






如果有更好的做法,或者一些新奇的思路可以在评论区跟我分享交流,谢谢。
希望能对一些想要学习算法的一些帮助
只是我写《算法竞赛》这本书以及打codeforces感觉有必要记下的题目;
方便以后本人随时查看...
本文对所有算法的讲解几乎都是一笔带过,只是针对那些知道这些算法的人加强一下记忆的作用。
最后感谢所有为我学习算法路上的各位老师们!(名字我就不一一列举了全在算法讲解的超链接当中)
春风得意马蹄疾,一日看尽长安花。——孟郊《登科后》
Codeforces
1、In Love
题意:
你有 T 次操作,每次操作分为两种:
-
+ l r,表示添加一条区间范围为 [l,r]的线段。
-
− l r,表示删除一条区间范围为 [l,r]的线段。
问每次操作后是否存在两条线段,使得它们的区间范围没有交集。
思路:把l和r放入某个数据中,只要最大的l > 最小的r 就说明这两条线段没有交集。
那么该如何维护数据的最大值和最小值呢?而且要多次删除
如果只是维护数据的最大值和最小值,我们可以用堆,但是我们需要查询并且删除
那我们就需要用红黑树在O(logn)的复杂度来查找、插入、删除元素。
而map和set原理都是红黑树来构造的(堆可以用priority_queue)
所以我们用一个multiset(st1)来维护l的最大值,以及一个multiset(st2)来维护r的最小值
因为multiset的默认是从小到大排列的,所以我们需要另外构建一个从大到小排列的数据结构
struct node{
int x;
bool operator<(const node &a) const {return a.x < x;}
};
#include <iostream>
#include <set>
using namespace std;
struct node{
int x;
bool operator<(const node &a)const{
return a.x < x;
}
};
multiset<node> st1; //存储最大值l
multiset<int> st2; //存储最小值r
int main()
{
int t;cin>>t;
while(t--)
{
char c;
cin>>c;
int l,r;scanf("%d%d",&l,&r);
if(c=='+'){
st1.insert({l});
st2.insert(r);
}else{
st1.erase(st1.find({l}));
st2.erase(st2.find(r));
}
//如果最小值l > 最大值r
if((*st1.begin()).x>(*st2.begin())){
cout << "YES" << endl;
}else {
cout << "NO" << endl;
}
}
return 0;
}
2、Look Back
题意:
给定长度为 n 的序列 a,你可以进行以下操作。
选取一个 i 满足 1≤i≤n,使 ai 变为原来的 2 倍。
求最少需要几次操作使得 a 为一个不下降的序列。(就是递增但可以相等的序列)
1 <= ai <= 1e9 1 <= n <= 1e5
思路:
让每一个a[i-1] <= a[i] * 2^k
我一开始想的是暴力求出每一个k的值,然后让它们相加,答案就是 sumk
但显然还是太天真了,如果有1000~1的顺序数组a,那么最后一个数的大小相当于 2^999那么大!
那么我们优化一下,创建一个数组b[i]来存储k的值
然后判断 a[i-1] <= a[i] * 2^(k-b[i-1])的值,那么我们如何得知k的值呢?显然,k-b[i-1]肯定要在-2^32~2^32之间。那么我们枚举 k在范围 b[i-1]-32,b[i-1]+32
如果b[i-1]-32 <0 就要让k=0;
假如k是从1开始的会怎么样? 如果a[i-1] = 2^32 ,并且 b[i-1] = 1e3,那我们枚举b[i-1]-k 有999,那么我们要计算的pow(2,999)显然十分巨大,不符合计算。
#include <iostream>
using namespace std;
const int N = 1e5+10;
#include <cmath>
long long a[N];
long long b[N];
int i;
int main()
{
int t;cin>>t;
while(t--)
{
int n;scanf("%d",&n);
b[0] = 0;
long long ans = 0;
for(i=1;i<=n;i++) scanf("%lld",&a[i]);
for(i=2;i<=n;i++){
int k;
for(k=b[i-1]-32;k<=b[i-1]+32;k++){
if(k-b[i-1]<0){
if(a[i-1]*pow(2,b[i-1]-k)<=a[i]){
break;
}
}else{
if(a[i-1]<=a[i]*pow(2,k-b[i-1])){
break;
}
}
}
b[i] = k;
}
for(int i=1;i<=n;i++){
ans += b[i];
}
cout << ans << "\n";
}
return 0;
}我这段代码是可以把空间优化到O(1)的,因为每次只用到了前一个a[i]和a[i-1]。
总结:对于数据十分巨大的2^9999... 要想到“相对值”来计算。不然根本没数据来存储。
3、Don't Try to Count(KMP)
题意:有字符串x和字符串a。通过一次操作可以让x变成x的两倍。然后求最少几次操作可以从x中找到字符串a。
思路:虽然题目中x和a的长度都十分的短,但我还是想用KMP算法qaq
如果不懂的可以看看下面的图

代码如下:
#include <iostream>
using namespace std;
#include <vector>
vector<int> prefix_function(string s)
{
int n = s.length();
vector<int> pi(n);
for(int i=1;i<n;i++)
{
int j = pi[i-1];
while(j>0&&s[i]!=s[j]) j = pi[j-1];
if(s[i]==s[j]) j++;
pi[i] = j;
}
return pi;
}
vector<int> find_occerence(string s,string text)
{
int n = s.length(),m=text.length();
string nx = s + '#' + text;
vector<int> v = prefix_function(nx);
vector<int> Ans;
for(int i=n+1;i<=n+m;i++){
if(v[i]==n){
Ans.push_back(i-2*n);
}
}
return Ans;
}
int main()
{
int t;cin>>t;
while(t--)
{
int n,m;cin>>n>>m;
string x,s;
cin>>x>>s;
//操作的最小次数,貌似可以二分?不过题面不大
vector<int> L = find_occerence(s,x);
if(!L.empty()){
cout << 0 << "\n";
continue;
}
int ans = 0;
//先翻倍到n刚好大于等于m
while(n<m){
ans++;
x = x+x;
n = 2*n;
}
L = find_occerence(s,x);
if(!L.empty()){
cout << ans << "\n";
continue;
}
//再翻一倍
ans++;
x = x+x;
n = 2*n;
L = find_occerence(s,x);
if(!L.empty()){
cout << ans << "\n";
continue;
}else{
cout << -1 << endl;
}
}
return 0;
}4、Divide and Equalize
题意:给出一个序列a1,a2,...an。找出一个整数x使得pow(x,n) == a1*a2*a3..an
思路:因为ai <= 1e6,且n<=1e4,故肯定不能直接硬求。那么这个问题可以转换成什么问题呢?首先。可以转换成把n个ai转换成最小质因子,然后每个质因子刚好是n的倍数。比如180 = 2*2*3*3*5;然后我们最后只要判断质因子的个数能否被n整除即可。
代码如下:
#include <iostream>
using namespace std;
const int N = 1e6+10;
#include <algorithm>
#include <cstring>
#include <cmath>
#include <vector>
#include <map>
int n;
int a[N];
map<int,int> q;
void check(int x)
{
for(int i=2;i<=sqrt(x);i++){
while(x%i==0){
q[i]++;
x/=i;
}
}
if(x>1) q[x]++;
}
int main()
{
int t;cin>>t;
while(t--)
{
cin>>n;
q.clear();
memset(a,0,sizeof(a));
for(int i=1;i<=n;i++){
int x;cin>>x;
check(x);
}
bool flag = true;
for(auto i:q){
int k = i.second;
if(k %n!=0){
flag = false;
break;
}
}
if(flag==true){
cout << "YES" << endl;
}else{
cout << "NO" << endl;
}
}
return 0;
}总结:这是一道怎么把数转换成它所有的质因数的题目; 而且要注意用map记录质因子>0的数,我就是因为一开始遍历的是0~1e6导致时间超限...
5、E. Block Sequence(动态规划)
题意:给了一个数字序列,比如:[3,[3,4,2],2,[4,5]] 和 [1,[3],4,[1,1,1,1]] 就是完美序列,因为这个序列中第i个后面跟着a[i]个元素,且从第一个元素开始,跟着的元素无所谓。然后现在知道了一个序列,我们可以删除元素,让它成为一个完美序列,求删除最少的个数。。
思路:我对动态规划还不是太熟练,所以一开始的想法是深搜做的,dfs第一个,然后下一种情况有两种,一种是删除一个元素,一种是跳过a[x]个元素,如果x大于n+1,就return,如果刚好等于n+1,就说明这个情况可以,记录这时候的ans值。虽然我剪枝了,但还是时间超限了。所以今天要恶补下我的动态规划/(ㄒoㄒ)/~~
动态规划就很简单了。
dp[i][j] = min(dp[i+1][j]+1,dp[i+a[i]+1][j]) 代表从第i个到第j个的最小值要么是跳,要么删除的情况,然后dp[i][j]代表最小值即可。然后j这个可以优化掉;就是dp[i] = min(dp[i+1]+1,dp[i+a[i]+1])
#include <iostream>
using namespace std;
const int N =2e5+10;
#include <cstring>
int a[N];
int dp[N];
int main()
{
int t;cin>>t;
while(t--)
{
int n;cin>>n;
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
}
memset(dp,0,sizeof(dp));
for(int i=n;i>=1;i--){
if(i+a[i]+1<=n+1){
dp[i] = min(dp[i+1]+1,dp[i+a[i]+1]);
}else{
dp[i] = dp[i+1] + 1;
}
}
cout << dp[1] << "\n";
}
return 0;
}6、E. Iva & Pav(ST+倍增) 或者(二分+线段树) 或者(ST+二分)
#include <iostream>
using namespace std;
int n;
const int N = 2e5+10;
#include <cmath>
int a[N],f[N][26];
void init(){
for(int j=0;j<=log2(n);j++){
for(int i=1;i+(1<<j)<=n+1;i++)
{
if(!j) f[i][0] = a[i];
else f[i][j] = (f[i][j-1] & f[i+(1<<(j-1))][j-1]);
}
}
}
int query(int L,int R)
{
int s = log2(R-L+1);
return (f[L][s] & f[R-(1<<s)+1][s]);
}
int main()
{
int t;cin>>t;
while(t--){
cin>>n;
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
init();
int q;cin>>q;
while(q--){
int l,k,r,x;cin>>l>>k;
if(a[l]<k){cout << "-1 ";continue;}
//优化二分+ST表
r = l,x = INT_MAX;
for(int i=log2(n);~i;i--){
if(r+(1<<i)-1<=n&&(x&f[r][i])>=k){
x &= f[r][i];
r += (1<<i);
}
}
cout << r-1 << " ";
}
cout << endl;
}
return 0;
}7、Data Structures Fan(异或运算)
一些性质:
1、x^x = 0; 所以异或运算是可以利用前缀和来做的 l~r的异或和 = sum[r] ^ sum[l-1]
2、可移项性: a^b = c ==> a = b^c
#include <iostream>
using namespace std;
char s[100005];
int sum[100005],a[100005];
int main()
{
int t;cin>>t;
while(t--){
int n;cin>>n;
int ans = 0;
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
sum[i] = sum[i-1] ^ a[i];
}
scanf("\n%s",s+1);
for(int i=1;i<=n;i++){
if(s[i]=='1') ans ^= a[i];
}
int q;cin>>q;
while(q--)
{
int op;cin>>op;
if(op==2){
int x;cin>>x;
if(x==1)cout<<ans<<" ";
else cout<<(sum[n]^ans)<< " ";
}else{
//修改
int l,r;cin>>l>>r;
ans ^= (sum[r]^sum[l-1]);
}
}
cout << endl;
}
return 0;
}8、E.Power of Points
题意:已知一个序列a,然后对于每个s=a[i],对于每个线段[s,a[j]](j∈[1,n])。求全部覆盖的点的数量。
思路:如果用暴力的思想去做的话就是遍历a序列,然后把a[i]当作s,然后再遍历一遍序列a获得线段覆盖点的sum,然后求解,时间复杂度是O(n²),显然超时。所以想办法找规律或者转化为O(nlogn)。对于每一个s=a[i]来说,我们求解了一个sum,然后对于s=a[i+1]来说,sum2 = sum + (i-1)*(a[i+1]-a[i]) - (n-i+1)*(a[i+1]-a[i]); 就可以通过s=a[1]来递推后面的所有结果。
代码如下:
#include <iostream>
using namespace std;
#include <algorithm>
#include <vector>
const int N =2e5+10;
#include <cstring>
long long a[N],b[N];
#include <map>
int main(){
int t;
scanf("%d",&t);
while(t--){
long long n;cin>>n;
memset(a,0,sizeof(a));
memset(b,0,sizeof(b));
map<long long,long long> mp;
for(long long i=1;i<=n;i++){
scanf("%lld",&a[i]);
b[i] = a[i];
}
sort(a+1,a+1+n);
long long sum = 0;
long long s = a[1];
for(long long i=1;i<=n;i++){
sum += (abs(s-a[i])+1);
}
mp[a[1]] = sum;
for(int i=2;i<=n;i++){
sum = sum + (i-1)*(a[i]-a[i-1]) - (n-i+1)*(a[i]-a[i-1]);
mp[a[i]] = sum;
}
for(long long i=1;i<=n;i++){
if(i<n)cout << mp[b[i]] << " ";
else cout << mp[b[i]];
}
cout << endl;
}
return 0;
}9、 Divisor Chain(二进制拆分)
题意:获得一个整数x,将x减少到1,为此,可以执行以下操作。
选择以x的除数d,然后将x更改为x-d。
有一个额外的限制:你不能选择相同的d值超过两次
最后获得了一个数列(就是x到1过程中的所有数字)
思路:每个整数x可以改为二进制(1...010....0)
我们可以知道证明最后一个1(lowbit)是x的约数
我们以三个1为例子:2^j + 2^k + 2^i
除以2^i
因为j>k>i 那么一定能被整除,所以2^i是x的约数
获得最后一个1的十进制就是树状数组学的lowbit(x&-x)
那么我们第一步先把所有后置1减去,然后再把(10000000...0)一直除以2就可以了(x变成x/2,这里面d=x/2,后面不可能再有一个d==x/2,即使前几步操作有,也最多是2次)
代码如下:
#include <iostream>
using namespace std;
#include <vector>
int main()
{
int t;cin>>t;
while(t--)
{
vector<int> v;
int x;cin>>x;
v.push_back(x);
//每次减去最后一个1,直到x的二进制变成(100...0)形式
while(1)
{
int l = (x&-x);
if(l==x) break;
x -= l;
v.push_back(x);
}
//每次除以2
while(x!=1)
{
x/=2;
v.push_back(x);
}
cout << v.size() << endl;
for(int i=0;i<v.size();i++)
{
cout << v[i] << " ";
}
cout << "\n";
}
return 0;
}总结:对于这道题我一开始是通过计算x所有的约数,然后通过深搜来做的,即使我加了剪枝,但效率显然还是很低。然后我通过题解了解到化成二进制的方法。。(妙啊)
10、 Anonymous Informant
题意:
给定长度为 n 的数列 a,定义一次轮换为将 a1,a2,⋯ ,ana1,a2,⋯,an 变为 a2,a3,⋯ ,an,a1a2,a3,⋯,an,a1。
定义一次操作为,先选择一个满足 ax=x 的数 x,然后对数列做 x 次左移轮换。
再给定 k 与数列 b,求是否存在一个初始序列 a,使得其能经过恰好 k 次合法的操作变为 b。
n≤2×10^5,k≤10^9。
思路:
①、看到操作,选择一个ax = x的数,然后将数组左移轮换x次,那么这个ax的数不就到了数组的末尾。(重点)
②、然后我们如果正向思考,是建立n个不同的图,然后找到里面ax=x的部分,通过k次移动,最后到达给定的a数组,然后输出这个图。这显然是很耗时的,我们可以考虑逆向思考
③、逆向思考:对原来的数组a,找到一个数 a[i] ,如果 (i+a[i])%n == a[i] 说明这个数可以由右移了a[i]次的数组转化而来,而且第一步我们说过了,左移后的ax一定到了数组的末尾,所以我们只需要对结尾的数组进行分析,如果它<=n,那么它一定能由数组向右轮换x次的数组通过这个x左轮回x获得。
④、所以我们先判断初始数组的最后一个a[i],如果它<=n,那么k--,向右轮换a[i],重复这个操作,直到k==0,或者出现了最后一个a[i]>n的情况(说明失败)
⑤、由时间复杂度分析,我们每次判断结尾需要O(n),然后移动数组需要O(n),一共需要O(n²),显然是不允许的,所以我们需要优化移动数组,我们只需要一个指针指向结尾的地方,然后判断即可,可以将时间复杂度优化到O(n)
代码如下:
#include <iostream>
using namespace std;
const int N =2e5+10;
int a[N];
bool vis[N];
int n,k;
void solve()
{
cin>>n>>k;
for(int i=0;i<n;i++)scanf("%d",&a[i]),vis[i]=0;
//让结尾指针指向最后的last
int now = n-1;
//循环k次让结尾指针往前,如果>n说明结束
while(k--)
{
if(vis[now]==1) break; //如果访问过就循环了
vis[now] = 1;
if(a[now]>n){//说明在k之内结束了,输出No即可
cout << "No" << endl;
return;
}
//让now指针往前移动a[now]次,并且注意如果<0 + n
now = (now-a[now]+n)%n;
}
cout << "Yes" << endl;
}
int main()
{
int t;cin>>t;
while(t--){
solve();
}
return 0;
}总结:对于这种轮换数组的题目,我们可以初始数组从0开始,这样我们就不用考虑5%5==5这种特殊情况了。(想了挺久的)
11、Zero Quantity Maximization(利用哈希存储小数,约分利用gcd)
题意:给了两个数组a和b,ci = d*ai+bi,并且d是任意的。求给定一个d,使得c数组中0最少。由题意得,我们可以知道d*ai+bi = 0,所以d=-bi/ai;我们只需要用哈希来存储这个分数即可。
代码如下:
#include <iostream>
using namespace std;
#include <map>
map<int,map<int,int>> mp;
const int N = 2e5+10;
int a[N];
int b[N];
int gcd(int x,int y)
{
return y==0?x:gcd(y,x%y);
}
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
}
for(int i=1;i<=n;i++){
scanf("%d",&b[i]);
}
int Max = 0;
int era = 0;
for(int i=1;i<=n;i++){
double d;
if(a[i]==0&&b[i]!=0){
continue;
}
if(a[i]!=0&&b[i]==0){ //只有d==0,才可以++
d = 0;
mp[0][0]++;
Max = max(Max,mp[0][0]);
continue;
}
if(a[i]==0&&b[i]==0){//不管如何都是0,最终结果也要加上
era++;
}else{
//存入b[i]/gcd和a[i]/gcd
mp[b[i]/gcd(b[i],a[i])][a[i]/gcd(b[i],a[i])]++;
Max = max(Max,mp[b[i]/gcd(b[i],a[i])][a[i]/gcd(b[i],a[i])]);
}
}
cout << Max+era << endl;
return 0;
}12、Maximum Sum of Products(区间dp+前缀和)
题意:有两个数组a和b,然后反转数组a中一个子段,使得ai*bi的和最大。
思路:暴力O(n³),遍历段长,左端点,然后再遍历一遍段长获得反转的值
代码:
#include <iostream>
using namespace std;
const int N = 5001;
//不开longlong见祖宗
long long a[N];
long long b[N];
long long sum[N];
long long dp[N][N];
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++)scanf("%lld",&a[i]);
for(int j=1;j<=n;j++){
scanf("%lld",&b[j]);
sum[j] = sum[j-1] + b[j]*a[j];
dp[j][j] = a[j] * b[j];
}
long long Max = sum[n];
for(int l=1;l<=n;l++){
for(int i=1;i+l<=n;i++){
int j = i+l;
dp[i][j] = dp[i+1][j-1] + a[i]*b[j] + a[j] *b[i];
long long now = sum[i-1] + sum[n] - sum[j] + dp[i][j];
Max = max(Max,now);
}
}
cout << Max << endl;
return 0;
}13、Number of Pairs(求l<=ai+aj<=r的对数)(i<j)
思路:1、排序。(可能有人会想这不是会破坏原来的顺序么,但其实我们只要找到ai+aj不管i和j的大小,只要除以2即可。)2、对于每个ai,从a[i+1]~a[n]找到满足条件的,这时候不用除以2了,因为我们是从i+1~n中选择的,故只需要用二分找到答案即可。
代码如下:
#include <iostream>
using namespace std;
const int N = 2e5+10;
#include <algorithm>
int a[N];
int main()
{
int t;cin>>t;
while(t--){
int n,l,r;scanf("%d%d%d",&n,&l,&r);
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
sort(a+1,a+1+n);
long long sum = 0;
for(int i=1;i<=n;i++){//对于每个ai,找到l-ai~r-ai,如果 i就在这中间呢?
sum += upper_bound(a+i+1,a+1+n,r-a[i]) - lower_bound(a+i+1,a+1+n,l-a[i]);
}
cout << sum << '\n';
}
return 0;
}14、Potions(优先队列或者线性DP)
题意:有个序列a[1],a[2],...a[n]。从左往右,每次可以选择sum+a[i]也可以选择不+,要保证中途sum不能<0,那么我们最多可以选择多少个数?
