当前结点所对应的左子树,right表示其对应的右子树。其中key需要继承Comparable比较器接口,主要用于比较key的大小,方便我们二叉查找树后续的添加操作。
4.2创建BinarySearchTree核心类
我们创建BinarySearchTree核心类,并定义两个成员变量,其中root表示当前二叉查找树的根结点,size用于表示当前树中有效的结点个数。
package com.ignorance.tree;
import com.ignorance.tree.node.Node;
/**
* @ClassName BinarySearchTree
* @Description 二叉查找树
* @Author ignorance
* @Version 1.0
**/
public class BinarySearchTree<K extends Comparable<K>,V> {
//根结点
private Node<K,V> root;
//二叉树有效结点个数
private int size;
}
4.3二叉树添加结点方法
对于添加方法,我们创建两个重载方法,如下所示:
public void put(K key,V value){
}
private Node put(Node<K,V> currentTreeNode,K key,V value){
return null;
}
第一个put方法用于向整棵树添加结点,第二个用于向树中指定子树添加结点。接下来咱们详细讲一下二叉树的添加流程:
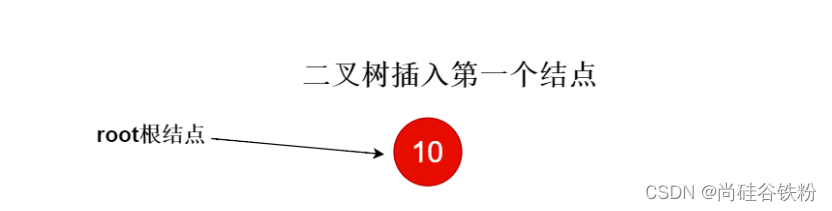
如果当前二叉树中没有一个结点,我们将新插入的结点作为根结点即可,如下图所示:
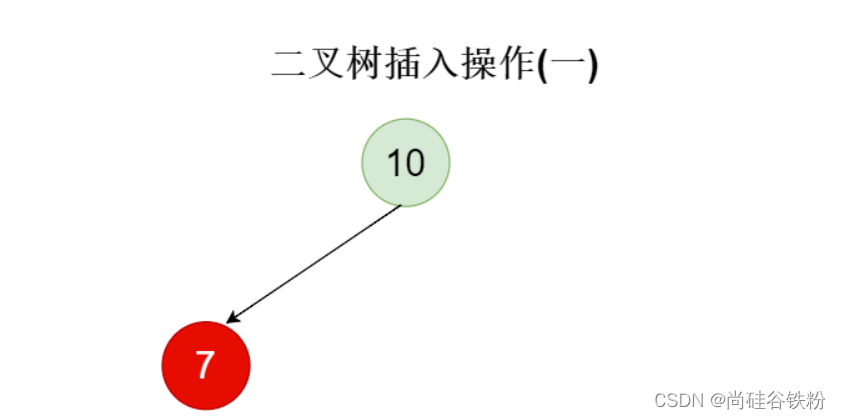
如果插入的结点并不是根结点,比如咱们向二叉树插入第2个结点时,则需要跟当前根结点比较,如果待插入的结点的key比根结点key小,则需要将待插入结点作为根结点的左子结点,反之则将其作为根结点的右子结点。例如:我们插入的第二个结点的key为7,它比其父结点10小,所以将其作为左子结点添加到二叉树中。如下图所示:
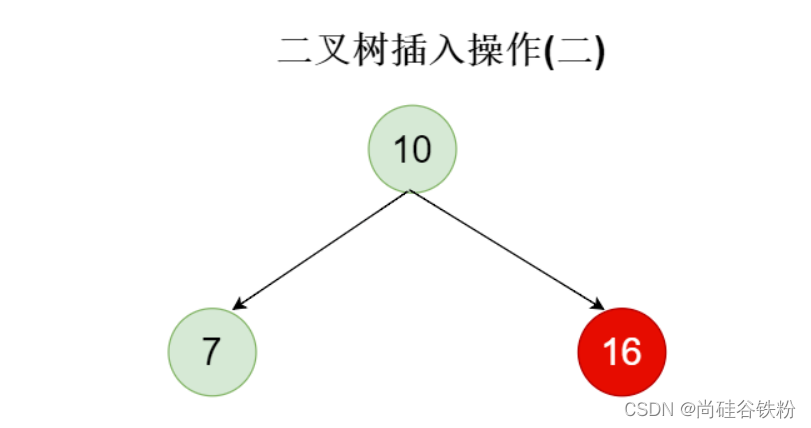
我们插入的第三个结点的key为16,它比其父结点10大,所以将其作为右子结点添加到二叉树中。
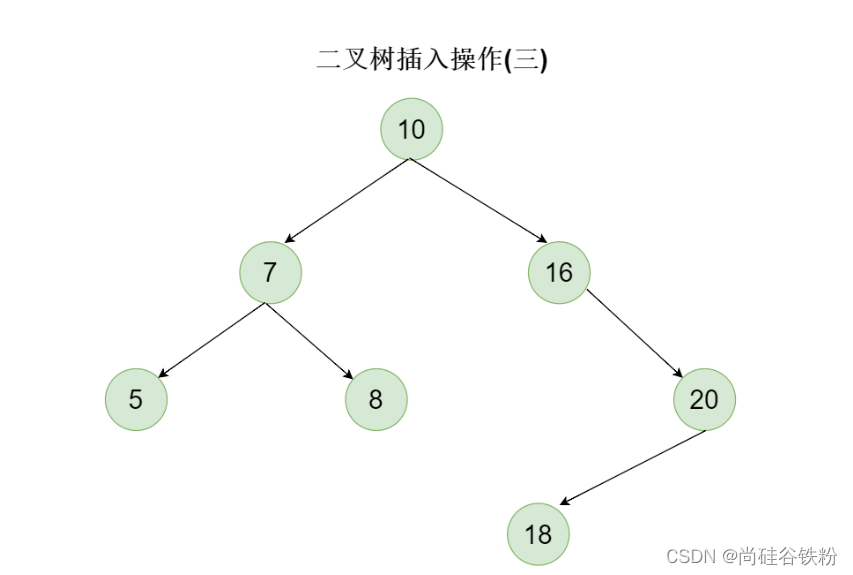
依次类推,我们每次插入结点都需要和当前结点的key值进行比较,如果待插入结点的key比当前结点key小,则添加到它的左子结点,待插入的结点的key比当前结点key大,则插入到它的右子结点。
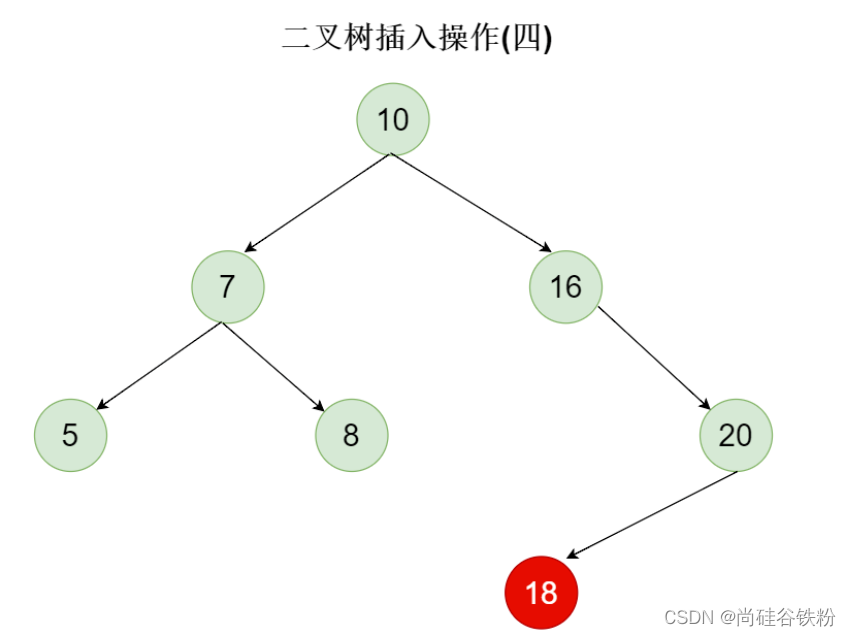
那么此外还有种情况,比如此时咱们的二叉树中已经存在18这个结点了,这个时候我们应该怎么添加呢?
1.跟根结点10进行比较,发现当前结点的key比10大,则需要 再比较它的右子结点;
2.我们发现18仍然比16大,则继续比较16的右子结点;
3.这个时候我们需要比较18和20的大小,会发现18比20小,下一步就需要比较18和20的左子结点大小;
4.我们最后20的左子结点的值也为18,此时两者相等,我们直接就不需要再添加了,直接将原来key所对应的value值修改为最新的即可。如下图所示:
核心实现代码如下:
public void put(K key,V value){
this.root = put(root,key,value);
}
private Node put(Node<K,V> currentTreeNode,K key,V value){
//如果当前子树为空,则创建新的结点
if (currentTreeNode == null){
this.size++;
return new Node(key,value);
}
//比较待插入结点key和当前结点key的大小
int result = key.compareTo(currentTreeNode.getKey());
//如果待插入结点比当前结点小,则继续和左子树进行递归
if (result < 0){
currentTreeNode.left = put(currentTreeNode.left,key,value);
}else if(result > 0){
//如果待插入结点比当前结点小,则继续和右子树进行递归
currentTreeNode.right = put(currentTreeNode.right,key,value);
}else {
//能走到这儿,则说明待插入结点和跟当前结点的key相等,直接替换对应的value值即可
currentTreeNode.setValue(value);
}
return currentTreeNode;
}
4.4二叉树遍历
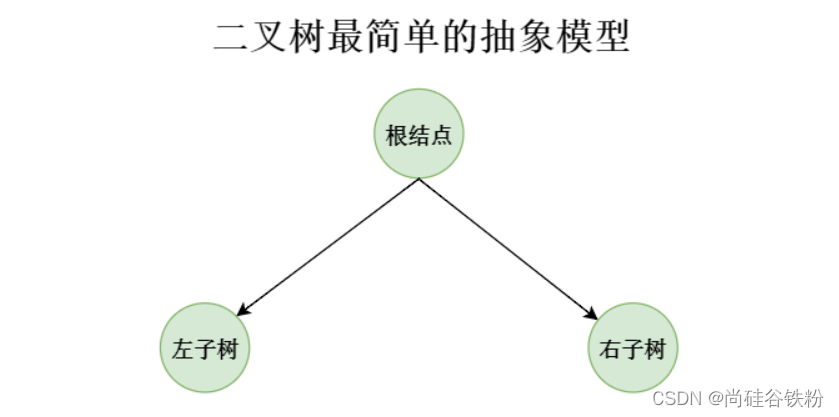
二叉树的遍历和之前的线性表相比,还是有很大差距的。之前的线性表能够按照一个方向走到底,一个循环就能直接完成,但是咱们的二叉树不是线性表,涉及到很多分支,所以并不能一次直接遍历完,所以针对二叉树的遍历,我们将其简单化,不管一棵二叉树多复杂,我们都可以将其抽象成一棵最简单的子树,一棵子树都是由最简单的三部分构成,当前结点以及其左子结点以及右子结点,如下图所示:
4.4.1 前序遍历
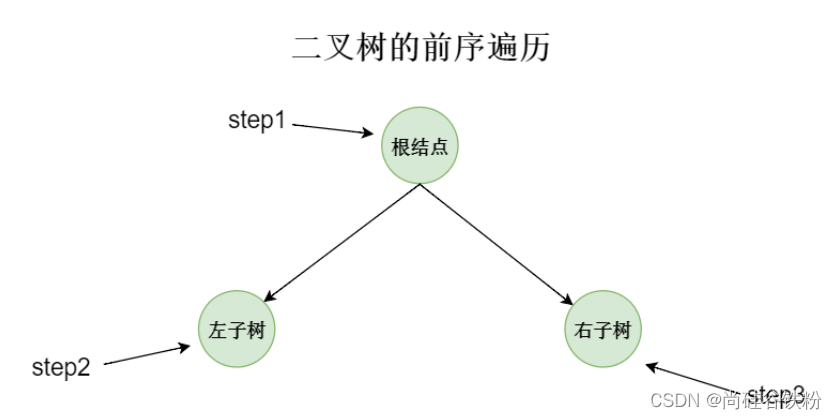
二叉树的前序遍历,前面我们也说过,我们先遍历根结点,然后再遍历左子树,最后再遍历右子树,如下图所示:
比如对咱们创建最开始的一棵树,我们在通过这棵树进行分析。如下图所示:
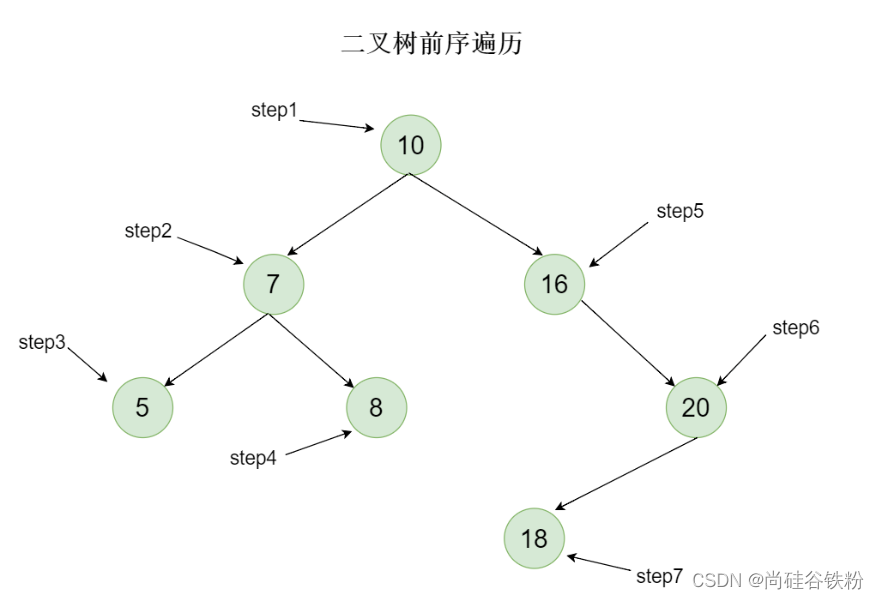
对咱们这棵树而言,前序遍历思想如下:
第一步:当遍历到根结点时,因为前序遍历先遍历根结点,所以第一步遍历出来的为10;
第二步:遍历左子树,我们这时候将7看作新的根结点,这时候再遍历新的根结点7;
第三步:7遍历完后再遍历它的左子树,这时候同理将5看作新的根结点,遍历完后再去遍历左子树,这个时候5已经成为叶子结点了,就不用继续向左递归了;
第四步:我们此时再去遍历7的右子树8,又将7的右子树8看作根结点,它已经成为叶子结点了,这个时候10的左子树已经完成遍历了;
第五步:下一步就去遍历10的右子树,我们将16看作新的根结点,先遍历16;
第六步:遍历完后再去遍历16的左子树,此时16左子树为空,则继续遍历16的右子树;
第七步:遍历完20后,再将20的左子节点18看作新的根结点继续遍历,此时18已经成为叶子结点了,代表咱们最原始根结点的右子树已经完成遍历,也就代表咱们前序遍历结束。
