






1. uptime
uptime命令用于显示系统运行时间及负载。
uptime 命令可以打印出系统总共运行了多长时间和系统的平均负载。
显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的 1 分钟、5 分钟和 15 分钟内的平均负载。
$ uptime
13:28:11 up 39 days, 20:50, 1 user, load average: 0.80, 0.70, 0.74
这是一个快速展示系统平均负载的方法,这也指出了等待运行进程的数量。这些数字包括等待 CPU 运行的进程数,也包括了被不可中断 I/O(通常是磁盘 I/O)阻塞的进程。
load average的含义
系统负载:是系统CPU繁忙程度的度量,即有多少进程在等待被CPU调用(进程等待队列的长度)
Load是对当前CPU工作量的度量,简单的来说是进程队列的长度。
系统运行时间
$ uptime -p
up 21 hours, 4 minutes
系统启动时间
$ uptime -s
2021-01-15 22:46:06
2.vmstat 1
对虚拟内存统计的简短展示,vmstat 是一个常用工具(最早是几十年前为 BSD 创建的)。它每一行打印关键的服务信息统计摘要。
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 4965308 2108 6194360 0 0 0 67 2 2 2 7 91 0 0
0 0 0 4965512 2108 6194296 0 0 0 277 46162 57352 3 8 88 0 1
1 0 0 4965388 2108 6194296 0 0 0 128 45035 54750 2 5 91 0 1
3 0 0 4965940 2108 6194240 0 0 0 24 42020 51751 2 6 91 0 1
2 0 0 4973984 2108 6175688 0 0 0 378 54076 70236 7 13 77 1 1
1 0 0 4932720 2108 6195176 0 0 0 327 58256 81618 10 10 78 0 2
1 0 0 4964432 2108 6194704 0 0 0 585 45919 56941 8 8 80 1 3
vmstat 使用参数 1 来运行的时候,是每 1 秒打印一条统计信息。在这个版本的 vmstat 中,输出的第一行展示的是自从启动后的平均值,而不是前一秒的统计。所以现在,可以跳过第一行,除非你要看一下抬头的字段含义。
每列含义说明:
-
r: CPU 上的等待运行的可运行进程数。这个指标提供了判断 CPU 饱和度的数据,因为它不包含 I/O 等待的进程。可解释为:“r” 的值比 CPU 数大的时候就是饱和的。
-
free:空闲内存,单位是 k。如果这个数比较大,就说明你还有充足的空闲内存。“free -m” 和下面第 7 个命令,可以更详细的分析空闲内存的状态。
-
si,so:交换进来和交换出去的数据量,如果这两个值为非 0 值,那么就说明没有内存了。
-
us,sy,id,wa,st:这些是 CPU 时间的分解,是所有 CPU 的平均值。它们是用户时间,系统时间(内核),空闲,等待 I/O 时间,和被偷的时间(这里主要指其它的客户,或者使用 Xen,这些客户有自己独立的操作域)。
CPU 时间的分解可以帮助确定 CPU 是不是非常忙(通过用户时间和系统时间累加判断)。持续的 I/O 等待则表明磁盘是瓶颈。这种情况下 CPU 是比较空闲的,因为任务都由于等待磁盘 I/O 而被阻塞。你可以把等待 I/O 看作是另外一种形式的 CPU 空闲,而这个命令给了为什么它们空闲的线索。
系统时间对于 I/O 处理来说是必须的。比较高的平均系统时间消耗,比如超过了 20%,就有必要进一步探索分析了:也有可能是内核处理 I/O 效率不够高导致。
在上面的例子中,CPU 时间几乎都是用户级别的,说明这是一个应用级别的使用情况。如果CPU 的使用率平均都超过了 90%。这不一定问题;可以使用 “r” 列来检查使用饱和度。
3. mpstat -P ALL 1
这个命令打印各个 CPU 的时间统计,如果有一个使用率明显较高的 CPU 就可以明显看出来这是一个单线程应用。
$ mpstat -P ALL 1
Linux 3.10.0-957.el7.x86_64 (test1.internal.moqi.ai) 2021年02月24日 _x86_64_ (8 CPU)
13时51分58秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13时51分59秒 all 3.61 0.00 5.62 0.13 0.00 3.21 0.67 0.00 0.00 86.75
