







前言:
💞💞大家好,我是书生♡,今天主要和大家分享一下Hive中常见的优化手段----数据采集!常见的Join 优化有哪几种!什么是Hive索引!数据怎么发生倾斜!什么是mapreduce的本地模式!map和reduce数量调整!!!希望对大家有所帮助。
💞💞代码是你的画笔,创新是你的画布,用它们绘出属于你的精彩世界,不断挑战,无限可能!
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬
目录
1. 分桶表
我们先来回顾一下,什么是分桶表?本质是什么?有什么作用?
- 分桶表
分桶表(Bucketed Table)是相对分区表进行更细粒度的划分。它的原理是将数据按照指定字段的哈希值分成固定数量的桶(Buckets),将每条记录分配到对应的桶中。分桶表将整个Hive表数据内容按照某列属性值的hash值进行分区,通过分区将这些表数据划分到多个文件中进行存储。
- 分桶表的本质
分桶表的本质无论是分区,还是分桶,本质都是对数据的拆分存储,作用是为了提升查询的效率。
因为分桶表就是将数据存储在不同的文件中。
- 作用
- 数据管理和优化:
数据分散:通过将数据按照指定的列进行哈希并分配到不同的桶中,分桶表可以将大数据集分散到多个小文件中进行存储。这有助于管理和维护大型数据集,因为每个桶都可以独立地进行处理。
数据均匀分布:选择适当的分桶列可以确保数据在桶之间均匀分布,从而避免数据倾斜问题。数据倾斜是指某些桶中的数据量远大于其他桶,这可能导致某些任务执行缓慢或失败。
- 查询性能提升:
JOIN操作优化:当两个表都进行了分桶,并且分桶的列和桶的数量相同时,Hive可以只扫描那些具有相同桶编号的桶来执行JOIN操作。这显著减少了需要扫描的数据量,从而提高了JOIN操作的性能。
采样查询:分桶表支持基于桶的采样查询,这意味着可以只查询一个或多个桶中的数据,而不是整个表。这对于快速分析和测试数据集的一部分非常有用。
- 数据倾斜的避免:
选择合适的分桶列可以确保数据在桶之间均匀分布,从而避免数据倾斜问题。数据倾斜是大数据处理中常见的问题之一,它可能导致某些任务执行缓慢或失败。通过使用分桶表,可以更好地管理和控制数据的分布。
2.数据采集
定义:
采样是从数据集中抽取部分样本数据进行分析和查询的一种技术。在Hive中,可以使用TABLESAMPLE子句来进行采样查询。采样可以帮助在大数据集上进行快速的试验和分析,而不需要处理整个数据集。
当表的数据量比较庞大的时候, 在编写SQL语句后, 需要首先测试 SQL是否可以正常的执行, 需要在表中执行查询操作, 由于表数据量比较庞大, 在测试一条SQL的时候整个运行的时间比较久, 为了提升测试效率, 可以整个表抽样出一部分的数据, 进行测试。
- 语法
采样函数:
tablesample(bucket x out of y [on column|rand()])
x: 从第几个桶开始进行采样;
y: 抽样比例;
column: 分桶的字段, 可以省略,rand()表示随机抽取
注意:
- x 不能大于 y; 2. y 必须是表的分桶数量的倍数或者因子
案例:
- 假设 A表有10个桶, 请分析, 下面的采样函数, 会将那些桶抽取出来呢?
tablesample(bucket 2 out of 5 on xxx) - 假设 A 表有20个桶, 请分析, 下面的抽样函数, 会将那些桶抽取出来呢?
tablesample(bucket 4 out of 4 on xxx) 共计抽取2个桶, 分别是 1号桶和6号桶
tablesample(bucket 8 out of 40 on xxx) 共计抽取5个桶, 分别是 3,7,11,15,19
抽取二分之一个桶, 分别是7号桶二分之一
3. Join优化
我们常见的MR流程是怎么样子的?
