







在写爬虫时往往会碰到一些通过js之类动态加载的网页,这时直接去读取的话,拿到的往往是不完整的源代码,需要一些方法去解决
- 使用一些工具模拟浏览器把js加载完后再去解析
比如selenium
java中使用selenium有几种方法,主要分成两类:一类会启动一个浏览器,对js的支持较好;一类不用启动浏览器,使用htmlUnit,不需要加载浏览器,不过对js的支持不大好 。
相对于java,在python中使用selenium稍微麻烦点,如果你想使用htmlUnit的话,你需要另外在运行一个selenium server,参见:
http://stackoverflow.com/questions/4618373/how-do-i-use-the-htmlunit-driver-with-selenium-from-python
如果你是在linux服务器上运行,没有GUI的话,直接使用那种开个窗口加载浏览器的方法会报以下的错误:
selenium.common.exceptions.WebDriverException: Message: The browser appears to have exited before we could connect. If you specified a log_file in the FirefoxBinary constructor, check it for details.解决方法:
需要安装一个类似虚拟机的东西来模拟:
sudo apt-get install xvfb
sudo pip install pyvirtualdisplayfrom pyvirtualdisplay import Display
from selenium import webdriver
display = Display(visible=0, size=(1024, 768))
display.start()
browser = webdriver.Firefox()
browser.get('http://www.ubuntu.com/')
print browser.page_source
browser.close()
display.stop()具体参见:
2.使用谷歌开发者工具等分析目标网站的加载过程
参见:https://www.zhihu.com/question/21332889
下面我以一个例子来说明下怎么看目标网站请求的url是什么?
比如腾讯应用宝:http://sj.qq.com/myapp/category.htm?orgame=1
当我们在看腾讯应用宝的应用时,它下面有一个 加载更多 的选项,当我们往下拉浏览器的右侧下拉条时,它会加载新的app。但是我们如果直接去获取这个页面的时候,通过浏览器下拉条下拉加载的app我们是获取不到的。
