







前言:
💞💞大家好,我是书生♡,今天主要和大家分享一下我们在进行项目的时候,数据是如何进行数据的传输也就是说怎么从mysql或者是SQLserver数据库将数据传输到hive数仓中!Data X怎么使用!数据的同步方式!,希望对大家有所帮助。感谢大家关注点赞。
💞💞前路漫漫,希望大家坚持下去,不忘初心,成为一名优秀的程序员
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬

目录
1. 数仓工具 Data X的使用
1.1 Data X的介绍
定义: DataX 是阿里推出的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。 将DataX安装好之后, 仅需要配置Json的采集文件即可实现数据的同步。
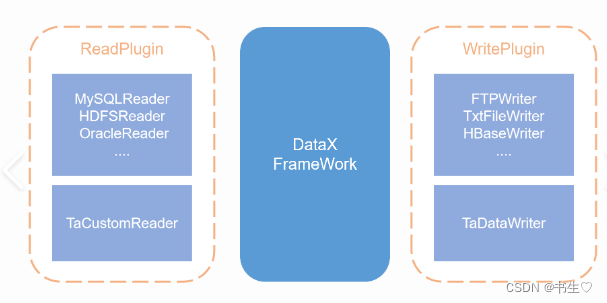
DataX的组成部分:
- Reader : Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer:Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。

DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入 。
DataX的国内的开源的地址: https://gitee.com/mirrors/DataX?from=giteesearch
1.2 Data X的使用
1.2.0 准备条件
1) 在mysql创建test数据库,在此数据库下创建student表,然后往表中插入数据。
-- 建库
create database if not exists test character set utf8;
-- 使用库
use test;
-- 建表
create table student(id int,name varchar(20),age int,createtime timestamp );
-- 插入数据
insert into `student` (`id`, `name`, `age`, `createtime`) values('1','zhangsan','18','2021-05-10 18:10:00');
insert into `student` (`id`, `name`, `age`, `createtime`) values('2','lisi','28','2021-05-10 19:10:00');
insert into `student` (`id`, `name`, `age`, `createtime`) values('3','wangwu','38','2021-05-10 20:10:00');
-- 验证数据
select id,name,age,createtime from student where age <30;
因为数据要存储在hdfs上。所以我们要在hdfs上创建一个文件夹用来存放我们的数据。
使用finalshell等工具
hdfs dfs -mkdir -p /test/datax/mysql2hdfs -- 在hdfs上创建一个 test/datax/mysql2hdfs的多级文件夹
1.2.1 MySQL数据写入hdfs
1.2.1.1 命令写入hdfs
我们在服务器上安装好了datax以后。
进入到datax的目录下:
通过命令查看配置模板。我们主要是通过执行模版将数据进行传输
cd /export/server/datax -- 进入该目录下
python bin/datax.py -r mysqlreader -w hdfswriter -- 获取执行的json格式
模版如下:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
当我们想要通过命令进行数据的传输,首先要创建json文件,将上面模版的内容复制到文件中,填入信息。最后执行文件。
- 要在datax目录下的job目录下创建一个json文件,命名为 mysql2hdfs.json
cd /export/server/datax/job
vim mysql2hdfs.json -- vim 会帮我们自动创建文件,在文件不存在的情况下
# 将模板内容复制到该文件中
选择该文件后,右键该文件,选择文本编辑器为外部文本编辑器就是说使用Windows的编辑器打开(这里推荐使用Notepad++)
打开文件后,编辑修改文件,按照你的数据库信息,具体信息如下:

然后返回datax目录下执行该文件
cd /export/server/datax/
python bin/datax.py job/mysql2hdfs.json -- 刚刚创建的json文件
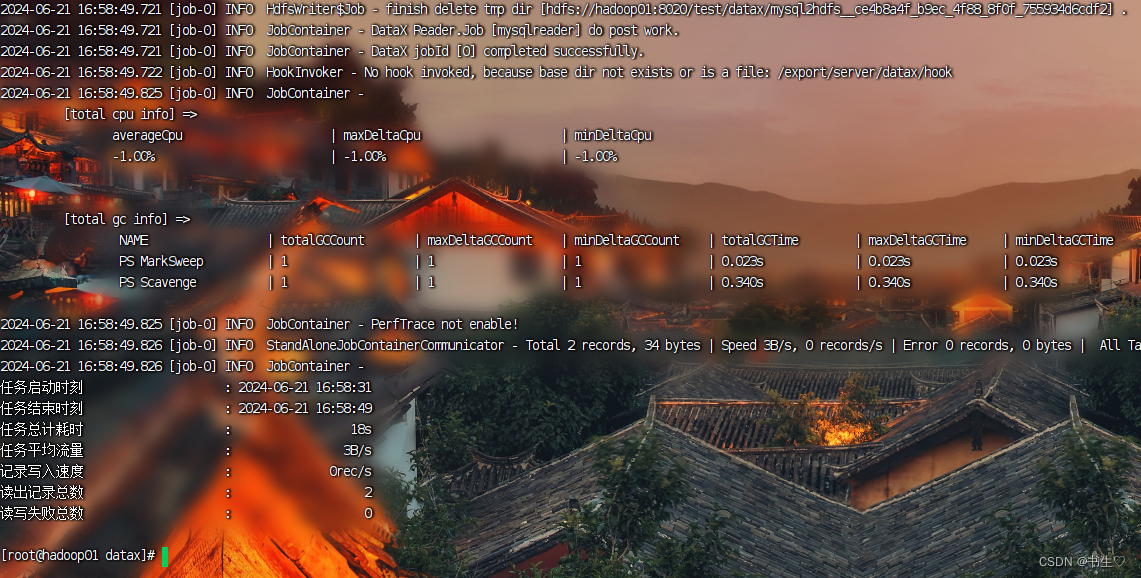
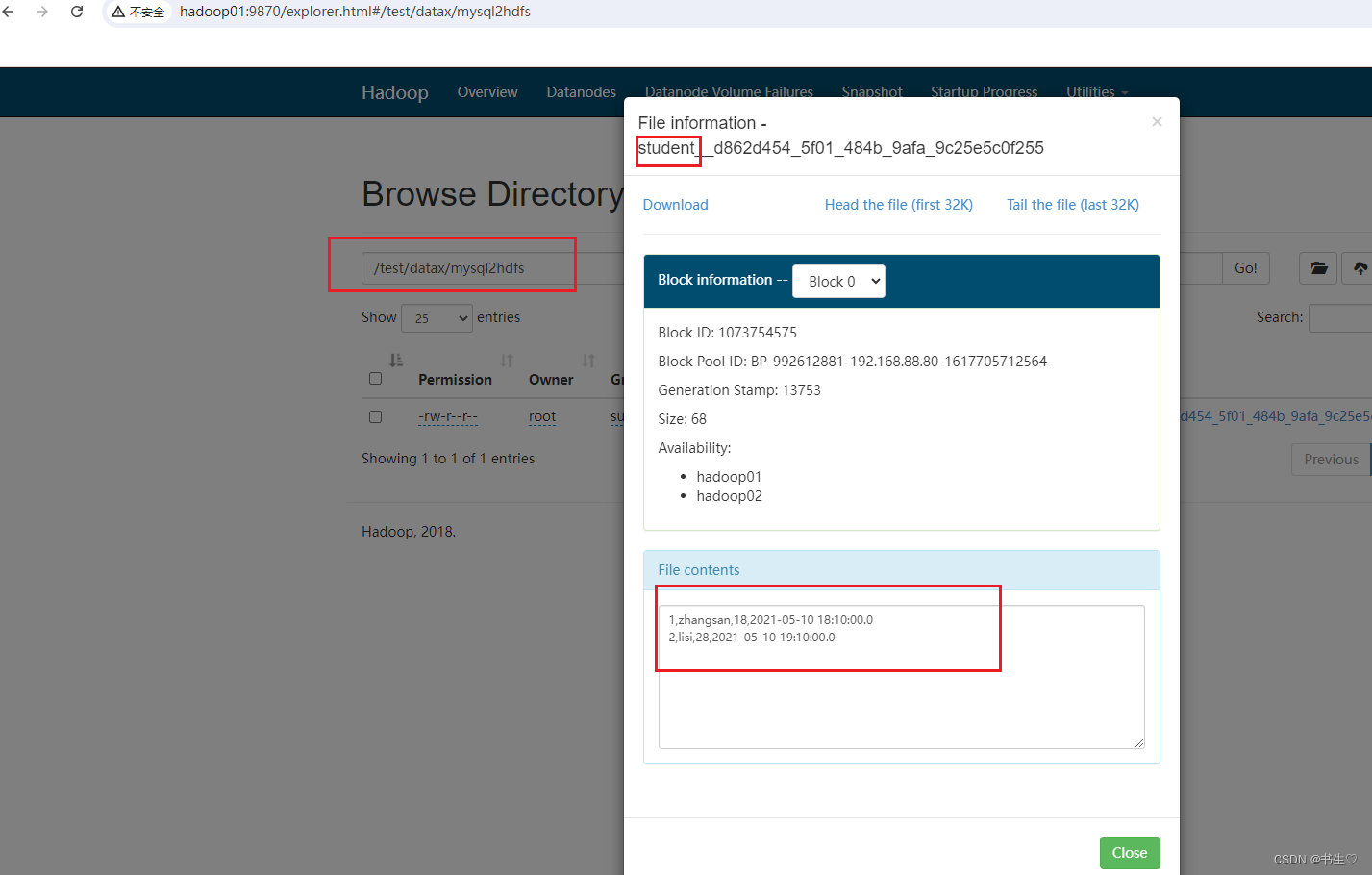
最后查看hdfs,检验是否导入成功!
1.2.1.2 官方模版写入hdfs
我们在自己修改文件的时候很容易出现错误,因此我们使用另外一种方法。使用官方给我们写好的模版。
通过官方链接,查看所有配置模板
链接: https://gitee.com/mirrors/DataX/tree/master
如果实在没网的情况下,那么可以先在有网的地方下载到本地。
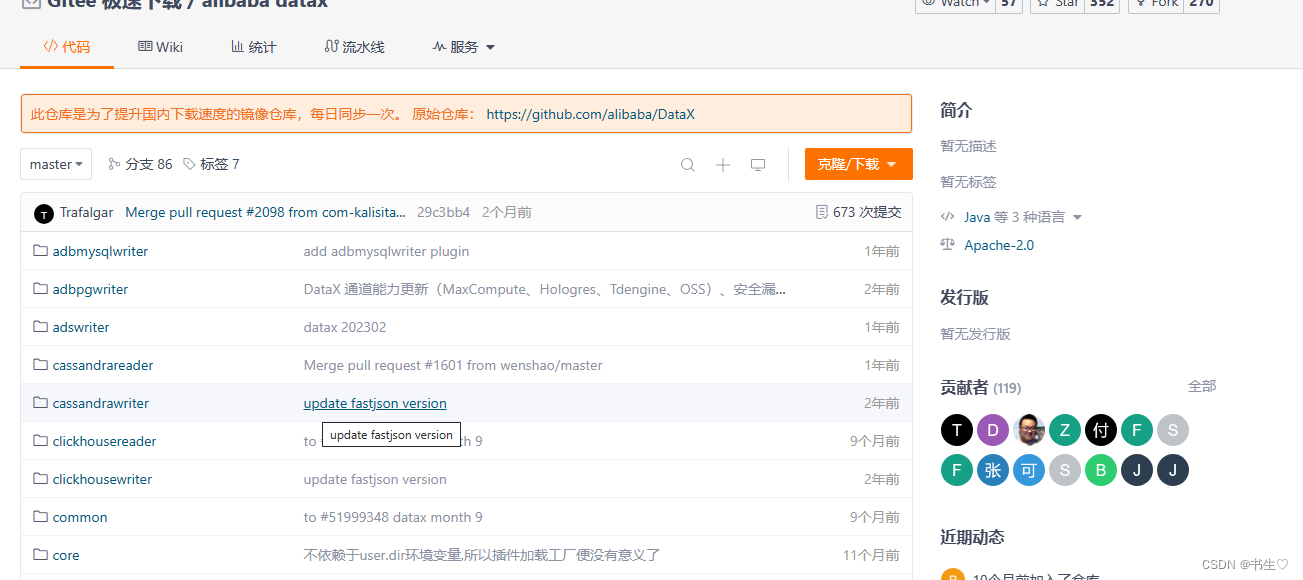
进入之后就是这样样子,我们是从MySQL导入到hdfs中,那我们就要找到MySQLReader 和hdfsWriter 的模版配置文件。
 hdfs的reader模块 ,注意mysql中只需要复制reader中的就可以了
hdfs的reader模块 ,注意mysql中只需要复制reader中的就可以了
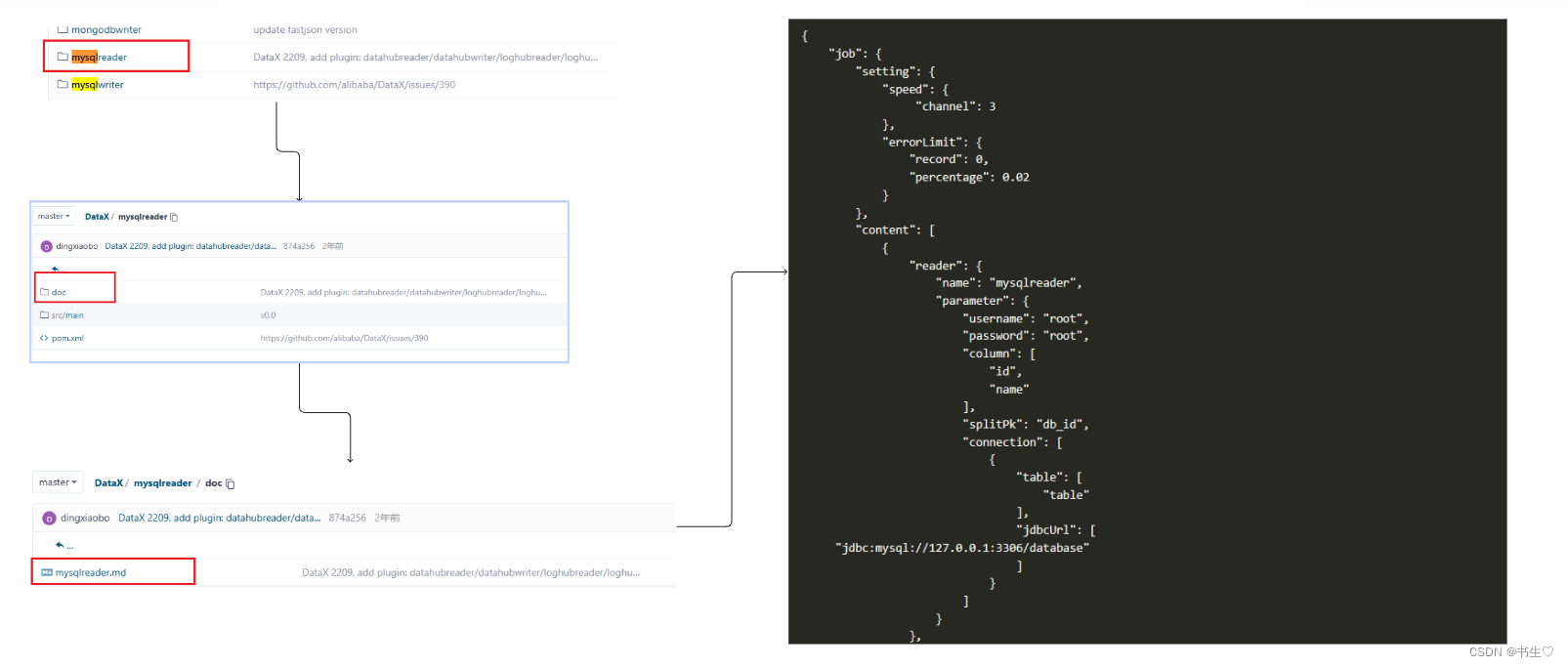
我们在选择mysql的模板的的时候有两种选择,官方配别了两个,选择其中一个即可(推荐第二种)

hdfs的Writer模块 ,注意hdfs中只需要复制Writer中的就可以了
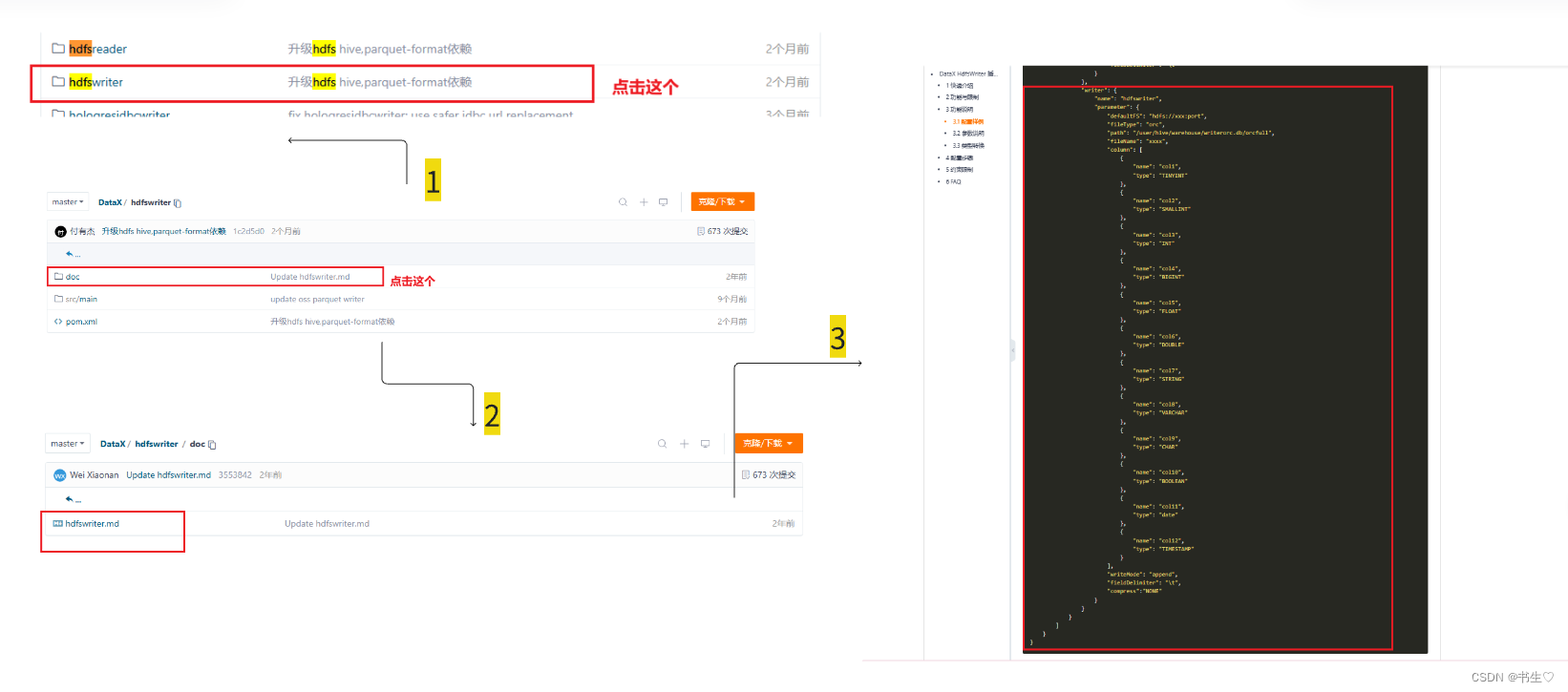
最后把写好的文件执行一遍就可以啦。
1.2.2 MySQL数据写入Hive
准备测试数据:
-- 1) 在mysql创建test数据库,在此数据库下创建user表,然后往表中插入数据。
drop database if exists test;
-- 建库
create database if not exists test character set utf8;
-- 使用库
use test;
-- 建表
create table user(id int,name varchar(20),age int,createtime timestamp );
-- 插入数据
insert into `user` (`id`, `name`, `age`, `createtime`) values('1','曹操','18','2021-05-10 18:10:00');
insert into `user` (`id`, `name`, `age`, `createtime`) values('2','刘备','28','2021-05-10 19:10:00');
insert into `user` (`id`, `name`, `age`, `createtime`) values('3','孙权','38','2021-05-10 20:10:00');
-- 验证数据
select id,name,age,createtime from user where age <30;
注意:Hive上设置的数据仓库的存储路径为:/user/hive/warehouse/库名.db/表名
建立测试数据库:test,
创建测试表:tb_user;
则对应数据存储目标位置为:/user/hive/warehouse/test.db/tb_user
创建对应的Hive的表
-- 建立测试数据库:test
create database if not exists test;
-- 使用库
use test;
-- 创建测试表:user
create table tb_user(
id int comment '编号',
name string comment '名称',
age int comment '年龄',
createtime string comment '创建时间'
) comment '测试表'
row format delimited fields terminated by ',';
-- 验证数据
select * from tb_user limit 10;
-- 查看表的存储路径
desc formatted test.tb_user;
-- 注意:对应表的存储路径为:hdfs://hadoop01:8020/user/hive/warehouse/test.db/tb_user
写入Hive和写入hdfs其实操作是一样的,因为和Hive就是在hdfs上存储的,只不过是文件的位置的不同。
因此我们只需要修改文件的hdfs的目录路径就可以了。
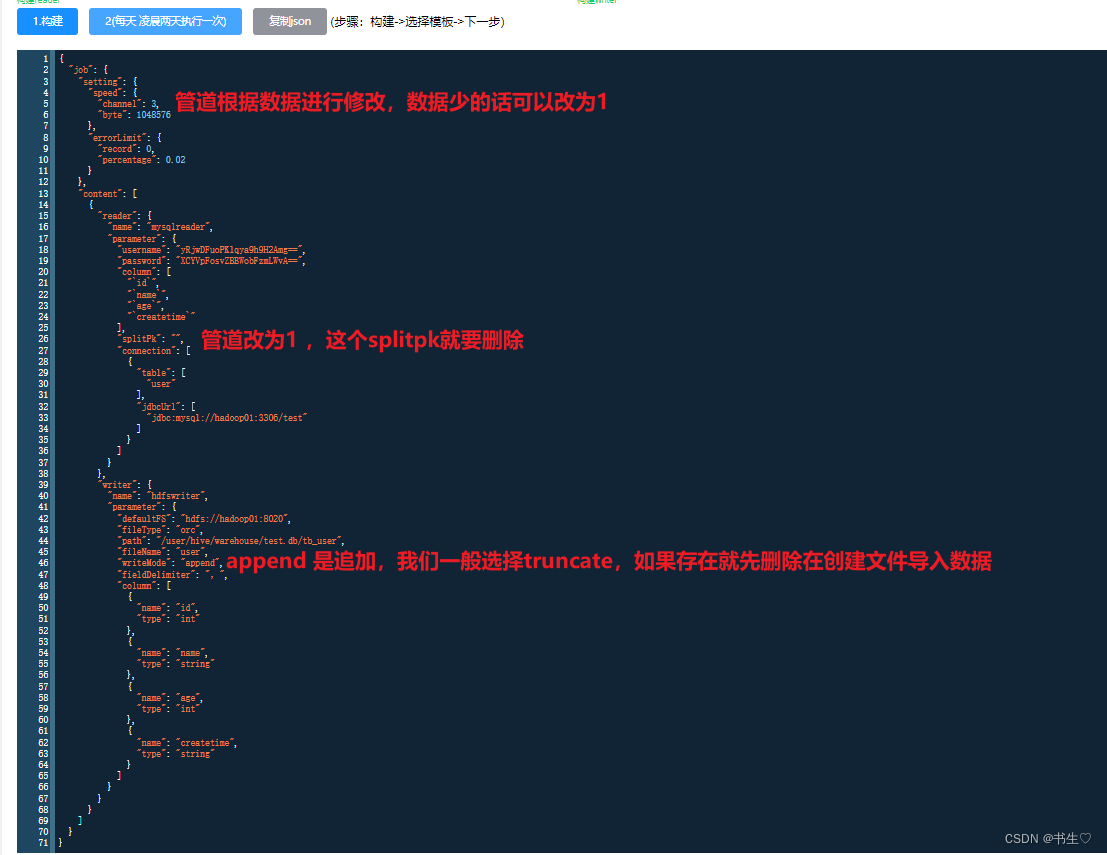
注意:写入hive时与写入hdfs的写入名称name都为hdfswriter。只是在写入hive时,为与hive表关联,在path参数后填写hive表在hdfs上的存储路径。以及保证存储格式和分隔符号与HIVE表保持一致!!!