所以呢,集合咱们的分析,咱们二叉查找树最后的遍历顺序为10->7->5->8->16->20->18。
接下来咱们通过代码实现二叉树的前序遍历,同样我们创建两个重载方法完成二叉树的前序遍历:
public void preShow(){
prevShow(root);
public void prevShow(Node<K,V> currentTreeNode){
//当前子树非空校验
if (currentTreeNode == null){
return;
}
//将当前结点作为根结点,第一步遍历
System.out.println(currentTreeNode);
//第二步递归遍历左子树
if (currentTreeNode.left != null){
prevShow(currentTreeNode.left);
}
//第三步递归遍历右子树
if (currentTreeNode.right != null){
prevShow(currentTreeNode.right);
}
}
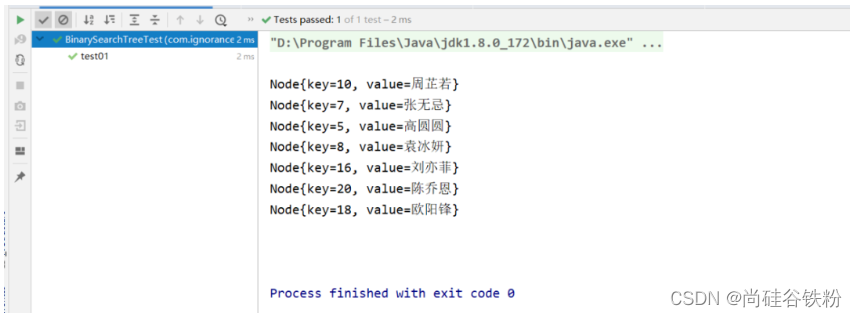
下面咱们测试一下咱们的结点添加和前序遍历方法,测试代码如下:
@Test
public void test01(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
binarySearchTree.put(18,"欧阳锋");
binarySearchTree.preShow();
}
咱们再看一下咱们的测试结果:
4.4.2 中序遍历
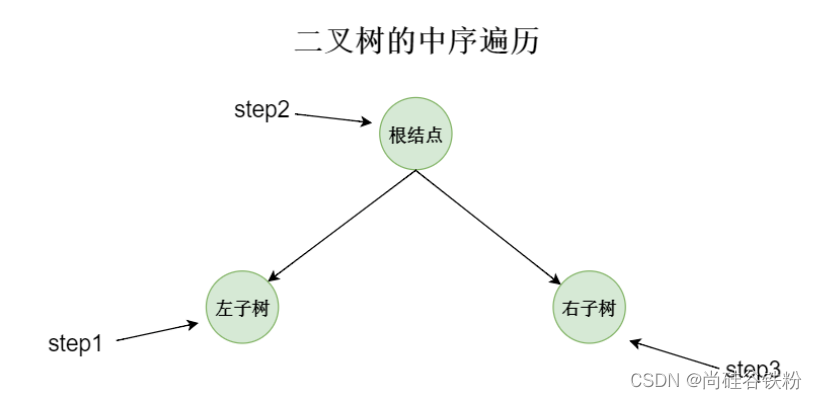
二叉树的中序遍历,我们先遍历左子树,然后再遍历根结点,最后再遍历右子树,如下图所示:
比如对咱们创建最开始的一棵树,我们在通过这棵树进行分析。如下图所示:
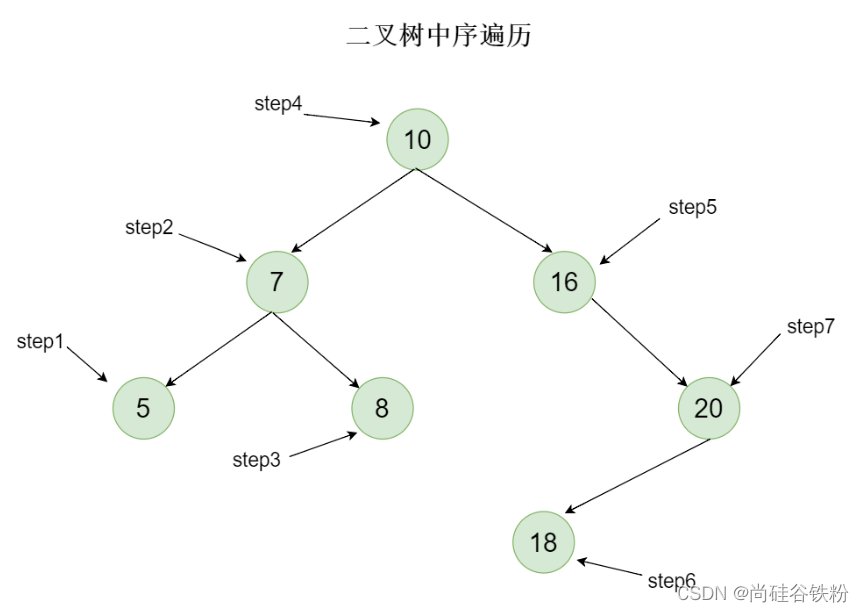
对咱们这棵树而言,中序遍历思想如下:
第一步:当遍历到根结点时,因为中序遍历先遍历左子树,所以下一步查找根结点对应的左子树;
第二步:将7作为左子树的根结点,继续查找7所对应的左子树;
第三步:将5作为7所对应左子树的根结点,此时继续查找5所对应的左子树,此时5已经为叶子结点了,所以就不用再继续遍历左子树了。下一步遍历根结点,所以第一次遍历到的结点为5;
第四步:5作为根结点遍历完后继续遍历它的右子树,此时将8看成右子树的根结点,我们继续查找它的左子树,可以看出8此时已经是叶子结点,所以左子树不用再递归,下一步遍历根结点8,8遍历完后遍历8这个结点对应的右子树;
第五步:此时8没有右子树,这时候遍历完后,代表原始根结点10对应的左子树已经遍历完全,下一步我们遍历根结点10;
第六步:10遍历完后,继续查找它的右子树;
第七步:此时将16作为10对应右子树的根结点,此时我们继续查找16对应的左子树;
第八步:16没有左子树,此时将16看作根结点,遍历16,遍历完后再查找16的右子树;
第九步:将20看作16右子树的根结点,继续查找20所对应的左子树;
第十步:将18看作20所对应左子树的根结点,继续向左查询;此时18已经没有左子树了,下一步遍历18这个根结点,18遍历完成后,继续搜索18所对应的右子树;
第十一步:18为叶子结点,右子树不存在,这个时候代表20的左子树遍历完成,下一步遍历20,20遍历完成后,继续搜索20所对应的右子树;
第十二步:20所对应的右子树为空,这个时候相当于20这棵子树已经遍历完全,也表示16所对应的右子树遍历完成。
以上步骤完成过后,代表咱们整棵树完成了所有遍历。集合咱们的分析,咱们二叉查找树中序遍历最后的顺序为5->7->8->10->16->18->20,有没有发现这个顺序刚好是从小到大排好序的数据,所以说,二叉树的中序遍历是有序的一种遍历方式。
下面我们通过代码完成中序遍历,跟之前同理,常见两个重载方法,一个表示对整棵树进行遍历,另外一个方法表示对某个子树进行遍历,如下所示:
public void middleShow(){
middleShow(root);
}
private void middleShow(Node<K,V> currentTreeNode){
//非空校验
if (currentTreeNode == null){
return;
}
//中序遍历:第一步,遍历左子树
if (currentTreeNode.left != null){
middleShow(currentTreeNode.left);
}
//中序遍历:第二步,遍历当前根结点
System.out.println(currentTreeNode);
//中序遍历:第三步,遍历当前右子树
if (currentTreeNode.right != null){
middleShow(currentTreeNode.right);
}
}
以下是中序遍历的测试代码:
@Test
public void test02(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
binarySearchTree.put(18,"欧阳锋");
binarySearchTree.middleShow();
}
咱们再看一下对应的测试结果:
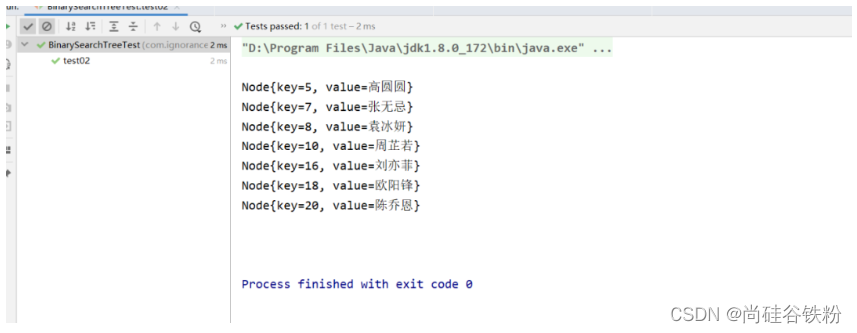
4.4.3 后序遍历
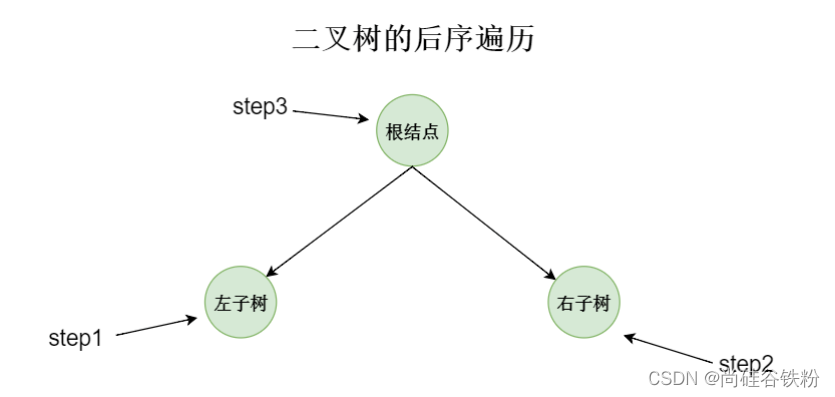
二叉树的后序遍历,我们先遍历左子树,然后再遍历右子树,最后再遍历当前根结点,如下图所示:
比如对咱们创建最开始的一棵树,我们在通过这棵树进行分析。如下图所示:
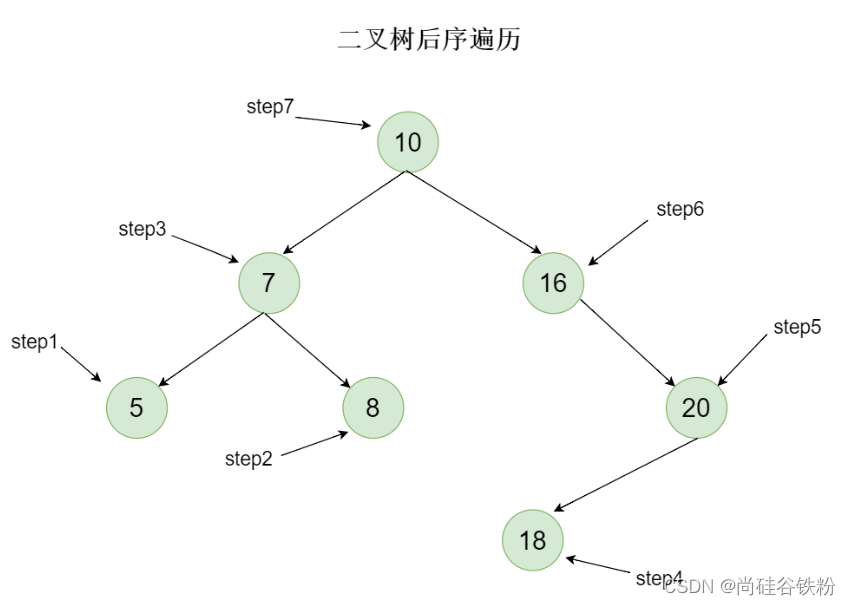
对咱们这棵树而言,后序遍历思想如下:
第一步:查找到根结点10,因为后续遍历先查找左子树,所以下一步我们会查找根结点10所对应的左子树;
第二步:我们继续查找10的左子树,即以7为根结点的子树,将此时的7作为子树的根结点,我们再查找7所对应的左子树;
第三步:我们再继续查找7的左子树,也就是将5看作根结点的子树,此时5作为叶子结点,再也没有左右子树了,即查找出咱们的第一个结点为5;
第四步:5这棵子树遍历完全后,也代表着7的左子树遍历完成,那么下一步我们再查找7的右子树,即以8为根结点的子树;
第五步:8这个节点已经是整棵树的叶子结点,即不存在左右子树,所以这个时候就不用再向下搜素了,所以咱们遍历出的第二个结点为8;
第六步:8这个节点遍历完后,表示7的右子树已经全部遍历完全,所以接下来就遍历出7这个节点;也就是咱们第三次遍历出来的结点为7;
