






在被面试管问到ConcurrentHashMap是如何保证线程安全的,只知道ConcurrentHashMap是线程安全的,具体如何保证线程安全,却说不清楚,本文将带大家彻底解读ConcurrentHashMap的原理。
首先我们用图解的方式讲述ConcurrentHashMap的实现原理,熟悉ConcurrentHashMap内部结构,这样就更通俗易懂了。
简单回顾一下HashMap的结构:
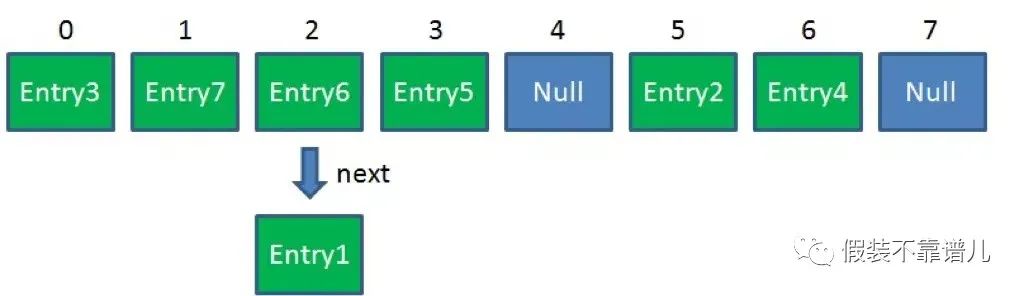
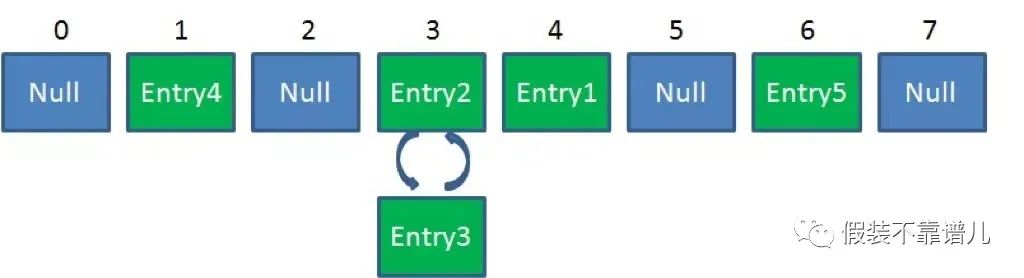
简单来说,HashMap是一个Entry对象的数组。数组中的每一个Entry元素,又是一个链表的头节点。Hashmap不是线程安全的。在高并发环境下做插入操作,有可能出现下面的环形链表:
避免HashMap的线程安全问题有很多办法,比如改用HashTable或者Collections.synchronizezMap。但两者有着共同的问题:性能。无论读操作还是写操作,他们都会给整个集合加锁,导致同一时间的其他操作为之阻塞。
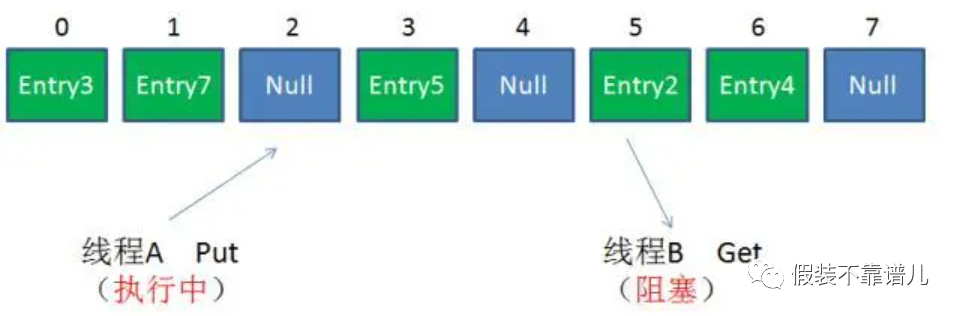
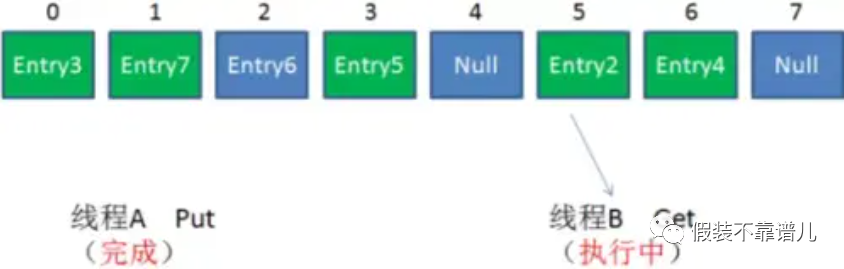
在并发环境下,如何能够兼顾线程安全和运行效率呢,ConcurrentHashMap就应运而生了。
JDK1.7CurrentHashMap实现原理
在JDK1.7中ConcurrentHashMap采用了数组+Segment+分段锁的方式实现。
ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表,同时又是一个ReentrantLock(Segment继承ReentrantLock)。
单一的Segment结构如下:
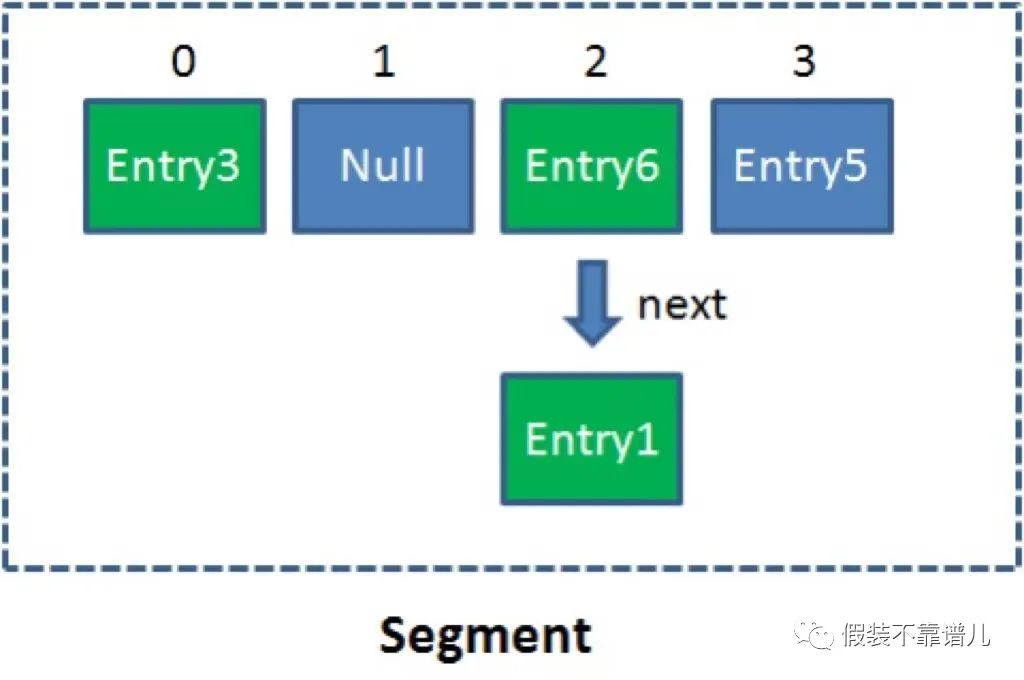
像这样的Segment对象,在ConcurrentHashMap集合中有多少个呢?有2的N次方个,共同保存在一个名为segments的数组当中。
因此整个ConcurrentHashMap的结构如下:
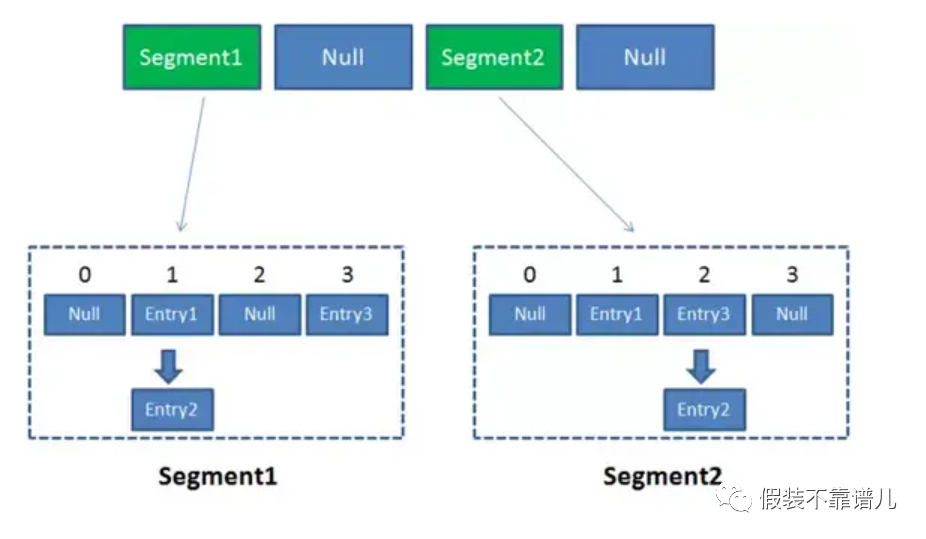
ConcurrentHashMap是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。ConcurrentHashMap优势就是采用了(锁分段技术),每一个Segment就好比一个自治区,读写操作高度自治,Segment之间互不影响。
我们来看看ConcurrentHashMap并发读写的几种情形。