执行的原理是一样的,最后去Hive的目录下查看是否创建成功们也可以通过sql语句进行Hive的语句查询。
1.3 Data X的web使用
我们再使用执行json配置的时候需要手写模版,容易产生错误。这里我们使用Data X web就可以解决这个问题。
DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。
启动Data X web需要通过命令自己启动。
[root@hadoop01 datax]# cd /export/server/datax-web-2.1.2
[root@hadoop01 datax-web-2.1.2]# ./bin/start-all.sh
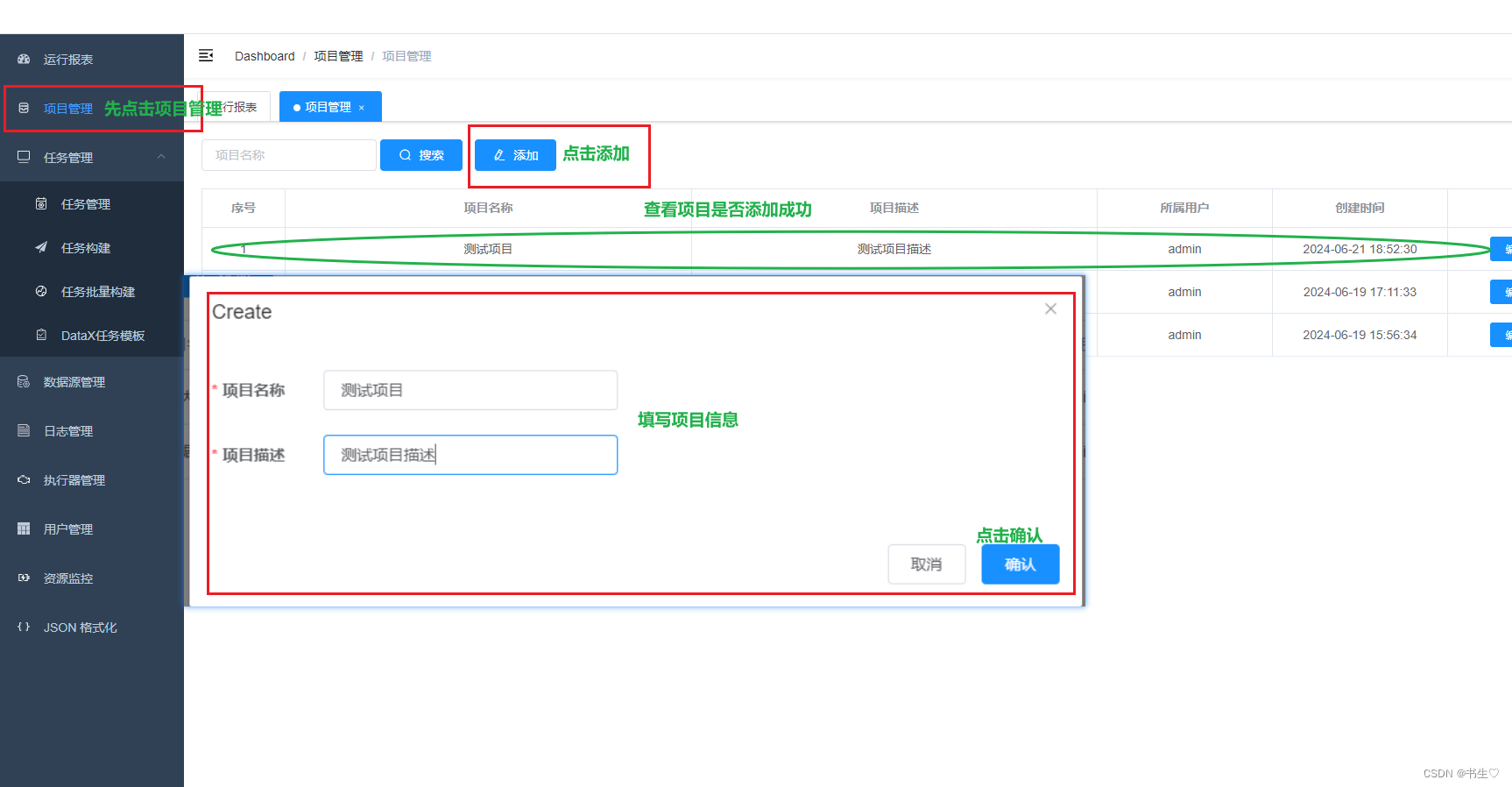
- 添加项目管理
项目管理只是让我们明确每一个任务归属于哪一个项目。
实例:
添加测试项目
- 创建数据源
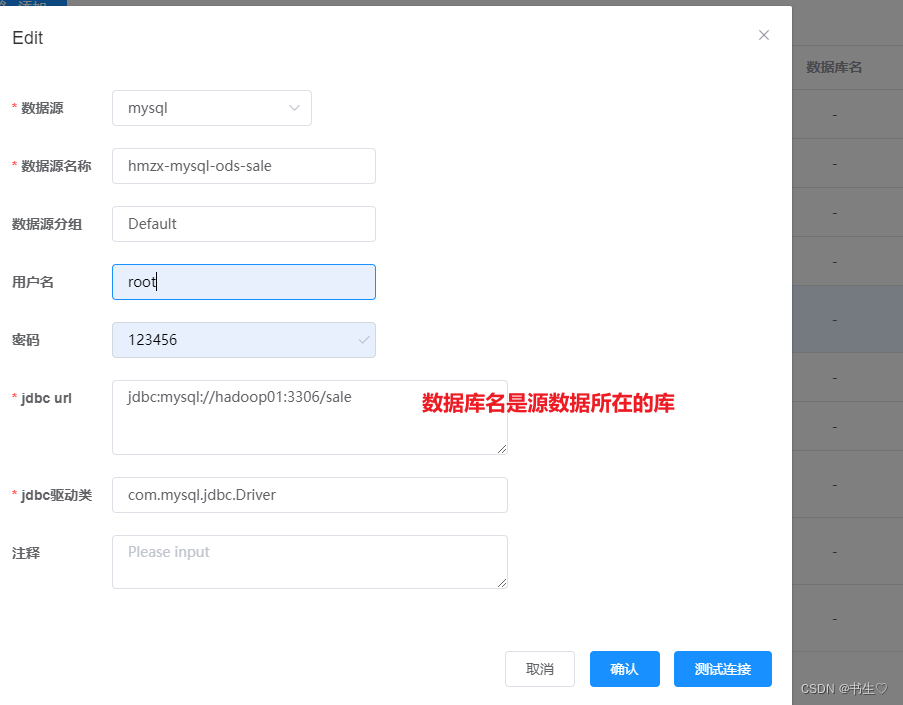
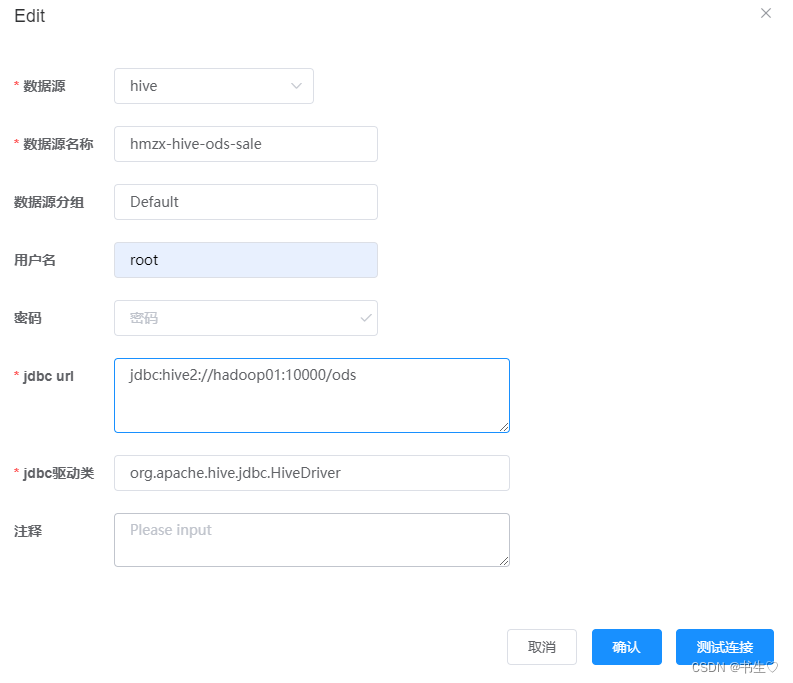
注意:在创建数据源之前,我们要保证数据库都连接成功并且MySQL中数据存在,并且Hive中对应的表已经创建完成。
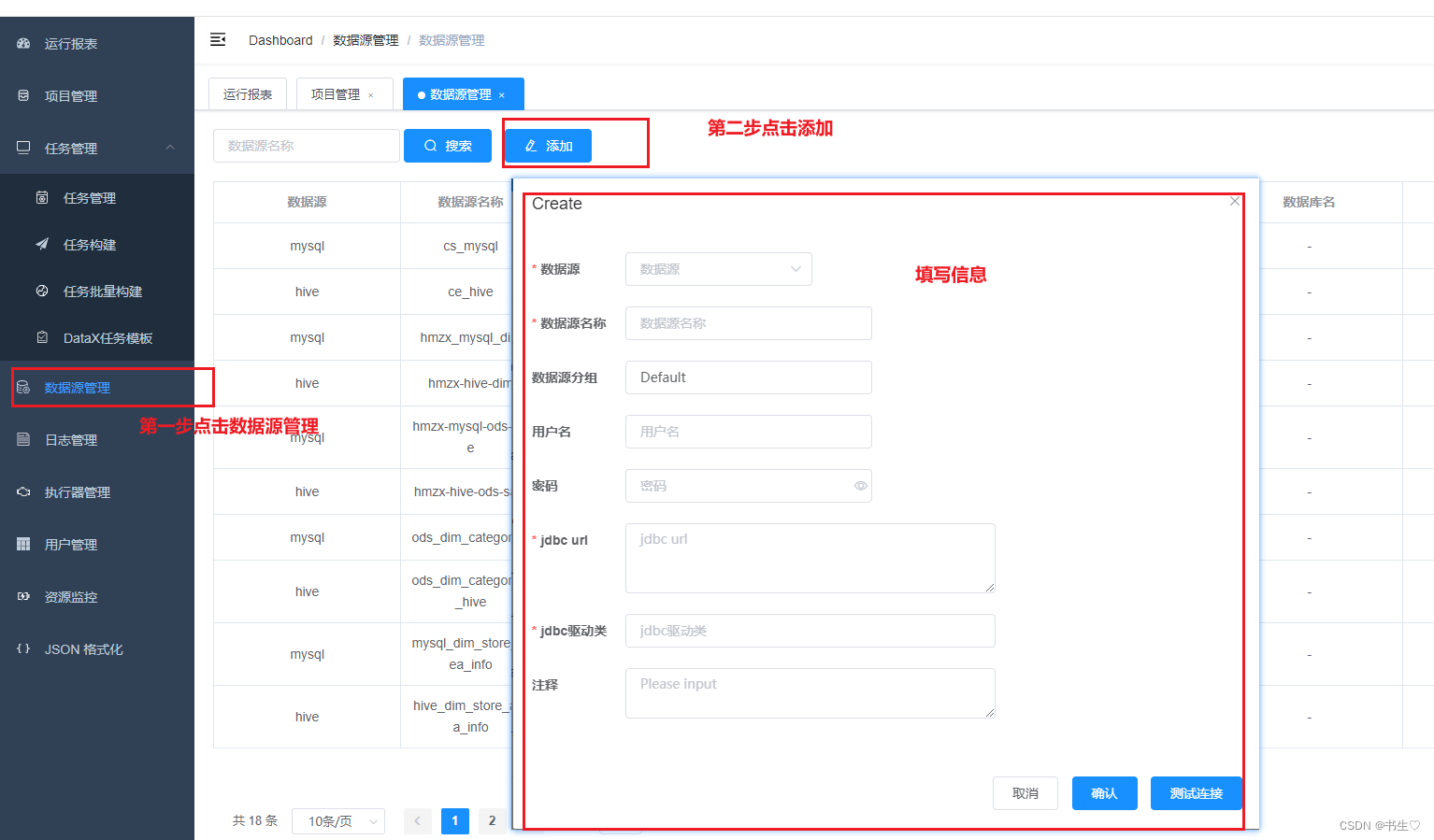
源数据管理我们要连接两个:一个是MySQL 一个是hive的,
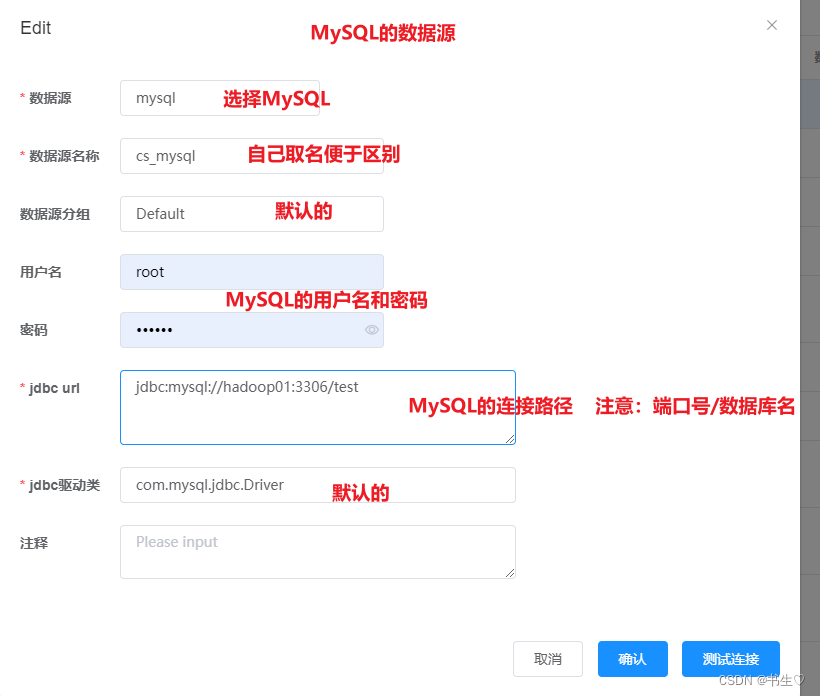