按照上面的链接介绍的方法,我们打开谷歌开发者工具,点击Network 标签,然后刷新腾讯应用宝页面,我的如下图:
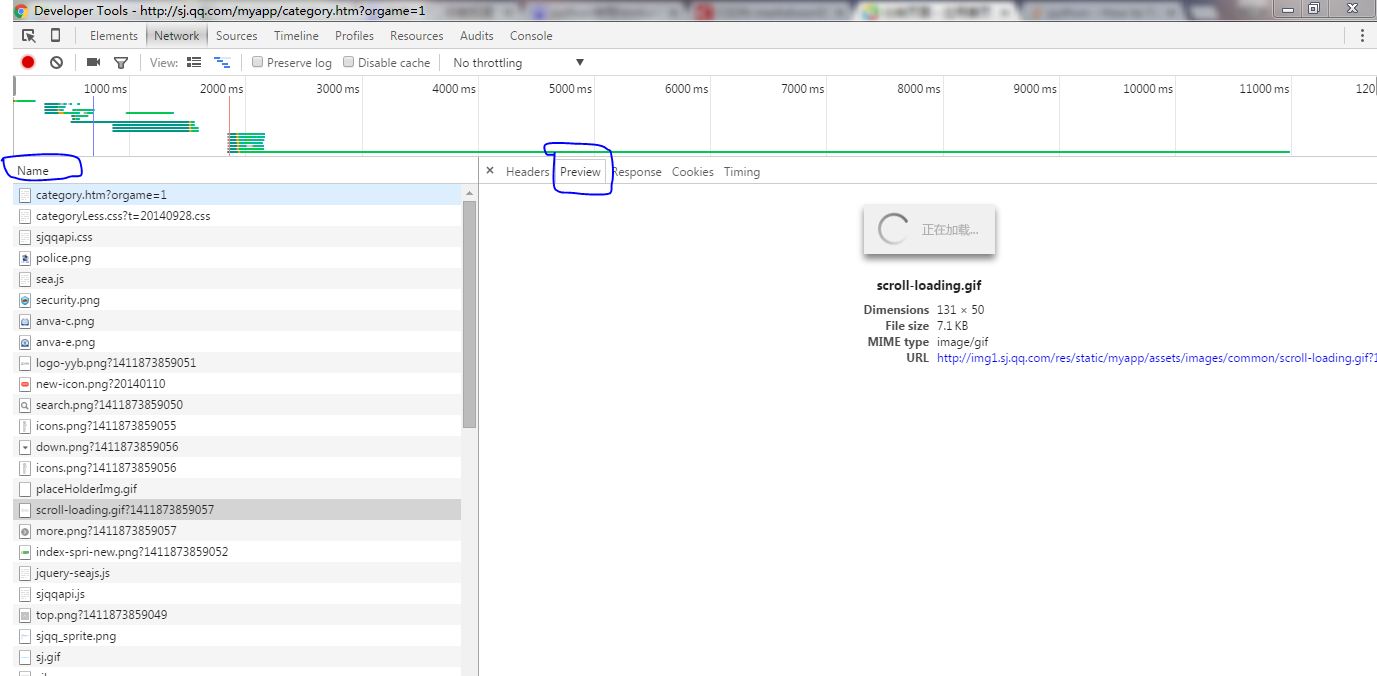
我们查看 Name,一个一个看,图片之类的就不用看了,主要看那些有点像链接的东西,点击,看对应右边的 Preview,慢慢找,并在浏览器手工下拉那个下拉条,让页面加载新的app,再次查看 Name,会发现多了很多的图中的蓝框中链接:
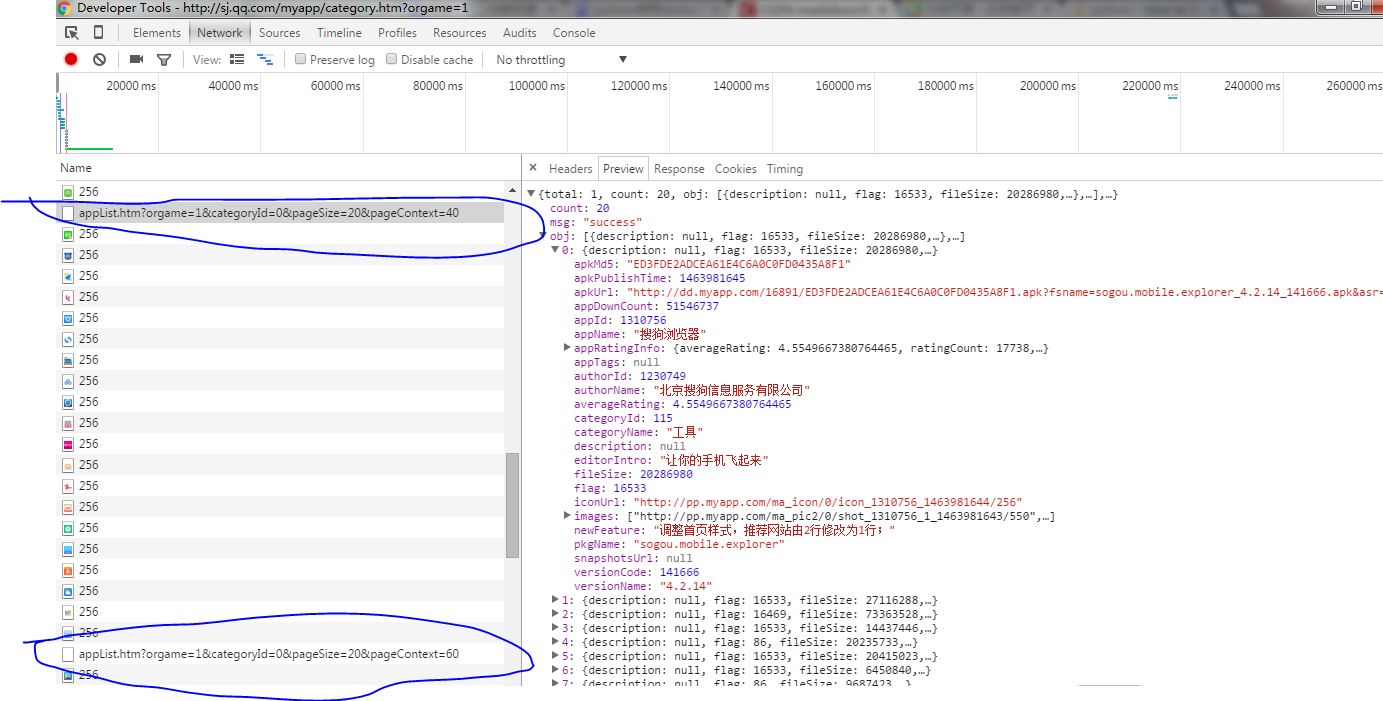
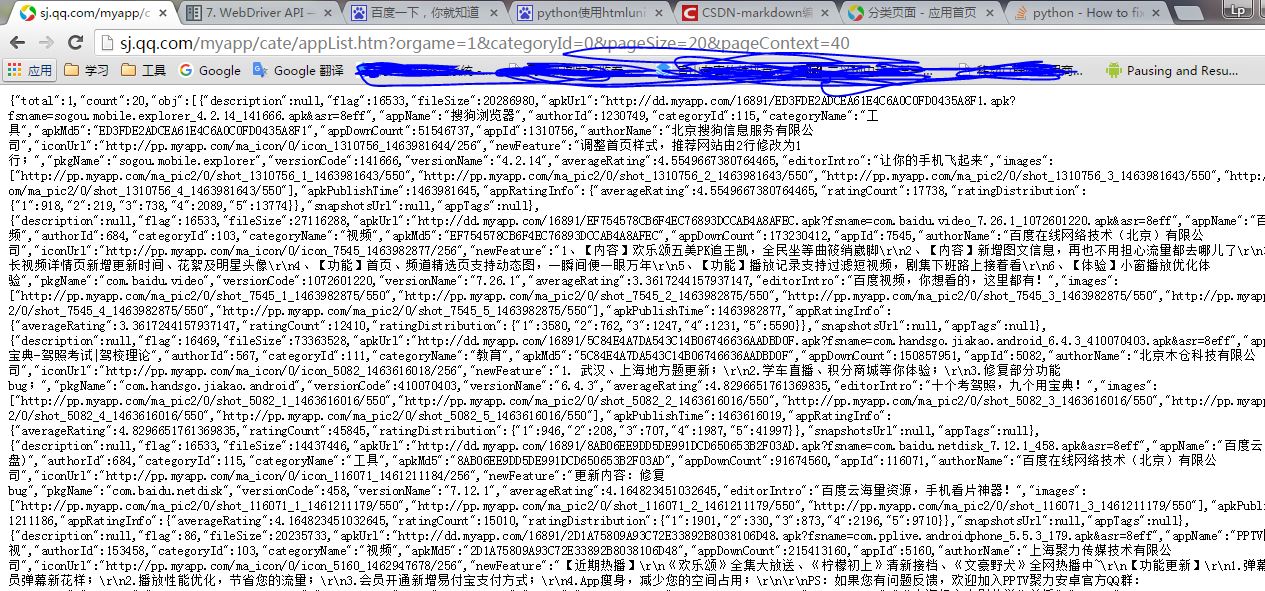
看右边对应的 Preview ,可以发现这其实就是我们每次下拉时,腾讯页面自动加载的app,他每次加载20个,我们找到了这个链接便可以直接向服务器发出请求了,返回的是json数据,如下图:
最后有的网站对header和cookie之类的都有要求,这时可以将
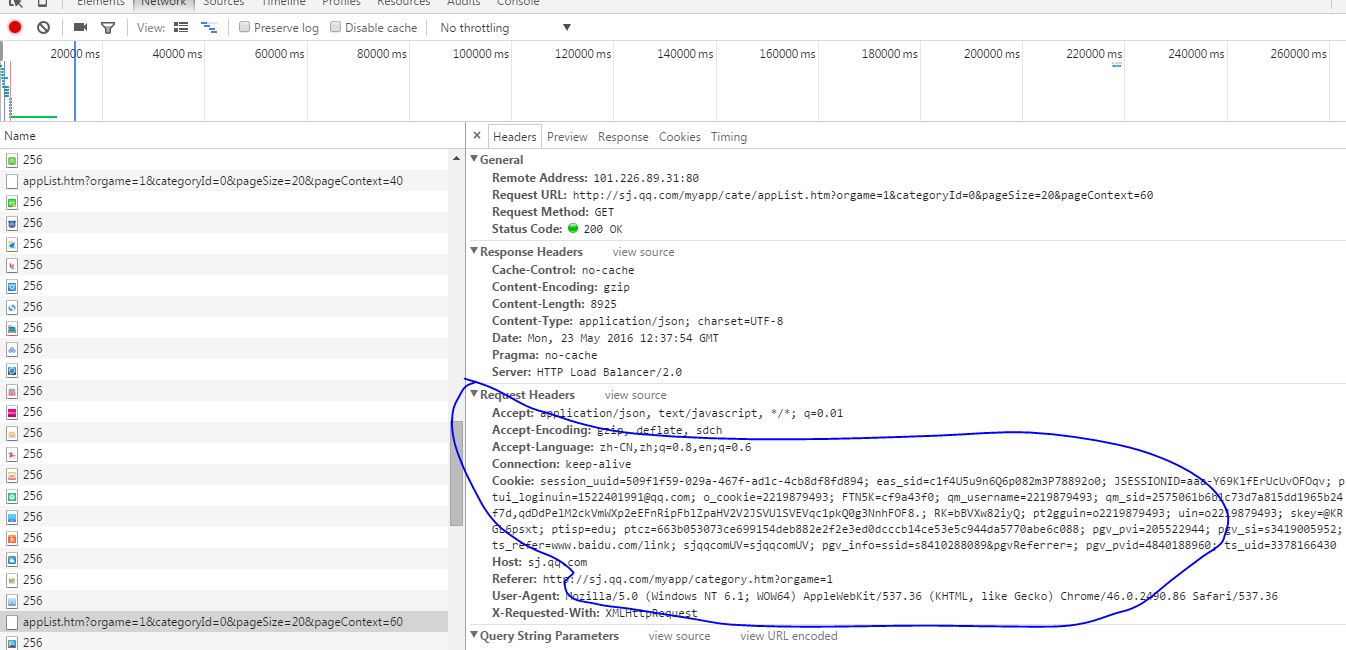
图中 Request Headers 里的东西设置到我们的程序里便可以了
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