1.不同Segment的写入是可以并发执行的。

2.同一Segment的写和读是可以并发执行的。
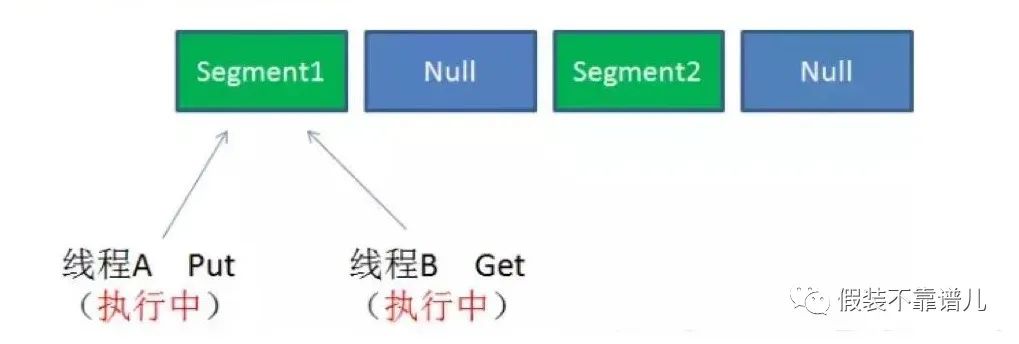
3.同一Segment的并发写入
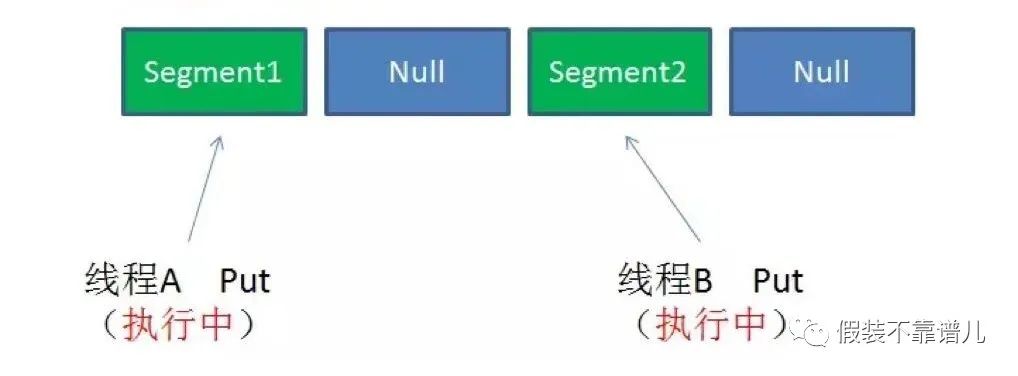
Segment的写入是需要上锁的,因此对同一Segment的并发写入会被阻塞。由此可见,ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
接下来我们看下ConcurrentHashMap读写的详细过程。
get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象。
3.再次通过hash值,定位到Segment当中数组的具体位置。
put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象。
3.获取可重入锁。
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
从步骤可以看出,ConcurrentHashMap在读写时需要二次定位,首先定位到Segment,之后定位到Segment内的具体数组下标。
size方法:
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
size方法源码如下:
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
这样设计的理由是为了尽量不锁住所有Segment,首先乐观地假设Size过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有Segment保证强一致性。
JDK1.8CurrentHashMap实现原理
在Java8中,ConcurrentHashMap弃用了Segment类,但是保留了Segment属性,用于序列化。目前ConcurrentHashMap采用Node类作为基本的存储单元,每个键值对(key-value)都存储在一个Node中。同时Node也有一些子类,TreeNodes用于树结构中(当链表长度大于8时转化为红黑树);TreeBins用于维护TreeNodes。当链表转树时,用于封装TreeNode。也就是说,ConcurrentHashMap的红黑树存放的是TreeBin,而不是treeNode;ForwordingNodes是一个重要的结构,它用于ConcurrentHashMap扩容时,是一个标志节点,内部有一个指向nextTable的属性,同时也提供了查找的方法;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val; //使用了volatile属性
