









对数组执行数学运算和逻辑运算时,Numpy 是非常有用的。在用 Python 对 n 维数组和矩阵进行运算时,Numpy 库提供了大量有用特征。Numpy 库数组有两种形式:向量和矩阵。严格地讲,向量是一维数组,矩阵是多维数组。在某些情况下,矩阵只有一行或一列。
在导入 Numpy 库时,我们通过 as 将 np 作为 Numpy 的别名,导入方式如下。
> import numpy as np
import numpy as np### 1.1创建数组
数组的操作---排序,拼接,求和,找最值,这些是基本操作
my_list = [1, 2, 3, 4, 5]
my_numpy_list = np.array(my_list) #通过列表参数传入数组
print(my_numpy_list)
my_list.append(6) #列表中添加新元素,只能添加一个
my_numpy_list1 = np.array(my_list)
my_numpy_list1
print(type(my_numpy_list1))
my_turple = (1, 2, 3, 4, 5)
my_numpy_turple = np.array(my_turple) #通过元组传入
my_numpy_turple
c = np.arange(1,10,2)
c

np.arange函数作用
np.arange函数用于创建具有等差数列的数组。可以通过指定其步幅和范围内生成的元素数量来创建等距离的数字序列。
stop值不包括在内
a = my_numpy_list1
a+1
my_numpy_list.dtype #也可以指定类型
np.array(my_list, dtype=np.float64) #指定数据类型
q = my_numpy_list.astype(int)
q.dtype
type(my_list)
type(my_turple )
## 函数说明
✪type() :返回数据结构类型(list、dict、numpy.ndarray 等)
✪dtype():返回数据元素的数据类型(int、float等)
备注:
1)由于 list、dict 等可以包含不同的数据类型,因此不可调用dtype()函数
2)np.array 中要求所有元素属于同一数据类型,因此可调用dtype()函数
astype()改变np.array中所有数据元素的数据类型。能用dtype() 才能用 astype()
### 1.2 创建多维数组
my_list0 = [[1,2,3,9],[5,4,0,3],[7,4,8,1]]
mn = np.array(my_list0) #创建二维数组,几层中括号就是几维数组
mn
my_list1 = [[[1,2,3,9],[5,4,0,3],[7,4,8,1]]]
nm = np.array(my_list1) #创建二维数组,几层中括号就是几维数组
nm
mn.tolist() #数组转化为列表
mn.shape #查看数组的形状、维度、大小
.shape对于二维数组来说是测定行和列,这个是测定数组长度的。我们通常在不知道它有多少数据的时候,我们想求平均数,我们不知道它有多少数据,我们用shape[0]就知道它有多少行,如果你不想用shape,直接用len加数组名就可以,就可以知道有多少行了
和.size的区别是,.size你有多少个

mn.shape =(2,6) #修改数组的形状
mn
mn.shape = (-1,3) #注意-1的作用,-1的作用是只管有三列,具体的多少行由机器去计算得知
mn-1的意思就是不管你有多少行,只要保证是三列就可以