13时51分59秒 0 3.12 0.00 6.25 0.00 0.00 4.17 0.00 0.00 0.00 86.46
13时51分59秒 1 4.08 0.00 6.12 0.00 0.00 3.06 0.00 0.00 0.00 86.73
13时51分59秒 2 2.04 0.00 5.10 0.00 0.00 4.08 0.00 0.00 0.00 88.78
13时51分59秒 3 3.19 0.00 7.45 0.00 0.00 3.19 1.06 0.00 0.00 85.11
13时51分59秒 4 4.04 0.00 8.08 0.00 0.00 3.03 2.02 0.00 0.00 82.83
13时51分59秒 5 4.12 0.00 5.15 0.00 0.00 1.03 0.00 0.00 0.00 89.69
13时51分59秒 6 4.12 0.00 5.15 0.00 0.00 2.06 1.03 0.00 0.00 87.63
13时51分59秒 7 4.41 0.00 2.94 0.00 0.00 7.35 0.00 0.00 0.00 85.29
4. dmesg | tail
$ dmesg | tail
[3446172.222743] docker0: port 17(veth26c0d59) entered disabled state
[3446172.724767] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
[3446172.725270] IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready
[3446172.725297] IPv6: ADDRCONF(NETDEV_CHANGE): veth26c0d59: link becomes ready
[3446172.725375] docker0: port 17(veth26c0d59) entered blocking state
[3446172.725378] docker0: port 17(veth26c0d59) entered forwarding state
[3446174.855078] docker0: port 17(veth26c0d59) entered disabled state
[3446174.872684] docker0: port 17(veth26c0d59) entered disabled state
[3446174.877793] device veth26c0d59 left promiscuous mode
[3446174.877959] docker0: port 17(veth26c0d59) entered disabled state
这里展示的是最近 10 条系统消息日志,如果系统消息没有就不会展示。主要是看由于性能问题导致的错误。不要略过这一步!dmesg 永远值得看一看。
可读性时间转换
date -d "1970-01-01 UTC `echo "$(date +%s)-$(cat /proc/uptime|cut -f 1 -d' ')+69740.690129"|bc `seconds"
Fri Aug 15 11:41:35 CST 2014
5. free -m
缓存cache占用过大,CPU达到85%以上。
手动释放掉被系统Cache占用的数据命令:echo 3 > /proc/sys/vm/drop_caches
1、buffers:用于块设备 I/O 缓冲的缓存。
buffers是指用来给块设备做的缓冲大小,他只记录文件系统的metadata以及 tracking in-flight pages.
2、cached:用于文件系统的页缓存。
cached是用来给文件做缓冲。也就是说:buffers是用来存储,目录里面有什么内容,权限等等。
而cached直接用来记忆我们打开的文件,如果你想知道他是不是真的生效,你可以试一下,先后执行两次命令#man X ,你就可以明显的感觉到第二次的开打的速度快很多。
To free pagecache, use
echo 1 > /proc/sys/vm/drop_caches;
to free dentries and inodes, use
echo 2 > /proc/sys/vm/drop_caches;
to free pagecache, dentries and inodes, use
echo 3 >/proc/sys/vm/drop_caches.
