






在前面的文章中,我们主要介绍了树这种特殊的非线性数据结构,针对树这种结构,我们又展开讲解了二叉排序树、平衡树、二三查找树,以及二三查找树的落地实现,也就是咱们耳熟能详的红黑树。相信大家也会对其产生一定的理解和体会,对一些API的底层有了一个更好更深入的认识。
今天呢,在本篇文章中,咱们结束树这种数据结构,讲解最后几个知识点,也就是大家学习Java过程中肯定听说过的B树以及B+树,我相信大家肯定听过这两种树,大部分是在MySQL高级篇讲解索引的底层原理的时候,大家肯定知道索引的底层是B+树,在咱们B+树key保存着每条数据的唯一索引,而data域则保存着当前数据在咱们硬盘中的内存地址。而对于为什么会使用B+树实现索引以及B+树长成什么样子,以及B+树和咱们前面讲解过的二叉树、平衡树以及红黑树有什么差异可能就知道的比较少了。今天呢,咱们好好讲解一下B树以及B+树,最后咱们手写一下B+树,让大家更好的掌握这棵特别重要且效率非常之高的树,让咱们的技术更上一层楼,离优秀的自己更近一步。
一、什么是B树?
B树的全称叫做BalanceTree,翻译成中文也就是平衡树。在前面我们讲过平衡树是一种理论上的概念,它的思想主要是将一棵效率较低的树结构通过一系列算法转化为一个趋近于完全二叉树甚至满二叉树的过程,而咱们今天讲得B树也是树的平衡化的一种过程。在上篇文章中,咱们讲解了红黑树,咱们知道红黑树的原理其实就是二三查找树,因为红黑树实质就是一棵二叉树,在一棵二叉树中,只能存在2-结点,无法表示3-结点,所以咱们借助一种非常特殊并且巧妙的过程,也就是给每个结点添加颜色来完成3-结点的表示,进而构建出咱们最终的二三查找树。
今天咱们的B树同样是继承了二三查找树的思想,B树也是基于二三查找树的思想演变而来,我们可以说二三查找树或者红黑树是最基本的B树,是一种比较特殊的B树。
那么什么是B树呢?B树实质是一棵(N-1)-N查找树,N叫做B树的阶,B树延续了二三查找树的本质,将其结点的key进行拓展,我们知道一个结点能够存储更多的key,那么这棵树的高度也就越低,进而查找效率就会高。像咱们B树就不会像红黑树以及二三查找树那么单一,因为一棵B树的阶数一般都会大于100甚至更大,主要用于海量数据的查找,而咱们的红黑树、二三查找树其实本质也就是一棵最简单的B树,只是此时的N=3。下面呢,咱们看一下B树的结构。

在上图中,描述的是一棵5阶B树,即一个结点有4个key,每个key最多可以衍生出5个子链接,那么最简单的5阶B树的结点模型如下所示。

我相信大家看过我前面写得二三查找树,这些东西都能很好理解。下面呢,咱们主要通过一个例子来构建一棵B树,来帮助咱们更好的理解这种平衡思想。
咱们本次添加的键分别为10,20,30,40,1,3,5,7,11,13,15,17,21,23,25,27,31,33,35,37,41,43,45,47。因为咱们画图的篇幅有限,所以还是构建一棵5阶B树。咱们下面主要完成一下这棵5阶B树的添加过程。
第一步:添加第一个键10:
因为10作为第一个键,咱们直接将其作为根结点的一个键,将其添加到根结点中即可,为了画图更易懂,咱们省略data域。最终添加的结果如下图所示:

第二步:添加第二个键20:
20作为第二个键,此时B树的阶为5,那么一个结点最多可容纳4个有效key,此时咱们同样将20这个键添加到root结点中,因为20比10大,则将20这个key放到10号key的右边。如下图所示:
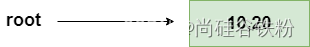
第三步:同理完成30,40号键的添加:
30和40号key的添加过程和20号key一样,如下图所示:
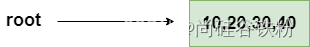
第四步:添加第五个键1:
当我们添加第五个key的时候,直接添加到root结点中,在每个结点中,每个key是有序的,所以1号key添加的位置在最前面。如下图所示:

此时我们的root结点已经存了5个key了,咱们五阶B树一个结点最多只能存4个key,这个时候和2-3查找树一般,将其转化为一个临时的5-结点,但是对于一棵5阶B树,也可以看作4-5查找树,只能是有小于等于4的key结点构成,不能出现5-结点。此时咱们根据2-3查找树的思想,将其进行分解,如下图所示:
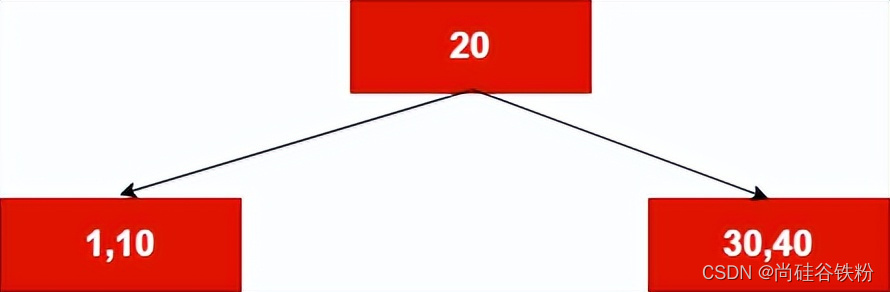
此时将根结点分解为3个结点,根结点此时作为一个2-结点,其他两个结点作为两个3-结点,并成为20号结点的两个子结点。这个不用多说,大家看过咱们的2-3查找树的思想应该很好理解。
第六步:添加第六个键3:
添加6号key时,我们需要根据原始二叉查找树的思想,递归查找3号key的添加位置,此时跟根结点进行比较,发现1号key比根结点小,然后递归找到插入的位置是1,10组成的结点,此时3介于1和10之间,此时呢,将其插入到1和10之间的位置。如下图所示:

第七步:同理,添加第七个键5:

第八步:添加第八个键7:
此时7号键添加的位置为根结点左子结点,添加的位置在5-10之间,此时我们将该结点转换为一个临时的5-结点。如下图所示:

将该结点进行分解,5号键上移,最终形成的内存图如下所示:

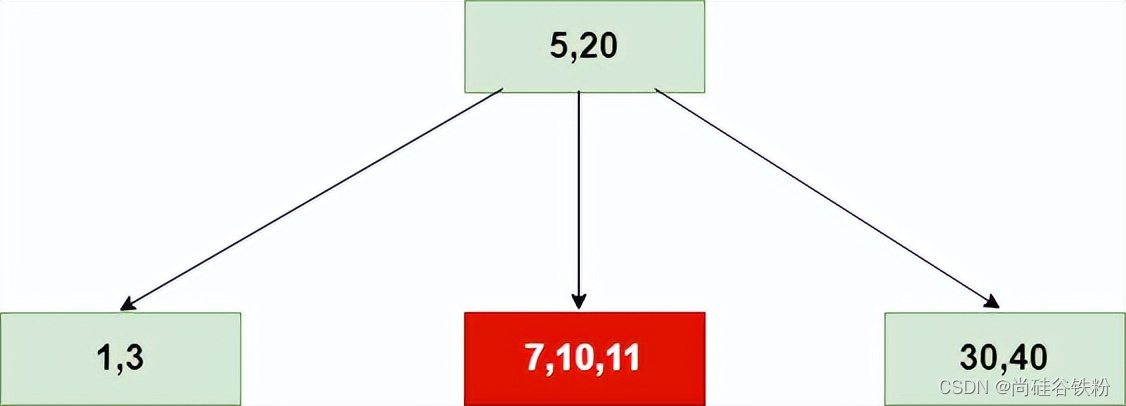
第九步:添加第九个键11:
添加步骤和上面一样,咱们通过递归找到11号key添加的位置为7,10号key所在的结点,直接插入即可。如下图所示:
第十步:添加第十个键13:
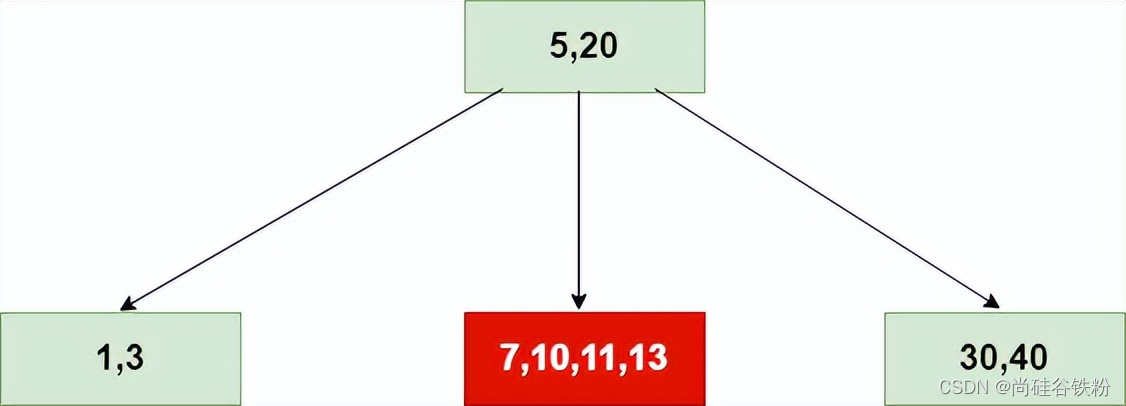
第十一步:添加第十一个键15:
此时15号键添加的位置为7,10,11,13这四个key组成的结点,此时将其转化为一个临时的5-结点。如下图所示:

此时临时的5-结点进行分解,11号key提取为7,10号key对应的结点以及13,15号key对应结点的父结点。如下图所示:

第十二步:添加键17、21以及23:

第十三步:添加第十三个键25:
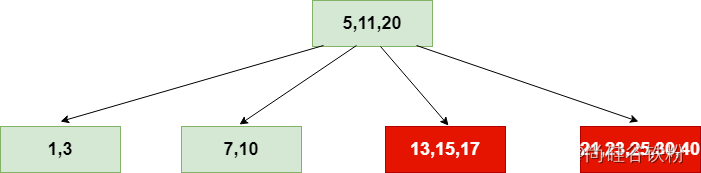
该结点大于最大当前key最大容纳量,进行分解:
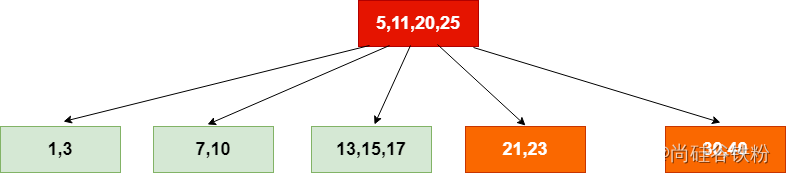
第十四步:添加27号以及31号key:

第十五步:添加33号key:

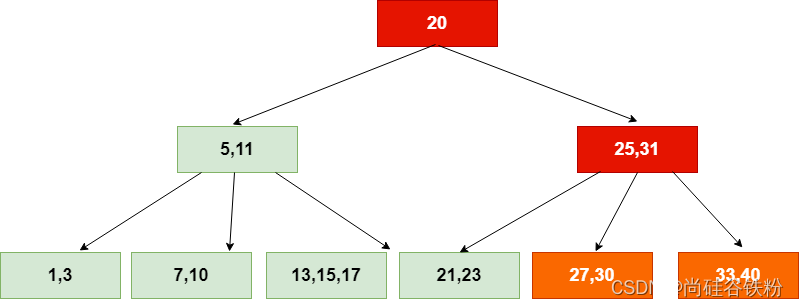
此时构成临时5-结点,同理,对临时的5-结点进行分解,将31号key提取为原来结点的父结点。

第十六步:此时咱们的根结点也变成了5-结点,此时将根结点进行分解,这时候根结点发生改变,咱们B+树的高度增加一层。如下图所示:
第十七步:以下的步骤咱们就不演示了,跟前面的添加步骤一样。将所有的key添加完全后,咱们最后构造的B树如下图示:
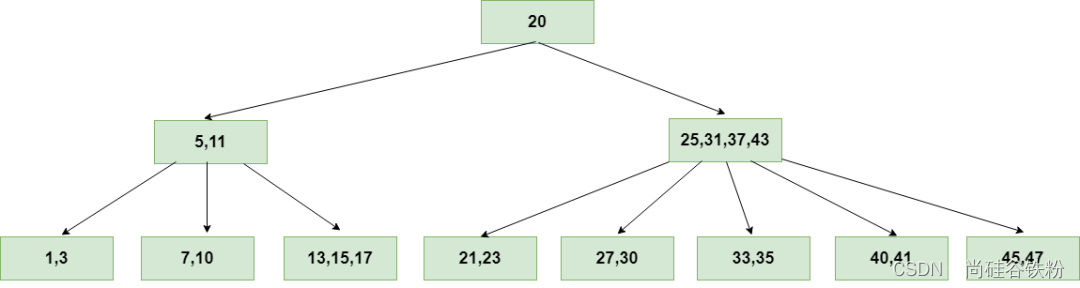
可以看出:咱们的B树构造就是2-3查找树的构造过程。只是相比2-3查找树咱们每个结点的key变多了,key多就代表咱们每个结点存储的数据就会更多,咱们树的高度也就越低,查询效率自然也就得到了提升。
二、什么是B+树?
B+树是在特定的场景下对B树做了优化,像咱们B树是key和data都存储在一块,这样无疑增加了内存消耗。而B+树数据是存储在当前树的叶子结点上,非叶子结点存储的只是相应的key。
一般key只是代表着数据域的索引,消耗内存比较小,就像你电脑上英雄联盟一样,一般都有好几十个G,但是咱们桌面的访问图标也就是快捷方式,咱们可以将其理解为当前英雄联盟游戏可执行文件的一个快速导航索引,一般也就1-2KB大小左右。又或者像咱们Java的JVM内存区域,大家都知道在JVM内存中,堆内存是主要内存,占用了JVM大部分,栈内存占据了很小一部分。
但是我们操作咱们的局部变量一般都是存储在栈中,比如GrilFriend girl = new grilFriend("Lucy","女",178,"36D");大家都知道这个女朋友对象是在堆内存分配的,而咱们的引用变量gril保存的并不是这个对象本身,而是咱们堆内存女朋友(grilFriend)这个对象的内存地址,咱们访问栈内存中可以从堆内存中快速加载定位到对应的对象。
那么为什么栈内存不能保存对象本身了,第一是因为栈内存太小,举个不恰当的例子,比如一个对象占用内存大小为1GB,栈内存的空间一共为512MB。是不是肯定保存不了进而导致内存溢出。这个时候,我们可以将堆内存的对象看作data域,栈内存的引用可以看作一个能够快速定位当前对象的索引值。
其次呢,咱们知道在(N-1)-N查找树中,每个结点的key都是有序的,所以呢,我们在每个结点可以使用二分查找快速定位到需要查找的key,然后层层递归找到咱们叶子结点中的数据。在咱们的叶子结点中,每个数据域结点又构成一个有序的单向链表。
因为在上面B树的构建思路中,咱们为了图解更易懂,省略了数据域,咱们这时候画一下B树和B+树加上data域的存储模型。
B树的内存模型如下图所示:

B+树的内存模型如下图所示:
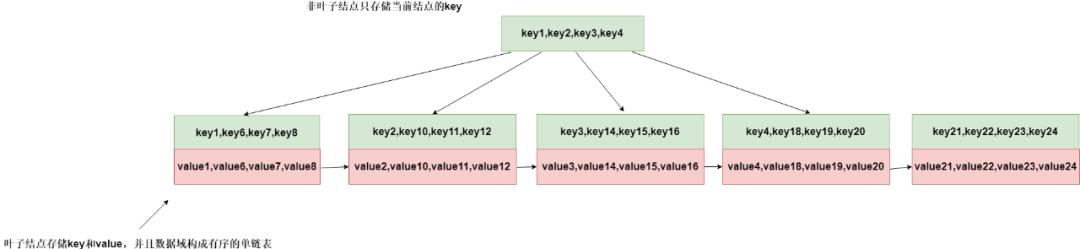
B+树的运用场景:
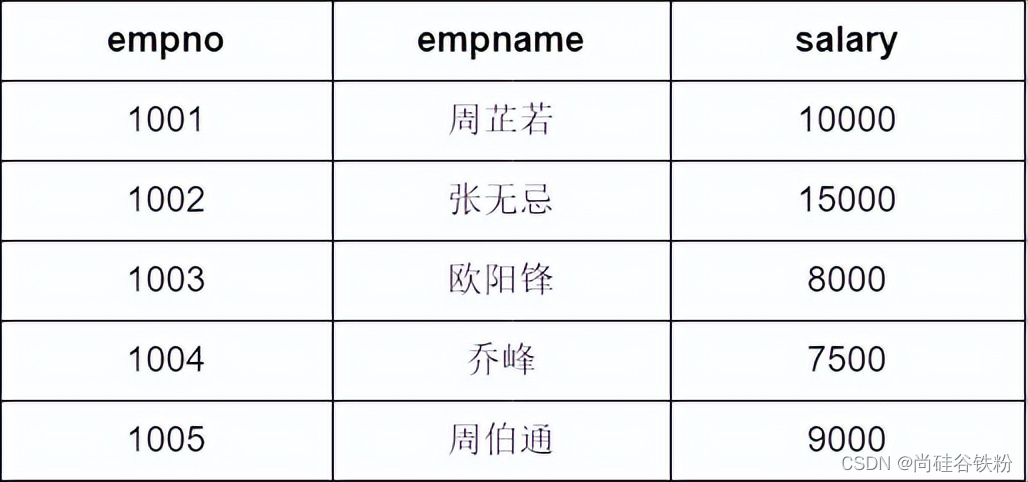
前面咱们说了,咱们MySQL的索引底层就是使用的B+树完成的。比如在下面的表,t_emp表示员工信息表,empno表示员工编号、empname表示员工姓名、salary表示员工工资,其中empno为主键id,大家也都知道一般主键id也会是唯一索引。
大家应该知道,咱们数据库的数据实质也是存储在咱们服务器硬盘上的,要想读取文件肯定是绕不过IO的,IO会消耗很大的性能是毋容置疑的,所以在数据库查询时,会通过索引快速定位到目标数据在咱们硬盘的地址。
比如这个时候,我们要查1005对应的数据,如果不使用索引,需要从第一条数据开始进行暴力匹配,直到找到对应的数据位置。试想如果一张表中存在上千万条数据了,那最坏的情况是不是要查询上千万次。试想,你在京东购买商品时,加载一个商品需要一两个小时,此时你是什么感觉。所以为了提高数据库的查询效率,我们就有了索引的概念,进而来优化咱们SQL的查询效率。
索引底层是通过B+树实现的,那么在底层是怎么实现的呢?
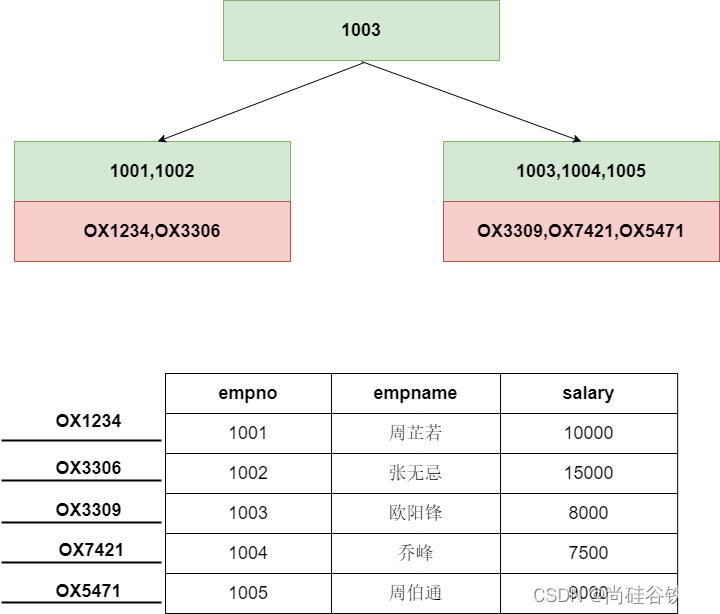
在这棵B+树中,咱们的索引字段存储在非叶子结点,对应的目标数据的内存地址存储在叶子结点。如下图所示:
三、B+树的代码实现
下面呢,我们结合前面讲得知识,为了帮助咱们更好的掌握和理解,咱们接下来完成B+树的实现。
B+树的结点比较特殊,因为针对叶子节点以及非叶子节点存储的数据不同,叶子节点主要存储键和值,非叶子节点只会存储键,所以在构建B+树的时候,针对结点咱们分开设计。
创建BalancePlusTreeNode作为叶子结点以及非叶子结点的公共父类:
package com.ignorance.bplus.node;
import com.ignorance.bplus.BalancePlusTree;
import java.util.List;
public abstract class BalancePlusTreeNode<K extends Comparable<K>,E> {
//当前结点的key集合
protected List<K> entries;
//当前结点最大容纳的键个数
public static Integer UPPER_bOUND;
//当前结点至少应该包括的键个数
public static Integer LOWER_BOUND;
public BalancePlusTreeNode() {
}
public BalancePlusTreeNode(List<K> entries) {
this.entries = entries;
}
public List<K> getEntries() {
return entries;
}
public void setEntries(List<K> entries) {
this.entries = entries;
}
}
在结点类中,因为不管是叶子结点还是非叶子结点,都会存储entry也就是key值,所以咱们把entry当做公共属性定义在父类中,让叶子与非叶子结点这两个子类进行继承。同理每个结点都有至少容纳entry的个数以及最多容纳entry的个数,比如对于一个5阶B+树,每个结点最少应该存在2个key,最多应该存在4个key。
接下来我们定义叶子结点BalancePlusTreeLeafNode类:
package com.ignorance.bplus.node;
import com.ignorance.bplus.utils.BalancePlusUtils;
import java.util.List;
import java.util.Set;
public class BalancePlusTreeLeafNode<K extends Comparable<K>,E> extends BalancePlusTreeNode<K,E> {
//当前叶子结点的数据域
private List<Set<E>> data;
//当前叶子结点数据域的next域
private BalancePlusTreeNode next;
public BalancePlusTreeLeafNode(List<K> entries, List<Set<E>> data) {
super(entries);
this.data = data;
}
}
在叶子结点BalancePlusTreeLeafNode中,咱们定义data属性来表示当前叶子结点的数据域,因为它继承了结点类,所以叶子结点存在两个属性,一个entries以及data,分别来表示叶子结点所存储的键集以及数据集。使用next属性来表示构建单向链表,表示当前叶子结点的下一个结点。
创建非叶子结点BalancePlusTreeNonLeafNode类:
package com.ignorance.bplus.node;
import java.util.List;
public class BalancePlusNonTreeLeafNode<K extends Comparable<K>,E> extends BalancePlusTreeNode<K,E> {
//当前非叶子结点的子结点集合
private List<BalancePlusTreeNode<K,E>> child;
public BalancePlusNonTreeLeafNode(List<K> entries, List<BalancePlusTreeNode<K, E>> child) {
super(entries);
this.child = child;
}
}
在非结点类BalancePlusTreeNonLeafNode中,我们创建child属性来表示当前结点的子结点,因为一个非叶子结点存在不确定数量的子结点,所以我们将child设置为List类型的。
创建BalancePlusTree作为B+树的核心操作类:
package com.ignorance.bplus;
import com.ignorance.bplus.node.BalancePlusTreeLeafNode;
import com.ignorance.bplus.node.BalancePlusNonTreeLeafNode;
import com.ignorance.bplus.node.BalancePlusTreeNode;
import com.ignorance.bplus.utils.BalancePlusUtils;
import java.util.List;
import java.util.Set;
public class BalancePlusTree<K extends Comparable<K>,E> {
//B+树的默认阶数
private static final Integer DEFAULT_BOUND = 4;
//上限
private final Integer UPPER_BOUND;
//下限
private final Integer LOWER_BOUND;
//B+树的根结点
private BalancePlusTreeNode<K,E> root;
public BalancePlusTree(int bound) {
this.UPPER_BOUND = bound - 1;
this.LOWER_BOUND = this.UPPER_BOUND >> 1;
BalancePlusTreeNode.UPPER_bOUND = this.UPPER_BOUND;
BalancePlusTreeNode.LOWER_BOUND = this.LOWER_BOUND;
}
public BalancePlusTree() {
this(DEFAULT_BOUND);
}
}
在B+树核心操作类BalancePlusTree中,我们定义DEFAULT_BOUND来表示我们B+树的默认阶数、UPPER_BOUND表示一个结点最大的key数量、LOWER_BOUND表示一个结点最少的key数量,root表示当前B+树的根结点。并且定义两个构造方法,第一个构造方法用于让调用者传入当前B+树的阶数,主要初始化B+树结点key数量的上下限。无参构造器主要是外部没有指定阶数的时候,使用咱们B+树阶数的默认值。
3.1B+树添加功能
3.1.1:在BalancePlusTree类中添加put方法:
public void put(K entry,E value){
//1-1:如果待添加结点是第一个结点,将其直接作为根结点添加
//1-2:而此时我们创建的结点肯定是叶子结点
if (root == null){
List<K> entries = BalancePlusUtils.transToList(entry);
List<Set<E>> data = BalancePlusUtils.transToList(BalancePlusUtils.transToSet(value));
root = new BalancePlusTreeLeafNode<K,E>(entries,data);
return;
}
}
在put方法中,我们第一步判断当前root是否为空,如果为空,则说明当前添加的为第一个结点,这个时候我们初始化的第一个结点肯定为叶子结点,将其作为当前B+树的root结点即可。
该过程我们会调用BalancePlusUtils.transToList(T...element)以及transToSet(T...ele)两个方法来构建咱们的B+树结点,主要是将当前entry以及value转化为List以及Set集合,因为我们一个结点跟key和value的对应关系总是一对多。
下面我们完成一下这两个工具方法:
package com.ignorance.bplus.utils;
import java.util.*;
public class BalancePlusUtils {
public static <T> List<T> transToList(T...data){
List<T> list = new ArrayList<>();
Collections.addAll(list,data);
return list;
}
public static <E> Set<E> transToSet(E...ele){
Set<E> set = new HashSet<>();
