







前言
Bert (Bi-directional Encoder Representations from Transfromers) 预训练语言模型可谓是2018年 NLP 领域最耀眼的模型,看过很多对 Bert 论文和原理解读的文章,但是对 Bert 源码进行解读的文章较少,这篇博客 有一份 TensorFlow 版本的 Bert 源码解读,这里来对 Pytorch 版本的 Bert 源码记录一份 “详细” 注释。
这份基于 Pytorch 的 Bert 源码由 Espresso大神提供,地址在这 https://github.com/aespresso/a_journey_into_math_of_ml ,大家也可以在 Espresso大神 的 B站 观看他的视频,讲得非常不错。
今天记录的这一部分是 bert_model.py 文件,主要实现了 bert 的预训练模型搭建部分。
Bert 源码解读:
1. 模型结构源码: bert_model.py
2. 模型预训练源码:bert_training.py
3. 数据预处理源码:wiki_dataset.py
开始
1. 定义激活函数
def gelu(x):
"""Implementation of the gelu activation function.
For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
Also see https://arxiv.org/abs/1606.08415
"""
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
ACT2FN = {"gelu": gelu, "relu": torch.nn.functional.relu}首先就是定义了 gelu 激活函数,Bert 中不同于传统 Transformer,Bert 中的某些层的激活函数使用了 gelu 来代替 relu,使得具备了更多的随机因素,在 gelu的论文 中,gelu 的实验效果也要优于 relu。
这里是论文中提出的 GELUs(x) 的近似计算的数学公式:
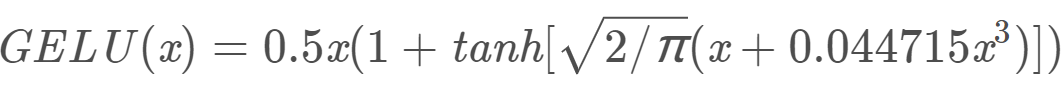
其次定义了 activate function 字典,方便激活函数的使用。
2. 配置参数
class BertConfig(object):
"""Configuration class to store the configuration of a `BertModel`.
"""
def __init__(self,
vocab_size,
hidden_size=384,
num_hidden_layers=6,
num_attention_heads=12,
intermediate_size=384*4,
hidden_act="gelu",
hidden_dropout_prob=0.4,
attention_probs_dropout_prob=0.4,
max_position_embeddings=512*2,
type_vocab_size=256,
initializer_range=0.02
):
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range接下来,定义 BertConfig 类,对 Bert 中的一些参数进行设置,具体的设置项为:
vocab_size : 词典大小
hidden_size : 隐藏层维度 & 字向量维度
num_hidden_layers : Transformer Block 的个数
num_attention_heads : Multi-head Self-Attention 的头数
intermediate_size : Feedforword 线性映射层的维度
hidden_act : 隐藏层激活函数
hidden_dropout_prob : 隐藏层 dropout 概率
attention_probs_dropout_prob : Attention 中使用的 dropout 概率
max_position_embedding : 位置编码的最大长度
type_vocab_size : 用来做 next sentence预测时的分类类别数量,这里预留了256个类别,但用到的只有0,1
initializer_range : 初始化模型参数的标准差
3. Embedding部分
class BertEmbeddings(nn.Module):
def __init__(self, config):
super(BertEmbeddings, self).__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=0)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# embedding矩阵初始化
nn.init.orthogonal_(self.word_embeddings.weight)
nn.init.orthogonal_(self.token_type_embeddings.weight)
# embedding矩阵进行归一化
epsilon = 1e-8
self.word_embeddings.weight.data = \
self.word_embeddings.weight.data.div(torch.norm(self.word_embeddings.weight, p=2, dim=1, keepdim=True).data + epsilon)
self.token_type_embeddings.weight.data = \
self.token_type_embeddings.weight.data.div(torch.norm(self.token_type_embeddings.weight, p=2, dim=1, keepdim=True).data + epsilon)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids, positional_enc, token_type_ids=None):
"""
:param input_ids: 维度 [batch_size, sequence_length]
:param positional_enc: 位置编码 [sequence_length, embedding_dimension]
:param token_type_ids: BERT训练的时候, 第一句是0, 第二句是1
:return: 维度 [batch_size, sequence_length, embedding_dimension]
"""
# 字向量查表
words_embeddings = self.word_embeddings(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = words_embeddings + positional_enc + token_type_embeddings
# embeddings: [batch_size, sequence_length, embedding_dimension]
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings__init__ 部分中,主要是对 Embedding 向量的初始化以及标准化,positional encoding 由于是公式计算得出,所以不用初始化。
forward 函数中,主要实现了 input_ids 与 token_type_ids 由 index token 到 embedding 的转化,以及 将 words embedding、positional encoding、token type embedding 相加生成最终输入 tansformer block 的 embedding,这里在相加后还进行了 Layer normal 和 dropout 的操作,在 embedding 输入的部分做 layer normal 同样是为了加快loss收敛,加快训练速度,但这里不太明白为什么要在输入时就进行 dropout 的操作。
4. Self-Attention机制
class BertSelfAttention(nn.Module):
"""自注意力机制层, 见Transformer(一), 讲编码器 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3102
3102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









