







题目本来是想写从入门到放弃的,后来想想, Python 操作数据还是挺简单的,不至于放弃
再加上有我这篇文章在,绝对不会让你想要放弃,会让你入个门~
背景是这样的,我这边拿到一个需求,要处理客户那边一个 excel 表格中的数据,一万多条
这个量人工去搞太麻烦了,肯定是想要程序去处理,刚开始是想要用 java 去实现的,毕竟是我的老本行
然后想到要去建类,引入依赖,最后打包交给客户,一个 jar 包怎么着也要几兆,怪麻烦的
想到 Python 不是可以处理数据嘛,而且听别人说挺简单的, try 一下
然后就有了今天这篇文章
假设表格数据内容是这样的
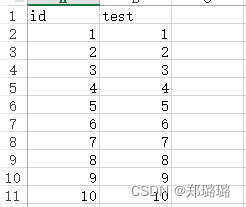
Python 和 java 语言很类似,所以就直接上 demo 的代码了
import xlrd
from xlrd import xldate_as_tuple
def init():
excel_data = xlrd.open_workbook(r"C:\Users\Deer\Desktop\Python\test.xlsx")
table = excel_data.sheets()[0]
# 创建一个空列表,存储 excel 数据
tables = []
for rown in range(1,table.nrows):
array = {'id':'','test':''}
array['id'] = table.cell_value(rown,0)
array['test'] = table.cell_value(rown,1)
tables.append(array)
print(tables)
if __name__ == '__main__':
init()
上面的代码一执行,嗯,还不错,起码是把 excel 数据读出来了

但是,你发现了嘛
表格里面 test 那一列是 1 2 但是代码执行出来,读到的是 1.0 2.0 ,这是因为 xlrd 模块去读 excel 时会将数字类型的自动转化为浮点数,所以这块需要再完善下
这里逻辑就是 excel 表格数据我们是确定的,既然这两列都是数据,那我们就可以去判断,如果这一列数据类型是数字,就转一下
所以加个 if 判断就 ok 了
if table.cell(rown,0).ctype == 2 :
array['id'] = int(table.cell_value(rown,0))
if table.cell(rown,1).ctype == 2 :
array['test'] = int(table.cell_value(rown,1))
ok ,拿到了想要的结果

咱们转换下思路
现在这是个 demo , print 出来的内容,你可以把它理解为我想要处理的逻辑,所以实际上这块的内容是不会有输出的
所以上面整个运行完之后,它就是这样的

虽然说,程序没有任何输出就是最好的消息
但是总感觉差点儿意思,是不是该告诉我下成功处理了多少条数据?
这也简单,咱们定义一个全局变量,然后成功处理了一条数据就对这个变量进行 ++
最后打印输出一下就完了
定义一个全局变量: total_update = 0
成功处理了一条数据就对这个变量进行 ++
def init():
excel_data = xlrd.open_workbook(r"C:\Users\Deer\Desktop\Python\test.xlsx")
table = excel_data.sheets()[0]
# 创建一个空列表,存储 excel 数据
tables = []
name_data = []
for rown in range(1,table.nrows):
array = {'id':'','test':''}
if table.cell(rown,0).ctype == 2 :
array['id'] = int(table.cell_value(rown,0))
if table.cell(rown,1).ctype == 2 :
array['test'] = int(table.cell_value(rown,1))
tables.append(array)
# 处理完数据之后,就对 total_update ++
total_update += 1
print("successfully processed ",total_update, " pieces of data")
对于我这个用惯了 java 语言的人来说,这代码 ok 的,能跑起来
结果
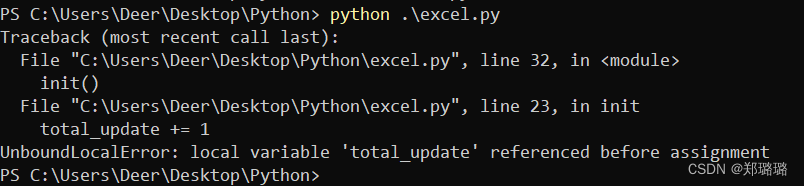
对于 Python 来说,如果想要用全局变量,用之前需要先声明
要不然它就当做本地变量去处理了,但是我的 init 方法里面没有声明这个,它就报错了
成,那咱们声明一下子

到这里,其实整个逻辑已经搞完了
不过我相信聪明的你一定还发现了
你这个文件路径是写死在了代码里啊
这要是回头给客户了,人家那里根本就没有 C:\Users\Deer\Desktop\Python\ 岂不是 g 了
所以上面代码还需要再优化下,把文件路径这块给写成变量
这时候就需要用到 argparse 了
详细我就不讲了,直接放完整的代码了
import argparse
import xlrd
from xlrd import xldate_as_tuple
total_update = 0
def init(dir_path = "." ):
excel_data = xlrd.open_workbook(r"C:\Users\Deer\Desktop\Python\test.xlsx")
table = excel_data.sheets()[0]
# 创建一个空列表,存储 excel 数据
tables = []
for rown in range(1,table.nrows):
array = {'id':'','test':''}
if table.cell(rown,0).ctype == 2 :
array['id'] = int(table.cell_value(rown,0))
if table.cell(rown,1).ctype == 2 :
array['test'] = int(table.cell_value(rown,1))
tables.append(array)
# 处理完数据之后,就对 total_update ++
global total_update
total_update += 1
print("successfully processed ",total_update, " pieces of data")
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="please enter required variables")
parser.add_argument("--dir_path", "-dir", help="please enter the file path", default=".", type=str, required=False)
args = parser.parse_args()
init(args.dir_path)
运行的时候,加个启动参数 -dir 就行了,完美

整个小 demo 大概就是这样
Python 大佬轻喷~
以上,感谢阅读哇~















 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