思路:最多数,一般用DP,想要前i个数最多可以选择j个数?==>前i个数选择j个数后的值
dp[i][j] = dp[i-1][j-1] + a[i]。
代码如下:
#include <iostream>
using namespace std;
#include <queue>
const int N = 2e5+10;
long long a[N];
long long dp[N];
int main()
{
int n;scanf("%d",&n);
for(int i=1;i<=n;i++)scanf("%lld",&a[i]),dp[i]=-1e18;
for(int i=1;i<=n;i++){//dp[i][j]代表前i个数喝了j药水后的值,保证喝了j个药水后的值尽可能最大即可。
for(int j=i;j>0;j--){
if(dp[j-1]+a[i]>=0){
dp[j] = max(dp[j],dp[j-1]+a[i]);
}
}
}
for(int i=n;i>=0;i--){
if(dp[i]>=0){
cout << i << '\n';
break;
}
}
return 0;
}贪心思路(O(nlogn):如果a[i]是正数,那么一定要选择,如果a[i]是负数,为了统一操作,我们也都选择。但是如果出现了负数怎么办?删除前面出现过的最小负数即可,用优先队列维护
代码如下:
#include <iostream>
using namespace std;
#include <queue>
const int N = 2e5+10;
long long a[N];
//正数一定要
//负数不一定要,但是一定要保证要的都大于等于0
//如果这时候不大于等于0,那么只要把前面出现的负数删除即可
int main()
{
int n;scanf("%d",&n);
for(int i=1;i<=n;i++)scanf("%lld",&a[i]);
long long sum = 0;
int ans = 0;
priority_queue<int> Q;
for(int i=1;i<=n;i++){
sum+=a[i];
if(a[i]<0){
Q.push(-a[i]);
}
ans++;
while(sum<0){
int x = Q.top();Q.pop();
ans--;
sum+=x;
}
}
cout << ans << '\n';
return 0;
}Atcoder补题
D.Pedometer(map+前缀和)
题意:有N个点围成一个圈,然后有个N大小的序列a,a[i]代表第i个点到第i+1个点的距离。然后如果有s点到t点的最小距离是M的倍数,我们就说有一对(s,t)。求一共有多少对(s,t)
思路:如果用暴力来做就是求区间和为M的倍数,如果遍历节点肯定是超时的,O(n²)而数据是2e5 ,需要进行优化。一般区间和为定值问题是用map问题,就是说如果pre代表前缀和,pre[j]-pre[i] = M的倍数即可,对于求区间和的优化问题,就是把每个点到终点的距离 % MOD ,然后计算出现了多少次就行。
化圆为线,将数组翻倍。
然后求前缀和%m == 0
转化为求前缀和%m 相同的数
值得注意有范围
代码
#include <iostream>
using namespace std;
const int N = 2e5+10;
int a[N*2];
long long pre[N*2];
#include <map>
int main()
{
int n,m;cin>>n>>m;
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
a[n+i] = a[i];
}
for(int i=1;i<=2*n;i++){
pre[i] = pre[i-1] + a[i];
}
map<int,int> cnt;
long long ans = 0;
for(int i=1;i<=n;i++){
ans += cnt[pre[i]%m]++;
}
for(int i=n+1;i<2*n;i++){
cnt[pre[i-n]%m]--;
ans += cnt[pre[i]%m];
}
cout << ans << endl;
return 0;
}总结:对于求前缀和为定值(或者取模)的问题,要用map优化。
E、Permute K times(操作合并,分治)
题意:给出了两个序列X,和A序列,X序列的元素全是1~N,然后有K次操作,每次操作是把A序列更新为A’ = A[X[i]]。K<=1e18
思路:如果用暴力做的话就是遍历K遍,然后每次进行n次遍历。O(Kn),但是K的范围很大,所以最多时间复杂度应该在O(nlogk),就是对K进行二分操作。每次把两个K操作进行合并。
代码如下:
#include <iostream>
using namespace std;
#include <algorithm>
const int N =2e5+10;
int A[N];
int X[N];
int Y[N];
int temp[N];
int main()
{
int n;
long long k;cin>>n>>k;
for(int i=1;i<=n;i++)scanf("%d",&X[i]);
for(int i=1;i<=n;i++)scanf("%d",&A[i]);
for(int i=0;i<=n;i++)Y[i] = i;
while(k>0){
if(k%2==1){
for(int i=1;i<=n;i++){
Y[i] = X[Y[i]];
}
}
for(int i=1;i<=n;i++){
temp[i] = X[X[i]];
}
for(int i=1;i<=n;i++){
X[i] = temp[i];
}
k/=2;
}
for(int i=1;i<=n;i++){
temp[i] = A[Y[i]];
cout << temp[i] << " ";
}
return 0;
}总结:对于一些操作重复问题可以考虑能否将操作合并然后求解,能将线性的操作转化为Logn
这道题目就类似于Qpow思想。如何快速的求X的n次方,就是每次将N个乘法变成N/2个平方相乘,然后一直二分。
D、Bonus EXP (动态规划)
题意:
高桥将按顺序遇到 N 怪物。 i 第一个怪物 (1≤i≤N)的力量为 Ai 。
对于每个怪物,他可以选择放手或打败它。 每个动作奖励他的经验值如下:
-如果他让一个怪物走,他获得 0 经验值。 -如果他以力量 X 击败怪物,他将获得 X 经验值。 如果它是一个偶数被击败的怪物(第2,第4,…),他获得额外的 X 经验值。
找出他能从怪物身上获得的最大经验值。
思路:问能从怪物上获得的最大经验值,应该考虑动态规划。那么要考虑dp[i]状态的前一个状态是何?可以先考虑两种情况,第一种是i-1被放走了,或者没有放走。那如果我们考虑dp[i] = max(dp[i-1],dp[i-1]+2*a[i])嘛?感觉这肯定不是正确的答案,好像是少了某些条件,比如偶数个被击败的怪物将获得两倍的经验。
少条件了一般就要加维数。
那如果是dp[i][j],时间复杂度一般是O(n²),肯定是不行的
所以j应该是一个常数项。
刚好又只有奇数和偶数
可以考虑dp[i][0]为第i个怪物是第偶数个被打败的
dp[i][1]为第i个怪物是第奇数个被打败的
那么dp[i][0]的前一个情况,1)第i个怪物放走了dp[i-1][0] 2)i-1是奇数个被打败的dp[i-1][1]
那么dp[i][1]的前一个情况,1)第i个怪物放走了dp[i-1][1] 2)i-1是偶数个被打败的dp[i-1][0]
综上所述
dp[i][0] = max(dp[i-1][0],dp[i-1][1]+2*a[i]);
dp[i][1] = max(dp[i-1][1],dp[i-1][0]+a[i]);
重点!:(考虑初始化)
dp[1][0] = 0 这样dp[2][1] = dp[1][0] + a[i]是成立的
dp[1][1] = a[1] 这样
代码如下:
#include <iostream>
using namespace std;
const int N = 2e5+10;
int a[N];
long long dp[N][2];
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
}
dp[1][0] = 0,dp[1][1] = a[1];
for(int i=2;i<=n;i++){
dp[i][0] = max(dp[i-1][0],dp[i-1][1]+2*a[i]);
dp[i][1] = max(dp[i-1][1],dp[i-1][0]+a[i]);
}
cout << max(dp[n][0],dp[n][1]);
return 0;
}图类似于(来源:evima lab)
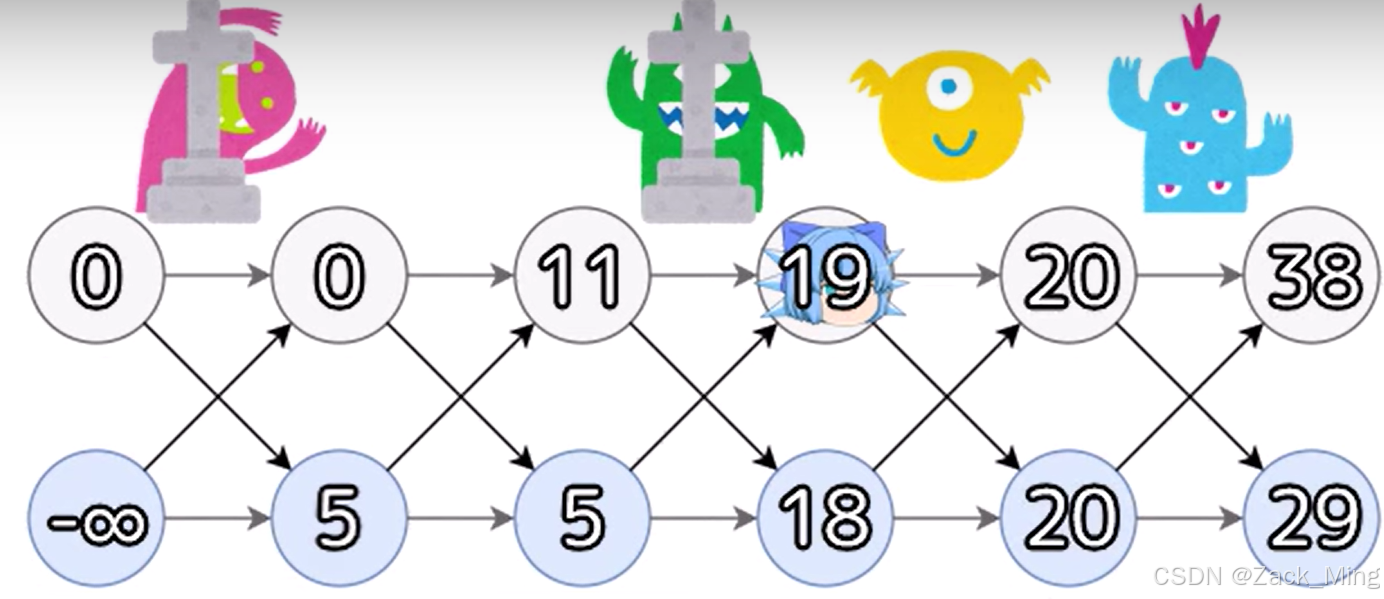
每个状态只由上一个状态转化而来,可以考虑空间优化为O(1)
空间优化后的时间复杂度O(n),空间复杂度(1)
代码如下:
#include <iostream>
using namespace std;
long long dp0,dp1;
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
}
long long x;scanf("%d",&x);
dp0 = 0,dp1 = x;
for(int i=2;i<=n;i++){
scanf("%d",&x);
dp0 = max(dp0,dp1+2*x);
dp1 = max(dp1,dp0+x);
}
cout << max(dp0,dp1);
return 0;
}总结:这种常数二维的动态规划还得练/(ㄒoㄒ)/~~
队列
1、P1540 [NOIP2010 提高组] 机器翻译
题意:有一个英语文本N(长度)、一本外存、一个内存。每次出现一个新单词。先快速从内存中读取翻译,如果内存里面没有,就从外存中获取,并且把外存中的翻译放入内存当中,但是内存有容量上限M,如果超过这个M,就自动把最前面的排出( 0<=ai <= 1000)
输入:M N
a1 a2 a3 ... aN
输出:从外存中获取的次数
思路:首先这个结构类似“对列”,先进后出,并且有一定的长度,很可能就会想可不可以用C++里面的queue做,但实际上queue是不允许遍历的。所以我们可以想想可不可以构造一个类似于队列的结构。想法一、通过vector构造一个对列,每次出来一个新的就放进去,如果size大于M就把vector的头排出,(如果数据较大,反复排出显然是十分浪费效率的,所以我们可以先把原来的元素放在内存中,利用一个指针指向开头,如果end()-it > M 就it++)
原因是vector删除元素的时间复杂度是O(n),如果反复删除,那就是O(n²),对于n=1e5来说,时间复杂度只有在O(nlogn)往往才有资格在合适的时间通过样例。
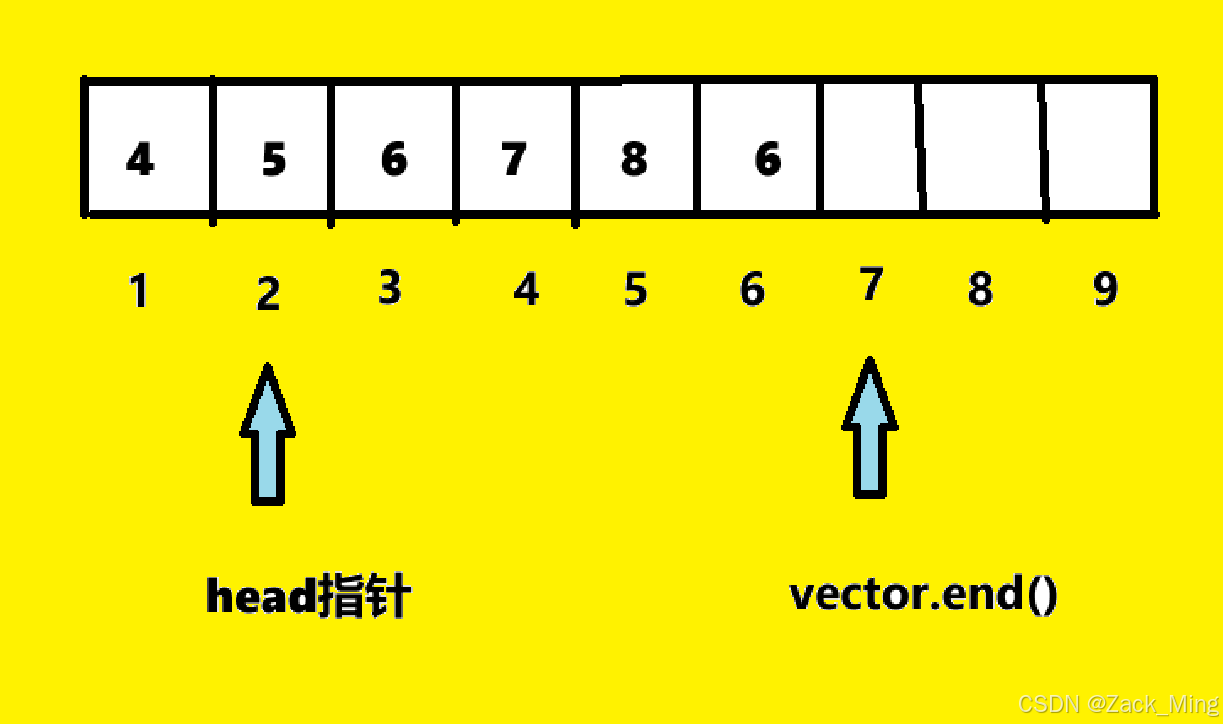
vector.end() - head = 5
如果M = 4,则 head++(指针+1)
优化:每次我们判断队伍里面head~end()中有没有元素X的时候我们的时间复杂度是O(n),所以我们可以利用map来优化这里面的时间效率,利用map<int,int> 如果出现一个就+1,如果vector.end() - head > M ,就让head指向的那个元素-1。 时间复杂度就减少到了1。
#include <iostream>
using namespace std;
#include <vector>
#include <map>
int main()
{
int m,n;cin>>m>>n;
vector<int> arr;
arr.reserve(n);
map<int,int> mp;
int ans = 0;
int head = 0,rear = 0;
for(int i=1;i<=n;i++)
{
//i就是尾指针
int x; cin>>x;
//判断原来有没有
if(mp[x]>0){//有的话就continue
continue;
}else{//没有的话 就从外存中放入内存中
ans++;
arr.push_back(x);
mp[x]++;
if(arr.size()-head > m){
mp[arr[head]]--;
head++;
}
}
}
cout << ans << endl;
return 0;
}总结:对于一些看着类似队列的问题,我们可以利用vector+map+指针来模拟队列,相对于STL里面的queue数据这个数据,能快速查询中间值。
额外知识:对于vector底层操作,它是顺序结构,也就是说它会提前找一个空间 > 1的地方来存放我们的数据(不是size) 当我们的size() > 这个空间的长度的时候,vector就会另外找一片空间,让它大于原来的空间,然后把原来空间的数据复制过去,但这复制的操作有O(n),如果我们增加了m次,那么这个时间复杂度会达到O(nm),会很浪费效率。所以我们可以提前预留vector.reserve(n)这些空间。
2、单调队列模板题
题意:给了一个队列,一个窗口(窗口大小为3),然后用窗口从队列从左往右扫过去,求出窗口每一次滑动的最小值和最大值。
思路:维护固定长度的最大值和最小值可以利用单调队列来维护这个最大值和最小值
单调队列做法:1、队列里面放着下标,然后首先出尾,然后放元素,最后判断头是否超过范围来出头。
#include <iostream>
using namespace std;
#include <deque>
const int N = 1e6+10;
int a[N];
int main()
{
int n,k;cin>>n>>k;
deque<int> Q1;
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
}
deque<int> Q2;
for(int i=1;i<=n;i++)
{
while(!Q2.empty()&&a[i]<a[Q2.back()])Q2.pop_back();
Q2.push_back(i);
if(i>=k){
while(!Q2.empty()&&Q2.front()<=i-k)Q2.pop_front();
cout << a[Q2.front()] << " ";
}
}
cout << endl;
for(int i=1;i<=n;i++)
{
while(!Q1.empty()&&a[i]>a[Q1.back()])Q1.pop_back();
Q1.push_back(i);
if(i>=k){
while(!Q1.empty()&&Q1.front()<=i-k)Q1.pop_front();
cout << a[Q1.front()] << " ";
}
}
return 0;
}总结:如果出现一些维护一定区间内的最大值和最小值的问题,我们可以用“单调队列来维护最小值”
额外知识:如果我们要维护的是一组数据的最大值或最小值问题,我们可以用红黑树来实现,就是在O(logn)的时间复杂度下进行查询find、删除erase、插入insert。并且能在O(1)的时间复杂度下查询数据的最大值或最小值。注意和堆这个数据结构进行区分。堆是一种二叉树结构,然后它只能每次查询最上面的根,并且删除元素也只能删除最上面那个根节点....
对于这两者的区别就好比栈和数组(bushi),堆(栈)是易于理解的结构,并且堆的结构相对简单,在某些情况下占用较少的空间,构建一个堆通常只需要O(n)(是吗?我是查询chatgpt,虽然我觉得貌似构建一个堆也是O(nlogn)吧?),而构建一个红黑树选哟O(nlogn)
3、Max sum
题意:给出序列a1,a2,...an,求连续子序列的最大和。
思路:1、动态规划:列出状态方程,dp[i]表示以i结尾的连续最大子序列的。则dp[i] = max(dp[i-1]+a[i],a[i]);
2、暴力:一个一个加过去,如果sum为负数就抛弃。从下一个数重新加起,然后每次加的时候都要更新这个最大值 Max = max(Max,sum);
#include <iostream>
using namespace std;
#include <deque>
#include <cmath>
const int N = 1e6+10;
int a[N];
int dp[N];
int main()
{
int T;cin>>T;
for(int i=1;i<=T;i++)
{
cout << "Case " << i << ":"<<endl;
int n;cin>>n;
dp[0] = 0;
int Max = -99999999;
int rear;
for(int j=1;j<=n;j++) scanf("%d",&a[j]);
for(int j=1;j<=n;j++){
dp[j] = dp[j-1]+a[j]>a[j]?dp[j-1]+a[j]:a[j];
if(dp[j]>Max){
Max = dp[j];
rear = j;
}
}
int temp = Max;
int j;
int head = 0;
for(j=rear;j>=1;j--){
temp -= a[j];
if(temp==0) head = j;
}
cout << Max << " " << head << " " << rear << endl;
cout << endl;
}
return 0;
}
拓展:如果这个连续子序列加一个限制因素,即这个连续子序列最大不能超过m怎么办?
思路:如果还利用动态规划的话,也许可以加一个数组div[]来记录长度如果dp[i-1]+a[i] <= a[i],则div[i] = 1,否则 div[i] = div[i-1] + 1;然后div[i]就是dp[i]的长度,然后找出满足div[i]<m的最大值...但是我们还可以用单调队列。想法二:如果利用单调队列;就是用一个固定长度的队列来维护前缀和这个,如果超过了长度,就把前面的排掉。
纠正:好像用不了动态规划,因为可能dp[i]它的div[i]>m,但是答案可能还是以i结尾,但是长度较少的值......
4、求m区间的最小值(单调队列训练题)
题意:一个含有 n 项的数列,求出每一项前的 m 个数到它这个区间内的最小值。若前面的数不足 m 项则从第 1 个数开始,若前面没有数则输出 0。
输入:n m
a1,a2,....an
输出:b1,b2,...bn
题意:看到维护区间的最小值,那显然就是利用单调队列即可。
坑点:不能用endl,要用\n
知识:\n不会刷新缓冲区,可以让显示在屏幕中的速度更快。综上所述,如果要求输出的\n很多的时候,最好用\n
#include <iostream>
using namespace std;
#include <deque>
#include <cmath>
const int N = 2e6+10;
int a[N];
int main()
{
int n,m;cin>>n>>m;
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
deque<int> dq;
for(int i=1;i<=n;i++){
//求这时候队列的最小值
if(dq.empty()){
cout << "0\n";
}else{
cout << a[dq.front()] << "\n";
}
while(!dq.empty()&&a[i]<a[dq.back()]) dq.pop_back();
dq.push_back(i);
while(!dq.empty()&&dq.front()<=i-m) dq.pop_front();
}
return 0;
}总结:尽可能用\n来代替endl;好比用scanf代替cin可以加快速度...
5、Look up S
题意:有N头奶牛排在一排,现在每头牛向右看。如果i<j Hi < Hj 我们就说第i只牛仰望第j只牛,求每只牛可以仰望的第一只牛的位置。如果没有就输出0
思路:就是求每个从i+1开始,后面第一个大于h[i]的下标。寻找元素中下一个比它大的值。可以利用单调栈来做。
#include <iostream>
using namespace std;
const int N =1e6+10;
int a[N];
int b[N];
#include <stack>
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
}
stack<int> st;
for(int i=n;i>=1;i--){
//新来的值来看st里面有没有大于它的
while(!st.empty()&&a[i]>=a[st.top()]) st.pop();
if(st.empty()){
b[i] = 0;
}else{
b[i] = st.top();
}
st.push(i);
}
for(int i=1;i<=n;i++){
cout << b[i] << "\n";
}
return 0;
}总结:求元素下一个的较大(较小)值,当然是用单调栈~
6、切蛋糕
题意:在一个序列中找到,最长子序列和,且这个长度限制在1~m内。
思路:利用 前缀和+单调队列 可以来维护 一定 区间的最长子序列的和。sum[l~r] = sum[r] - sum[l-1]。那么我们让r遍历1~n,然后维护这个值前面m个之中最小的sum[l-1],从而维护最大的sum[l~r]
然后我们只需要从维护的最大值中找到最大的就可以了。这道题类似与后面章节《二分》里面第一题《寻找段落》很像。都是通过 前缀和+单调队列 来维护 区间内的最长子序列的和,且有范围大小,而且这里大小是1~m, 那一题是s~t。可以好好参考一下。
#include <iostream>
using namespace std;
const int N = 5e5+10;
int n,m;
int a[N];
int sum[N];
#include <queue>
int main()
{
cin >> n>>m;
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
//想要知道区间最大和,且范围在1~m之间
for(int i=1;i<=n;i++){
sum[i] = sum[i-1] + a[i];
}
deque<int> q;
//找到最大值里面的最大值
int max = -999999999;
for(int i=1;i<=n;i++){
if(i-1>=0){
while(!q.empty()&&sum[i-1]<sum[q.back()]) q.pop_back();
q.push_back(i-1);
}
while(!q.empty()&&i-q.front()>m) q.pop_front();
if(!q.empty()&&sum[i]-sum[q.front()]>max){
max = sum[i] - sum[q.front()];
}
}
cout << max << endl;
return 0;
}总结:对于求最长连续子序列的和的问题我们可以用dp来做,但如果这个子序列的长度范围有限定,那我们就可以用 单调队列 + 前缀和的思想来做....
7、好消息,坏消息
题意:小明有n个消息要给boss,但是每个消息有好心情有坏心情,如果累计的心情值小于0,那么小明就要被炒鱿鱼。坏消息,这n个消息是有顺序的,好消息是小明可以从第k个消息开始给boss看,比如从第k个信息给老板看,那么接下来就是k+1,k+2,k+3,...,n,1,2,3... k-1。
请问有多少个这样的k。使得小明不会被老板炒鱿鱼-。-
思路:对于这种循环的问题,我们首先可以将数组×2,然后a[n+i] = a[i] 。然后如图

代码如下:
#include <iostream>
using namespace std;
#include <deque>
const int N = 2e6+10;
int a[N];
int sum[N];
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
a[n+i] = a[i];
}
for(int i=1;i<=2*n;i++){
sum[i] = sum[i-1] + a[i];
}
deque<int> q;
int ans = 0;
for(int i=1;i<2*n;i++){
//维护sum[1]-sum[0],sum[2]-sum[0]....sum[4] - sum[0]中的最小值,就是维护sum[]的最小值
while(!q.empty()&&sum[i]<sum[q.back()]) q.pop_back();
q.push_back(i);
while(!q.empty()&&i-q.front()+1>n) q.pop_front();
if(i>=n){
//找出最小值的sum,然后用sum[i] - sum[i-n]
if(sum[q.front()]-sum[i-n]>=0) ans++;
}
}
cout << ans << endl;
return 0;
}8、P2776 [SDOI2007] 小组队列
题意:
有 m 个小组, n 个元素,每个元素属于且仅属于一个小组。
支持以下操作:
push x:使元素 x 进队,如果前边有 x 所属小组的元素,x 会排到自己小组最后一个元素的下一个位置,否则 x 排到整个队列最后的位置。
pop:出队,弹出队头并输出出队元素,出队的方式和普通队列相同,即排在前边的元素先出队。
第一行有两个正整数 n, m,分别表示元素个数和小组个数,元素和小组均从 0 开始编号。
思路:
是先把元素放入一个组里面,然后组还形成了一个队列。类似于队列套队列。双重队列的感觉。
看代码~
#include <iostream>
using namespace std;
#include <deque>
const int M = 3e2+10;
const int N = 1e5+10;
int a[N];
int main()
{
int n,m;cin>>n>>m;
deque<int> q[n],Q;
for(int i=0;i<n;i++){
scanf("%d",&a[i]);
}
//a[i]代表i的小组
int K;cin>>K;
while(K--){
string str;cin>>str;
if(str=="push"){
int x;cin>>x;
q[a[x]].push_back(x);
if(q[a[x]].size()==1){
Q.push_back(a[x]);
}
}else{
int X = Q.front();
cout << q[X].front() << "\n";
if(q[X].size()==1){
q[X].pop_front();
Q.pop_front();
}else{
q[X].pop_front();
}
}
}
return 0;
}总结:有助于理解队列套队列..
二叉树和哈夫曼树
哈夫曼树介绍:带权路径长度最短的最优树,是贪心+二叉树的应用。
1、Entropy
题意:对一个字符串输出它ASCII编码长度和哈夫曼编码长度。并且输出压缩比。ASCII编码长度为8。
思路:构建一个哈夫曼树,并且记录字符串的哈夫曼编码长度。
代码如下:
#include <iostream>
using namespace std;
#include <queue>
#include <algorithm>
#include <vector>
int main()
{
string s;
while(cin>>s&&s!="END")
{
cout << s.size()*8 << " ";
//构建哈夫曼树,先选择最小的两个结点,每个字符个数代表结点大小,
priority_queue<int,vector<int>,greater<int>> q;
//然后将s里面排序,将每个数字放入q里面
sort(s.begin(),s.end());
for(int i=0;i<s.length();i++){
int ans = upper_bound(s.begin(),s.end(),s[i]) - lower_bound(s.begin(),s.end(),s[i]);
q.push(ans);
i+=ans;
i--;
}
int ans = 0;
if(q.size()==1) ans = 1;
//然后选取最小的两个
while(q.size()>1){
int a = q.top();q.pop();
int b = q.top();q.pop();
q.push(a+b);
ans += (a+b); //每次加入a+b,因为小的都在底部,如果
}
cout << ans << " ";
printf("%.1lf\n",(double)s.size()*8 / (double)ans);
}
return 0;
}2、FBI树
题意:一个0/1字符串和一个N,2^N是0/1字符串的长度
思路:可以用线段树的思想,将每个段落分为一个tree,然后再遍历这个线段树...
代码如下:
#include <iostream>
using namespace std;
const int N = 2e5+10;
#include <cmath>
#include <algorithm>
#include <cstring>
int tree[N<<2];
int ls(int q){return q<<1;}
int rs(int q){return q<<1|1;}
string s;
void push_up(int q)
{
//如果两个孩子都是一个就为孩子的
if(tree[ls(q)]==tree[rs(q)]){
tree[q] = tree[ls(q)];
}else{
tree[q] = 3;
}
}
void build(int q,int ql,int qr)
{
if(ql==qr){
if(s[ql]=='1'){
tree[q] = 1;
}else if(s[ql]=='0'){
tree[q] = 2;
}
return;
}
int mid = (ql+qr)/2;
build(ls(q),ql,mid);
build(rs(q),mid+1,qr);
push_up(q);
}
void print(int q)
{
//后序遍历
if(tree[ls(q)]!=0)print(ls(q));
if(tree[rs(q)]!=0)print(rs(q));
if(tree[q]==1){
cout << "I";
}else if(tree[q]==2){
cout << "B";
}else if(tree[q]==3){
cout << "F";
}
}
int main()
{
int N;cin>>N;
cin>>s;
s = ' '+s;
int x = pow(2,N);
build(1,1,x);
print(1);
return 0;
}堆
1、利用堆来快速求数据流的中位数。
1、中位数
题意:N 非负整数序列A,前奇数项求中位数
思路:利用堆的性质,构建一个大根堆和小根堆来快速求得中位数。
1、看当前数是否小于等于大根堆堆顶(理解为数组小的一半数中的最大值)
2、如果是就把数放入大根堆,否则放入小根堆
3、最后判断大根堆和小根堆的差是否==2,维护一下两者的size()相差<= 1
奇数时,中位数就是大小根堆中size()大的堆顶。偶数时,中位数就是两个堆的堆顶
代码如下:
#include <iostream>
using namespace std;
#include <queue>
#include <vector>
const int N =2e5+10;
int main()
{
int n;cin>>n;
priority_queue<int,vector<int>,greater<int>> q;
priority_queue<int> Q;//大根堆
int x; cin>>x;
Q.push(x);
cout << x << endl;
for(int i=2;i<=n;i++){
//放入
int x;scanf("%d",&x);
//判断与大根堆的大小
if(x<=Q.top()){
Q.push(x);
}else{
q.push(x);
}
//然后稳定根的平衡性
int u = Q.size() - q.size();
if(u>=2){
int x = Q.top();Q.pop();
q.push(x);
}
u = q.size() - Q.size();
if(u>=2){
int x = q.top();q.pop();
Q.push(x);
}
if(i%2==1){
//输出size最大的
if(Q.size()>q.size()){
cout << Q.top() << endl;
}else{
cout << q.top() << endl;
}
}
}
return 0;
}2、求函数的最小值
题意:有n个函数类似于 F(x) = Ax²+Bx+C,然后已经知道每个函数的A,B,C(均为正整数),然后求这些函数里面当x为正整数的m个最小值。
思路:因为ABC均为正整数,根据-b/2a,对称轴都在负数,所以每个函数在(0,+∞)是递增的。所以最暴力的做法,就是每个函数取m个数放入小堆中,然后依次取出m个最小值即可。时间复杂度O(nmlog(nm)),而题目要求n<=1e5,m<=1e5。显然是不可取的。那么考虑优化,将每个函数x=1的值放入堆中,然后输出最小的值,然后再把这个最小值所在函数的x=2带入。重复即可。时间复杂度来到了(nlogn)。是可以完成题目要求的。
代码如下:
#include <iostream>
using namespace std;
#include <queue>
#include <vector>
int n,m;
const int N = 1e5+10;
int A[N],B[N],C[N];
int function(int a,int b,int c,int x)//函数值
{
return a*x*x+b*x+c;
}
struct node{
int i;//第几个函数标号
int x=1;//x的值
//小根堆
bool operator<(const node &a) const{
return function(A[i],B[i],C[i],x)>function(A[a.i],B[a.i],C[a.i],a.x);
}
}a[N];
int main()
{
priority_queue<node> q;
cin>>n>>m;
for(int i=1;i<=n;i++) a[i].i=i,scanf("%d%d%d",&A[i],&B[i],&C[i]);
for(int i=1;i<=n;i++){
q.push(a[i]);
}
while(m--)
{
//取出最小的
node x = q.top();q.pop();
//输出
cout << function(A[x.i],B[x.i],C[x.i],x.x) << " ";
//然后把这个i
a[x.i].x++;
x.x ++;
q.push(a[x.i]);
}
return 0;
}总结: 加强了对结构体和重载运算符的运用。
二分
1、寻找段落
题意:一个长度为n的序列a,定义ai为第i个元素的价值。现在需要找到序列中最有价值的"段落"。最有价值段落是指 子序列和最大的段落 / 段长。
思路:1、如果我们用暴力法来做,就是用点和线段求一段的和,然后求这些线段和的最大值,稍微优化就是利用前缀和把时间复杂度从O() -> O(
)。但是题目中n 最大有1e6,故最好优化到nlogn的时间复杂度才可以。2、根据题意我们可以知道,我们要求的是 子序列和最大的段落 /段长。如果只要 子序列和最大的段落 且 段长 在S~T之间。
第一步、二分mid值
第二步、设计check函数:如果 sum = mid * k ( k∈[S,T] ),我们需要找到k长度
al + a.. + ar = mid + mid + mid...
