






Meltwater和Fairhair.ai两个信息检索系统的核心是包含数十亿社交媒体帖子和社论文章的Elasticsearch集群。我们集群中的索引分片在访问模式、工作负载和大小方面差异很大,这带来了一些非常有趣的挑战。此博客文章描述了我们如何使用线性优化建模在群集中的所有节点上尽可能均匀地分布搜索和索引工作负载。我们的解决方案使硬件利用率更均匀,且降低了单个节点成为瓶颈的可能性。因此,我们改善了搜索响应时间,并节省了架构所需资金。
背景
Fairhair.ai的信息检索系统包含大约400亿个社交媒体帖子和社论文章,每天处理数百万个查询。该平台为我们的客户提供搜索结果,图表,分析,数据集导出和高级别见解。这些海量数据集托管在Elasticsearch集群上,共有750个节点,包含数千个索引和50,000多个分片。有关我们的集群架构的更多信息,请查看我们之前的博客文章运行400+节点Elasticsearch集群,或者最近一篇使用机器学习来加载平衡Elasticsearch查询,它们都解释了我们集群架构的其他关键部分。
不均匀的工作量分配
我们的数据和客户查询主要基于日期,大多数查询都会在特定时间段,例如过去一周,过去一个月,上一季度或其他某个日期范围。为了方便这种索引和查询模式,我们使用基于时间的索引,类似于ELK堆栈。这种索引体系结构提供了许多好处,例如,我们可以进行有效的批量索引,并在数据变旧时删除整个索引。这也意味着给定索引的工作量随时间变化很大。最近的索引都接收了大多数索引请求,并且与过去索引相比,查询的指数也大大增加。

图1:基于时间的索引的访问模式。Y轴显示执行的查询数,X轴显示索引的年龄。我们可以清楚地看到每周,每月和一年的变化趋势,然后是旧指数较低工作量的长尾。
图1中的访问模式是预期的,因为我们的客户对最近的信息更感兴趣,并定期进行本月与上个月和或今年与去年的比较。我们的问题是Elasticsearch不知道这种模式,也没有自动优化观察到的工作量!
内置的Elasticsearch分片放置算法仅考虑:
- 每个节点上的碎片数量,并试图均匀地平衡集群中每个节点碎片的数量
- 高低磁盘水印。在决定是否将新分片分配给该节点或主动从该节点重新定位分片之前,Elasticsearch会考虑节点上的可用磁盘空间。已达到低水印的节点(即使用的85%磁盘)不允许接收更多分片。已达到高水印(即90%)的节点将开始主动移动碎片远离它。
该算法的基本假设是集群中的每个分片都接收大致相同的量,并且所有分片的大小都相似,这与我们的情况相差甚远。这很快就会导致我们称之为群集中随机发展的热点。随着工作量随时间变化,这些热点即将到来。热点实质上是一个节点,其运行接近其一个或多个系统资源的限制,例如CPU,磁盘I/O或网络带宽。当发生这种情况时,节点首先将请求排队一段时间,这会使请求响应时间增加,但如果过载持续很长时间,则最终请求将被拒绝,并且错误会传播给用户。
另一个常见的重载事件是由于查询和索引操作导致的不可持续的JVM垃圾压力,这导致了可怕的JVM GC地狱现象,其中JVM无法快速收集内存并且内存不足(OOM)和崩溃,或者卡住在一个永无止境的GC循环中,冻结并停止响应请求和群集ping。当我们重构架构以在AWS上运行时,这个问题变得更糟,更明显。之前“保存”的事实是,我们在数据中心内的同一个非常强大的(24核)裸机上运行了4个Elasticsearch节点。这掩盖了偏斜的碎片分布的影响,并且它大部分被每台机器相对较多的核心吸收。通过重构,我们开始在每个功能较弱(8核)的机器上只运行一个Elasticsearch节点; 在我们的早期测试中,我们立即发现了热点问题。