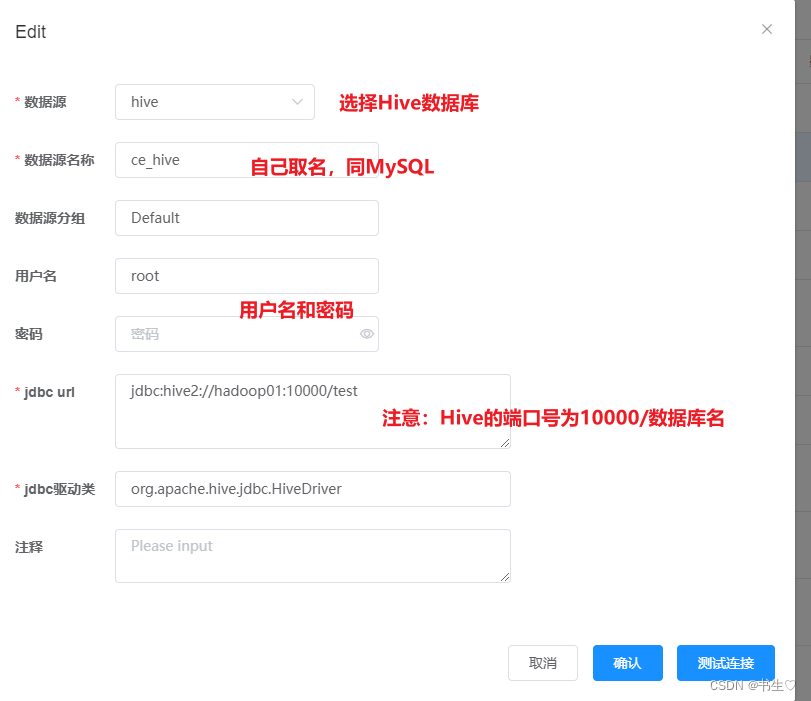
写完之后可以点击“连接测试” ,查看是否填写成功。
- 创建任务模版
任务模版是让我们定时执行文件的一种方式,可以指定具体的时间自动执行。
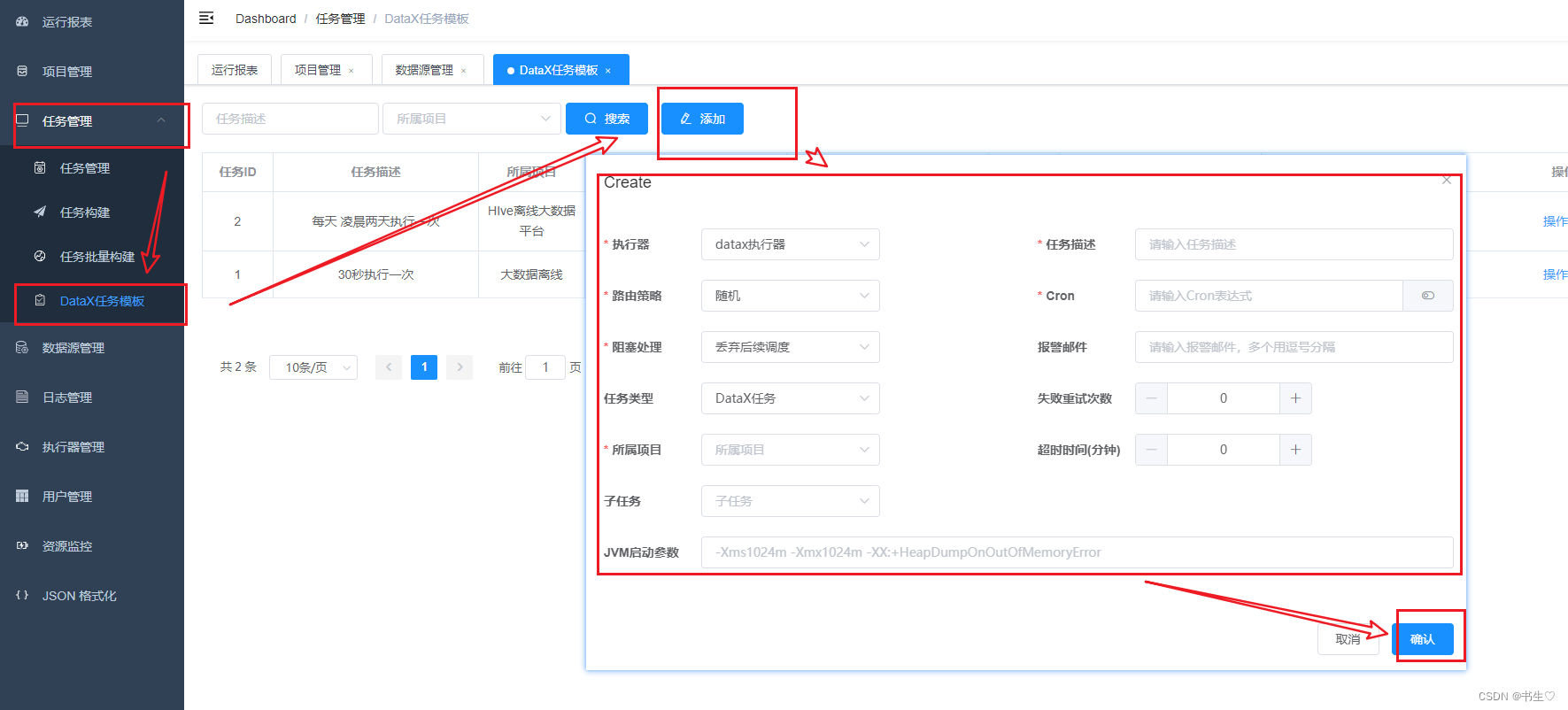
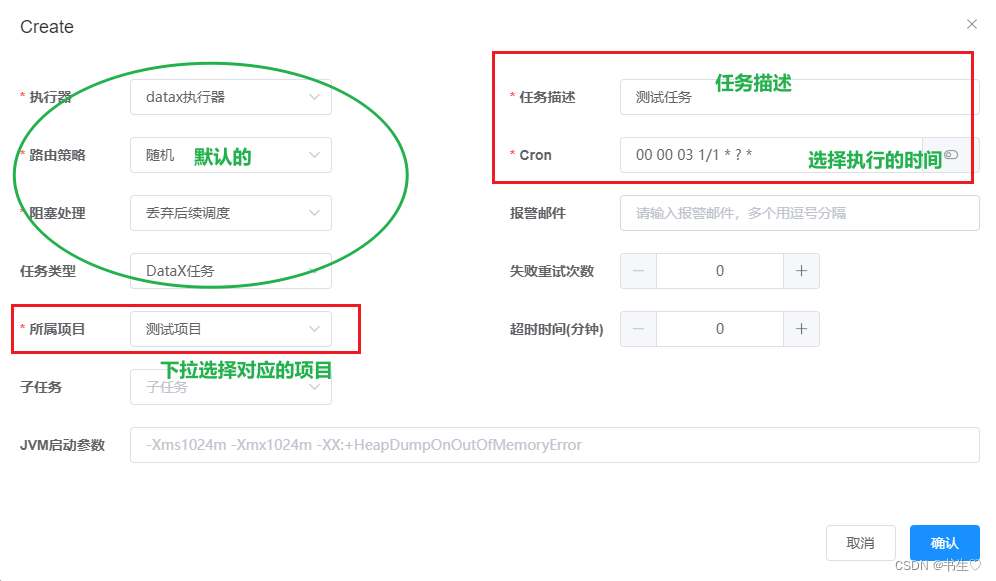
假设我们想要每天凌晨3点执行这些文件,那么分秒都应该设为00,小时选择03,天数选择循环。
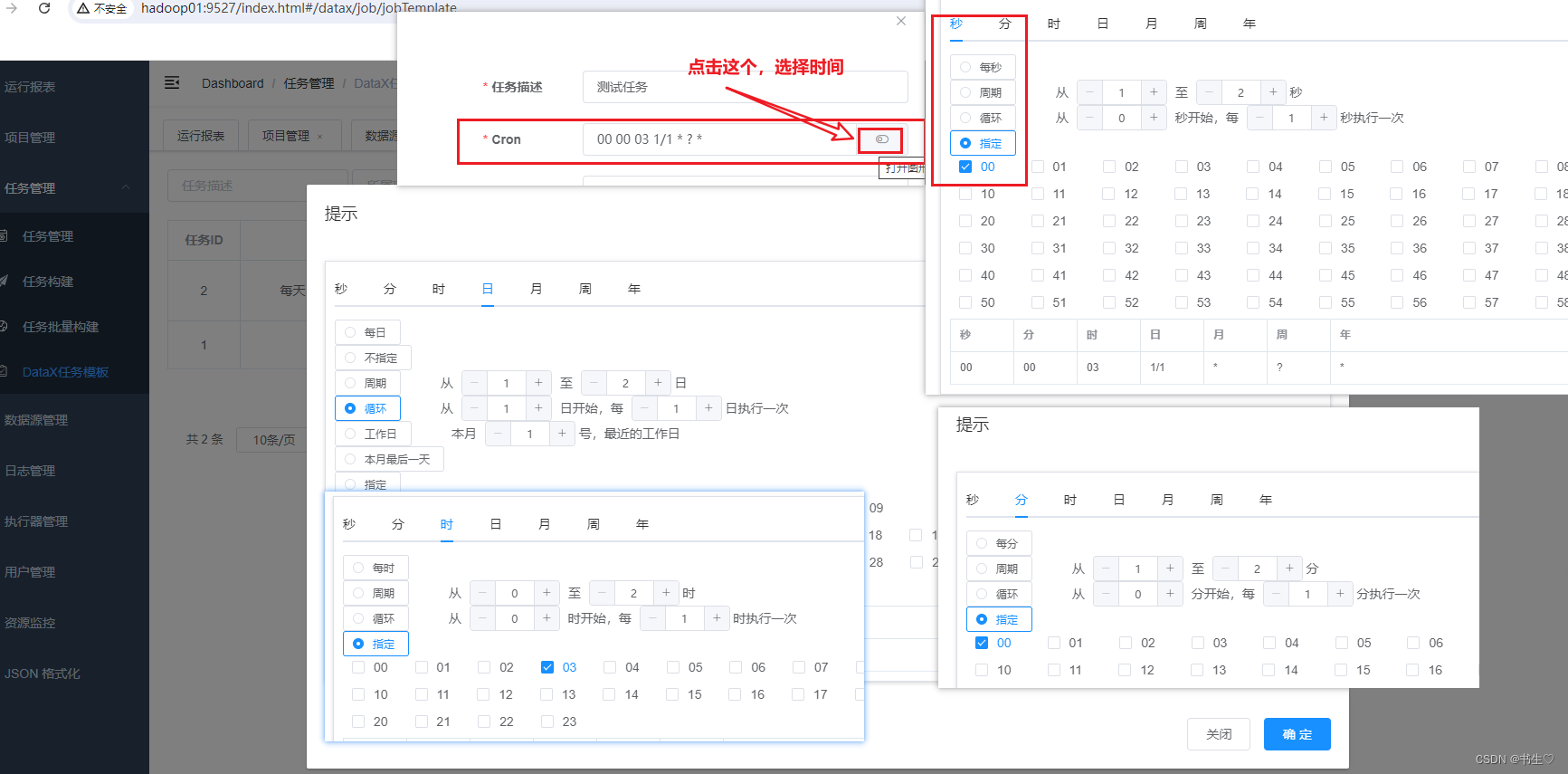
最后时间显示应该是这个样子的。

- 任务构建
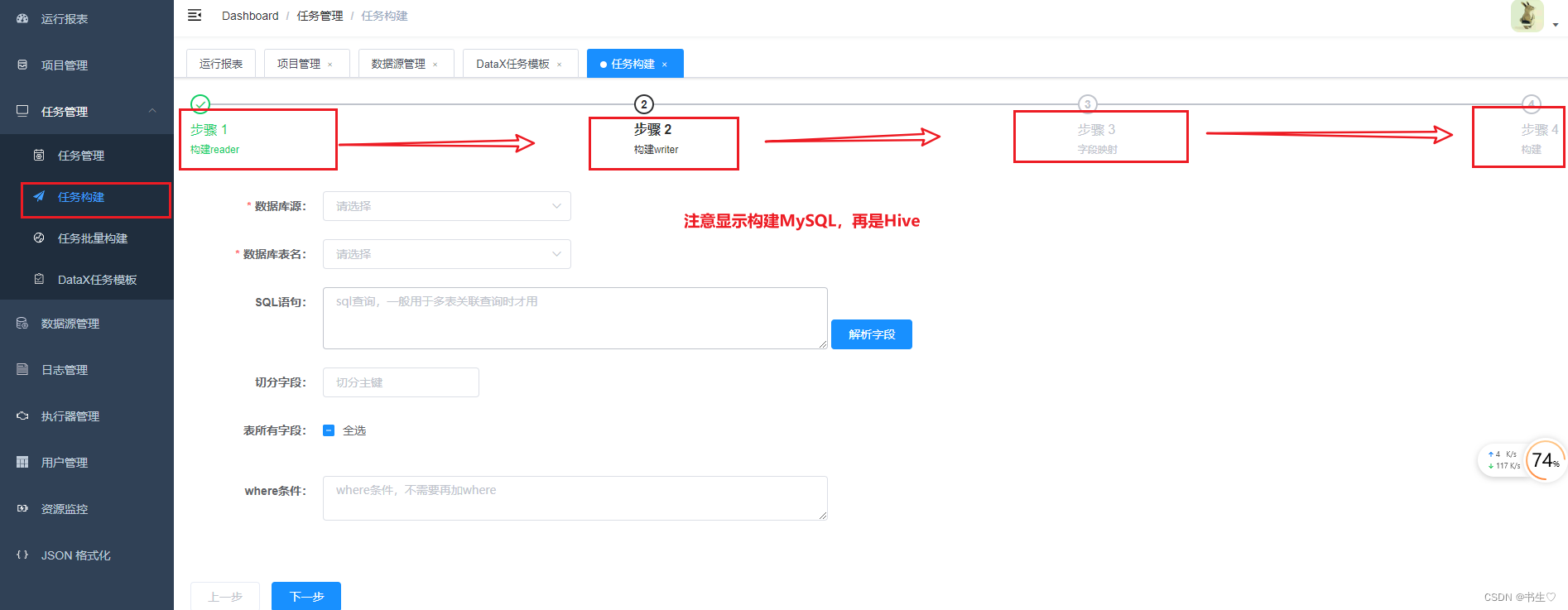
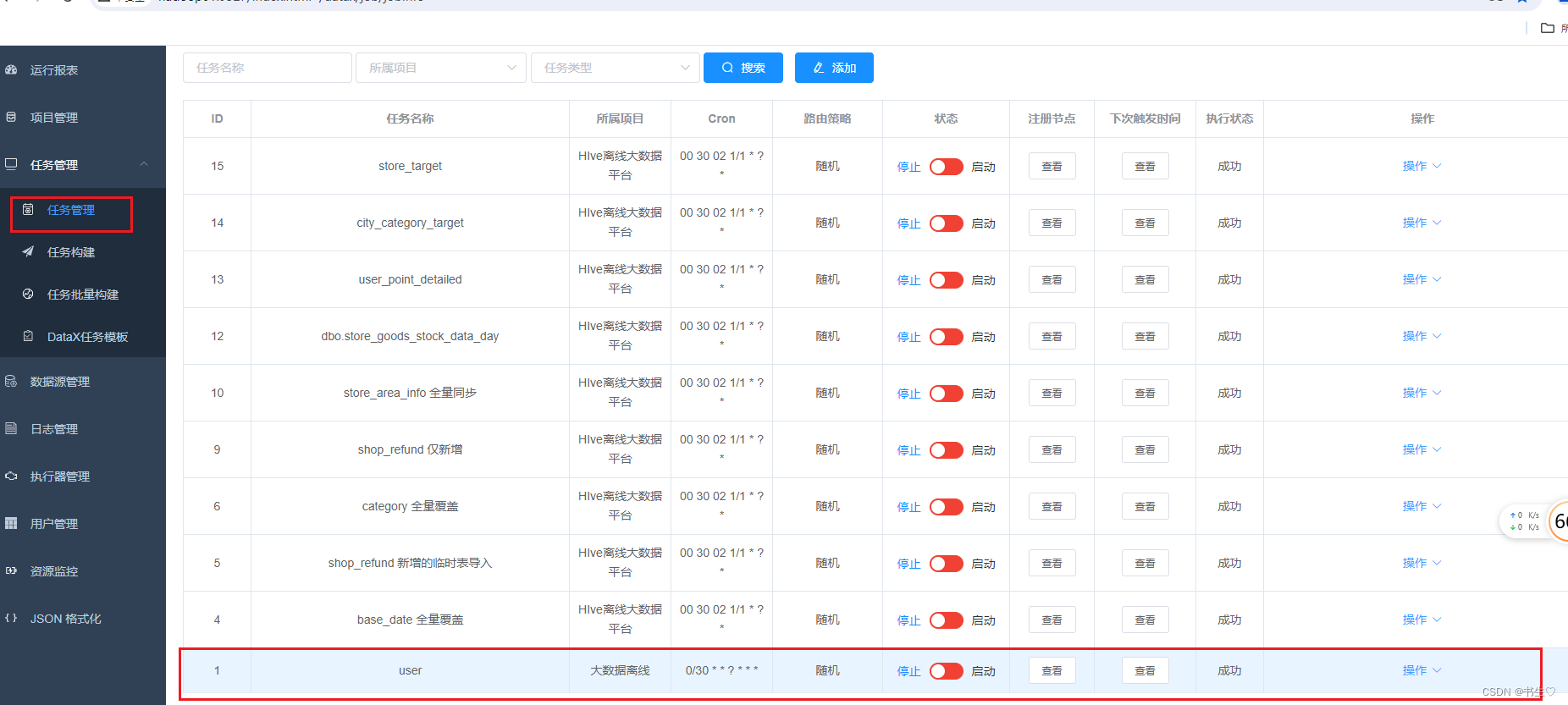
任务管理 查看 且 启动
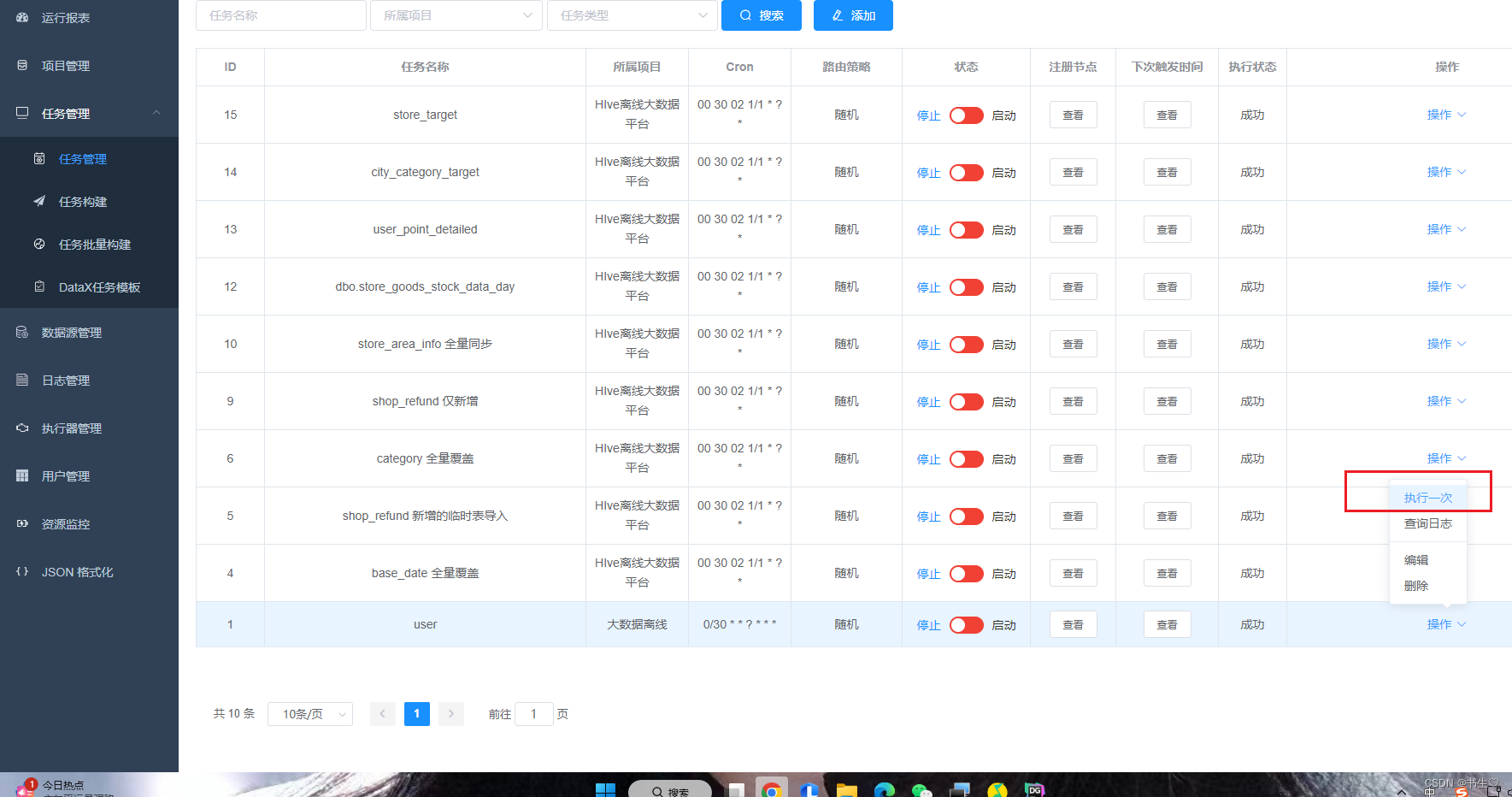
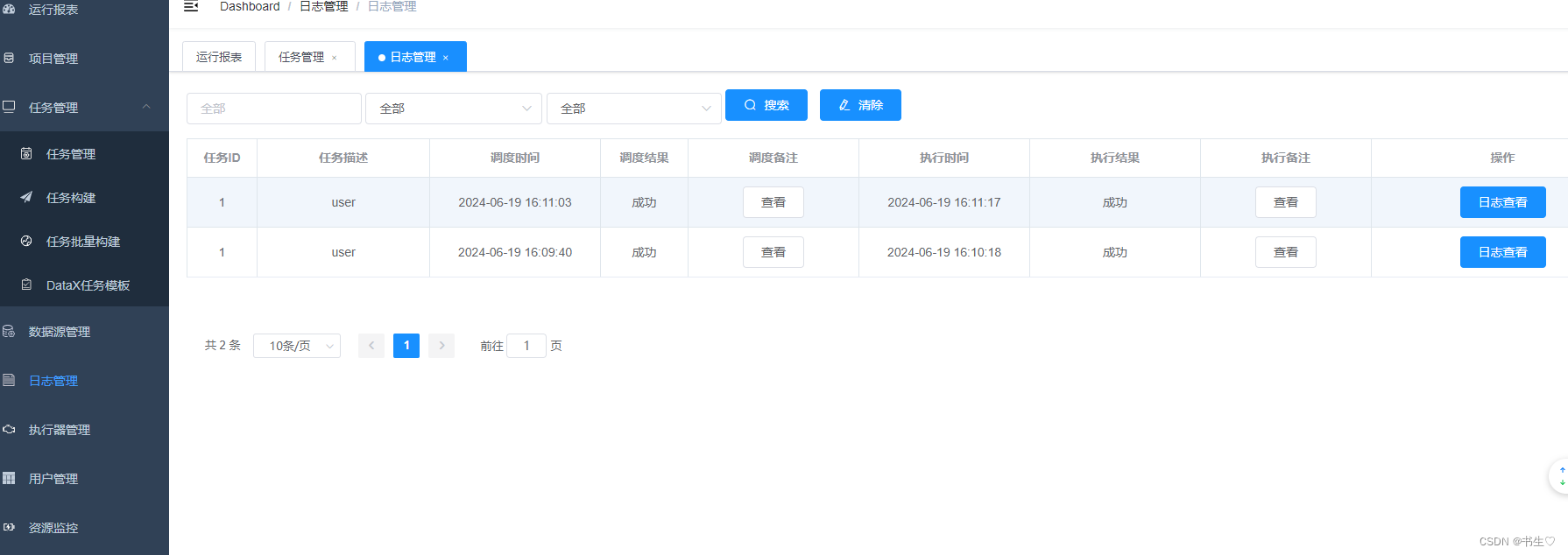
点击任务管理,选择我们任务,下拉操作,点击执行一次,后点击日志查看
2. 基于DataX完成数据导入
2.1 建模设计: 需要考虑的问题
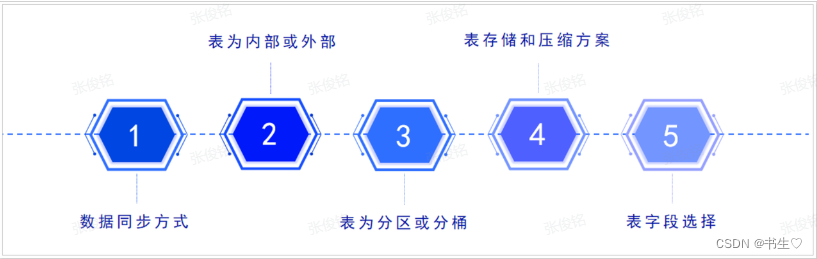
首先我们要考虑,数据的存储问题,内部表还是外部表(重要的放在外部表中),行存储还是列存储,表的字段有哪些,数据同步方式有哪些?