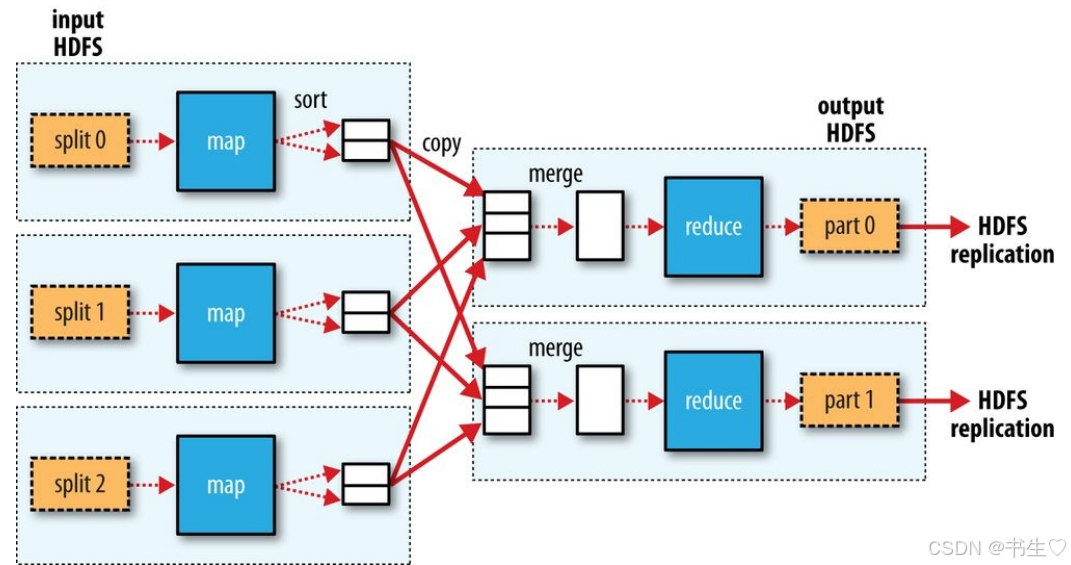
那么这种的工作流程可能会出现什么弊端呢?
- 可能会存在数据倾斜的问题 (某几个reduce接收数据量远远大于其他的reduce接收数据量)
- 所有的数据处理的操作, 全部都压在reduce中进行处理, 而reduce数量相比Map来说少的多,导致整个reduce压力比较大。
那我们就说说怎么提高效率
3.1 Map Join 优化
一、Map Join概述
Map Join是一种在Map阶段进行表之间连接的技术,它避免了传统的Reduce阶段连接,从而节省了Shuffle阶段的大量数据传输,提高了查询性能。Map Join通常用于小表与大表之间的连接操作。
二、Map Join原理
- 小表加载到内存:
在Map阶段开始之前,MapJoin操作会首先加载小表的数据到每个Mapper的内存中,通常是将小表数据构造成一个哈希表(HashTable)的形式。 - 大表数据读取与哈希计算:
Mapper在读取大表数据时,会按照Join键对大表的每条记录进行哈希计算。 - 内存匹配:
Mapper将大表数据的哈希计算结果与内存中加载的小表哈希表进行匹配。
如果匹配成功,则直接将两个表的记录进行连接并输出。
Map Task 原理图