Elasticsearch有效地随机分配了分片,并且在群集中有500多个节点,很可能突然变得太多的“热”分片被放置在单个节点上,并且这些节点很快就不堪重负。这会给我们的客户带来非常糟糕的用户体验,超载节点响应缓慢,有时甚至拒绝请求或崩溃。如果我们为生产中的用户运行该设置,他们会看到UI的频繁,看似随机的减速和偶尔的超时。与此同时,我们将拥有大量节点,这些节点被分配了“较冷”的分片,有效地空闲和无所事事,导致我们的群集资源使用效率低下。如果我们可以让Elasticsearch更智能地放置其分片,则可以避免这两个问题,因为所有节点的平均系统资源使用率都处于健康的40%水平。
连续群集状态更改
运行500多个节点时我们观察到的另一件事是集群状态在不断变化。由于,碎片正在从节点移入和移出
- 新指数创建,旧指数下降。
- 磁盘水印由于索引和其他碎片移动而触发。
- 与群集平均值相比,Elasticsearch随机确定节点的分片太少/太多。
- 硬件和操作系统级故障导致新AWS实例启动并加入群集。有500多个节点,平均每周发生几次。
- 由于数据正常增长,几乎每周都会添加新节点。
考虑到所有这一切,我们得出的结论是,需要连续和动态的重新优化算法来全面解决所有这些问题。
解决方案 - Shardonnay
经过对可用选项的大量研究,我们得出结论,我们想要
- 自己构建解决方案。我们没有找到任何好的文章,代码或其他现有的想法能够在现有应用中良好运作。
- 在Elasticsearch之外运行重新平衡过程并使用集群重新路由API而不是尝试构建插件,就像在这种方法中一样。这样做的主要原因是我们想要一个快速的反馈周期,并且在这种规模的集群上部署插件版本可能需要数周时间。
- 使用线性编程在任何给定时间计算最佳的碎片移动。
- 连续运行优化,使群集状态逐渐稳定到最佳状态。
- 一次不要移动太多碎片。
我们做的一个有趣的观察是,如果我们试图同时移动太多碎片,则很容易触发级联碎片重定位风暴。这些事件可能持续数小时,碎片以不受控制的方式来回移动,在不同位置触发高水位,这反过来导致更多的碎片重新定位,链条继续。
要理解为什么会发生这种情况,重要的是要知道当主动索引的分片从节点移出时,它实际上使用的磁盘比它在该节点上静止时使用的磁盘多得多。这与Elasticsearch如何将其写入持久写入Translogs有关。我们看到索引可以在发送它的节点上使用多达两倍的磁盘的情况,当然,在接收它的节点上也会使用更多的磁盘。这意味着由于高磁盘水印而触发分片重定位的节点实际上会在一段时间内使用更多的磁盘,直到它将足够的分片移到其他节点。
我们为完成这一切而建造的服务称为Shardonnay,作为着名的霞多丽葡萄的参考。
线性优化
线性优化(也称线性规划)是在数学模型中实现最佳结果的方法,例如最大利润或最低成本,其数学模型的要求由线性关系表示。
优化技术基于线性变量系统,必须满足的一些约束,以及定义成功的目标函数。线性优化的目标是找到最小化目标函数的变量值,同时仍然遵守约束条件。
分片分配 - 建模为线性优化问题
Shardonnay应该连续运行,并在每次迭代时执行以下算法:
- 使用Elasticsearch API,获取有关群集中现有分片,索引和节点的信息,以及它们当前的位置。
- 将集群状态建模为一组二进制LP变量。(节点,索引,分片,副本)的每个组合都有自己的变量。LP模型还具有许多启发式,约束和我们精心设计的目标函数,更多内容如下。
- 通过线性求解器发送LP模型,在给定约束和提供的目标函数的情况下生成最优解。解决方案是将更新的分片分配到节点中。
- 解释LP解决方案并将其转换为一组碎片移动。
- 指示Elasticsearch使用群集重新路由API执行分片移动。
- 等待群集移动分片。
- 从第1步开始。
该算法的难点在于获得目标函数和约束。其余的将由LP解算器和Elasticsearch本身处理。不出所料,事实证明,在这样大小和复杂的集群中建模和解决这个问题并不容易!