第七步:7遍历完成后,表示根结点10所对应的最字数遍历完成,下一步咱们需要遍历根结点10所对应的右子树。即以16作为根结点的子树;
第八步:将16作为子树的根结点,下一步继续查找16的左子树,我们可以看出咱们16结点没有对应的左子树了,所以接下来查找16的右子树。也就是以20作为根结点的子树;
第九步:对20这棵子树,继续搜索20的左子树,也就是以18为根结点的子树;
第十步:对18这棵子树,18已经作为整棵树的叶子叶子结点了,所以这个时候咱们遍历出的结点就是18;
第十一步:18遍历完成后,也就代表着20的左子树遍历完成,下一步遍历20的右子树,又因为20的右子树为空,所以这个时候遍历出的结点为20;
第十二步:20遍历完成够,也就代表着16的右子树遍历完成,下一步遍历出来的结点也就是20;
第十三步:20遍历完后,也就代表着根结点10的右子树遍历完成,最后一步遍历根结点10即可;
接下来咱们通过代码实现二叉树的后序遍历,同样我们创建两个重载方法完成二叉树的后序遍历:
public void nextShow(){
nextShow(this.root);
}
private void nextShow(Node<K,V> currentTreeNode){
if (currentTreeNode == null){
return;
}
if (currentTreeNode.left != null){
nextShow(currentTreeNode.left);
}
if (currentTreeNode.right != null){
nextShow(currentTreeNode.right);
}
System.out.println(currentTreeNode);
}
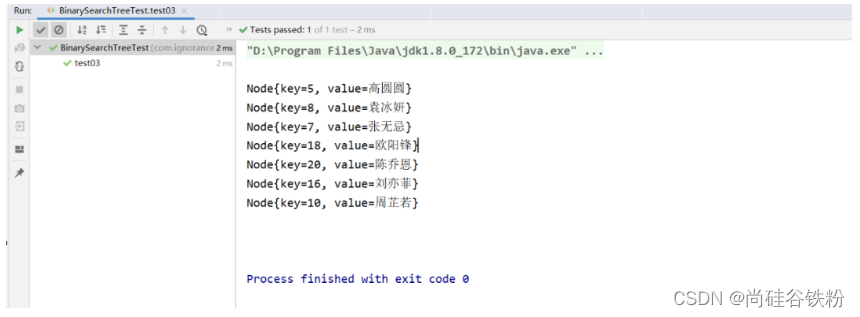
以下是后序遍历的测试代码:
@Test
public void test03(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
binarySearchTree.put(18,"欧阳锋");
binarySearchTree.nextShow();
}
咱们再看一下对应的测试结果:
4.5二叉树删除结点
一种数据结构,最核心的就是增删改查数据的过程,对咱们二叉树而言,也不例外,二叉查找树的删除功能也是咱们这几个功能最难的;下面咱们分析一下二叉树删除结点的思路:
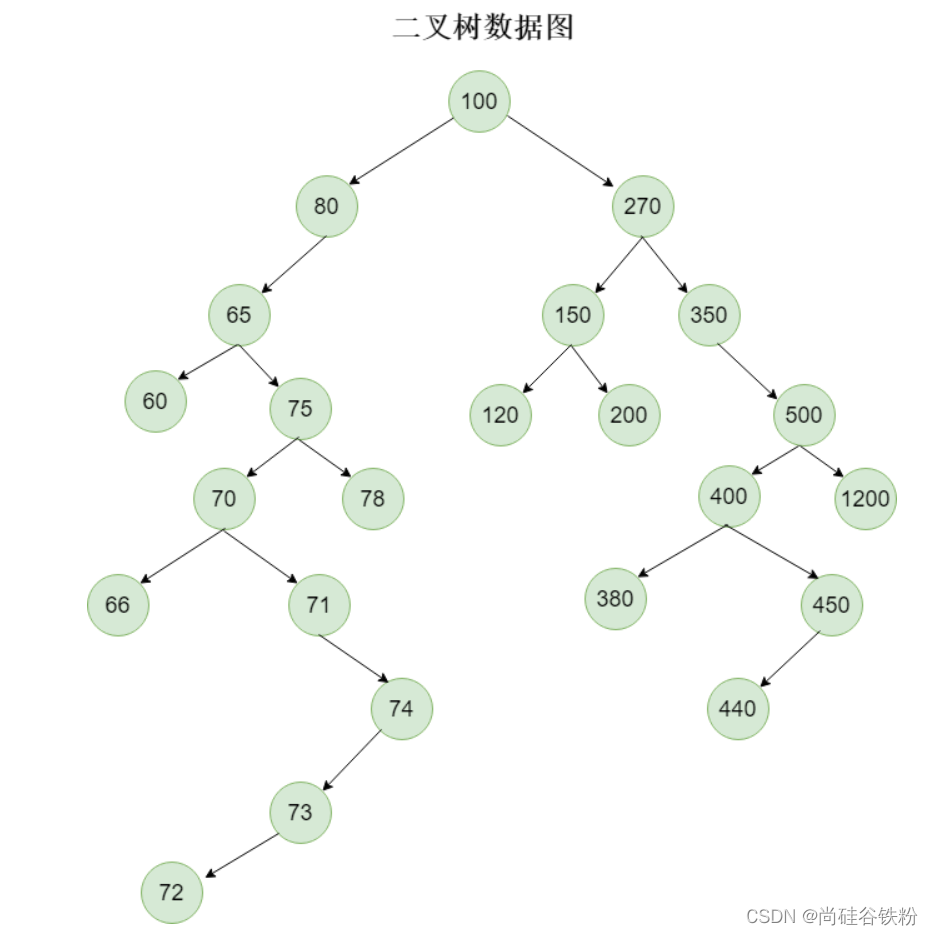
比如咱们创建一棵稍微复杂一点的二叉树,如下图所示:
比如这个时候我们要删除270号结点,如下图所示:
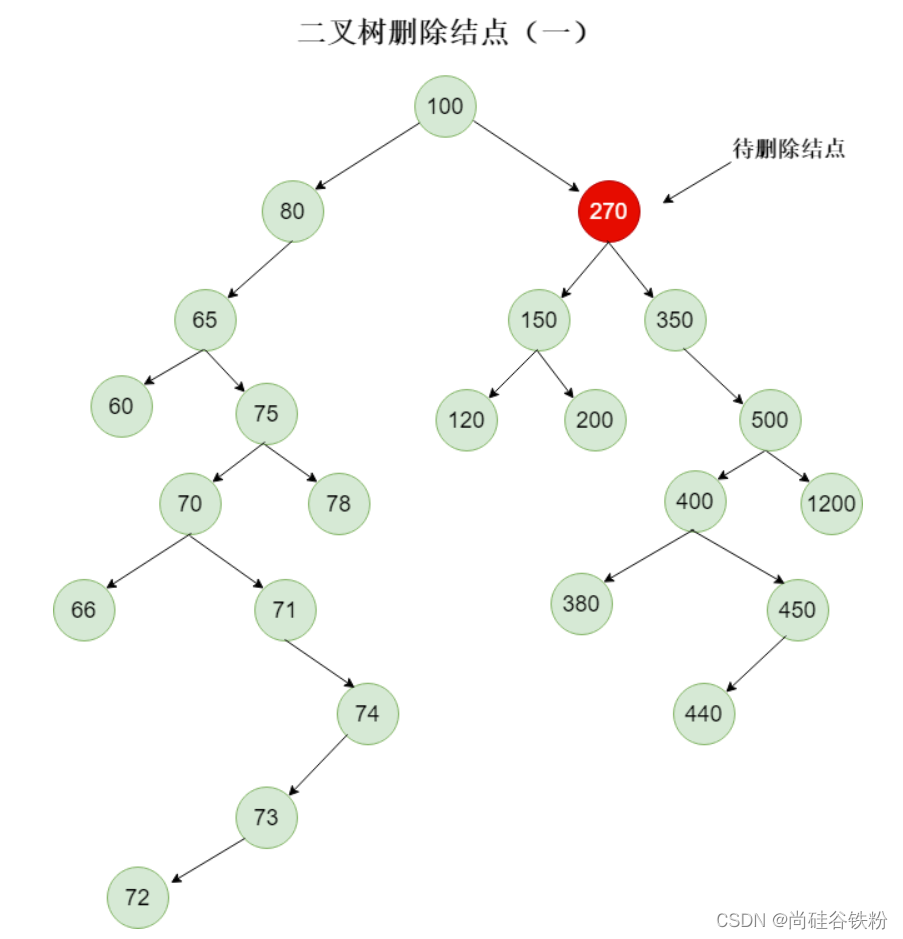
那么这个时候问题来了,我们删除270号结点,能直接将它的父结点也就是100的right指针设为null吗?如下图所示:
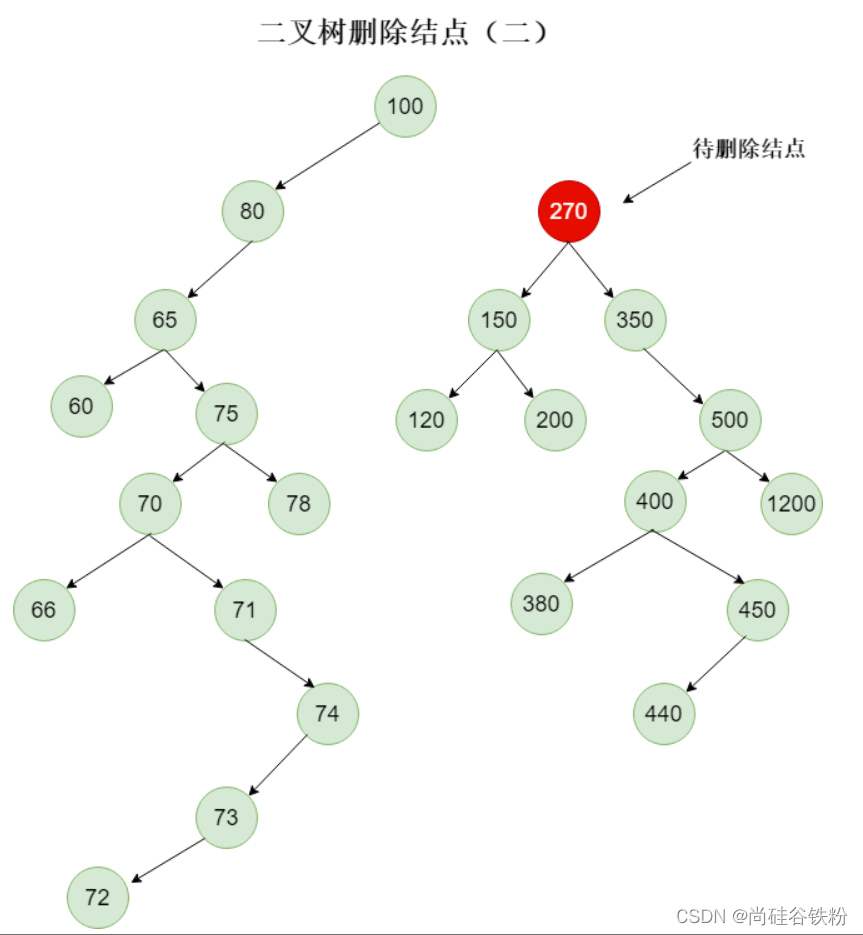
那么这种情况显然不合理,我们将待删除结点的right指针指向空,能满足将270号结点从原树删除,但是这时候删除的就不仅仅是270号这个结点了,而是把270号这棵子树所有结点删除了,这显然是不对不合理的。
既然上面的做法不对,那么我们根据链表的删除思路,将待删除结点的父结点的left指针指向待删除结点的left指针,将待删除结点的父结点的right指针指向待删除结点的父结点。这种思路如下图所示:
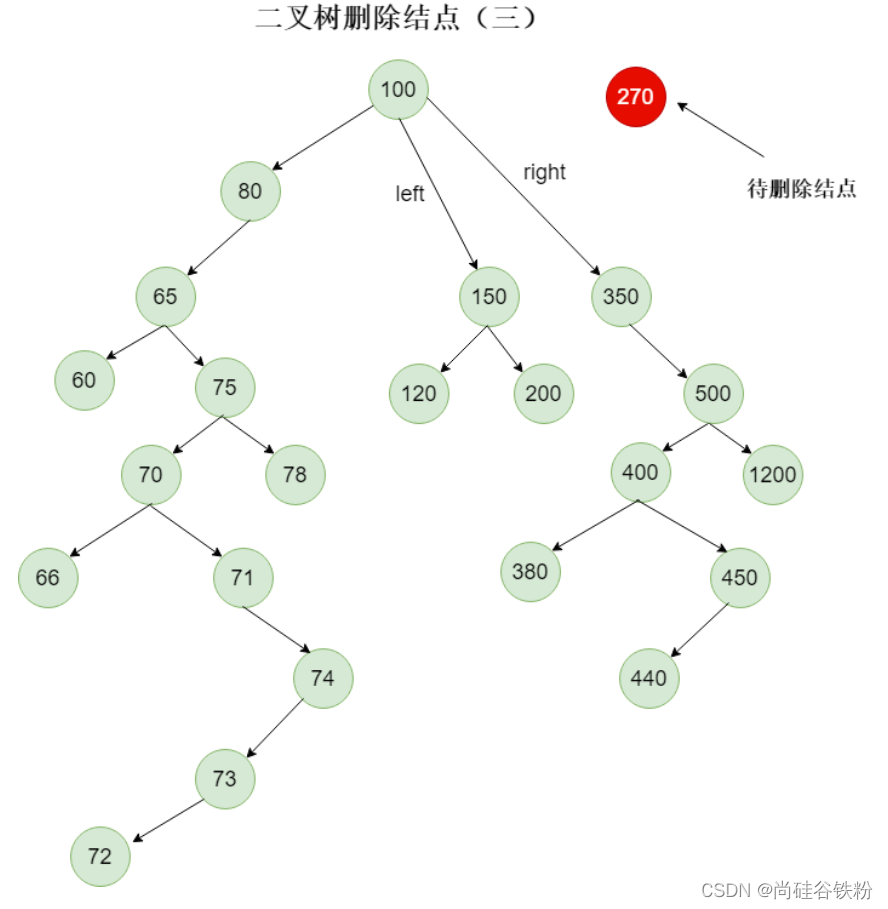
这种情况能满足将270号这个结点从原树中删除,但是这个时候出现更大的问题,如下图所示:
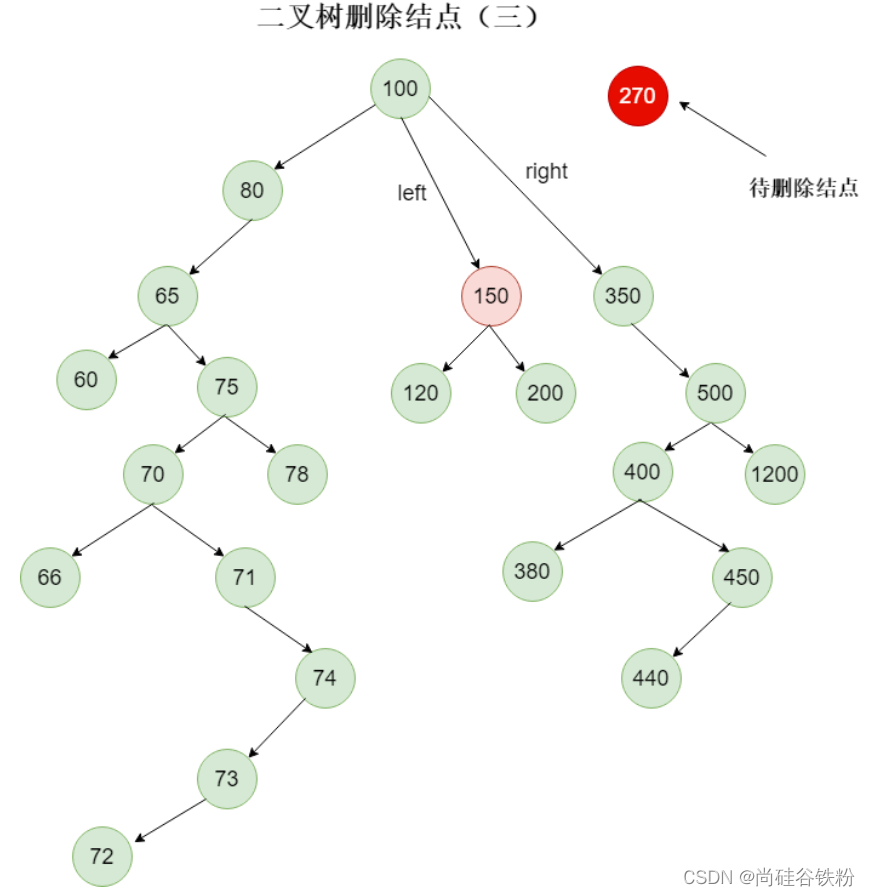
请注意咱们重点标记的150号结点,这个结点的位置是不是有很大的问题,咱们二叉查找树的规则是左子结点的元素都比父结点小,右子结点的元素比父结点大,那么这个150是不是比它的父结点100要大。出现这种问题的原因,那是因为我们150的添加规则是添加到最原始的270的左子结点,而270这个结点作为100的右子结点,肯定是比100要大的,就算是270的左子结点,满足的条件也是比100大,比270小而已。那么这么看来我们直接改变待删除结点的父结点left以及right指针指向显然是一种错误的做法,能够删除结点毋庸置疑,但是已经违反了咱们二叉查找树最开始的设计原则了。
那么这个时候,咱们应该怎么删除了,一定要清楚,咱们的二叉树删除有两个原则:一是将待删除结点从树中移除,而是还要保证任何一棵子树它的左子结点都比其父结点小,任何一棵子树的右子结点都比其父结点大。
所以咱们在删除结点时,除了考虑删除本身之外,还要考虑从删除的子树中选取一个能够满足规则的结点,作为能够替换待删除结点的结点作为待删除结点子树的父结点。
那么这个能够替换的结点时哪个结点呢?我们抽象出270这个结点对应的子树,如下图所示:
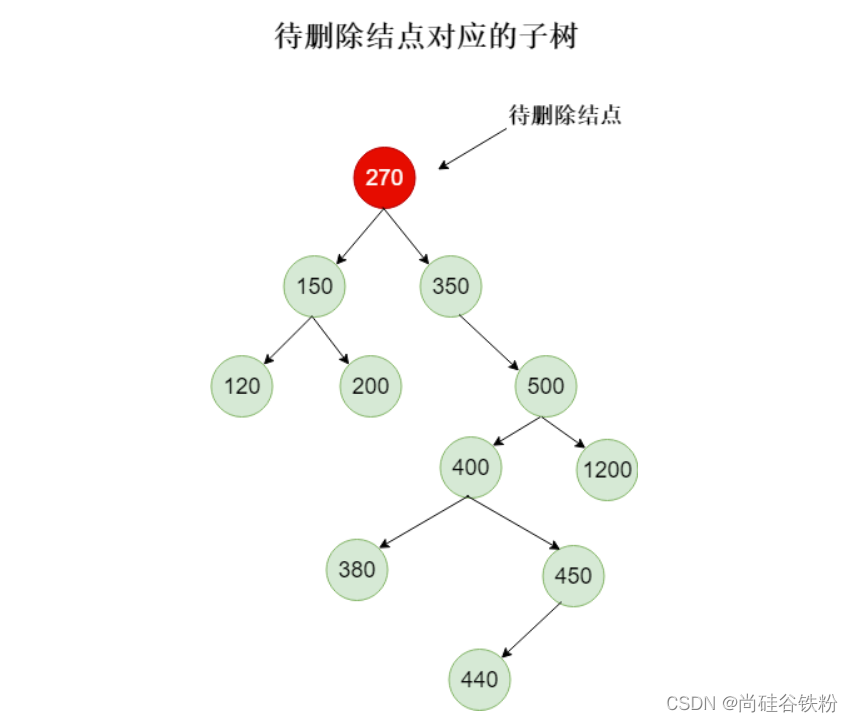
对以上子树而言,我们删除270这个结点后,我们选出一个结点来替换270这个位置,我们最开始使用根结点肯定是有问题的。所以我们选择一个结点,需要满足这个结点大于270所有的左子树结点,且小于270所有的右子树结点,那么我们应该选哪个结点呢?咱们都知道咱们父结点的右子树全部大于根结点,那么左子树全部小于父结点。我们选取待删除结点的右子树最小的一个结点是不是就可以了呢?对这个结点因为是右子树的最小值,肯定大于所有左子结点,又小于右子树的其他结点。那么咱们右子树的最小结点就是右子树的左子树叶子结点。如下图所示:
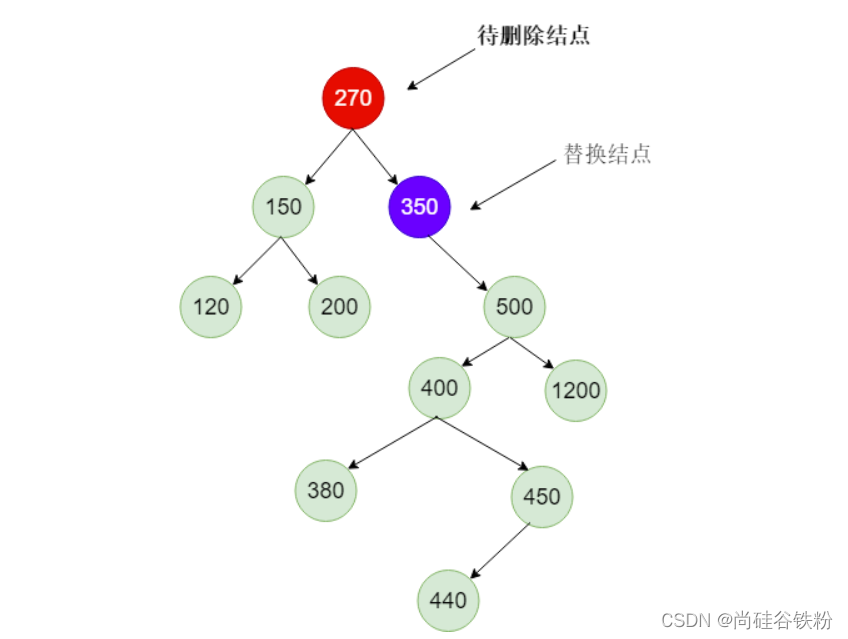
270的右子树以350号结点作为根结点,此时350没有左子树,那么我们选取的替换节点就会350,我们将350号结点替换270号结点位置,如下图所示:
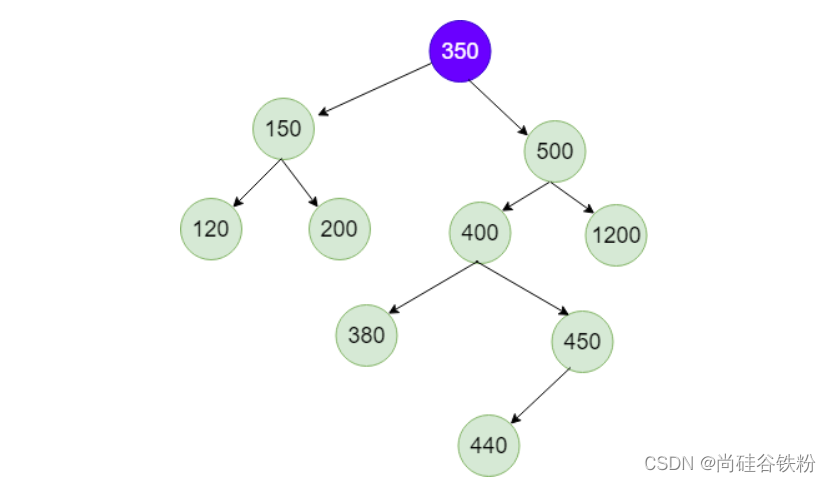
现在整棵树就完成将270号结点删除,且二叉树再度有序,如下图所示:

比如我们删除72号结点,这个时候72号结点已经成为叶子结点了,这时候就不用那么复杂了,直接找到它的父结点,将父结点left指针直接重置为null即可,如下图所示:
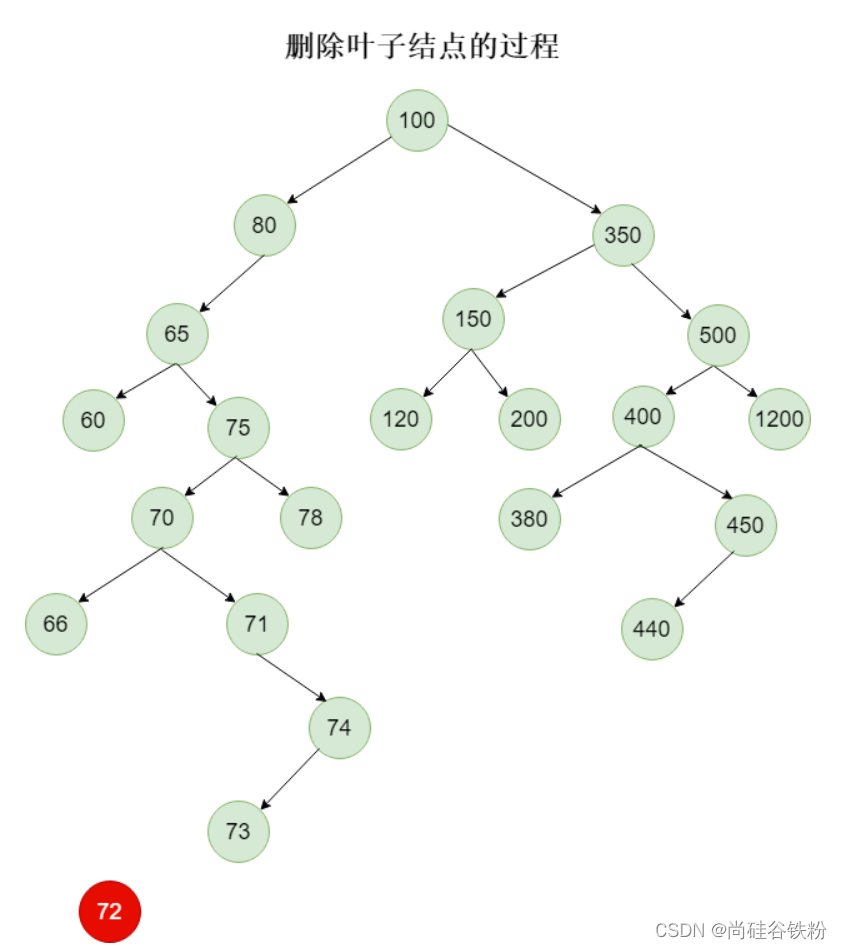
下一步,我们删除根结点100,这个时候我们查找100的右子树所对应左子树的叶子结点,即找到最小的右子树结点,过程如下图所示:
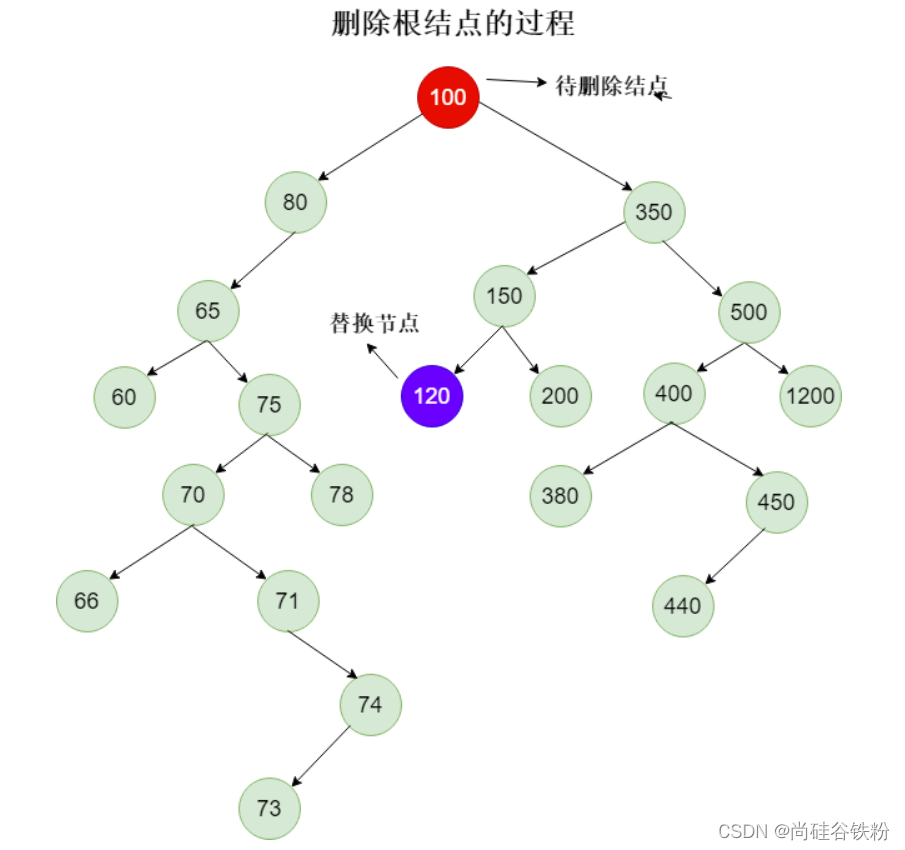
最终删除的结果如下图:
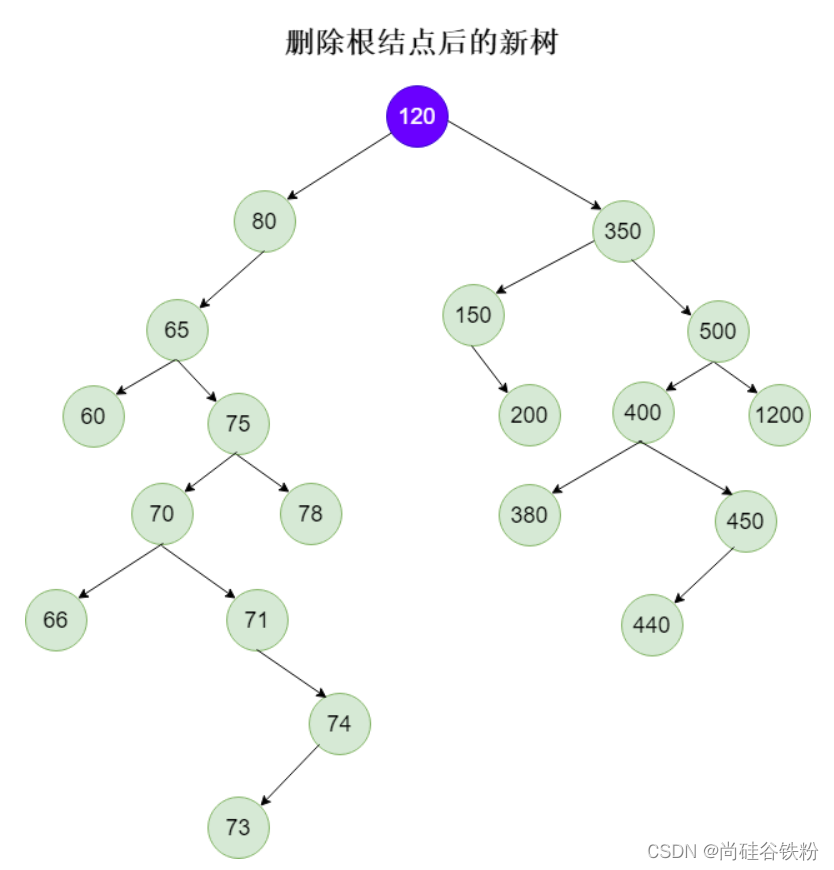
如果我们删除的结点没有右子树,那么这时候怎么办呢,比如我们这时候删除74号结点,如下图所示:
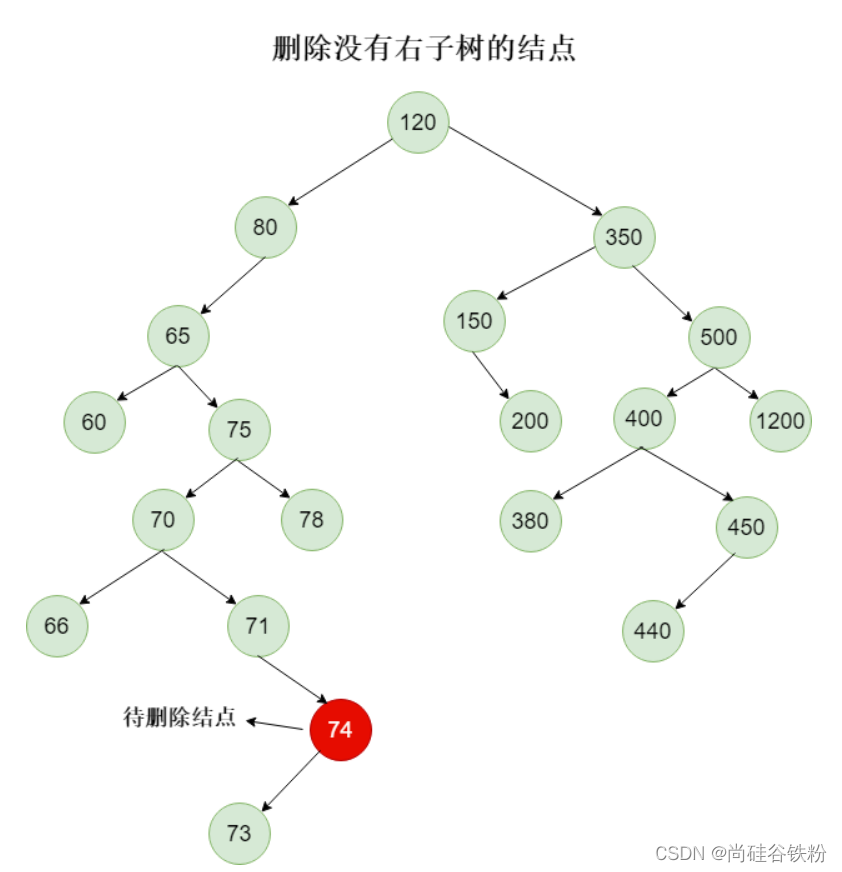
那么这时候也比较结点,我们直接让待删除结点的父结点的right指针指向待删除结点左子树就可以了,如下图所示:

同理待删除结点没有左子树,因为右子树本来就有序,就不用再多次一举去找替换结点了,那么直接让待删除结点的父结点left指针指向待删除结点的右子树即可;比如我们删除150号结点,那么直接让350号结点的left指向200号结点即可,如下图所示:
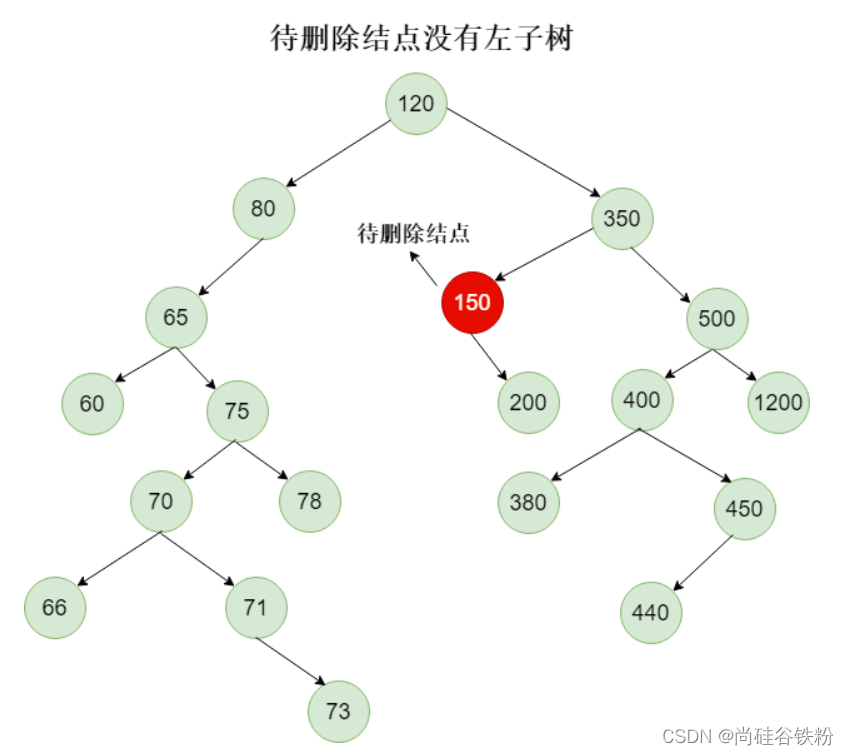
那么删除后的结果如下图所示:
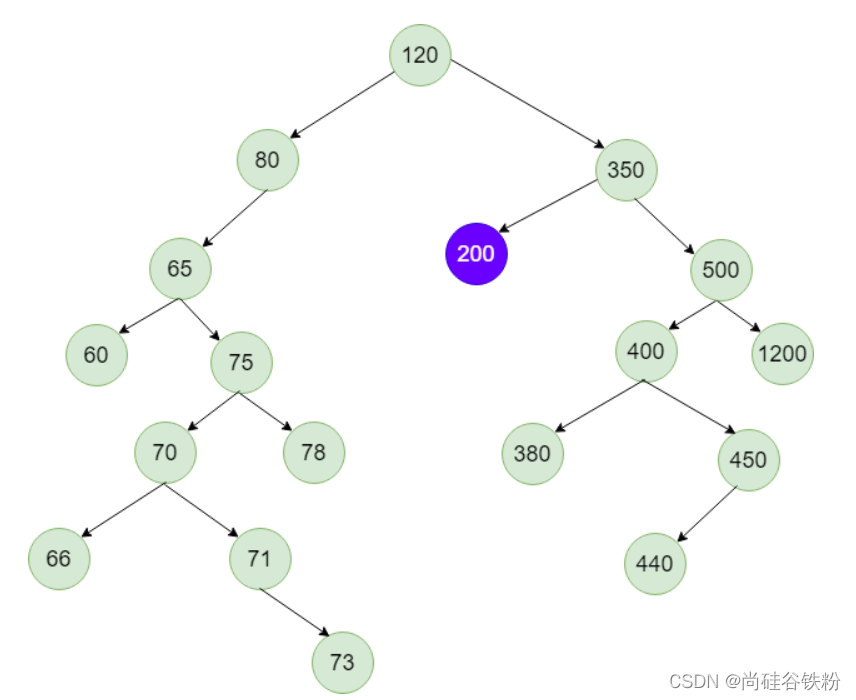
最后一种情况,如果咱们删除结点的右子树的最左节点并不是叶子结点,这个替换节点还存在右子树的情况,比如我们再添加几个结点,如下图所示:
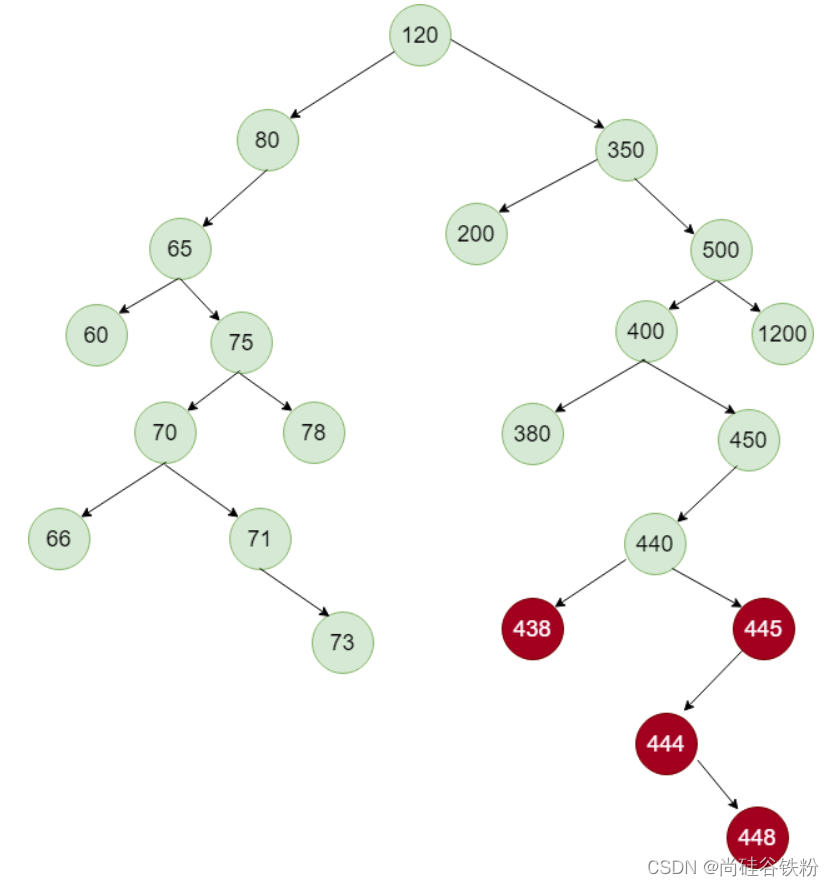
比如这个时候我们删除440号结点,这个时候我们替换结点为444,但是444号结点还存在右子树,也就是448号结点,我们删除且替换的时候还需要445号结点的right指针指向448号结点,也就是替换结点的右子树,如下图所示:
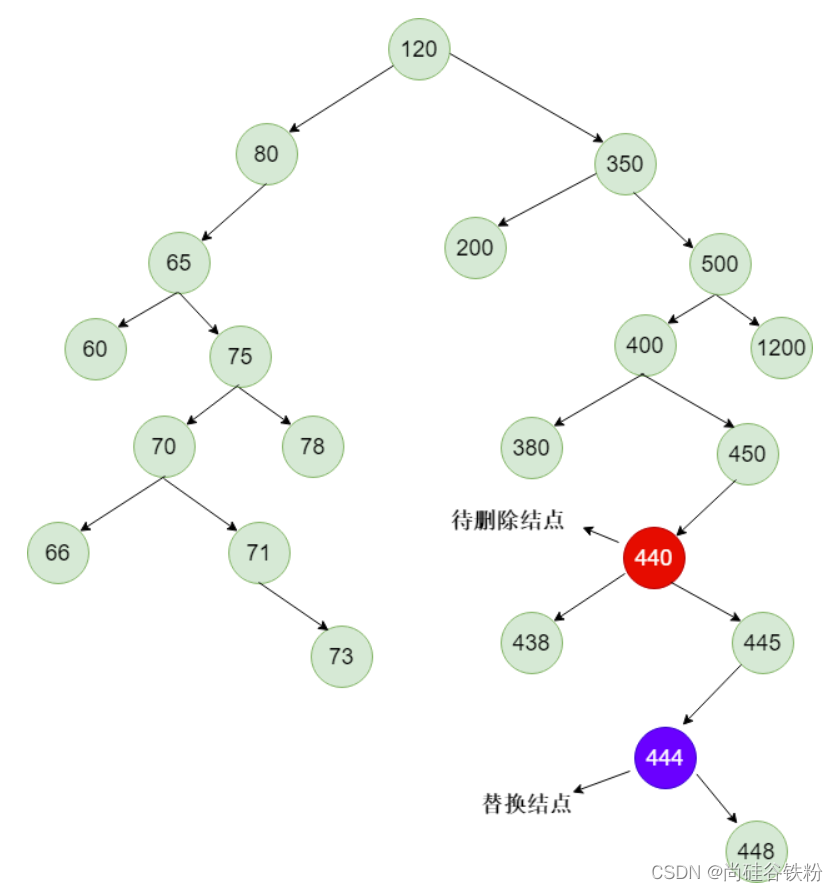
将替换结点的右子树关系绑定道待删除结点父结点上,如下图所示:
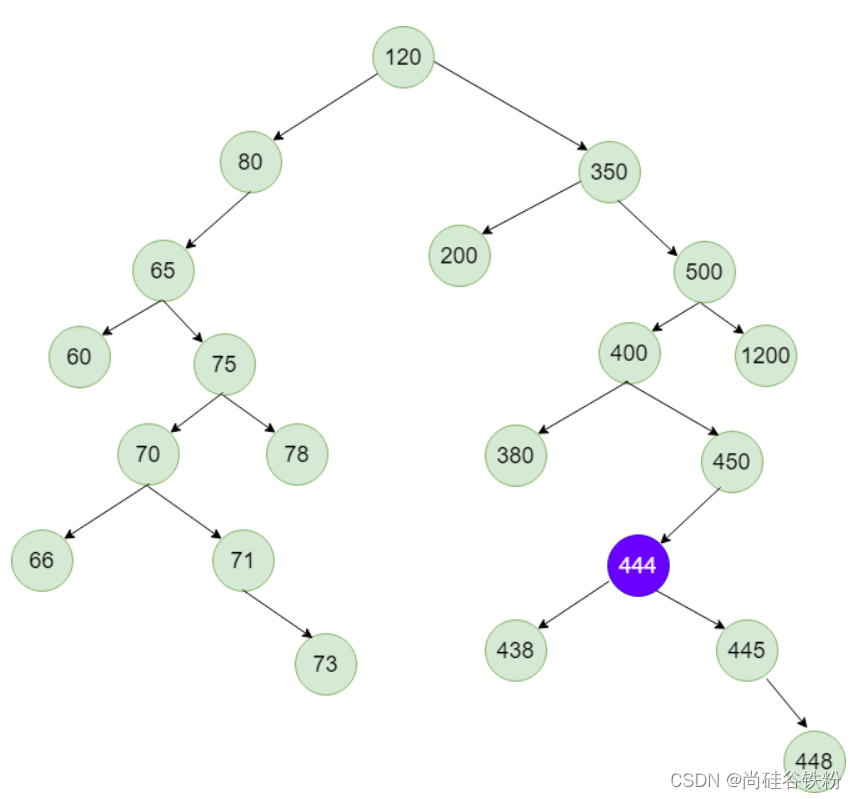
那么针对二叉树的删除功能,我们同一用两个重载方法实现,具体代码如下:
public void remove(K key){
remove(root,key);
}
private Node<K,V> remove(Node<K,V> currentBinarySearchTree,K key){
//如果当前子树不存在,返回空即可
if (currentBinarySearchTree == null){
return null;
}
int result = key.compareTo(currentBinarySearchTree.getKey());
if (result < 0){
//如果待删除key比当前结点小,则递归查找左子树
currentBinarySearchTree.left = remove(currentBinarySearchTree.left,key);
}else if(result > 0){
//如果待删除key比当前结点大,则递归查找左子树
currentBinarySearchTree.right = remove(currentBinarySearchTree.right,key);
}else {
//如果相等,则表示找到删除结点
//如果待删除结点为叶子结点,将待删除结点的父结点的left或者right指针指向空即可
if (currentBinarySearchTree.left == null && currentBinarySearchTree.right == null){
this.size--;
return null;
}
/**
*如果待删除结点的左子树为空,则直接让父结点的指针域指向待删除节点的右子树即可
* 因为左子树没有,右子树本身就是有序的,就不用再多此一举了
*/
if (currentBinarySearchTree.left == null){
this.size--;
return currentBinarySearchTree.right;
}
/**
*同理:如果待删除结点的右子树为空,则直接让父结点的指针域指向待删除节点的左子树即可
* 因为右子树没有,左子树本身就是有序的,就不用再多此一举了
*/
if (currentBinarySearchTree.right == null){
this.size--;
return currentBinarySearchTree.left;
}
/**
* 能走到这儿,说明左右子树都存在
*/
Node<K,V> resetNode = null;
//找到当前待删除结点的右子树
Node<K,V> cur = currentBinarySearchTree.right;
//找到替换结点的父结点,方便删除替换结点
if (cur.left != null){
while (cur.left.left != null){
cur = cur.left;
}
//需要替换的结点
resetNode = cur.left;
//删除替换结点
cur.left = resetNode.right;
}else {
/**
*如果待删除结点的右子树没有左子树
*那么替换结点就是待删除结点的右子结点
* 我们此时还需要将右子结点的右子树保存下来
*/
cur = currentBinarySearchTree;
resetNode = currentBinarySearchTree.right;
cur.right = resetNode.right;
}
/**
* 替换结点
* 让替换结点的left指针指向删除结点的left子树
* 让替换结点的right指针指向删除节点的right子树
*/
resetNode.left = currentBinarySearchTree.left;
resetNode.right = currentBinarySearchTree.right;
//如果删除的结点为根结,需要重置root
if (currentBinarySearchTree == root){
root = resetNode;
}
this.size--;
return resetNode;
}
return currentBinarySearchTree;
}
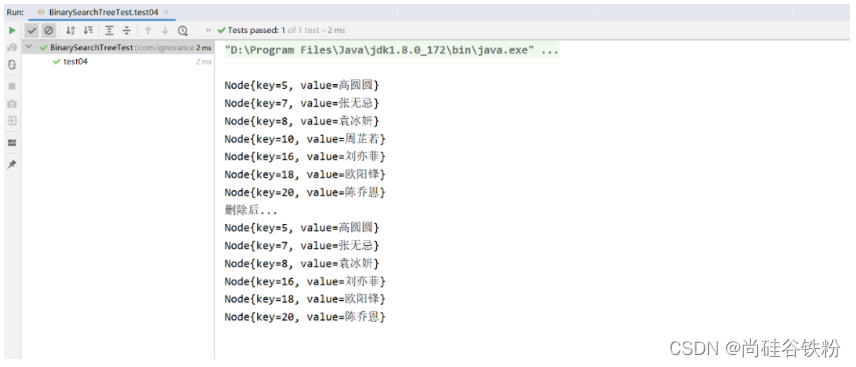
以下是删除功能的测试代码:
@Test
public void test04(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
binarySearchTree.put(18,"欧阳锋");
binarySearchTree.middleShow();
System.out.println("删除后...");
binarySearchTree.remove(10);
binarySearchTree.middleShow();
}
测试结果如下图:
4.6获取二叉树高度
二叉树的高度也是一个比较重要的功能,我们怎么去获得一棵树的高度了,如下图所示:

我们可以这样想:二叉树总是由左子树以及右子树两棵子树组成的,我们只需要计算两个子树高度的最大值,最后针对父结点层数加上1即可;那么针对这个问题我们可以使用递归的思想:
第一步:我们算叶子结点的高度:例如在我们这棵树中,叶子结点有3个,分别为5号、8号、18号结点。
第二步:我们将这三个叶子结点看作根结点,比如对5号这棵子树,它的左子树高度为0,右子树为0,那么5号这个结点的高度为其左右子树高度最大值加1,也就是1。同理8和10号子树的高度都为1;
第三步:我们对7号结点进行统计,7号结点可以看作是由5号和8号两棵子树构成的,那么5号和8号子树的高度为1,两棵子树的最大值为1,那么7号这棵子树的的高度就为1+1=2;而7号刚好是根结点10对应的左子树,那么根结点的左子树高度就为2;
第四步:我们再对20号结点进行统计,20号结点的左子树也就是18这棵子树的高度,我们算出的为1,右子树没有就为0,那么两棵子树的最大值为1,所以20这棵子树的高度就为1+1=2;
第五步:对16号结点进行统计,16号结点的左子树不存在,左子树高度为0,右子树也就是20这棵子树的高度,也就是2。那么16号结点两棵子树高度的最大值为2,所以16号子树的高度为2+1=3;而16号刚好是根结点的右子树,所以根结点10号的右子树高度为3+1=4;
第六步:最后统计根结点,根结点的左子树高度为2,右子树高度为3,所以根结点的高度,也就是咱们整棵树的高度则为3+1=4。
我们同样定义两个方法来实现,第一个方法用来统计整棵树高度,第二个方法用来统计某棵子树的高度,核心代码如下:
public int calcBinaryTreeDeep(){
return calcBinaryTreeDeep(root);
}
private int calcBinaryTreeDeep(Node<K,V> currentTreeNode){
return currentTreeNode == null ? 0 : Integer.max(calcBinaryTreeDeep(currentTreeNode.left),calcBinaryTreeDeep(currentTreeNode.right)) + 1;
}
代码测试:
@Test
public void test05(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
binarySearchTree.put(18,"欧阳锋");
System.out.println(binarySearchTree.calcBinaryTreeDeep());
}
测试结果如下图所示:
4.7获取二叉树最小结点
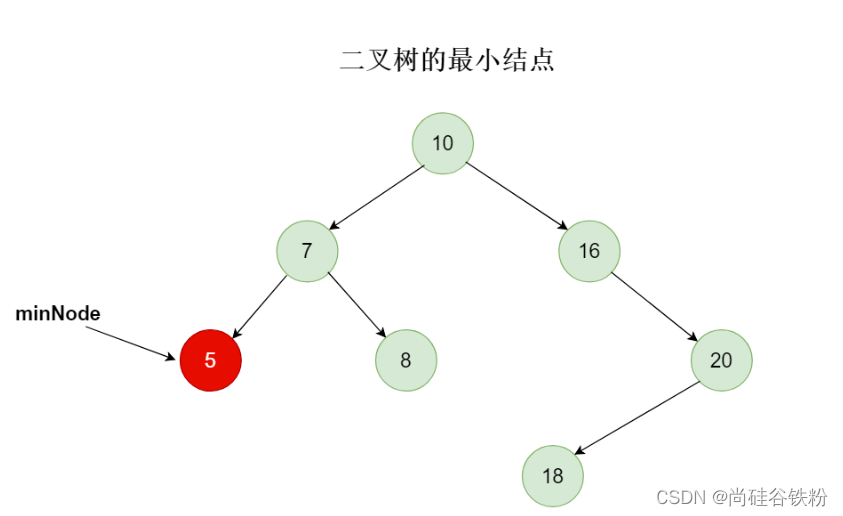
那么此时实现就相对比较简单了,我们只需要遍历根结点的左子树就可以了,直到left指针指向null即可,实质上就是单链表的遍历,核心代码如下:
public Node<K, V> getMinNode(){
if (this.root == null){
return null;
}
return getMinNode(this.root);
}
private Node<K,V> getMinNode(Node<K,V> currentNode){
return currentNode.left == null ? currentNode : getMinNode(currentNode.left);
}
接下来咱们来进行测试,测试代码如下:
@Test
public void test06(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
System.out.println(binarySearchTree.getMinNode().getKey() + "-------" + binarySearchTree.getMinNode().getValue());
}
测试结果如下图所示:
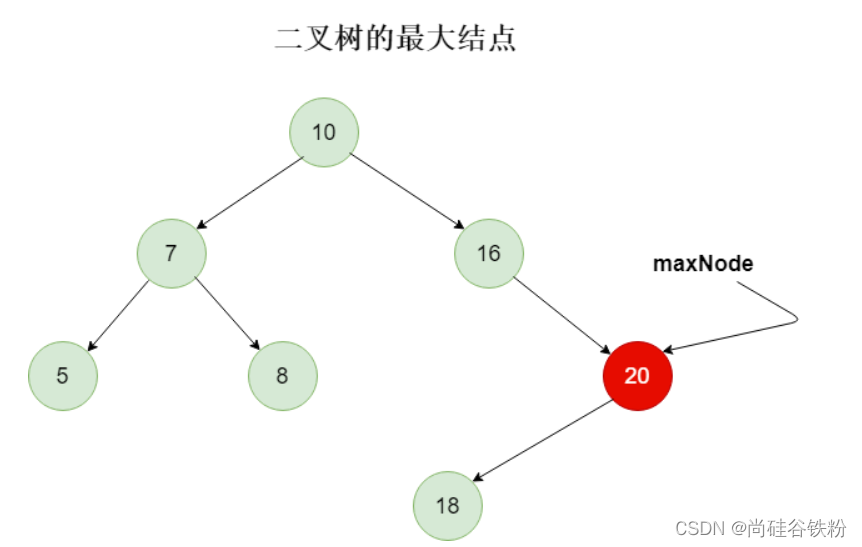
4.8获取二叉树最大结点
求出了最小结点,那么二叉树的最大结点就更简单了,二叉查找树的最大结点就是根结点右子树的最右叶子结点。如下图所示:
实现代码和求最小结点类似,核心代码如下:
public Node<K, V> getMaxNode(){
if (this.root == null){
return null;
}
return getMaxNode(this.root);
}
private Node<K,V> getMaxNode(Node<K,V> currentNode){
return currentNode.right == null ? currentNode : getMaxNode(currentNode.right);
}
以下是测试代码:
@Test
public void test07(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
System.out.println(binarySearchTree.getMaxNode().getKey() + "-------" + binarySearchTree.getMaxNode().getValue());
}
测试结果如下图所示:
4.9二叉树查找
二叉树的查找跟我们最开始的插入的规则一样,对一个结点的查找,先从根结点查找,比较根结点的key和要查找的key的大小,如果查找的key比根结点大,就递归查找它的右子树,如果查找的key比根结点小,则递归查找它的左子树,
如果相等,则直接返回即可。直到查到最后一层的叶子结点为止,比如咱们还是对这棵树,如下图所示:
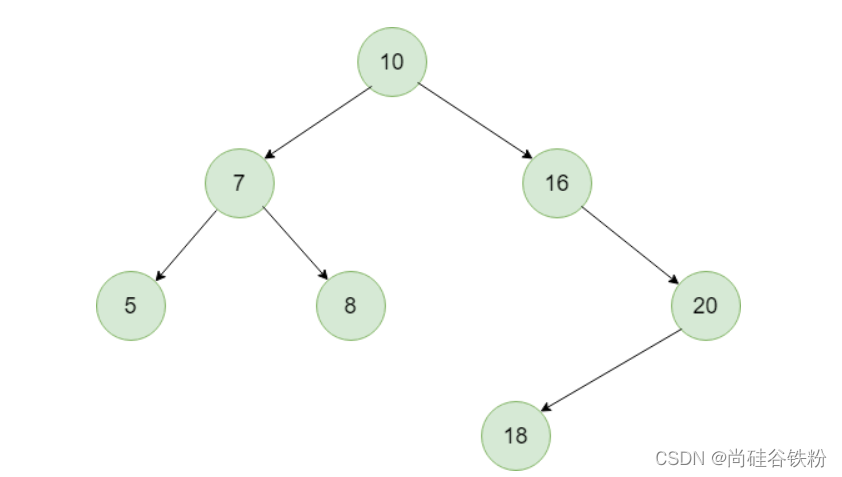
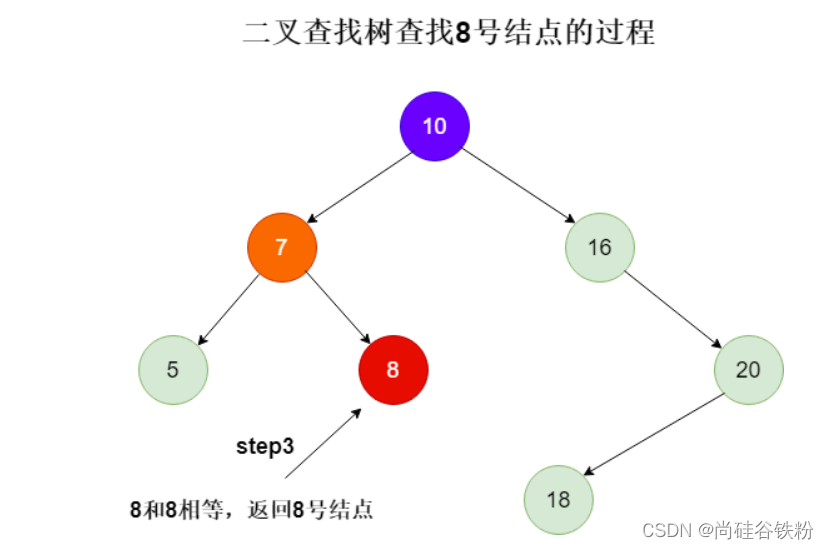
咱们此时要查找8号结点,咱们的步骤如下所示:
第一步:从根结点开始,将查找的key与根结点作比较,8比10要小,所以此时我们再去它的左子树搜素;
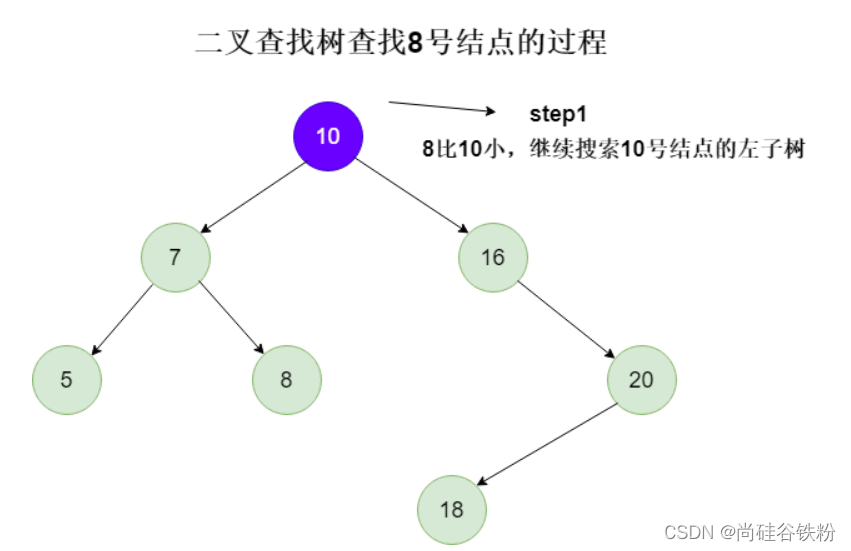
第二步:将7作为根结点,跟8比较,此时8比7要大,下一步咱们继续搜索7号结点的右子树;
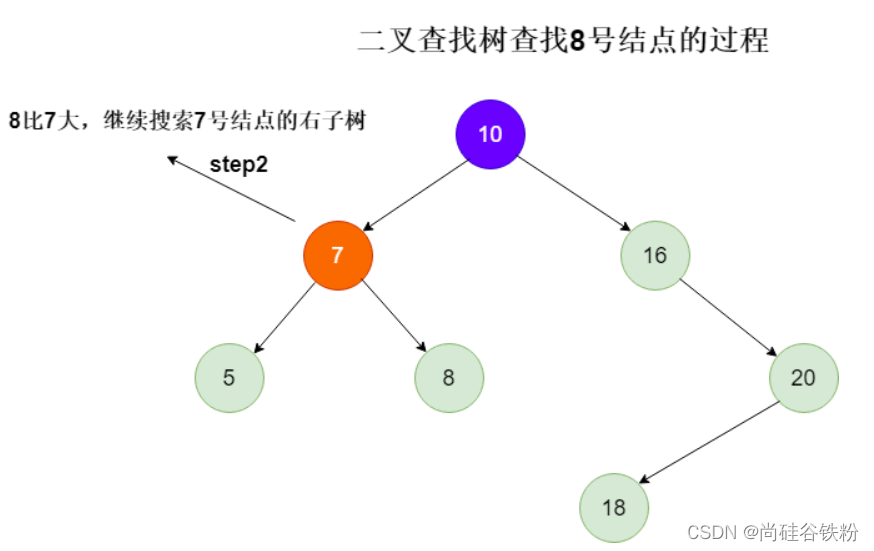
第三步:将8号结点作为根结点,跟8比较,此时两者相等,直接返回根结点即可;
根据以上的分析,实现也比较简单,核心代码如下:
public V search(K key){
return search(this.root,key);
}
private V search(Node<K,V> currentSearchTree,K key){
if (currentSearchTree == null){