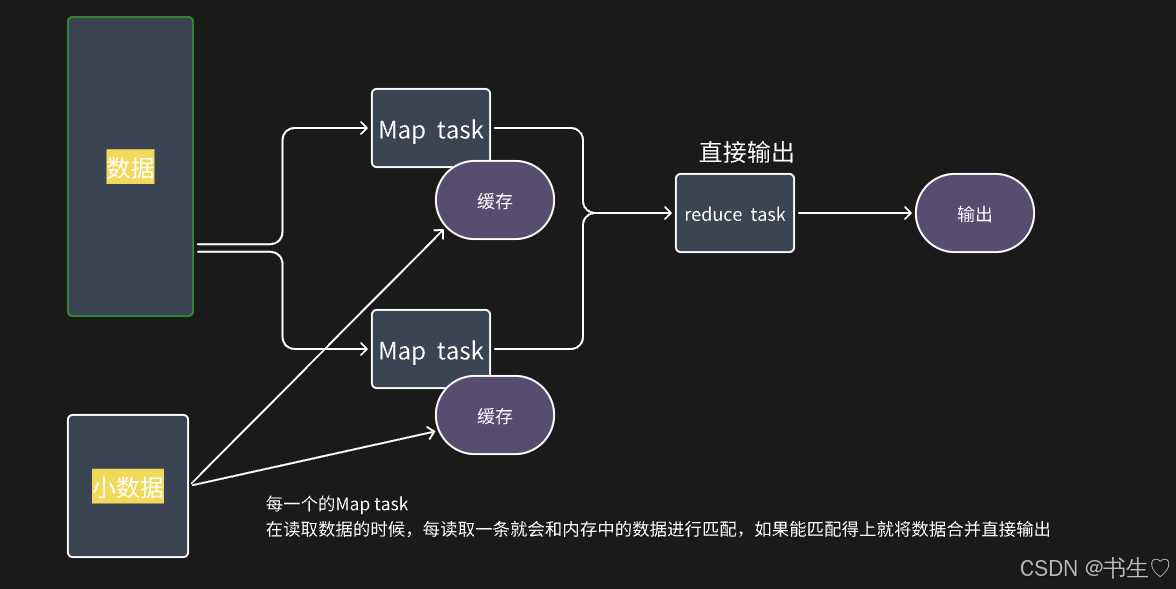
Map Join: 每一个mapTask在读取数据的时候, 每读取一条数据, 就会和内存中表数据进行匹配, 如果能匹配的上,将匹配上数据合并在一起, 输出即可
好处: 将原有reduce join 问题全部都可以解决
弊端:
1- 比较消耗内存
2- 要求整个 Join 中, 必须的都有一个小表, 否则无法放入到内存中
仅适用于: 小表 join 大表或者大表 join 小表
使用的条件,需要开启的设置
set hive.auto.convert.join=true; -- 开启 map join的支持 默认值为True
set hive.mapjoin.smalltable.filesize= 25000000; --设置 小表的文件大小(23.84m)
set hive.auto.convert.join.noconditionaltask.size=20971520; -- 设置 join任务数据量
如果不满足条件, HIVE会自动使用 reduce join 操作
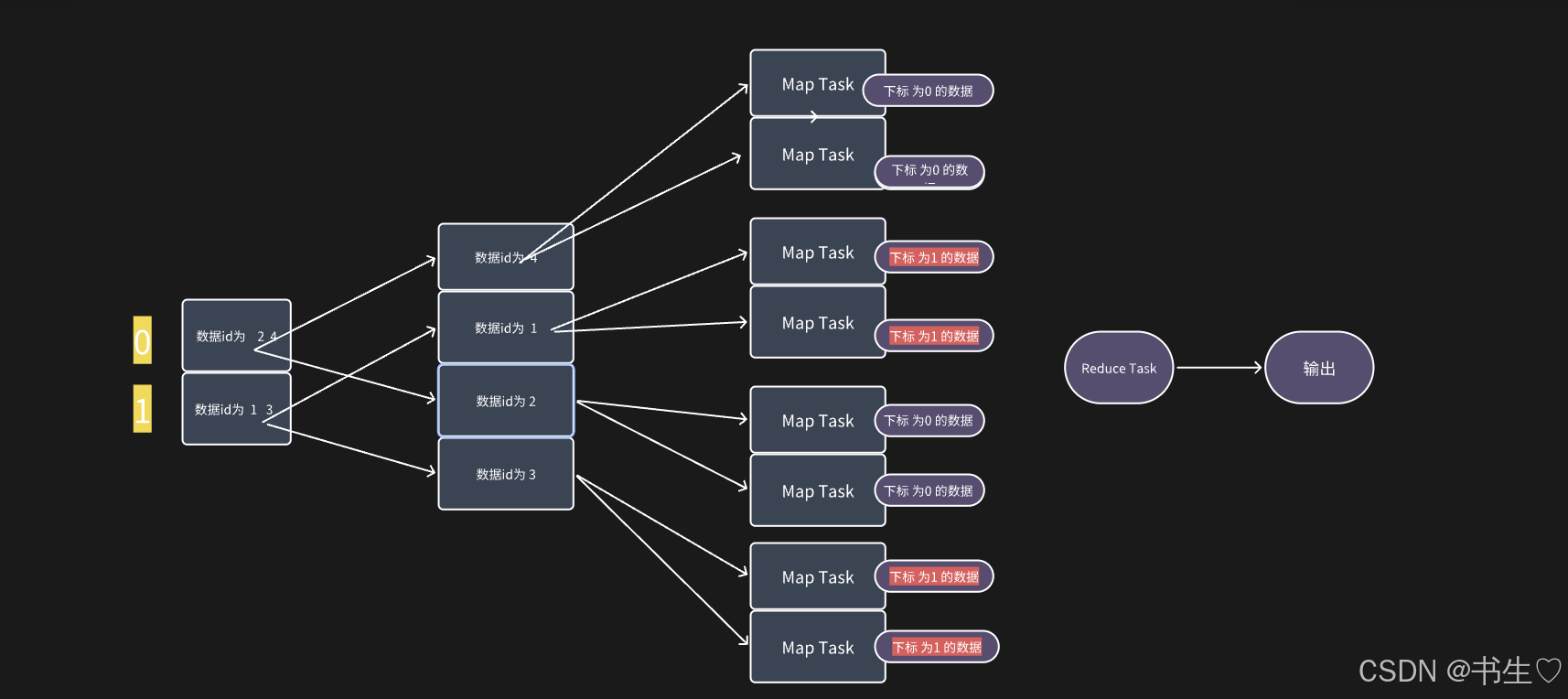
3.2 Bucket Map Join 优化
Map Task 只是适用于大表和小表连接,如果是一个中表应该怎么办呢?