Collections.addAll(set,ele);
return set;
}
}
3.1.2:在BalancePlusTreeNode中添加put方法,将其声明为抽象方法让咱们的叶子结点以及非叶子结点去实现。
public abstract BalancePlusTreeNode<K,E> put(K entry, E value);
3.1.3:叶子结点实现put方法,完成叶子结点的创建。
@Override
public BalancePlusTreeNode<K, E> put(K entry, E value) {
//查询叶子结点是否存在同样的entry,如果存在就将value添加一次
int currentReplaceIndex = super.gainReplaceIndex(entry);
if (currentReplaceIndex != -1){
data.get(currentReplaceIndex).add(value);
return null;
}
//能走到这儿,就说明叶子结点不存在对应的key,此时我们应该计算出当前entry在结点中的插入位置
int currentInsertIndex = super.gainInsertIndex(entry);
entries.add(currentInsertIndex,entry);
data.add(currentInsertIndex, BalancePlusUtils.transToSet(value));
return isOverFlow() ? split() : null;
}
在B+树的entry集合中,因为每个键都是有序的,所以我们可以使用二分查找来判断一下当前添加的键是否能够查找到,如果能够定位到,我们将当前key对应的data集合中的对应位置的set集合中再插入一个value集合。所以考虑到叶子结点和非叶子结点key都是有序的,所以我们将二分查找算法定义在它们两个类的父类即可:
protected int gainReplaceIndex(K entry){
int left = 0;
int right = entries.size() - 1;
while (left <= right){
int middle = left + ((right - left) >> 1);
if (entry.compareTo(entries.get(middle)) > 0){
left = middle + 1;
}else if (entry.compareTo(entries.get(middle)) < 0){
right = middle - 1;
}else {
return middle;
}
}
return -1;
}
二分查找算法相信大家已经很熟悉了,主要是针对一个有序集合,使用折半查找的方式进行定位目标元素,将目标值与中间值进行比较,如果是一个从小到大的序列,如果目标值比中间值大,则递归查找中间索引值后面的子序列。如果目标值比中间值小,则向前递归中间索引值前面的子序列。如果目标值等于中间值,则返回中间值的索引值即可。
如果当前叶子结点不存在对应的key,此时咱们应该计算出当前叶子结点key的存储位置,因为key有序,我们还是可以通过二分查找的方式计算出当前key在当前结点的存储位置。比如当前结点有1001,1007,1010,1020四个entry,这个时候咱们插入的1009刚好落到这个结点,这个时候咱们1009应该存储在1007和1010位置的中间,也就是1001,1007,1009,1010,1020。所以呢,同理考虑到叶子结点和非叶子结点都需要计算,我们将这个方法定义在父类BalancePlusTreeNode中,用于叶子结点以及非叶子结点继承。如下所示:
protected int gainInsertIndex(K entry){
int left = 0;
int right = entries.size();
while (left < right){
int middle = left + ((right - left) >> 1);
if (entry.compareTo(entries.get(middle)) > 0){
left = middle + 1;
}else if (entry.compareTo(entries.get(middle)) <= 0){
right = middle;
}
}
return left;
}
在叶子结点中,找到entry对应位置后,咱们将当前entry以及value分别添加到对应位置即可,最后还需要判断当前叶子结点是否需要分裂。
那么什么时候需要分裂呢?咱们前面说到过,一棵N阶B+树,一个结点最多存储的entry数量最多只能为N-1个,所以我们需要判断一下当前结点entry的数量是否超过了咱们当前结点的上限,因为叶子以及非叶子结点都需要判断,同样的道理,咱们将其定义在父类中。如下所示:
protected boolean isOverFlow(){
return entries.size() > UPPER_bOUND;
}
在咱们叶子结点类,调用代码为:
return isOverFlow() ? split() : null;
如果当前entry数量达到了上限,此时咱们添加完entry后。就像咱们前面讲解的一棵5阶B树,最多只能存在4-结点,此时再添加entry后,我们会暂时将其添加到当前结点,让当前结点形成一个临时的5-结点。当满足当前entry的数量超过当前结点容纳上限后,咱们这时候需要分裂当前结点,将原始结点分裂成三个结点。将中间entry提取到父结点,另外两个结点构成中间entry对应结点的两个子结点。
3.1.4:因为叶子和非叶子结点都存在分裂操作,所以我们将其定义在父类中,作为抽象方法让叶子以及非叶子结点去继承:
protected abstract BalancePlusTreeNode<K,E> split();
3.1.5:叶子结点实现分裂方法:
@Override
protected BalancePlusTreeNode<K, E> split() {
//获取分割位置
int currentSplitIndex = super.gainSplitIndex();
//保留原来叶子结点的entry集合
List<K> currentSplitEntries = this.entries;
//保留原来叶子结点的data集合
List<Set<E>> currentSplitData = this.data;
//将当前结点的entries截取到分割位置
this.entries = BalancePlusUtils.splitBalancePlusTreeNode(this.entries,0,currentSplitIndex);
//将当前结点的data截取到分割位置
this.data = BalancePlusUtils.splitBalancePlusTreeNode(this.data,0,currentSplitIndex);
/*
构建新的结点
1-1 让新结点的entries为原来叶子结点分割位置后的entries
1-2 让新结点的data为原来叶子结点分割位置后的data
*/
List<K> splitAnotherEntries = BalancePlusUtils.splitBalancePlusTreeNode(currentSplitEntries,currentSplitIndex + 1,currentSplitEntries.size() - 1);
List<Set<E>> splitAnotherData = BalancePlusUtils.splitBalancePlusTreeNode(currentSplitData,currentSplitIndex + 1,currentSplitData.size() - 1);
//构建新结点
BalancePlusTreeLeafNode<K,E> balancePlusLeafTreeNode = new BalancePlusTreeLeafNode<>(splitAnotherEntries,splitAnotherData);
//完成叶子结点next指针构建
balancePlusLeafTreeNode.next = this.next;
this.next = balancePlusLeafTreeNode;
//将新结点进行返回
return balancePlusLeafTreeNode;
}
叶子结点的分裂方法比较简单,如果满足分裂条件,我们主要将待分裂叶子结点的entries以及data分别进行分裂,然后将右边的新结点进行返回。比如针对一棵5阶B树,一个叶子结点存在5个键后,也就是5个entry,此时该叶子结点需要进行分裂,比如一个叶子结点1001,1002,1003,1004,1005,咱们先计算出当前结点的分裂位置,也就是让当前UPPER_BOUND >> 1,最后分裂位置为2,也就是把1001,1002这两个entry以及其对应的data分裂成一个结点,并且让原来的根结点指向它。让1003,1004,1005这三个entries以及其对应的data组成另外一个结点,并且让前面的叶子结点的next指向后面的叶子结点。最终提取1003这个entry,让其成为1001,1002以及1003,1004,1005这两个结点的父结点。
3.1.6 非叶子结点类BalancePlusTreeNonLeafNode实现put方法:
如果此时咱们的root结点不是叶子结点或者咱们的B+树的高度不为1,此时咱们需要完成实现非叶子结点的put方法,实现代码如下:
@Override
public BalancePlusTreeNode<K, E> put(K entry, E value) {
BalancePlusTreeNode<K,E> insertChildNode = child.get(super.gainInsertIndex(entry)).put(entry, value);
if (insertChildNode != null) {
K newEntry = findLeafEntry(insertChildNode);
int newEntryIndex = gainInsertIndex(newEntry);
entries.add(newEntryIndex, newEntry);
child.add(newEntryIndex + 1, insertChildNode);
