







最近入门BERT,在网上观看了一些网课视频理解了原理,并且找到了pytorch版本的源码,经过一遍阅读有了初步的认知,所以在此记录,温故而知新。
本文所解读的源码链接为:https://github.com/daiwk/BERT-pytorch/tree/master/bert_pytorch
其整体代码框架如下(有些部分我也略有改动,但整体不影响):
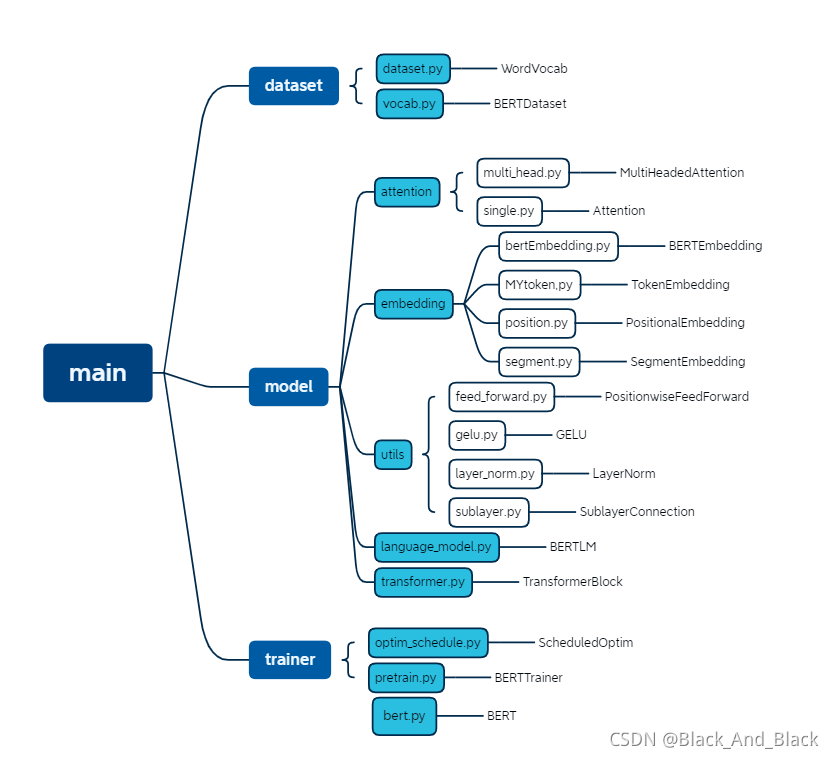
解读一个项目的代码,自然要从main开始,所以我们打开main.py(项目中是__main__.py)后看到首先是对一些路径参数的填写:

我个人的上述自个的参数为
--train_dataset ./corpus/train.tsv --test_dataset ./corpus/test.tsv --vocab_path ./vocab/vocab.txt --output_path output/bert.model
其中train_dataset和test_dataset是指你选的任务的训练数据和测试数据,我们一般称之为corpus(语料库)这里我们选取了GLUE数据集中的MRPC任务的训练集和测试集。而vocab_path指的是vocabulary库(词汇表库),它相当于一个大字典,记录了所有可能出现的单词,后边我们将语料库中的单词转为id时候需要在这个大字典里查找(这个vocab.txt可以去huggingface上找,GLUE数据集网上有许多好心人分享了网盘,但是需要注意的是不同的任务数据的样式是不同的,所以处理起来是有差别的!!比如说有的数据是一个类+一个句子+一个句子,有的是一个类+一个句子)
接下来我将以main函数中每行代
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9194
9194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