移项: (a[i] - mid)* k = 0) ——> b[i] = a[i] - mid所以如果存在S~T的b[i]区间和大于0,就说明还有更大的mid。二分让left = mid 反之则 right = mid; (浮点数的二分的left = mid ,right =mid)
第三步、问题就转换为了,我们如何在check函数中找到存在一个区间和S~T 大于 0呢?
我们可以先求b[i]的前缀和。
区间和 sum[] = sum[i] - sum[j] 且 S<= i-j <= T
所以我们想让sum[]最大,就要让sum[j]尽可能的小,我们用单调队列来维护一个长度为S的滑动窗口,然后数列是sum的最小值。 (单调队列模板题)就是说sum中每个S滑动窗口的最小值是多少,如图:
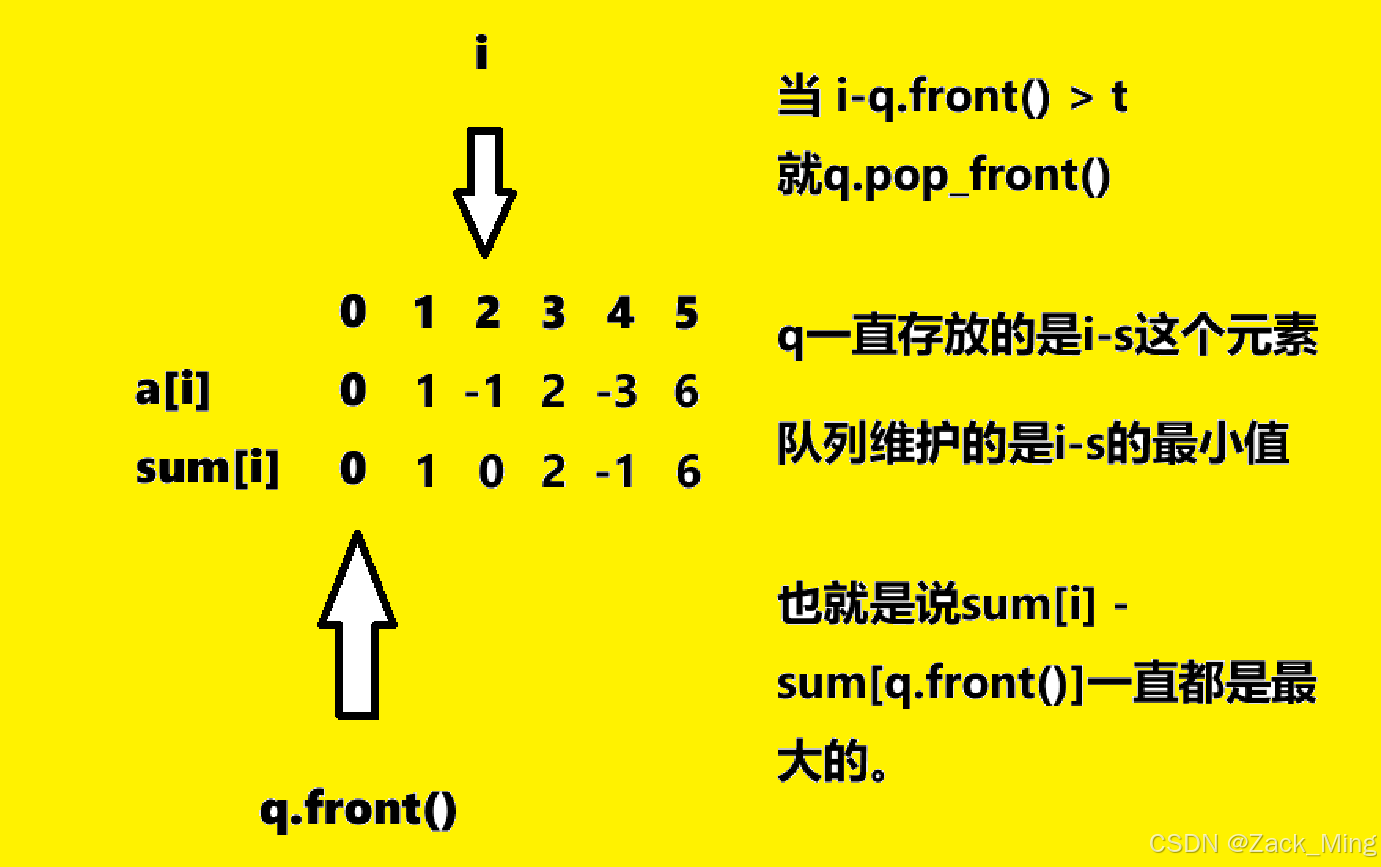
#include <iostream>
using namespace std;
#include <deque>
const int N = 1e6+10;
int S,T,n;
double a[N];
double b[N];
double sum[N];
bool check(double mid)
{
sum[0] = 0;
for(int i=1;i<=n;i++)
{
b[i] = a[i] - mid;
sum[i] = sum[i-1] + b[i];
}
//寻找区间中范围S~T的区间和 > 0
// sum = sum[i] - sum[j]
// 如果i随着0~n变化,当sum[j]最小的时候,sum是最大的。
// 也就是说,我们只要维护在区间[i-t,i-s]中sum[j]是最小的,那么这个sum就是最大的。只要存在一个最大值大于0,就说明还有比mid更大的平均值
deque<int> de;
de.clear();
for(int i=1;i<=n;i++){
if(i>=S)
{//维护sum[j]的最小值
while(!de.empty()&&sum[i-S]<sum[de.back()]) de.pop_back();//维护最小值,就是让这个队列从左往右是递增的
de.push_back(i-S);
}
//当 i - de.front() > t 的时候 说明 区间比t大了 就要排走
while(!de.empty()&&i-de.front()>T) de.pop_front();
//然后计算这个最大值,如果大于0 就直接退出就好了, 说明有更大的平均值, 让mid往右边走,所以让left = mid
if(!de.empty()&&sum[i]-sum[de.front()]>=0){
return true;
}
}
return false;
}
int main()
{
cin>>n;
cin >> S >> T;
for(int i=1;i<=n;i++) scanf("%lf",&a[i]);
double l = -10000,r = 10000;
while(r-l > 1e-5)
{
double mid = (l+r) / 2;
if(check(mid)){
l = mid;
}else{
r = mid;
}
}
printf("%.3lf\n",l);
return 0;
}总结:单调队列+二分。最主要的是这个单调队列很难想,不过既然做过这种题目了,我们只需记住当 我们想要知道S~T区间范围的最大值 的时候,我们可以用单调队列,然后转换为前缀和,然后当 i - q.front() > t 的时候 就排出最前面的即可
易错点:我第二次做的时候想着不减去那个mid可以优化一些效率,就想看看怎么做,然后去做,发现是错误的。然后经过断点分析,我发现,这个单调队列维护的是S~T区间范围的最大值,而我们想要的 不是 (最大区间和/它的长度 >= mid) 而是最大的 ((区间和 / 长度) >= mid) ,然后只有当我们每个数减去mid的时候
总结2:对于求 “最大平均值" 问题可以二分平均值的方法,然后把数组里面每个元素-mid,再判断最大区间和是否大于0即可。如果有范围S~T可以用单调队列进行维护
总结3:这个可有可无,就是double类型的数据不能用>>运算
2、借教室
题意:
题目描述
在大学期间,经常需要租借教室。大到院系举办活动,小到学习小组自习讨论,都需要向学校申请借教室。教室的大小功能不同,借教室人的身份不同,借教室的手续也不一样。
面对海量租借教室的信息,我们自然希望编程解决这个问题。
我们需要处理接下来 n 天的借教室信息,其中第 i 天学校有 ri 个教室可供租借。共有 m 份订单,每份订单用三个正整数描述,分别为 dj,sj,tj,表示某租借者需要从第 sj 天到第 tj 天租借教室(包括第 sj 天和第 tj 天),每天需要租借 djdj 个教室。
我们假定,租借者对教室的大小、地点没有要求。即对于每份订单,我们只需要每天提供 dj 个教室,而它们具体是哪些教室,每天是否是相同的教室则不用考虑。
借教室的原则是先到先得,也就是说我们要按照订单的先后顺序依次为每份订单分配教室。如果在分配的过程中遇到一份订单无法完全满足,则需要停止教室的分配,通知当前申请人修改订单。这里的无法满足指从第 sjsj 天到第 tjtj 天中有至少一天剩余的教室数量不足 dj 个。
现在我们需要知道,是否会有订单无法完全满足。如果有,需要通知哪一个申请人修改订单。
输入格式
第一行包含两个正整数 n,m,表示天数和订单的数量。
第二行包含 n 个正整数,其中第 ii 个数为 ri,表示第 i 天可用于租借的教室数量。
接下来有 m 行,每行包含三个正整数 dj,sj,tj,表示租借的数量,租借开始、结束分别在第几天。
每行相邻的两个数之间均用一个空格隔开。天数与订单均用从 1 开始的整数编号。
输出格式
如果所有订单均可满足,则输出只有一行,包含一个整数 0。否则(订单无法完全满足)
输出两行,第一行输出一个负整数 −1,第二行输出需要修改订单的申请人编号。
思路:如果第k份订单不能满足。那前面的任何都是可以满足的,第k份开始的后面所有都是不可以满足的。符合二分的原理,一边成立,另一边不成立,我们只需要通过二分获取右边不满足的第一个利用二分模板(这个模板的意思就是获得满足条件的第一个的位置,然后K份前面肯定都是满足的,第K份满足,则获取第K份即可
while(l<r){
int mid = (l+r) / 2;
if(check(mid)){
r = mid;
}else{
l = mid + 1;
}
}
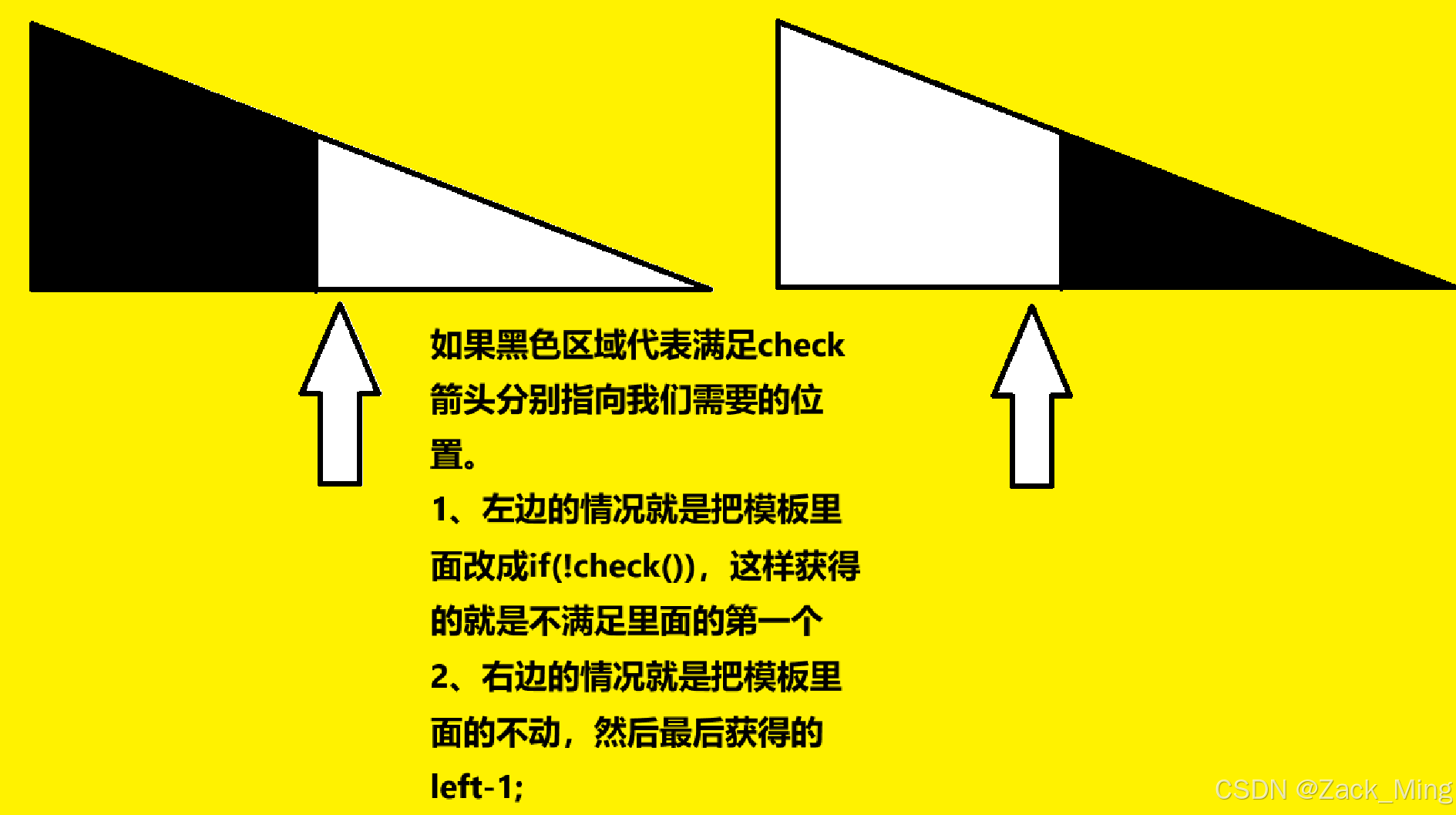
所以几乎所有的二分我们只需要记住一个模板就好了,这个模板就是满足条件的第一个..可以通过一些理解转换成不满足的第一个等等...
继续我们的想法,当我们对k份订单二分的时候,我们来构造check函数,什么时候我们第k份订单不满足呢?就是获得前k份订单后,每一天会有几个教室被租用,一旦有一天教室被借爆,就说明这个肯定是不满足,那么对于区间操作我们用线段树、树状数组、前缀和与差分。显然题目只是简单的区间统一修改和,只需用前缀和与差分即可,下面是本题的代码
#include <iostream>
using namespace std;
#define int long long
const int N = 1e6+10;
int a[N];
int d[N];
int s[N];//s~t天
int t[N];
int sum[N];
int dsum[N];
int n,m;
bool check(int mid)
{
for(int i=0;i<=n;i++) dsum[i] = 0;
for(int i=1;i<=mid;i++){//要让s[i]~t[i]天 +d[i]//会爆int 10^9 10^9 10^9 ...前缀和就大于2e9
dsum[s[i]] += d[i];
dsum[t[i]+1] -= d[i];
}
sum[0] = 0;
for(int i=1;i<=n;i++){
sum[i] = sum[i-1] + dsum[i];
}
for(int i=1;i<=n;i++){//如果存在有一天sum[i] > a[i]
if(sum[i]>a[i]){
return true;
}
}
return false;
}
signed main()
{
cin>>n>>m;
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
for(int i=1;i<=m;i++)scanf("%d%d%d",&d[i],&s[i],&t[i]);
//二分答案
int left = 0,right = m;
if(!check(m)){cout<<"0";return 0;}
while(left < right){
int mid = (left + right ) / 2;
if(check(mid)){//不满足
right = mid ;
}else{
left = mid + 1;
}
}
if(left>m){//left不可能大于m,所以我们要提前判断m是否可行即可...
cout << 0 << endl;
}else{
cout << -1 << endl;
cout << left << endl;
}
return 0;
}WA点:1、int会爆。2、如果恰好第m个点不满足的时候,left = mid,第m个点满足的时候,left也是mid,所以我们可以提前判断第m点是否满足...
总结:简单的 前缀和 + 二分 的题目啦~
离散化
伪代码:
1、用新数组存储原数组
——> 1000 1000 100 1 10 (olda[i]和newa[i])
2、对原数组排序
——> 1 10 100 1000 1000 (olda[i])
3、去重
——> 1 10 100 1000 (olda[i])
4、然后遍历存储新数组,对newa[i],二分获取在olda[i]中newa的位置-olda,就是newa[i]的值
(1)、newa[i]数组是1000 1000 100 1 10
(2)、i=1时,1000在olda[i]的位置是4,所以newa[1]=4
(3)、i=2时,1000在olda[i]的位置是4,所以newa[2]=4
(4)、i=3时,100在olda[i]的位置是3,所以newa[3]=3
(5)、i=4时,1在olda[i]的位置是1,所以newa[4]=1
(6)、i=5时,10在olda[i]的位置是2,所以newa[5]=2
5、获得离散数组newa[i] ={4,4,3,1,2};
代码如下:
#include <iostream>
using namespace std;
#include <algorithm>
const int N = 2e5+10;
int olda[N]; //离散化之前
int newa[N]; //离散化之后
int main()
{
int n;
scanf("%d",&n);
for(int i=1;i<=n;i++){
scanf("%d",&olda[i]);
newa[i] = olda[i];
}
//对olda排序
sort(olda+1,olda+n+1);
int cnt;
if(unique(olda+1,olda+1+n)==olda+1+n){//如果成立说明没有重复元素
cnt = n
}else{//说明有重复元素
cnt = unique(olda+1,olda+1+n) - olda;
}
for(int i=1;i<=cnt;i++){
newa[i] = lower_bound(olda+1,olda+1+n,newa[i]) - olda;
}
for(int i=1;i<=cnt;i++){
cout << newa[i] << " ";
}
cout << "\n";
return 0;
}总结:加强对unique函数的使用(1)、对一个有序表进行去重(2)、返回值是指向最后一个不重复的指针,如果没有重复的就返回最后一个元素,所以需要我们分情况讨论。
三分
三分用于求峰值
1、实数三分
#include <iostream>
using namespace std;
int n;
double a[16];
double f(double mid){
double s = 0;
for(int i=n;i>=0;i--){
s = s*mid + a[i];
}
return s;
}
int main()
{
double l,r;
cin>>n>>l>>r;
for(int i=n;i>=0;i--)cin>>a[i];
while(r-l>1e-12){
double k = (r-l) / 3;
double mid1 = l + k;
double mid2 = r - k;
if(f(mid1)<f(mid2)){
l = mid1;
}else{
r = mid2;
}
}
printf("%.5lf",l);
return 0;
}动态规划
动态规划从0/1背包开始、其实还是挺简单的。最简单的0/1背包就是小偷偷东西,每个东西价值是v[i],重量是w[i]。然后小偷最多偷重量为W。
0/1 背包
首先我们不管前面怎么样,判断每个东西要不要偷(0/1)
然后从最后一个物品开始讨论:dp[i][j]表示偷i个东西,背包是j,最多能偷的价值是dp[i][j]
最后一个东西要不要偷? 偷的话 :dp[i][j] = dp[i-1][j-w[i]]+v[i]
不偷的话:dp[i][j] = dp[i-1][j]
偷不起:dp[i][j] = dp[i-1][j]
所以每一个物品是不是就可以转换成
dp[i][j] = max(dp[i-1][j],dp[i-1][j-w[i]]+v[i])
记住不管i和j是多少,这个状态都成立。所以叫状态转移方程
就跟走楼梯一样。
多重背包
就是每个物品有m[i]个。其实我们也可以转换成 0/1 背包的问题。
比如3种物品分别有2,3,4个。那就可以转换成2+3+4=9种物品的0/1背包
但是这个时间复杂度就来到了O(n³)所以,我们可以通过二进制优化或单调区间进行优化
二进制优化
比如我们现在有1种物品,这种物品有12种,如果我们按传统的来做,我们需要假设有12种物品,dp[12]这么大,但是如果把这个物品分成4堆 1,2,8,1(二进制剩余的) 。那么,我们只需要判断dp[4]一点,如果数据很大,优化就很明显。其实就是说1000个苹果,我们要判断1000苹果要不要,我们判断1000种物品,但是如果我们分成了 2^10 2^9 2^8.... 2^3 2^2 2^1 2^0 那么就只要判断10种物品。代码就看下面这道题吧
1、宝物筛选(二进制优化 +dp 或者 单调队列 + dp)
题意:有n个宝贝,第i个宝贝的价值、重量、数量分别是v[i]、w[i]、m[i]。然后现在背包只有W容量。求能获得的宝贝的最大价值是多少。
思路:如果用传统的方法做,时间复杂度来到了O(n三次方),通过二进制优化可以降到O((n+logn)²)
代码如下:
#include <iostream>
using namespace std;
const int N = 2e5+10;
int v[N],w[N],m[N],new_v[N],new_w[N],dp[N];
int new_n = 0;
int main()
{
int n,W;cin>>n>>W;
for(int i=1;i<=n;i++) scanf("%d%d%d",&v[i],&w[i],&m[i]);
//二进制优化代码如下
for(int i=1;i<=n;i++){
for(int j=1;j<=m[i];j*=2){
m[i] -= j;
new_v[++new_n] = j * v[i];
new_w[new_n] = j * w[i];
}
if(m[i]){ //如果有剩余
new_v[++new_n] = m[i] * v[i];
new_w[new_n] = m[i] * w[i];
}
}
//0/1背包
for(int i=1;i<=new_n;i++){
for(int j=W;j>=new_w[i];j--){
dp[j] = max(dp[j],dp[j-new_w[i]]+new_v[i]);
}
}
cout << dp[W] << endl;
return 0;
}2、砝码称重
设有 1g、2g、3g、5g、10g、20g 的砝码各若干枚(其总重 ≤1000≤1000),可以表示成多少种重量?
思想:如果是暴力的想法,应该是遍历每一种砝码的个数,然后用砝码乘以*克数。那就是n的六次方。显然十分暴力,如果用搜索的方法,就是先遍历1g的砝码,然后要几个,然后再遍历2g砝码,要几个.... 既然能用搜索做的题目,优先要想到动态规划,如果把这些分成6种砝码,每种砝码分别有多少个,然后问种类,是不是与多重背包有些类似。那我们用dp[i]代表有前i个砝码能组合多少种搭配。但我们需要的是多少种重量,我们该如何把这个多少种搭配去掉呢?
我们可以换个思路,把重量带上dp[i][j]代表有i种背包,背包最多能装 j g东西。如果每个东西价值是它的重量,那么背包装满了不就刚好是它的重量吗?
所以最后遍历一遍dp[i][1000] 如果dp[6][j] == j 就说明有途径可以装满j克的背包。
代码如下:
#include <iostream>
using namespace std;
int a[7];
int w[7] = {0,1,2,3,5,10,20};
int dp[1001];
int new_w[1001];
int new_n = 0;
int main()
{
for(int i=1;i<=6;i++)cin>>a[i];
for(int i=1;i<=6;i++){
for(int j=1;j<=a[i];j<<=1){
a[i] -= j;
new_w[++new_n] = j * w[i];
}
if(a[i]){
new_w[++new_n] = a[i] * w[i];
}
}
for(int i=1;i<=new_n;i++){
for(int j=1001;j>=new_w[i];j--){
dp[j] = max(dp[j],dp[j-new_w[i]]+new_w[i]);
}
}
int ans = 0;
for(int i=1;i<=1000;i++){
if(dp[i]==i) ans++;
}
cout << "Total=" << ans << endl;
return 0;
}3、最长公共子序列
题意:有两个X和Y,求X和Y的最长公共子序列;比如abcdadsasd和adsdaf的最长公共子序列就是adsd
思考:这类题目,直接用dp做即可,dp[i][j]中的i代表X序列的前i个字母,j代表Y序列的前J个字母。dp[i][j]代表X序列前i个字母序列和Y前j个字母序列的最长公共子序列的大小
(我没搞懂HDU里面的输入输出是怎么回事,如果有知道的可以告诉我一下)
#include <iostream>
using namespace std;
const int N = 1e3+10;
int dp[N][N];
#include <cstring>
int main()
{
string a,b;
while(cin>>a>>b){
memset(dp,0,sizeof(dp));
int n = a.length();
int m = b.length();
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
if(a[i-1]==b[j-1]){
dp[i][j]=dp[i-1][j-1]+1;
}else{
dp[i][j]=dp[i-1][j]>dp[i][j-1]?dp[i-1][j]:dp[i][j-1];
}
}
}
cout << dp[n][m] << endl;
}
return 0;
}4、最少拦截系统
题意:有一个序列,求它的非递增子序列的最小数量。
思路:贪心:每当新增加一个数a[i],我们有2个选择:
1、从以前的子序列中找到可以加入的,然后加入
2、新创立一个新的子序列
因为我们想要非递增子序列的最小数量,所以优先度 1 > 2
然后从从前的子序列中还有很多情况:
1、这个子序列最后一个数小于新来的数a[i]
2、这个子序列最后一个数大于等于新来的数a[i]
因为我们求的是非递增子序列,所以当然只能选择2
最后能加入的子序列中应该加入哪一个子序列?(比如a[i] = 4,前面能加入的子序列最后一个数是 1,4,5。
因为我们想要非递增子序列最多。
如果我们选择把新来的子序列放入数最大的,比如把数放入5那么更新为4,如果之后新来一个5,那么必须要新开辟一个子序列,如果我们把数放入4里面,那么新来一个5,还可以放入原来老系统中的5.
