







elements,console,source,network
elements分析网络结构,获取想要的数据
console打印一些网站的数据,做网站的时候有时候可能会在控制台上打印一些数据
source源文件,相等于一个文件夹,不仅包含网络的元素,还包含一些其他的内容,
如果是静态数据,在elements当中就可以查看到,如果是动态数据在elements之中无法查看
 比如说我们在百度之中搜索美女,会出现各种美女图片,此时随着我们下拉的过程,滚动条会越变越小,然后我们搜索网页源代码之中的关键信息
比如说我们在百度之中搜索美女,会出现各种美女图片,此时随着我们下拉的过程,滚动条会越变越小,然后我们搜索网页源代码之中的关键信息
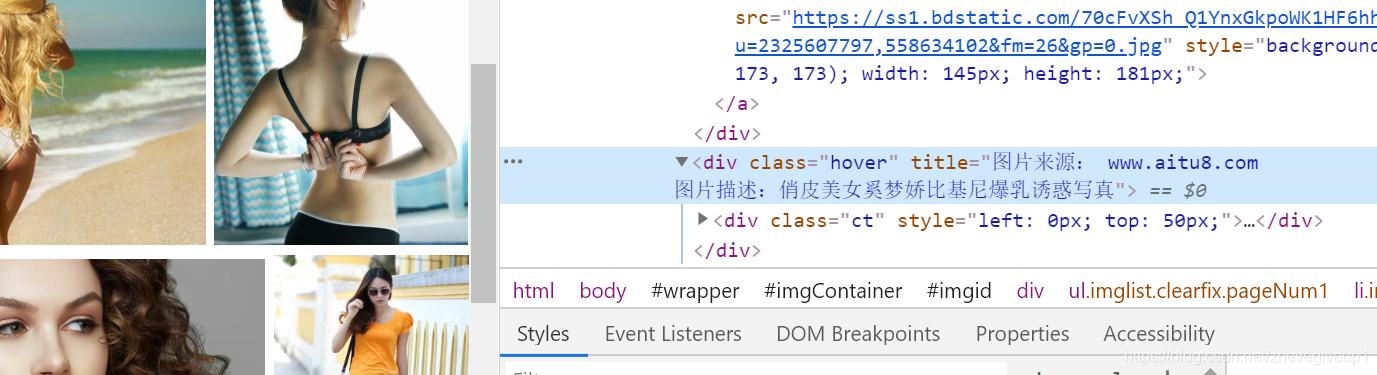
点击source标签,按ctrl+f7输入关键信息,将俏皮美女奚梦瑶的信息输入进去,发现无法找到相应的内容
(也可以右击上面的page按钮,然后点击search in all files的对应属性)
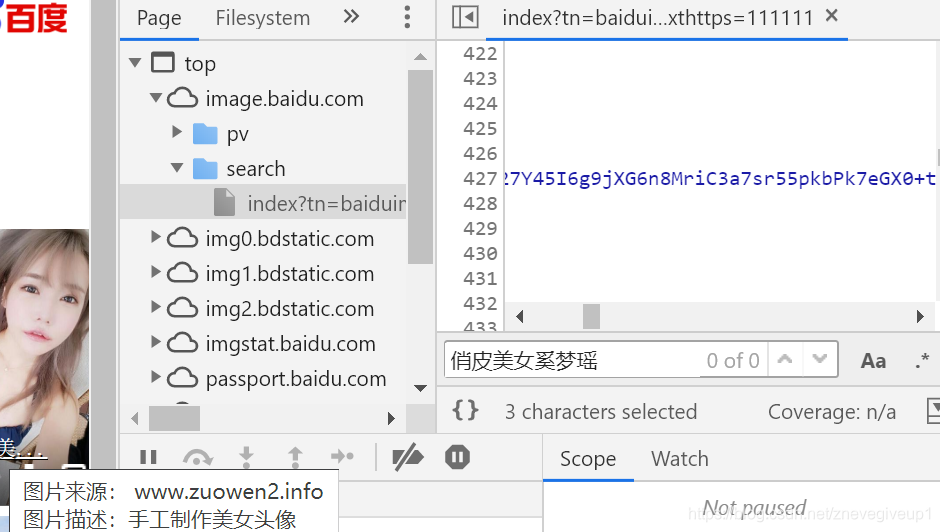
说明网页中呈现的为动态信息,是后来嵌入到页面之中的,为模板+ajax渲染的动态数据,爬虫一定要关注请求与响应。
浏览器:发送请求(请求的url,请求的方式get/pos,请求数据)
服务器:作出响应(响应的状态码,响应数据[二进制数据?文本数据?JSON数据?])