mn.shape = (6,-1)
mn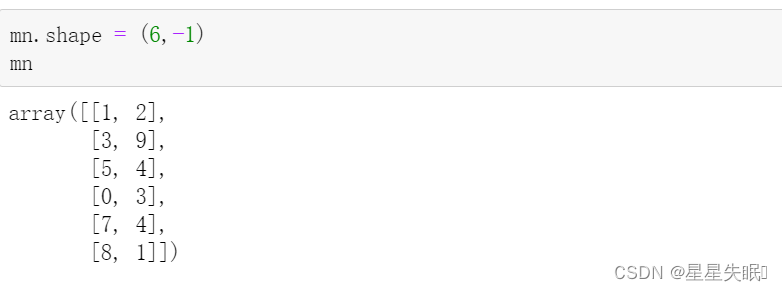
mn = np.array(my_list0).reshape(4,3) #改变数组的形状
mn
### 1.3 创建特殊数组
np.zeros(5) #产生全0数组
np.ones(3) #产生全1数组
zero = np.zeros((2,3)) #产生形状为(2,3)全0的数组
zero
one = np.ones((2,6,3)) #产生形状为(6,3)全1的数组
one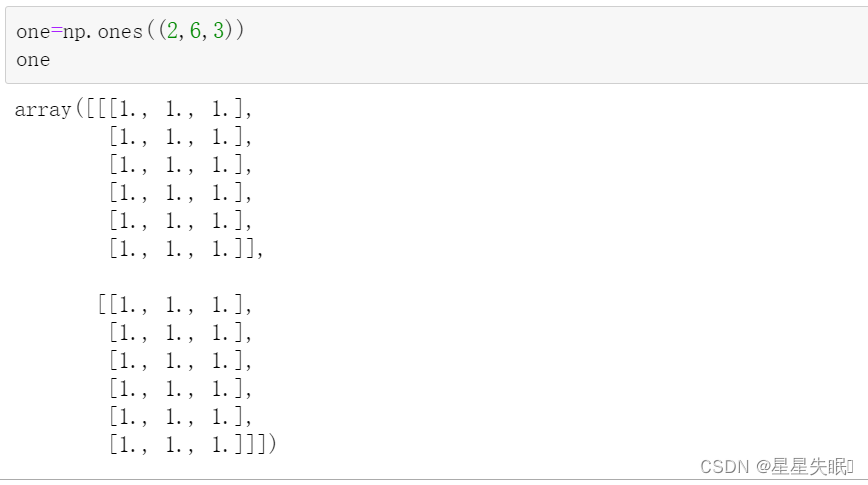
np.full((2,3),8) #产生 按照形状填充指定的元素
np.eye(6) #产生单位矩阵
### 1.4 随机数组
☯np.random.rand()可以生成一个从 0~1 均匀产生的随机数组成的数组。
☯np.random.randn()可以从以 0 为中心的标准正态分布或高斯分布中产生随机样本。
☯np.random.randint()在半开半闭区间[low,high)上生成离散均匀分布的整数值;若high=None,则取值区间变为[0,low)
np.random.rand(5)#可以在[0,1]间生成一个均匀的随机数组
np.random.rand(5, 4)
np.random.randn(3)#可以从以 0 为中心的标准正态分布或高斯分布中产生随机样本
np.random.randn(3,5)
np.random.randint(7)#在半开半闭区间[low,high)上生成离散均匀分布的整数值;若high=None,则取值区间变为[0,low)
np.random.randint(4,7)
np.random.randint(1,7,4)
np.random.randint(10, 15, size=(2,3)) 
np.random.randint(10, size=(2,3)) #同 np.random.randint(10, high=None, size=(2,3)) ✪ 其他创建特殊数组的方法如下。
np.empty((m,n)) : 创建 m 行 n 列,未初始化的二维数组。
np.ones_like(a) :根据数组 a 的形状生成一个元素全为 1 的数组。
np.zeros_like(a) :根据数组 a 的形状生成一个元素全为 0 的数组。
np.full_like(a,val) :根据数组 a 的形状生成一个元素全为 val 的数组。
np.empty((2,3),np.int):只分配内存,不进行初始化。
a=np.empty((3,3))
a
a=np.array([[1,2,3],[4,5,6]])
print("a=",a)
b=np.ones_like(a)
b
#### 1.5 测定数组的长度大小
测定数组的长度、以及包含数据的多少可用len和size。
> 注意:len 和 size 的区别,len 是指元素的个数,
而 size 是指数据的个数,也就是说元素可以包含多个数据。



len(mn) #查阅数组有多少行len(one)mn.size #查阅数组有多少个数据,即:行数*列数np.random.randint(2, 100, 24).reshape((3,8)) #修改数组的形状从2到100之间产生24个随机整数,并生成一个3*8的随机数组,reshape的格式,就把你需要的维度传进去就可以了,可以是随机正态分布的,也可以是均匀正态分布的。正态分布的数据最有用,然后是均匀分布,之后是随机整数

mn.reshape((3,-1))
#### 1.6 访问数组(索引和切片)

a=np.array([1,2,3,4,5])
a[::-1] #5,4正着的索引是从0开始的,倒着的索引从-1开始,这就是数组的逆序输出
a=np.random.randint(1, 15, 24).reshape((3,8))
a
只要元素个数不变的情况下,可以给她变成任意形状,可以变成一维,二维,三维都行,只要他们乘起来是24就可以

b = a.reshape((2,3,4))#将 a 改为三维数组
b
注意!!!!!!考试重点,
页索引,行索引,列索引都是从0开始的
b[:,2:,2] #访问元素4个,每个维度一个切片值,用逗号分隔。 不写就代表所有,后面不写就代表到最后,前面不写就代表从最头,:前后都不写从头到尾,:后面写了,都是左闭右开的,二维数组的切片,切完应该还是个二维数组

