








在人工智能领域,OpenAI 的每一个动作都备受瞩目。近日,OpenAI 联合创始人兼 CEO 萨姆・阿尔特曼(Sam Altman)与 GPT-4.5 的 3 位核心技术人员进行了一场 45 分钟的深度对谈,首次披露了这款强大模型背后诸多不为人知的训练细节。从项目的启动与规模,到 10 万卡集群带来的难题,再到性能提升的显著成果,以及关键的数据效率转向,这一系列内容为我们展现了一幅波澜壮阔的 AI 研发画卷。
GPT-4.5 项目启动与规模:几乎全员上阵的宏大计划
GPT-4.5 项目启动于两年前,堪称 OpenAI 迄今为止最为周密的计划。这一项目涉及数百人团队的紧密协作,阿尔特曼甚至称 OpenAI 为了这一项目几乎是 “全员上阵”。当时,OpenAI 即将上线一个新的大型计算集群,团队敏锐地捕捉到了这个机会。负责 GPT-4.5 预训练机器学习算法的 Alex Paino 回忆道,团队为此做了大量前期工作,确定模型需要包含的功能,并进行了一系列降低风险的运行测试。
从一开始,机器学习团队和系统团队便展开了密切合作。系统架构师 Amin Tootoonchian 表示,在明确要训练的模型之前,两个团队就开始了深度协同,试图对机器学习和系统方面做出准确预测,尽量缩小预期和现实之间的差距。然而,由于工作节奏快,且要充分利用最新的计算资源,模型训练难以提前进行完美规划。他们几乎总是带着许多未解决的问题开启训练,并在运行过程中努力克服挑战。
为了降低风险和为训练做准备,这是一个漫长的执行过程,而训练本身更是一个庞大的工程,需要众多人员长期投入大量精力和动力,才能推动项目逐步前行。可以说,GPT-4.5 从启动之初,就承载着 OpenAI 对未来 AI 发展的巨大期望,以一种宏大而复杂的姿态开启了它的研发之旅。
10 万卡集群难题:暴露基础设施深层次故障
当集群规模从 1 万卡拓展到 10 万卡时,OpenAI 团队遇到了诸多棘手问题。Amin Tootoonchian 指出,部分问题其实在小规模阶段就能被敏锐的系统开发者观察到,但还有一些问题并非大规模训练阶段所独有,只是在规模提升后,其影响被放大成了灾难性问题,而团队并未提前预料到这些问题会恶化到如此程度。
在 10 万卡集群这个大规模的样本池中,基础设施的各种问题暴露无遗。网络方面出现了状况,单个加速器也频繁出问题。几乎所有组件都需要按预期工作,才能保证训练产生预期结果,而任何一个组件的故障都可能影响全局。其中,有一个隐藏的小 bug 让集群频繁报错,直到训练进度条走过约 40% 才被揪出。这一问题的排查和修复耗费了团队大量的时间和精力。
面对这些基础设施的问题,团队不得不做出艰难的抉择:到底是推迟启动,等待问题解决,还是提早启动并在过程中解决问题。最终,他们选择了后者,采取 “边修边训” 的策略,尽可能地处理好这些节点,应对未知因素,并为模型训练制定灵活的计划。这一过程不仅考验着团队的技术能力,更考验着他们的应变能力和决策智慧。
性能提升成果:实现约 10 倍性能飞跃
