







Firecrawl 部署安装及 Dify 调用(保证好使)
简介
Firecrawl 是一个可以提供 API 服务的开源爬虫工具,我们只需要给它一个 URL,无需提供网站地图(sitemap),它就能抓取该 URL 的当前网页或更深层的网页,并可以把抓到的数据转变成 markdown 格式,这种格式更适合 LLM 阅读,在当今的 AI 浪潮下可以说是非常适合了。
截至2025年3月 Firecrawl 支持以下功能:
- Scrape:抓取 URL 当前页面的内容,可以以 markdown 格式返回
- Crawl:递归抓取 URL 的子域,并可以以 markdown 格式返回内容
- Map:可以非常快速的获取输入网站的所有 URL
- Extract:使用 LLMs 从页面中提取结构化数据
前期准备
一、环境要求
- 硬件要求:2核、4GB 内存、50GB 硬盘
- 软件要求:Ubuntu 24.04(VMware 虚拟环境)、Docker、Git
二、网络环境
- 本地网络:部署时可以使用 VMware 的 NAT 模式,如果只是本机使用就已经无需调整了,如果是需要内网中为其他设备提供服务,那就需要配置成 bridge(桥接)模式了。
- 外部网络:我们是把 Firecrawl 部署在 docker 中,所以构建时需要从网络上拉去镜像,国内虽然有镜像源,但是并没有外面的全,所以可能会导致超时导致构建失败,所以提前准备一个靠谱的代理(科学上网)是非常必要的。
三、docker 的安装
关于 docker 的安装在这里就不进行细说了,可以跟着这篇博客来操作:https://blog.csdn.net/qq_75277260/article/details/140246580
Firecrawl 的安装
一、检查系统的网络环境
在装好 Ubuntu 系统后最先开始检查的及时网络问题了,首先我们要把之前提到的代理打开,并调节到全局模式(拉取镜像的成败关键)

同时即使开了代理有的还是会失败,这是由于运营商的问题,因为每个运营商对于不同 IP 访问的路由设置都不一样,目前在广东测试发现电信是最好使的。
之后就进入 Ubuntu 虚拟机进行 ping 测,命令如下:
ping www.google.com
ping www.github.com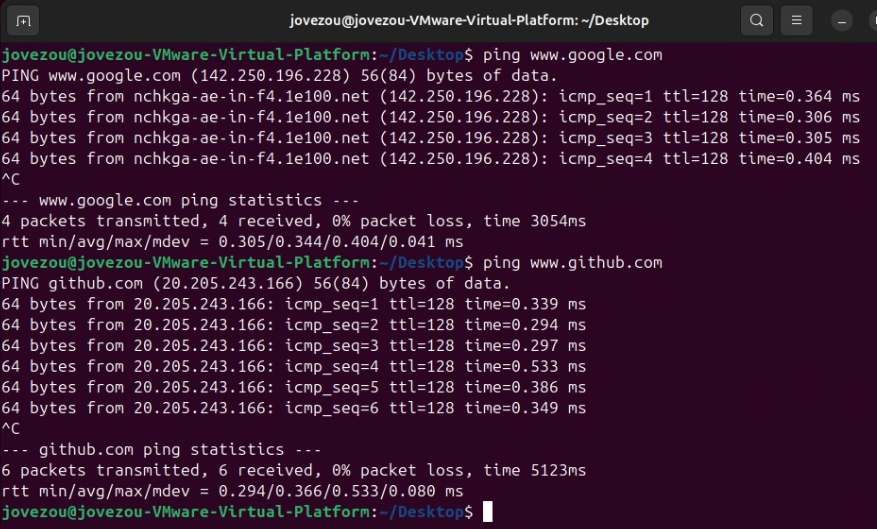
如果到最后实在是没办法了,可以拿我提前安装好的镜像直接导入到 docker 当中来使用,这样就可以避免网络问题了,链接在“备份与加载 Firecrawl 的镜像”的部分。
二、下载 Firecrawl 源码