6. sar -n DEV 1
使用这个工具是可以检测网络接口的吞吐:rxkB/s 和 txkB/s,作为收发数据负载的度量,也是检测是否达到收发极限。
sar -n DEV #查看当天从零点到当前时间的网卡流量信息
$ sar -n DEV 1 1
Linux 3.10.0-957.el7.x86_64 (xxx) 2021年02月24日 _x86_64_ (8 CPU)
14时20分36秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
14时20分37秒 vethaea2518 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时20分37秒 vethffdbfac 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时20分37秒 veth455706e 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时20分37秒 vethbd56f11 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时20分37秒 vethef65369 3.00 2.00 0.94 0.91 0.00 0.00 0.00
14时20分37秒 veth0067e3a 24629.00 24630.00 2894.78 1695.76 0.00 0.00 0.00
14时20分37秒 veth683e9a4 9.00 14.00 4.00 1.20 0.00 0.00 0.00
14时20分37秒 vethfd386c6 1.00 1.00 0.05 0.07 0.00 0.00 0.00
14时20分37秒 eth0 24742.00 24664.00 4075.65 2902.21 0.00 0.00 0.00
14时20分37秒 veth8ba2153 33.00 22.00 2.74 5.62 0.00 0.00 0.00
14时20分37秒 lo 1.00 1.00 0.04 0.04 0.00 0.00 0.00
14时20分37秒 veth5c0a30d 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时20分37秒 veth8cc0b08 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时20分37秒 veth09f2905 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时20分37秒 vethd762a09 11.00 15.00 1.52 1.30 0.00 0.00 0.00
14时20分37秒 vetha967007 6.00 4.00 3.78 0.29 0.00 0.00 0.00
14时20分37秒 veth87e77ff 1.00 1.00 0.05 0.07 0.00 0.00 0.00
14时20分37秒 veth3261085 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时20分37秒 docker0 24685.00 24682.00 2569.64 1704.77 0.00 0.00 0.00
平均时间: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
平均时间: vethaea2518 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: vethffdbfac 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: veth455706e 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: vethbd56f11 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: vethef65369 3.00 2.00 0.94 0.91 0.00 0.00 0.00
平均时间: veth0067e3a 24629.00 24630.00 2894.78 1695.76 0.00 0.00 0.00
平均时间: veth683e9a4 9.00 14.00 4.00 1.20 0.00 0.00 0.00
平均时间: vethfd386c6 1.00 1.00 0.05 0.07 0.00 0.00 0.00
平均时间: eth0 24742.00 24664.00 4075.65 2902.21 0.00 0.00 0.00
平均时间: veth8ba2153 33.00 22.00 2.74 5.62 0.00 0.00 0.00
平均时间: lo 1.00 1.00 0.04 0.04 0.00 0.00 0.00
平均时间: veth5c0a30d 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: veth8cc0b08 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: veth09f2905 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: vethd762a09 11.00 15.00 1.52 1.30 0.00 0.00 0.00