#更多的时候是访问符合条件的元素,如条件为 c[x][y],x 和 y 为条件
c = np.array([[1, 2, 3, 4],[4, 5, 6, 7], [7, 8, 9, 10]])
c
c[: , 2][c[: , 0] < 5][: , 2]表示取所有行的第 3 列(第 3 列索引号为 2)
(所有的行第三列,刚才切片访问三维的返回的是二维的,二维的访问完之后是一维的,一定要注意降一维!!!!!!!!!)
[c[: , 0] < 5]表示取第一列(第 1 列索 引号为 0)值小于 5 所在的行(第 1、 2 行)
终表示取第 1、 2 行的第 3 列,得到结果 array([3, 6])这个“子”数组。
考试一定要注意最终结果的写法,降一维!!!!

所有行的第一列的值小于5的,返回的值是布尔值,按照布尔值进行取舍,是true的就留下来了,flase的就没了前面返回的是3,6,9,后面再给一个位置索引,所以返回值是3和6
c = np.array([[1, 2, 3, 4],[4, 5, 6, 7], [7, 8, 9, 10]])
c
#经常用到查找符合条件元素的位置,这时可以使用 where()函数
np.where(c==4) #查找c中数据4的位置
访问数据4的位置,第一列第二个数的索引是4,位置索引加1,把所有数索引的位置返给你