响应返回的数据不同,解析的过程也不同。
418:发现被爬虫了。
爬虫:模拟浏览器想服务器发送请求并处理响应结果
Element(元素html,css,js)
Console
Source(相等于文件夹,Elements,html,css,js)
Network(所有发送的请求都会在这)
查询北京到天津的车次,查询结果如下图
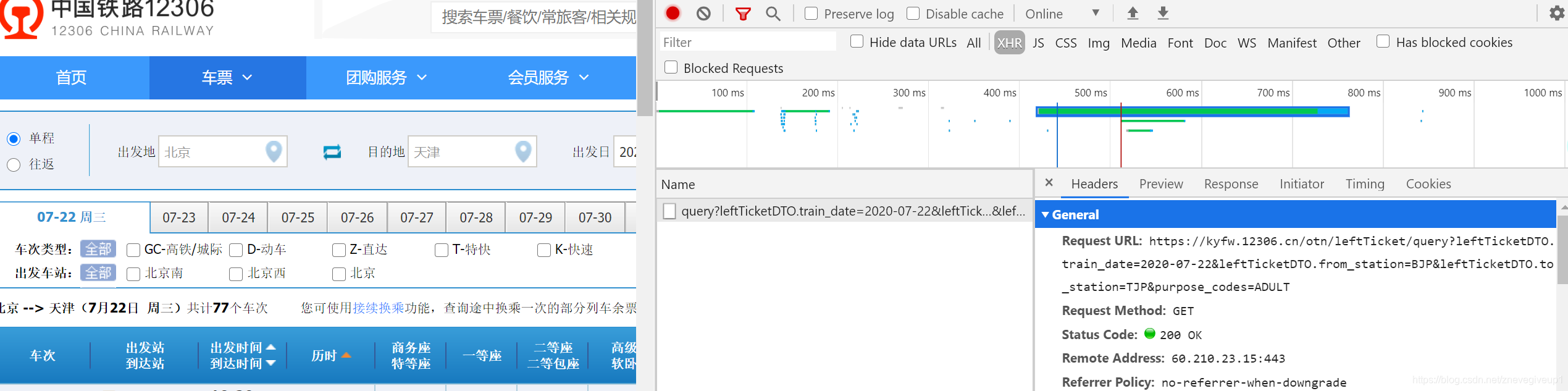 找到请求对应的url
找到请求对应的url
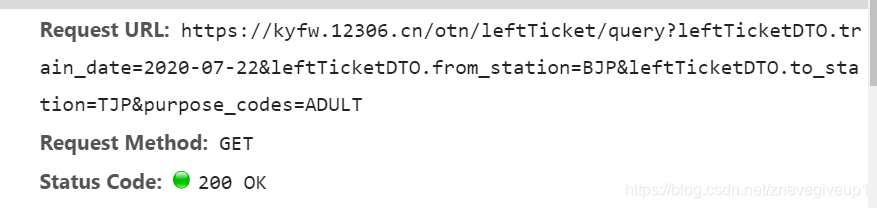 打开网页之后的地址栏保存的为页面的结构,这里面打开的内容才为数据的请求
打开网页之后的地址栏保存的为页面的结构,这里面打开的内容才为数据的请求
原先地址栏中的内容:
https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc&fs=%E5%8C%97%E4%BA%AC,BJP&ts=%E5%A4%A9%E6%B4%A5,TJP&date=2020-07-22&flag=N,N,Y
请求参数为中文并且为get请求的时候,如果想要放到地址栏上,就需要进行编码
通过编码并且解码之后得到的就是地址栏中对应的相应的结果
import urllib.parse
kw = {
'city':'北京'}
#编码
result = urllib.parse.urlencode(kw)
print(result)
#解码
res = urllib.parse.unquote(result)
print(res)
想要数据必须解析相应的格式
在elements栏目中找到对应的编码方式

#编写python代码,模拟浏览器向服务器发送请求,安装一个第三方模块requests
import requests
#请求:url,方式,由于该url请求方式为get,所以使用requests中的get方法
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2020-07-22&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=TJP&purpose_codes=ADULT'
resp = requests.get(url) #请求的结果为响应
#设置响应的编码格式,不然会发生乱码
resp.encoding = 'utf-8'
print(resp.text)
此时会发现爬取到的数据与浏览器中的数据不一样--------数据爬丢了,因为使用python发请求被服务器发现了,所以响应回来的数据不是想要的数据,必须加上header
#编写python代码,模拟浏览器向服务器发送请求,安装一个第三方模块requests
import requests
#请求:url,方式,由于该url请求方式为get,所以使用requests中的get方法
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2020-07-22&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=TJP&purpose_codes=ADULT'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'}
resp = requests.get(url,headers=headers) #请求的结果为响应
#设置响应的编码格式,不然会发生乱码
resp.encoding = 'utf-8'
print(resp.text)
此时仍然失败,还需要加上一个cookie内容,
继续加到请求头当中(如果不行还需要继续添加请求头)
#编写python代码,模拟浏览器向服务器发送请求,安装一个第三方模块requests
import requests
#请求:url,方式,由于该url请求方式为get,所以使用requests中的get方法
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2020-07-22&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=TJP&purpose_codes=ADULT'
headers = {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