这个时候我们就使用 Bucket Map Join 优化 解决问题。当然 如果中型表能对数据进行提前过滤, 尽量提前过滤, 过滤后, 有可能满足了Map Join 条件 (并不一定可用)。
我们的这个设置默认是关闭的,需要我们手动开启
-- bucket map join
set hive.optimize.bucketmapjoin; -- 默认false
前提条件:
1- Join两个表必须是分桶表
2- 开启 Bucket Map Join 支持: set hive.optimize.bucketmapjoin = true;
3- 一个表的分桶数量是另一个表的分桶数量的整倍数
4- 分桶列 必须 是 join的ON条件的列
5- 必须建立在Map Join场景中(中型表是小表的3倍, 此时分至少3个桶)
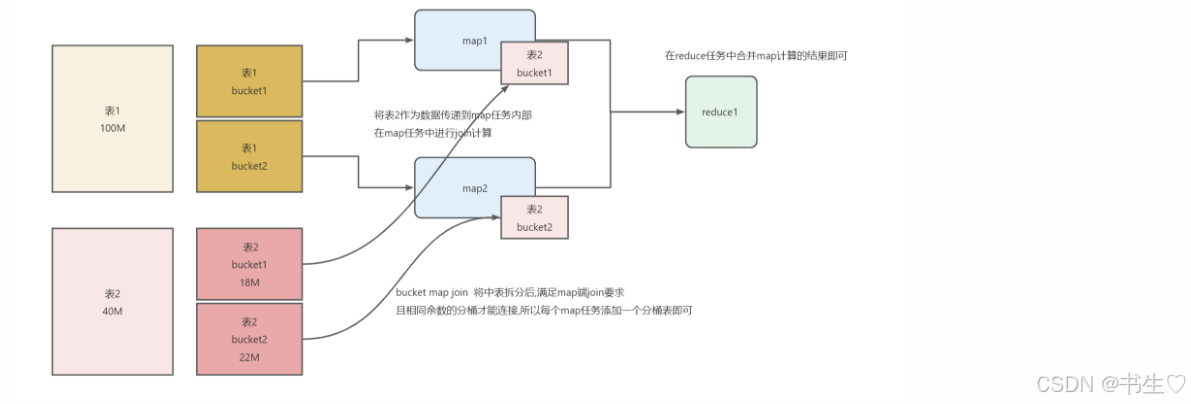
Bucket Map Join 优化 流程图
原理图–方便理解
3.3 SMB Join 优化
这个优化适用于我们的大表和大表进行关联。
-- 使用条件:
-- 1- 两个表必须都是分桶表
-- 2- 开启 SMB Join 支持:
set hive.auto.convert.sortmerge.join; -- 默认false
set hive.optimize.bucketmapjoin.sortedmerge ;-- 默认false
set hive.auto.convert.sortmerge.join.noconditionaltask;-- Hive 0.13.0默认开启
-- 3- 两个表的分桶的数量是一致的
-- 4- 分桶列 必须是 join的 on条件的列, 同时必须保证按照分桶列进行排序操作
-- 开启强制排序
set hive.enforce.sorting; -- hive2.x移除 默认true
-- 在建分桶表使用: 必须使用sorted by()
-- 5- 应用在Bucket Map Join 场景中
-- 开启 bucket map join
set hive.optimize.bucketmapjoin ; --默认false
[外链图片转存中…(img-y3XU0ivK-1719551256849)]
注意在我们的开发中
事实表 + 低基数的维度表 进行关联: Map Join 优化
事实表 + 高基数的维度表 进行关联: Bucket Map Join 优化
事实表 + 事实表 进行关联: SMB Join 优化(相对使用最少, 因为条件过于苛刻, 而且对资源消耗过大, 如果资源不够, 运行效率低于原始Join方案)
4. Hive索引
4. 1什么是索引
索引的定义:
-
关系型数据库中的索引:
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。一般是建立在主键上的。 -
关系型数据库中的索引:
hive中的索引功能是有限的,hive中没有关系数据库中主键的概念,但是还是可以对某一些字段建立索引。
Hive索引的目标是提高对表的某些列进行查询查找的速度。如果没有索引,则使用类似于“WHERE tab1.col1 = 10”这样的谓词进行查询’加载整个表或分区并处理所有行。但是如果col1存在索引,那么只需要加载和处理文件的一部分。
4.2 索引的作用
- 提高检索效率:
索引可以对数据库表中的一列或多列的值进行排序,形成一个单独的、物理的存储结构。
类似于图书的目录,索引允许数据库系统快速定位到所需的数据,而不必全表扫描,从而大大提高了检索效率。
在数据量庞大的情况下,使用索引可以显著减少查询时间,提高系统响应速度。 - 优化系统性能:
通过索引,数据库系统可以减少磁盘I/O操作,因为索引通常存储在内存中,可以快速访问。
索引将数据进行结构化的存储和管理,有助于减少系统的存储空间和访问时间。
优化索引的使用可以进一步提高系统的性能和响应速度,提升用户的使用体验。
4.3 Hive索引原理
Hive索引原理:
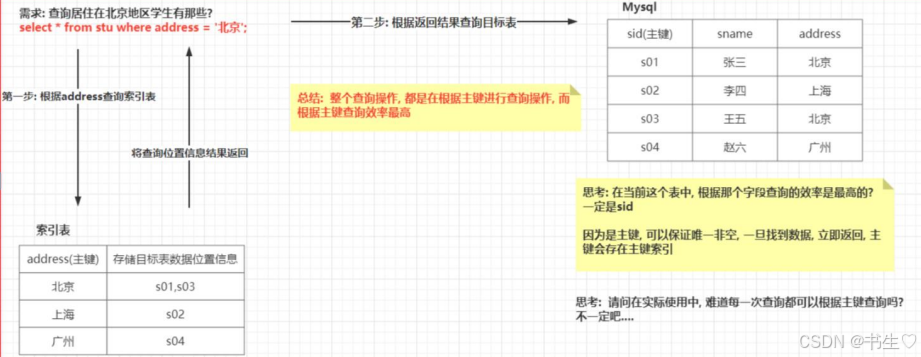
- 在指定列上建立索引,生成一张索引表(Hive的一张物理表),记录以下三个字段:索引列的值、该值对应的HDFS文件路径、该值在文件中的偏移量
- 在执行索引字段查询时候,首先额外生成一个MapReduce job,根据对索引列的过滤条件,从索引表中过滤出索引列的值对应的hdfs文件路径及偏移量,输出到hdfs上的一个文件中,然后根据这些文件中的 hdfs路径和偏移量,筛选原始input文件,生成新的split,作为整个job的split,达到不用全表扫描的目的。
简单点来说就是,我们在将一个字段设置为索引的时候,我们会将这个字段的值以及对应文件在hdfs的位置和文件的偏移量存在一个临时表中。通过这个偏移量就可以直接查到我们对应数据的那一行。所以速度会比较快!!!
