
 关注
关注
 分享
分享
唐僧爱吃唐僧肉
这个作者很懒,什么都没留下…
展开
-
gradient_checkpointing以计算时间换取内存
gradient_checkpointing的方法能够以计算时间去换取内存,这里我阅读longformer的源代码的时候,读取到了以下的内容,可以作为以计算时间换取内存的经典代码方式if self.gradient_checkpointing and self.training: #gradient_checkpoint:以计算时间换内存的方式,显著减小模型训练对gpu的占用 def create_custom_forward(module): def custom_for原创 2022-07-07 16:57:00 · 3542 阅读 · 0 评论 -
单步调试调用堆栈方法
在单步调试的过程中,vscode调用堆栈的部分会显示出各个函数以及调用的过程,以前知道大概有这个功能,但是没用过,都是习惯了手动找函数,今天调试的时候用一下,确实非常地银性,非常地好用,尤其是针对transformers库这种一个套一个的库函数调用,非常地nice,爆赞!...原创 2022-05-25 16:28:11 · 1222 阅读 · 0 评论 -
longformer代码结构解读
Longformer模型难点解读_sliding_chunks_query_key_matmul函数之中的结构变换longformer在延伸maxlen的同时,结构上也存在着很多的难点,这里逐步分析出来。_sliding_chunks_query_key_matmul函数之中的结构变换这里最难懂的是这样的几句query_size = list(query.size())query_size[1] = query_size[1]*2-1query_stride = list(query.strid原创 2022-02-12 22:40:10 · 2236 阅读 · 0 评论 -
“No inf checks were recorded for this optimizer.“ AssertionError:错误解决
"No inf checks were recorded for this optimizer." 错误解决原创 2022-03-19 18:32:36 · 5597 阅读 · 0 评论 -
pandas函数没有进度条解决
对于pandas函数在运行的过程中,如果数值的数量过多,此时一些pandas自带的函数,比如merge,concat等函数,往往会由于运行时间过长,导致你不知道它会运行到哪里,会运行多长时间,此时我们选择自己写循环加进度条来解决这一问题from tqdm import tqdmimport pandas as pdimport numpy as npdf1 = pd.DataFrame({"A":[1.0, 2.0, 3.0, 1.0, 2.0, 3.0, 1.0, 2.0, 3.0],原创 2022-03-18 16:52:41 · 373 阅读 · 0 评论 -
agg函数加入进度条
在panda之中,我们经常需要使用到agg函数来将pandas之中的某几列聚合起来from tqdm import tqdmimport pandas as pdimport numpy as npdf = pd.DataFrame({"A":[1.0, 2.0, 3.0, 1.0, 2.0, 3.0, 1.0, 2.0, 3.0], "B":[1.0, 1.0, 1.0, 2.0, 2.0, 2.0, 3.0, 3.0, 3.0],原创 2022-03-18 16:51:07 · 316 阅读 · 0 评论 -
‘>‘ not supported between instances of ‘list‘ and ‘float‘错误排坑
今天在编程序的时候,运行下面的代码pred_result[pred_result > 0.5] = 1发生了相应的报错TypeError: '>' not supported between instances of 'list' and 'float'仔细查看一下pred_result的类型,发现pred_result是np.array类型呀pred_resultarray([0.38331976532936096, 0.38331976532936096, 0.3833197原创 2022-03-07 17:08:30 · 5895 阅读 · 0 评论 -
深度学习梯度累积到最后卡住了