所以想要非递增子序列最多,就要把a[i]放入能放入的最小值(二分)
综上所述,暴力做法就是遍历数组a,然后对每一个a[i],要遍历前n个子序列中,找到第一个大于等于a[i]的a[j]。 时间复杂度O(n²)
优化:对于查找、删除、增添的O(n)操作,可以利用红黑树进行操作。就是multiset,这样能把时间复杂度降至O(nlogn)
代码如下:
#include <iostream>
#include <cstring>
using namespace std;
#include <vector>
#include <algorithm>
#include <set>
int main()
{
int n;
while(scanf("%d",&n)!=EOF)
{
vector<int> a(n+1);
vector<int> dp(n+1);
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
multiset<int> st;
for(int i=1;i<=n;i++){
//来了一个导弹,
//跟上老系统 或者 新建一个新系统
//因为要系统尽可能少,所以跟上老系统,然后是非递增,所以要从老系统中找到a[j] >= a[i]
//如果老系统中有很多可以选择,因为要系统尽可能少,所以要跟上可以选择的老系统中 高度最小的哪一个
//能否跟上老系统
//能,从老系统中找到第一个可以选择的
auto p = st.lower_bound(a[i]); //找到第一个a[j] >= a[i]
//如果有,就更新这个值
if(p!=st.end()){
st.erase(p);
st.insert(a[i]);
}else{
st.insert(a[i]);
}
}
cout << st.size() << endl;
}
return 0;
}额外知识:Dilworth 定理(序理论),通过这个理论将问题转换求最长子序列的长度,就是非递增子序列的最少数量。然后求最长子序列的长度就是dp问题
5、编辑距离
题意:给出两个字符串A,B。现在能进行3个操作,1、插入一个字符,2、删除一个字符,3、替换一个字符。求将A转化为B的最小操作数
思路:对于求最小操作数之类的,还是用dp。首先是考虑子问题是什么,那就是对字符串进行增、删、改、不变、四种情况。
想想倒数第二种情况,也就是B字符串的前身
如果将某个字符串只进行一次操作就变成B字符串,那么这个字符串有3种情况、
(1、比B字符串多一个字符,删除那个多的字符)
(2、比B字符串少一个字符,插入一个字符)
(3、相对于B字符串数量不变,但是有一个字符不一样)
然后我们要开始考虑状态转移方程:
如果是一维的dp[i]这个i代表的应该是什么呢?
(1)、是A转换成前i个B字符需要操作?那我们来试试,dp[n-1]是将A转换成前n-1个B字符的最小操作数,则dp[n]应该是这个dp[n-1]通过增加一个字符转移而来的,显然少考虑了另外两种情况。(2)、如果是前i个A子字符串转移B字符,则dp[n-1]-> dp[n]也是dp[n-1] + 1或者不变(如果最后一个刚好跟B字符一样?)
(3)、还有一维的dp么?
那么一维的不行,我们考虑二维的 dp[i][j]
dp[i][j]代表前i个A子串 转化为 前j个B子串 的最小操作数
答案就是dp[a.length()][b.length()] 那么我们来看看答案的前一状态能否通过三种情况来变成最后一种情况
1、如果是删除操作,那么dp[i][j] 等价于 dp[i-1][j] + 1
(解释:就是第a[i] != b[j],那么我们暂时不管a[i]字符,只考虑前i-1个字符串,将这些字符串转变为B字符串,需要的最小操作数,然后最后把前面那么我们不管的字符删除即可)
2、如果是添加操作,那么dp[i][j] 等价于 dp[i][j-1] + 1
(解释:如果第a[i] != b[j],那么我们也暂时不管b[j]字符,只考虑a[i]以前所有元素转化为b[j-1]以前所有元素的最少操作数,然后最后在a字符串的最后加一个b[j]字符,就变成了B字符串)
3、如果是替换操作,那么dp[i][j] 等价于 dp[i-1][j-1] + 1
(解释:如果第a[i]!=b[j],那么我们同时不管a和b的最后字符,把前面的a前面的字符串转化为b前面字符串的,然后因为最后元素都不相同,那么只需替换即可)
4、上面的结果我们都没有考虑a[i]==b[j]的情况,所以我们最后还需判读if(a[i]==b[j])那么dp[i][j] = dp[i][j-1]即可。
综上所述,我们满足了所有的情况,所以递推成立;
最后我们只需写出代码即可,注意一定要初始化(┭┮﹏┭┮)
#include <iostream>
using namespace std;
#include <vector>
#include <cstring>
const int N = 2e3+10;
long long dp[N][N];
int main()
{
string a,b;cin>>a>>b;
a = ' '+a;
b = ' '+b;
memset(dp,0,sizeof(dp));
//初始化
for(int i=1;i<=a.length();i++) dp[i][0] = i;
for(int j=1;j<=b.length();j++) dp[0][j] = j;
for(int i=1;i<=a.length();i++){
for(int j=1;j<=b.length();j++){
if(a[i]==b[j]){
dp[i][j] = dp[i-1][j-1];
}else{
dp[i][j] = min(dp[i-1][j]+1,min(dp[i][j-1]+1,dp[i-1][j-1]+1));
}
}
}
cout << dp[a.length()][b.length()] << endl;
return 0;
}易错点:dp要注意对dp函数进行初始化,不然很容易出错......
6、Multiplication Puzzle
题意:给出一个序列1~n,每次取中间的值a[k],然后得分+a[k]*a[k-1]*a[k+1],k不能为1和n
也就是说最后只剩下1和n两个数。然后求最小的得分
思路:1、首先如果求最少得分或者个数之类的,就用动态规划。然后看子问题。
首先看最后一种情况,如果还剩三个数,那么答案很明显,就是+ a[1]*a[k]*a[n]
然后再看倒数第二种情况,还剩下四个数,那么答案就是从两个中选择得分最少的,
如果选择第2张牌,那么还剩下1,3,4 + a[2] * a[1] * a[3]
如果选择第3张牌,那么还剩下1,2,4 + a[3]*a[2]*a[4]
我们注意看a[2]*a[1]*a[3]是不是可以等价于从1~3三张牌里面选一张得分最少的
a[3]*a[2]*a[4] 等价于 从2~4三种牌里面选一张得分最少的。
所以我们定义状态方程 dp[i][j]代表i~j获得的最少分数,dp[1][n]就是答案
dp[i][j] 等价于 dp[i][k]+dp[k][j]+a[k]*a[1]*a[j]
解释:k是i~j中间的一个数,因为直到最后它才被删除,所以对于i~k来说 k不就相当于那个不能被选择的边界嘛? 对于k~j来说,k同理相当于不能被选择的边界。
综上所述,dp[i][j] = min(dp[i][j],dp[i][k]+dp[k][j]+a[k]*a[1]*a[j]);
然后大区间由小区间递推而来(i~j > i~k 或者 k~j) 所以我们只要知道i~k和k~j就知道i~j
然后小区间我们都知道dp[i][i+2] = a[i]*a[i+1]*a[i+2]
所以我们先遍历区间长度从2开始,到最大的长度,
然后再遍历起点j = 1,直到j+length <= n 。 dp[j][j+length]
代码如下:
#include <iostream>
using namespace std;
const int N = 1e3+10;
int a[N];
long long dp[N][N];
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++) cin>>a[i];
for(int i=0;i<=n;i++){//初始化
for(int j=0;j<=n;j++){
dp[i][j] = INT_MAX;
}
}
for(int i=1;i<=n-2;i++){//初始化
dp[i][i+2] = a[i]*a[i+1]*a[i+2];
}
for(int i=2;i<=n-1;i++){//长度 j=1
for(int j=1;j+i<=n;j++){//这个是起点
//左边是j ,右边是j+i
//k 从j+1 ~ j+i-1
for(int k=j+1;k<j+i;k++){
if(k-j>=2&&j+i-k>=2){//当区间长度<3的时候,我们定义的是无穷大,所以要单独判断
dp[j][j+i] = min(dp[j][k]+dp[k][j+i]+a[k]*a[j]*a[j+i],dp[j][j+i]);
}else if(k-j>=2){
dp[j][j+i] = min(dp[j][j+i],dp[j][k]+a[k]*a[j]*a[j+i]);
}else if(j+i-k>=2){
dp[j][j+i] = min(dp[j][j+i],dp[k][j+i]+a[k]*a[j]*a[j+i]);
}
}
}
}
cout << dp[1][n] << endl;
return 0;
}总结: 终于是一遍过的题啦~ 就是调试了好久,因为最小值,我们一开始必须初始化无穷大,然后如果j~k区间长度和k~j+i区间长度小于3的时候又要单独考虑,一开始没想到,调试了十几分钟。做完这道题,我感觉我动态规划明显变强了,哈哈哈哈哈哈!!!(大佬勿喷...我补药被骂)
7、[IOI1994]数字三角形 Number Triangles
题意:见链接,有点不好解释
思路:使得路径的和最大,可以把问题转化成,从顶点到底部的路径和最大,然后从这些路径和中再找到最大的。然后子问题,第n行第一个的路径和 等价于 第n-1行第一个路径和+a[n][1]。
这个有点特殊,都是某行第一个的和,看第n行的第二个 可以等价于 第n-1行第一个路径和+a[n][2]
或者 第n-1行第二个路径和 + a[n][2]。
所以我们可以得到状态转移方程 dp[i][j] = max(dp[i-1][j-1],dp[i-1][j])+a[i][j]
对于一些特殊的解,只要初始化全为0即可。
#include <iostream>
using namespace std;
const int N = 1001;
#include <cstring>
int a[N][N],dp[N][N];
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++){
for(int j=1;j<=i;j++){
scanf("%d",&a[i][j]);
}
}
memset(dp,0,sizeof(dp));
dp[1][1] = a[1][1];
for(int i=1;i<=n;i++){
for(int j=1;j<=i;j++){
dp[i][j] = max(dp[i-1][j-1],dp[i-1][j])+a[i][j];
}
}
int Max = -1;
for(int i=1;i<=n;i++){
Max = max(Max,dp[n][i]);
}
cout << Max << endl;
return 0;
}8、合唱队列
题意:给出一个序列长度为n,找出一个子序列,使得这个子序列前缀是严格递增,剩下的部分严格递减。然后求这个子序列的最大个数k,输出n-k 。 比如 ai < ai+1 < ai+2 <...<ak-i <..<ak-2 > ak-1 >ak
思路:又是求最大个数,当然是用动态规划,然后先看最后的状态:一个子序列,前面严格递增,剩下严格递减。那么我们假设是在k开始递减的,那么一个子序列就可以分为1~k的最长严格递增子序列长度 + k~n 的最长严格递减子序列。
一开始我的想法:是dp[i][j]代表i~j的最长递增子序列的长度和dp2[i][j]代表i~j的最长递减子序列的长度,然后dp[1][n] = max(dp[1][k]+dp2[k][n]),然后我突然想到求最大的递增子序列长度好像是dp[i]代表以i结尾的最长递增子序列,而且刚刚的求法中,dp[1][k]和dp2[k][n]并不能保证前者最大的数和后者最大的数不相等(因为是严格递增递减,不能相等)。
所以转变思路:dp[i]代表1~i以i结尾的最长递增子序列的长度,那如何求后缀的最长递减子序列呢?可以先将数组倒置,然后求它的最长递减子序列的长度以j结尾,然后再把这个dp2倒置。获得的dp3[i]就可以代表以i开头的,i~n的最长递减子序列的长度。
最后遍历i=1 ~ n
遍历j=i+1 ~ n
如果 a[i] != a[j] ,Max = max(Max,dp[i]+dp2[j])
然后输出n-Max即可!
#include <iostream>
using namespace std;
const int N = 1e2+10;
int a[N],b[N];
int dp1[N],dp2[N],dp3[N];
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
//dp求i~j的
for(int i=1;i<=n;i++){
dp1[i] = 1;
}
for(int i=1;i<=n;i++){
for(int k=1;k<i;k++){
if(a[i]>a[k]){
dp1[i] = max(dp1[i],dp1[k]+1);
}
}
}
//翻转a
for(int i=1;i<=n;i++)b[i] = a[n-i+1];
for(int i=1;i<=n;i++){
dp2[i] = 1;
}
for(int i=1;i<=n;i++){
for(int k=1;k<i;k++){
if(b[i]>b[k]){
dp2[i] = max(dp2[i],dp2[k]+1);
}
}
}
int Max = -1;
for(int i=1;i<=n;i++)dp3[i] = dp2[n-i+1];
for(int i=1;i<=n;i++){
for(int j=i+1;j<=n;j++){
if(a[i]!=a[j]){
Max = max(Max,dp1[i]+dp3[j]);
}
}
}
cout << n-Max << endl;
return 0;
}总结:因为这道题的范围很小,我没有考虑优化,如果要优化的话,求最长递增子序列的最优做法是可以优化到O(nlogn)的,但是我没有想到怎么把最后一步求Max优化到O(nlogn)的做法,如果有人知道可以在评论区跟我讨论一下,谢谢。
9、数字计数(数位DP)
题意:给定两个正整数 a 和 b,求在 [a,b] 中的所有整数中,每个数码(digit)各出现了多少次
思路:先想a~b的数码出现的次数可以转化为0~b - 0~a-1的数码出现的次数。
随机一个数123。
0~123的每个数码出现次数可以转化为 0~99 + 100~119 + 120~123
而0~9的每个数码出现次数是1
00~99的每个数码出现次数是 (0~9)*10 + 10 = 20
000~999的每个数码出现次数是(00~99)*10 + 100 = 300
0000~9999的每个数码出现次数是(000~999)*10+1000 = 4000
最后需要去掉前面的0
代码如下:
#include <iostream>
using namespace std;
#define ll long long
const int N = 15;
ll l,r,dp[N],mi[N];
ll ans1[N],ans2[N];
ll a[N];
void solve(ll n,ll ans[])
{
ll mid = n;
int len = 0;
while(n){
a[++len] = n%10;
n/=10;
}//4433 -> 3344
for(int i=len;i>=1;i--){
for(int j=0;j<10;j++) ans[j] += dp[i-1]*a[i];
for(int j=0;j<a[i];j++) ans[j] += mi[i-1];
mid -= mi[i-1]*a[i];
ans[a[i]] += mid + 1; //比如3000~3332 最前面的3在后面还出现了333次
ans[0] -= mi[i-1];
}
}
int main()
{
scanf("%lld%lld",&l,&r);
mi[0] = 1ll;
for(int i=1;i<=14;i++){
dp[i] = dp[i-1]*10 + mi[i-1];
mi[i] = 10*mi[i-1];
}
solve(r,ans1),solve(l-1,ans2);
for(int i=0;i<10;i++){
cout << ans1[i] - ans2[i] << " ";
}
return 0;
}
ST表
1、ST表模板
题意:给出一个序列,然后求q次,问最大值,一般来说求一个区间的最大值会用线段树O(logn)的操作,但是如果是静态的序列,用ST表查询只要(loglogn),所以最好用ST表查询
模板: //如果嫌log2()函数慢的话,可以自己写一个LOG[n]函数
void init()
{
for(int j=0;j<=log2(n);j++){
for(int i=1;i+(1<<j)<=n+1;i++){
if(!j) f[i][0] = a[i];
else f[i][j] = max(f[i][j-1],f[i+(1<<(j-1))][j-1]);
}
}
}
int query(int l,int r)
{
int s = log2(r-l+1);
return max(f[l][s],f[r-(1<<s)+1][s]);
}AC:
#include <iostream>
using namespace std;
const int N = 1e4+10;
int a[N],dp[N][26];
#include <cmath>
int n;
int max(int x,int y){
return x>y?x:y;
}
void init(){
for(int j=0;j<=log2(n);j++){
for(int i=1;i+(1<<j)<=n+1;i++){
if(!j) dp[i][0] = a[i];
else dp[i][j] = max(dp[i][j-1],dp[i+(1<<(j-1))][j-1]);
}
}
}
int query(int l,int r){
int s = log2(r-l+1);
return max(dp[l][s],dp[r-(1<<s)+1][s]);
}
int main()
{
int t;cin>>t;
while(t--){
cin>>n;
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
}
init();
int q;cin>>q;
while(q--){
int l,r;scanf("%d%d",&l,&r);
//查询l,r的最大值
cout << query(l,r)<<endl;
}
}
return 0;
}链式前向星
一般有3种存储图的方式
1、邻接表:一般用来存储稀疏图
2、邻接矩阵:用空间来换时间,访问效率很高,一般用来存储密集的图
3、链式前向星:是最节省空间的存储方式,就是代码稍微复杂了一点
一种高效存储图的方式,主要由head[]和edge[]组成。
head数组存储的是最后一个以u为起点的线段
edge数组存储的是线段

代码如下:
#include <iostream>
using namespace std;
const int N = 2e5+10,M=4e5+10;
int head[N];
struct{int to,w,next;}edge[M];
int cnt = 0;
void addedge(int u,int v,int w)
{
cnt++;
edge[cnt].to = v;
edge[cnt].w = w;
edge[cnt].next = head[u]; //指向上一个以u为起点的线段
head[u] = cnt; //以u为起点的最后的线段指向这个新的线段
}
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++){
int u,v,w;cin>>u>>v>>w;
addedge(u,v,w);
}
//遍历以1为起点的所有线段
for(int i=head[1];i>0;i=edge[i].next)
{
cout << 1 << " " << edge[i].to << " " << edge[i].w << endl;
}
//如果是遍历整个图,就是遍历所有起点即可。
//假如有m个点
for(int i=1;i<=m;i++){
for(int j=head[i];j>0;j=edge[j].next)
{
//...
}
}
return 0;
}A*算法
定义:是一种在图形平面上,对于有多个结点的路径求出最低通过成本的算法,它属于图遍历和最优优先搜索算法,也是BFS的改进。
过程:定义起点s,终点t,从起点开始的距离函数g(x),到终点的距离函数h(x),h*(x),以及每个点的估价函数f(x)=g(x)+h(x)
A*算法每次从优先队列中取出一个f最小的元素
然后开始更新相邻的状态。
如果h<=h*,则A*算法能找到最优解。
上述条件下,如果h满足三角形不等式,则A*算法不会将重复结点加入队列
当h=0时,A*算法变为Dijkstra;当h=0并且边权为1时变为BFS。
所以A*算法可以看作是Dijkstra+BFS
做题才能更好理解,建议先考虑下暴力如何去做,然后再看题解,考虑如何从A*的做法去求解第一道题,后面的题目可以思考完再做。
1、八数码
题目大意:在 ![]() 的棋盘上,摆有八个棋子,每个棋子上标有
的棋盘上,摆有八个棋子,每个棋子上标有 ![]() 至
至 ![]() 的某一数字。棋盘中留有一个空格,空格用
的某一数字。棋盘中留有一个空格,空格用 ![]() 来表示。空格周围的棋子可以移到空格中,这样原来的位置就会变成空格。给出一种初始布局和目标布局(为了使题目简单,设目标状态如下),找到一种从初始布局到目标布局最少步骤的移动方法。
来表示。空格周围的棋子可以移到空格中,这样原来的位置就会变成空格。给出一种初始布局和目标布局(为了使题目简单,设目标状态如下),找到一种从初始布局到目标布局最少步骤的移动方法。
123 123
804 - > 456
765 780
解题思路:首先找到h(x)函数:位置不在正确位置的个数。g(x)就是已经走过的步数,然后f(x)=h(x)+g(x)是我们的估价函数。我们想要初始布局到目标布局最小步骤的移动方法,显然需要f(x)最小。所以我们可以用BFS遍历节点,然后用优先队列,小根堆维护。
//下面代码初始矩阵是自定的,这道题是有初始值的,所以改成初始矩阵即可。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <queue>
#include <map>
using namespace std;
char ch;
int dx[4] ={0,0,1,-1},dy[4] = {1,-1,0,0};
struct matrix{
int a[5][5];
bool operator<(const matrix x) const{
for(int i=1;i<=3;i++){
for(int j=1;j<=3;j++){
if(a[i][j]!=x.a[i][j]) return a[i][j] > x.a[i][j];
}
}
return 0;
}
}f,st;
int h(matrix a)
{
int ans = 0;
for(int i=1;i<=3;i++){
for(int j=1;j<=3;j++){
if(a.a[i][j]!=f.a[i][j]) ans++;
}
}
return ans;
}
struct node{
matrix a;
int t;
bool operator<(const node x) const {//小根堆,且用 t+h(a)表示
return t+h(a)>x.t+h(x.a);
}
}x;
priority_queue<node> q;
map<matrix,bool> m;
int main()
{
//首先初始化开始的
for(int i=1;i<=3;i++){
for(int j=1;j<=3;j++){
scanf(" %c",&ch);
st.a[i][j] = ch - '0';
}
}
//然后定义目标矩阵
for(int i=1;i<=3;i++){
for(int j=1;j<=3;j++){
scanf(" %c",&ch);
f.a[i][j] = ch - '0';
}
}
q.push({st,0});
//对矩阵进行广搜,但是需要一个估价函数f[x] = g[x] + h[x] h[x]表示距离目标的距离,可以用矩阵里面有几个元素与目标不同来记录
while(!q.empty())
{
x = q.top();
q.pop();
if(!h(x.a)){//h(x)如果表示0就等于两个矩阵相等,这时候的t就是次数
cout << x.t << endl;
return 0;
}
int fx,fy;
for(int i=1;i<=3;i++){
for(int j=1;j<=3;j++){
if(x.a.a[i][j]==0) fx=i,fy=j;
}
}
for(int i=0;i<4;i++){
//可能的情况就是0与周围交换,所以先找到0的位置
int xx = fx + dx[i],yy = fy + dy[i];
if(xx>=1&&xx<=3&&yy>=1&&yy<=3){
swap(x.a.a[xx][yy],x.a.a[fx][fy]);//交换之后用一个set来记录这个节点是否被遍历过,也可以用map
if(!m[x.a]){
m[x.a] = true;
q.push({x.a,x.t+1});
}
swap(x.a.a[xx][yy],x.a.a[fx][fy]);//记得换回来
}
}
}
return 0;
}总结:首先学会了自创结构体要重载运算符以便于queue,set,map进行比较运算操作。然后进一步加强了重载运算符的使用。最后要注意广搜的时候,要注意值的修改。而且可以知道A*算法其实就是贪心+优先队列+BFS,每次往最靠近目标的结点走。用优先队列每次取出最小或最大的值。但如果一些图故意出一些往目标走的图在最远的距离,那时间复杂度就会退化成BFS。
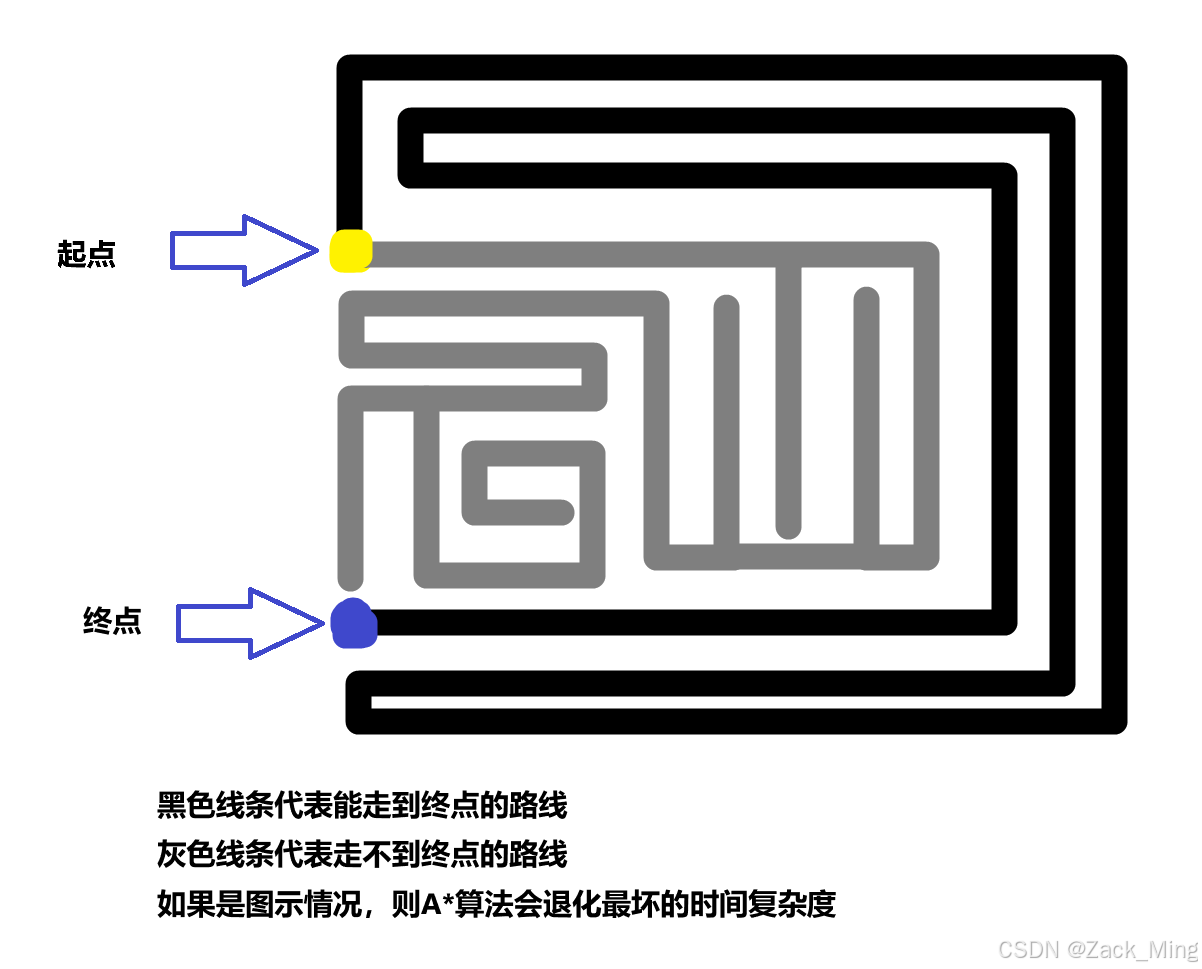
2、Remmarguts' Date
题意:求K短路径,可以用A*算法来计算,但是最好的做法还是“可持久化可并堆做法”(目前还不会)
思路:用A*算法求最短路的时候,h(x)表示当前点到终点的距离时间,然后用Floyd算法去求最短路径。理论上就是A*+Floyd = BFS+贪心+Floyd+优先队列
代码如下(可能有错,因为题目不允许提交了,不过样例是过了的,如果有问题可以在评论区跟我讨论(那不知道猴年马月了,毕竟我打算一年以后再发布qaq))
#include <iostream>
using namespace std;
const int N = 1e3+10;
#include <algorithm>
#include <cstring>
#include <queue>
int mp[N][N];
int path[N][N];
int n,m;
int s,t,k;
int vis[N];
void floyd()
{
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
path[i][j] = -1;
}
}
for(int v=1;v<=n;v++){
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
if(mp[i][j]>mp[i][v]+mp[v][j]){
mp[i][j] = mp[i][v] + mp[v][j];
path[i][j] = v;
}
}
}
}
}
int h(int x)//当前点到目标地的距离
{
return mp[x][s];
}
struct node{
int x;
int t;
bool operator<(const node a) const{
return t+h(x)>a.t+h(a.t);
}
};
priority_queue<node> q;
int main()
{
memset(vis,0,sizeof(vis));
cin>>n>>m;
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
if(i==j) mp[i][j] = 0;
else mp[i][j] = INT_MAX;
}
}
while(m--)
{
int u,v,t;cin>>u>>v>>t;
mp[u][v] = t;
}
cin>>t>>s>>k;
if(t==s) k++;
floyd();
q.push({t,0});
vis[t] = 1;
int ans = 0;
while(!q.empty())
{
node x = q.top();
q.pop();
if(x.x==s){
ans++;
if(ans==k){
cout << x.t << endl;
break;
}
}
//可能的情况
for(int j=1;j<=n;j++){ //mp[x.x][j]
if(j!=x.x&&vis[j]<=k&&mp[x.x][j]!=INT_MAX){
vis[j]++;
q.push({j,x.t+mp[x.x][j]});
}
}
}
return 0;
}最短路
首先明确一点,对于任意正边权的图,最短路不会经过重复的点与重复的边。
1、Floyd 算法
介绍:用来解决任意两点的最小路径问题,而Dijkstra算法是用来解决固定两点的最短距离。
讲解:MojitoCoco老师的讲解视频
然后我由此写了一个简单的求多源最短路径的算法巩固下学习。
#include <iostream>
using namespace std;
const int N = 1e3+10;
int path[N][N];
int mp[N][N];
int n;
int A[N][N];
int ans;
void floyd()
{
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
A[i][j] = mp[i][j];
path[i][j] = -1;
}
}
for(int v=0;v<n;v++){
for(int i=0;i<n;++i){
for(int j=0;j<n;++j){
if(A[i][j]>A[i][v]+A[v][j]){
A[i][j] = A[i][v] + A[v][j];
path[i][j] = v;
}
}
}
}
}
void print(int u,int v)
{
if(path[u][v]==-1){
cout << ans++ << ": " <<u << "->" <<v << "长度为:"<<A[u][v]<<endl;
}else{
int mid = path[u][v];
print(u,mid);
print(mid,v);
}
}
int main()
{
//首先初始化所有点之间的距离是无穷
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
if(i==j) mp[i][j] = 0;
else mp[i][j] = INT_MAX;
}
}
cin>>n;
int m;cin>>m;
while(m--){
int u,v,w;cin>>u>>v>>w;
mp[u][v] = w;
}
floyd();
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
//输出i~j的路径
if(i!=j&&A[i][j]!=INT_MAX){
ans = 1;
cout << "从" << i << "到" << j << "的路线是:" << endl;
print(i,j);
}
}
}
return 0;
}可以用我这丑陋的例子来说明应该是正确的


综上所述,Floyd算法是一个很好的求多源最短路径的算法,通过这个算法我们可以知道任意两个点之间的最短路径长度以及路径,就是算法复杂度比较高,也许地图APP可以利用这种算法,提前算好所有的点之间的最短路径,然后用O(n²)的空间复杂度来存储(如果全国划分了100个万个点,那我们需要100w*100w的int类型的空间,那好像几十个G了。虽然后续效率较高但是空间占比太大。所以对于一些小地方可以用这种方法来快速。不过一般与A*算法来说,这点时间几乎可以忽略不记。或者我们可以将这些数据放入服务器中,然后通过通讯将用户想要的结果传输回来?(胡言乱语)
后记:哈哈哈哈,其实A*算法就是包含了求多源最短路径的-。-因为需要用h(x)知道与目标的距离来贪心选择优先队列。(这就是为什么A*算法后面紧接着最短路的学习,因为A*算法第二题需要用到Floyd算法)
2、Bellman–Ford 算法
Bellman-Ford算法是一种基于松弛relax操作的最短路算法,可以求出(有负权的图的最短路),并可以对最短路不存在的情况进行判断,国内OI界大名鼎鼎的[SPFA]就是Bellman-Ford算法的一种实现(仰慕好久了)
可以先看这位老师的对于Bellmanford算法的图解视频,对于每一步你都尝试理解后,那五分钟你可能就能很了解这个算法的基础思想,后续再通过我写的代码一步一步理解,那几乎是完成了这个算法的学习。
过程:
对于边(u,v),松弛操作对应下面的式子:dis(v) = min(dis(v),dis(u)+w(u,v))。
尝试用S—u—v这条路径去更新v点最短路的长度,如果这条路径更优,就进行更新。。
Bellman-Ford算法所做的,就是不断尝试对图上每一条边进行松弛。我们每进行一轮循环,就对图上所有的边都尝试进行一次松弛操作,当一次循环中没有成功的松弛操作时,算法停止。
每次循环是O(m)的,那么最多会循环多少次呢?