1- 数据的同步方式是什么?
全量覆盖同步:
在建表的时候, 不需要构建分区表, 每一次都是将之前的数据全部删除, 然后全部都重新导入一遍
适合于: 数据量比较少, 而且不需要维护历史变化行为
仅新增同步:
在建表的时候, 需要构建分区表, 分区字段是以更新的周期一致即可, 比如 更新的周期为天, 分区字段也应该为天, 每一次导入上一天的新增的数据
适合于: 数据量比较大, 而且不需要维护历史变化行为(并不代表表不存在变化, 只不过这个变化对分析没有影响)
新增及更新同步:
处理逻辑: 在建表的时候, 需要构建分区表, 分区字段是以更新的周期一致, 比如 更新的周期为天, 分区字段也应该为天,每一次导入上一天的新增及更新的数据
适合于: 数据量比较大, 而且需要后期维护历史变化
全量同步:
在建表的时候, 需要构建分区表, 分区字段以更新的周期一致即可, 比如 更新的周期为天, 分区字段也应该为天,每一次导入的时候, 都是将整个数据集全部导入到一个新的分区中, 后期定期删除老的历史数据(比如: 仅保留最近一周)
适合于: 数据量比较少, 而且还需要维护历史变化, 同时维度周期不需要特别长
注意: 此种同步方式相对较少
2- 表是否选择为内部表 还是 外部表?
判断的依据: 是否对数据有绝对的控制权, 如果没有 必须是外部表, 如果有 随意
3- 表是否为分区表还是分桶表?
分区表: 分文件夹, 将数据划分到不同的文件夹中, 当查询数据的时候, 通过分区字段获取对应分区下的数据, 从而减少数据扫描量, 提高查询效率
分桶表: 分文件 将数据根据指定的字段划分为N多个文件 可以通过这种方式对数据进行采样操作 以及分桶表在后续进行join优化的时候也会涉及到(bucket Map Join | SMB Join)
4- 表选择什么存储格式 和 压缩方案?
存储格式: 一般都是 ORC / Text File
压缩格式: 一般都会 SNAPPY / GZ
存储格式: 如果数据直接对接的普通文本文件的操作 只能使用textFile 否则大多数都是ORC
压缩格式: 读多写少 采用SNAPPY 写多读少 采用GZ 如果普通的文本文件对接, 一般不设置压缩
如果空间比较充足, 没有特殊要求, 建议统一采用SNAPPY
5- 表中字段应该如何选择呢?
ODS层: 业务库有那些表, 表中有哪些字段, 对应在ODS层建那些表, 表中对应有相关的字段 额外根据同步方式, 选择是否添加分区字段
其他层次: 不同层次 需要单独分析, 目标: 把需求分析的结果能够完整的在表中存储起来即可
2.2 Hive中构建原始业务表
表设计:
- 表类型: 内部表 + ORC + ZLIB + 基于同步方式选择分区表
- 字段内容: 与业务库保持一致(注意调整数据类型)
2.3 基于DataX完成数据导入
由于ODS层涉及到不同的同步方式导入方案, 每一种导入方式均有所差异性, 此处举例四种导出模式, 其余的表自行完成即可。
- 首先创建一个项目
- 创建一个每日凌晨两点半执行的任务模版
添加完成,点击下次触发时间下的查看,可以看到后续执行的时间。
2.3.1 全量覆盖
- 添加源数据 ,点击源数据管理,添加MySQL中的dim库
- 在hive中创建好表,如果是全量覆盖我们,我们就以 _f 结尾,如果是仅新增的就以_i 结尾。
-- 1 建库
drop database if exists dim cascade;
create database dim;
use dim;
-- 2 建表
-- 时间维度表
-- auto-generated definition
create table dim.ods_dim_base_date_f
(
trade_date string comment '日期编码',
year_code int comment '年编码',
month_code int comment '月份编码',
day_code int comment '日编码',
quanter_code int comment '季度编码',
quanter_name string comment '季度名称',
week_trade_date string comment '周一时间',
month_trade_date string comment '月一时间',
week_end_date string comment '周末时间',
month_end_date string comment '月末时间',
last_week_trade_date string comment '上周一时间',
last_month_trade_date string comment '上月一时间',
last_week_end_date string comment '上周末时间',
last_month_end_date string comment '上月末时间',
year_week_code int comment '一年中第几周',
week_day_code int comment '周几code',
day_year_num int comment '一年第几天',
month_days int comment '本月有多少天',
is_weekend int comment '是否周末(周六和周日)',
days_after1 string comment '1天后的日期',