进行到最后 jupyter notebook进度条停住了最主要的是最后循环退出来的时候需要梯度更新 for batch_ids,batch_token,batch_text,batch_offset,batch_attention_mask,batch_label in tqdm(train_loader): batch_token = batch_token.to(device) batch_attention_mask = batch_a原创 2022-02-25 22:57:35 · 1229 阅读 · 0 评论 -
torch as_strided调用
https://zhuanlan.zhihu.com/p/64933417转载 2022-01-27 21:20:39 · 190 阅读 · 0 评论 -
ubuntu关闭notepadqq的好方法
使用命令ps -e查找所有的进程,然后使用kill …杀死对应的进程原创 2021-11-11 22:23:06 · 1030 阅读 · 0 评论 -
LookAhead优化器方法
SGD优化器:1.自适应学习率方法,如AdaGrad和Adam优化器方法2.加速训练方式,如Nesterov momentum优化器的方法。Lookahead优化器算法通过预先(look ahead)由另外一个优化器生成的"快速权重"序列来选择搜索方向。蓝色实线为本来应该走的fast path的路线,紫色的线为直接到达的slow path路线,这里画出本来应该去走的路线和现在使用了lookahead优化器方法之后去走的路线。可以看出来,常规的梯度下降优化器的优化方向为图中的红色箭头所示,而使用了lo原创 2021-07-05 14:39:57 · 1238 阅读 · 0 评论 -
nezha计算position_embeddings的函数整个流程解读
先放入nezha中的position_embeddings计算过程的整个的函数内容def relative_position_encoding(depth, length=512,max_relative_position=127): vocab_size = max_relative_position * 2 + 1 # 129 print('vocab_size = ') print(vocab_size) #vocab_size = 129 range_ve原创 2021-07-03 15:54:24 · 402 阅读 · 0 评论 -
pytorch输入tensor看对应的输出数值
pytorch输入相应的数值,查看对应的输出数值与tensorflow类似,这里放入一段pytorch由输入计算对应的输出内容的过程。比如如下的代码内容# coding:utf-8import osimport pickleimport torchimport randomimport warningsimport numpy as npimport pandas as pdfrom tqdm import tqdmfrom typing import List, Tuple, Di原创 2021-07-02 09:21:46 · 1590 阅读 · 0 评论 -
权重参数中的adam_v,adam_m,lamb_m,lamb_v等一系列参数的讲解
今天加载了一下对应的nezha模型的权重内容,发现对应的权重名称之中,出现了如下的一些权重名称‘bert/encoder/layer_3/attention/output/dense/bias/lamb_v’‘bert/encoder/layer_1/attention/output/LayerNorm/beta/lamb_m’‘bert/pooler/dense/bias/lamb_v’‘bert/embeddings/word_embeddings/lamb_v’等内容,阅读transform原创 2021-07-01 17:48:53 · 693 阅读 · 0 评论 -
tensorflow之中的tf.shape()和get_shape()函数的区别
tensorflow之中的get_shape()函数好tf.shape()函数输出的形状有很大的区别这里我们以一个小例子来说明具体用法的不同input_ids = keras.layers.Input(shape=(None,),dtype='int32',name="token_ids")input_shape = input_ids.get_shape()print('input_shape1 = ')print(input_shape)maxlen = input_shape[1]pri原创 2021-07-01 10:39:53 · 805 阅读 · 0 评论 -
读取pytorch.bin权重文件解读
