







背景(可以忽略)
项目在本地写完了,和队友测试都通过了,最后部署到云端,云端服务器是Windows Server 2008 R2 Standard操作系统,部署到云端后再次和队友测试一下,就出现了问题。
问题描述
云端服务器上使用dom4j生成words.xml文件,文件内容包含中文。使用EditPlus软件打开,部分内容如下:
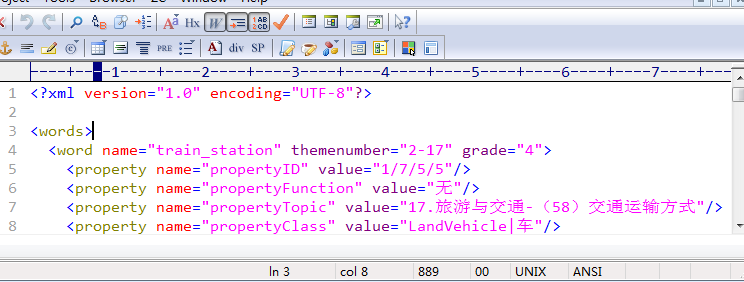
队友使用android设备下载该文件并来解析,错误发生了:最终解析内容成功,但是发现解析出来保存到数据库的中文内容是乱码
解决
1.推给队友
我的思考:我部署本地给你提供服务时你那边解析是正常的,我放到云端没有做任何修改,你那边是不是修改了,你看一下。
打脸:我让队友检查一下是不是你那边解析数据库的字符编码不是utf-8,或者你读的时候是不是设置了编码,队友就按照我的思路去检查,她说她的代码也没有变。
为了验证,她还把我们之前在项目部署在本地时生成的words.xml文件放到android中解析,解析后得到的内容没有乱码。
队友提示:你的文件内容是utf-8,但是你的文件保存到磁盘上上的编码是utf-8吗?
2.对比发现问题
- 我把之前在本地服务器上生成的words.xml和在云端服务器生成的words.xml进行了对。
上面图片是云端生成的words.xml文件,下面是之前在本地生成的words.xml部分内容:
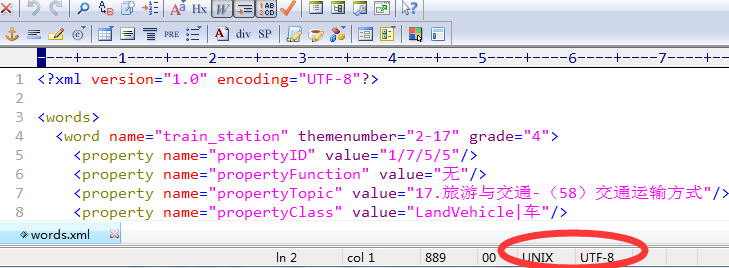
发现问题
两份文件内容都一样,声明编码格式encoding都是UTF-8,不同是两份文件保存在磁盘上的编码不同,云端是GBK(显示是ANSI),本地服务器保存的是UTF-8。问题就是文件声明的内容的编码和保存到磁盘上使用的编码不一致(?),至于具体的原理下面会解释。
云端:encoding=UTF-8 保存编码:GBK
本地服务器端:encoding=UTF-8 保存编码:UTF-8
进一步发现
我把两份words.xml分别用Google Chrome浏览器打开,结果不一样。
encoding=UTF-8 保存编码:GBK 的words.xml:显示异常
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3369
3369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