缺点:
hive原始索引不会自动更新,每次表中数据发生变化后, 都是需要手动重建索引操作, 比较耗费时间和资源, 整体提升性能一般
4.4 ORC相关索引
什么是ORC:
ORC的全称是(Optimized Record Columnar),是列式存储格式,使用ORC文件格式可以提高hive读、写和处理数据的能力。
在ORC格式的hive表中,记录首先会被横向的切分为多个stripes,然后在每一个stripe内数据以列为单位进行存储,所有列的内容都保存在同一个文件中。每个stripe的默认大小为256MB,相对于之前RCFile每个4MB而言,更大的stripe使ORC的数据读取更加高效。
ORC在RCFile的基础上进行了一定的改进,所以与RCFile相比,具有以下一些优势:
- ORC中的特定的序列化与反序列化操作可以使ORC file writer根据数据类型进行写出。
- 提供了多种RCFile中没有的indexes,这些indexes可以使ORC的reader很快的读到需要的数据,并且跳过无用数据,这使得ORC文件中的数据可以很快的得到访问。
- 由于ORC file writer可以根据数据类型进行写出,所以ORC可以支持复杂的数据结构(比如Map等)。
- 除了上面三个理论上就具有的优势之外,ORC的具体实现上还有一些其他的优势,比如ORC的stripe默认大小更大,为ORC writer提供了一个memory manager来管理内存使用情况。
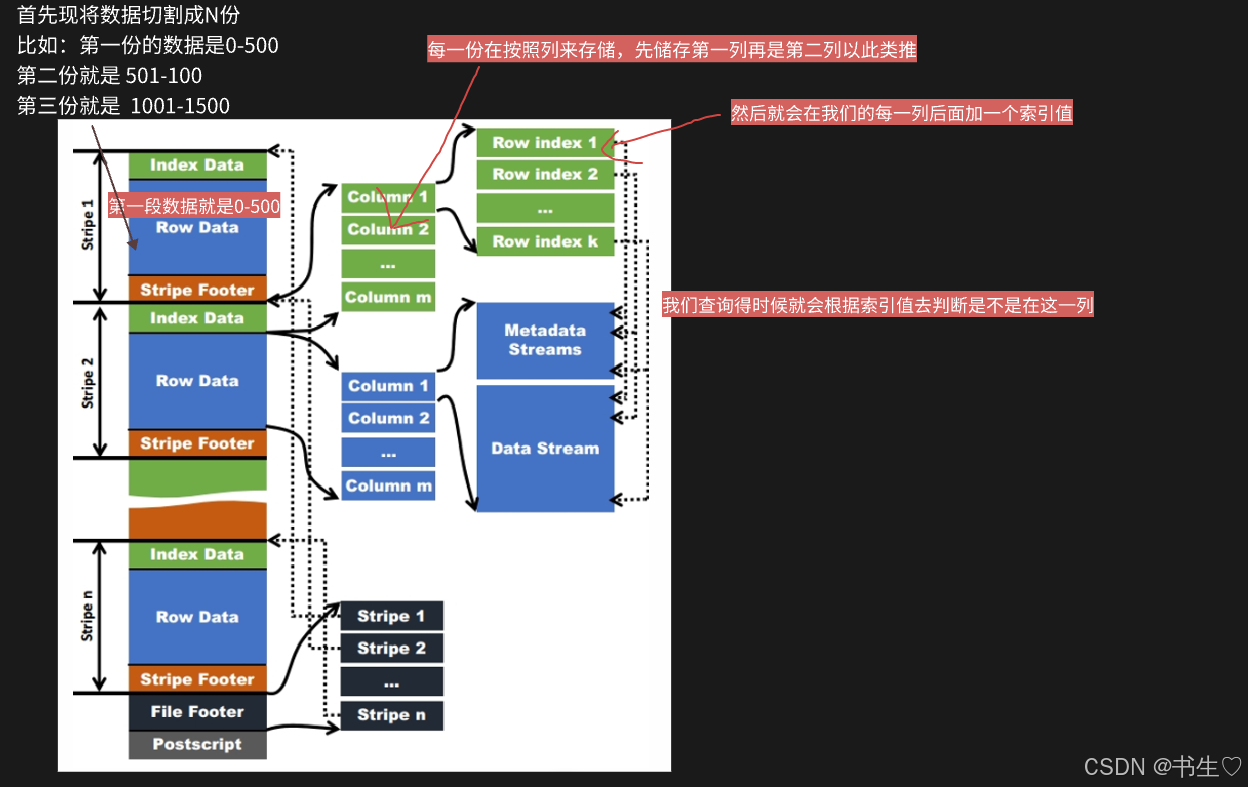
索引的原理步骤
- 首先现将数据切割成N份
比如:第一份的数据是0-500
第二份就是 501-100
第三份就是 1001-1500 - 每一份在按照列来存储,先储存第一列再是第二列以此类推
- 然后就会在我们的每一列后面加一个索引值
- 我们查询得时就会根据索引值去判断是不是在这一列
4.4.1 Row Group Index索引
row group index: 行组索引 (又叫最小最大索引)
前提条件
- 要求表的存储类型为ORC存储格式
- 在创建表的时候, 必须开启 row group index 索引支持 ‘orc.create.index’=‘true’
- 在插入数据的时候, 必须保证需求进行索引列, 按序插入数据
适用于什么样子数据?
数值类型的, 并且对数值类型进行 > < >= <=操作
插入数据到ORC表后, 会自动进行划分为多个script片段, 每个片段内部, 会保存着每个字段的最小, 最大值, 这样, 当执行查询 > < = 的条件筛选操作的时候, 根据最小最大值锁定相关的script片段, 从而减少数据扫描量, 提升效率
注意:
我们如果要使用这个索引就要在建表的时候添加相关语句
CREATE TABLE lxw1234_orc2 (字段列表 ....) stored AS ORC
TBLPROPERTIES (
'orc.compress'='SNAPPY',
-- 开启行组索引
'orc.create.index'='true'
)
4.4.2 Bloom Fliter Index索引
bloom filter index (布隆过滤索引): 布隆过滤器
前提条件
要求表的存储类型为 ORC存储方案
在建表的时候, 必须设置为那些列构建布隆索引
仅能适合于等值过滤查询操作
适用于什么样子的数据呢?