days_after2 string comment '2天后的日期',
days_after3 string comment '3天后的日期',
days_after4 string comment '4天后的日期',
days_after5 string comment '5天后的日期',
days_after6 string comment '6天后的日期',
days_after7 string comment '7天后的日期'
)
comment '时间维度表'
row format delimited fields terminated by ','
stored as orc
tblproperties ('orc.compress'='zlib')
;
-- 3 查询
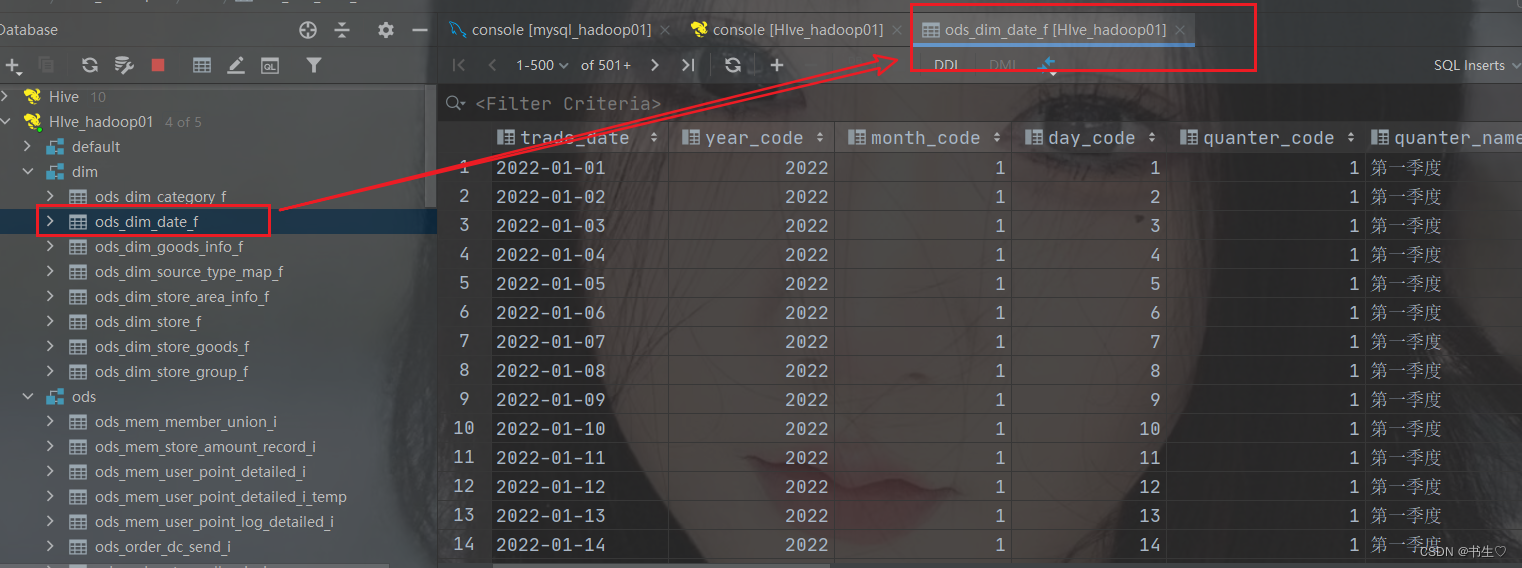
select * from dim.ods_dim_base_date_f;
desc formatted dim.ods_dim_base_date_f;
-- hdfs://hadoop01:8020/user/hive/warehouse/dim.db/ods_dim_base_date_f
-- hdfs://hadoop01:8020
-- /user/hive/warehouse/dim.db/ods_dim_base_date_f
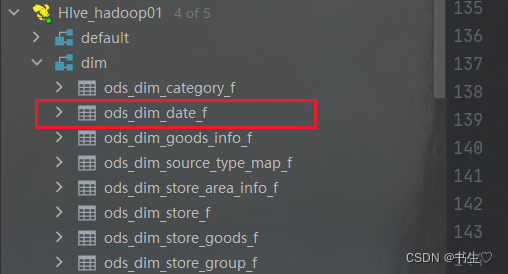
- 接着添加hive的dim库。
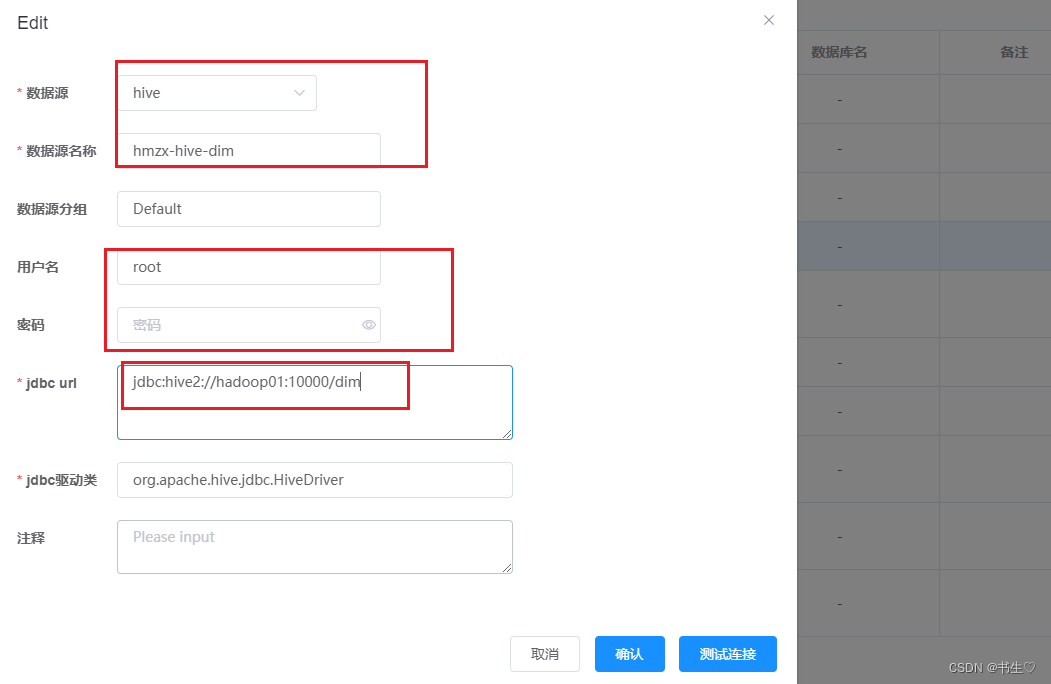
- 任务构建
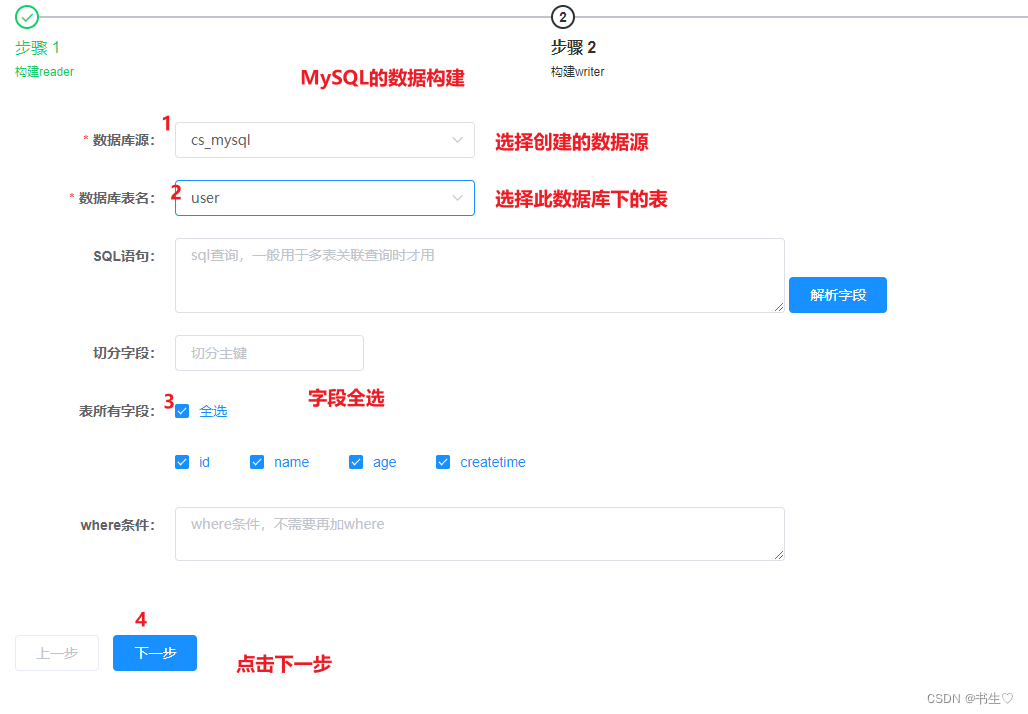
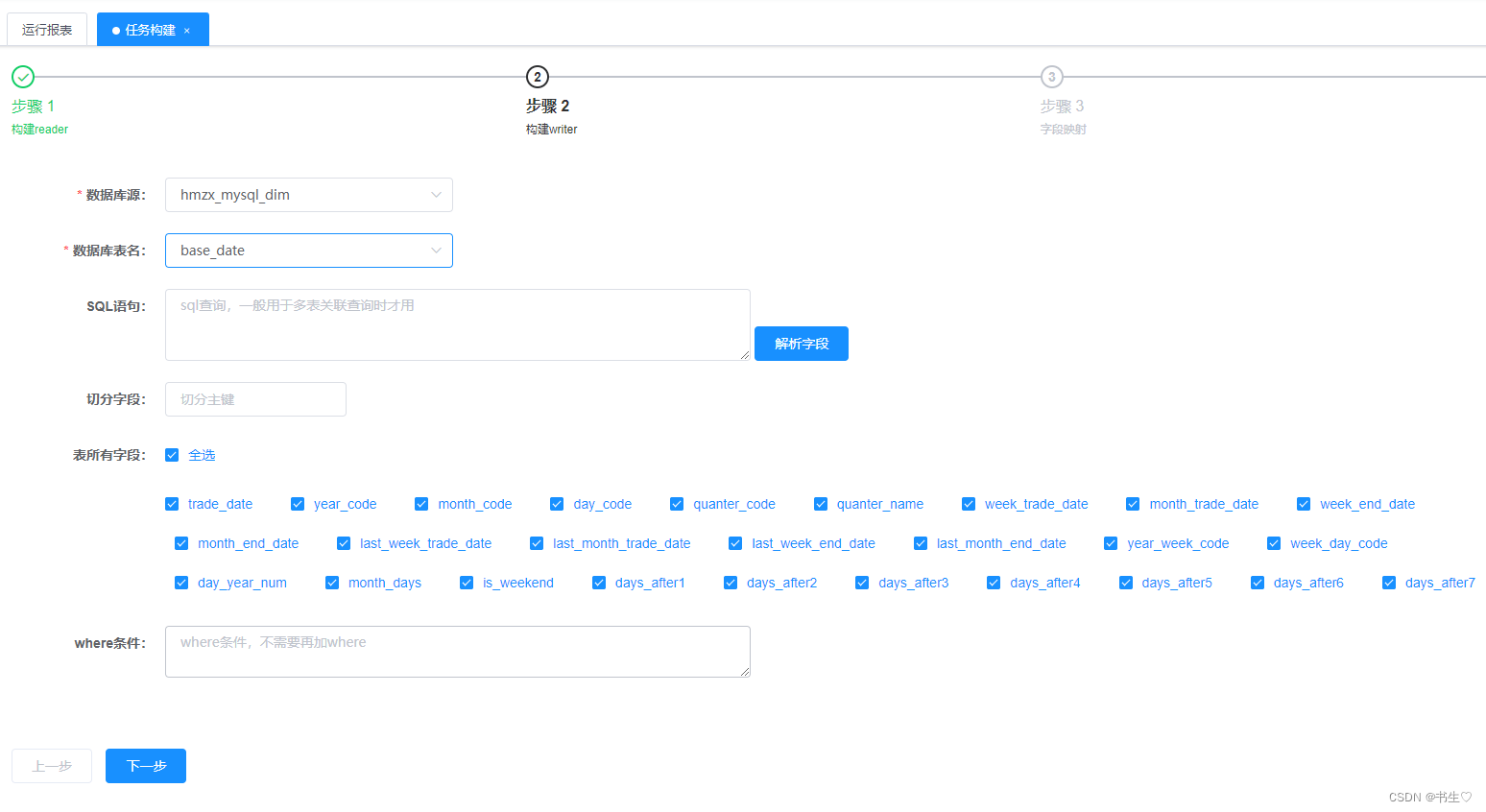
构建MySQL数据,如下:只需要选择刚才创建的数据源,选择表,全选字段
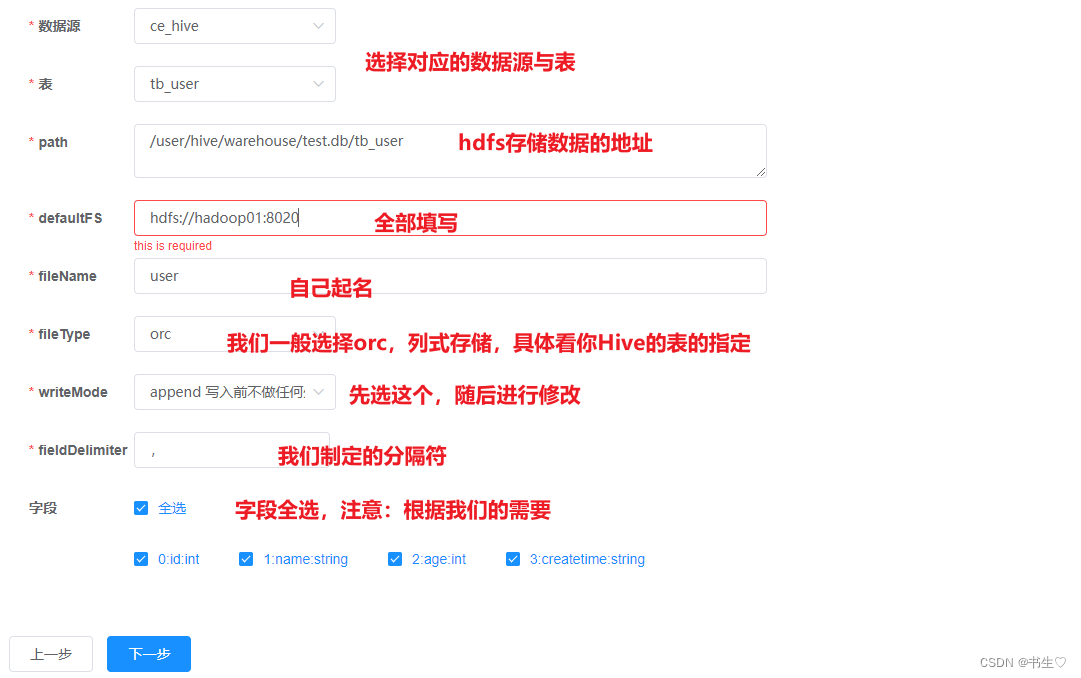
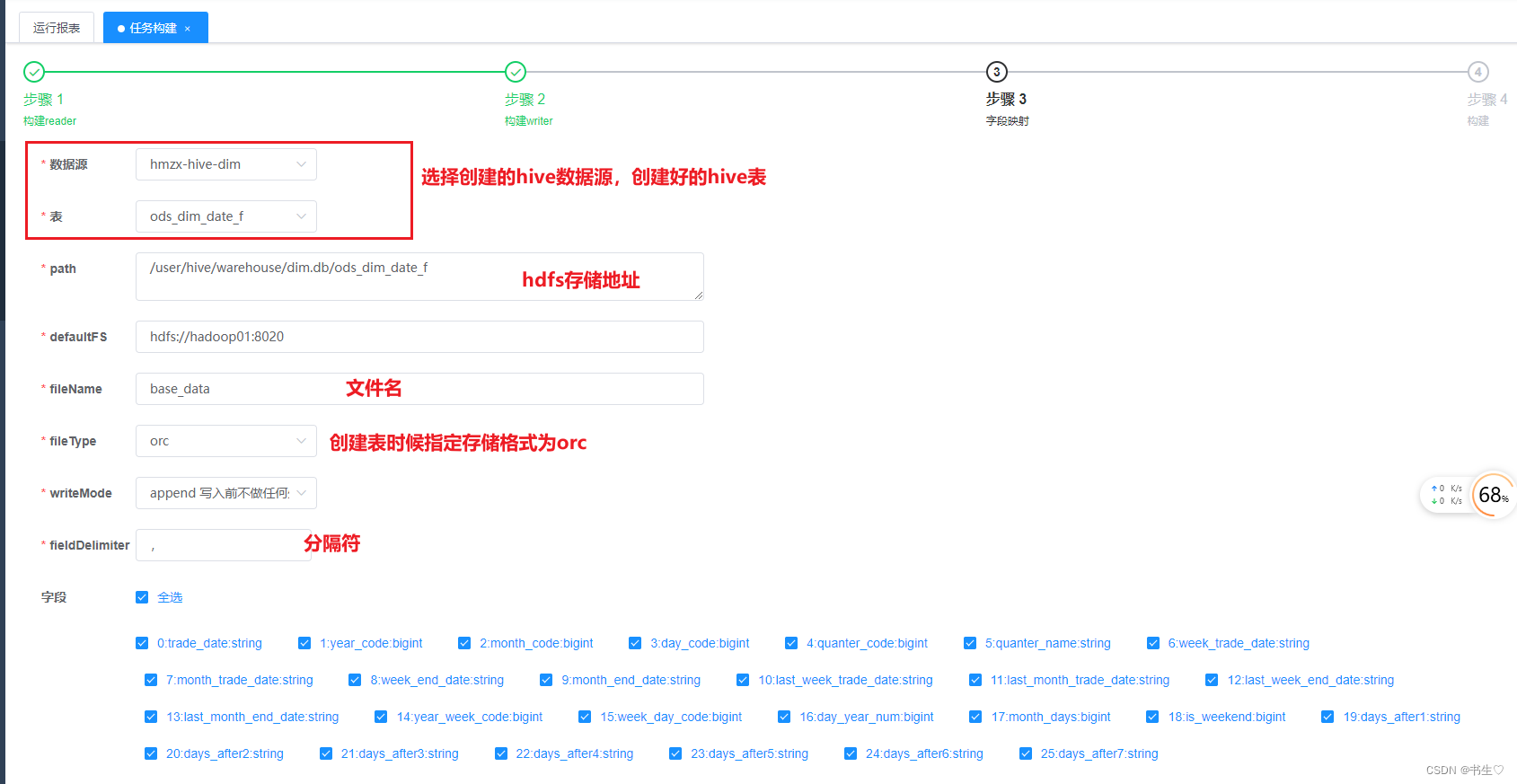
构建hive数据,如下:只需要选择刚才创建的数据源,选择表,填写地址,存储格式以及分隔符
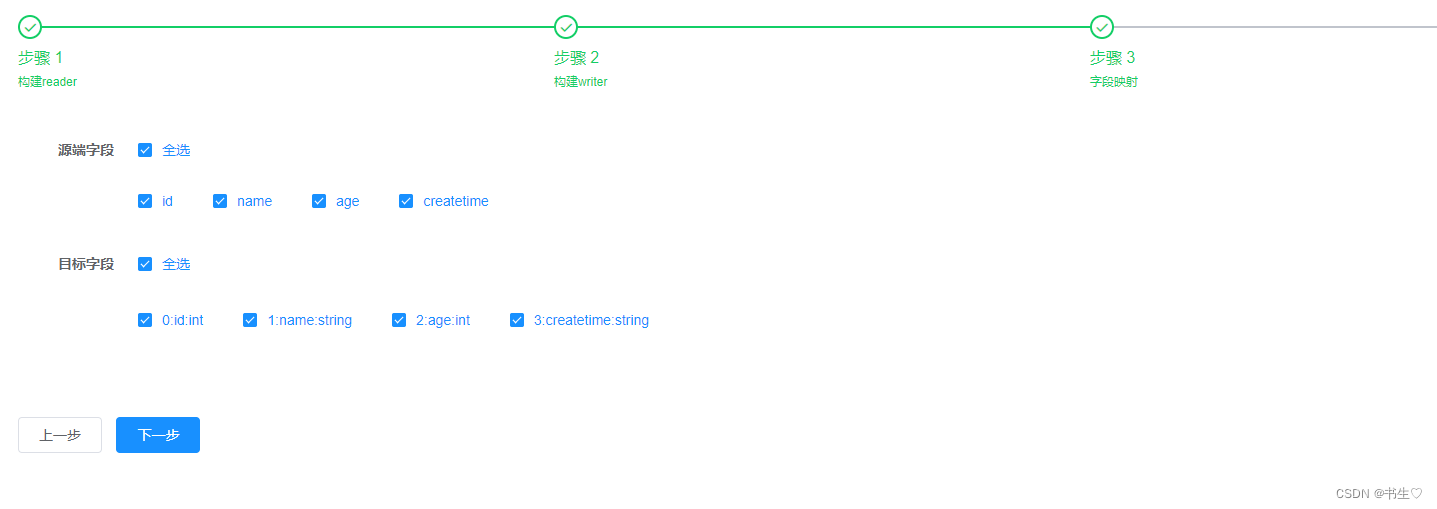
字段映射:全选字段
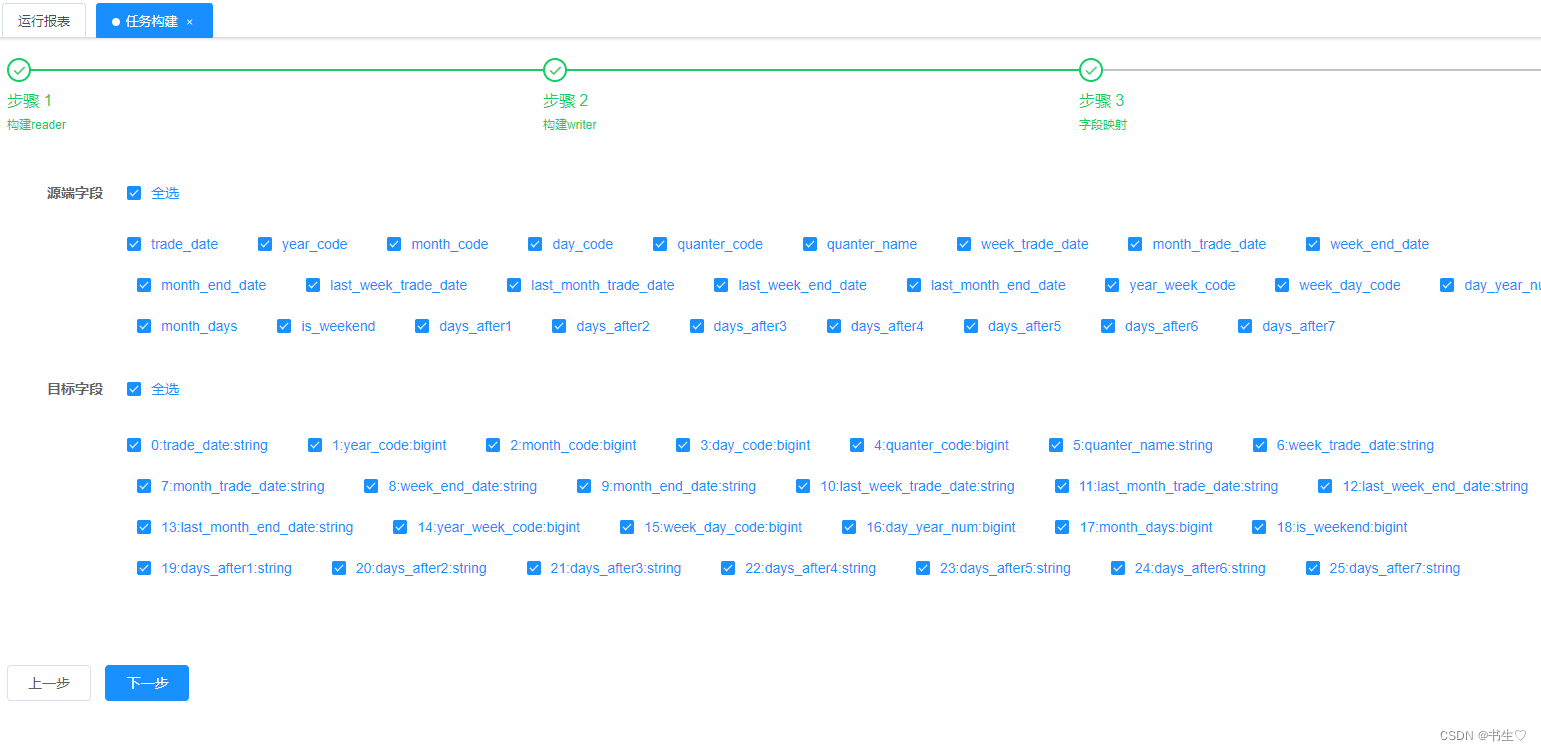
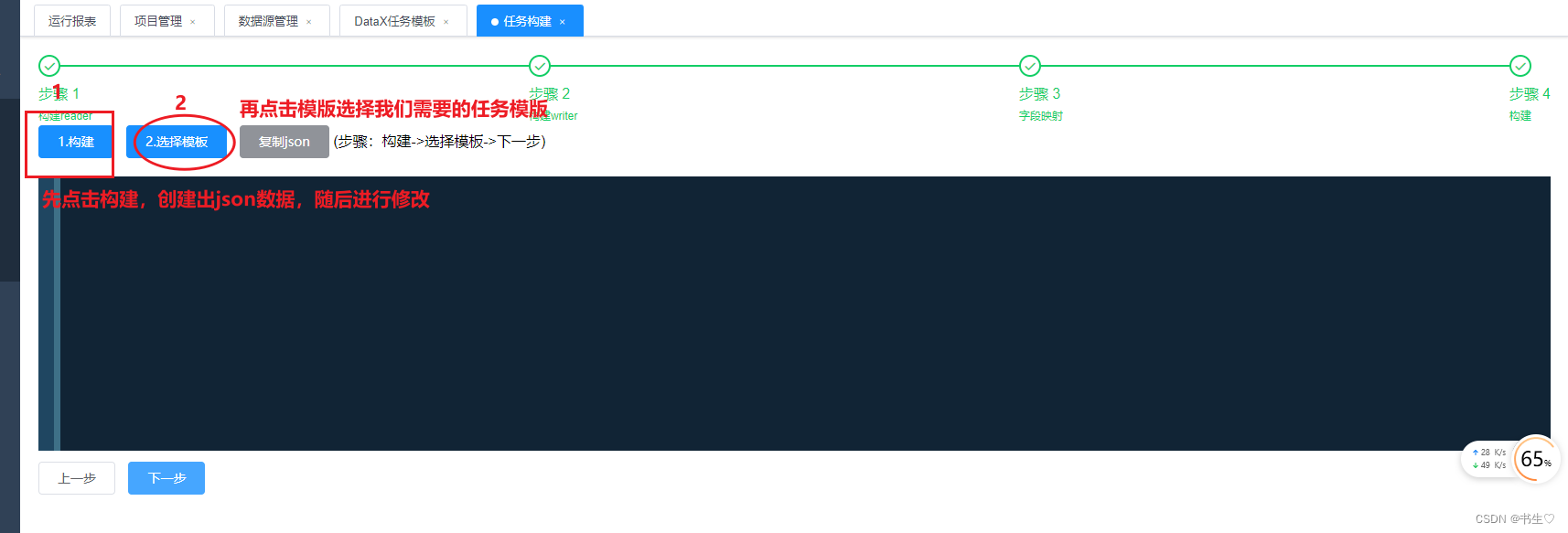
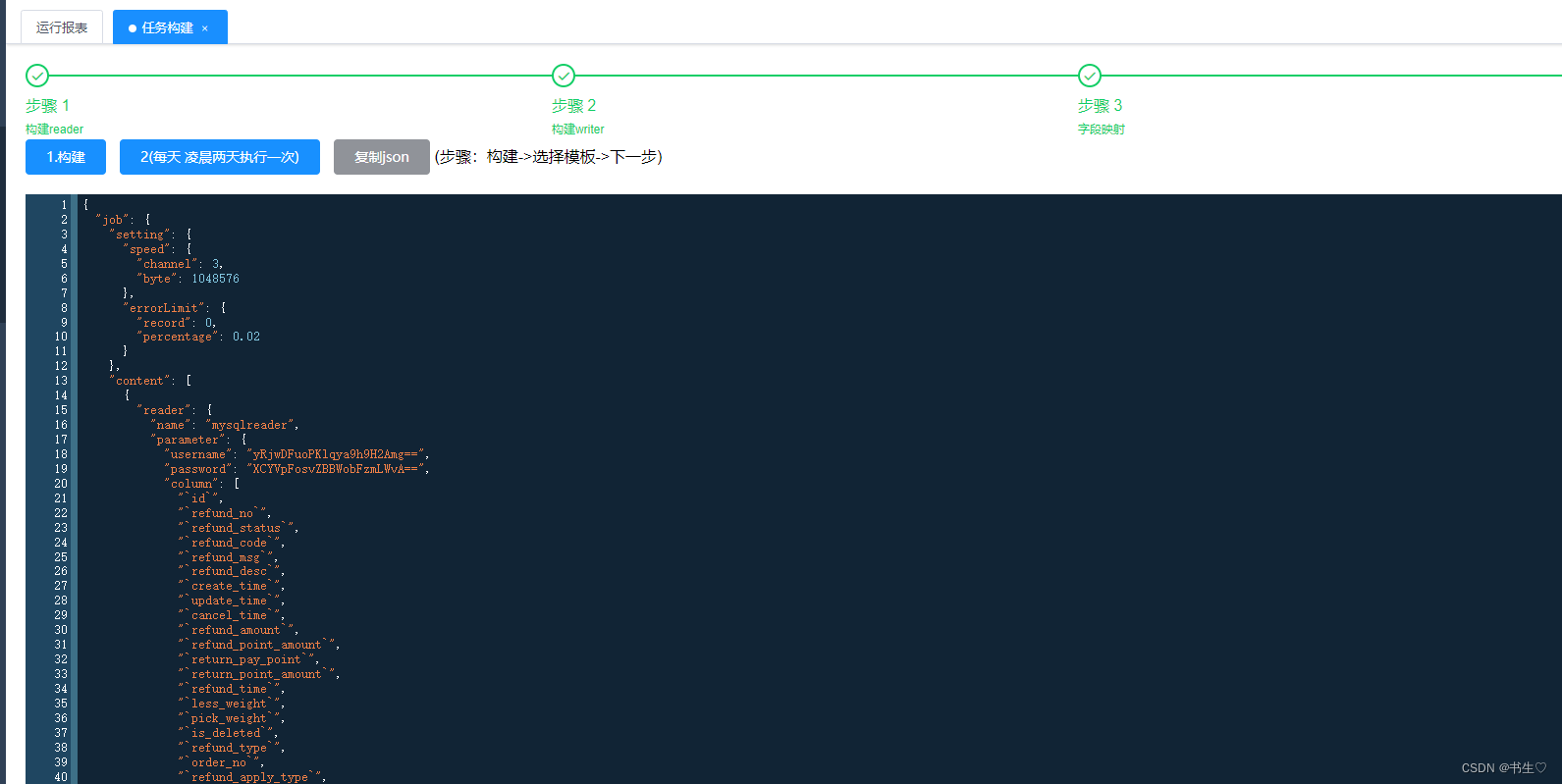
构建:点击构建,生成json数据,选择任务模版,这里我们修改json的文件数据
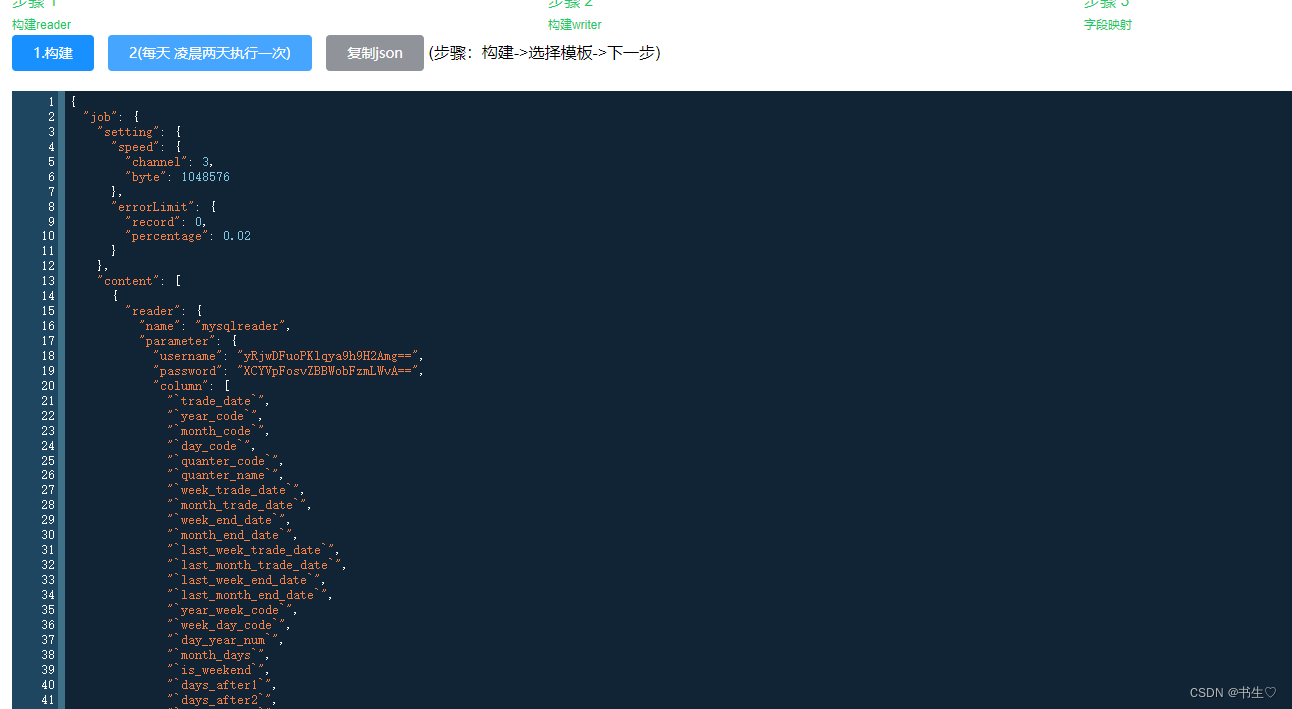
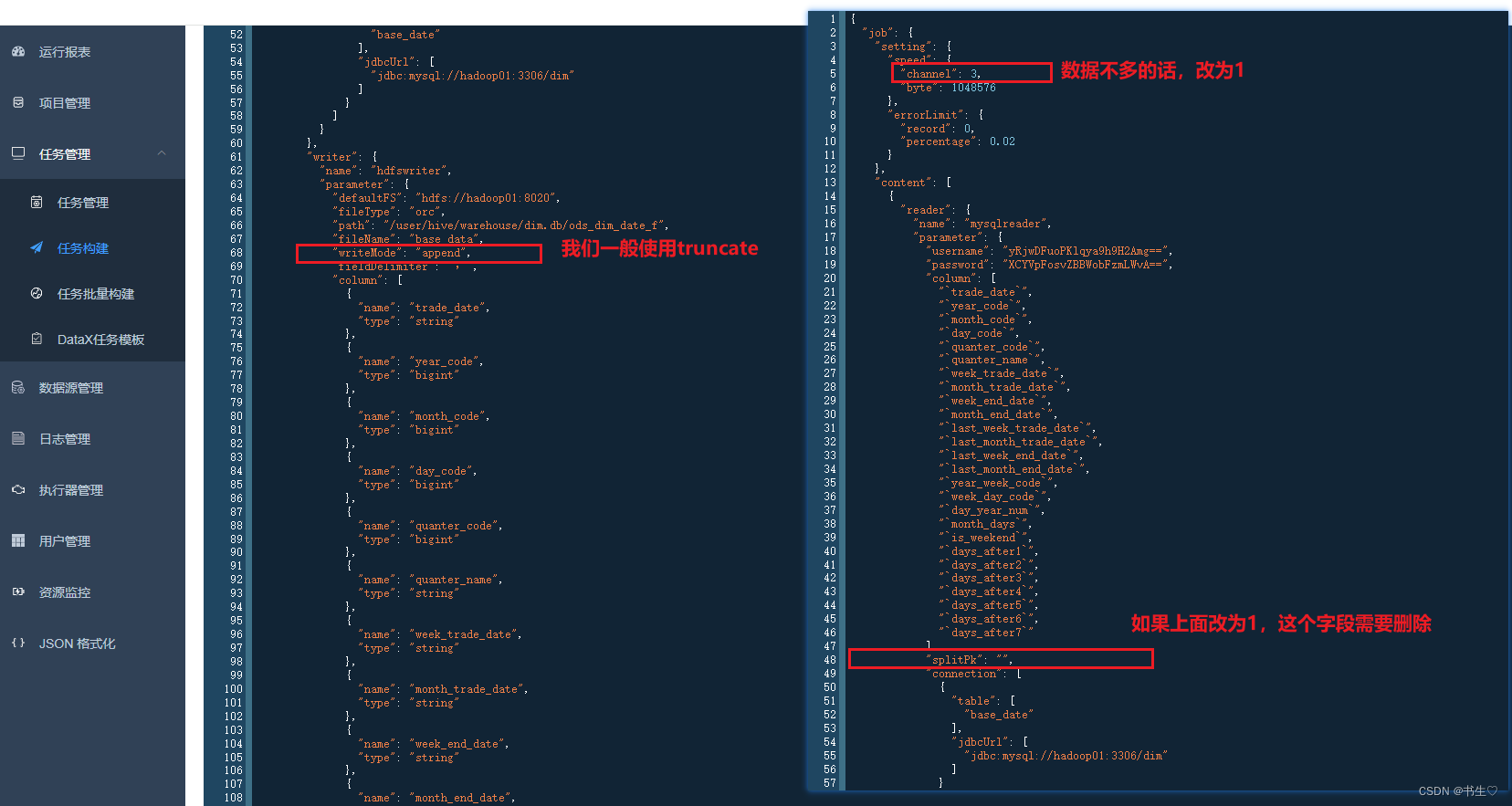
- 点击下一步,执行任务

点击查询日志
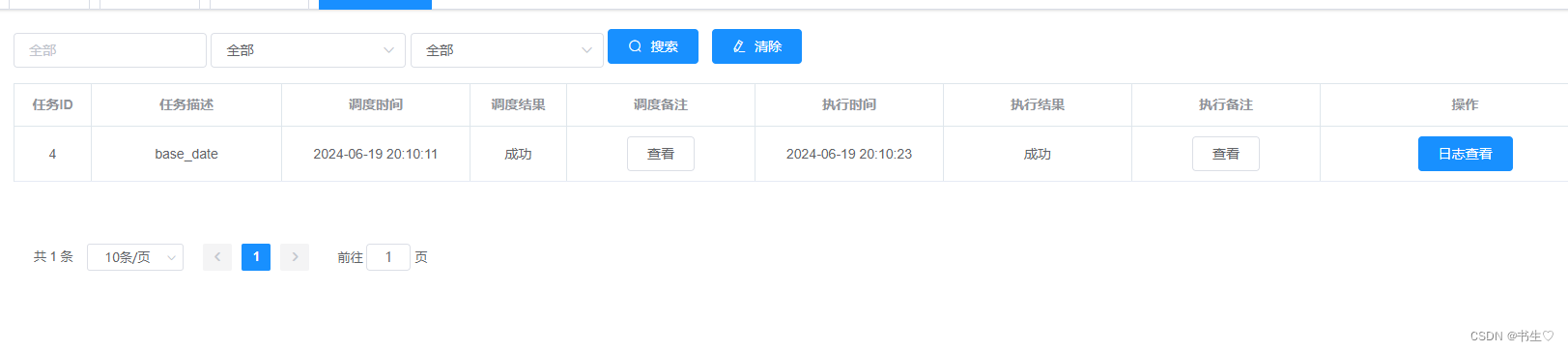
- 去Datagrip 查看是否有数据
2.3. 2 仅新增方案
2.3.2.1 全量导入(第一次)
从业务库将数据导入到ODS层, 分为 首次导入和增量导入两部分, 其中首次导入指的第一次建表, 导入数据, 此时一般都是全量导入, 后续每一天都是采用增量导入的方式,
当前项目, 增量模式: T+1(当天处理都是上一天的数据/ 每天的数据在下一天进行处理)
技术: DataX
思考: 当全量导入数据的时候, 整个数据集是应该放置到上一天的分区中呢? 还是说应该按照实际表数据创建时间划分到不同分区呢?
二种方式均可以, 其实在实际应用中两种其实都是存在的, 只不过我们当前选择的第二种方式, 直接将数据不同的日期放置到不同的分区下
如何做呢?
DataX不支持直接导入多个分区数据, 仅支持导入一个分区, 因为DataX本质上是将数据对接HDFS, 而非HIVE,只是HIVE正好映射到HDFS对应目录下, 正好吧数据加载到了, 所以在HIVE正好就看到了数据
既然dataX不支持那如何处理呢?
先创建一个临时表(没有分区), 通过DataX 将数据导入到临时表中, 然后在通过临时表灌入到HIVE的ODS层目标表表, 处理完成后, 删除临时表
-- 建库
drop database if exists ods cascade;
create database if not exists ods;
use ods;
-- 建表
CREATE TABLE IF NOT EXISTS ods.ods_sale_shop_refund_i (
id BIGINT COMMENT '主键',
refund_no STRING COMMENT '退款单号',
refund_status BIGINT COMMENT '退款状态:1-退款中;2-退款成功;3-退款失败',
refund_code BIGINT COMMENT '退款原因code',
refund_msg STRING COMMENT '退款原因',
refund_desc STRING COMMENT '退款描述',
create_time TIMESTAMP COMMENT '创建时间/退款申请时间',
update_time TIMESTAMP COMMENT '更新时间',