平均时间: vetha967007 6.00 4.00 3.78 0.29 0.00 0.00 0.00
平均时间: veth87e77ff 1.00 1.00 0.05 0.07 0.00 0.00 0.00
平均时间: veth3261085 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: docker0 24685.00 24682.00 2569.64 1704.77 0.00 0.00 0.00
这个版本的工具还有一个统计字段: %ifutil,用于统计设备利用率(全双工双向最大值),这个利用率也可以使用 Brendan 的 nicstat 工具来测量统计。在这个例子中 0.00 这种情况就似乎就是没有统计,这个和 nicstat 一样,这个值是比较难统计正确的。
sar -n TCP,ETCP 1
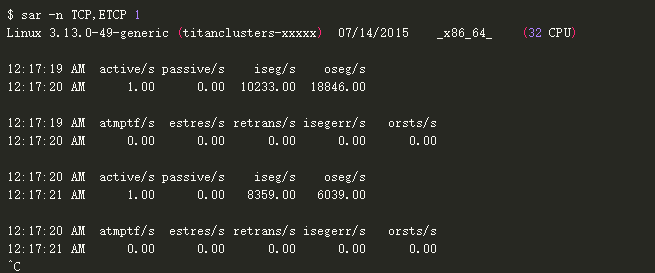
这是对 TCP 关键指标的统计,它包含了以下内容:
-
active/s:每秒本地发起的 TCP 连接数(例如通过 connect() 发起的连接)。
-
passive/s:每秒远程发起的连接数(例如通过 accept() 接受的连接)。
-
retrans/s:每秒TCP重传数。
这种主动和被动统计数通常用作对系统负载的粗略估计:新接受连接数(被动),下游连接数(主动)。可以把主动看作是外部的,被动的是内部,但是这个通常也不是非常准确(例如:当有本地到本地的连接时)。
重传是网络或者服务器有问题的一个信号;可能是一个不可靠的网络(例如:公网),或者可能是因为服务器过载了开始丢包。上面这个例子可以看出是每秒新建一个 TCP 连接。
7、dstat
通过man帮助,可以看到官方对dstat的定义为:多功能系统资源统计生成工具( versatile tool for generating system resource statistics)。在获取的信息上有点类似于top、free、iostat、vmstat等多个工具的合集,官方解释为vmstat、iostat、ifstat等工具的多功能替代品,且添加了许多额外的功能(Dstat is a versatile replacement for vmstat, iostat and ifstat. Dstat overcomes some of the limitations and adds some extra features.);其结果可以保持到csv文件,使用脚本或第三方工具对性能进行分析利用(如通过监控平台监控,也可以保持到数据库)。
dstat非常强大,可以实时的监控cpu、磁盘、网络、IO、内存等使用情况。 直接使用dstat,默认使用的是-cdngy参数,分别显示cpu、disk、net、page、system信息,默认是1s显示一条信息
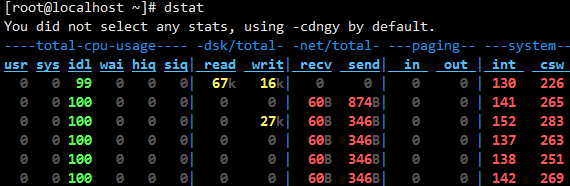
下面对显示出来的部分信息作一些说明:
- cpu:hiq、siq分别为硬中断和软中断次数。
- system:int、csw分别为系统的中断次数(interrupt)和上下文切换(context switch)。
# 直接跟数字,表示#秒收集一次数据,默认为一秒;dstat 5表示5秒更新一次
-c,--cpu 统计CPU状态,包括 user, system, idle(空闲等待时间百分比), wait(等待磁盘IO), hardware interrupt(硬件中断), software interrupt(软件中断)等;
-d, --disk 统计磁盘读写状态
-D total,sda 统计指定磁盘或汇总信息
-l, --load 统计系统负载情况,包括1分钟、5分钟、15分钟平均值
-m, --mem 统计系统物理内存使用情况,包括used, buffers, cache, free
-s, --swap 统计swap已使用和剩余量
-n, --net 统计网络使用情况,包括接收和发送数据
-N eth1,total 统计eth1接口汇总流量
-r, --io 统计I/O请求,包括读写请求
-p, --proc 统计进程信息,包括runnable、uninterruptible、new
-y, --sys 统计系统信息,包括中断、上下文切换
-t 显示统计时时间,对分析历史数据非常有用
--fs 统计文件打开数和inodes数
如想监控swap,process,sockets,filesystem并显示监控的时间:
# dstat -tsp --socket --fs
----system---- ----swap--- ---procs--- ------sockets------ --filesystem-
time | used free|run blk new|tot tcp udp raw frg|files inodes
12-10 12:30:40| 0 240M| 0 0 3.5| 1 11 4 0 0| 1664 94610
12-10 12:30:41| 0 240M| 0 0 1.0| 1 11 4 0 0| 1664 94610
12-10 12:30:42| 0 240M| 0 0 0| 1 11 4 0 0| 1664 94610