约束
模型中的一些约束我们基于Elasticsearch本身规定的规则,例如始终遵守磁盘水印或副本不能放置在与同一碎片的另一个副本相同的节点上。
我们基于多年运行大型集群所获得的实用主义,增加了其他限制因素。我们自己约束的一些例子是;
- 不要移动今天的索引,因为那些索引是最热门的,并且接收几乎恒定的读写加载。
- 更喜欢将较小的分片移动到较大的分片上,因为它们可以更快地移动Elasticsearch
- 在它们变得活跃之前的几天内最佳地创建和放置未来的分片,并获得索引和繁重的工作量。
这些约束共同确保了正确放置了碎片,并且所有解决方案都尊重碎片移动限制。
成本函数
我们的成本函数将许多不同因素加在一起。例如,我们想要
- 最小化索引和搜索工作负载的差异,以减少热点问题
- 保持磁盘利用率差异尽可能小,以实现稳定的系统操作
- 最小化碎片移动的数量,以防止如上所述的碎片重定位风暴
LP变量修剪
在我们的规模上,这些LP模型的大小本身就成了一个问题,我们很快就知道在任何合理的时间内解决超过60M LP变量的问题是非常困难的。因此,我们应用了大量的优化和建模技巧来大幅减少问题的大小; 包括有偏差的抽样,启发式,分而治之,放松和迭代优化。
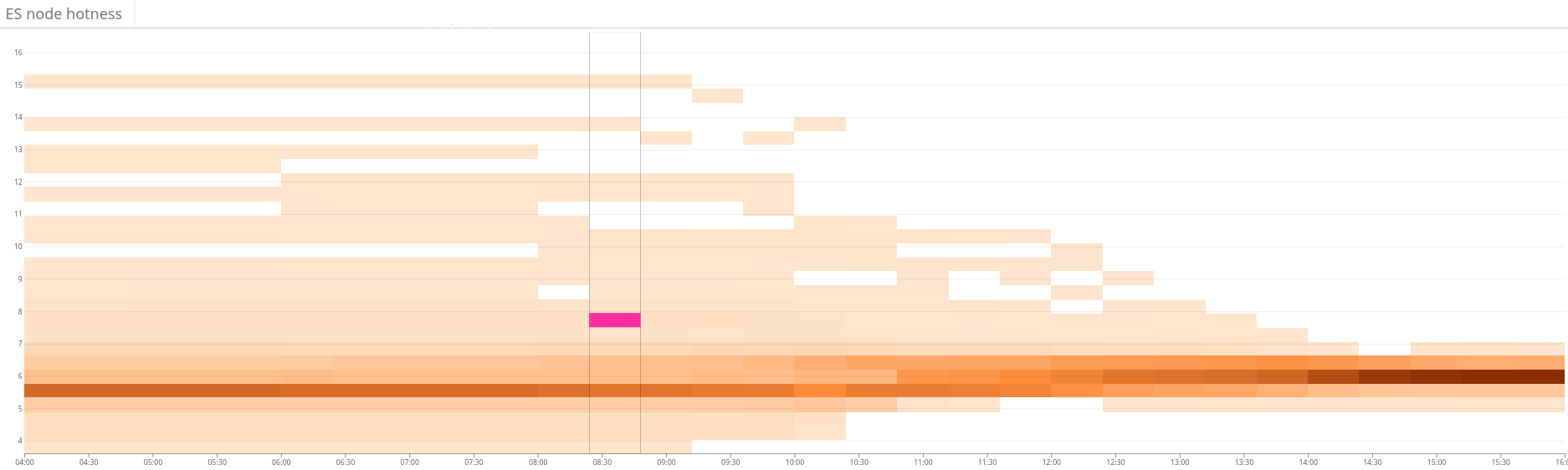
图2:热图显示Elasticsearch集群上的工作负载不平衡。这显示为图表左侧的资源使用量的大变化,并且通过连续的分片放置优化,它逐渐稳定到更紧密的资源使用范围。
