









前面的初识c语言属于扫盲篇,让大家对c有一个基本的了解和认知,同时也为我们后面的分讲打下坚实的基础,无论学习什么,都要先有一个笼统的概念,就像看书先看目录,只有知道了要学什么,才能在学习的过程中对知识进行有序的分配和汲取。
现在,我们开始讲第一个内容——判断与循环
(在初始c语言中打下的良好基础使得我们对于该节的认知和讲解大为轻松,我将不必分配精力到一些基础的语法,因此就更着重于细节和实例。大家加油哦!!!)
( 我们把判断与循环的详细知识放在这一篇讲完,后面几篇是我们的实战练习,所以这篇会格外的长,希望大家能沉下心来,慢慢读完,真正的知识永远留给有决心和有毅力的人。)
目录
1. c语言的语句格式
对于c来说:每一个‘ ;’(分号)都代表着一个语句,分号是语句的结束标志,在写代码时,我们强烈建议一条语句一行,而不要多条语句写在一起(可读性极差)

很容易就发现第一张的可读性远远大于第二张。
注意:
a:花括号{}等其他符号并不是语句,只是代码块的分割,{}是作用域的分割。
b:单独的‘ ;’也代表一条语句,只是该语句没有内容而已。
2.语句种类
2.1顺序语句
在c中,默认有一种语句,即默认情况下自上而下依次执行每一条语句(在不违反其他规则下),这种语句就叫作顺序语句。
2.2分支语句
实质是:进行逻辑判断后选择分支
2.21 if:
语法大家都了解了,直接上例子。

补充:解决scanf不兼容vs高版本:
a:将scanf改成scanf_s
b:在第一行加上
#define _CRT_SECURE_NO_WARNINGS (意思就是跳过安全检查)
c:加上
#pragma warning(disable:4996) (具体解释如上图注释,4996号错误就是scanf不兼容的错 误,意思就是禁止报4996号错误)
那我们如果要用if写一个多分支呢?如图

如上图: 通常用else if语句实现if的多分支
注意:
a:
不能写成 18<age<=35 ,这是一个表达式,运算顺序由左向右,先运算18<age,而关系运算符得出的是逻辑结果,即18<age的结果非0即1,然后进行0<=35或1<=35判断,显然始终为真,导致判断错误,因此要用逻辑与(即且的意思)。
b:
对于上图中,程序首先进入第一个if判断,即age<18,如果该判断成立,则直接跳出if语句而不会再进行其他else if或else的判断,即只进行一次正确的判断,若第一个if不成立,则会在第一个if不成立的前提下进入下一个else if的判断,即只要进入了第一个else if,说明一定存在age>=18,因此我们完全可以做如下优化。

当然,多分支不一定非要使用else if,我们也可以使用多个if 来完成。

但在该图中,当第一个if成立时,程序仍然会进入第二个if语句,重新进行判断,若第一个if不成立,则程序会进入第二个if中重新判断,但不会有前提条件,也就是说,这里的每个if都是一个单独的模块,无论第一个if是否成立,程序都会依次执行每一个if判断并且互相独立,如果输入10,那么每一个if判断都会成立,因此每一个if里的代码块都会被执行。如下图执行结果。

2.22悬空else(就近原则)
那是不是每一个else都会与和他对齐的if相匹配呢?看下面啦!

首先进入第一个if,显然3==a不成立,所以进入else语句,应该输出“hello else!”,但实际上没有输出结果!!
这是因为if语句拥有着就近原则,else会与和它最近的if相匹配(前提是该if未匹配到else时,若已有else匹配该if,则找下一个距离最近的if),因此,else实际上是与第二个if相匹配的,而当第一个if不满足时,压根就不会执行第二个if语句,所以自然没有输出结果。
实际应该为下图(if与它相匹配的else算一个模块,会一起跳过,即if不执行,else自然也不会执行):