return super.isOverFlow() ? split() : null;
}
return null;
}
第一步:咱们需要去递归当前非叶子结点的子结点,查找到其对应的叶子结点,并完成叶子结点的添加。
第二步:如果返回的插入结点不为null,表示咱们的叶子结点出现的分裂,叶子结点的中间entry会向上提升,咱们的非叶子结点需要存储当前的的结点entry。
第三步:如果子结点是叶子结点并出现了分裂,此时我们当前非叶子结点添加对应的entry,并且将分裂出来的叶子结点添加到对应的child集合中即可。
第四步:咱们的非叶子结点当满足entries的数量大于结点数量上限,也会进行分裂。
查找叶子结点key的代码如下,其实就是一个很简单的递归:
private K findLeafEntry(BalancePlusTreeNode<K,E> curNode) {
if (curNode instanceof BalancePlusTreeLeafNode) {
return curNode.entries.get(0);
}
BalancePlusNonTreeLeafNode<K,E> targetNode = (BalancePlusNonTreeLeafNode)curNode;
return findLeafEntry(child.get(0));
}
3.1.7:非叶子结点的分裂:
@Override
protected BalancePlusTreeNode<K, E> split() {
//1-1:计算非叶子结点的分割位置
int splitIndex = super.gainSplitIndex();
//1-2:存储该非叶子结点的entries
List<K> currentNodeEntries = entries;
//1-3:存储该非叶子结点子结点
List<BalancePlusTreeNode<K,E>> childList = child;
//1-4:重置当前非叶子结点的entries为起始位置到分割点的entries
this.entries = BalancePlusUtils.splitBalancePlusTreeNode(currentNodeEntries,0,splitIndex);
//1-5:重置当前非叶子结点的child为起始位置到分割点+1的child
this.child = BalancePlusUtils.splitBalancePlusTreeNode(childList,0,splitIndex);
//创建新的entries,该集合对应分割点后的entries
List<K> rightEntries = BalancePlusUtils.splitBalancePlusTreeNode(currentNodeEntries,splitIndex + 1,currentNodeEntries.size() - 1);
//创建新的child,该集合对应分割点+1后的child
List<BalancePlusTreeNode<K, E>> rightChildren = BalancePlusUtils.splitBalancePlusTreeNode(childList, splitIndex + 1, childList.size() - 1);
//将新创建的非叶子返回给调用者
return new BalancePlusTreeNonLeafNode<>(rightEntries, rightChildren);
}
非叶子结点的分割也相对比较简单,和叶子结点相差不大,只是叶子结点需要处理entries与data,而咱们的非叶子结点需要处理的是entries以及child。具体分割步骤如下:
第一步:获取分裂点,也就是折中处理,让咱们的UPPER_BOUND >> 1;
第二步:存储当前非叶子结点的entries以及child集合;
第三步:让当前的非叶子结点的entries以及child改变,让其entries截取到分割点,让当前结点的child截取到分裂点的位置;
第四步:创建新的非叶子结点,新结点的entries则存储原非叶子结点分割点之后的entries,它的child则为分割点+1后的child集合;
第五步:最后再将新创建的非叶子结点返回给调用者,也就是咱们BalancePlusTree的put方法即可。
3.1.8:继续完善BalancePlusTree类的put方法:
public void put(K entry,E value){
//1-1:如果待添加结点是第一个结点,将其直接作为根结点添加
//1-2:而此时我们创建的结点肯定是叶子结点
if (root == null){
List<K> entries = BalancePlusUtils.transToList(entry);
List<Set<E>> data = BalancePlusUtils.transToList(BalancePlusUtils.transToSet(value));
root = new BalancePlusTreeLeafNode<K,E>(entries,data);
return;
}
//如果当前root不为空,则调用当前结点的put方法
BalancePlusTreeNode<K, E> insertNode = root.put(entry, value);
K splitRootKey = null;
if (insertNode != null){
/**
* 1-1:如果insertnode 不为空,表示该结点需要分裂
* 1-2:如果返回的结点为叶子结点,则提取该结点的第一个key,并且让当前root和当前返回结点成为第一个key所在结点的子结点
* 1-3:如果返回的结点时非叶子结点,则需要递归查找它的叶子结点的第一个key,并且让当前root和当前返回结点成为第一个key
* 所在结点的子结点
* 1-4:最后重置root结点为分裂结点即可
*/
if (insertNode instanceof BalancePlusTreeLeafNode){
splitRootKey = insertNode.getEntries().get(0);
}else {
splitRootKey = ((BalancePlusTreeNonLeafNode<K,E>) insertNode).findLeafEntry(insertNode);
}
this.root = new BalancePlusTreeNonLeafNode<K,E>(BalancePlusUtils.transToList(splitRootKey),BalancePlusUtils.transToList(root,insertNode));
}
}
非叶子结点递归查找叶子结点的代码如下:
public K findLeafEntry(BalancePlusTreeNode<K, E> curNode) {
if (curNode instanceof BalancePlusTreeLeafNode) {
return curNode.entries.get(0);
}
BalancePlusTreeNonLeafNode<K,E> targetNode = (BalancePlusTreeNonLeafNode)curNode;
return findLeafEntry(child.get(0));
}
下面我们创建一棵B+树进行测试,添加的entry为了跟之前的保持一致,还是10,20,30,40,1,3,5,7,11,13,15,17,21,23,25,27,31,33,35,37,41,43,45,47这一组entry,我们也进一步验证咱们B+树的添加功能是否正确。
3.1.9:测试方法如下:
package com.ignorance.bplus.test;
import com.ignorance.bplus.BalancePlusTree;
import org.junit.Test;
public class BalancePlusTreeTest {
@Test
public void testBalancePlusTreePutMethod(){
System.out.println("【开始测试put方法】");
long startTime = System.currentTimeMillis();
BalancePlusTree<Integer,String> balancePlusTree = new BalancePlusTree<>(5);
balancePlusTree.put(10,"张无忌");
balancePlusTree.put(20,"周芷若");
balancePlusTree.put(30,"赵敏");
balancePlusTree.put(40,"夏诗涵");
balancePlusTree.put(1,"赵云");
balancePlusTree.put(3,"李白");
balancePlusTree.put(5,"韩信");
balancePlusTree.put(7,"瑶瑶");
balancePlusTree.put(11,"澜");
balancePlusTree.put(13,"诸葛亮");
balancePlusTree.put(15,"刘备");
balancePlusTree.put(17,"孙尚香");
balancePlusTree.put(21,"关羽");
balancePlusTree.put(23,"马超");
balancePlusTree.put(25,"貂蝉");
balancePlusTree.put(27,"周芷若");
balancePlusTree.put(31,"欧阳锋");
balancePlusTree.put(33,"花木兰");
balancePlusTree.put(35,"郭靖");
balancePlusTree.put(37,"杨过");
balancePlusTree.put(41,"后羿");
balancePlusTree.put(43,"嫦娥");
balancePlusTree.put(45,"猪八戒");
balancePlusTree.put(47,"小乔");
long endTime = System.currentTimeMillis();
System.out.println("【测试结束】:一共消耗" + (endTime - startTime) + "毫秒");
}
}
咱们看一下测试结果:

再通过Debug的方式看一下这棵B+树长什么样子:
由于截图有限,感兴趣的同学可以自己调试一下。下面我们根据debug的变量存储情况画出这棵5阶B+树,结果如下图所示:
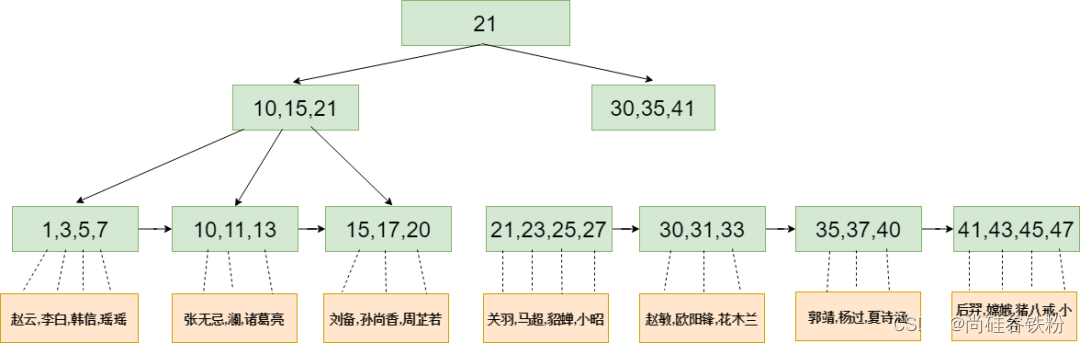
3.2B+树的精确搜索功能
B+树的精确查询比较简单,我们只需从根结点使用递归层层遍历就好
第一步:在BalancePlusTreeNode中定义抽象方法query:
public abstract List<E> query(K entry);
第二步:在BalancePlusTreeNonLeafNode中实现query方法:
@Override
public List<E> query(K entry) {
return child.get(gainInsertIndex(entry)).query(entry);
}
第三步:在BalancePlusTreeLeafNode中实现query方法:
@Override
public List<E> query(K entry) {
int entryIndex = gainReplaceIndex(entry);
return entryIndex == -1 ? Collections.emptyList() : new ArrayList<>(data.get(entryIndex));
}
第四步:在BalancePlusTree中完成精确查找功能:
public List<E> query(K entry) {
if (root == null) {
return Collections.emptyList();
}
return root.query(entry);
}
第五步:测试:
package com.ignorance.bplus.test;
import com.ignorance.bplus.BalancePlusTree;
import org.junit.Before;
import org.junit.Test;
public class BalancePlusTreeTest {
private BalancePlusTree<Integer,String> balancePlusTree;
@Before
public void init(){
balancePlusTree = new BalancePlusTree<>(5);
balancePlusTree.put(10,"张无忌");
balancePlusTree.put(20,"周芷若");
balancePlusTree.put(30,"赵敏");
balancePlusTree.put(40,"夏诗涵");
balancePlusTree.put(1,"赵云");
balancePlusTree.put(3,"李白");
balancePlusTree.put(5,"韩信");
balancePlusTree.put(7,"瑶瑶");
balancePlusTree.put(11,"澜");
balancePlusTree.put(13,"诸葛亮");
balancePlusTree.put(15,"刘备");
balancePlusTree.put(17,"孙尚香");
balancePlusTree.put(21,"关羽");
balancePlusTree.put(23,"马超");
balancePlusTree.put(25,"貂蝉");
balancePlusTree.put(27,"小昭");
balancePlusTree.put(31,"欧阳锋");
balancePlusTree.put(33,"花木兰");
balancePlusTree.put(35,"郭靖");
balancePlusTree.put(37,"杨过");
balancePlusTree.put(41,"后羿");
balancePlusTree.put(43,"嫦娥");
balancePlusTree.put(45,"猪八戒");
balancePlusTree.put(47,"小乔");
}
@Test
public void testBalancePlusTreePutMethod(){
System.out.println("【开始测试put方法】");
long startTime = System.currentTimeMillis();
BalancePlusTree<Integer,String> balancePlusTree = new BalancePlusTree<>(5);
balancePlusTree.put(10,"张无忌");
balancePlusTree.put(20,"周芷若");
balancePlusTree.put(30,"赵敏");
balancePlusTree.put(40,"夏诗涵");
balancePlusTree.put(1,"赵云");
balancePlusTree.put(3,"李白");
balancePlusTree.put(5,"韩信");
balancePlusTree.put(7,"瑶瑶");
balancePlusTree.put(11,"澜");
balancePlusTree.put(13,"诸葛亮");
balancePlusTree.put(15,"刘备");
balancePlusTree.put(17,"孙尚香");
balancePlusTree.put(21,"关羽");
balancePlusTree.put(23,"马超");
balancePlusTree.put(25,"貂蝉");
balancePlusTree.put(27,"小昭");
balancePlusTree.put(31,"欧阳锋");
balancePlusTree.put(33,"花木兰");
balancePlusTree.put(35,"郭靖");
balancePlusTree.put(37,"杨过");
balancePlusTree.put(41,"后羿");
balancePlusTree.put(43,"嫦娥");
balancePlusTree.put(45,"猪八戒");
balancePlusTree.put(47,"小乔");
long endTime = System.currentTimeMillis();
System.out.println("【测试结束】:一共消耗" + (endTime - startTime) + "毫秒");
}
@Test
public void testSearch01(){
System.out.println("【开始测试query方法】");
long startTime = System.currentTimeMillis();
balancePlusTree.query(45).forEach(System.out::println);
long endTime = System.currentTimeMillis();
System.out.println("【测试结束】:一共消耗" + (endTime - startTime) + "毫秒");
}
}
测试结果如下:

为了体现我们B+树的效率,我们不妨创建一个520阶B+树,向里面添加200000个键值对,来测试一下咱们B+树的查询效率有多快。
@Before
public void init(){
balancePlusTree = new BalancePlusTree<>(520);
for (int i = 1;i <= 200000;i++){
balancePlusTree.put(i,"Lucy" + i);
}
}
我们添加20w条数据,下一步,我们随机查询一个树来查看一下执行的效率:
@Test
public void testSearch02(){
System.out.println("【开始测试B+树的查询性能】");
long startTime = System.currentTimeMillis();
balancePlusTree.query(88888).forEach(System.out::println);
long endTime = System.currentTimeMillis();
System.out.println("【测试结束】:一共消耗" + (endTime - startTime) + "毫秒");
}
运行结果如下:

从上面的测试来看,咱们一共向B+树插入了20w条数据,随机的去查找一个key,可以看出查询速度还是比较快的。咱们B+树其实很类似咱们前面讲过的Hash表的思想,将一组跟庞大的数据进行层层分片以及分组,然后再每个小组或者小片进行查找,从而排除了很多次无效查找,这种思想还是比较重要的,其实很多算法的实现都具有异曲同工之妙的。
四、综合代码
以下是本次B+树的所有代码,希望能跟正在学习以及奋斗的大家给一个参考:
4.1BalancePlusTreeNode
package com.ignorance.bplus.node;
import com.ignorance.bplus.BalancePlusTree;
import java.util.Collections;
import java.util.List;
public abstract class BalancePlusTreeNode<K extends Comparable<K>,E> {
//当前结点的key集合
protected List<K> entries;
//当前结点最大容纳的键个数
public static Integer UPPER_bOUND;
//当前结点至少应该包括的键个数
public static Integer LOWER_BOUND;
public BalancePlusTreeNode() {
}
public BalancePlusTreeNode(List<K> entries) {
this.entries = entries;
}
public List<K> getEntries() {
return entries;
}
public void setEntries(List<K> entries) {
this.entries = entries;
}
protected int gainReplaceIndex(K entry){
int left = 0;
int right = entries.size() - 1;
while (left <= right){
int middle = left + ((right - left) >> 1);
if (entry.compareTo(entries.get(middle)) > 0){
left = middle + 1;
}else if (entry.compareTo(entries.get(middle)) < 0){
right = middle - 1;
}else {
return middle;
}
}
return -1;
}
protected int gainInsertIndex(K entry){
int left = 0;
int right = entries.size();
while (left < right){
int middle = left + ((right - left) >> 1);
if (entry.compareTo(entries.get(middle)) > 0){
left = middle + 1;
}else if (entry.compareTo(entries.get(middle)) <= 0){
right = middle;
}
}
return left;
}
public abstract BalancePlusTreeNode<K,E> put(K entry, E value);
protected boolean isOverFlow(){
return entries.size() > UPPER_bOUND;
}
protected abstract BalancePlusTreeNode<K,E> split();
protected int gainSplitIndex(){
return UPPER_bOUND >> 1;
}
public abstract List<E> query(K entry);
}
4.2BalancePlusTreeNonLeafNode
以下是非叶子结点类的代码:
package com.ignorance.bplus.node;
import com.ignorance.bplus.utils.BalancePlusUtils;
import java.util.List;
public class BalancePlusTreeNonLeafNode<K extends Comparable<K>,E> extends BalancePlusTreeNode<K,E> {
private List<BalancePlusTreeNode<K,E>> child;
public BalancePlusTreeNonLeafNode(List<K> entries, List<BalancePlusTreeNode<K, E>> child) {
super(entries);
this.child = child;
}
@Override
public BalancePlusTreeNode<K, E> put(K entry, E value) {
BalancePlusTreeNode<K,E> insertChildNode = child.get(super.gainInsertIndex(entry)).put(entry, value);
if (insertChildNode != null) {
K newEntry = findLeafEntry(insertChildNode);
int newEntryIndex = gainInsertIndex(newEntry);
entries.add(newEntryIndex, newEntry);
child.add(newEntryIndex + 1, insertChildNode);
return super.isOverFlow() ? split() : null;
}
return null;
}
public K findLeafEntry(BalancePlusTreeNode<K, E> curNode) {
if (curNode instanceof BalancePlusTreeLeafNode) {
return curNode.entries.get(0);
}
BalancePlusTreeNonLeafNode<K,E> targetNode = (BalancePlusTreeNonLeafNode)curNode;
return findLeafEntry(child.get(0));
}
@Override
protected BalancePlusTreeNode<K, E> split() {
//1-1:计算非叶子结点的分割位置
int splitIndex = super.gainSplitIndex();
//1-2:存储该非叶子结点的entries
List<K> currentNodeEntries = entries;
//1-3:存储该非叶子结点子结点
List<BalancePlusTreeNode<K,E>> childList = child;
//1-4:重置当前非叶子结点的entries为起始位置到分割点的entries
this.entries = BalancePlusUtils.splitBalancePlusTreeNode(currentNodeEntries,0,splitIndex);
//1-5:重置当前非叶子结点的child为起始位置到分割点+1的child
this.child = BalancePlusUtils.splitBalancePlusTreeNode(childList,0,splitIndex);
//创建新的entries,该集合对应分割点后的entries
List<K> rightEntries = BalancePlusUtils.splitBalancePlusTreeNode(currentNodeEntries,splitIndex + 1,currentNodeEntries.size() - 1);
//创建新的child,该集合对应分割点+1后的child
List<BalancePlusTreeNode<K, E>> rightChildren = BalancePlusUtils.splitBalancePlusTreeNode(childList, splitIndex + 1, childList.size() - 1);
//将新创建的非叶子返回给调用者
return new BalancePlusTreeNonLeafNode<>(rightEntries, rightChildren);
}
@Override
public List<E> query(K entry) {
return child.get(gainInsertIndex(entry)).query(entry);
}
}
4.3BalancePlusTreeLeafNode
以下是叶子结点的实现:
package com.ignorance.bplus.node;
import com.ignorance.bplus.BalancePlusTree;
import com.ignorance.bplus.utils.BalancePlusUtils;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Set;
public class BalancePlusTreeLeafNode<K extends Comparable<K>,E> extends BalancePlusTreeNode<K,E> {
//当前叶子结点的数据域
private List<Set<E>> data;
//当前叶子结点数据域的next域
private BalancePlusTreeNode next;
public BalancePlusTreeLeafNode(List<K> entries, List<Set<E>> data) {
super(entries);
this.data = data;
}
@Override
public BalancePlusTreeNode<K, E> put(K entry, E value) {
//查询叶子结点是否存在同样的entry,如果存在就将value添加一次
int currentReplaceIndex = super.gainReplaceIndex(entry);
if (currentReplaceIndex != -1){
data.get(currentReplaceIndex).add(value);
return null;
}
//能走到这儿,就说明叶子结点不存在对应的key,此时我们应该计算出当前entry在结点中的插入位置
int currentInsertIndex = super.gainInsertIndex(entry);
entries.add(currentInsertIndex,entry);
data.add(currentInsertIndex, BalancePlusUtils.transToSet(value));
return isOverFlow() ? split() : null;
}
@Override
protected BalancePlusTreeNode<K, E> split() {
//获取分割位置
int currentSplitIndex = super.gainSplitIndex();
//保留原来叶子结点的entry集合
List<K> currentSplitEntries = this.entries;
//保留原来叶子结点的data集合
List<Set<E>> currentSplitData = this.data;
//将当前结点的entries截取到分割位置
this.entries = BalancePlusUtils.splitBalancePlusTreeNode(this.entries,0,currentSplitIndex);
//将当前结点的data截取到分割位置