大于5的不显示,小于5的显示它的行索引
np.delete(c,1,0) #a为数组,1为行的索引号,0表示axis=0
axis是数组的轴向
这个就是按行删除
#### 1.7 数组的拼接与切分
数组的拼接 vstack 和 hstack 方法可以实现两个数组的“拼接” 。
np.vstack((a,b)):将数组 a、b 竖直拼接(vertical)。
np.hstack((a,b)):将数组 a、b 水平拼接(horizontal)
vsplit 和 hsplit 方法可以实现对数组“切分”,返回的是列表。
np.vsplit(a,v):将 a 数组在水平方向切成 v 等分。
np.hsplit(a,v):将 a 数组在垂直方向切成 v 等分。
m = np.full((2,3),2)
m
n = np.ones((2,3),dtype=np.int32)
n
p = np.vstack((m,n)) #垂直叠加
p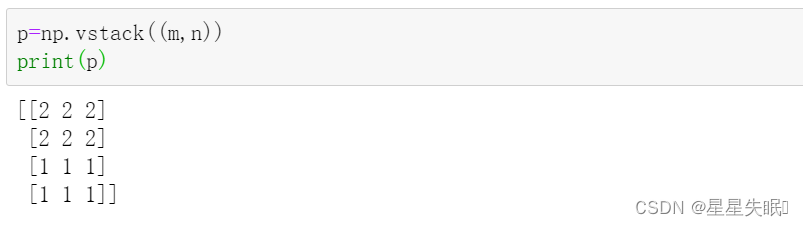
这是垂直叠加
q = np.hstack((m,n)) #横向延展
q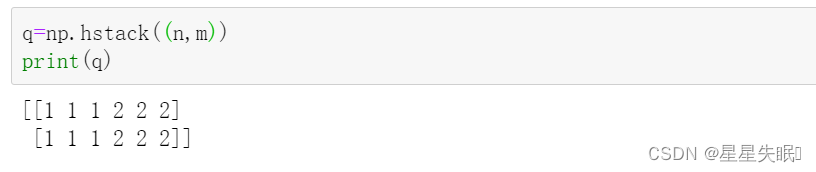
这是水平叠加
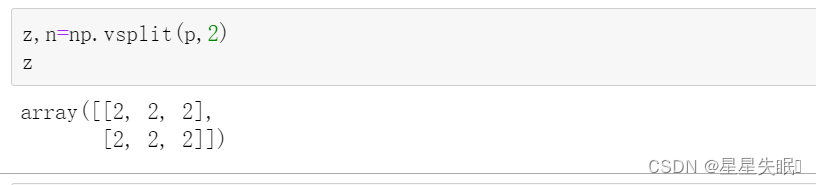
x,y = np.hsplit(q,2) #横向等分切割,切割后为两个元素
y
#### 1.8 查重
对于一维数组或者列表,unique 函数去除其中重复的元素,并按元素由大到小返回一个新的无元素重复的元组或者列表。
>np.unique(a,return_index,return_inverse)
> a : 表示数组。
> return_index : Ture 表示同时返回原始数组中的下标。
> return_inverse: True 表示返回重建原始数组用的下标数组。
这个了解即可,因为我们在数据清洗的时候洗的已经很干净了
d = np.array([[1, 0, 3, 4],[0, 5, 6, 4]])
d
w = d.flatten() #展成一维
w
np.unique(w)
np.unique(w,return_index=True)
np.unique(w,return_inverse=True)
#### 1.9 缺失值检测
在进行数据处理前,一般都会对数据进行检测,看是否有缺失项,对缺失值一般要做删 除或者填补处理。
>np.isnan(a):检测是否是空值 nan,返回布尔值。
对空值的判断不能使用直接的数学比较形式"==",不能用"==np.nan"来判断,只能用np.isnan()来操作。
np.nan的数据类型是float。
查找空值nan时用np.where(np.isnan(c))或者np.argwhere(np.isnan(c))。赋值空值时用np.nan。
import numpy as np
c = np.array([[1, 2, 3, 4],[4, 5, 6, 7], [7, 8, 9, np.NAN]])
print(c)
np.where(np.isnan(c)) #返回空值的位置
#由于nan值不能用“==”来判断,所以用np.isnan()当做条件
np.argwhere(np.isnan(c)) #返回空值的位置,类似坐标形式
#### 1.10 数组排序
在数据处理时,常会对数据进行按行或列排序,或者需要引用排序后的索引等。
np.sort(a,axis=1):对数组 a 里的元素按行排序并生成一个新的数组。
a.sort(axis=1):因 sort 方法作用在对象 a 上,a 被改变。
j=np.argsort(a):对 a 元素排序后的索引位置。
axis=1: 对每行中的元素进行排序,行位置不变,横看 跨列
axis=0:对每列中的元素排序,换行不换列 ,竖看 跨行
查找最大值 在数据分析中,常会用于寻找数据的大值、小值,并返回值的位置。
np.argmax(a, axis=0):查找每列的大值位置。
np.argmin(a, axis=0):查找每列的小值位置。
a.max(axis=0):查找每列的最大值。
a.min(axis=0):查找每列的最小值。
a = np.array([[1,8,3],[4,2,5],[9,7,10],[6,3,7]])
a
a.sort(axis=0) #注意不抛出结果,表明修改了原变量
a
b= np.array([[1,8,3],[4,2,5],[9,7,10],[6,3,7]])
b
np.sort(b,axis=1) #注意:换了个写法,生成一个新的数组
a = np.array([[[1,2,3],[4,5,6]],[[1,8,3],[4,2,5]]])
a
a = np.array([[[1,2,3],[4,5,6]],[[1,8,3],[4,2,5]]])
a
求和:第一个维度是跨页,第二个维度是跨行,第三个维度是跨列
求和降维,三维的求和变成二维的了,
把排序和求和会了,numpy就差不多了
#### 1.11 数组的保存与读取
import numpy as np
c = np.array([[1, 2, 3, 4],[4, 5, 6, 7], [np.nan, 8, 9, 10]])
np.save('save_1.npy',c) #将数组c保存在当前环境下的,命名为save_1.npy建完一个数组,使用np.save存成.npy的文件,这是存一个文件
上面的代码的意思就是把c存成一个.npy的文件,第一个参数是文件的名,如果你需要路径的话,路径照写,如果这么存代表你存的位置和jupter文件放在同一个文件夹下,所以不需要添加路径
在编程的时候,如果你要用到数据,你需要新建一个jupter文件,再把跟它一样的文件放到一个文件夹底下,这一点很重要,把表和.npy文件放在同一个目录下,那么所以得文件直接写名就可以了,就能找得到了
c = np.load('save_1.npy') #将当前环境下的save_1.npy文件中的数组c读取出来,并赋值给变量cnp.load
















 2079
2079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