在最短路存在的情况下,由于一次松弛操作会使得最短路的边数至少+1,而最短路的边数最多为n-1,因此整个算法最多执行n-1轮松弛操作。所以总时间复杂度为O(nm)
但还有一种请情况,如果从S点出发,抵达一个负环时,松弛操作会无休止地进行下去。注意到前面的论证中已经说明了,对于最短路存在的图,松弛操作最多只会执行n-1轮,因此如果第n轮循环时仍然存在能松弛的边,说明从S点出发,能够抵达一个负环。
代码如下:
#include <iostream>
using namespace std;
#include <vector>
const int MAXN = 1e3+10;
//首先建立了一个边(包含了u,v,w)
struct Edge{
int u,v,w;
};
//用动态数组存储边
vector<Edge> edge;
//初始化dis[MAXN]
int dis[MAXN],u,v,w;
const int INF = 0x3f3f3f3f;
bool bellmanford(int n,int s){
memset(dis,0x3f,(n+1)*sizeof(int));
//1、初始化起点
dis[s] = 0;
//2、判断是否一轮中发生了松弛操作,如果不发生中止
bool flag = false;
//3、循环n遍,如果循环到了第n遍说明有负环(因为理论上最多循环n-1遍)
for(int i=1;i<=n;i++){
flag = false; //1、判断每一轮有没有负环
//遍历每一条边
for(int j=0;j<edge.size();++j){
//1、获取每个边的信息
u = edge[j].u,v = edge[j].v,w = edge[j].w;
//2、如果到达u的时间等于INF,那就不用比较了,continue即可
if(dis[u]==INF) continue;
//3、如果不等于INF,判断从s-u-v 和s-v的操作进行比较
if(dis[v]>dis[u]+w){
dis[v] = dis[u] + w;
flag = true;
}
}
//3、如果不松弛退出循环即可
if(!flag) break;
}
//如果到了第n遍还在循环,那么返回值flag是true,那么我们可以通过flag == true得知有没有负环。。
return flag;
}
int main()
{
return 0;
}SPFA算法就是在此基础上加入了队列,其实每次循环之后会发生改变的点只与上一轮发生改变的点有关。所以我们每次遍历只需遍历上一轮发生改变的点即可。
代码如下:
#include <iostream>
using namespace std;
const int N = 1e4+10;
#include <vector>
#include <cstring>
#include <queue>
int dis[N],cnt[N],vis[N],pre[N];
struct edge{int v,w;};
vector<edge> e[N];
queue<int> q;
int n;
bool spfa(int s)
{
//1、首先初始化dis数组
memset(dis,0x3f,(n+1)*sizeof(int));
//2、s的三个初始化
dis[s]=0;vis[s]=0;q.push(s);
//3、广搜
while(!q.empty())
{
//1、取头,排空,重置vis[u]
int u = q.front();q.pop();vis[u] = 0;
//2、遍历以u结点为起点的所有线段
for(auto ed:e[u]){
int v=ed.v,w=ed.w;
//如果从s-u-v > s-v 那么更新这个线段的最小值,注意用pre数组记录前一个顶点
if(dis[v]>dis[u]+w){
dis[v] = dis[u]+w;
pre[v] = u; //记录pre前一个点的位置
cnt[v] = cnt[u]+1; //cnt数组就是用来防止出现负环的,如果cnt[v]=n,那就说明进入了死循环,需要跳出
if(cnt[v]>=n) return false;
if(!vis[v]) q.push(v),vis[v]=1; //
}
}
}
}
void print(int u) //打印最短的路径
{
if(u==1){printf("%d",u);return;}
//首先一直往深处搜索,到了u==1的时候输出即可,然后后面就会依次printf操作
print(pre[u]);
printf("%d",u);
}
int main()
{
return 0;
}3、Dijsktra算法
可以先通过一些简单的视频来了解Dijsktra,再来分析它的代码作用
由荷兰计算机科学家发现,是一种求解非负权图上单源最短路径的算法
过程
将结点分为两个集合:
1、已经确定最短路长度的点集合
2、未确定最短路长度的点集合
然后初始化dis[s]=0,其他点的dis均为INT_MAX
然后重复这些操作
1、从T集合中,选取一个最短路长度最小的结点,移到S集合中。
2、对那些刚刚被加入S集合的结点的所有出边执行松弛操作。
直到T集合为空。
1、初始化dis数组
2、遍历n遍(因为最多有n个点)
3、选取一个最短路长度最小且没被访问过的点作为出点u(贪心)
4、访问u的所有出边,并且对它进行松弛操作,如果s-u-v < s-v 那么就松弛成功。
#include <iostream>
using namespace std;
#include <vector>
#include <cstring>
const int N = 1e3+10;
int dis[N];
bool vis[N];
struct edge{
int w,v;
};
vector<edge> e[N];
void dijkstra(int n,int s)
{
//1、初始化dis数组
memset(dis,0x3f,sizeof(dis));
dis[s] = 0;
//2、遍历n次
for(int i=1;i<=n;i++){
//3、从没被选择过的集合中选取一个最短路径长度最小的点作为u
int u = 0,mid=0x3f3f3f3f;
for(int j=1;j<=n;j++){
if(!vis[j]&&dis[j]<mid) u=j,mid=dis[j];
}
vis[j]=true;
//4、访问u的所有出边,并且对其做松弛操作
for(auto ed:e[u]){
int v=ed.v,w=ed.w;
if(dis[v]>dis[u]+w){
dis[v] = dis[u] + w;
}
}
}
}我们可以发现这里维护最短路径长度的最小值可以用堆(优先队列)进行维护,所以可以把O(n²)优化到O(mlogm) 如果不是很密集的图是优化显著的(如果各个顶点之间有线,那m=n²,反而效率降低了)
综上所述,我们总结一下三种最短路算法可。
1)、Floyd算法 用 O(n³)的时间复杂度 求得了 多源最短路径(任意两点的最短路径)且可以检测负环。
2)、Bellman-ford算法 用O(nm)的求解了单源最短路径,也可以检测负环。如果用队列优化就是spfa算法,算法在有些时候效率不高(容易被卡)
3)、Dijkstra算法 用O(n²)的时间复杂度求得了 单源最短路径 但是不能检测负环,还可以用优先队列把时间复杂度优化为O(mlogm) 取决于图的稀疏程度来选取。
学完算法最重要的就是通过大量的练习:
1、Minimum Transport Cost
题意:有N个城市,每个城市之间有一条或没有路径,然后一条路径是有一定成本的。求从s到t城市的最小成本
思路:既然是最基础的题目,这道题我就用三种算法分别尝试求解一遍,加强理解。
可持久化线段树
有时候我们需要记录不同时间点(历史)的数据状态,此时需要创建它的多个历史副本。
由于连续的副本之间往往只有少数改动
那么只需要记录这部分改动即可
如果一个数据结构在连续的两个时间点之间对应的数据形态变化很少,且容易操作,那么它适合做持久化,常见的有可持久化线段树、可持久化Trie等
我们先用以下例题来理解一下可持久化线段树(前缀和思想、共用点、离散化、权值线段树)
1、给出数列a,求区间[L,R]求第k小,查询m次问题
暴力:取出区间[L,R],然后用O(nlogn)来排序找出第k小答案,输出,如果算上查询那么时间复杂度为O(mnlogn)
这个问题还可以用莫队算法解决。
以下是用利用可持久化线段树的步骤:
eg.一个数列{520,211,1314,985}
1、离散化:用另外一个数组b{211,520,985,1314}其中用二分查找a[i]然后减去begin就是离散化后的{1,2,3,4} ->
2、构建n个线段树[1,i]:然后每个线段树的节点代表线段有几个数据。n个线段树有2n个节点,也就是说需要2*n*n个节点,如果n=2e5+10,那么我们需要很大的空间,这显然是不可取的。我们可以利用持久化的特点:因为相邻线段树前后的差别很小,我们只需要记录不同点即可(动态存点)。这样我们只存储了根节点到叶节点一条路径(logn)那么存储n个线段树只需要(nlogn)空间
(不懂可以看代码)
如图
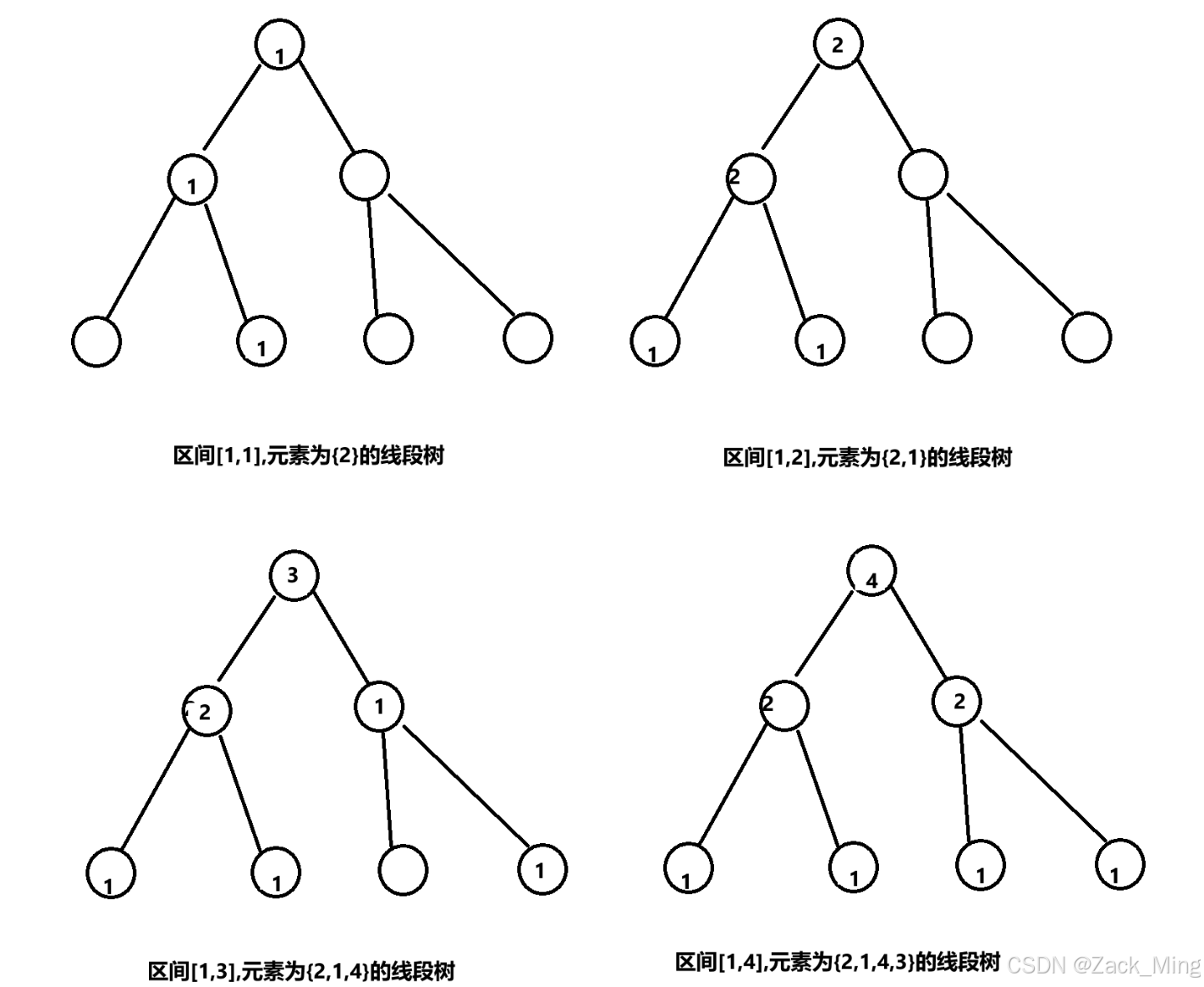
3、那么如何通过[1,i]查找 第k小问题呢?
举个例子,[1,3]查找第3小问题,根节点的左子树节点为2,说明第3小在根节点的右子树,那么只要在根节点的右子树中查找第3-2=1小问题即可,最后可以找到[4,4],返回4然后通过b[4] = 1314。
4、那么如何通过这些线段树查找[L,R]的第k小问题呢?
只需要用两颗线段树相减即可比如查找[2,4]的第2小问题,可以用[1,4]线段树减去[1,1]线段树,然后用上诉方法找到第k小问题即可。时间复杂度为O(n),如何优化呢?那就是只需要对查询的路径相减即可。这样时间复杂度优化到O(logn),比如之前需要把2n节点都复制然后相减,后者只需要对根节点到叶节点那一条路径进行相减即可。获得的结果是相同的
编程时这里有3个细节:
1、如何定位每颗树?利用root[i]数组用来记录动态的根节点分别为多少
2、初始化空树,我们无需初始化,因为所有的初始化都是0
3、原始序列有重复的元素如何解决,我们用unique函数去重然后用size表示不重复的数字,然后每个线段树的叶节点为size个,但是仍然有n个线段树。
以下是用代码实现了上诉代码,其中每个线段树都是动态开点,查询函数query可以看作在一颗树上完整做查询。
我们知道一颗线段树一般需要分配4n个节点(N<<2)但是我们有2e5+10个节点,那么nlogn就是20*N,那么用tree[N<<5]即可。
#include <iostream>
using namespace std;
#include <algorithm>
const int N = 2e5+10;
int cnt = 0; //用cnt标记可以使用的新结点,动态开点
int a[N],b[N],root[N]; //a,b表示原数组和离散后的数组,root[i]表示第i棵树的根结点编号
struct{
int L,R,sum;//sum为结点i的权值
}tree[N<<5]; //32倍的Nnlogn的空间 就是
int update(int pre,int pl,int pr,int x){//pre是前一颗树,然后当pl==pr==x的时候,加了一个1
int rt = ++cnt;//代表建立了多少棵树。 //新的节点,下面动态开点
tree[rt].L = tree[pre].L;
tree[rt].R = tree[pre].R;
tree[rt].sum = tree[pre].sum+1;
int mid = (pl+pr)>>1;
if(pl<pr){
if(x<=mid)
tree[rt].L = update(tree[pre].L,pl,mid,x);
else
tree[rt].R = update(tree[pre].R,mid+1,pr,x);
}
return rt;
}
int query(int u,int v,int pl,int pr,int k){//查询区间[u,v]中的第k小值
//本来是将第v棵树 - 第u棵树,但是这样O(n),所以,我们只需将要改的节点进行修改即可
if(pl==pr) return pl;//返回这个[i,i]就是第几个位置(相当于b数组的下标)
int x = tree[tree[v].L].sum - tree[tree[u].L].sum; //线段树相减
int mid = (pl+pr)>>1;
if(x>=k){//如果左子树的大小大于等于k,说明在左子树上
return query(tree[u].L,tree[v].L,pl,mid,k);
}else{
return query(tree[u].R,tree[v].R,mid+1,pr,k);
}
}
int main()
{
int n,m;cin>>n>>m;//长度为n,查询为m
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
b[i] = a[i];
}
sort(b+1,b+1+n);//对b排序
int size = unique(b+1,b+1+n) - b - 1;//不重复数字的个数
//build(),初始化一棵空树,实际上没必要
for(int i=1;i<=n;i++){
int x = lower_bound(b+1,b+1+size,a[i]) - b;
//x是原数组离散后的大小,比如{211,10,12414,1231,10} -> {10,10,211,1231,12414}那么211就在 b+3 - b = 3 {3,1,5,4,2}
root[i] = update(root[i-1],1,size,x);//建第i棵树,利用前一颗树,仅仅比前一颗树,叶节点多一个树,然后往上传,就是第i棵树。不同的地方
}
while(m--){
int x,y,k;cin>>x>>y>>k;
int t = query(root[x-1],root[y],1,size,k);//第k小在下标几呢?
printf("%d\n",b[t]);
}
return 0;
}总结:通过这个例子可以很好知道可持久化线段树是如何实现的,如果要深入理解可以通过输出倒输入来理解。
2、区间内小于或等于k的数字有多少个?
思路:对于区间问题可以用线段树,如果用暴力法来做就是取出这个区间然后从小到大排序,然后二分知道有多少个。持久化线段树方法:离散化,建树,查询最小k所在的位置pos(b下标)然后在区间[L,R]中找到小于这个叶子节点的个数。
就是把query函数修改为查询小于k所在的位置即可。
代码如下:
#include <iostream>
using namespace std;
const int N =1e5+10;
#include <algorithm>
int a[N],b[N],root[N];
struct{
int L,R,sum;
}tree[N<<5];
int cnt = 0;
int ans = 0;
int update(int pre,int pl,int pr,int x)
{
int rt = ++cnt;
tree[rt].L = tree[pre].L;
tree[rt].R = tree[pre].R;
tree[rt].sum = tree[pre].sum + 1;
int mid = (pl+pr)>>1;
if(pl<pr){
if(x<=mid){//如果x在mid左边,就查询左子树
tree[rt].L = update(tree[pre].L,pl,mid,x);
}else{
tree[rt].R = update(tree[pre].R,mid+1,pr,x);
}
}
return rt;
}
void query(int L,int R,int pl,int pr,int k){//最后返回的是那个位置的大
if(pl==pr){//加上b[pl]的数量,
ans += (tree[R].sum - tree[L].sum);
return;
}
int x = tree[tree[R].L].sum - tree[tree[L].L].sum;
int mid = (pl+pr)>>1;
if(k<=mid){//在左子树
query(tree[L].L,tree[R].L,pl,mid,k);
}else{//在右子树
ans += x;
query(tree[L].R,tree[R].R,mid+1,pr,k);
}
}
int main()
{
int t;cin>>t;
for(int j=1;j<=t;j++){
cout << "Case "<<j << ":\n";
int n,m;cin>>n>>m;//求区间中小于等于k的个数
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
b[i] = a[i];
}
sort(b+1,b+1+n);
int size = unique(b+1,b+1+n) - b - 1;
for(int i=1;i<=n;i++){
int x = lower_bound(b+1,b+1+size,a[i]) - b;
root[i] = update(root[i-1],1,size,x);
}
while(m--){
int u,v,k;cin>>u>>v>>k;
u++;
v++;
ans = 0;
int pos = upper_bound(b+1,b+1+size,k) - b - 1;//pos是刚好为
if(pos==0){
cout << 0 << endl;
continue;
}
query(root[u-1],root[v],1,size,pos);
cout << ans << '\n';
}
}
return 0;
}3、区间内有多少不同的数字 ?(倒序构建主席树)或者说第几个整数第一次出现的位置?
朴素做法就是取区间,排序,unique去重求size;
1、每个线段树的叶子节点有n个,第i个叶子节点表示第i个元素是否出现。
2、按照倒序建立线段树。
第n个元素A[n]建立第1个线段树
第n-1个元素A[n-1]建立第2个线段树
...