Firecrawl 是一个开源软件,我们可以直接上 Github 上搜索并下载其源码,链接为:https://github.com/mendableai/firecrawl,可以直接下载 ZIP 压缩包然后通过 WinSCP 之类的软件传出到 Ubuntu 当中
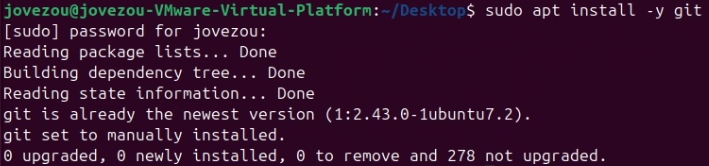
1、本次我们使用 git 命令来克隆代码。git 命令安装过程如下:
Ubuntu:
sudo apt-get install -y git如果已经安装过会如下图所示
Windows:
直接打开该链接下载:https://git-scm.com/downloads
下载完成后双击安装,安装选项默认即可。
2、然后我们去 Github 上获取克隆链接,如下图所示
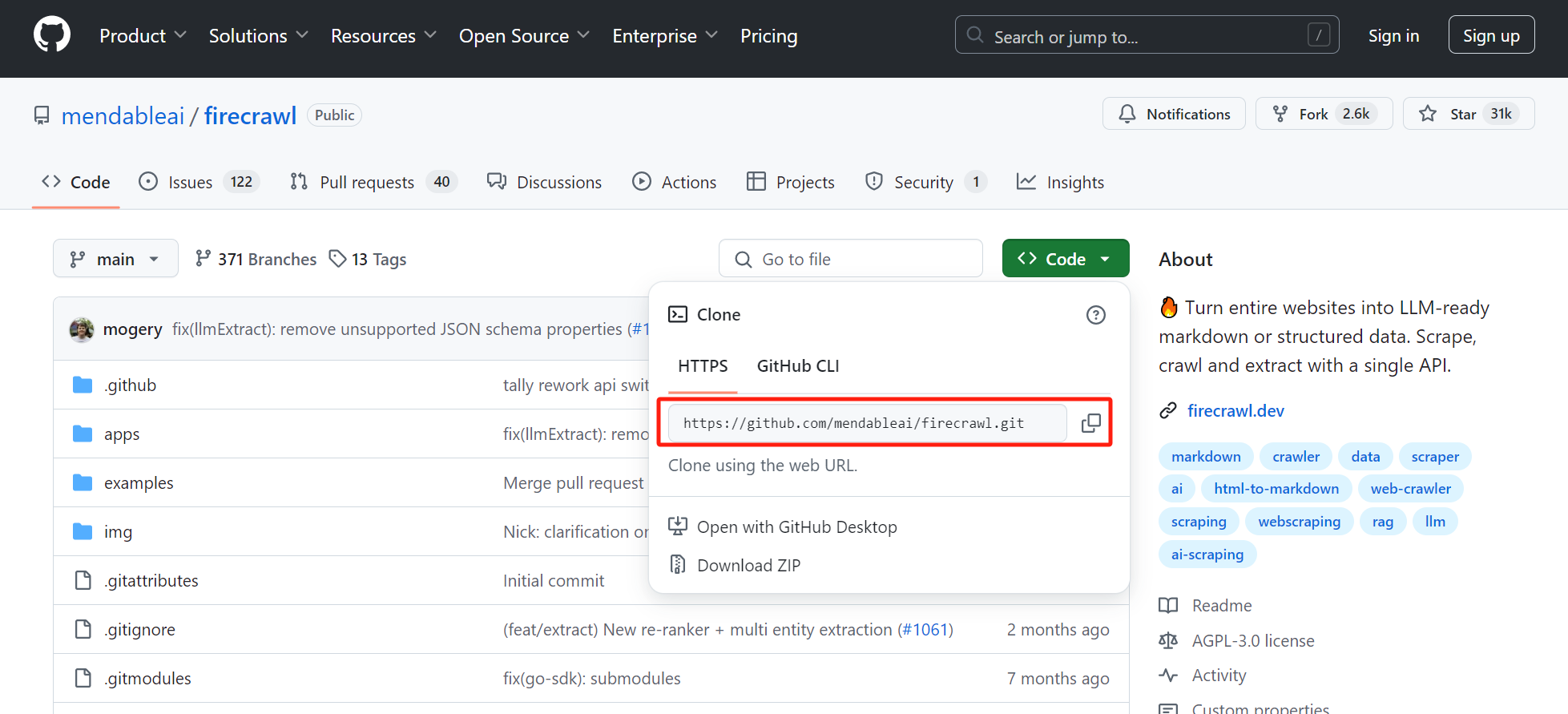
进入命令行输入以下命令(该命令会下载到当前所在目录下)
# 例如,当前目录是 /home/jovezou/ 他就会下载到这个目录下
cd /home/jovezou/
git clone https://github.com/mendableai/firecrawl.git
三、Firecrawl 环境变量与配置文件的修改
下载完成源码后我们需要准备两个文件,分别是 .env 和 docker-compose.yaml。
.env:该文件就是该 Firecrawl 的环境变量,api key 之类的都是在该文件中设置,在 ./firecrawl/apps/api 目录下有一个 .env.example 的参考文件

如果没什么特殊需要设置的直接使用下面的命令重命名为 .env 并复制到 ./firecrawl/ 下即可
cd ./firecrawl/apps/api/
# 复制到 ./firecrawl 下
cp ./.env.example ../../.env
在 .env 文件中我修改了以下配置
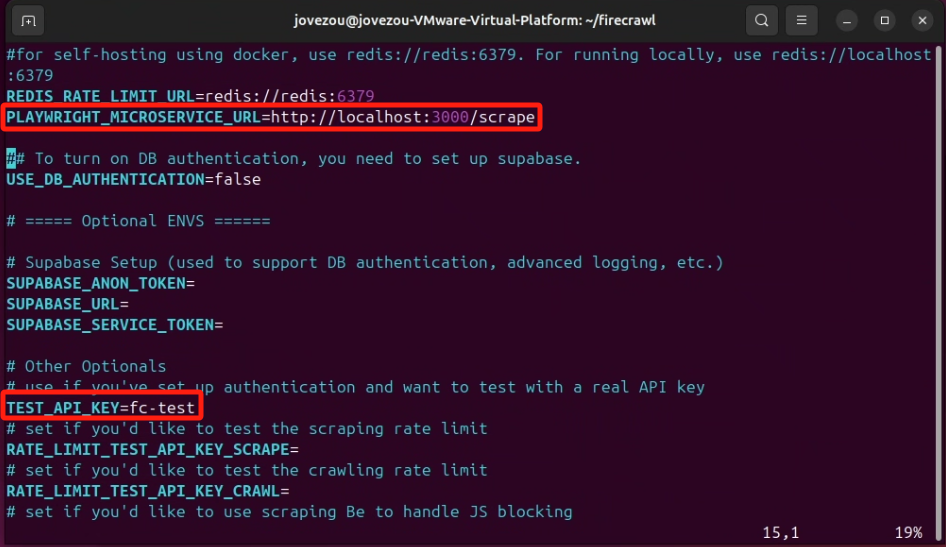
如果需要可以直接复制我的环境变量,如下所示
# .env
# ===== Required ENVS ======
NUM_WORKERS_PER_QUEUE=8
PORT=3002
HOST=0.0.0.0
#for self-hosting using docker, use redis://redis:6379. For running locally, use redis://localhost:6379
REDIS_URL=redis://redis:6379
#for self-hosting using docker, use redis://redis:6379. For running locally, use redis://localhost:6379