数据的值是确定的 例如:我们的数据是唯一数据的“北京”,‘爱好’等等。
在开启布隆过滤索引后, 可以针对某个列, 或者某几列来建立索引, 构建索引后, 会将这一列的数据的值存储在对应script片段的索引信息中, 这样当进行 等值查询的时候, 首先会到每一个script片段的索引中, 判断是否有这个值, 如果没有, 直接跳过script, 从而减少数据扫描量, 提升效率
注意:
我们如果要使用这个索引就要在建表的时候添加相关语句
CREATE TABLE lxw1234_orc2 (字段列表....)
stored AS ORC
TBLPROPERTIES (
'orc.compress'='SNAPPY',
-- 开启 行组索引 (可选的, 支持全部都打开, 也可以仅开启一个)
'orc.create.index'='true',
-- pcid字段开启BloomFilter索引
'orc.bloom.filter.columns'='pcid,字段2,字段3...'
)
4.5 什么是时候使用什么索引
1- 对于行组索引: 我们建议只要数据存储格式为ORC, 建议将这种索引全部打开, 至于导入数据的时候, 如果能保证有序, 那最好, 如果保证不了, 也无所谓, 大不了这个索引的效率不是特别好
2- 对于布隆过滤索引: 建议将后续会大量的用于等值连接的操作字段, 建立成布隆索引, 比如说: JOIN的字段 经常在where后面出现的等值连接字段
5. 数据倾斜
数据倾斜(Data Imbalance)或称为类别不平衡(Class Imbalance),是指在分类问题中,不同类别的样本数量存在显著差异的情况。具体来说,当某个类别的样本数量远大于其他类别时,就称该数据集存在数据倾斜问题。
5.1 Join数据倾斜
我们在进行一些SQL语句的时候, 描述过reduce 端Join的问题, 其中就包含reduce端Join存在数据倾斜的问题。
比如按照某个分区就会发现,我们的某一个分区的数据可能会过多,这就会导致数据倾斜。
解决方法一:使用Join 优化
Map Join (默认开启),
Bucket Map Join(默认关闭,条件是分桶表,且数量是倍数关系) ,
SMB Join(条件是分桶表,且桶数量必须一致,插入数据的时候要排序)
注意:
通过 Map Join,Bucket Map Join,SMB Join 来解决数据倾斜, 但是 这种操作是存在使用条件的, 如果无法满足这些条件, 无法使用 这种处理方案
解决方法二(运行期):将产生倾斜的数据,单独放到一个MR中处理,然后在和之前的MR进行合并
问题:我们怎么知道那些数据是过多的呢?如何找到那些存在倾斜的key呢? 特点: 这个key数据有很多
- 在执行MR的时候, 会动态统计每一个 k2的值出现重复的次数, 当这个重复的次数达到一定的阈值后, 认为当前这个k2的数据存在数据倾斜, 自动将其剔除, 交由给一个单独的MR来处理即可,两个MR处理完成后, 将结果基于union all 合并在一起即可
我们可以设置一个门阀值,一旦数据超过这个值就属于数据倾斜。
set hive.optimize.skewjoin=true; -- 开启运行期处理倾斜参数默认false
set hive.skewjoin.key=100000; -- 阈值, 此参数在实际生产环境中, 需要调整在一个合理的值(否则极易导致大量的key都是倾斜的),默认100000
我们怎么去设计这个门阀值呢?