return null;
}
System.out.println("【开始搜索】:" + "[查询次数+1]" );
return key.compareTo(currentSearchTree.getKey()) == 0 ? currentSearchTree.getValue() :
(key.compareTo(currentSearchTree.getKey()) > 0 ? search(currentSearchTree.right,key)
: search(currentSearchTree.left,key));
}
测试代码如下:
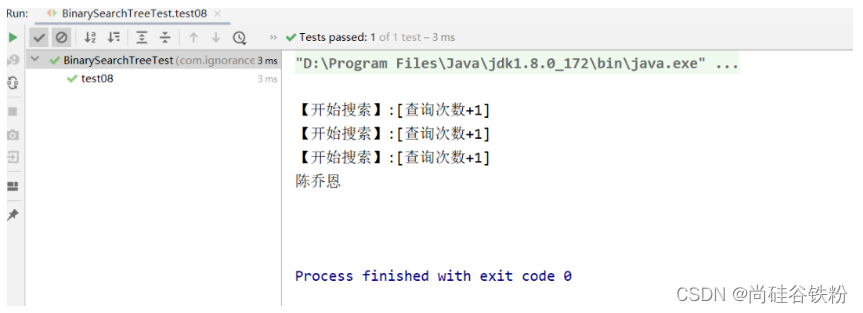
public void test08(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
String searchVal = binarySearchTree.search(20);
System.out.println(searchVal);
}
测试结果如下图:
可以看出,咱们的二叉树查询效率还是挺不错的,查询效率为log2(n),相比链表来说提高了不少。
五综合代码
以下是本篇文章所有的代码,希望在大家学习的过程中给大家一个参考作用:
5.1二叉树结点类
package com.ignorance.tree.node;
/**
* @ClassName Node
* @Description 二叉树结点类
* @Author ignorance
* @Version 1.0
**/
public class Node<K extends Comparable<K>,V> {
private K key;
private V value;
public Node<K,V> left;//左子树指针
public Node<K,V> right;//右子树指针
public Node(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
@Override
public String toString() {
return "Node{" +
"key=" + key +
", value=" + value +
'}';
}
}
5.2二叉查找树核心类
package com.ignorance.tree;
import com.ignorance.tree.node.Node;
/**
* @ClassName BinarySearchTree
* @Description TODO
* @Author ignorance
* @Date 2022/9/30 9:25
* @Version 1.0
**/
public class BinarySearchTree<K extends Comparable<K>,V> {
//根结点
private Node<K,V> root;
//二叉树有效结点个数
private int size;
public void put(K key,V value){
this.root = put(root,key,value);
}
private Node put(Node<K,V> currentTreeNode,K key,V value){
//如果当前子树为空,则创建新的结点
if (currentTreeNode == null){
this.size++;
return new Node(key,value);
}
//比较待插入结点key和当前结点key的大小
int result = key.compareTo(currentTreeNode.getKey());
//如果待插入结点比当前结点小,则继续和左子树进行递归
if (result < 0){
currentTreeNode.left = put(currentTreeNode.left,key,value);
}else if(result > 0){
//如果待插入结点比当前结点小,则继续和右子树进行递归
currentTreeNode.right = put(currentTreeNode.right,key,value);
}else {
//能走到这儿,则说明待插入结点和跟当前结点的key相等,直接替换对应的value值即可
currentTreeNode.setValue(value);
}
return currentTreeNode;
}
public void preShow(){
prevShow(root);
}
public void prevShow(Node<K,V> currentTreeNode){
//当前子树非空校验
if (currentTreeNode == null){
return;
}
//将当前结点作为根结点,第一步遍历
System.out.println(currentTreeNode);
//第二步递归遍历左子树
if (currentTreeNode.left != null){
prevShow(currentTreeNode.left);
}
//第三步递归遍历右子树
if (currentTreeNode.right != null){
prevShow(currentTreeNode.right);
}
}
public void middleShow(){
middleShow(root);
}
private void middleShow(Node<K,V> currentTreeNode){
//非空校验
if (currentTreeNode == null){
return;
}
//中序遍历:第一步,遍历左子树
if (currentTreeNode.left != null){
middleShow(currentTreeNode.left);
}
//中序遍历:第二步,遍历当前根结点
System.out.println(currentTreeNode);
//中序遍历:第三步,遍历当前右子树
if (currentTreeNode.right != null){
middleShow(currentTreeNode.right);
}
}
public void nextShow(){
nextShow(this.root);
}
private void nextShow(Node<K,V> currentTreeNode){
if (currentTreeNode == null){
return;
}
if (currentTreeNode.left != null){
nextShow(currentTreeNode.left);
}