读取pytorch.bin的权重文件实现的函数在modeling_utils.py之中。 print('!!!load Pytorch model!!!') if state_dict is None: try: state_dict = torch.load(resolved_archive_file, map_location="cpu") except原创 2021-06-22 17:55:06 · 11961 阅读 · 1 评论 -
tensorflow keras crf实现
import tensorflow_addons as tfaimport tensorflow as tfimport numpy as npinputs=tf.random.truncated_normal([2,10,5])target=tf.convert_to_tensor(np.random.randint(5,size=(2,10)),dtype=tf.int32)out=tf.keras.layers.Softmax(inputs)lens=tf.convert_to_ten原创 2021-06-22 11:12:59 · 1810 阅读 · 4 评论 -
对于训练过程的数据分析
最近跑了一波bert模型,分析一下相应的训练过程以及自己的心得体会Epoch 1/10184/184 [==============================] - 91s 411ms/step - loss: 69.9343 - sparse_accuracy: 0.6796100%|██████████| 1970/1970 [03:19<00:00, 9.87it/s]准确率 = {1: 1.0, 2: 0.9789741956036955, 3: 0.9465433050原创 2021-06-18 09:09:55 · 1362 阅读 · 1 评论 -
Keras自定义Loss函数
Keras本身提供了很多常用的loss函数(即目标函数),但这些损失函数都是比较基本的、通用的。有时候我们需要根据自己所做的任务来自定义损失函数,虽然Keras是一个很高级的封装,自定义loss还是比较简单的。第一种方式:自定义函数进入keras/keras/losses.py文件中,我们可以看到很多keras自带loss的实现代码,比如最简单的均方误差损失函数def mean_squared_error(y_true,y_pred): return K.mean(K.square(y_pred-y原创 2021-05-31 19:12:37 · 2627 阅读 · 0 评论 -
tf.float32和tf.int32数据不能直接相乘问题解决
不能相乘的部分loss = K.sum(tf.matmul(loss,y_mask))/K.sum(y_mask))这里相乘的时候会产生报错,因为loss的类型为tf.float32类型,而y_mask的类型为tf.int32类型。所以这里此时在做乘法之前,需要将对应的类型进行转换一下:y_mask = tf.cast(y_mask,dtype=tf.float32)这里转换的部位需要注意,如果是在外面进行转换的话可能会发生报错问题常规的模型调用内容如下:batch_size = 5ma原创 2021-05-31 19:12:18 · 1546 阅读 · 0 评论 -
assertion failed:[Condition x==y did not hold element-wise解决
今天在写程序的时候,发现有相应的矩阵形状的不一致发生的报错,具体报错内容如下所示:从内容之中可以看出来,这个错误是由SparseSoftmaxCrossEntropyWithLogits函数引起的,由于调用的损失函数为keras.losses.SparseCategoricalCrossentropy(from_logits=True),所以想到进入损失函数keras.losses.SparseCategoricalCrossentropy的损失函数之中,去查看相应的交叉熵损失函数的输入和输出进入到sp原创 2021-05-31 15:53:37 · 2076 阅读 · 0 评论 -
tf.add不同形状矩阵的加法操作
tf.add进行不同形状的矩阵相加data1 = tf.ones((1,2,1))data2 = tf.ones((2,2,9))results = data1+data2这里相加的时候不会发生报错,因为不相等的两个维度第一个打头的维度1与2不相等的时候有一个数值1,最后一个维度的数值1与9不相等的时候有一个数值1,所以此时相加的时候不会发生报错。如果是进行以下的操作就会发生报错:data1 = tf.ones((1,2,2))data2 = tf.ones((2,2,9))results原创 2021-05-30 22:04:25 · 1238 阅读 · 0 评论 -