然后建立第i-1棵树的时候,A[i-1]出现过,那么将第map[A[i-1]](记录上一个的位置)个叶子节点设置为0,然后第i-1个叶子节点为1,且map[A[i-1]] = i-1;
那么第L棵树代表A[L]~A[n]内不同数字的情况。那我们只需要在这棵树上讨论[1,R]的区间和即可。
如果我们要求比如第2个整数第一次出现的位置,那么我们只需要找到第k小的pos(节点代表不同数,用之前做法就可以)
4、区间更新
分块
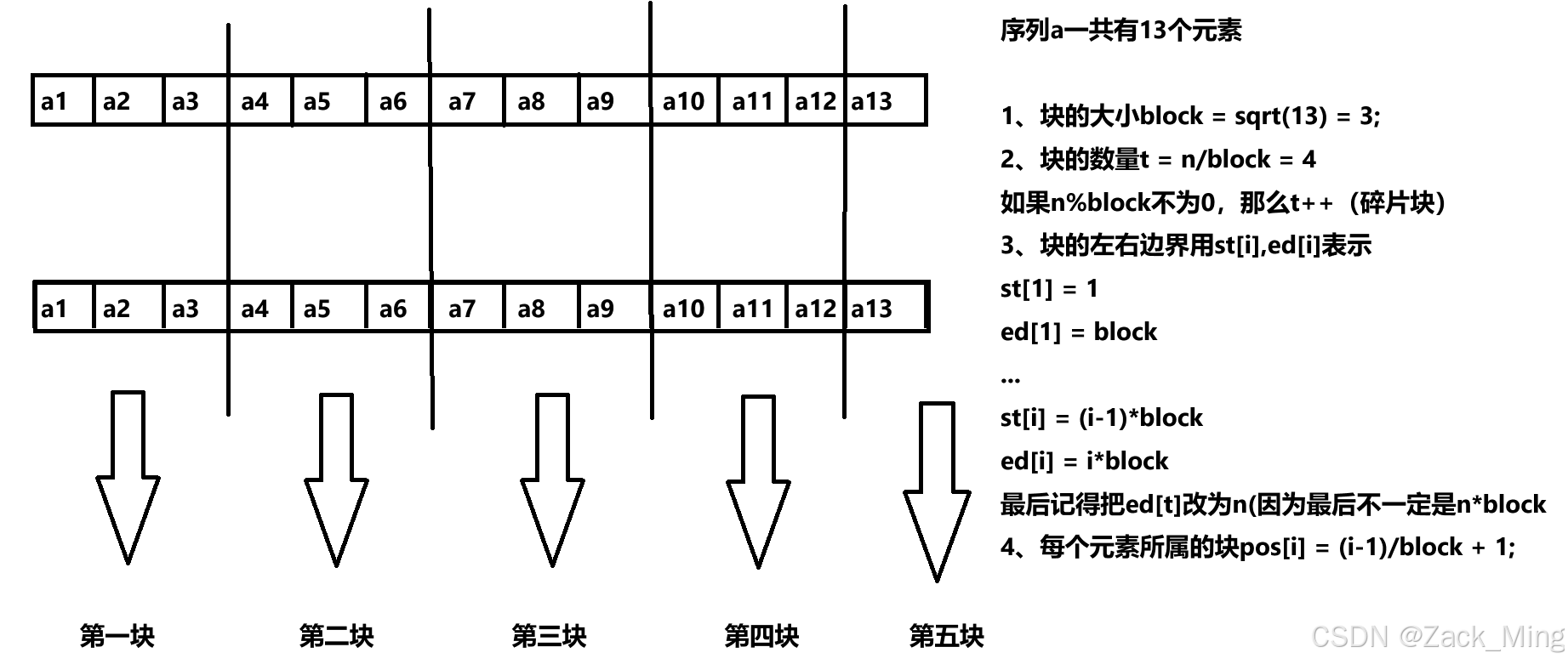
概括为:“整块打包维护,碎片个个枚举”
1、区间查询+区间修改
题意:给出一个序列a,长度为n,有m次查询,每次查询有两种情况:"W":选择区间[L,R]每个数+k,“A”:输出区间[L,R]中大于等于k的个数。
思路:对于求区间[L,R]大于等于k的标准解法是可持久化线段树
莫队算法
以HH项链(洛谷P1972)为例子学习莫队算法
题意:给定一个数列,查询数列某个区间内不同的数有多少个。
如果我们以暴力来计算:取出这个区间,然后遍历+cnt就可以以n的时间复杂度获取不同的数。但是如果要查询m遍,那时间复杂度就是m*n。[L,R]代表一个区间,L和R都可以以O(1)的方式进行移动。那么我们建立一个L-R的坐标轴,以点(L,R)代表解的答案,如果一开始从(0,0)出发。那么求解第一个答案的时间复杂度就是两点之间的曼哈顿距离。
以下我们画图来表达一下暴力法的几何解释:
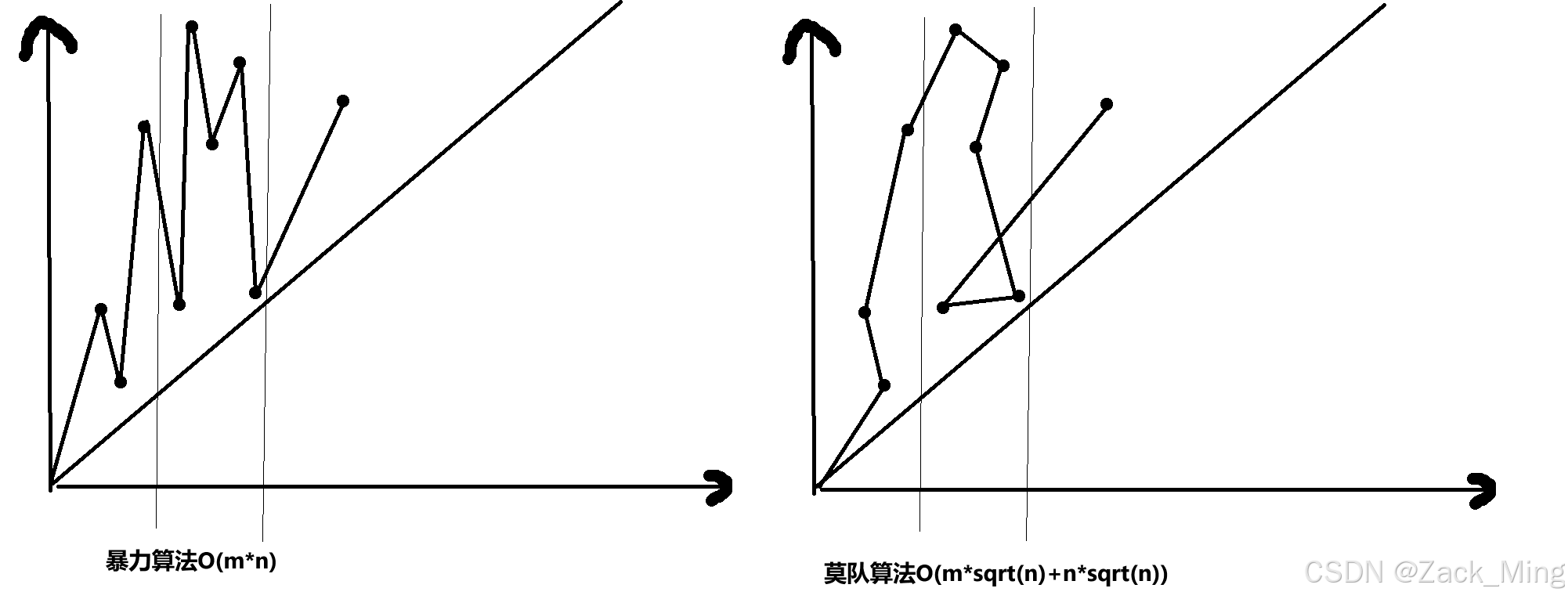
莫队算法就是对排序做了简单的修改。
其实就是求从一个点开始经过所有的点的最小距离,这是著名的旅行商问题,是NP难度的,没有多项式复杂度的解法,那么就可以用莫队算法进行贪心优化。
1、暴力法的排序:把查询的区间按左端点排序,如果左端点相同,再按右端点排序
2、莫队算法的排序:把数组分块,然后把查询的区间按左端点所在的块的序号排序
代码如下:
#include <iostream>
using namespace std;
#include <algorithm>
const int N = 1e6+10;
#include <cmath>
int a[N];
int pos[N];
int n,m,block;
int from[N];
int ls = 0;
int cnt[N];
struct node{
int L,R,k;
}q[N];
inline void read(int &x){
char ch=getchar();int f=1;x=0;
while(!isdigit(ch) && ch^'-') ch=getchar();
if(ch=='-') f=-1,ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
x*=f;
}
bool cmp(node &a,node &b){
//先分块,然后再根据
if(pos[a.L]!=pos[b.L]) return pos[a.L] < pos[b.L];
if(pos[a.L]&1) return a.R > b.R;
return a.R < b.R;
}
int query[N];
int main()
{
cin>>n;
block = sqrt(n);
for(int i=1;i<=n;i++){
read(a[i]);
if(!from[a[i]]) from[a[i]] = ++ls;//重编号
a[i] = from[a[i]];//重编号
pos[i] = (i-1)/block + 1;
}
int m;scanf("%d",&m);
//求[L,R]不同的个数,暴力法是通过移动L和R,然后获得答案
//将暴力区间从n变成sqrt(n),分块处理这些点,让
for(int i=1;i<=m;i++){
scanf("%d%d",&q[i].L,&q[i].R);
q[i].k = i;
}
//然后就是
sort(q+1,q+1+m,cmp);
int x = 1,y=0;
int ans = 0;
for(int i=1;i<=m;i++){//先移动L,再移动R
//对于问题i,先移动
while(q[i].L>x){//把x往右边移减少
//把q[i].L这个数减去
cnt[a[x]]-=1;
if(cnt[a[x]]==0) ans--;
x++;
}
while(q[i].L<x){//要x往左移,增加
x--;
cnt[a[x]]+=1;
if(cnt[a[x]]==1) ans++;
}
while(q[i].R>y){//把x往右移,增加
y++;
cnt[a[y]]+=1;
if(cnt[a[y]]==1) ans++;
}
while(q[i].R<y){//把x往左移,减少
cnt[a[y]]-=1;
if(cnt[a[y]]==0) ans--;
y--;
}
//ans记录现在的数
query[q[i].k] = ans;
}
for(int i=1;i<=m;i++){
printf("%d\n",query[i]);
}
return 0;
}值得注意的是这道题如果只用莫队算法会被毒瘤数据卡,通过大佬对颜色重编号的做法,能过完所有的数据点,值得学习!
应用:基础莫队算法只用于无修改只查询的区间问题,如果是比较简单的单点修改,也能应用莫队算法,得到时间复杂度为O(m*n的三分之2次方),也就是说n=1e5,且m=1e5的问题勉强能过.
1、带修改的莫队算法(简单的单点修改)
例题:有n个数,有两个操作,Q:查询L~R不同的数,R:把第P个数改成Col
思路:其实就是把原来的二维空间改为了三维空间用来表示[,R]以及时间t(修改了以后时间就会变)
2、树上莫队(将其他数据结构转化为一维数组而且是区间问题,那么也能应用莫队算法)
其中线段的曼哈顿距离就是时间复杂度,而暴力法很陡峭,显然不适合用来,而莫队算法的震荡幅度被限制在了区内,幅度为O(sqrt(n));
块状链表
结合了顺序表和链表的数据结构。
1、顺序表:增删O(n),移动光标O(1)
2、链表:增删O(1),移动光标O(n)
链表就是list<vector<int>> List;
主要是以下几个函数
1、查找和定位:list<vector<int>>::iterator Find(int &pos)通过pos查找是第几个链表,并且pos更新为在这块上第几个位置
2、分割一个块:Split(it x,int pos)把第x个块在它的pos位置分割为两个块
3、合并两个块:Merge(it x) 把第x和第x+1块合并
4、维护:Update() 遍历一下块状链表,如果每个长度不对,就维护,少了就合并,多了就分割。
5、插入:Insert(int pos,const vector<char> &ch>把一串vector插入到某个点后面
1、文本编辑器
代码如下:
#include <iostream>
using namespace std;
#include <list>
#include <vector>
typedef list<vector<char>>::iterator it;
list<vector<char>> List;
int block = 2500,len;
//1、Find
it Find(int &pos){
for(it i = List.begin();;i++){
if(i==List.end()||pos<=i->size()) return i;
pos -= i->size();
}
}
//2、Merge
it Next(it x){
return ++x;
}
void Merge(it x){//合并x和x+1
x->insert(x->end(),Next(x)->begin(),Next(x)->end());
List.erase(Next(x));
}
//3、Split : 分割第i块的第pos个
void Split(it x,int pos){
if(pos==x->size()) return;
List.insert(Next(x),vector<char>(x->begin()+pos,x->end()));
x->erase(x->begin()+pos,x->end());
}
//4、Update ; 更新每个块的大小为block
void Update(){
for(it i = List.begin();i!=List.end();i++){
while(i->size()>=(block<<1)){ //如果块大于两个block,分开
Split(i,i->size()-block);
}//所以每个块不是严格相等的,只不过最大不能超过2*sqrt(n)
while(Next(i)!=List.end()&&Next(i)->size()+i->size()<=block){
Merge(i);
}
while(Next(i)!=List.end()&&Next(i)->empty()){
List.erase(Next(i));
}
}
}
//5、Insert
void Insert(int pos,const vector<char> &ch)
{
it curr = Find(pos);
if(!List.empty()) Split(curr,pos); //把一个块拆成两个
List.insert(Next(curr),ch);
Update();
}
void Delete(int L,int R){
it L_block = Find(L);
Split(L_block,L);
it R_block = Find(R);
Split(R_block,R);
R_block++;
while(Next(L_block)!=R_block) List.erase(Next(L_block));
Update();
}
void Output(int L,int R){
it L_block = Find(L),R_block = Find(R);
for(it it1=L_block;;it1++){
int a,b;
//如果是起点,那么a=L,否则a=0
if(it1==L_block) a = L;
else a = 0;
if(it1==R_block) b = R;
else b = it1->size();
//如果是终点,那么b=R,否则b=it1->size()
//把a~b删除即可
for(int i=a;i<b;i++) putchar(it1->at(i));
if(it1==R_block) break;
}
putchar('\n');
}
int main()
{
int n;cin>>n;
int pos = 0;
while(n--){
char opt[10];cin>>opt;
if(opt[0]=='M'){
cin>>pos;
}else if(opt[0]=='I'){
cin>>len;
vector<char> ch;
ch.resize(len);
for(int i=0;i<len;i++){
ch[i] = getchar();
while(ch[i]<32||ch[i]>126) ch[i] = getchar();
}
Insert(pos,ch);
}
if(opt[0]=='D'){
cin>>len; Delete(pos,pos+len); //[pos,pos+len)
}
if(opt[0]=='G'){
cin>>len; Output(pos,pos+len);
}
if(opt[0]=='P'){
pos--;
}
if(opt[0]=='N'){
pos++;
}
}
return 0;
}简单树上问题
1、树的重心
随便找树中一个点,然后遍历一遍,注意不能返回父亲节点,然后只需要旁段各个子树中节点,然后一个子树的节点个数 = n-d[u]
例题如下:
#include <cstdio>
#include <iostream>
using namespace std;
const int N = 50005;
#include <algorithm>
int head[N];
struct{
int to,next;
}edge[N<<1];
int n;
int cnt = 1,d[N];
void addedge(int u,int v){
edge[cnt].to = v;
edge[cnt].next = head[u];
head[u] = cnt++;
}
int maxnum = 1e9,num = 0;
int ans[N];
void dfs(int u,int fa){
d[u] = 1;
int tmp = 0;
for(int i=head[u];i!=0;i=edge[i].next){
int v = edge[i].to;
if(v==fa) continue;
dfs(v,u);
d[u] += d[v];
tmp = max(tmp,d[v]);//找到其中最大的
}
tmp = max(tmp,n-d[u]); //找到最大的节点数
if(tmp < maxnum){
num = 0;
maxnum = tmp;
ans[++num] = u;
}else if(tmp==maxnum){
ans[++num] = u;
}
}
int main()
{
cin>>n;
for(int i=1;i<N;i++){
edge[i].next = 0;
head[i] = 0;
}
cnt = 1;
for(int i=1;i<n;i++){
int u,v;
scanf("%d%d",&u,&v);
addedge(u,v);addedge(v,u);
}
//从dfs(1,0)遍历
dfs(1,0);
sort(ans+1,ans+1+num);
for(int i=1;i<=num;i++){
cout << ans[i] << " ";
}
return 0;
}2、树的直径
1、做两次dfs或者bfs
先找到距离r节点最远的s节点
再找到距s节点最远的t节点。s~t就是最远的两个点
2、树形DP
LCA(最近公共祖先)
公共祖先,在一颗有根树上,若节点F是节点x的祖先,也是节点y的祖先,那么成 F是x和y的公共祖先。
最近公共祖先:在x和y的所有公共祖先中,深度最大的成为最近公共祖先。LCA(x,y)
推论:1、在x和y的所有公共祖先中,最近公共祖先离它们最近。
2、x、y之间的最短距离经过LCA(x,y)
3、x,y本身也可以是它们自己的公共祖先,比如LCA(x,y) = y代表y是x的父亲
那么如何求LCA呢?
分别从x和y出发,一直向根节点走,第1次相遇的节点就是LCA(x,y)。时间复杂度是O(n),查询m次就是O(nm)
1、倍增法:O(mlogn+nlogn)在线
①:先把x和y提到相同的深度。例如x比y深,就把x提到y的高度。如果发现y就是x的祖先,那么LCA(x,y) = y。
②:让x和y同步向上走,每走一步判断是否相遇,相遇点加上LCA(x,y)
那么如何优化呢?首先第一步,需要用
fa[x][0] = x的父亲
fa[x][1] = x的2*1祖先
fa[x][i] = x的2^i祖先
递推 fa[x][i] = fa[fa[x][i-1]][i-1]
用递推找到和y相同深度的节点
比如我们先确定每个f[u][0] = 0;
那么fa[u][1] = fa[fa[u][0][0];
fa[u][2] = fa[fa[u][1]][1];
...
第二步优化:
如果跳过头了 fa[x][i] = fa[y][i]
如果没有跳过头,x = fa[x][i],y = fa[y][i]。并且i = i-1;
循环即可,直到i==0;
fa[x][0]=fa[y][0]
那么fa[x][0]就是LCA
1、最近公共祖先(倍增法)
首先预处理是通过深度优先搜索,得出fa[x][i],deep[x]。时间复杂度为O(n)
然后就是倍增法(其实可以想象成二分)
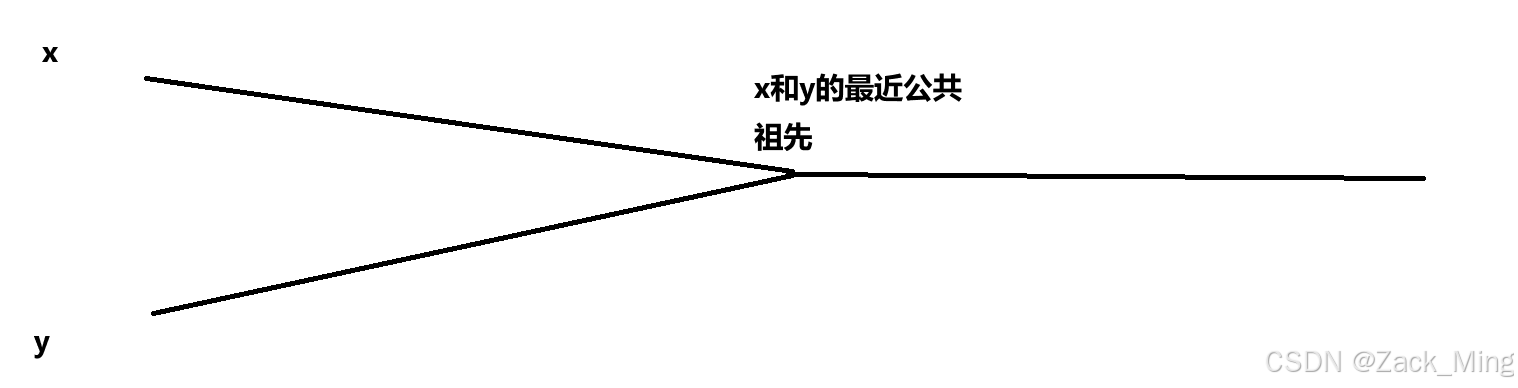
1、提层把x提层到y。其实就看x的2^i祖先如果小于等于y的层数,就让x=fa[x][i],最后x的层数一定是y的层数。最多计算logn次
2、如果x==y说明y是x的祖先,直接返回y即可
3、将x和y一起提层,如果fa[x][i] == fa[y][i]那不就说明两者的2^i祖先是相同的,那么可能是它,但是我们不要,我们一直往上提层,最后x和y一定会到最近公共祖先的前两个点,此时fa[x][0]==fa[y][0],且fa[x][0]就是它们的最近公共祖先!
代码如下:
#include <iostream>
using namespace std;
const int N = 5e5+10;
struct{
int to,next;
}edge[N*2];
int deep[N],cnt = 0,head[N],fa[N][20];
void addedge(int u,int v){
cnt++;
edge[cnt].to = v;
edge[cnt].next = head[u];
head[u] = cnt;
}
void dfs(int x,int father){
deep[x] = deep[father] + 1;
fa[x][0] = father;
for(int i=1;i<=19;i++){
fa[x][i] = fa[fa[x][i-1]][i-1];
}
for(int i=head[x];i!=0;i=edge[i].next){
if(edge[i].to!=father){
dfs(edge[i].to,x);
}
}
}
int LCA(int x,int y)
{
//1、提层
if(deep[x]<deep[y]) swap(x,y);
//把x往上提
for(int i=19;i>=0;i--){
if(deep[x]-(1<<i)>=deep[y])
x = fa[x][i];
}
if(x==y) return x;
//2、找最近公共祖先
for(int i=19;i>=0;i--){
if(fa[x][i]!=fa[y][i]){
x = fa[x][i],y = fa[y][i];
}
}
return fa[x][0];
}
int main()
{
int n,m,root;scanf("%d%d%d",&n,&m,&root);
for(int i=1;i<n;i++){
int u,v;scanf("%d%d",&u,&v);
addedge(u,v),addedge(v,u);
}
dfs(root,0);
while(m--){
int a,b;scanf("%d%d",&a,&b);
printf("%d\n",LCA(a,b));
}
return 0;
}2、最近公共祖先(tarjan算法)
首先介绍下tarjan他开发了一些重要的数据结构,比如斐波那契堆(Fibonacci Heap,插入查询合并O(1),删除O(logn)的强大数据结构)、伸展树(Splay Tree,和另外一位计算机科学家共同发明)、动态树(Link-Cut Tree,发明人之一)。
他独立研究的算法有:Tarjan离线的LCA算法(一种优秀的求最近公共祖先的线性离线算法)、Tarjan强连通分量算法(甚至比后来才发表的Kosaraju算法平均要快30%)、Hopcroft-Tarjan算法(第一个平面性测试的线性算法)。
作为一种离线算法,它先把所有查询进行某种排序之后再计算,在整体上能获得较好的效率。如何排序呢?把一个查询(x,y)看作一对节点,那么处理每一对(x,y)和(y,x)。
我们先思考下查询LCA最简单的思想就是从x和y节点出发,直到第一次相遇。
而DFS的后序遍历很适合这种情况,符合标记法的计算顺序。
我们记录每一对(x,y)和(y,x)那么只要我们走到一个节点x,我们只要看vis[y]是否==true。如果为真,我们只要一直找y的父亲直到fa[y] == y那么就是x和y的最近公共祖先(为什么呢?因为一开始每个节点的fa[i]=i,vis[y]==true,代表fa[y]就不是它本身,而是它的父亲,而x和y的最近公共祖先的fa[u]仍然等于它本身,因为还没有回到上层)
比如这张图,当我们后序遍历到y节点,此时vis[x]==true,那么我们只要一直找到x的父亲节点,直到fa[x]==x说明此时x==u(后序遍历:先遍历,再让fa[x的儿子]=x),这样此时fa[u]仍然等于u。
上面是第一种情况,如果y是x的祖先呢?

其实答案是一样的,这时候vis[x]==True,那么LCA(x,y)就是x的祖先的祖先...直到fa[x]==y,也就是说,两者合并即可。以下是上一题的tarjan代码:
#include <iostream>
#include <cstring>
using namespace std;
const int N = 5e5+10;
int fa[N],head[N],cnt,head_query[N],cnt_query,ans[N];
bool vis[N];
struct{
int to,next,num;
}edge[2*N],query[2*N];
void addedge(int u,int v){
edge[++cnt].to = v;
edge[cnt].next = head[u];
head[u] = cnt;
}
void add_query(int x,int y,int num){
query[++cnt_query].to = y;
query[cnt_query].num = num;
query[cnt_query].next = head_query[x];
head_query[x] = cnt_query++;
}
int find_set(int x){
return fa[x] == x?x:find_set(fa[x]);
}
void tarjan(int x){
vis[x] = true; //这个节点为vis[x]
for(int i=head[x];i;i=edge[i].next){
int y = edge[i].to;
if(!vis[y]){
tarjan(y);
fa[y] = x;
}
}
for(int i=head_query[x];i;i=query[i].next){//遍历所有以
int y = query[i].to;
if(vis[y])
ans[query[i].num] = find_set(y); //LCA就是find(y)
}
}
int main()
{
memset(vis,0,sizeof(vis));
int n,m,root;scanf("%d%d%d",&n,&m,&root);
for(int i=1;i<n;i++){
fa[i] = i; //并查集初始化
int u,v;scanf("%d%d",&u,&v);
addedge(u,v);addedge(v,u);
}
fa[n] = n;
for(int i=1;i<=m;++i){
int a,b;scanf("%d%d",&a,&b);
add_query(a,b,i);add_query(b,a,i);
}
tarjan(root);
for(int i=1;i<=m;++i){
printf("%d\n",ans[i]);
}
return 0;
}LCA的应用:
3、树上两点之间的最短距离
根据LCA的定义和推论:两点之间的最短距离一定经过两点的最短公共祖先.
dist(x,y) = deep(x)+deep(y) - 2*deep(LCA(x,y));
4、树上差分
如图,树上差分,其实就是以O(1)实现区间+1
如何让x~y的最短路径统统+1呢?
