






远程模式的部署是为了什么呢?为什么一定要部署远程模式?远程模式到底该怎么部署?
各位小伙伴跟好节奏 让我们一起学习安装 如果说你想通过DataGrip操作hive的话,这个时候就一定要开启远程模式!接下来按照我的步骤走轻轻松松安装 一起来吧家人们!
一、创建临时目录
首先第一步我们需要创建一个临时目录
创建临时目录本质上是为Hive提供可靠的数据暂存空间,确保分布式环境下各组件能协同工作。跳过此步骤可能导致权限错误、路径不存在异常或作业执行失败,尤其在依赖HDFS的场景中,手动创建和授权是必要的部署前提。
[root@bigdata01 ~]# cd /opt/installs/hive/
[root@bigdata01 hive]# mkdir iotmp
[root@bigdata01 hive]# chmod 777 iotmp二、准备工作(相当重要)
在我们安装之前首先要做好前期的准备工作 首先我们需要先来配置一下相关内容
在hive-site.xml中添加如下配置信息
<!--Hive工作的本地临时存储空间-->
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/installs/hive/iotmp/root</value>
</property>
<!--如果启用了日志功能,则存储操作日志的顶级目录-->
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/opt/installs/hive/iotmp/root/operation_logs</value>
</property>
<!--Hive运行时结构化日志文件的位置-->
<property>
<name>hive.querylog.location</name>
<value>/opt/installs/hive/iotmp/root</value>
</property>
<!--用于在远程文件系统中添加资源的临时本地目录-->
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/installs/hive/iotmp/${hive.session.id}_resources</value>
</property>其中hive.downloaded.resources.dir
这个文件中hive一定要小写不能大写 因为在hdfs上下载的额一些资源会被存放在这个目录下 一定要小写否则会报如下错误一定要注意!!
cause: java.net.URISyntaxException: Illegal character in path at index 26: /opt/installs/hive/iotmp/${Hive.session.id}_resources/json-serde-1.3.8-jar-with-dependencies.jar接下来修改 hadoop中的 core-site.xml
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 不开启权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>这个修改完成之后要注意我们需要把三个集群全部都修改,刚才我们修改完成之后现在需要同步其余两个集群,并且重新启动hdfs
xsync.sh core-site.xml #同步
stop-dfs.sh #重启
start-dfs.sh三、配置远程服务
1.首先第一个我们先来配置hiveserver2服务
第一步:修改hive-site.xml
<property>
<name>hive.server2.thrift.bind.host</name>
<value>bigdata01</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>修改完成之后我们就可以启动,启动有三种方式我们用最好用的一种
直接输入
nohup hive --service hiveserver2 >/dev/null 2>&1 &启动完成之后怎么知道到底有没有启动成功呢?我们先来测试一下
step1. beeline 回车
step2. !connect jdbc:hive2://bigdata01:10000 回车
step3. 输入用户名 回车 用户名
step4. 输入密码 可以不输入
Ctrl+ C 可以退出客户端按照上述我们测试一下正常进入后我们就配置成功咯!
2.配置metastore
警告:
假如 hive 直接进入的,操作了数据库,其实底层已经帮助创建了一个metastore服务器,可能叫ms01
通过hiveserver2 运行的命令,默认底层帮你创建了一个metastore服务器,可能叫ms02,假如有很多人连接我的mysql,就会有很多个metastore,非常的占用资源。
解决方案就是:配置一个专门的metastore,只有它可以代理mysql服务,别人必须经过它跟mysql进行交互。这样解决内存。
警告:只要配置了metastore以后,必须启动,否则报错!
首先我们需要修改一下
hive-site.xml
修改hive-site.xml的配置
注意:想要连接metastore服务的客户端必须配置如下属性和属性值
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata01:9083</value>
</property>
解析:thrift:是协议名称
ip为metastore服务所在的主机ip地址
9083是默认端口号修改完完成之后我们来启动一下
nohup hive --service metastore 2>&1 >/dev/null &输入完成之后我们就成功启动 metastory
启动完成之后我们需要测试一下看刚才是否出成功启动
没有启动metastore 服务器之前,hive进入报错!
