







了解最早以前的只有英文数字字符、控制代码、空格与二进制之间的关系——ASCII码
在计算机内部,所有数据都是使用二进制存储。每一个二进制都代表一位(bit),这一位数有0和1两种状态,在ASCII中是由一个字节表示,也就是8位。最前面的数统一规定为0,那么ASCII编码操作的位数只有7位数,是一个7位的编码标准。因此只能规定128种不同的字符编码,在十进制中为0~127,其中包括26个小写字母、26个大写字母、10个数字、32个符号、33个控制代码(不能打印)和一个空格。
例如:空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。缺点就是:因为太少只有128种,不能代表所有字符,也就是不满足世界互联网的语言需求。
了解万能编码——Unicode码
乱码:世界上存在着多种编码方式,同一串二进制数字可以被解释成不同的符号。因此,想要保存一个文本文件,必须选择编码方式。反而言之,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
Unicode:是一种编码方式,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,使用Unicode 没有乱码的问题。
Unicode 的缺点:Unicode 只规定了所有语言的二进制代码,却没有规定这个二进制代码应该如何存储,因此计算机无法区别Unicode 和ASCII。例如计算机无法区分两个字节一起表示一个符号还是分别表示两个符号。另外,我们知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用两个字节表示,那么每个英文字母前都必然有一个字节是0,这对于存储空间来说是极大的浪费。此时UTF-8代码诞生了
了解UTF-8 码
UTF-8 是在互联网上使用最广的一种Unicode 的实现方式。
UTF-8 是一种变长的编码方式。它可以使用1-6 个字节表示一个符号,根据不同的符号而变化字节长度。(在标准UTF-8编码中,超出基本多语言范围(BMP-Basic Multilingual Plane)的字符被编码为4字节格式,但是在修正的UTF[编码中,他们由代理编码对(surrogatepairs)表示,然后这些代理编码对在序列中分别重新编码。结果标准UTF-8编码中需要4个字节的字符,在修正后的UTF-8编码中将需要6个字节)
UTF-8的编码规则(参考如下黑色背景图):
对于单字节的UTF-8编码,该字节的最高位为0,其余7位用来对字符进行编码(等同于ASCII码)。
对于多字节的UTF-8编码,如果编码包含n 个字节,那么第一个字节的前n位为1,第一个字节的第n+1 位为0,该字节的剩余各位用来对字符进行编码。在第一个字节之后的所有的字节,都是最高两位为"10",其余6位用来对字符进行编码。

UTF-8与Unicode互转流程(重点)
存储过程
描述:
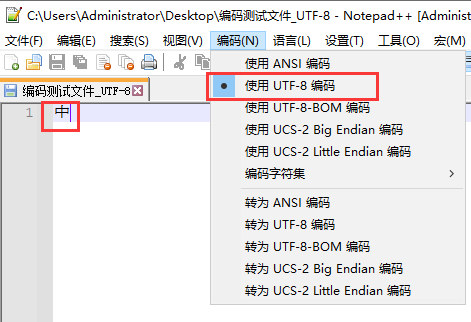
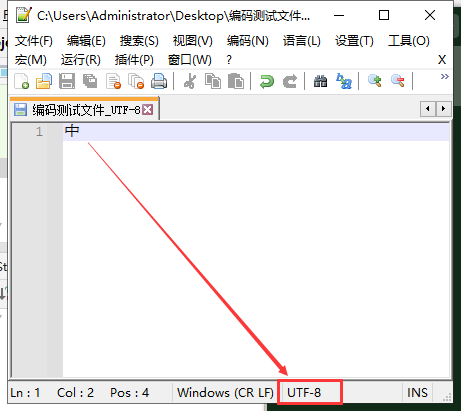
- 在文本框输入"中"一个字符,然后选择UTF-8编码方式保存,此时该文件就是用UTF-8编码方式保存的
- 使用UTF-8解码再次打开文件时发现编码无异常,“中”字也正常显示
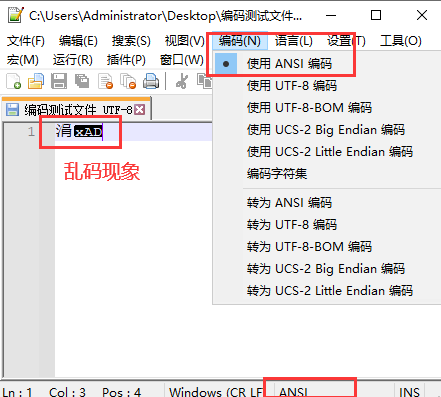
- 如果用了不符合的编码格式解码打开文件就会乱码,例图使用ANSI编码解码打开UTF-8编码格式的文件
- "中"字符在Unicode编码表十进制是20013,Unicode表中对应的是"\u4e2d",也就是十六进制为4E2D,二进制为100 1110 0010 1101
int i = (int)'中';//字符串根据Unicode转十进制 System.out.println(i);//20013 String s1 = Integer.toHexString(i);//十进制转十六进制 System.out.println(s1);//4e2d String s2 = Integer.toBinaryString(i);//十进制转二进制 System.out.println(s2);//100 1110 0010 1101- 然后再将十六进制的4E2D转换成"100 1110 0010 1101"的二进制数,其中
- 4的二进制是100
- E是15,转成二进制就是1110
- 2的二进制是0010
- D是14,转换成二进制就是1101
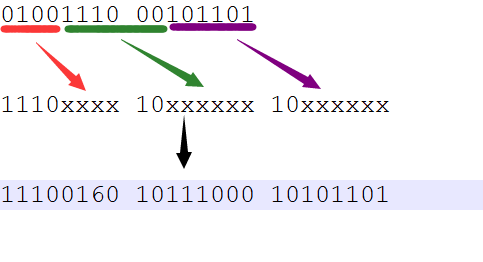
- 如果按照Unicode编码方式存放,此时的二进制"100 1110 0010 1101"会加一个0,变成两个字节"01001110 00101101"存在计算机中,但是这样存入后读取时计算机编码时不知道怎么读,回到之前提出的疑问:"计算机无法区分两个字节一起表示一个符号还是分别表示两个符号"
- 因此我们引入UTF-8完善Unicode存储,使得既可以读又可以写,下面我们查看UTF-8的在不同的Unicode的十六进制值的范围内的存储区别,来选择应该用第几行的方式存储。我们的十六进制“4E2D”明显是属于800-FFFF之间的,因此
- 我们的"4E2D"就选择第三行的方式存储,也就是用三个字节存储我们的Unicode.然后把两个字节的数从左往右填入到第三行的xxxx....中,造出的"11100160 10111000 10101101"就是我们通过UTF-8的编码方式将“中”字存储到磁盘的三个字节
读取过程
描述:
- 通过UTF-8的格式读取数据,先通过开头的"1"的位数从左到右取出几个字节
- 取出UTF-8的XXXX的代替数,也就是Unicode的二进制数"0100111000101101"
- 把二进制数"01001110 00101101"翻译成16进制的数"4E2D"
- 将二进制数前加上"/u",也就是"/u"+"4E2D"组成"/u4E2D"
- 对照Unicode表对照翻译就是"中"字符


















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