其实就是让D(x) + 1,D(y)+1,D(u)-1,D(fa[u])-1
其中u = LCA(x,y)
我们只需最后遍历一遍求出sum即可
代码如下:
#include <iostream>
using namespace std;
const int N = 50010;
struct {int to,next;}edge[2*N];
int head[N*2],D[N],deep[N],fa[N][32],ans,cnt;
void addedge(int u,int v){
edge[++cnt].to = v;
edge[cnt].next = head[u];
head[u] = cnt;
}
void dfs1(int x,int father){
deep[x] = deep[father] + 1;
fa[x][0] = father;
for(int i=1;(1<<i)<=deep[x];i++){ //如果2^i小于等于deep[x],就让fa[x][i] = fa[fa[x][i-1]][i-1];
fa[x][i] = fa[fa[x][i-1]][i-1];
}
for(int i=head[x];i!=0;i=edge[i].next){
if(edge[i].to!=father){
dfs1(edge[i].to,x);
}
}
}
int LCA(int x,int y){ //先提x,再同进
if(deep[x]<deep[y]) swap(x,y);
//这样deep[x]最大
for(int i=31;i>=0;i--){
if(deep[x]-(1<<i)>=deep[y]){//如果可以跳就跳,最后x一定是和y同层的
x = fa[x][i];
}
}
if(x==y) return x;
for(int i=31;i>=0;i--){
if(fa[x][i]!=fa[y][i]){
x = fa[x][i];
y = fa[y][i];
}
}
return fa[x][0];
}
void dfs2(int u,int father){//求树上差分
for(int i=head[u];i!=0;i=edge[i].next){
int v = edge[i].to;
if(v==father) continue;
dfs2(v,u);
D[u] += D[v]; //D[u]+=D[v]
}
ans = max(ans,D[u]);
}
int main()
{
cnt = 0;
int n,m;scanf("%d%d",&n,&m);
for(int i=1;i<n;i++){
int u,v;scanf("%d%d",&u,&v);
addedge(u,v);addedge(v,u);
}
dfs1(1,0); //计算每个节点的深度并预处理fa[][]数组
for(int i=1;i<=m;++i){
int a,b;scanf("%d%d",&a,&b);
int lca = LCA(a,b);//让a~b的路径都+1,那么
D[a]++,D[b]++;D[lca]--;D[fa[lca][0]]--;//树上差分
}
dfs2(1,0);
printf("%d\n",ans);
return 0;
}本题的树上修改比较简单,依次修改只涉及一条链路,如果有更复杂的修改,如一次修改整颗子树,需要用到树链剖分。
树上的分治
把分法思想应用到树上,分别处理点和边两种情况。
1、点分治:找到一个点v,把一棵树分为两棵或者更多子树,子树再继续分治,直到结束。为了提高分治的效率,应该让这些子树的节点数接近,也就是说,使得最大子树的节点数最少,根据树的重心的定义,这个点v实际上就是树的重心,所以点分治都是基于树的重心。
2、边分治:找到一条边,一棵树被分成两棵子树,尽量让这两棵子树的大小接近。
点分治是一种能高效统计树上路径信息的算法。树上的点分治有两种常见题型:一种基于静态树,只查询不修改;一种是带修改的查询,称为动态点分治或点分树。
1、查找树上节点路径是否存在路径为k(点分治)
思路:运用点分治的思想,找到一个点v,把一棵树分为两颗以上的子树,然后不断找重心再进行求解。
①、找重心(上面简单树上问题学到过),如果每次分治找到重心再分治就可以把复杂度从hn降到nlogn,其中h是树的高度,因为每一层都要做n次时间复杂度,那么最后时间复杂度就是hn,如果找重心每一次,那么高度最多只有logn,那么时间复杂度只要O(nlogn)
void getroot(int u,int fa){
int siz[u] = 1; //当前节点为1
int s = 0; //存储所有子树中节点最大的个数
for(int i=h[u];i;i=e[u].ne){
int v = e[u].v; //遍历该节点的所有相连的边
if(v==fa||del[v])continue; //除去所有删除的节点以及它的父亲
getroot(v,u); //dfs的后序遍历
siz[u] += siz[v]; //以当前节点为根的所有子树的个数
s = max(s,siz[v]); //获取所有子树中最大的子树的个数
}
s = max(s,sum-siz[u]); //还要加上如果该节点父亲也是子树的可能
if(s<mxs) mxs=s;root=u; //如果这个节点中最大的节点的个数最小,那么它就是重心
}②、求出子树中各个节点到根的距离,getdis();
void getdis(int u,int fa){
dis[++cnt] = d[u]; //dis数组记录了子树上所有到根节点的距离
for(int i=head[u];i;i=edge[i].next){ //链式前向星的遍历
int v = edge[i].v;
if(v==fa||del[v])continue;
d[v] = d[u] + edge[i].w; //每个子树到根节点的距离=父亲到根节点的距离+w
getdis(v,u);
}
}③、点分治divide(int u)
void divide(int u){//O(mnlogn)
//计算经过节点u的路径,并且查询有多少个答案O(mn)
calc(u);
//对u的子树进行分治O(logn)
for(int i=head[u];i;i=edge[i].next){
int v = edge[i].v;
if(del[v]) continue;
mxs = sum = siz[v]; //初始化mxs = sum = siz[v]为当前节点的个数
getroot(v,0); //找到该子树的重心
divide(root); //通过重心对该子树进行分治。
}
}④、calc(int u)统计经过u的路径
void calc(int u){//计算经过u的距离
del[u] = judge[0] = true;
int p = 0;
for(int i=head[u];i;i=edge[i].next){ //遍历根节点的子节点
int v = edge[i].v;
if(del[v])continue;
cnt = 0;
d[v] = edge[i].w; //记录该节点到u的距离
getdis(v,u); //获得以v为根节点的子树到u的距离
for(int k=1;k<=cnt;k++){ //然后通过judge判断是否有ans[j]的结果
for(int j=1;j<=m;j++){
if(ask[j]-dis[k]>=0) ans[j]|=judge[ask[j]-dis[k]];
}
}
//记录这个v子树出现的所有距离,方便下一个判断
for(int j=1;j<=cnt;j++){
if(dis[j]>=INF){
q[++p] = dis[j];//用了一个q数组记录了所有的judge的位置,这样删除不用重置judge
judge[dis[j]] = true;
}
}
}
//删除所有的judge,不能用memset,不然超时。
for(int i=0;i<=p;i++){
judge[q[i]] = 0;
}
}这里我再写一个图解方便理解:
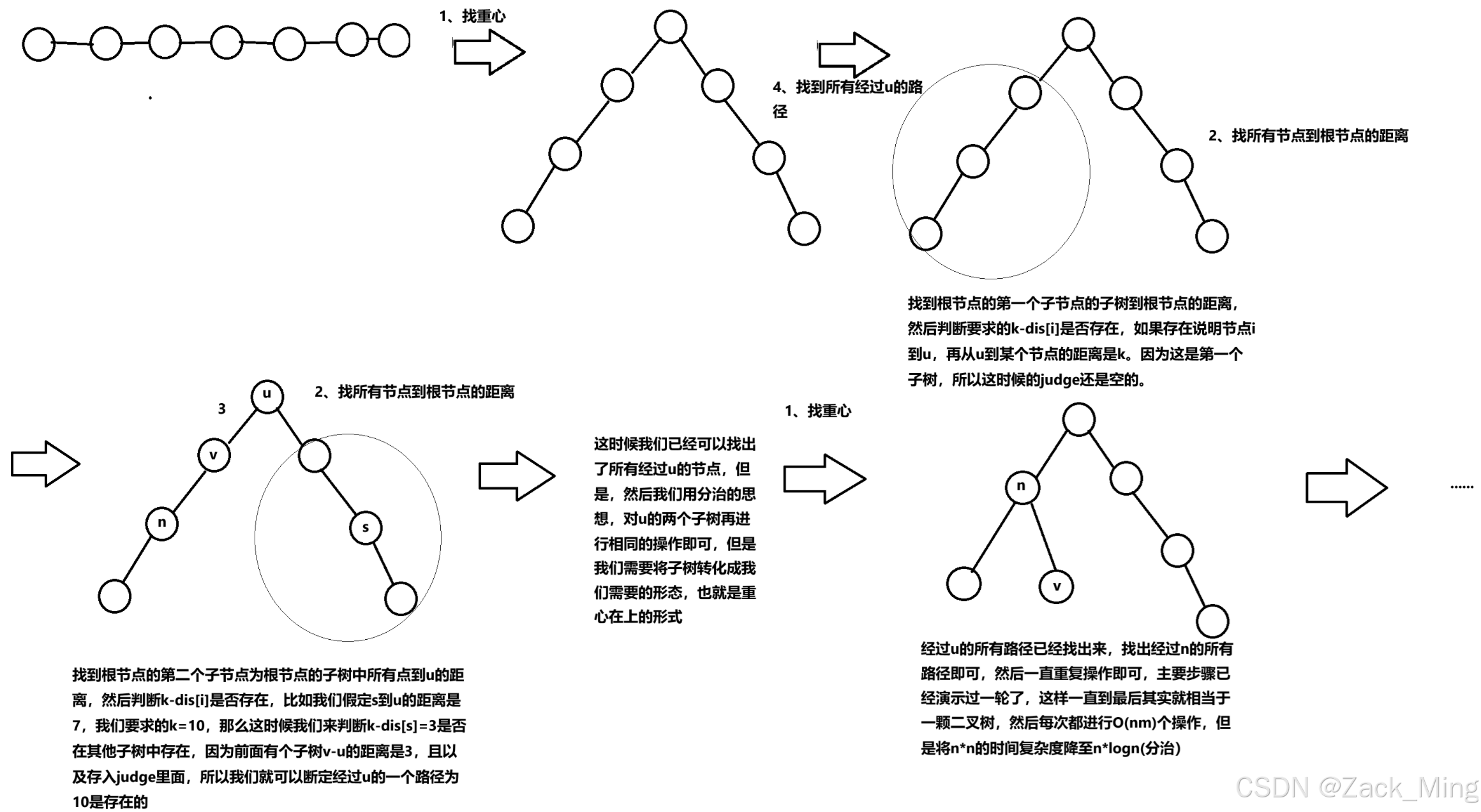
本题代码:
#include <iostream>
using namespace std;
const int N = 1e5+10;
const int INF = 1e7+10;
struct{
int v,w,next;
}edge[N*2];
int judge[10000010];
int n,m,cur,head[N],ask[N],del[N],siz[N],mxs,root,sum,cnt,d[N],dis[N];
int ans[N];
void add(int u,int v,int w){
edge[++cur].v = v;
edge[cur].w = w;
edge[cur].next = head[u];
head[u] = cur;
}
void getroot(int u,int fa)//获得根
{
siz[u] = 1;
int s = 0;
for(int i=head[u];i;i=edge[i].next){
int v = edge[i].v;
if(v==fa||del[v]) continue;
getroot(v,u);
siz[u] += siz[v];
s = max(s,siz[v]);
}
s = max(s,sum-siz[u]);
if(s<mxs) mxs=s,root=u;
}
void getdis(int u,int fa){
dis[++cnt] = d[u]; //dis是当前子树中到根节点的距离
for(int i=head[u];i;i=edge[i].next){ //遍历
int v= edge[i].v;
if(v==fa||del[v]) continue;
d[v] = d[u] + edge[i].w; //d[v] = d[u] + edge[i].w;
getdis(v,u);
}
}
int q[N];//差不多是一个队列,用来删除judge这个
void calc(int u){
del[u] = judge[0] = 1;
int p = 0; //队列q的大小
for(int i=head[u];i;i=edge[i].next){
int v = edge[i].v;
if(del[v])continue;
cnt = 0; //初始化dis的大小
d[v] = edge[i].w;
getdis(v,u); //统计该子树到u的距离,然后再遍历一遍dis,找出judge[ans[k]-dis[cnt]]是否存在
for(int k=1;k<=cnt;++k){
for(int j=1;j<=m;j++){
if(ask[j]>=dis[k]){
ans[j] |= judge[ask[j]-dis[k]];
}
}
}
//然后把这个子树到u的距离存进去
for(int j=1;j<=cnt;++j){
if(dis[j]<INF){ //如果小于1e7,就存入吧
q[++p] = dis[j];
judge[dis[j]] = true;
}
}
}
//最后清理一下这个judge即可,肯定不能用memset,不然时间复杂度太大了
for(int i=1;i<=p;i++) judge[q[i]] = 0;
}
void divide(int u){//O(mnlogn)
//计算经过节点u的路径,并且查询有多少个答案O(mn)
calc(u);
//对u的子树进行分治O(logn)
for(int i=head[u];i;i=edge[i].next){
int v = edge[i].v;
if(del[v]) continue;
mxs = sum = siz[v]; //初始化mxs = sum = siz[v]为当前节点的个数
getroot(v,0); //找到该子树的重心
divide(root); //通过重心对该子树进行分治。
}
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<n;i++){
int u,v,w;scanf("%d%d%d",&u,&v,&w);
add(u,v,w);add(v,u,w);
}
for(int i=1;i<=m;i++){
scanf("%d",&ask[i]);
}
mxs = sum = n;
getroot(1,0);
divide(root);
for(int i=1;i<=m;++i){
if(ans[i]==1){
cout << "AYE\n";
}else{
cout << "NAY\n";
}
}
return 0;
}2、查找树上节点路径小于等于k的个数(点分治)
思路:可以把树上问题转化为区间问题,比如遍历一遍子树,获得一个dis数组,对数组进行排序,然后用双指针找到ai+aj<=k的个数,不过要注意需要减去子树的。
#include <iostream>
#include <algorithm>
#include <cstdio>
using namespace std;
const int N = 1e5+10;
int head[N],del[N];
struct{
int v,w,next;
}ed[N*4];
int n,k,cur=0;
int root,siz[N],sum,mxs;
void add(int u,int v,int w){
ed[++cur].v = v;
ed[cur].w = w;
ed[cur].next = head[u];
head[u] = cur;
}
void getroot(int u,int fa){
siz[u] = 1;
int s = 0;
for(int i=head[u];i!=0;i=ed[i].next){
int v = ed[i].v;
if(v==fa||del[v])continue;
getroot(v,u);
siz[u] += siz[v];
s = max(s,siz[v]);
}
s = max(s,sum-siz[u]);
if(s<mxs) mxs=s,root=u;
}
int deep[N],d[N];
int cnt;
void getdis(int u,int fa){
deep[++cnt] = d[u];
for(int i=head[u];i!=0;i=ed[i].next){
int v = ed[i].v;
if(v==fa||del[v])continue;
d[v] = d[u] + ed[i].w;
getdis(v,u);
}
}
int ans = 0;
int q;
int calc(int u,int w){
d[u] = w;q=0;
cnt = 0;
getdis(u,u);
sort(deep+1,deep+1+cnt);
int l = 1,r = cnt;
int ls = 0;
while(l<r){
if(deep[l]+deep[r]<=k){
ls += (r-l);
l++;
}else{
r--;
}
}
return ls;
}
void dfz(int u){
del[u] = 1;
ans += calc(u,0);
for(int i=head[u];i!=0;i=ed[i].next){
int v = ed[i].v;
if(del[v])continue;
ans -= calc(v,ed[i].w);
mxs=sum=siz[v];
getroot(v,u);
dfz(root);
}
}
int main()
{
scanf("%d%d",&n,&k);
while(n!=0||k!=0){
ans = 0;
for(int i=0;i<=n;i++){
del[i] = 0;
head[i] = 0;
}
for(int i=1;i<n;i++){
int u,v,w;
scanf("%d%d%d",&u,&v,&w);
add(u,v,w);add(v,u,w);
}
mxs=sum=n;
getroot(1,1);
dfz(root);
cout << ans << '\n';
scanf("%d%d",&n,&k);
}
return 0;
}树链剖分
重链剖分:特征是把最大的儿子称为重儿子,把树分为若干长链。重链剖分的应用很多。
重链剖分是提高树上搜索效率的一个巧妙方法。它按一定规则把树剖分成一条条线性的不相交的链,对整棵树的操作就转换为对链的操作。而从根到任何一条链只需经过O(log2n)条链,从而时间复杂度为O(log2n)
重链剖分的一个特别之处是每条链的DFS序是有序的,可以使用线段树处理,从而高效地解决一些树上的修改和查询问题。
进行树链剖分LCA是必须的步骤,所以我们先从LCA开始
求LCA的各种算法都是快速向上跳到祖先节点。回顾求LCA的两种方法,其思想可以概括为:1、倍增法、用二进制递增直接向祖先跳;2、Tarjan算法:用并查集合并子树,子树内的节点都指向子树的根,查询LCA时,可以从节点直接跳到它所在的子树的根,从而快速跳的目的。
树链剖分也是“跳”到祖先节点,它的跳法比较巧妙。
它把树剖为从根到叶子的一条跳链路,链路之间不相交;每条链上的任意两个响铃节点都是父子关系;
链路上的节点查询LCA时,都指向链头,从而实现快速跳的目的。特别关键的是:
从根到叶子只需要经过O(log2n)条链,
那么从一个节点跳到它的LCA,只需要O(log2n)条链。
1、重儿子:对一个非叶子节点,它最大的儿子是重儿子,所谓”最大“,是指以这个儿子为根的子树上的节点数量最多(包括这个儿子)。例如,a的重儿子是b,因为以b为根的子树有8个节点,比另一个儿子c大,以c为根的子树只有3个节点。又如,e的重儿子是j。
2、轻儿子:除了重儿子以外的儿子。
3、重边:连接两个重儿子的边。
4、重链:连续的重边形成的链
5、轻边:除了重边意外的边
6、链头:一条重链上深度最小的点
利用上面定义好的链,最关键的一个性质是从任意点出发,到根节点的路径上经过的重链不会超过log2n条,由于每两条之间有一个轻边,经过的轻边不会超过log2n条。
如何用这些链条获取LCA呢?我们以p,q为例子。求LCA(p,q)。
先从p开始条,跳到链头top[p]=d;
然后通过轻边进入b,此时top[b]=top[q]=a;
说明b和q在同一条链上面;
如果b的深度比q浅,那么LCA(p,q) = b;
注意不能从q开始跳。
1、用熟练剖分求LCA代码O(mlogn)
用树链剖分求LCA的代码,主要是三个函数
①:dfs1(),求以下数组:
deep[]
fa[]
siz[]
son[]
②:dfs2(),计算top(),top[x]为节点x所在的重链的链头。
③:LCA()
dfs1(int u,int fa)
void dfs1(int u,int fa){
deep[u] = deep[fa] + 1; //树的深度
fa[u] = fa; //父亲
siz[u] = 1; //子树大小用来找重心、重儿子
for(int i=head[u];i;i=edge[i].next){ //遍历子树
int v = edge[i].v;
if(v==fa)continue;
dfs1(v,u);
siz[u] += siz[v];
if(!son[u]||siz[son[u]]<siz[v]) son[u] = v;//找出u的重儿子
}
}dfs2(int u,int topu)
void dfs2(int u,int topu)
{//找出
id[x] = ++num; //重链的一个重要特性:一条重链上的点序是连续的。
top[u] = topu;
if(!son[u])return; //如果没有重儿子,直接返回
dfs2(son[u],topu);
//能到这一步说明有儿子,那就以这些轻儿子重新构起一条重链。
for(int i=head[u];i;i=edge[i].next){
int v = edge[i].v;
if(v==fa[u]||v==son[u])continue;//排除u的父亲和u的重儿子就是u的轻儿子
dfs2(v,v); //这些轻儿子当然以自己为链头
}LCA(int a,int b)
int LCA(int a,int b)
{ //求a,b的LCA,先循环找到同一条链
while(top[a]!=top[b]){ //让深度大的往上搜
if(deep[top[a]<deep[top[b]) swap(a,b);
a = fa[top[a]]; //a的深度更大
}
return deep[a]<deep[b]?a:b; //返回深度更小的点
}有关重链还有一个重要特征:一条重链内部节点的DFS序是连续的。也就是说一个重链的节点是一段连续的数字,可以看作是线段,线段内的区间问题用线段树处理正合适。
可以解决以下问题:
1、修改点x到点y的路径上各点的权值。
2、查询x到y的路径上节点权值之和.
替罪羊树
优雅的暴力维护平衡树
建议看看B站大佬做的图解视频,短短两分钟就可以很好的理解替罪羊树的原理,再来看注释就很简单
采用一种简单且直接的方法来维护二叉树的平衡:如果检测到某个子树失去平衡,就将其摧毁,并以中间元素为根,重建一个平衡的子树。
将摧毁子树形象地描述为“拍扁”,而用中间元素重建平衡树则形容为“重新托起”。
替罪羊树的计算复杂度和保持二叉树平衡的效率取决于设定的不平衡率alpha。
如果每次添加或删除节点都进行摧毁重建,代价显然过大。我们的目标是维护一棵大致平衡的二叉树。
若alpha=0.5,意味着树是完全平衡的。如果n=1000,那么重建的次数将是n²,这是我们无法承受的。
若alpha=1.0,则树完全不平衡,如果n=1000,树的深度将达到1000,这同样无法接受。
因此,设置alpha为0.7或者0.75是一个较好的选择。
替罪羊树的操作:
1、插入和重建:
void Insert(int &u,int x)实现插入和重建功能。
插入按BST的规律,把元素xcherubic以u为根的子树的一个空节点上;然后用notbalance()判断是否平衡,
如果不平衡就用rebuild()函数重建。
2、删除和重建:
利用标记法del[v]代表这个节点已被删除,并且将它所在的子树大小-1;
如果一棵子树上标记被删除的节点太多就不平衡了,就重构它,重构,先回收那些被删除的节点,然后对没被删除的元素进行“拍平和重建”。
Treap树
名字的由来:Tree + Heap堆
为何?
因为每个节点包含了Key值和HeapKey值,利用HeapKey值能够构建比较平衡的二叉树。
直接看洛谷P3369代码
#include <iostream>
#include <ctime>
#include <cstdlib>
using namespace std;
//1、动态节点
struct Node{
Node *ls= 0,*rs = 0;
int pri= 0,key= 0;
int size= 0;
int sum= 0;
};
//2、创建新节点
Node* newNode(int x){
Node *p = new Node;
p->key = x;
p->size = 1;
p->sum = 1;
p->ls = p->rs = 0;
p->pri = rand(); //关键点,堆值的是随机赋予的。
return p;
}
//3、更新u的size值,可以理解为线段树的push_up
void Update(Node *u){
int lsize = 0,rsize = 0;
if(u->ls!=0) lsize = u->ls->size;
if(u->rs!=0) rsize = u->rs->size;
u->size = lsize + rsize + u->sum;
}
//4、d==0是右旋转,d==1是左旋转
void rotate(Node *&u,int d){//0右旋,1左旋
Node *k;
if(d==0){//右旋
k = u->ls;
u->ls = k->rs;
k->rs = u;
}else{//左旋
k = u->rs;
u->rs = k->ls;
k->ls = u;
}
//k指向
k->size = u->size;
Update(u);
u = k;
}
//5、插入操作
void Insert(Node *&u,int x){//插入x
if(u==0) {u = newNode(x);return;}
u->size++;
if(x==u->key){
u->sum++;
}else if(x>u->key){//在左子树上
Insert(u->rs,x);
}else{
Insert(u->ls,x);
}
//旋转维护平衡
if(u->ls!=0&&u->pri > u->ls->pri) rotate(u,0);//右旋
if(u->rs!=0&&u->pri > u->rs->pri) rotate(u,1);
Update(u);
}
//6、删除操作
void Del(Node *&u,int x){//删除元素x
u->size--;
if(u->key<x){
Del(u->rs,x);
Update(u);
}else if(u->key>x){
Del(u->ls,x);
Update(u);
}else{
if(u->sum>1){
u->sum--;
return;
}
if(u->ls==0&&u->rs==0){u=0;return;}
if(u->ls==0){u=u->rs;return;}
if(u->rs==0){u=u->ls;return;}
if(u->ls->pri < u->rs->pri){
rotate(u,0); Del(u->rs,x);return;
}else{
rotate(u,1); Del(u->ls,x);return;
}
}
Update(u);
}
//返回小于x的数即可
int Rank(Node *u,int x)
{
int lsize = 0,rsize = 0;
if(u==0)return 0;
if(u->ls!=0) lsize = u->ls->size;
if(u->key==x) return lsize;
if(u->key>x) return Rank(u->ls,x);
if(u->key<x) return Rank(u->rs,x) + u->sum + lsize;
}
int kth(Node *u,int x)//返回排名是x的数
{
int lssize = 0,rssize = 0,usize = 0;
if(u!=0) usize = u->sum;
if(u->ls!=0) lssize = u->ls->size;
if(u->rs!=0) rssize = u->rs->size;
if(x>lssize&&x<=lssize+usize) return u->key;
if(x<=lssize&&u->ls!=0) return kth(u->ls,x);
if(x>lssize+usize&&u->rs!=0) return kth(u->rs,x-lssize-usize);
}
int Precursor(Node *u,int x){//返回x的前继
if(u==0) return 0;
if(u->key>=x) return Precursor(u->ls,x);
int tmp = Precursor(u->rs,x);
if(tmp==0) return u->key;
return tmp;
}
int Successor(Node *u,int x){//返回x的前继
if(u==0) return 0;
if(u->key<=x) return Successor(u->rs,x);
int tmp = Successor(u->ls,x);
if(tmp==0) return u->key;
return tmp;
}
int main()
{
srand(time(NULL));
Node* root = nullptr;
int n;cin>>n;
while(n--){
int opt,x;
scanf("%d%d",&opt,&x);
switch (opt)
{
case 1:Insert(root,x); break;
case 2:Del(root,x); break;
case 3:printf("%d\n",Rank(root,x)+1); break;
case 4:printf("%d\n",kth(root,x));break;
case 5:printf("%d\n",Precursor(root,x));break;
case 6:printf("%d\n",Successor(root,x));break;
}
}
return 0;
}FHQ Treap树
非旋转Treap,巧妙的利用了Split把一个树分成了<=x和>x的两棵树,然后进行操作,最后再进行合并。Merge
FHQ的Split分别有权值分裂以及排名分裂。
第一题文艺平衡树用的就是排名分裂
1、文艺平衡树
题意:一个n长度的序列,每个元素为它的下标+1,经过m次旋转区间[L,R],求最后序列为多少。
思路:用FHQ Treap以及线段树的lazy标签。这里需要证明的一个事情是,一个序列可以通过递归吗,,最后变成旋转的。比如旋转区间[2,3,4,5,6]。可以随便取一个点为轴。旋转两侧。
比如选取4为轴
[{5,6},{4},{2,3}]
然后左右两侧选取第一个元素为轴
[{6,5},4,{3,2}]这个答案就是[2,3,4,5,6]旋转后的情况。可以用树来表示就是交换左右子树的位置。
代码如下:
#include <iostream>
#include <ctime>
#include <algorithm>
using namespace std;
const int N = 1e5+10;
struct Node{
Node *ls,*rs;
int pri,num;
int size,lazy;
};
Node* newNode(int x){
Node *p = new Node;
p->ls = nullptr;
p->rs = nullptr;
p->lazy = 0;
p->num = x;
p->size = 1;
p->pri = rand();
return p;
}
void swap(Node *&L,Node *&R)//交换L和R的指针
{
Node* temp = L;
L = R;
R = temp;
}
void pushdown(Node* p){//翻转操作,对任何一个东西的左右交换,然后再分..
if(p==nullptr) return;
if(p->lazy){//还要保证左子树和右子树是存在的!
swap(p->ls,p->rs); //翻转u的左右部分
if(p->ls!=nullptr){
p->ls->lazy ^= 1;
}
if(p->rs!=nullptr){
p->rs->lazy ^= 1;
}
p->lazy = 0;
}
}
void Update(Node *p){
int lsize = 0,rsize = 0;
if(p->ls!=nullptr) lsize = p->ls->size;
if(p->rs!=nullptr) rsize = p->rs->size;
p->size = 1 + lsize + rsize;
}
Node* Merge(Node* L,Node* R)//返回根节点(左子树必须全小于右子树)
{
if(L==nullptr&&R==nullptr){return nullptr;}
if(L==nullptr){return R;}
if(R==nullptr){return L;}
if(L->pri > R->pri){//如果左子树的优先度更大,就让L子树的根做根
pushdown(L);//记得对L做去lazy操作
L->rs = Merge(L->rs,R);
Update(L);//记得更新L的size
return L;
}else{//右子树优先度更大,就让R子树的根做根,并且
pushdown(R);
R->ls = Merge(L,R->ls);
Update(R);
return R;
}
}
void Split(Node *p,int k,Node *&L,Node *&R){
//将p所指的树划分为前者为k的树的两棵树
if(p==nullptr){ R = L = nullptr;return;}
pushdown(p);
//如果p的左子树的大小+1 <= k 那么直接找
int lsize=0,rsize=0;
if(p->rs!=nullptr) rsize = p->rs->size;
if(p->ls!=nullptr) lsize = p->ls->size;
if(lsize + 1 <= k ){//如果没有左子树?
L = p;//那么此时p就是上一层的根,并且继续划分右子树中的
Split(p->rs,k-lsize-1,p->rs,R);
}else{
R = p;
Split(p->ls,k,L,p->ls);
}
Update(p);
}
void solve(Node* p)//中序遍历即可
{
if(p == nullptr) return;
pushdown(p);
if(p->ls!=0)solve(p->ls);
cout << p->num << " ";
if(p->rs!=0)solve(p->rs);
}
int main()
{
Node *root = nullptr;
int n,m;cin>>n>>m;
for(int i=1;i<=n;i++){
Node* p = newNode(i);
//将p所指的树与root所指的树合并
root = Merge(root,p);
}
while(m--){
int x,y;scanf("%d%d",&x,&y);
Node *L,*R,*p;//分别指向<x >y [x,y]的三棵树!