注意:
a:
当本来应有的{}未添加时,只会执行单行语句。如if下如果有{},当if成立时,就会执行{}内的所有语句,而当if后没有{}时,就只会执行if后的第一个语句,之后的语句不管if是否满足按照由上至下的顺序被执行,也就是说,若没有{},即便if不成立,if的第二个语句依旧要被执行
如上两图,无论if是否满足,第二个printf总会被执行。


实例小检测:

大家是否看出正确结果了呢?hhhh。
第一个if里面a=3,而非a==3,因此第一个if里面首先进行的是赋值操作,即先将3赋给a,再检测a的逻辑结果,非0自然是真,所以该if永远满足执行条件,进入该if后,进入第二个if语句,满足b==2,执行相对应的printf,因为下面的else与第二个if想对应,而第二个if已经满足了正确判断,就不会再进行else的判断。
注意:
我们在写等于的判断条件时,最好把常量写到左边,即3==a,而不要写成a==3,如此一来,当你不小心写成一个等号即3=a时,由于赋值操作符左边不能是常量(常需量不能进行赋值)就会报错,便于及时改正。避免当3写到右边,导致a=3执行赋值操作而引起程序混乱。我们通常之为“防御性编程”。
2.22 :switch
switch同样是进行判断然后选择分支,其功能完全可以由if语句替代。但switch仍然存在是因为switch对于多分支循环的编写更加简洁易读。
不同于if语句的是,switch本身并不具有判断分支的能力,判断能力由case承担,分支能力由break承担。
在switch里有三个常用的关键字(continue break default),我们会在下面讲到。
首先看一个例子:
 ”
”
上图中,switch读取day的值交给case进行判断,如图,day的值是7,因此case对7进行判断,由此进入case 7:的分支中,输出“星期日”。
注意:
a:
case后面的数不是代表着提一个、第二个、第三个.....,而是对应着day的值,如果day的值跟case后面的数相等,才判断进入这个case所代表的分支
b:
switch后面()里的数只能是整型常量或整型常量表达式(包括int ,short, long, long long,char.... )--字符型也属于整型,但浮点型不属于。同时,由于case后面的值与()里的值相等时才能判断成立,因此case后也是整型常量表达式或整型常量
c:
case后的数并不一定要1,2,3,4排序,只要满足整形常变量表达式即可,不必在意顺序,顺序不过是我们的习惯。

当day值为1时,自然由case 1开始执行,但由于执行完case 1后并未遇到break,因此就会一直向下执行,直到遇见第一个break或者执行完毕。
break:循环中作用是跳出循环,在switch中担任分支的功能,case只会确定入口位置,如果没有break负责调配分支,就会一直执行下去。
因此应该写成下图:

那么如果day值是8怎么办呢,这时候就需要default了
default作用就如用if语句里面的else,即当其他所有判断全部不满足时,便执行default分支,如此便可避免输入值范围大于判断范围的尴尬情况。
如下:

当输入8时,便进入default分支,即输出 “输入错误”
注意:
a:
default顺序不定,即default不是非要写在最后一个判断位置,它可以写在任意位置(如与case1语句互换顺序),但只有当其他判断全部为假是才会执行。
switch小检测(switch嵌套):

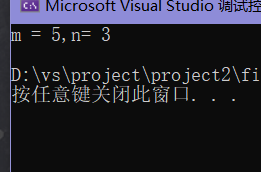
第一个switch读取n值为1,从第一个case 1分支进入,
执行m++ 后m值为3;
因为没有遇到break对分支进行调节,所以继续向下执行
执行n++后n值为2;
进入第二个switch语句
switch读取n值为2,从第二个switch语句中的case 2分支进入;
执行 m++后m为4, 执行n++后n值为3;
遇到break,跳出内层循环(即跳出第二个switch语句)
继续执行第一个switch中的case 4分支;
执行m++ 后m值为5;
遇到break 跳出switch语句
执行打印 5 3
补充:

我们常常把break加载caes和default后面,但有时候也需要放开一些分支,来让程序更简洁,如上图,1~5都是工作日,6~7都是周天,因此我们把1~5作为一个分支,6~7作为一个分支。
2.3循环语句
练习-判断1~100的奇偶

接下来我们把判断奇偶的功能进行封装,写成函数。

e,好像有点模糊,大家可以按(Ctrl+鼠标轮滑滚动)来控制大小,这个确实是我截图的失误。多多见谅hhh。
接下来我们在再次对函数进行优化前先了解一下 x%2的原理。

十进制中一个数%10得到的是十进制数最后一位
所以 二进制中一个数%2得到的是二进制数的最后一位
对于一个二进制 如1101,即1*2^3+1*2^2+0*2^1+1*2^0
提出一个2,即2*(1*2^2+1*2^1+0*2^0)+1*2^0,
因此前面的数一定时2的倍数,判断奇偶只要看最后一个数即可
当最后一位为1时—1*2^0==1,则该数必然是奇数
当最后一位为0时—0*2^0==0,则该数必然是偶数
x%2实质是检验最后一位是不是1
因此可以直接return x & 1;如: 5(101)&1(001)为1(001),4(100)&1(001)为0(000)
前面的二进制位数都会归零,只有最后一位留下来
最后一位为1则返回数为1
最后一位为0则返回数为0
所以另一种写法为:

2.31while循环:
因为我们在之前已经讲了基本知识,所以我们直接看一个while的使用来熟悉一下while,
这并不是一个复杂的代码,也不是什么坑,代码里写了注释,大家如果掌握了前面的知识的话是肯定可以看懂的,这里不做解释。

2.32for循环:

注意当i<9写成i<=9时,循环次数是(9-0)+1(闭区间注意+1)
For循环支持嵌套


每次不会重新回到条件初始化 ,直接回到条件判断

2.4跳转语句
下面我们来讲讲语句里的 break,continue
2.41Break:
结束循环(结束(跳出)本循环,如两个while嵌套,break会结束它所在的第二个while循环,但是会继续第一个while的循环),但在switch语句中,承担分支的调配。
2.42Continue:
2.421while中的continue

解释如图中注释:
2.422for中的continue:

2.423 do while中的continue

虽然未打印,但光标一直闪烁,说明程序有问题——这里是死循环
因此:
while/do while中的continue都是回到条件判断,而for里面的coutinue跳转到条件更新上,for更不容易死循环
补充:显示器只能显示字符--格式化输出(了解即可)

3. putchar()与getchar()

//getchar():获取一个字符放到ch里面
//putchar(ch)://输出ch里面的一个字符
//键盘的输入和显示屏的输出都是字符
//而scanf输入函数实际上是格式化输入(先记住即可)
//ASCLL码的缘由(美国创建)
//计算机只认识二进制,美国人使用的时候,想要打印美国文字
//于是就有了AKCLL,把二进制和字母对应起来
//getchar 的返回值是int类型,因为如果返回为char的话,在ascll所有的char都是有对应意义的,因此无法反映错误值,而返回类型为int的话,如果返回-1,说明错误
小练习:大小写转化

字符的运算实际上就是Ascll码值得运算,而在ascll中,小写字母比大写字母多32位
啊,终于写完这篇了,我写着都累,相信你们看过来肯定更不容易,想要得到更多,总是要付出更多,像我的博客基本上都是我每天晚上一点点熬出来的,我非常初学者的痛苦和无奈,但没有什么事情是一帆风顺的,更没有什么傍身技能是简简单单就可以得到的,世界上那么多人都在受苦,我们又凭什么超人一等,没有什么天才,坚持,就是一切。加油!
(这篇我很多讲解因为比较繁琐就写在了注释里,不知道看着是不是比较难受,如果觉得这种风格确实不太适应的话,可以在评论里说一下,看到后我尽量改)
















 4944
4944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











