






Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能,其本质是一个Hadoop客户端,用于将HQL(Hive SQL)转化成MapReduce程序。本文我们来介绍一下HIVE的架构以及HQL是如何转换为MR进程的。
一、HIVE架构
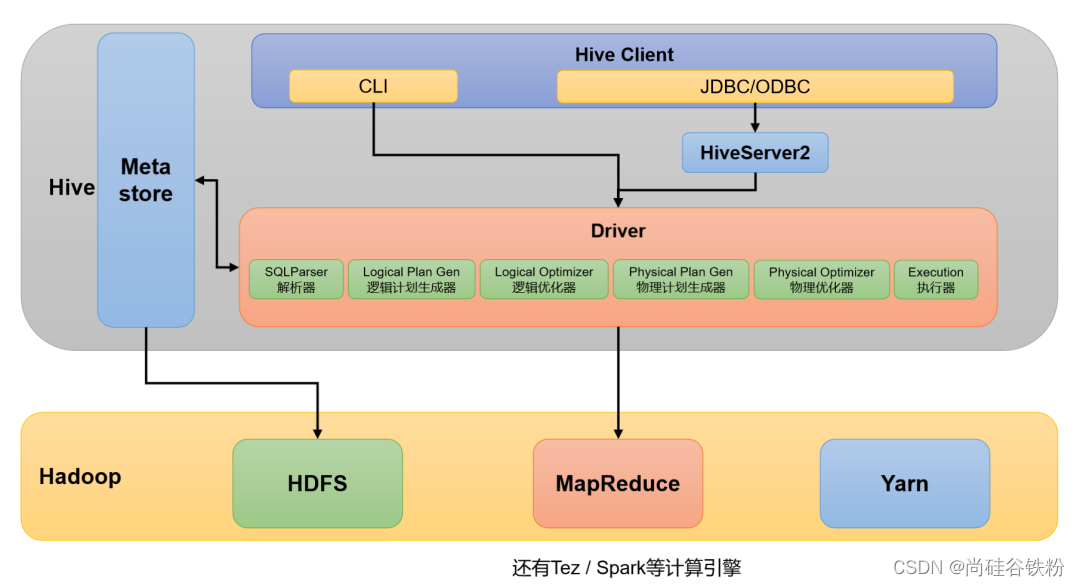
1. 用户接口:Client
CLI(command-line interface)、JDBC/ODBC。
说明:JDBC和ODBC的区别。
- JDBC的移植性比ODBC好;(通常情况下,安装完ODBC驱动程序之后,还需要经过确定的配置才能够应用。而不相同的配置在不相同数据库服务器之间不能够通用。所以,安装一次就需要再配置一次。JDBC只需要选取适当的JDBC数据库驱动程序,就不需要额外的配置。在安装过程中,JDBC数据库驱动程序会自己完成有关的配置。)
- 两者使用的语言不同,JDBC在Java编程时使用,ODBC一般在C/C++编程时使用。
2. 元数据:Metastore
元数据包括:数据库(默认是default)、表名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。
默认存储在自带的derby数据库中,由于derby数据库只支持单客户端访问,生产环境中为了多人开发,推荐使用MySQL存储Metastore。
3. 驱动器:Driver
- 解析器(SQLParser):将SQL字符串转换成抽象语法树(AST)
- 逻辑计划生成器(Logical Plan Gen):将语法树生成逻辑计划
- 逻辑优化器(Logical Optimizer):对逻辑计划进行优化
- 物理计划生成器(Physical Plan Gen):根据优化后的逻辑计划生成物理计划
- 物理优化器(Physical Optimizer):对物理计划进行优化
- 执行器(Execution):执行该计划,得到查询结果并返回给客户端
4. Hadoop
使用HDFS进行存储,可以选择MapReduce/Tez/Spark进行计算。
二、HQL转MR