if (currentTreeNode.right != null){
nextShow(currentTreeNode.right);
}
System.out.println(currentTreeNode);
}
public int calcBinaryTreeDeep(){
return calcBinaryTreeDeep(root);
}
private int calcBinaryTreeDeep(Node<K,V> currentTreeNode){
return currentTreeNode == null ? 0 : Integer.max(calcBinaryTreeDeep(currentTreeNode.left),calcBinaryTreeDeep(currentTreeNode.right)) + 1;
}
public void remove(K key){
remove(root,key);
}
private Node<K,V> remove(Node<K,V> currentBinarySearchTree,K key){
//如果当前子树不存在,返回空即可
if (currentBinarySearchTree == null){
return null;
}
int result = key.compareTo(currentBinarySearchTree.getKey());
if (result < 0){
//如果待删除key比当前结点小,则递归查找左子树
currentBinarySearchTree.left = remove(currentBinarySearchTree.left,key);
}else if(result > 0){
//如果待删除key比当前结点大,则递归查找左子树
currentBinarySearchTree.right = remove(currentBinarySearchTree.right,key);
}else {
//如果相等,则表示找到删除结点
//如果待删除结点为叶子结点,将待删除结点的父结点的left或者right指针指向空即可
if (currentBinarySearchTree.left == null && currentBinarySearchTree.right == null){
this.size--;
return null;
}
/**
*如果待删除结点的左子树为空,则直接让父结点的指针域指向待删除节点的右子树即可
* 因为左子树没有,右子树本身就是有序的,就不用再多此一举了
*/
if (currentBinarySearchTree.left == null){
this.size--;
return currentBinarySearchTree.right;
}
/**
*同理:如果待删除结点的右子树为空,则直接让父结点的指针域指向待删除节点的左子树即可
* 因为右子树没有,左子树本身就是有序的,就不用再多此一举了
*/
if (currentBinarySearchTree.right == null){
this.size--;
return currentBinarySearchTree.left;
}
/**
* 能走到这儿,说明左右子树都存在
*/
Node<K,V> resetNode = null;
//找到当前待删除结点的右子树
Node<K,V> cur = currentBinarySearchTree.right;
//找到替换结点的父结点,方便删除替换结点
if (cur.left != null){
while (cur.left.left != null){
cur = cur.left;
}
//需要替换的结点
resetNode = cur.left;
//删除替换结点
cur.left = resetNode.right;
}else {
/**
*如果待删除结点的右子树没有左子树
*那么替换结点就是待删除结点的右子结点
* 我们此时还需要将右子结点的右子树保存下来
*/
cur = currentBinarySearchTree;
resetNode = currentBinarySearchTree.right;
cur.right = resetNode.right;
}
/**
* 替换结点
* 让替换结点的left指针指向删除结点的left子树
* 让替换结点的right指针指向删除节点的right子树
*/
resetNode.left = currentBinarySearchTree.left;
resetNode.right = currentBinarySearchTree.right;
//如果删除的结点为根结,需要重置root
if (currentBinarySearchTree == root){
root = resetNode;
}
this.size--;
return resetNode;
}
return currentBinarySearchTree;
}
public Node<K, V> getMinNode(){
if (this.root == null){
return null;
}
return getMinNode(this.root);
}
private Node<K,V> getMinNode(Node<K,V> currentNode){
return currentNode.left == null ? currentNode : getMinNode(currentNode.left);
}
public Node<K, V> getMaxNode(){
if (this.root == null){
return null;
}
return getMaxNode(this.root);
}
private Node<K,V> getMaxNode(Node<K,V> currentNode){
return currentNode.right == null ? currentNode : getMaxNode(currentNode.right);
}
public V search(K key){
return search(this.root,key);
}
private V search(Node<K,V> currentSearchTree,K key){
if (currentSearchTree == null){
return null;
}
System.out.println("【开始搜索】:" + "[查询次数+1]" );
return key.compareTo(currentSearchTree.getKey()) == 0 ? currentSearchTree.getValue() :