volatile Node<K,V> next; //使用了volatile属性
Node(int hash, K key, V val) {
this.hash = hash;
this.key = key;
this.val = val;
}
Node(int hash, K key, V val, Node<K,V> next) {
this(hash, key, val);
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString() {...}
public final V setValue(V value) {...}
public final boolean equals(Object o) {...}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node<K,V> find(int h, Object k) {...}
}
处理Node之外,Node的一个子类ForwardingNodes也是一个重要的结构,它主要作为一个标记,在处理并发时起着关键作用,有了ForwardingNodes,也是ConcurrentHashMap有了分段的特性,提高了并发效率。
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
//hash值默认为MOVED(-1)
super(MOVED, null, null);
this.nextTable = tab;
}
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
//在nextTable中查找,nextTable可以看做是当前hash表的一个副本
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
}
ConcurrentHashMap中的原子操作
在ConcurrentHashMap中通过原子操作查找元素、替换元素和设置元素。这些原子操作起着非常关键的作用,你可以在所有ConcurrentHashMap的基本功能中看到它们的身影。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectAcquire(tab, ((long)i << ASHIFT) + ABASE);
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectRelease(tab, ((long)i << ASHIFT) + ABASE, v);
}
ConcurrentHashMap的get方法
ConcurrentHashMap的get方法就是从Hash表中读取数据,而且与扩容不冲突。该方法没有同步锁。
通过键值的hash计算索引位置,如果满足条件,直接返回对应的值;
如果相应节点的hash值小于0 ,即该节点在进行扩容,直接在调用ForwardingNodes节点的find方法进行查找。
否则,遍历当前节点直到找到对应的元素。
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
//满足条件直接返回对应的值
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//e.hash<0,正在扩容
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
//遍历当前节点
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock,原因如下几点:
1.因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了。
2.JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然。
3.在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据。
总结
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树。
1.数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
2.保证线程安全机制:JDK1.7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8采用CAS+Synchronized保证线程安全。
3.锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
4.链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
5.查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。














 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