1. HQL的执行方式
- $HIVE_HOME/bin/hive 进入客户端,然后执行 HQL。
- $HIVE_HOME/bin/hive -e "hql"。
- $HIVE_HOME/bin/hive -f hive.sql。
- 先开启 hivesever2 服务端,然后通过 JDBC 方式连接远程提交 HQL。
2. CliDriver
执行HQL主要依赖于$HIVE_HOME/bin/hive和$HIVE_HOME/bin/hivesever2两种脚本来实现提交 HQL,而在这两个脚本中,最终启动的JAVA程序的主类为“org.apache.hadoop.hive.cli.CliDriver”,所以其实 Hive 程序的入口就是“CliDriver”这个类。故当服务端接收到客户端的服务请求会启动一个CliDriver类,该类主要完成以下功能:
- 解析客户端的-e,-f等参数。
- 定义标准的输入输出流。
- 按照切分HQL语句。可以执行以分号隔开的多个SQL语句,按顺序执行。
3. 创建Driver类
a) 入程序,利用Antlr框架定义HQL的语法规则,对HQL完成词法语法解析,将HQL转换为为AST(抽象语法树)。
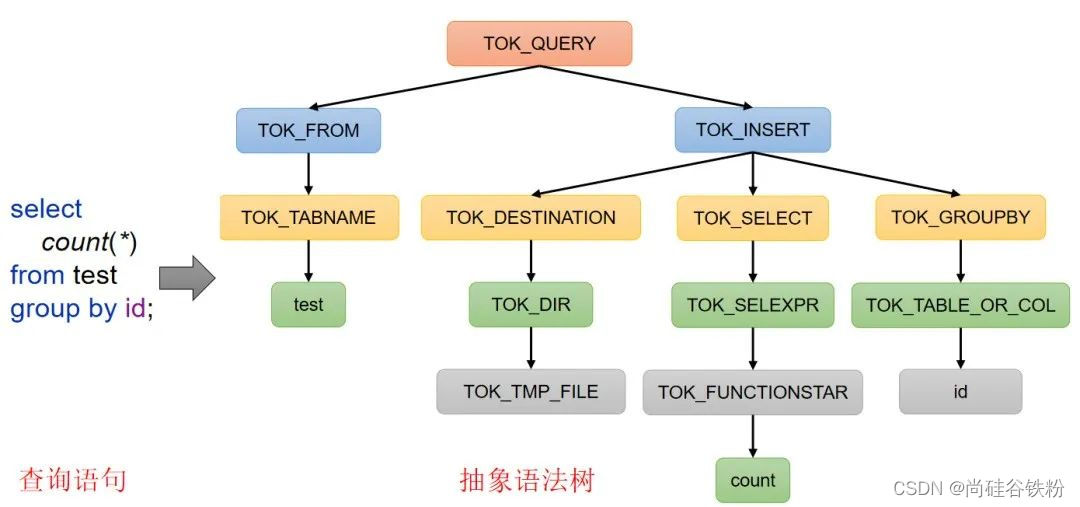
b) 遍历AST,抽象出查询的基本组成单元QueryBlock(查询块),可以理解为最小的查询执行单元。
c) 遍历QueryBlock,将其转换为OperatorTree(操作树,也就是逻辑执行计划),可以理解为不可拆分的一个逻辑执行单元。

d) 使用逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少Shuffle数据量。
e) 遍历OperatorTree,转换为TaskTree。也就是翻译为MR任务的流程,将逻辑执行计划转换为物理执行计划。

f) 使用物理优化器对TaskTree进行物理优化。
g) 生成最终的执行计划,提交任务到Hadoop集群运行,计划如下:
- 获取MR临时工作目录
- 定义分区器【Partitioner】
- 定义Mapper和Reducer
- 实例化job
- 提交job上
三、总结
本文讲解了HIVE的架构,包含用户接口、元数据、驱动器、Hadoop,HQl转换为MR进程的主体为Driver驱动器,将HQL转换为AST,进而生成执行计划,生成任务提交到Hadoop进行最终执行。如果想要看更细节的执行计划的猿友们可以使用explain+sql语句进行查看。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









