







目录
$ hive --help
一个简单说明的选项列表,Service List 后面的内容,是提供的服务

$ hive --help --service cli
显示了 CLI 所提供的选项列表

命名空间
$ hive -define foo=bar
定义一个变量 foo
set 显示或修改变量值,直接 set 显示全部变量,只截取了部分,还可以用于给变量赋新的值
hive>set

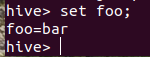
hive> set foo;
hivevar 命名空间定义变量,查看,修改
hive> set hivevar:foo;
hive> set hivevar:foo=bar2;
hive> set hivevar:foo;
![]()
前缀 hivevar: 是可选的, --hivevar --define 标记是相同的
变量替换
CLI 查询语句中的变量应用会先被替换掉后才会提交给查询处理器
创建一个表 toss1
hive> create table toss1(i int, ${hivevar:foo} string);
查看
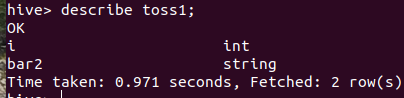
hive> describe toss1;
创建表 toss2,查看
hive> create table toss2(i2 int, ${foo} string);
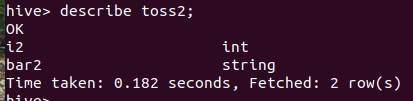
hive> describe toss2;
--hiveconf 选项
用于配置 hive 行为的所有属性
hive.cli.print.current.db 属性开启,默认是 false,可以在提示符前打印当前数据库名,debry 默认数据库名为 default
$ hive --hiveconf hive.cli.print.currrent.db=true
hive -e
可执行一个或多个查询语句(分号分隔),执行结束后 hive CLI 立即退出,例如
$ hive -e "select * from mytable limit 3";
OK
name1 10
name2 20
Time taken:4.324 second
$
hive -S
将查询结果保存到一个文件中,增加 -S 开启静默模式,这样可以在输出中去掉 “OK” “Time taken” 等无关的输出
$ hive -S -e "select * from mytable limit 3" > /tmp
$ cat tmp
name1 10
name2 20
输出是输出到本地,不是 hdfs
模糊查询
记不清某个属性名时,可以使用,而不用 set 翻滚查找,例如记不清 warehouse 的路径
$ hive -S -e "set" | grep warehouse

hive -f
指定文件名执行一个或多个查询语句,一般这些查询文件后缀为 .q .hql
$ hive -f /temp/123.hql
也可以在 hive shell 中执行
$ hive
hive> source /temp/123.hql;
hive -i
指定一个文件,但 CLI 启动时,在提示符出现之前会先执行这个文件
在提示符出现前,hive 会自动在 HOME 目录下寻找 .hiverc 文件,自动执行里面的命令
操作历史
会将最近 100,00 条命令记录到 $HOME/.hivehistory 中
执行 shell 命令
在命令前加上 !
hive> ! pwd;
![]()
不支持管道功能,和文件名的自动补全功能
hadoop dfs 命令
这种方式比 hadoop dfs 更高效,,hadoop 每次都会启动一个新 JVM 实例,hive 就在同一个进程中
hive> dfs -ls / ;

显示字段名称
hive> set hive.cli.print.header=true
执行查询就会显示字段名了















 1558
1558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