cancel_time TIMESTAMP COMMENT '退款申请取消时间',
refund_amount DECIMAL(27, 2) COMMENT '退款金额',
refund_point_amount DECIMAL(27, 2) COMMENT '扣减已赠积分',
return_pay_point BIGINT COMMENT '退还支付积分',
return_point_amount DECIMAL(27, 2) COMMENT '退还积分抵扣金额',
refund_time TIMESTAMP COMMENT '退款成功时间',
less_weight DECIMAL(27, 3) COMMENT '差额重量,单位kg',
pick_weight DECIMAL(27, 3) COMMENT '拣货重量,单位kg',
is_deleted BIGINT COMMENT '失效标志:0-正常;1-失效',
refund_type BIGINT COMMENT '退款类型:1-部分退;2-全额退; 3-差额退',
order_no STRING COMMENT '订单号',
refund_apply_type BIGINT COMMENT '退款申请类型:1-仅退款;2-退货退款',
refund_delivery DECIMAL(27, 2) COMMENT '运费退款',
sync_erp_status BIGINT COMMENT '同步erp状态:-1-失败,0-未同步,1-成功',
sync_erp_msg STRING COMMENT '同步erp失败消息',
create_sys_user_id BIGINT COMMENT '操作人id',
create_sys_user_name STRING COMMENT '操作人名称',
store_no STRING COMMENT '门店编码',
store_leader_id BIGINT COMMENT '团长id'
)
COMMENT '订单退款表'
partitioned by (dt string)
row format delimited fields terminated by ','
stored as orc
tblproperties ('orc.compress'='ZLIB');
-- 构建订单退款表 临时表:
drop table if exists ods.ods_sale_shop_refund_i_temp;
CREATE TABLE IF NOT EXISTS ods.ods_sale_shop_refund_i_temp(
id BIGINT COMMENT '主键',
refund_no STRING COMMENT '退款单号',
refund_status BIGINT COMMENT '退款状态:1-退款中;2-退款成功;3-退款失败',
refund_code BIGINT COMMENT '退款原因code',
refund_msg STRING COMMENT '退款原因',
refund_desc STRING COMMENT '退款描述',
create_time TIMESTAMP COMMENT '创建时间/退款申请时间',
update_time TIMESTAMP COMMENT '更新时间',
cancel_time TIMESTAMP COMMENT '退款申请取消时间',
refund_amount DECIMAL(27, 2) COMMENT '退款金额',
refund_point_amount DECIMAL(27, 2) COMMENT '扣减已赠积分',
return_pay_point BIGINT COMMENT '退还支付积分',
return_point_amount DECIMAL(27, 2) COMMENT '退还积分抵扣金额',
refund_time TIMESTAMP COMMENT '退款成功时间',
less_weight DECIMAL(27, 3) COMMENT '差额重量,单位kg',
pick_weight DECIMAL(27, 3) COMMENT '拣货重量,单位kg',
is_deleted BIGINT COMMENT '失效标志:0-正常;1-失效',
refund_type BIGINT COMMENT '退款类型:1-部分退;2-全额退; 3-差额退',
order_no STRING COMMENT '订单号',
refund_apply_type BIGINT COMMENT '退款申请类型:1-仅退款;2-退货退款',
refund_delivery DECIMAL(27, 2) COMMENT '运费退款',
sync_erp_status BIGINT COMMENT '同步erp状态:-1-失败,0-未同步,1-成功',
sync_erp_msg STRING COMMENT '同步erp失败消息',
create_sys_user_id BIGINT COMMENT '操作人id',
create_sys_user_name STRING COMMENT '操作人名称',
store_no STRING COMMENT '门店编码',
store_leader_id BIGINT COMMENT '团长id'
)
COMMENT '订单退款表'