this.data = BalancePlusUtils.splitBalancePlusTreeNode(this.data,0,currentSplitIndex);
/*
构建新的结点
1-1 让新结点的entries为原来叶子结点分割位置后的entries
1-2 让新结点的data为原来叶子结点分割位置后的data
*/
List<K> splitAnotherEntries = BalancePlusUtils.splitBalancePlusTreeNode(currentSplitEntries,currentSplitIndex + 1,currentSplitEntries.size() - 1);
List<Set<E>> splitAnotherData = BalancePlusUtils.splitBalancePlusTreeNode(currentSplitData,currentSplitIndex + 1,currentSplitData.size() - 1);
//构建新结点
BalancePlusTreeLeafNode<K,E> balancePlusLeafTreeNode = new BalancePlusTreeLeafNode<>(splitAnotherEntries,splitAnotherData);
//完成叶子结点next指针构建
balancePlusLeafTreeNode.next = this.next;
this.next = balancePlusLeafTreeNode;
//将新结点进行返回
return balancePlusLeafTreeNode;
}
@Override
public List<E> query(K entry) {
int entryIndex = gainReplaceIndex(entry);
return entryIndex == -1 ? Collections.emptyList() : new ArrayList<>(data.get(entryIndex));
}
}
4.4BalancePlusTree核心类
以下是BalancePlusTree核心类的代码实现:
package com.ignorance.bplus;
import com.ignorance.bplus.node.BalancePlusTreeLeafNode;
import com.ignorance.bplus.node.BalancePlusTreeNonLeafNode;
import com.ignorance.bplus.node.BalancePlusTreeNode;
import com.ignorance.bplus.utils.BalancePlusUtils;
import java.util.Collections;
import java.util.List;
import java.util.Set;
public class BalancePlusTree<K extends Comparable<K>,E> {
//B+树的默认阶数
private static final Integer DEFAULT_BOUND = 4;
//上限
private final Integer UPPER_BOUND;
//下限
private final Integer LOWER_BOUND;
//B+树的根结点
private BalancePlusTreeNode<K,E> root;
public BalancePlusTree(int bound) {
this.UPPER_BOUND = bound - 1;
this.LOWER_BOUND = this.UPPER_BOUND >> 1;
BalancePlusTreeNode.UPPER_bOUND = this.UPPER_BOUND;
BalancePlusTreeNode.LOWER_BOUND = this.LOWER_BOUND;
}
public BalancePlusTree() {
this(DEFAULT_BOUND);
}
public void put(K entry,E value){
//1-1:如果待添加结点是第一个结点,将其直接作为根结点添加
//1-2:而此时我们创建的结点肯定是叶子结点
if (root == null){
List<K> entries = BalancePlusUtils.transToList(entry);
List<Set<E>> data = BalancePlusUtils.transToList(BalancePlusUtils.transToSet(value));
root = new BalancePlusTreeLeafNode<K,E>(entries,data);
return;
}
//如果当前root不为空,则调用当前结点的put方法
BalancePlusTreeNode<K, E> insertNode = root.put(entry, value);
K splitRootKey = null;
if (insertNode != null){
/**
* 1-1:如果insertnode 不为空,表示该结点需要分裂
* 1-2:如果返回的结点为叶子结点,则提取该结点的第一个key,并且让当前root和当前返回结点成为第一个key所在结点的子结点
* 1-3:如果返回的结点时非叶子结点,则需要递归查找它的叶子结点的第一个key,并且让当前root和当前返回结点成为第一个key
* 所在结点的子结点
* 1-4:最后重置root结点为分裂结点即可
*/
if (insertNode instanceof BalancePlusTreeLeafNode){
splitRootKey = insertNode.getEntries().get(0);
}else {
splitRootKey = ((BalancePlusTreeNonLeafNode<K,E>) insertNode).findLeafEntry(insertNode);
}
this.root = new BalancePlusTreeNonLeafNode<K,E>(BalancePlusUtils.transToList(splitRootKey),BalancePlusUtils.transToList(root,insertNode));
}
}
public List<E> query(K entry) {
if (root == null) {
return Collections.emptyList();
}
return root.query(entry);
}
}
4.5BalancePlusTreeUtils工具类
以下是BalancePlusTreeUtils工具类的核心代码实现:
package com.ignorance.bplus.utils;
import java.util.*;
public class BalancePlusUtils {
public static <T> List<T> transToList(T...data){
List<T> list = new ArrayList<>();
Collections.addAll(list,data);
return list;
}
public static <E> Set<E> transToSet(E...ele){
Set<E> set = new HashSet<>();
Collections.addAll(set,ele);
return set;
}
public static <T> List<T> splitBalancePlusTreeNode(List<T> splitList,int startIndex,int endIndex){
List<T> subList = new ArrayList<>();
while (startIndex <= endIndex){
subList.add(splitList.get(startIndex++));
}
return subList;
}
}
4.6BalancePlusTreeTest测试类
以下是BalancePlusTreeTest测试类的代码:
package com.ignorance.bplus.test;
import com.ignorance.bplus.BalancePlusTree;
import org.junit.Before;
import org.junit.Test;
public class BalancePlusTreeTest {
private BalancePlusTree<Integer,String> balancePlusTree;
@Before
public void init(){
balancePlusTree = new BalancePlusTree<>(520);
for (int i = 1;i <= 200000;i++){
balancePlusTree.put(i,"Lucy" + i);
}
}
@Test
public void testBalancePlusTreePutMethod(){
System.out.println("【开始测试put方法】");
long startTime = System.currentTimeMillis();
BalancePlusTree<Integer,String> balancePlusTree = new BalancePlusTree<>(5);
balancePlusTree.put(10,"张无忌");
balancePlusTree.put(20,"周芷若");
balancePlusTree.put(30,"赵敏");
balancePlusTree.put(40,"夏诗涵");
balancePlusTree.put(1,"赵云");
balancePlusTree.put(3,"李白");
balancePlusTree.put(5,"韩信");
balancePlusTree.put(7,"瑶瑶");
balancePlusTree.put(11,"澜");
balancePlusTree.put(13,"诸葛亮");
balancePlusTree.put(15,"刘备");
balancePlusTree.put(17,"孙尚香");
balancePlusTree.put(21,"关羽");
balancePlusTree.put(23,"马超");
balancePlusTree.put(25,"貂蝉");
balancePlusTree.put(27,"小昭");
balancePlusTree.put(31,"欧阳锋");
balancePlusTree.put(33,"花木兰");
balancePlusTree.put(35,"郭靖");
balancePlusTree.put(37,"杨过");
balancePlusTree.put(41,"后羿");
balancePlusTree.put(43,"嫦娥");
balancePlusTree.put(45,"猪八戒");
balancePlusTree.put(47,"小乔");
long endTime = System.currentTimeMillis();
System.out.println("【测试结束】:一共消耗" + (endTime - startTime) + "毫秒");
}
@Test
public void testSearch01(){
System.out.println("【开始测试query方法】");
long startTime = System.currentTimeMillis();
balancePlusTree.query(45).forEach(System.out::println);
long endTime = System.currentTimeMillis();
System.out.println("【测试结束】:一共消耗" + (endTime - startTime) + "毫秒");
}
@Test
public void testSearch02(){
System.out.println("【开始测试B+树的查询性能】");
long startTime = System.currentTimeMillis();
balancePlusTree.query(88888).forEach(System.out::println);
long endTime = System.currentTimeMillis();
System.out.println("【测试结束】:一共消耗" + (endTime - startTime) + "毫秒");
}
}
总结
在本次文章中,我们主要讲解了最后一种树,也就是咱们的B树以及B+树,其实大家会发现无论是B树还是B+树,它的核心思想就是2-3查找树,可以说2-3查找树或者红黑树就是2-3查找树最简单的一种形式,我们最终解决的还是树的平衡性问题,让咱们的查询效率达到更高。
B+树我们并不陌生,MySQL索引的底层本质就是B+树,在本次讲解中,希望让正在学习的同学们加深对底层知识的掌握与理解,让咱们无论是技术还是学习等级都更上一个阶段。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