REDIS_RATE_LIMIT_URL=redis://redis:6379
PLAYWRIGHT_MICROSERVICE_URL=http://localhost:3000/scrape
## To turn on DB authentication, you need to set up supabase.
USE_DB_AUTHENTICATION=false
# ===== Optional ENVS ======
# Supabase Setup (used to support DB authentication, advanced logging, etc.)
SUPABASE_ANON_TOKEN=
SUPABASE_URL=
SUPABASE_SERVICE_TOKEN=
# Other Optionals
# use if you've set up authentication and want to test with a real API key
# 这里是设置 api key 的,但是内网使用的话可以随意设置的
TEST_API_KEY=fs-test
# set if you'd like to test the scraping rate limit
RATE_LIMIT_TEST_API_KEY_SCRAPE=
# set if you'd like to test the crawling rate limit
RATE_LIMIT_TEST_API_KEY_CRAWL=
# set if you'd like to use scraping Be to handle JS blocking
SCRAPING_BEE_API_KEY=
# add for LLM dependednt features (image alt generation, etc.)
OPENAI_API_KEY=
BULL_AUTH_KEY=@
# use if you're configuring basic logging with logtail
LOGTAIL_KEY=
# set if you have a llamaparse key you'd like to use to parse pdfs
LLAMAPARSE_API_KEY=
# set if you'd like to send slack server health status messages
SLACK_WEBHOOK_URL=
# set if you'd like to send posthog events like job logs
POSTHOG_API_KEY=
# set if you'd like to send posthog events like job logs
POSTHOG_HOST=
# set if you'd like to use the fire engine closed beta
FIRE_ENGINE_BETA_URL=
# Proxy Settings for Playwright (Alternative you can can use a proxy service like oxylabs, which rotates IPs for you on every request)
PROXY_SERVER=
PROXY_USERNAME=
PROXY_PASSWORD=
# set if you'd like to block media requests to save proxy bandwidth
BLOCK_MEDIA=
# Set this to the URL of your webhook when using the self-hosted version of FireCrawl
SELF_HOSTED_WEBHOOK_URL=
# Resend API Key for transactional emails
RESEND_API_KEY=
# LOGGING_LEVEL determines the verbosity of logs that the system will output.
# Available levels are:
# NONE - No logs will be output.
# ERROR - For logging error messages that indicate a failure in a specific operation.
# WARN - For logging potentially harmful situations that are not necessarily errors.
# INFO - For logging informational messages that highlight the progress of the application.
# DEBUG - For logging detailed information on the flow through the system, primarily used for debugging.
# TRACE - For logging more detailed information than the DEBUG level.
# Set LOGGING_LEVEL to one of the above options to control logging output.
LOGGING_LEVEL=INFOdocker-compose.yaml:该文件就是该 Firecrawl 的 docker 配置文件了,这里面定义了需要什么镜像和具体镜像的配置,Firecrawl 把该文件默认就放在根目录下(./firecrawl/)

同样的,如果没有什么特殊需求可以直接使用该文件当中的配置,如果在部署时发现与内网 IP 发生冲突或与本机的应用端口发生冲突就可以在该文件当中进行修改配置。
四、Firecrawl 构建
正式进入 Firecrawl 构建前我们可以通过国内的镜像源来下载一些依赖镜像,以提高构建的成功率
1、镜像加速(如果在安装 Docker 的时候已经执行过了请忽略)
# 新版的 Docker 使用 /etc/docker/daemon.json 来配置 Daemon
# 请在该配置文件中加入(没有该文件的话,请先建一个)Docker 中国官方加速
sudo vim /etc/docker/daemon.json
# 以下为文件内容
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"registry-mirrors": [
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc"
]
}重启 docker 服务以应用镜像加速
sudo systemctl restart docker2、拉去依赖镜像
docker pull python
docker pull golang:1.24
docker pull node:18-slim
docker pull redis:alpine3、构建 Firecrawl
注意:构建命令的执行一定要在 docker-compose.yaml 文件所在目录下执行