row format delimited fields terminated by ','
stored as orc
tblproperties ('orc.compress'='ZLIB');
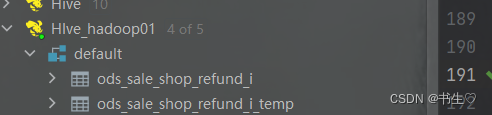
- 设置数据源: 连接mysql的 sale库
- 设置数据源: 连接HIVE的 ODS库
- 配置DataX任务模板(后续调度时间依然凌晨20分, 可以省略配置)
- 构建任务
MySQL同上,选择数据源,选择表,全选字段

hive同上
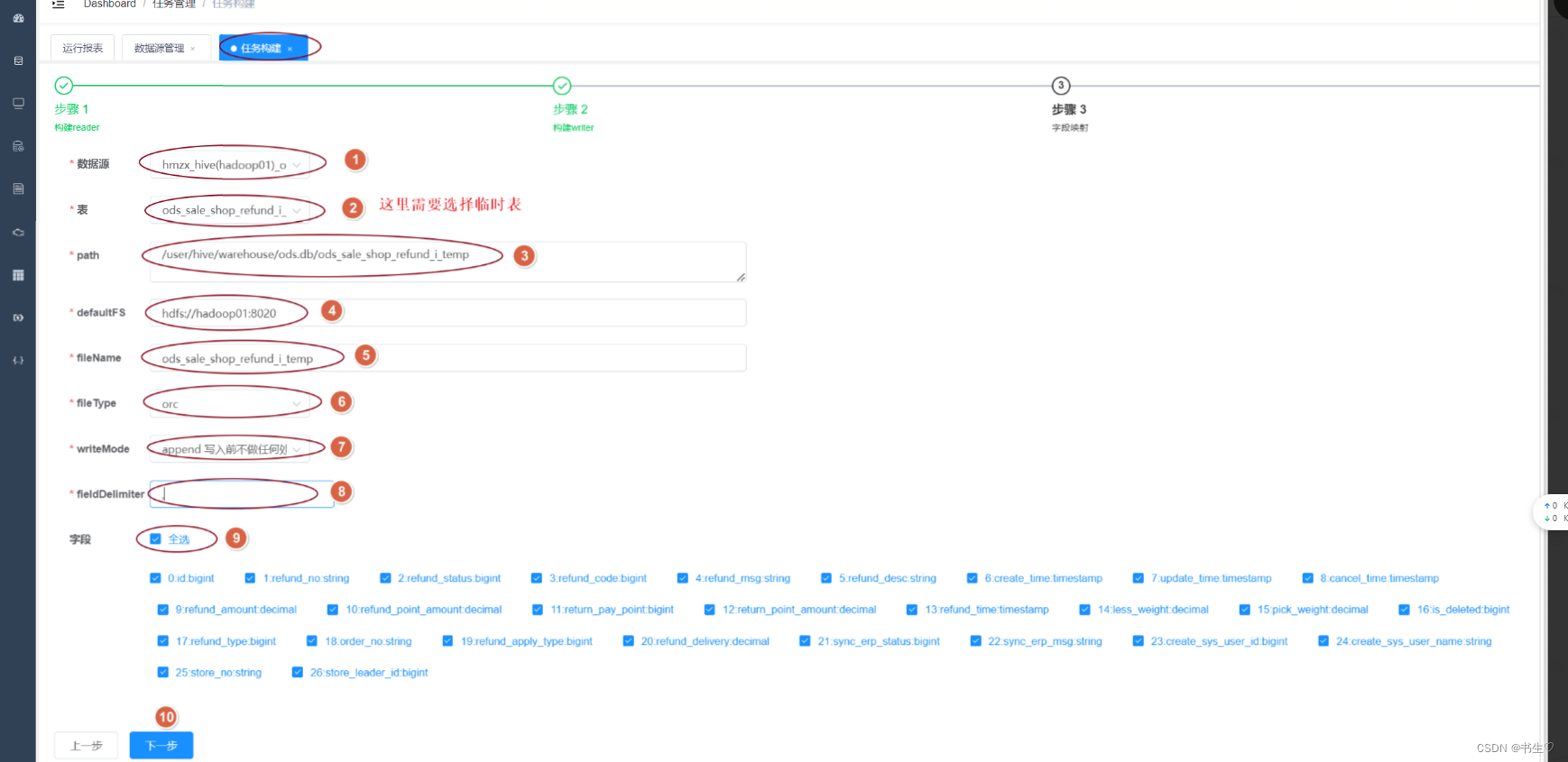
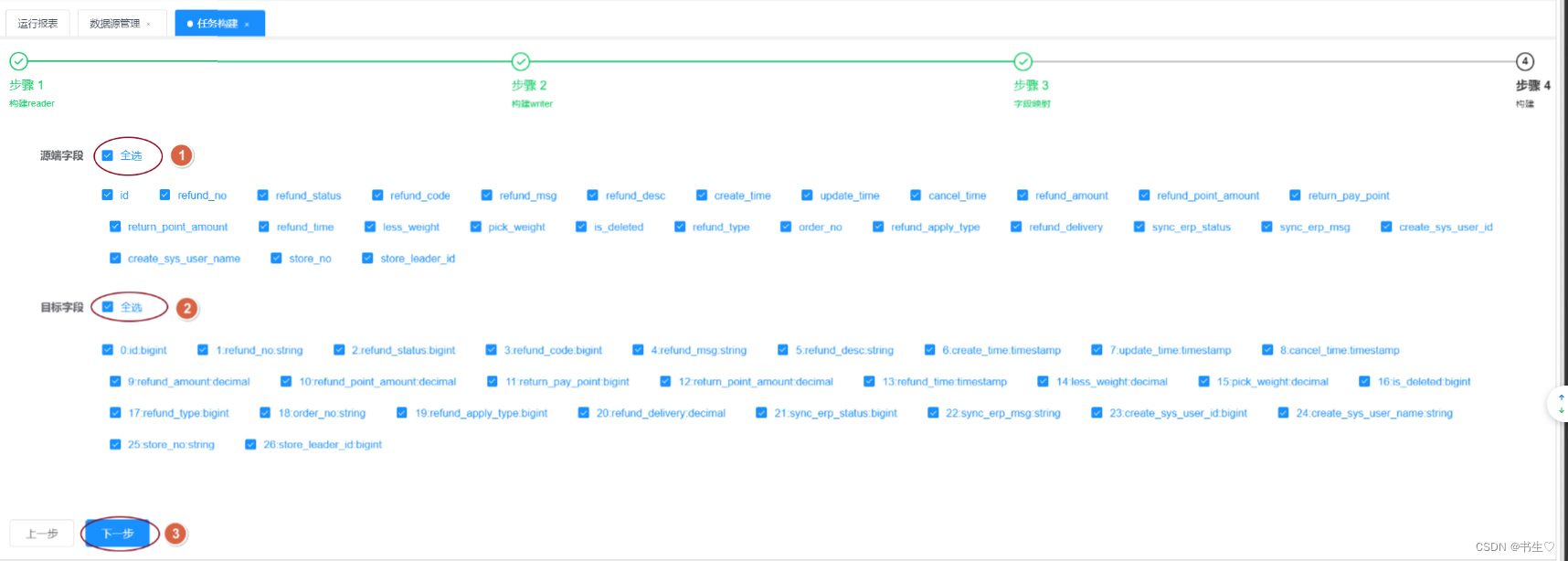
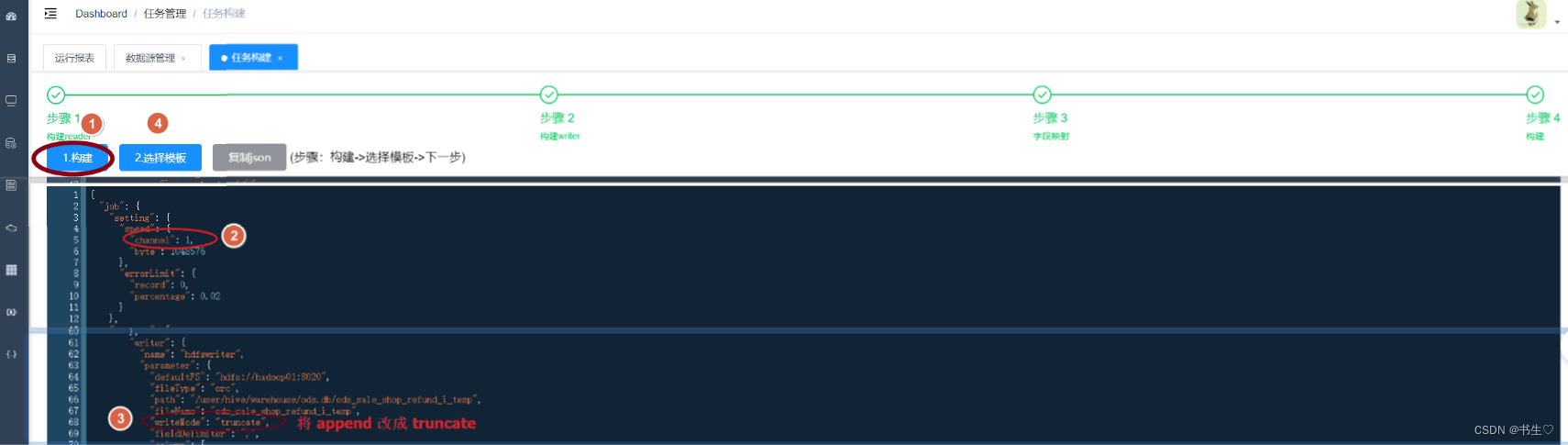
- 执行任务
点击执行任务,然后点击查看日志,是否成功


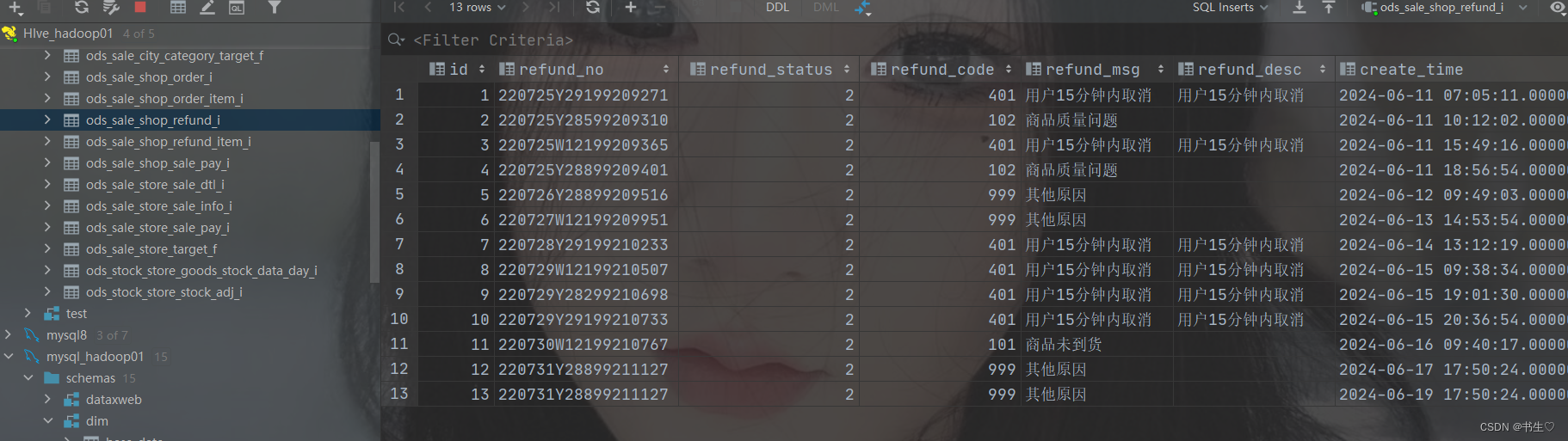
- 将临时表的数据插入到分区表中
注意:这里使用的是动态分区,需要先开启非严格模式
-- 开启非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
-- 从临时表中查询数据插入到真实表中
-- 方式1
insert overwrite table ods.ods_sale_shop_refund_i partition (dt)
select
*,
date_format(create_time,'yyyy-MM-dd') as dt
from ods.ods_sale_shop_refund_i_temp;
-- 方式2
insert overwrite table ods.ods_sale_shop_refund_i partition (dt)
select *,
date(create_time) as dt
from ods.ods_sale_shop_refund_i_temp;
2.3.2.2 增量导入: T+1模式
- 添加新增的数据
-- 模拟新增昨日数据
insert into sale.shop_refund (id, refund_no, refund_status, refund_code, refund_msg, refund_desc, create_time,
update_time,
cancel_time, refund_amount, refund_point_amount, return_pay_point, return_point_amount,
refund_time, less_weight, pick_weight, is_deleted, refund_type, order_no,
refund_apply_type,
refund_delivery, sync_erp_status, sync_erp_msg, create_sys_user_id, create_sys_user_name,
store_no, store_leader_id)
values (14, '220731Y28899211127', 2, 100, '其他原因', '',
DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) + INTERVAL '17:50:24' HOUR_SECOND,
DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) + INTERVAL '17:50:24' HOUR_SECOND,
null, 5.26, 5.00, null, null,
DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) + INTERVAL '18:56:36' HOUR_SECOND,
null, null, 0, 1, 'BL22073199620677', 1, 0.00, 1, null, 1001107, 1001107, 'Y288', null);
-- 查询昨天数据
SELECT *
FROM sale.shop_refund
WHERE create_time BETWEEN
CONCAT(DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY), ' 00:00:00')
AND CONCAT(DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY), ' 23:59:59');
- 如何获取上一天增量的sql语句?
# 方式一:使用 `BETWEEN` 和 `CONCAT`
SELECT *
FROM sale.shop_refund
WHERE create_time BETWEEN
CONCAT(DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY), ' 00:00:00')
AND CONCAT(DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY), ' 23:59:59');