(key.compareTo(currentSearchTree.getKey()) > 0 ? search(currentSearchTree.right,key)
: search(currentSearchTree.left,key));
}
public int getSize() {
return size;
}
}
5.3测试类
package com.ignorance.tree.test;
import com.ignorance.tree.BinarySearchTree;
import org.junit.Test;
/**
* @ClassName BinarySearchTreeTest
* @Description TODO
* @Author ignorance
* @Date 2022/9/30 11:28
* @Version 1.0
**/
public class BinarySearchTreeTest {
// 1005->1003->1004->1007->1006->1009->1008
// 1003->1004->1005->1006->1007->1008->1009
//1004-1003->1006->1008->1009->1007->1005
// 1005
// 1003 1008
// 1004 1006 1009
//
@Test
public void test01(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
binarySearchTree.put(18,"欧阳锋");
System.out.println(binarySearchTree.getSize());
binarySearchTree.preShow();
}
@Test
public void test02(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
binarySearchTree.put(18,"欧阳锋");
binarySearchTree.middleShow();
}
@Test
public void test03(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
binarySearchTree.put(18,"欧阳锋");
binarySearchTree.nextShow();
}
@Test
public void test04(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
binarySearchTree.put(18,"欧阳锋");
binarySearchTree.middleShow();
System.out.println("删除后...");
binarySearchTree.remove(10);
System.out.println(binarySearchTree.getSize());
binarySearchTree.middleShow();
}
@Test
public void test05(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
binarySearchTree.put(18,"欧阳锋");
System.out.println(binarySearchTree.calcBinaryTreeDeep());
}
@Test
public void test06(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
System.out.println(binarySearchTree.getMinNode().getKey() + "-------" + binarySearchTree.getMinNode().getValue());
}
@Test
public void test07(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
System.out.println(binarySearchTree.getMaxNode().getKey() + "-------" + binarySearchTree.getMaxNode().getValue());
}
@Test
public void test08(){
BinarySearchTree<Integer,String> binarySearchTree = new BinarySearchTree<>();
binarySearchTree.put(10,"周芷若");
binarySearchTree.put(7,"张无忌");
binarySearchTree.put(16,"刘亦菲");
binarySearchTree.put(5,"高圆圆");
binarySearchTree.put(8,"袁冰妍");
binarySearchTree.put(20,"陈乔恩");
binarySearchTree.put(18,"黄圣依");
String searchVal = binarySearchTree.search(20);
System.out.println(searchVal);
}
}
总结
以上是本篇文章讲解的所有内容,在本篇文章中,咱们主要讲解了树的一些基本概念,也对树这种结构有了初步的认识。在本篇文章,咱们主要讲解了树的一种,也就是咱们既陌生又熟悉的二叉树,并对它进行了详细的讲解与实现,相信大家在学习Java的时候,或多或少都听说过二叉树这个知识,希望本篇文章会对大家有一定的帮助与收益。
咱们的二叉树,现在看起来查询效率还挺不错,但是最原始的二叉树仍然存在隐藏的问题。比如我们插入8、7、6、5、4、3、2、1,我们会发现,全部结点都位于这棵树的左子树,高度特别大,说白了我们的二叉树达到了极端,变成了链表,此时查询效率可想而知。而且此时比链表效率还要低,因为我们还需要对每个结点,左右子树进行比较。
所以呢,针对以上的问题,后面咱们的树结构就又出来一些新成员,比如Avg平衡树、红黑树以及B树等,接下来的知识咱们放在后面的文章继续讲解。希望大家在学习的过程中都能够收获到自己想要的东西,同样呢,生活始终是不会辜负努力的人的。所以呢,加油吧!成为我们最想成为的那个自己!















 821
821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