在开发中,我们一般选择超过正常值得3-5 倍才算是倾斜
适用于: 并不清楚那个key容易产生倾斜, 此时交由系统来动态检测
解决方法三(编译期):将产生倾斜的数据,单独放到一个MR中处理,然后在和之前的MR进行合并
思路1: 在创建这个表的时候, 我们就可以预知到后续插入到这个表中数据, 那些key的值会产生倾斜, 在建表的时候, 将其提前配置设置好即可, 在后续运行的时候, 程序会自动将设置的key的数据单独找一个MR来进行处理即可, 处理完成后, 再和原有结果进行union all 合并操作
这个和上面的不同点在于 :
- 运行期是不知道那些数据会产生倾斜,让系统自己去识别,我们只需要设置门阀值。
- 编译期是预知到后续插入到这个表中数据, 那些key的值会产生倾斜,提前将这些值放到其他的Mr中。
设置编译期处理倾斜的设置
set hive.optimize.skewjoin.compiletime=true; -- 开启编译期处理倾斜参数
CREATE TABLE list_bucket_single (key STRING, value STRING)
-- 倾斜的字段和需要拆分的key值
SKEWED BY (key) ON (1,5,6)
-- 为倾斜值创建子目录单独存放
[STORED AS DIRECTORIES];
思路2: 大量的key可以拼接rand()
实操2: 举例: 如果大量相同的男,可以拼接随机数: concat(‘男’,rand())
适用于: 提前知道那些key存在倾斜。
底层union的优化
不管是运行期 还是编译期的join倾斜解决, 最终都会运行多个MR, 将多个MR结果通过union all 进行汇总, union all也是需要单独一个MR来处理
我们可以通过设置参数
开启此参数即可:
set hive.optimize.union.remove=true;
5.2 group by 数据倾斜
假设我们在进行group by 进行分组的时候,是通过男女性别分组,一旦出现男生数量远远大于女生的数量就会发生数据的倾斜。
解决方案一:提前聚合
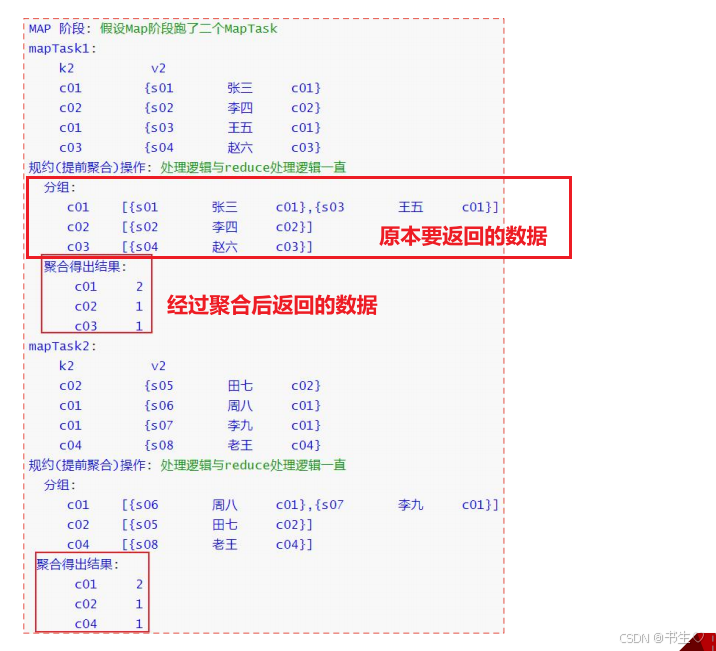
MR的 combiner(规约, 提前聚合) 减少数据达到reduce数量, 从而减轻倾斜问题
默认开启 set hive.map.aggr=true;
假设我们有一个表,需要在map返回500条数据到Reduce中,但是这其中有大量的数据是可以进行计算的,并且我们的结果就是需要这些计算,我们就可以在map的阶段先进行一次聚合,将数据量减少在给到Reduce进行数据的合并。
解决方案二:负载均衡:
负载均衡的解决方案(需要运行两个MR来处理) (大combiner方案)
默认关闭,如果需要,手动开启
set hive.groupby.skewindata=true;
怎么进行2个MR操作呢?