# 例如,Firecrawl 在 /home/jovezou/ 下
cd /home/jovezou/firecrawl/
docker compose build
五、Firecrawl 运行
构建完成后使用以下命令启动 Firecrawl,注意还是要在 ./firecrawl/ 目录下
docker compose up # 为了方便查看日志先不使用 -d 参数(后台运行)
启动完成后在浏览器输入以下 URL 来进行测试
http://192.168.174.130:3002/test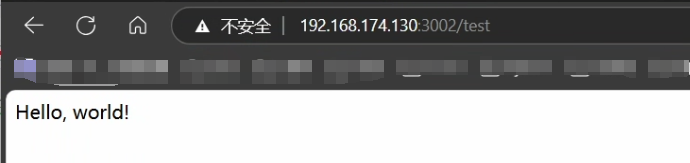
Windows 中的 Docker
当前基于 WSL2 的加持下 Windows 下都能运行专为 Linux 开发的软件,例如 Docker。我们可以从 Docker 的官网下载 Docker Desktop 在 Windows 上使用 Docker
安装完成后 Docker Desktop 会要求你安装 WSL2,你只需回车安装即可(千万不要自己使用微软提供的命令来安装,超级慢),同时在安装的过程中也会配置环境变量,这样你在 cmd 当中就可以使用 docker 命令了。
至此后面 Firecrawl 的安装步骤和命令都和 Ubuntu 当中的无异了。
关于 Docker 容器网络的修改
当需要把 Firecrawl 放开给内网的其他用户使用时,Firecrawl 的 Docker 容器是以 172.18.0.0/16 开始分配的,如果内网也是使用该地址的话,就会遇到 IP 冲突的问题,导致服务不可用了,这个时候就需要修改 docker-compose.yaml 的配置了。
修改网络的配置有几步:
- 对 docker 网络进行修改
- 对各个容器绑定的网络进行修改,换个说法就是让容器加入不同的网络
Docker 网络的名称:Docker 网络的名称是由写在开头的 name 字段和写在结尾的具体网络名称结合起来决定的,像 Firecrawl 的就是 firecrawl-backend,为了方便区分,我给前半部分定义为 Docker 网络的姓,后半部分定义为 Docker 网络的名。

下面为具体的配置,标红的为修改网络时需要修改的地方
name: firecrawl # Docker 网络名称的姓
x-common-service: &common-service
# NOTE: If you want to build the service locally,
# uncomment the build: statement and comment out the image: statement
# image: ghcr.io/mendableai/firecrawl
build: apps/apiulimits:
nofile:
soft: 65535
hard: 65535
networks:# 对各个容器绑定的网络进行修改
- backend
extra_hosts:
- "host.docker.internal:host-gateway"x-common-env: &common-env
REDIS_URL: ${REDIS_URL:-redis://redis:6379}
REDIS_RATE_LIMIT_URL: ${REDIS_URL:-redis://redis:6379}
PLAYWRIGHT_MICROSERVICE_URL: ${PLAYWRIGHT_MICROSERVICE_URL:-http://playwright-service:3000/scrape}
USE_DB_AUTHENTICATION: ${USE_DB_AUTHENTICATION}
OPENAI_API_KEY: ${OPENAI_API_KEY}
OPENAI_BASE_URL: ${OPENAI_BASE_URL}
MODEL_NAME: ${MODEL_NAME}
MODEL_EMBEDDING_NAME: ${MODEL_EMBEDDING_NAME}
OLLAMA_BASE_URL: ${OLLAMA_BASE_URL}
SLACK_WEBHOOK_URL: ${SLACK_WEBHOOK_URL}
BULL_AUTH_KEY: ${BULL_AUTH_KEY}
TEST_API_KEY: ${TEST_API_KEY}
POSTHOG_API_KEY: ${POSTHOG_API_KEY}
POSTHOG_HOST: ${POSTHOG_HOST}
SUPABASE_ANON_TOKEN: ${SUPABASE_ANON_TOKEN}
SUPABASE_URL: ${SUPABASE_URL}
SUPABASE_SERVICE_TOKEN: ${SUPABASE_SERVICE_TOKEN}
SCRAPING_BEE_API_KEY: ${SCRAPING_BEE_API_KEY}
SELF_HOSTED_WEBHOOK_URL: ${SELF_HOSTED_WEBHOOK_URL}
SERPER_API_KEY: ${SERPER_API_KEY}
SEARCHAPI_API_KEY: ${SEARCHAPI_API_KEY}
LOGGING_LEVEL: ${LOGGING_LEVEL}
PROXY_SERVER: ${PROXY_SERVER}
PROXY_USERNAME: ${PROXY_USERNAME}
PROXY_PASSWORD: ${PROXY_PASSWORD}
SEARXNG_ENDPOINT: ${SEARXNG_ENDPOINT}
SEARXNG_ENGINES: ${SEARXNG_ENGINES}
SEARXNG_CATEGORIES: ${SEARXNG_CATEGORIES}services:
playwright-service:
build: apps/playwright-service-ts
environment:
PORT: 3000
PROXY_SERVER: ${PROXY_SERVER}
PROXY_USERNAME: ${PROXY_USERNAME}
PROXY_PASSWORD: ${PROXY_PASSWORD}
BLOCK_MEDIA: ${BLOCK_MEDIA}
networks:
- backendapi:
<<: *common-service
environment:
<<: *common-env
HOST: "0.0.0.0"
PORT: ${INTERNAL_PORT:-3002}
FLY_PROCESS_GROUP: app
depends_on:
- redis
- playwright-service
ports:
- "${PORT:-3002}:${INTERNAL_PORT:-3002}"
command: [ "pnpm", "run", "start:production" ]worker:
<<: *common-service
environment:
<<: *common-env
FLY_PROCESS_GROUP: worker
depends_on:
- redis
- playwright-service
- api
command: [ "pnpm", "run", "workers" ]redis:
# NOTE: If you want to use Valkey (open source) instead of Redis (source available),
# uncomment the Valkey statement and comment out the Redis statement.
# Using Valkey with Firecrawl is untested and not guaranteed to work. Use with caution.
image: redis:alpine
# image: valkey/valkey:alpinenetworks:
- backend
command: redis-server --bind 0.0.0.0networks:
backend: # Docker 网络名称的名
driver: bridge# 对 docker 网络进行修改,修改容器的网段
ipam:
config:
- subnet: 169.254.20.0/24
gateway: 169.254.20.1
修改完成后我们执行以下命令来刷新一下 Docker 中容器的网络配置
#
cd /home/jovezou/firecrawl/
docker compose down # 一定要用 down,如果只用 stop 网络还是会存在的,而 down 会删除网络后重建,这就会重新读取配置文件了
docker compose up -d # 启动完成后,后台执行使用以下命令查看网络是否成功刷新
docker network ls
NETWORK ID NAME DRIVER SCOPE
a3aa1ddbabaf bridge bridge local
0ad4a68a3fed docker_default bridge local
8dbe0534bf14 docker_ssrf_proxy_network bridge local
ed326efaf97a firecrawl_backend bridge local
0ca63795ccdf host host local
d95b56d318f2 none null local
e9ada2586038 ragflow_docker_ragflow bridge local
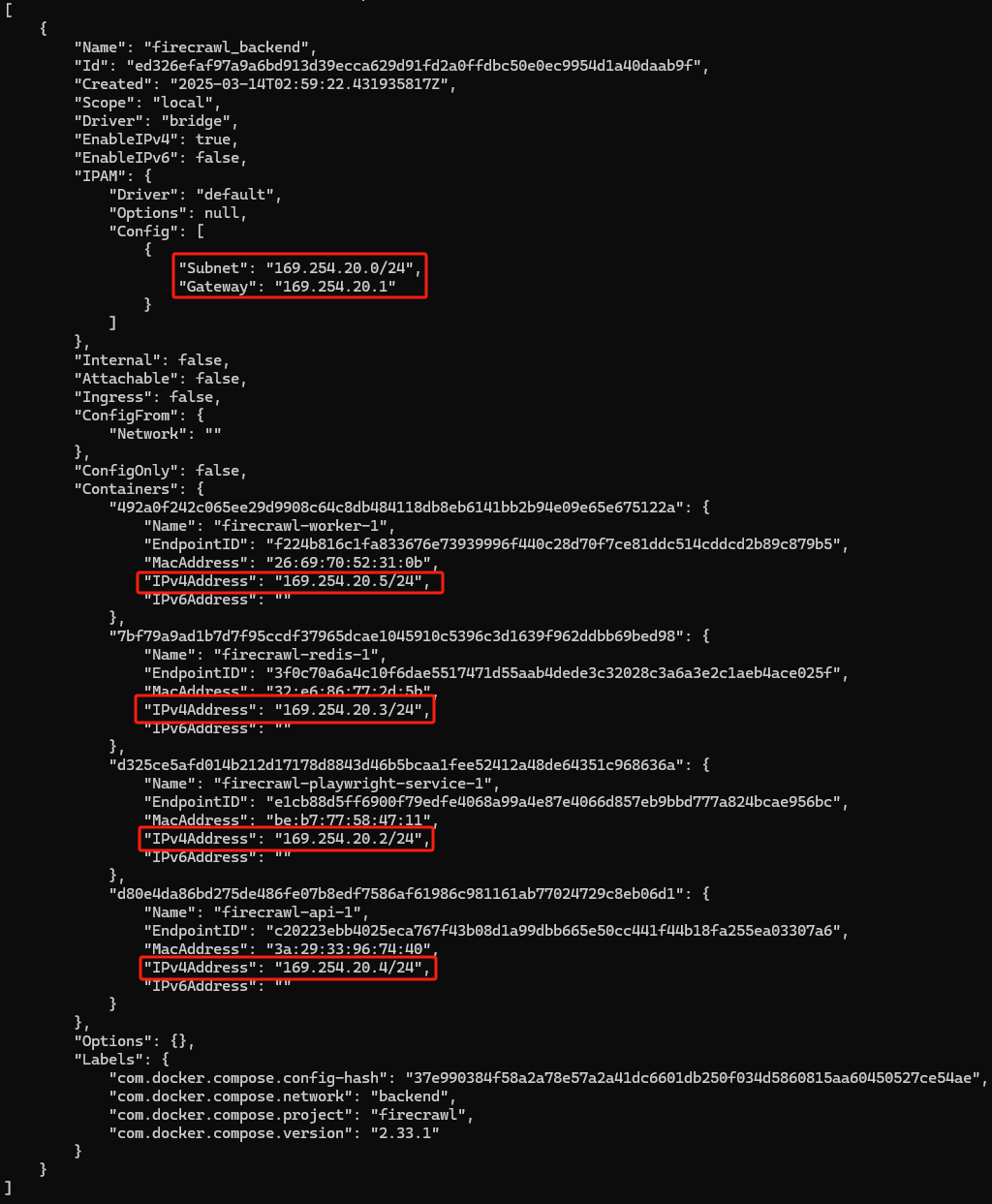
docker network inspect ed326efaf97a网络成功刷新后如下图所示
备份与加载 Firecrawl 的镜像
Docker 镜像的构建和拉去在国内的网络环境下是有一定难度的,这样无疑大大降低了容器的便捷性,而我们如果想要多在几台不同的机器上部署 Firecrawl 是不是每次都要重新构建呢?其实并不需要,我们只需要先在一台机器上进行搭建,然后备份相应的镜像,最后再拷贝到需要部署的机器上把镜像进行加载就可以快速的部署,备份和加载的过程如下
一、备份 Firecrawl 的镜像
1、Firecrawl 需要备份的镜像有:firecrawl-api、firecrawl-worker、firecrawl-playwright-service、redis,我们可以使用以下命令来查看
docker image ls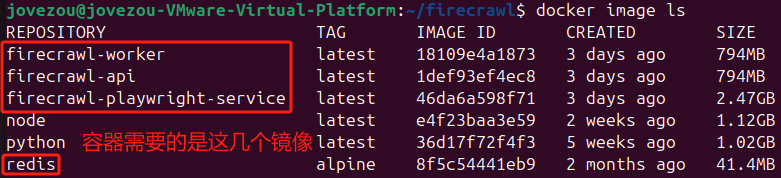
2、使用下面的命令来进行备份
docker save -o /home/jovezou/firecrawl_images/firecrawl-worker.tar firecrawl-worker
docker save -o /home/jovezou/firecrawl_images/firecrawl-api.tar firecrawl-api