hive> show databases;
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
启动之后,直接测试,发现可以使用。
hive> show databases;
OK
default
Time taken: 1.211 seconds, Fetched: 1 row(s)四、使用客户端工具连接hive
我们本次推荐使用的工具是:DataGrap
我们在连接之前首先先检查一下 工欲善其事 必先利其器嘛
请检查你的 metastore和hiveserver2是否启动
ps -ef|grep metastore
ps -ef|grep hiveserver2
假如没有启动:
nohup hive --service metastore 2>&1 >/dev/null &
nohup hive --service hiveserver2 2>&1 >/dev/null &
由于没办法看到4个session ID,等一下。接下来我们就可以打开我们的DataGrap进行连接
我们需要连接的Hive所以需要选择 Apache Hive
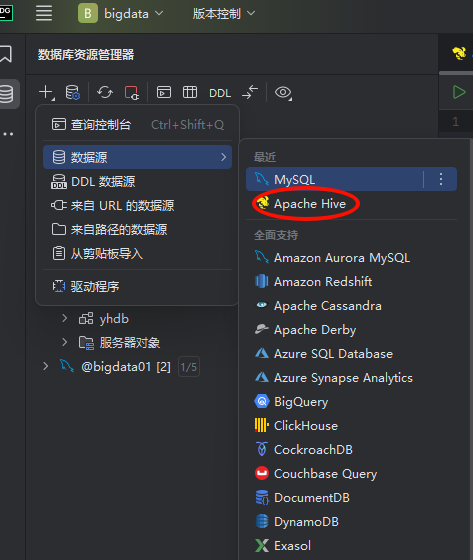
我们首次连接的话在红色框选位置会有一个黄色感叹号三角图标 放心不是报错 是我们需要先下载一个驱动 我们正常点击下载就可以
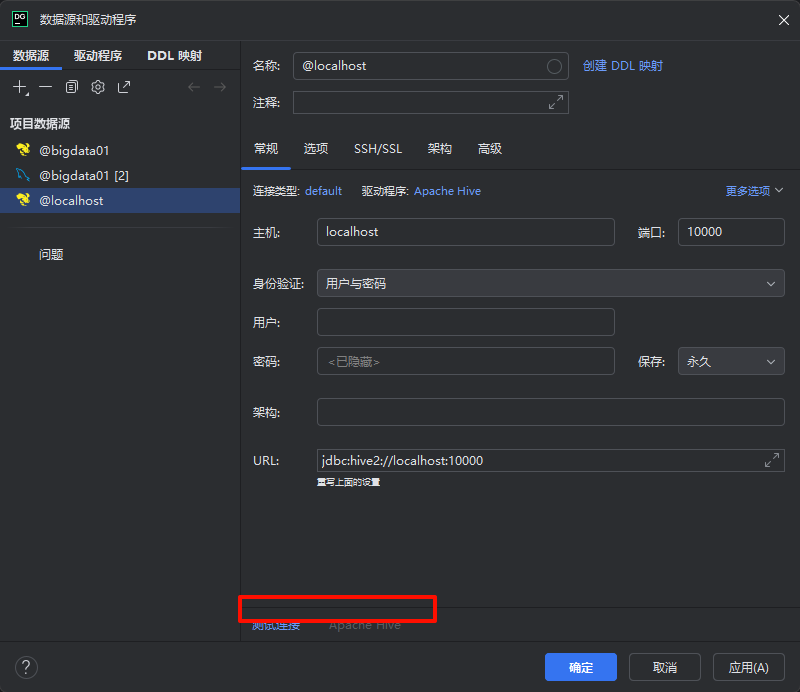
下载完成之后,输入你的主机号 还有用户名和密码就可以咯 我们先测试一下是否能正常连接 提示如下界面就证明测试成功 我们正常点击右下角应用就可以、
此处的密码我们输入不输入都没有关系 因为和我们的MySQL没有关系
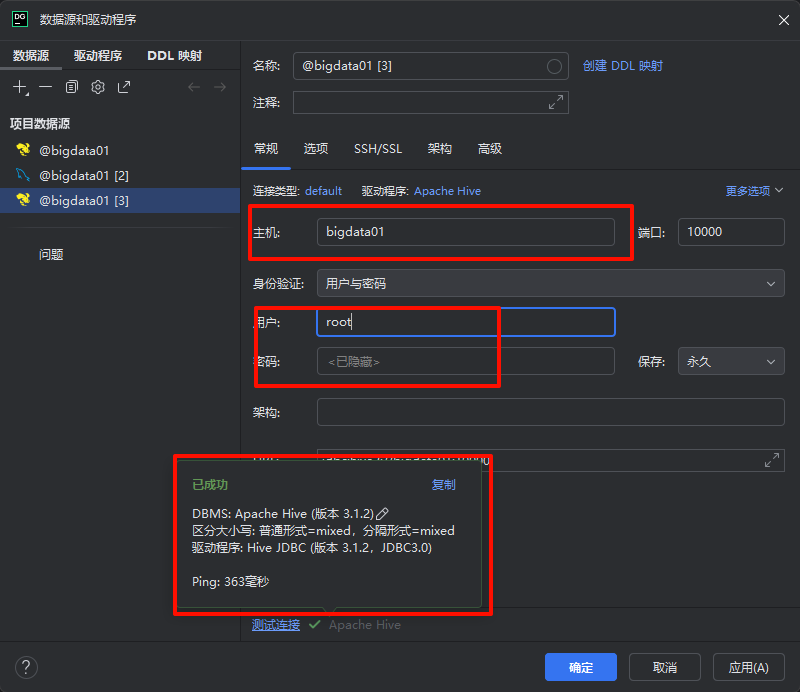
ok 那么好 通过以上我们的远程模式就部署完成咯!!!恭喜你又成功拿下


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