12-10 12:30:43| 0 240M| 0 0 1.0| 1 11 4 0 0| 1664 94610
12-10 12:30:44| 0 240M| 0 0 1.0| 1 11 4 0 0| 1664 94610
12-10 12:30:45| 0 240M| 0 0 1.0| 1 11 4 0 0| 1664 94610
12-10 12:30:46| 0 240M| 0 0 1.0| 1 11 4 0 0| 1664 94610
若要将结果输出到文件可以加--output filename:
# dstat -tsp --socket --fs --output /tmp/ds.csv
常用组合
# dstat -cmsdnl -D sda9 -N lo,ens33 100 5
Module dstat_disk24old failed to load. (No suitable block devices found to monitor)
----total-cpu-usage---- ------memory-usage----- ----swap--- ---net/lo----net/ens33- ---load-avg---
usr sys idl wai hiq siq| used buff cach free| used free| recv send: recv send| 1m 5m 15m
0 0 99 0 0 0| 603M 2108k 515M 4552M| 0 240M| 0 0 : 0 0 | 0 0.01 0.05
0 0 100 0 0 0| 602M 2108k 515M 4552M| 0 240M| 0 0 : 63B 466B| 0 0.01 0.05
监测界面各参数含义(部分)
Procs
- r:运行的和等待(CPU时间片)运行的进程数,这个值也可以判断是否需要增加CPU(长期大于1)
- b:处于不可中断状态的进程数,常见的情况是由IO引起的
- swpd: 切换到交换内存上的内存(默认以KB为单位)。如果 swpd 的值不为0,或者还比较大,比如超过100M了,但是 si, so 的值长期为 0,这种情况我们可以不用担心,不会影响系统性能。
- free: 空闲的物理内存
- buff: 作为buffer cache的内存,对块设备的读写进行缓冲
- cache: 作为page cache的内存, 文件系统的cache。如果 cache 的值大的时候,说明cache住的文件数多,如果频繁访问到的文件都能被cache住,那么磁盘的读IO bi 会非常小。
- si: 交换内存使用,由磁盘调入内存
- so: 交换内存使用,由内存调入磁盘
内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响。磁盘IO和CPU资源都会被消耗。
- bi: 从块设备读入的数据总量(读磁盘) (KB/s)
- bo: 写入到块设备的数据总理(写磁盘) (KB/s)
- in: 每秒产生的中断次数
- cs: 每秒产生的上下文切换次数
- usr: 用户进程消耗的CPU时间百分比
us 的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超过50% 的使用,那么我们就该考虑优化程序算法或者进行加速了(比如 PHP/Perl)
- sys: 内核进程消耗的CPU时间百分比
sys 的值高时,说明系统内核消耗的CPU资源多,这并不是良性的表现,我们应该检查原因。
- wai: IO等待消耗的CPU时间百分比
- idl: CPU处在空闲状态时间百分比
找出占用资源最高的进程和用户
--top-(io|bio|cpu|cputime|cputime-avg|mem) 通过这几个选项,可以看到具体是那个用户那个进程占用了相关系统资源,对系统调优非常有效。如查看当前占用I/O、cpu、内存等最高的进程信息.
# dstat --top-mem --top-io --top-cpu
--most-expensive- ----most-expensive---- -most-expensive-
memory process | i/o process | cpu process
dockerd 69.0M|bash 170k 4528B|containerd 0.4
dockerd 69.0M|irqbalance 8804B 0 |kworker/1:0 0.3
dockerd 69.0M|sshd: root@ 155B 196B|containerd 0.3
dockerd 69.0M|sshd: root@ 162B 212B|containerd 0.3
dockerd 69.0M|sshd: root@ 162B 212B|containerd 0.3
dockerd 69.0M|sshd: root@ 162B 212B|
dockerd 69.0M|sshd: root@ 155B 196B|kworker/1:0 0.3
dockerd 69.0M|vmtoolsd 11k 0 |containerd 0.3
https://mp.weixin.qq.com/s/EI0xANUpXUiu0JKsBaJftg
https://mp.weixin.qq.com/s/hyaVe4OfQkBVvE2MiRM3dQ 工具有待整理
















 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