docker save -o /home/jovezou/firecrawl_images/firecrawl-playwright-service.tar firecrawl-playwright-service
docker save -o /home/jovezou/firecrawl_images/redis.tar redis
备份好的镜像:https://pan.baidu.com/s/1E23srEQAzdFrbA8Oh9-pCw?pwd=7jgi 提取码:7jgi
二、加载 Firecrawl 的镜像
将备份的镜像拷贝到需要部署的机器之后使用以下命令进行镜像的载入
# 假设镜像存储的路径为 /home/jovezou/firecrawl_images/
docker load -i /home/jovezou/firecrawl_images/firecrawl-worker.tar firecrawl-worker
docker load -i /home/jovezou/firecrawl_images/firecrawl-api.tar firecrawl-api
docker load -i /home/jovezou/firecrawl_images/firecrawl-playwright-service.tar firecrawl-playwright-service
docker load -i /home/jovezou/firecrawl_images/redis.tar redis加载完成后可以使用以下命令查看是否加载成功
docker image ls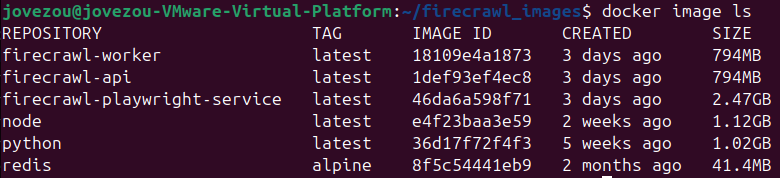
当然也是需要重新下载源码以及修改环境变量和配置文件的,请重复前面 Firecrawl 安装的第三步,在一切处理完成后就可以使用以下命令来启动了