# 方式二:使用 `DATE_FORMAT` 和 `DATE_SUB`
SELECT *
FROM sale.shop_refund
WHERE DATE_FORMAT(create_time, '%Y-%m-%d') = DATE_FORMAT(DATE_SUB(NOW(), INTERVAL 1 DAY), '%Y-%m-%d');
# 方式三:使用 `>=` 和 `<` 范围过滤
SELECT *
FROM sale.shop_refund
WHERE create_time >= DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY)
AND create_time < CURRENT_DATE;
# 方式四:使用 `DATE(create_time)`
SELECT *
FROM sale.shop_refund
WHERE DATE(create_time) = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY);
# 效率考虑
# 1. **方式一**:使用 `BETWEEN` 和 `CONCAT`,可以明确地界定时间范围,但字符串拼接可能稍微影响性能。
# 2. **方式二**:使用 `DATE_FORMAT`,能达到目标,但对每一行进行格式化,性能可能较低。
# 3. **方式三**:使用 `>=` 和 `<`,直接利用时间范围,通常效率较高,如果 `create_time` 列有索引,可以充分利用索引。
# 4. **方式四**:使用 `DATE` 函数,方便但会对每一行调用函数,可能影响性能。
#
# 对于大多数情况下,**方式三**(使用 `>=` 和 `<`)通常是推荐的,因为它可以更好地利用索引,提高查询性能。如果你对性能要求很高,并且 `create_time` 列上有索引,应该优先考虑这种方式。
- 重新构建任务
构建MySQL数据是一样的,但是我们要添加条件语句,因为我们只要新增的数据,也就是说是昨天的数据
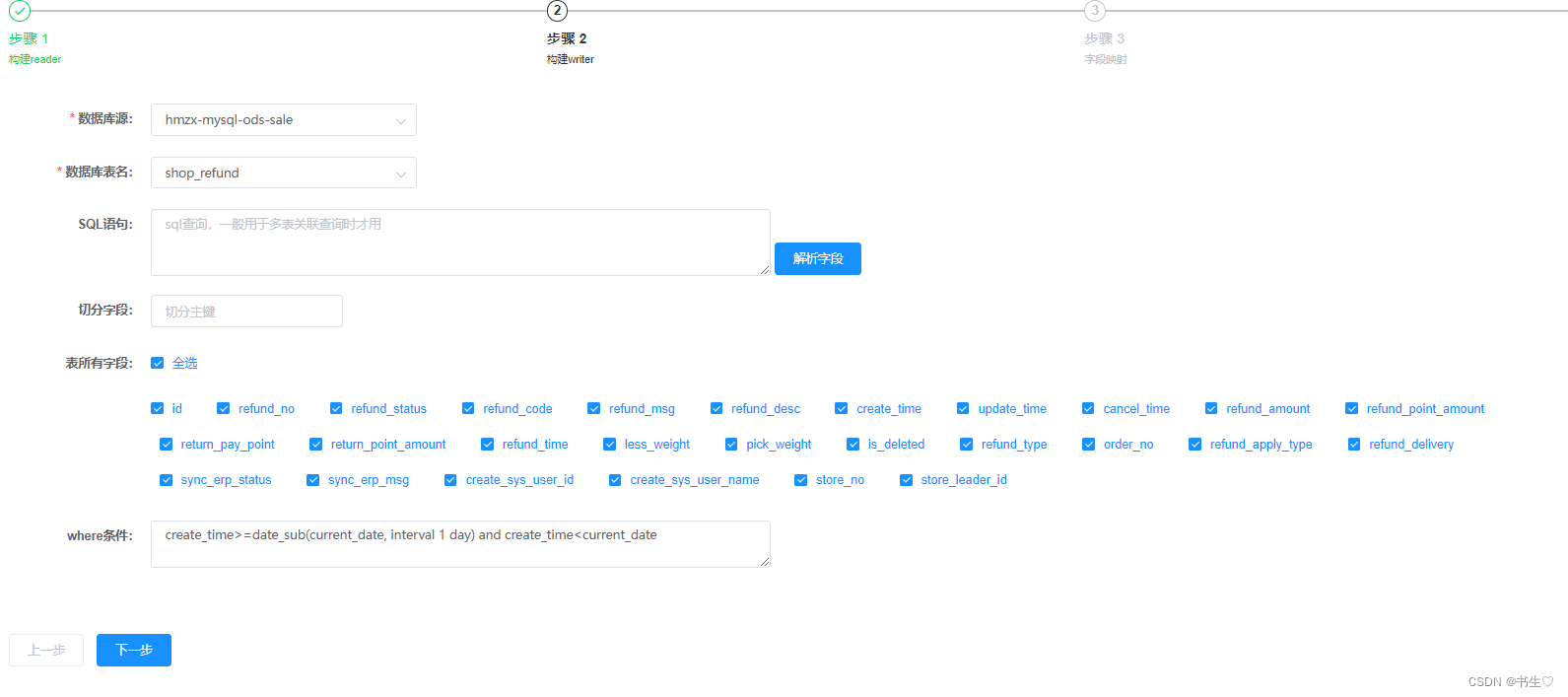
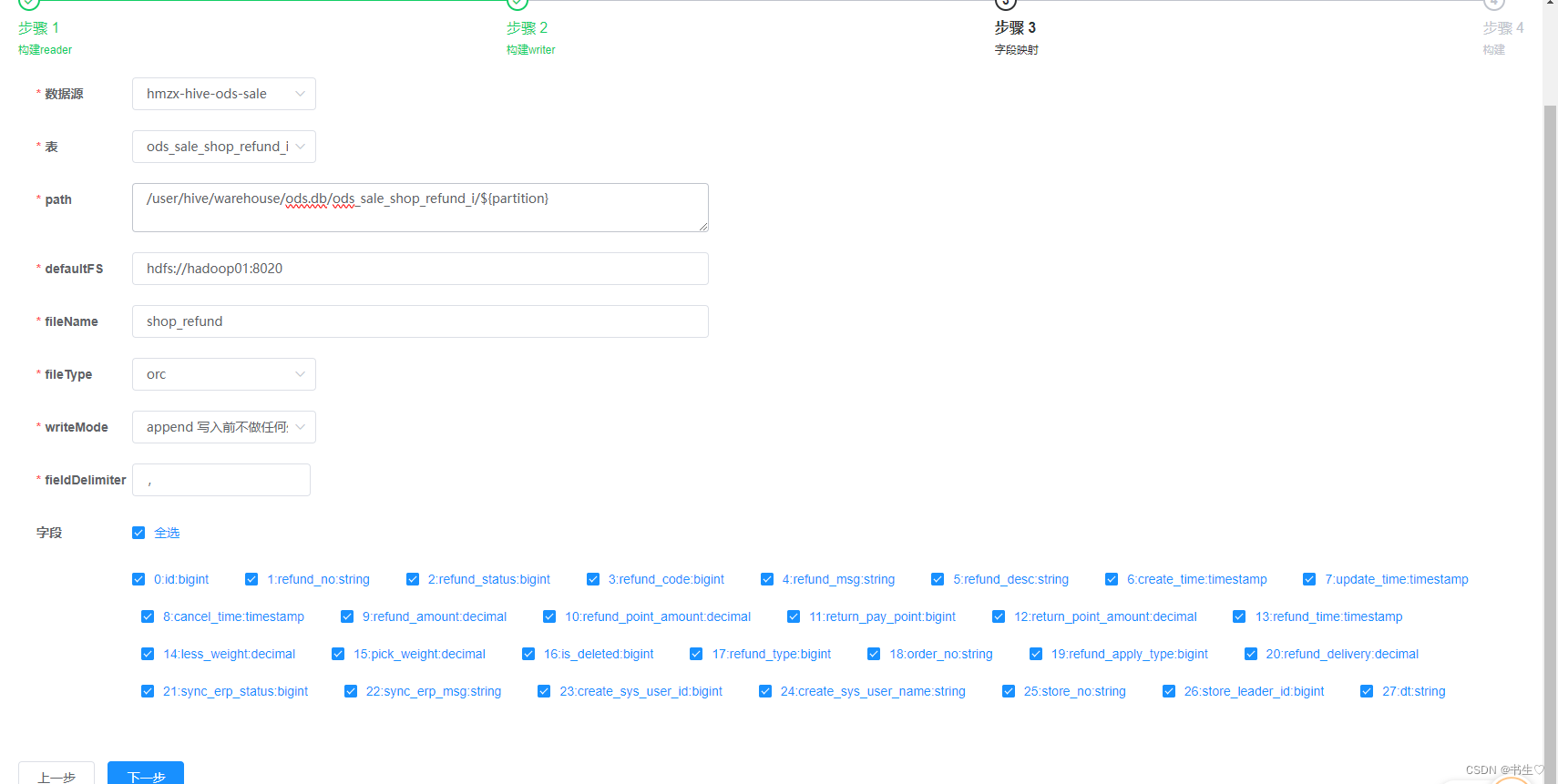
构建hive数据有一点区别:
- hdfs的地址后面要加上一个 ‘ /${partition} ’
- 字段中的dt 分区字段要勾选
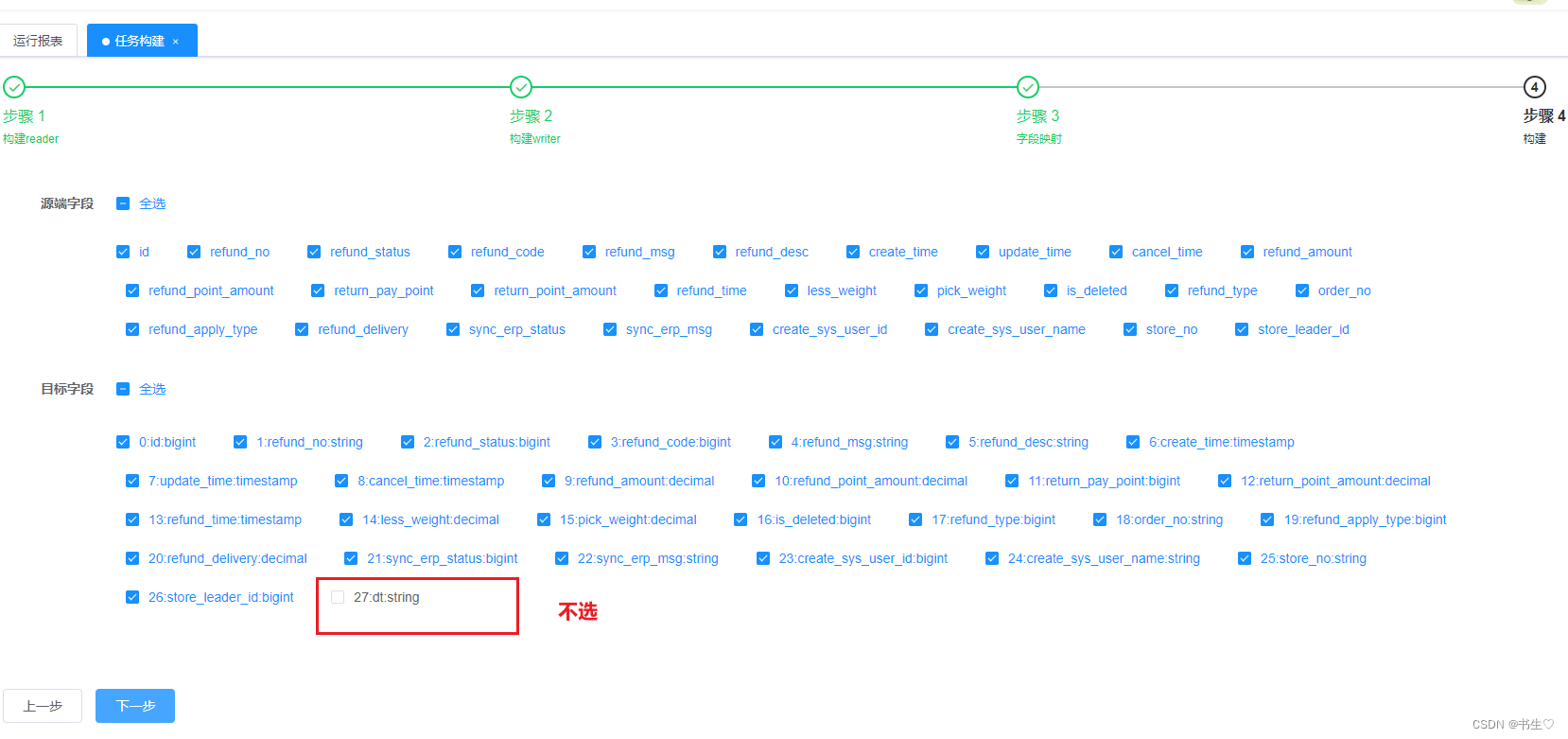
字段映射中的 ,dt字段不要勾选
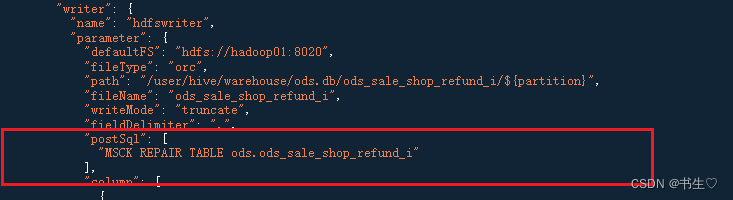
配置模版:同上,注意我们还要添加一行代码,这行代码是为了修复我们的分区的
"postSql":["MSCK REPAIR TABLE ods.ods_sale_shop_refund_i"],
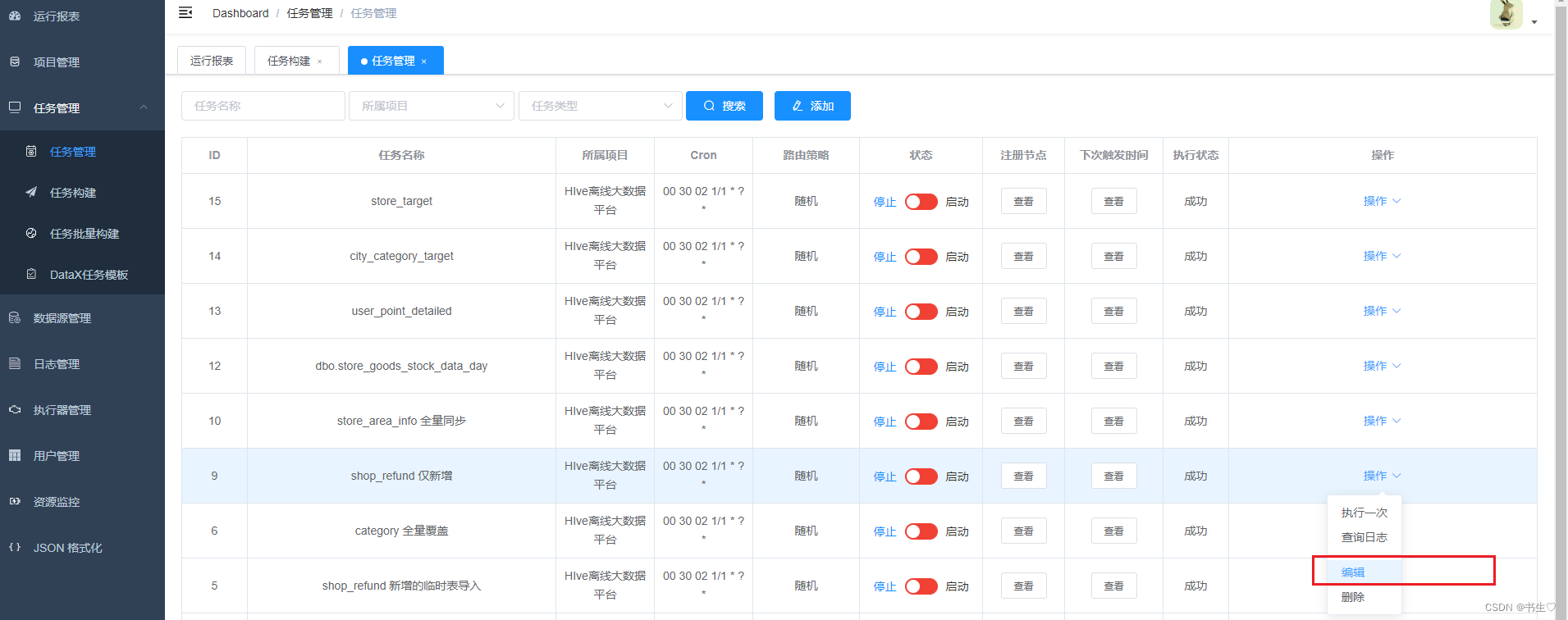
4. 任务管理
这个地方,我们选择编辑,修改一下
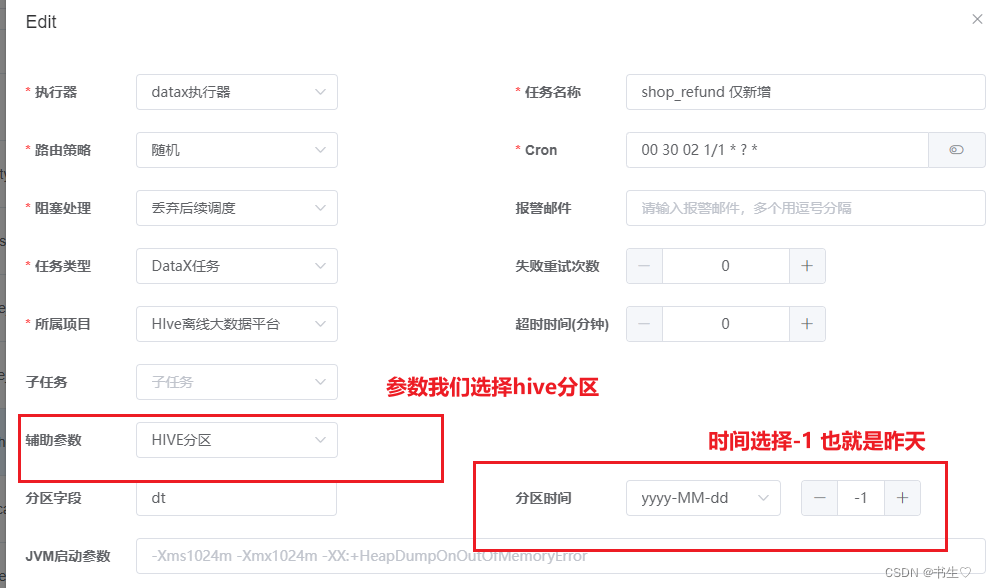
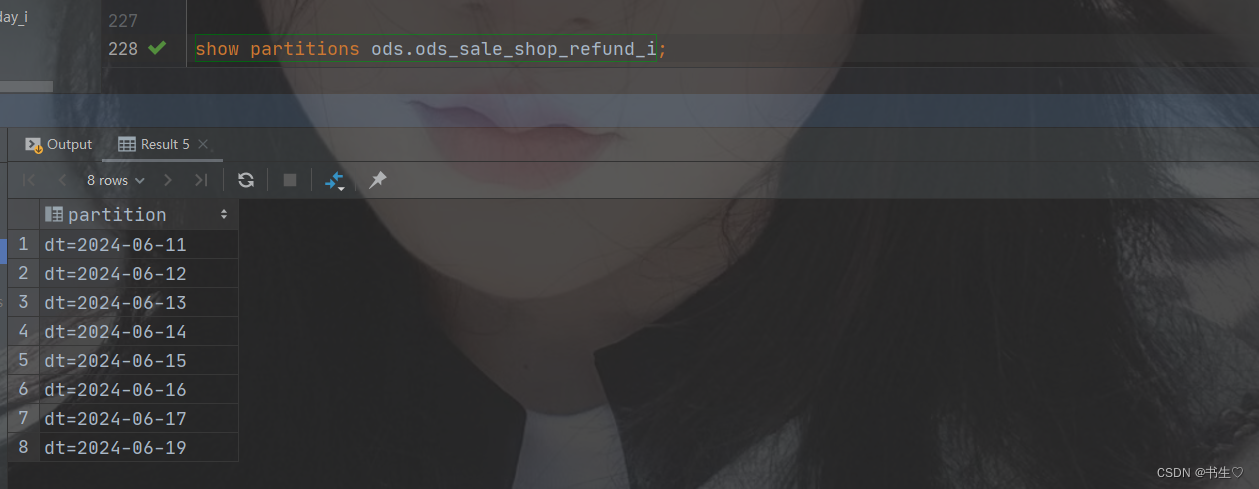
查看分区:
2.3.3 新增及更新导入
以shop_order(商城订单表)
首次导入:
与 仅新增的首次导入流程方案一模一样
增量导入:
--筛选条件
create_time between concat(date_sub(current_date,INTERVAL 1 DAY),' 00:00:00') and concat(date_sub(current_date,INTERVAL 1 DAY),' 23:59:59')
OR
last_update_time between concat(date_sub(current_date,INTERVAL 1 DAY),' 00:00:00') and concat(date_sub(current_date,INTERVAL 1 DAY),' 23:59:59')
--或者:
date_format(create_time,'%Y-%m-%d') = DATE_FORMAT(date_sub(NOW(),INTERVAL 1 DAY),'%Y-%m-%d')
OR
date_format(last_update_time,'%Y-%m-%d') = DATE_FORMAT(date_sub(NOW(),INTERVAL 1 DAY),'%Y-%m-%d')
2.3.4 全量同步
以:门店商品库存天表为例
这里跟全量覆盖表的区别是:ods表是一个分区表,即每次同步全量数据到一个新的分区里,不在进行覆盖
前面流程都是和进新增的模式是一样的,构建hive的时候,注意,添加/${partition},构建的dt字段需要勾选,字段映射不需要,构建的Json数据中添加一行数据。
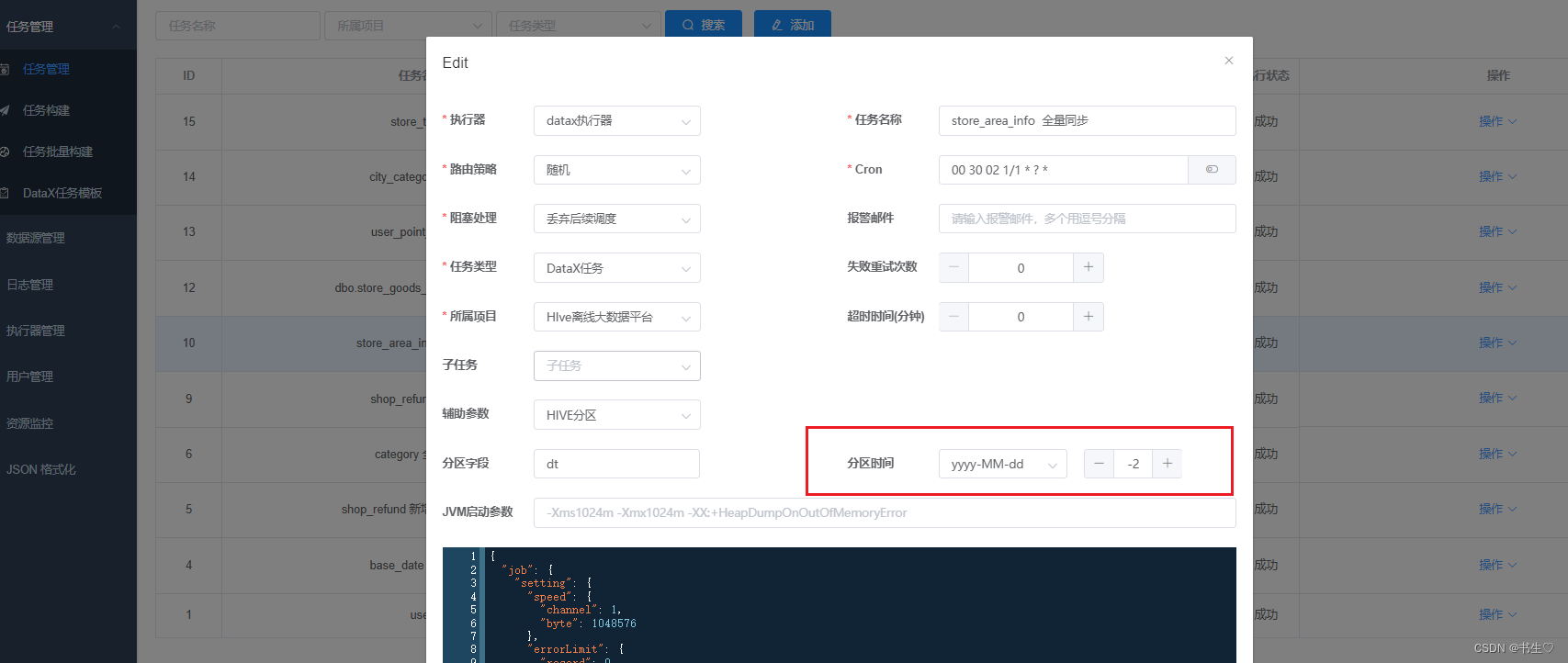
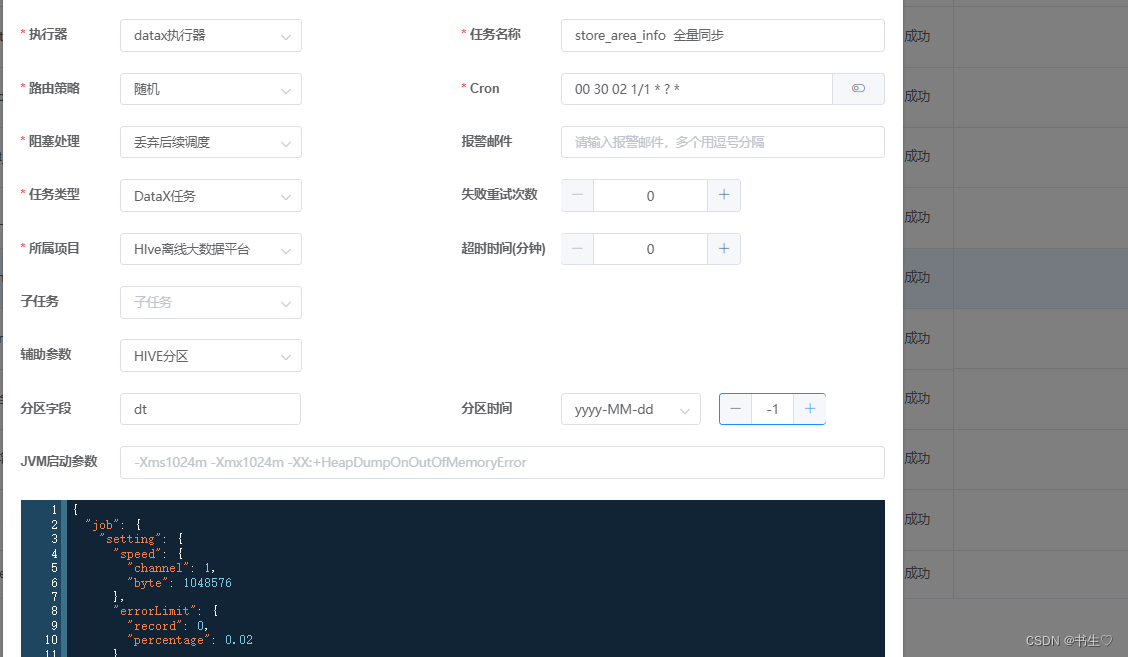
我们假设先将分区时间变为 -2 (前天),执行完后,对数据进行改变,再将分区时间变为 -1 (昨天)在执行一遍,查看区别。















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