//非权值分裂,而是排名分裂!
Split(root,y,L,R);
Split(L,x-1,L,p);
if(p!=nullptr)p->lazy ^= 1;
root = Merge(Merge(L,p),R);
}
solve(root);
return 0;
}可持久化平衡树:我们知道想线段树这样的数据结构适合做持久化,FHQTreap也适合做可持久化。
只需要在分裂和合并中记录树的变化就可以了。
2、可持久化文艺平衡树
笛卡尔树
其实就是简化版的Treap树,将位置看作是键值(这样中序遍历就是原来数组),然后把值看作是优先级。
这样有啥好处呢?
可以在O(n)的时间内建树,(但是树不一定平衡),所以在笛卡尔树上查找L和R可能很耗时间 O(n)。
笛卡尔树最直接的应用就是求RMQ问题,通过寻找L和R的最近公共祖先,就是他们的最小/最大值。
应用:1、笛卡尔树中序遍历就是1,2,3,4,..下标
2、后序遍历可以以O(n)的时间找到 连续区间长度*区间最大值(或者最小值)
矩阵快速幂
通过矩阵快速幂的方式可以加速递推的过程。举个简单的例子
F(n) = F(n-1) + F(n-2) 斐波那契数列
那么我们可以知道
[F(n) F(n-1)] = [F(n-1) F(n-2)]*A = ... = [F(1) F(0)] A^(n-1);
如果A这个矩阵能被计算出来,就可以直接通过计算矩阵快速幂来获得F(n)的值。
比如一开始我们是一步一步来获得的需要O(n)
通过矩阵快速幂,我们只需要O(logn)
1、Matrix power series
题意:已经知道n*n的矩阵A,sum(k) = A + A²+A³+... + A^k,求sum(k),结果对m取模
思路:我们已经会了矩阵快速幂,所以我们可以快速求出A^k(O(logk)) ,但是这里面的k<=1e9,十分巨大,显然需要优化。
1、发现存在隐含的递推公式F(n) = F(n-1) + A^n
2、可以尝试用E来找到A
3、[F(n) E] = [F(n-1) E]S = ... [F(1) F(0)] S^(n-1);
4、然后通过F(n) = F(n-1)*a + c ,E = F(n-1)*b + d 得出S矩阵[A O A E]
5、对S矩阵进行幂运算我们可以发现 S^k = [A^k O,A^k+A^(k-1)...+A,E],左下角刚好是我们所要求的答案。
6、综上所述,我们只要对S矩阵进行取幂,左下角的矩阵就是我们所要求的矩阵,而时间复杂度为O(n^3logk)
代码如下:
#include <iostream>
using namespace std;
#include <cstring>
int n,k,m;
struct matrix{
int mp[35][35];
};
struct Matrix_two{
matrix mp[2][2];
};
int mul(int a,int b){
a = a%m;
b = b%m;
int res = 0;
while(b>0){
if(b&1) res = (res+a) %m;
a = (a+a) %m;
b >>= 1;
}
return res;
}
matrix operator*(const matrix &a,const matrix &b)
{
matrix c;//返回c
memset(c.mp,0,sizeof(c.mp));
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
for(int k=0;k<n;k++){
c.mp[i][j] = (c.mp[i][j] + a.mp[i][k] * b.mp[k][j])%m; //相乘会不会超?
}
}
}
return c;
}
matrix operator+(const matrix &a,const matrix &b)
{
matrix c;
memset(c.mp,0,sizeof(c.mp));
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
c.mp[i][j] = (a.mp[i][j] + b.mp[i][j])%m;
}
}
return c;
}
Matrix_two operator*(const Matrix_two &a,const Matrix_two &b)
{
Matrix_two c;
//初始化c,让它的所有都为0
for(int i=0;i<2;i++){
for(int j=0;j<2;j++){
for(int k=0;k<n;k++){
for(int l=0;l<n;l++){
c.mp[i][j].mp[k][l] = 0;
}
}
}
}
for(int i=0;i<2;i++){
for(int j=0;j<2;j++){
for(int k=0;k<2;k++){
//让大矩阵和大矩阵中的小矩阵相加和相乘
c.mp[i][j] = c.mp[i][j] + (a.mp[i][k] * b.mp[k][j]);
}
}
}
return c;
}
Matrix_two Matrix_pow(Matrix_two a,int q)
{
Matrix_two ans;//答案,让它先为[E 0, E 0]
for(int i=0;i<2;i++){
for(int j=0;j<2;j++){
for(int k=0;k<n;k++){
for(int l=0;l<n;l++){
ans.mp[i][j].mp[k][l] = 0;
}
}
}
}
for(int i=0;i<2;i++){
for(int j=0;j<n;j++){
ans.mp[i][i].mp[j][j] = 1;
}
}
while(q){
if(q&1) ans = ans * a;
a = a * a;//a*a
q >>= 1;
}
return ans;
}
signed main()
{
cin>>n>>k>>m;
matrix A;
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
cin >> A.mp[i][j];
}
}
Matrix_two S;
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
S.mp[0][0].mp[i][j] = A.mp[i][j];
S.mp[1][0].mp[i][j] = A.mp[i][j];
S.mp[0][1].mp[i][j] = 0;
S.mp[1][1].mp[i][j] = 0;
}
}
for(int i=0;i<n;i++){
S.mp[1][1].mp[i][i] = 1;
}
//需要求出Matrix_pow(S,n) ,然后S左下角那个矩阵就是答案矩阵
Matrix_two answer = Matrix_pow(S,k);
//输出答案
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
cout << answer.mp[1][0].mp[i][j] << " ";
}
if(i<n-1)cout << endl;
}
return 0;
}2、路径问题与矩阵快速幂(加速求最短路径的长度)
题意:
给定一张由T条边构成的无向图,点的编号为1~1000之间的整数。
求从起点S到终点E恰好经过N条边(可以重复经过)的最短路。
注意: 数据保证一定有解。
思路:一些基本的路径算法,Dijkstra算法是基于BFS的,Bellman-Ford和SPFA算法的思想是”追层扩散“,和BFS差不多,它们都没有"兜圈子”的功能;Floyd算法的寻路过程无法限制两点之间只经过n条边,其实用矩阵来求路径问题是很难想到的,接下来有一些定理:
定理1、计算邻接矩阵的幂G = M^n,其元素G(i,j)的值是从i~j经过n条边的总路径数量。
定理2、计算邻接矩阵的广义幂G = M^n,其元素G(i,j)的值是i~j经过n条边的最短路径的和
其中广义幂的乘法需要重载为M*M = min(M[i][a]+M[a][j])
代码如下:
#include <iostream>
using namespace std;
#include <cmath>
#include <cstring>
int cnt = 0,Hash[1001];
struct matrix{
int m[120][120];
};
const int INF = 0x3f;
matrix operator*(const matrix &a,const matrix &b)
{
matrix c;
memset(c.m,INF,sizeof(c.m));
for(int i=1;i<=cnt;i++){
for(int j=1;j<=cnt;j++){
for(int k=1;k<=cnt;k++){
c.m[i][j] = min(c.m[i][j],a.m[i][k]+b.m[k][j]);
}
}
}
return c;
}
matrix pow_matrix(matrix a,int n)
{
matrix c = a;
n--;
while(n){
if(n&1) c = c * a;
a = a * a;
n >>= 1;
}
return c;
}
int main()
{
//给定一张由T条边构成的无向图,点的编号1~1000之间的整数
//求起点S~E恰好经过N条边的最短路
int N,T,S,E;cin>>N>>T>>S>>E;
matrix a;
memset(a.m,INF,sizeof(a.m));
while(T--){
int w,u,v;cin>>w>>u>>v;
if(!Hash[u]) Hash[u] = ++cnt;
if(!Hash[v]) Hash[v] = ++cnt;
a.m[Hash[u]][Hash[v]] = a.m[Hash[v]][Hash[u]] = w;
}
//矩阵幂运算
matrix ans = pow_matrix(a,N);
printf("%d",ans.m[Hash[S]][Hash[E]]);
return 0;
}高斯消元
简单来讲就是 程式化 来求解线性方程组(线性代数基础)的解,并且判断是否有没有解,且是无穷解还是无解?。
1、线性方程组
题意:已知 n 元线性一次方程组。求解,若无解输出-1,若无穷解输出0
思路:1、从第一列开始,选择一个最大的系数所在的行
2、交换最大系数所在行和当前列的行。
3、如果a[i][i]这时候==0(用eps来判断),则说明无解
4、把当前主行的系数除以a[i][i],保证对角线上当前行的系数为1
5、最后消去主元所在的其他行的主元
6、重复步骤2~5
代码如下:
#include <iostream>
using namespace std;
#include <cmath>
double a[105][105];
double eps = 1e-9;
int main()
{
int n;scanf("%d",&n);
for(int i=1;i<=n;i++){
for(int j=1;j<=n+1;j++){
scanf("%lf",&a[i][j]);
}
}
bool flag = true;
//1、枚举列
for(int i=1;i<=n;i++){
//2、选择一个最大的系数所在的行
int max = i;
for(int j=1;j<=n;j++){
if(fabs(a[j][j])>eps&&j<i) continue; //如果这一列的列元不为0,且j<i,直接continue即可
if(fabs(a[j][i])>fabs(a[max][i])) max = j;
}
//3、交换max行和第i行
for(int j=1;j<=n+1;j++){
swap(a[max][j],a[i][j]);
}
//4、判断是否无解
if(fabs(a[i][i])<eps){
//无解
flag = false;
continue;
}
//5、把当前行的系数除以a[i][i],注意要从后往前除
for(int j=n+1;j>=i;j--){
a[i][j] = a[i][j] / a[i][i];
}
//6、消去主元所在的其他行的主元
for(int j=1;j<=n;j++){
if(j!=i){
double temp = a[j][i] / a[i][i];
for(int k=1;k<=n+1;k++){
a[j][k] -= temp * a[i][k];
}
}
}
}
if(!flag){//如果无解
//如果存在某一行
for(int i=1;i<=n;i++){
if(fabs(a[i][n+1])>eps&&fabs(a[i][i])<eps){
puts("-1");
return 0;
}
}
puts("0");
}else{
for(int i=1;i<=n;i++){
printf("x%d=%.2f\n",i,a[i][n+1]);
}
}
return 0;
}异或空间线性基
“异或空间线性基” 是一种用于处理与 异或运算 相关问题的数据结构。它能够高效地表示一组数的所有异或组合,并且常用于解决最大异或和、能否通过异或得到某个值等问题。
假设有一组数 {a1,a2,…,an},构造线性基的代码伪代码如下:
void insert(long long x)
{
for(int i=MAX_BITS-1;i>=0;i--){
if((x>>i)&1){
if(!basis[i]){
basis[i] = x;
return;
}
x ^= basis[i];
}
}
}在这个过程中,basis[i] 表示第 i 位有值的基向量。当我们尝试将一个数插入基时,我们从最高位开始检查。如果该位没有对应的基向量,我们就将这个数作为新基。如果有基向量,则将当前数与对应基向量异或,直到消除该位。
接下来是异或空间线性基的一点点涉及到的问题:
1、最大异或和问题
2、子集异或查询问题
3、异或路径问题
4、异或和的不同结果数
5、最小异或和问题
6、能否表示某个值的异或和
7、异或基求第k小问题
8、异或基的构建
9、动态线性基
10、分块异或基
1、最大异或和
题意:给定一个数组,求它的最大异或和
思路:先求线性基,然后直接从大到小 异或 到最大值即可
代码如下:
#include <iostream>
using namespace std;
#include <vector>
const int MAX_BITES = 61;
long long basis[MAX_BITES];
//获得线性基
void insert(long long x){
for(int i=MAX_BITES-1;i>=0;i--){
if((x>>i)&1){
if(!basis[i]){
basis[i] = x;
return;
}
x ^= basis[i];
//如果存在,就取剩下的: 比如a^b = c 那么 b = a^c
//如果basis[i] = 10101 ,而x = 10011 那么x^=basis[i]之后 x就等于 00010 ,那么就可以用 x和basis[i] 来表示原来的x
}
}
}
//获得最大异或和
long long getMaxXor()
{
long long ans = 0;
for(int i=MAX_BITES-1;i>=0;i--){
if((ans ^ basis[i]) > ans){
ans ^= basis[i];
}
}
return ans;
}
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++){
long long x;
cin>>x;
insert(x);
}
long long ans = getMaxXor();
cout << ans <<'\n';
return 0;
}对getMaxXor函数的证明:
为什么这个策略得到的异或和是最大的?
- 贪心选择:我们从最高位(第 60 位)开始尝试,逐位检查是否能够增加当前的异或和。如果可以增加,那么我们就异或对应的基向量。
- 线性独立性:由于线性基中的数是独立的,每次异或操作都能保证添加一个新的未被包含的高位1。这意味着每次的异或操作都会为结果引入尽可能多的高位1。
- 最大化高位贡献:贪心地从最高位开始构造异或和,保证了在保证结果中尽可能多的高位1。高位的1对数值贡献最大,因此这个策略能够保证结果是可能的最大值。
2、子集异或查询问题
- 题解思路:
- 结合线性基来处理区间内的最大异或和。
- 使用分块算法或莫队算法对查询进行分块处理,降低每次查询的复杂度。
3、异或路径问题
逆
一般求解ax≡b(mod m),需要用到逆。
这种形式可能比较少见,如果我们换成 P/S (mod m),就很明显,比如我们知道P和S的值,我们想要知道P/S (mod m)的值,我们都知道模运算里面没有除法运算。如果P/S等于小数应该怎么办呢?
我们就可以将S转化为S的逆 P*S的逆 (mod m)
求逆的方法:
1、根据费马小定理 a的n-1次方 ≡ 1(mod n) 并且n是素数
2、通过ax≡1(mod n)来计算
等价于 ax = 1 - yn (y是整数)
等价于 ax+ny = 1
就可以通过扩展欧几里得算法来求解x和y的特解
下面给几道例题即可:
1、Sakurako's Box
思路:给出数列(a1,a2,a3...an),求随机取出两个数字乘积的期望值然后模1e9+7。显然,就是求
所有两数乘积之和 / 所有不同的两个数的二元组的个数 然后 模 1e9+7
P/Q (mod 1e9+7)
Q = n*(n-1)/2
P可以用前缀和维护
但是我们知道除法的模运算不是 (P/Q) mod 1e9+7
需要先求出Q的逆,然后输出 (P*Q的逆)mod 1e9+7
根据费马小定理我们可以知道模数p是一个质数(1e9+7),那么Q的逆可以是Q的p-2次方。可以用快速幂计算。
有人可能会感觉疑惑(比如我),为什么不能直接算出 (P/Q)然后模去1e9+7。因为P/Q可能是 小数,而小数是不能被模的,更何况C++里面P/Q是一个去掉精度的整数。所以要学习求逆的方法来求这种值。
代码如下:
#include <iostream>
using namespace std;
const int MOD = 1e9+7;
const int N = 2e5+10;
typedef long long ll;
long long a[N];
long long sum[N];
long long qpow(ll x,ll y)
{
ll res = 1;
while(y){
if(y&1) res = (res%MOD * (x%MOD))%MOD;
x = (x%MOD) * (x%MOD) %MOD;
y >>= 1;
}
return res;
}
int main()
{
int t;cin>>t;
while(t--){
int n;cin>>n;
for(int i=1;i<=n;i++){
scanf("%lld",&a[i]);
sum[i] = sum[i-1] + a[i];
}
long long ans = 0;
long long length = (n)*(n-1)/2;
for(int i=1;i<n;i++){
ans = (ans + ((a[i]%MOD)*(sum[n]-sum[i])%MOD)%MOD)%MOD;
}
//输出ans / n即可
cout << (ans%MOD*qpow(length,MOD-2))%MOD << endl;
}
return 0;
}素数
1、小素数的判定一般用试除法,时间复杂度O(sqrt(n))
2、大素数的判定有两种方法:
①、费马素性测试:根据费马小定理: 如果a和n互素,那么a的n-1次方 ≡ 1(mod n)。所以我们随机取1~n中某个数当作a,如果上面同余方程成立,那么n很大概率是素数,如果不成立,那么n一定不是素数。
坏消息:有一些数无论a取多少,它一定会通过素性测试,所幸这个数很少,前1亿个数里面只有255个这样的Carmichael数,而且随着数越大这种数越少。
好消息:我们可以通过另外一个定理(二次探测定理)来和费马素性定理双重判定某个数是合数还是素数。这种方法我们称为Miller-Rabin素性方法
②、Miller-Rabin素性方法:
首先要知道二次探测定理:如果p是一个奇素数,且e>=1,则方程x² ≡ 1(mod p的e次方)。
且当e>1时,只有两个解,x=1或x=-1。
当e==1时,只有两个解,分别是x=1或x=p-1;
如果一个数满足方程,但是x!=1或者x!=p-1,那就称它为“非平凡平方根”
⑩、下面给出定理的推论:如果对模n存在1的非平凡平方根,则n是合数。
如果直接看结论可能会很头疼,所以我们可以先从例子入手(算法竞赛上的例子)
对于一个Carmichael数n=561为例子,随机数为7,n-1 = 2^4 * 35(把n-1 转化为u2^t),
那么u = 35 , t = 4(其实u就是n-1的最后一个1前面的数字,t代表n-1二进制有多少个后缀0)
(比如对于n-1 = (1110000),那么u = (111) = 7 , t = 4,看不懂先跳过可以看代码)
(1)、a^u mod n = 7^35 mod 561 = 241;
(2)、241² mod 561 = 298;
(3)、298² mod 561 = 166;
(4)、166² mod 561 = 67;
(5)、67² mod 561 = 1。
判断合数点1、循环了t(4)次,如果最后答案不是1,那么一定是合数(为什么?费马小定理a^(n-1) ≡ 1(mod n)。如果最后模不是1不就说明费马小定理是错误的,那么就可以说n肯定不是素数)
判断合数点2、如果在中间出现了右边 = 1,但是左边不为1,且右边不为(n-1),那么说明它是合数。(为什么?,根据大概半面的距离有个⑩(并没有1~9,只是怕出现相同的)推论,如果对模n存在1的非凡平方根,说明n不是素数)
可能这个例子你没有看懂,那可以试试结合Miller-Rabin素性测试来相互印证。
1、令n-1 = u
2、通过二进制分别计算u和t(上面例子:如果n-1 = (1110000),那么u = (111) = 7,t = 4)
3、为了计算 mod n = 1,可以先计算
mod n,然后这个结果连续平方t次取模。最后结果为1.
4、根据判断合数点2:在连续平方t次过程中,如果出现了非凡平方根,那么说明一定为合数
5、根据判断合数点1:如果最后不是1,那么一定为合数。
6、如果最后通过了素性测试,那么它大概率是素数(重复50次几乎就可以说明它是素性的了)
代码如下:
#include <iostream>
using namespace std;
typedef long long ll;
#include <cstdlib>
//快速幂
ll fast_pow(ll x,ll y,int m){
ll res = 1;
while(y){
if(y&1) res = (res * x) % m;
x = (x*x) % m;
y >>= 1;
}
return res;
}
//二次探测定理 + 费马定理
bool witness(ll a,ll n){
//1、首先让假设 u*2^t = n - 1,根据二进制的特定,u就是以最后一个1结尾的前面的所有二进制,而t就是(n-1)的结尾。
//由此我们让u = n - 1,然后通过循环,分别获得u , t
ll u = n - 1;
int t = 0;
while(u&1==0) u>>=1,t++;
ll x1,x2;
//3、为了计算a^(n-1) mod n,可以先算出a^(u) mod n,然后对其结果连续平方t次取模。
//(1)、如果最后结果x1 不为 1 那么 就没有通过费马素性测试
//(2)、如果中间过程出现了一个解为1,但是另外一个解不是n-1,那么就出现了模n存在1的非凡平方根,那么没有通过二次探测定理
x1 = fast_pow(a,u,n);
for(int i=1;i<=t;i++){
//4、每次x2为新的解,然后变成了 x1² mod n = x2,如果出现了x2解为1,但是x1不是n-1,说明没有通过二次探测定理
x2 = fast_pow(x1,2,n);
if(x2==1&&x1!=n-1) return true; //是合数
x1 = x2;
}
if(x1!=1) return true;//是合数
return false;//false说明可能是素数
}
//miller-rabin素性测试
int miller_rabin(ll n,int s){
//1、如果n<2不用探测,肯定不是素数
if(n<2) return 0;
//2、如果是2,也不用探测,肯定是素数
if(n==2) return 1;
//3、循环n遍,但如果n<s,那么循环n遍即可
for(int i=0;i<s&&i<n;i++){
//4、构造随机数为 1~(n-1)
ll a = rand()%(n-1) + 1;
//5、素性判断
if(witness(a,n)) return 0;
}
return 1;
}
int main()
{
//求m个数里面有几个质数
int m;
while(scanf("%d",&m) != EOF){
int cnt = 0;
for(int i=0;i<m;i++){
ll n;scanf("%lld",&n);
int s = 50;
cnt += miller_rabin(n,s);
}
printf("%d\n",cnt);
}
return 0;
}注意:HDU好像不能在注释里面加(²) 符号,不然就会报错,如果把witness第四行注释删去即可。
综上,Miller-Rabin素性方法步骤为:
费马小定理与二次探测定理的结合。
误差分析,如果随机个数s=50,那么出错率为 2的-50次方,这已经很低了。
时间复杂度O(s*(log2(n))三次方)。如果n=2的64次方,那么时间复杂度就是O(50*64*64*64),在可以容忍的范围之内。
威尔逊定理
定义:若p为素数,则p可以整除(p-1)! +1
或者说 ((p-1)!) mod p = p-1
除了4,其他合数 ((h-1)!)mod h = 0;
用来解决某个素数与小于它的阶乘相关问题
欧拉函数
典型的积性函数。
欧拉函数定义:设n是一个正整数,欧拉函数f(n)为不超过n且与n互素的正整数的个数
eg f(9) = 6
定理 n = 约数的和:12的约数有1,2,3,4,6,12
那么 12 = f(1) + f(2) + f(3) + f(4) + f(6) + f(12)
1、若n是素数,Ouler(n) = n-1;
2、若n=p^k,且p是素数,那么Ouler(n) = p^(k-1)*Ouler(p)
3、一般n可以用 Ouler(n) = n* ( 1-1/p1) * ( 1-1/p2) *...*(1- 1/pk),其中pi为Ouler的质因子。
1、求Ouler(n)
int Ouler(int n){
int ans = n;
for(int p=2;p*p<=n;p++){
if(n%p==0){ //p是n的质因子
ans = ans/p*(p-1); //一般公式
while(n%p==0) n/=p; //去掉这个质因子的幂
}
}
if(n!=1) ans = ans/n*(n-1); //若n不等于1,说明n也是它的质因子。只不过因为遍历不到。
return ans;
}2、求Ouler的前i项和(时间复杂度为O(n)),而杜教筛就是在O( )时间复杂度求这个。
)时间复杂度求这个。
思路:如果新出一列的长度是n,那么教练距离新的一列的长为n-1,教练距离某个同学的函数y=(i)/(n-1)x。可以得知,若这个分数不能化简就说明教练可以看到这个同学,所以新出的一列的n个同学中,教练可以看到新同学的数量为Ouler(n-1)。根据n*n的对称,教练可以看到的同学数量就是2*sumOuler(n-1)+1
代码:
#include <iostream>
using namespace std;
const int N = 50005;
int phi[N];
int prime[N];
int vis[N];
void get_phi()
{
phi[1] = 1;
int cnt = 0;
for(int i=2;i<N;i++){
if(!vis[i]){//是素数
prime[cnt++] = i;
phi[i] = i-1;
vis[i] = i;
}
for(int j=0;j<cnt;j++){
if(i*prime[j]>N) break;
vis[i*prime[j]] = prime[j]; //最小质因子
if(i%prime[j]==0){//i本身就有i*prime[j]的所有质因子,所以i*prime[j] * (1-1/pi) 可以等价于 prime[j] * (i*...) = prime[j]*phi[i]
phi[i*prime[j]] = prime[j] * phi[i];
break;
}
phi[i*prime[j]] = phi[i] * phi[prime[j]];
}
}
}
int sum[N];
int main()
{
//求欧拉函数的前n项和,phi[1] = 1
get_phi();
int n;cin>>n;
sum[1] = 1;
for(int i=2;i<=n;i++) sum[i] = sum[i-1] + phi[i];
if(n==1){
cout << 0 << endl;
}else{
cout << 2*sum[n-1] + 1 << endl;
}
return 0;
}ICPC补题:
K.Maximum GCD
题意:给定一个序列,然后对每个数可以进行若干次对x(任意的)取模,然后将a[i]modx取代a[i]的数,最后求数组的最大公约数
思路:对于模运算,我不是很熟悉,所以我一开始以为是取最小值即可,后来学习到,对于每个数n取模运算后的整数值一定是小于 n/2 的最大整数值。
1、找到序列最小值m
2、判断序列中有没有值>m && <2*m。2*m因为可以被m整除,所以无需进行模运算(易错点1)
3、如果没有,那么答案就是m
否则,判断m是不是偶数,如果是偶数,那么本来对m取模后是m/2-1,但是其他序列的值可以变成m/2,而最小值不改变,同样也是m的倍数。(易错点2)所以m%2==0时,输出m/2。如果m是奇数,那么m/2在C++是向下取整的,m/2<(double)m/2,所以直接输出m/2就可以了。综上所述,答案要么是m,要么是m/2
代码如下:
#include <iostream>
using namespace std;
const int N =1e5+10;
int a[N];
int main()
{
int n;cin>>n;
int Min = 1000000000;
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
Min = min(Min,a[i]);
}
bool flag = true;
for(int i=1;i<=n;i++){
if(a[i]>Min&&a[i]<2*Min){
flag = false;
break;
}
}
if(flag==true){
cout << Min << endl;
}else{
if(Min%2==1){//如果是奇数
cout << Min/2 << endl;
}else{
cout << Min/2 << endl;
}
}
return 0;
}历程:
1、写了一道之前写过的题目,我感觉写的比以前要好很多,结果我用的是unoreder_map导致一直超时,因为这个本质上是用哈希来存储的,键值对很多的情况下会退化成O(n),而map是红黑树构建的,所以几乎都是O(logn)。建议以后还是尽量少用unoreder_map
2、记录一下开动态二维数组vector<vector<int>> mp(n,vector<int>(m)); //n行 m列

















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