# 假设下载源代码的路径为 /home/jovezou/firecrawl/
cd /home/jovezou/firecrawl/
docker compose up -dDify 的调用
1、在部署好的 Dify(v1.0.0)当中安装 Firecrawl 插件
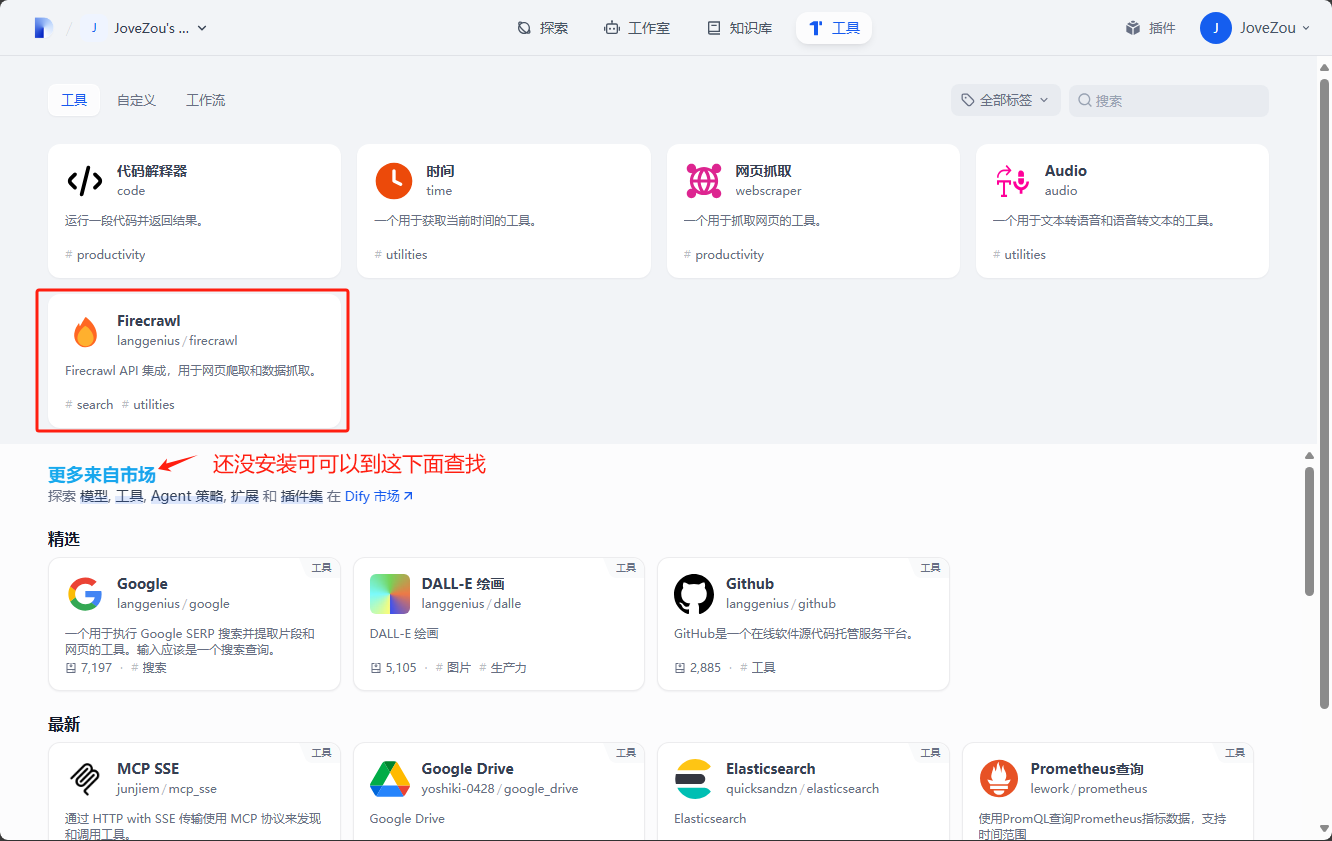
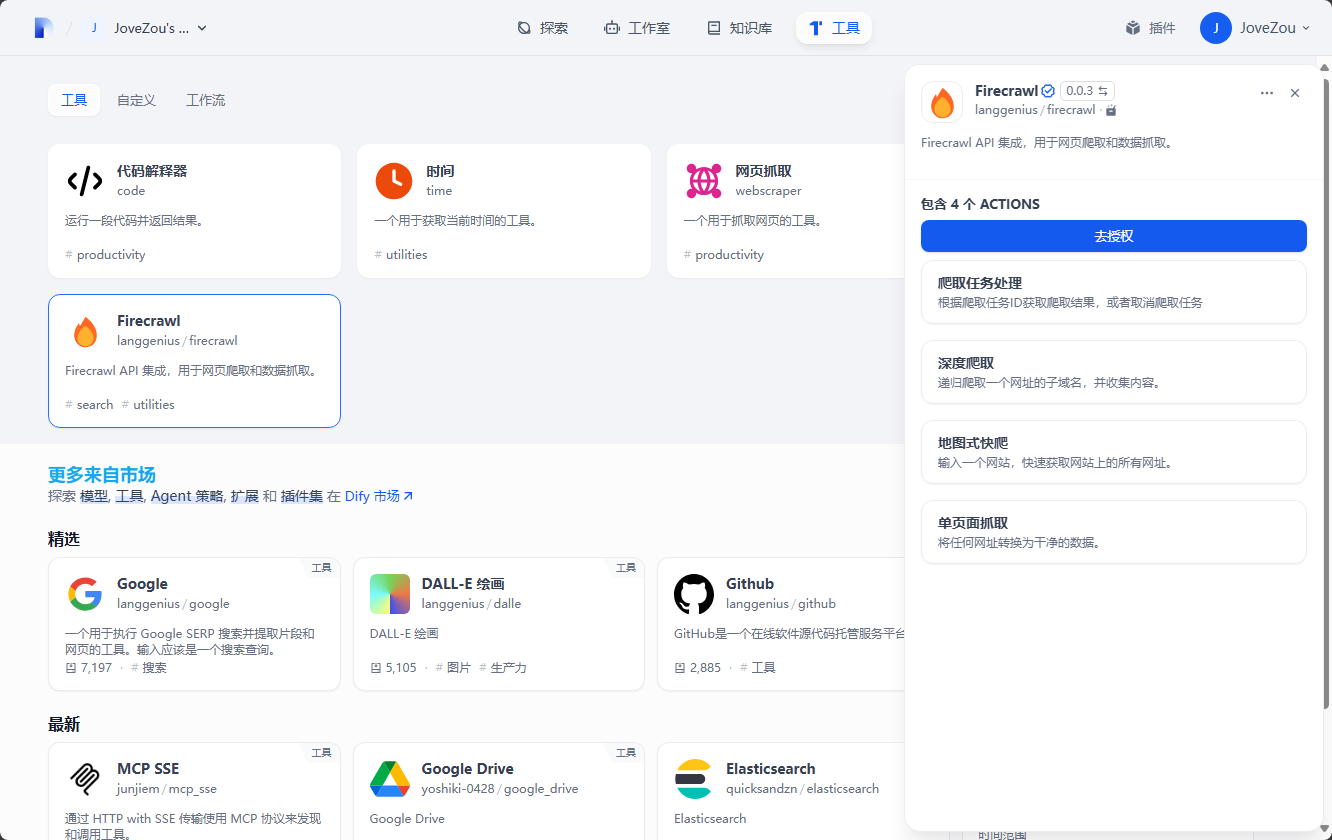
2、单击插件配置页面进行授权配置
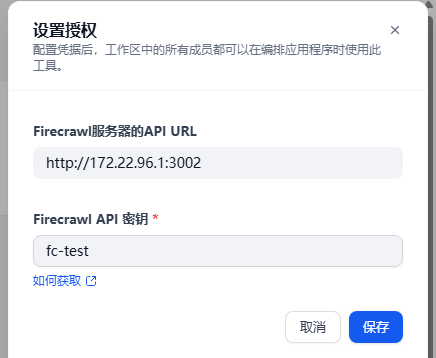
注意:如果是使用 Dokcer Desktop来进行部署的,并且 Firecrawl 和 Dify 部署在同一台机器上面,那么 API URL 的 IP 需要填使用 WSL 的地址来填写,这里我使用的就是 WSL 的 IP 地址;如果使用的是虚拟机则直接填写虚拟机地址即可,如果是 Firecrawl 和 Dify 都部署在同一台 Ubuntu 上也遇到了授权时的网络问题可以尝试使用 docker0 的地址
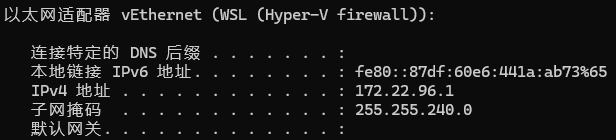

3、点击保存成功授权
4、测试
抓取的网页:https://baijiahao.baidu.com/s?id=1826651380645949331
流程图及单页面抓取配置如下,其他保持默认
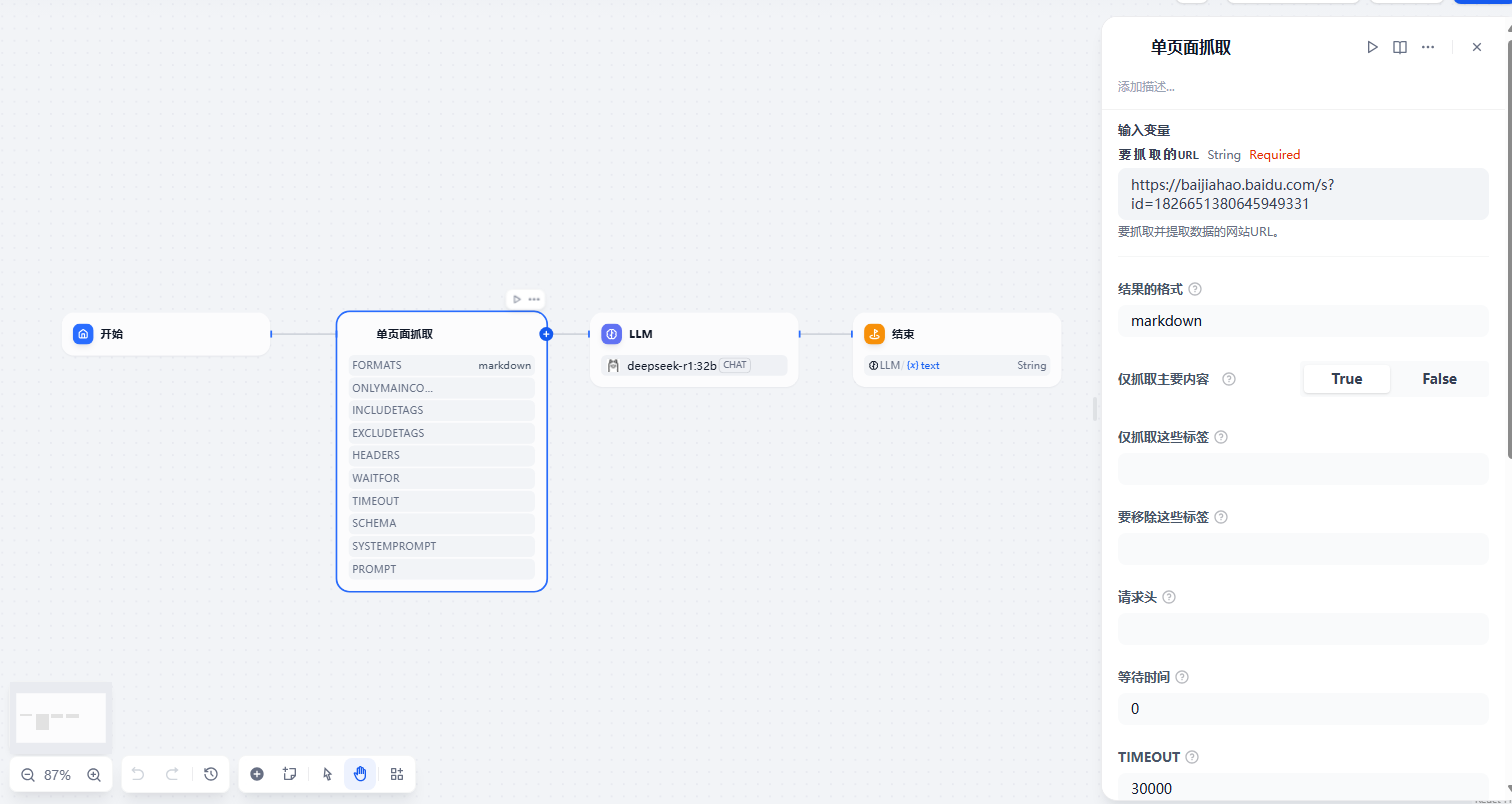
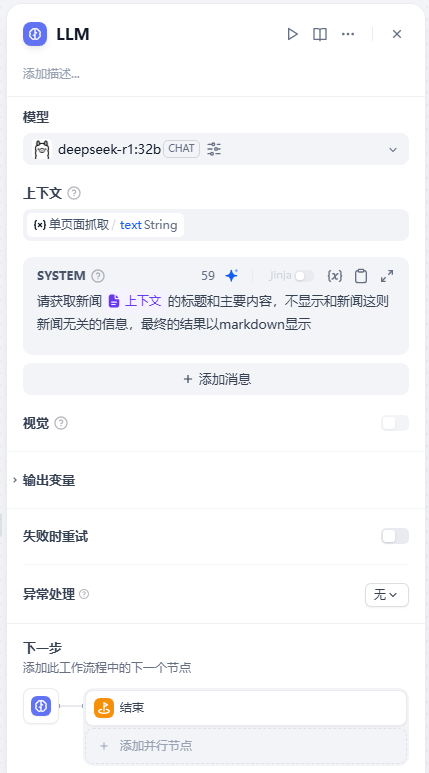
LLM 设置如下
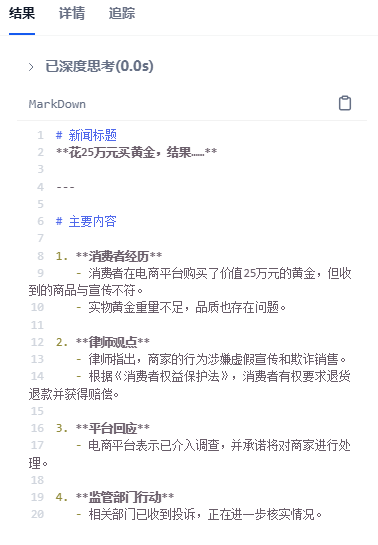
最终输出结果如下



















 3073
3073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