[外链图片转存中…(img-rDovwNNW-1719551256850)]
第一个MR执行完成了,每个reduce都接收到数据:
mapTask执行完成后, 在进行分发数据到达reduce, 默认情况下将相同key的数据发往同一个reduce, 目前采用方案为随机分发, 保证每一个reduce拿到相等数量的数据信息(负载过程, 让每一个reduce接收到相同数量的数据)
第二个MR进行处理:严格按照相同key发往同一个reduce
负载均衡解决:
第一个MR执行完成了, 随机打乱分配,假设每个reduce都接收到四条数据, 自然也就不存在数据倾斜的问题了
第二个MR进行处理: 严格按照相同key发往同一个reduce
注意:更能彻底解决数据倾斜问题, 因为其处理数据范围更大, 整个整个数据集来处理
5.3 怎么发现数据倾斜
倾斜发生后, 出现的问题, 程序迟迟无法结束, 或者说翻译的MR中reduceTask有多个, 大部分的reduceTask都执行完成了, 只有其中一个或者几个没有执行完成, 此时认为发生了数据倾斜。
查看方式:
- 通过Yarn查看(运行过程中) 或者 jobhistory查看(已经结束的程序) (此操作, 只能在本地演示查看, 云端环境没有开启yarn端口, 无法查看的), 我们需要观察每个reduceTask执行时间, 如果发现其中一个或者几个reduce执行时间, 远远大于其他的reduceTask执行时间, 那么说明存在数据倾斜的问题
6.列裁剪和分区裁剪
-
列裁剪(在列式存储中效果最明显)
只读取我们指定的列,其余列不查看,提高查询效率,减小检索范围
Hive在读数据的时候,可以只读取查询中所需要用到的列,而忽略其他列。例如,若有以下查询: 在实施此项查询中,Q表有5列(a,b,c,d,e),Hive只读取查询逻辑中真实需要的3列a、b、e, 而忽略列c,d;这样做节省了读取开销,中间表存储开销和数据整合开销。 注意:Hive自动执行这种裁剪优化 裁剪对应的参数项为: --默认值为真 在hive 2.x中无需在配置了, 直接为固定值: true hive.optimize.cp=true; -
分区裁剪
只读取我们指定的分区数据,其余分区不查看,提高查询效率,减小检索范围
在join中必须书写on 尽量不要使用where 如果一定要使用在连接之前使用where
执行查询SQL的时候, 能在join之前提前过滤的操作, 一定要提前过滤, 不要在join后进行过滤操作 如果操作的表是一张分区表, 那么建议一定要带上分区字段, 以减少扫描的数据量, 从而提升效率, 例如,若有以下查询: select * from t1 join t2 on t1.id = t2.id and t1.dt = '2021-12-31'; (dt是分区字段) select * from (select * from t1 where dt = '2021-12-31') t1 join t2 on t1.id = t2.id; 注意:Hive自动执行这种裁剪优化 分区参数为: -- 默认为就是true (在hive 2.x中无需在配置了, 直接为固定值: true) hive.optimize.pruner=true
7. Fetch抓取机制
- 功能:在执行sql的时候,能不走MapReduce程序处理就尽量不走MapReduce程序处理。
- 尽量直接去操作数据文件。
- 设置: hive.fetch.task.conversion= more。 默认设置
--在下述4种情况下 sql不走mr程序
-- more 模式下如下内容不需要走mr程序
--全局查找
select * from student;
--字段查找
select num,name from student;
--limit 查找
select num,name from student limit 2;
-- 简单的条件过滤
select num,name from student where num > 2;
-- minimal 模式下如下内容不需要走mr程序
--全局查找
select * from student;
--字段查找
select num,name from student;
--limit 查找
select num,name from student limit 2;
-- none 模式下所有的操作都需要走mr程序
8. mapreduce本地模式
-
功能:如果非要执行MapReduce程序,能够本地执行的,尽量不提交yarn上执行。
-
默认是关闭的。意味着只要走MapReduce就提交yarn执行。
mapreduce.framework.name = local 本地模式
mapreduce.framework.name = yarn 集群模式
-
Hive提供了一个参数,自动切换MapReduce程序为本地模式,如果不满足条件,就执行yarn模式。
开启本地模式后要注意: 我们满足如下条件后会走本地模式, 但是本地服务器中资源一定足够么? 不一定
有时候看上去还有空间但是空间已经分配给yarn了
set hive.exec.mode.local.auto = true;
--3个条件必须都满足 自动切换本地模式
The total input size of the job is lower than: hive.exec.mode.local.auto.inputbytes.max (128MB by default) --数据量小于128M
The total number of map-tasks is less than: hive.exec.mode.local.auto.tasks.max (4 by default) --maptask个数少于4个
The total number of reduce tasks required is 1 or 0. --reducetask个数是0 或者 1















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