尽管在训练过程中遭遇了重重困难,OpenAI 团队依然取得了令人瞩目的性能提升成果。Alex Paino 表示,他们的目标是让 GPT-4.5 的能力比 GPT-4 聪明 10 倍,而最终,就投入的有效计算而言,他们得到了一个达到这一目标的模型。GPT-4 至 GPT-4.5 的性能提升约为 10 倍,获得了 “难以量化但全方位增强的智能”,这一成果甚至让 OpenAI 员工们自己都感到意外。
这种性能的大幅提升,不仅体现在模型处理任务的速度上,更体现在其对自然语言的理解和生成能力的深度与细腻程度上。在各种复杂的语言任务中,GPT-4.5 展现出了远超 GPT-4 的表现,能够更好地理解用户的意图,生成更符合语境、更具逻辑性和创造性的回答。同时,OpenAI 团队在完成 GPT-4.5 的过程中,技术栈也得到了极大改进。如今,仅用 5 - 10 人便能够复刻出 GPT-4 级别的大模型。例如,他们在训练 GPT-4.5 的过程中训练了 GPT-4o,这是一个 GPT-4 级别的模型,使用了很多来自 GPT-4.5 研究项目的相同内容重新训练,而进行那次训练所用的人力要少得多。这充分体现了团队在技术研发上的巨大进步和效率提升。
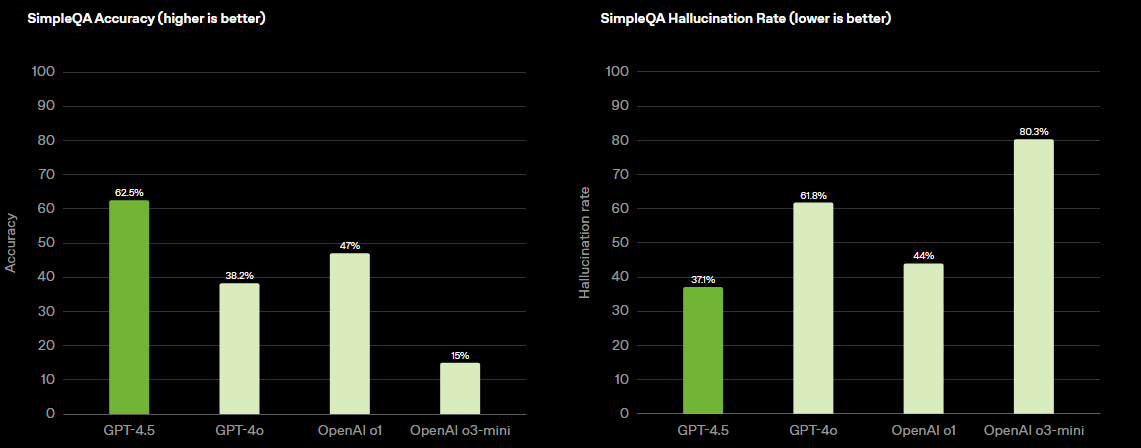
关键转向数据效率:未来性能提升的核心
随着对模型性能提升的不断追求,OpenAI 团队已经清晰地意识到,要实现下一个 10 倍乃至百倍的性能提升,算力已不再是瓶颈,关键在于数据效率。Alex Paino 指出,Transformer 架构(也就是 GPT 所采用的架构)在利用数据方面虽然已经非常高效,但当计算能力快速增长,而数据增长相对缓慢时,数据就会成为标准模式的瓶颈。此时,需要算法创新,开发出能够利用更多算力,从同样数量的数据中学到更多知识的方法。
研究数据效率与算法的 Daniel Selsam 进一步强调,在未来大规模模型的研发中,如何充分利用算力以从同一数量的数据中学习到更多知识,正在成为突破的关键。这意味着,AI 的发展正在步入一个由数据主导的全新时代,数据效率将成为决定模型性能提升的核心因素。为了提升数据效率,OpenAI 团队正在不断探索数据长尾效应与 Scaling Law 之间的关系,通过深入研究这些量化的提升,寻找突破的可能性。同时,系统正从单集群转向多集群架构,未来的训练可能涉及 1000 万块 GPU 规模的协作学习,这对系统的容错能力提出了更高的要求。团队需要进一步优化系统设计,确保在大规模协作学习中,能够高效地利用数据,提升模型性能。
GPT-4.5 的训练过程是一个充满挑战与突破的过程。从项目启动时的宏大规划,到 10 万卡集群带来的基础设施难题,再到实现 10 倍性能提升的卓越成果,以及关键转向数据效率的未来布局,OpenAI 团队在 AI 研发的道路上不断探索前行。他们所积累的经验和取得的技术突破,不仅为 GPT-4.5 的成功奠定了基础,也为整个 AI 领域的未来发展提供了宝贵的借鉴和启示。我们有理由期待,在数据效率这一关键因素的驱动下,OpenAI 以及整个 AI 行业能够实现更加惊人的性能飞跃,创造出更加智能、强大的 AI 模型,为人类社会带来更多的变革与惊喜。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