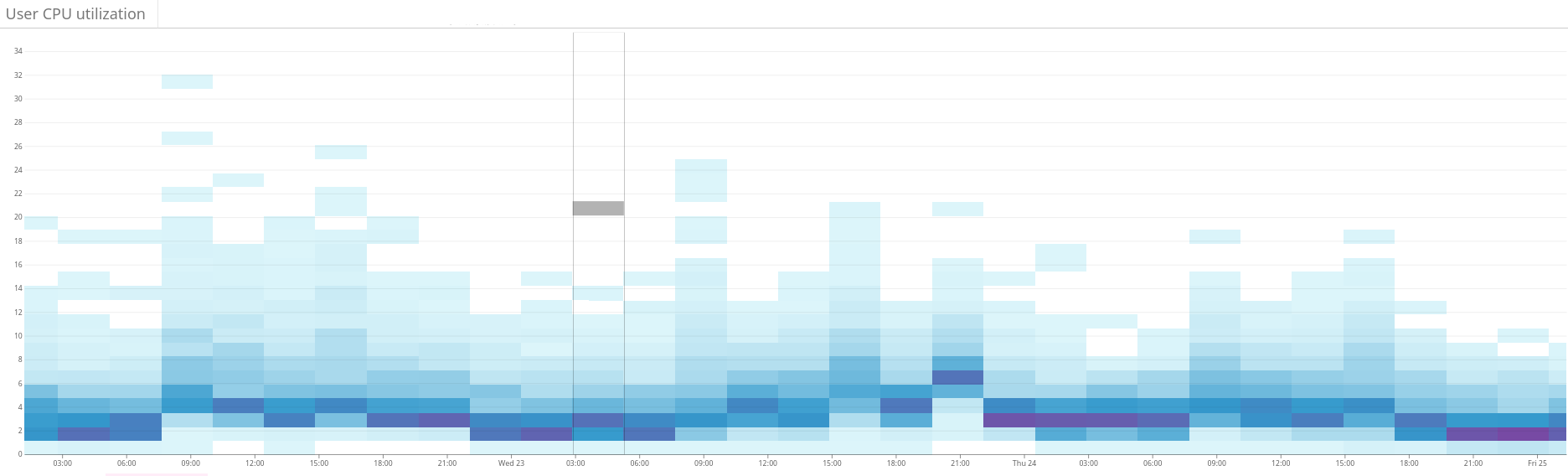
图3:热图显示了在我们对Shardonnay热度函数进行调整之前和之后,集群中所有节点的CPU使用情况。CPU使用率差异从一天到另一天的显着变化 - 具有相同的请求工作量。
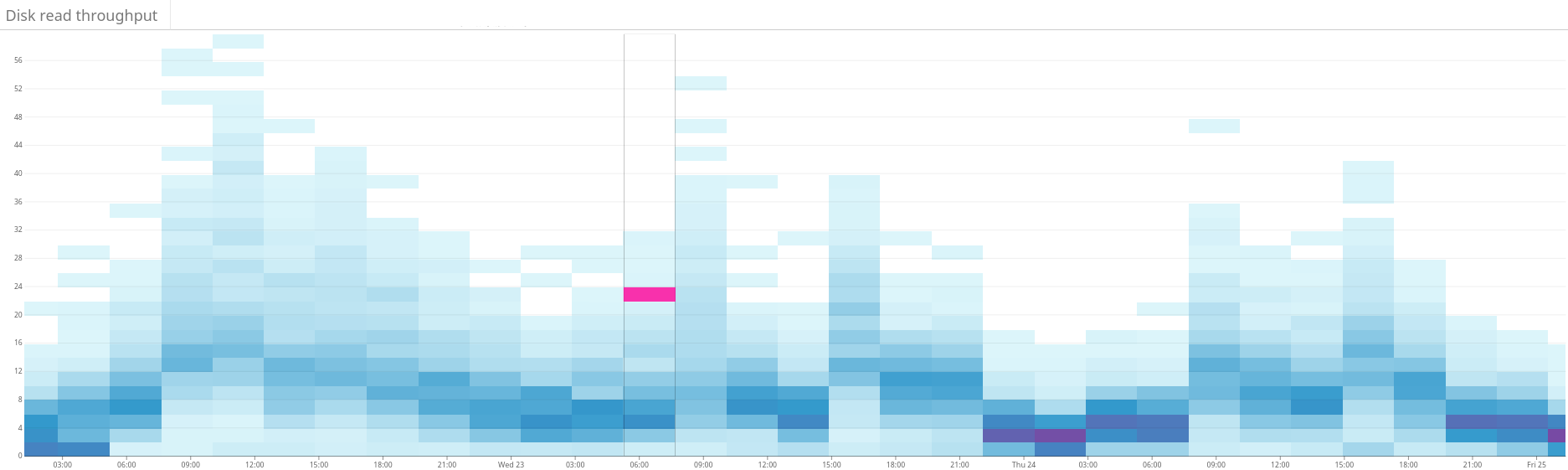
图4:热图显示了与图3相同时间段的磁盘读取吞吐量。磁盘读取也更均匀地分布在整个群集中。
结果
总之,所有这些都允许我们的LP求解器在几分钟内产生好的解决方案,即使对于我们巨大的簇状态,也可以迭代地改进簇状态以达到最优。
最重要的是,工作负载差异和磁盘利用率按预期收敛,并且通过我们自那时以来的许多有意和无法预料的集群状态变化,保持了接近最佳状态!
我们现在在Elasticsearch集群中保持健康的工作负载分配,这完全归功于线性优化和我们称之为Shardonnay的服务。
鉴于您已经阅读了这篇文章,您必须对分发搜索和索引工作负载非常感兴趣。谢谢!:)如果您想与分享平衡分享任何相关经验或对此主题有其他问题和意见,请在下面的评论部分发布。















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