rnn实现递归操作讲解
rnn的原理如下图所示:之前运算的内容会传入下一个网络层之中,与下个网络层的数值进行相加,这里正好与CRF中的条件概率路线的概率和叠加类似,所以CRF之中的概率叠加正好可以调用rnn的原理。下面使用具体的例子说明rnn函数的调用过程:import numpy as npimport tensorflow.keras as kerasimport tensorflow.keras.backend as Kimport tensorflow as tfbatch_size = 1time_st原创 2021-05-30 12:28:45 · 209 阅读 · 5 评论 -
lstm内部设计有残差连接的影子
今天思考的过程中,突然发现lstm之中的内部结构有着残差连接的影子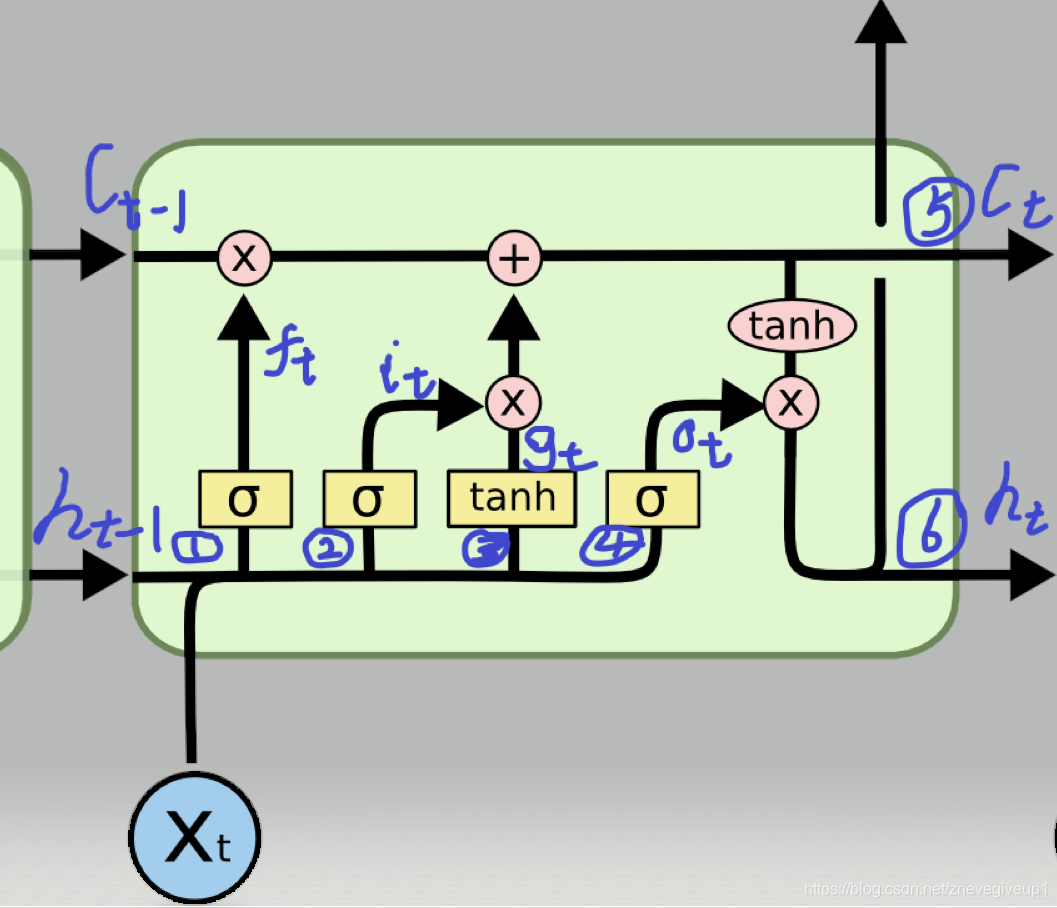...原创 2021-05-28 15:14:46 · 1039 阅读 · 0 评论 -
keras中的compute_mask函数讲解
keras中的mask操作1.使用背景最常见的一种情况, 在NLP问题的句子补全方法中, 按照一定的长度, 对句子进行填补和截取操作. 一般使用keras.preprocessing.sequence包中的pad_sequences方法, 在句子前面或者后面补0. 但是这些零是我们不需要的, 只是为了组成可以计算的结构才填补的. 因此计算过程中, 我们希望用mask的思想, 在计算中, 屏蔽这些填补0值得作用. keras中提供了mask相关的操作方法.2.原理在keras中, Tensor在各层之转载 2021-03-08 22:51:54 · 1661 阅读 · 0 评论 -
不需要在白天跑模型的策略
最终迭代的次数比较多,经常需要在白天跑模型,这严重地影响了我的学习效率,为此我想出来了一招不需要在白天跑模型的思路,能够在晚上进行跑模型,以方便白天学习的过程。每次跑模型之前首先取出之前的权重内容,然后训练一个epoch之后保存相应的权重内容model.load_weights('./folder/best_model.weights')#加载对应的权重model.fit( train_generator.cycle(), steps_per_epoch=len(train_generator)原创 2021-05-25 08:54:18 · 154 阅读 · 0 评论 -
测试的时候遇上难以处理的数据的处理方式
测试的时候,如果中间遇上难以处理的数据,可以在中间及时地插入相应的特殊数据在进行预测比如之前处理的过程中,生成数据有终止符号的时候需要单独处理。(终止符号为标志3)此时需要插入特殊的对应数组值output_ids = np.array([[3],[5],[2]])...原创 2021-05-24 21:54:06 · 124 阅读 · 0 评论 -
学习率不同导致损失值不同的问题以及不同的epoch过程中损失值的变化
今天写程序发现学习率不同导致训练中的损失值有着明显的差异,在我使用learning_rate = 0.001的时候,损失值上来为5…,而当我使用learning_rate = 0.00001的时候,损失值上来就为8.3309e-04,所以损失值会影响刚开始的学习率???...原创 2021-05-24 10:10:50 · 1584 阅读 · 0 评论 -
跑模型一次训练很长时间如何用加载权重的方法有效解决
跑模型每次一跑一晚上只能跑出10个epoch的值,但是这里我们训练的过程中想要训练50个epoch的数据,该如何解决呢?可以采用每次训练的过程中存储相应的训练权重的方式,一次训练10个epoch的值,在训练的过程中,如果有对应的权重文件,则直接加载相应的权重,没有权重文件的情况下再从头开始进行训练。...原创 2021-05-20 09:06:32 · 1542 阅读 · 0 评论 -
sparse_categorical_crossentropy和categorical_crossentropy()损失函数比较
最近在使用sparse_categorical_crossentropy函数的时候,对其中的输入输出内容不是特别的理解,首先我们看一下交叉熵损失函数的定义H(p,q)=H(p(x))+Dkl(p∣∣q)=−∑i=1np(xi)ln(p(xi))+∑i=1np(xi)ln(p(xi)q(xi))H(p,q) = H(p(x))+D_{kl}(p||q) = -\sum_{i=1}^{n}p(x_{i})ln(p(x_{i}))+\sum_{i=1}^{n}p(x_{i})ln(\frac{p(x_{i})原创 2021-05-17 16:46:30 · 3021 阅读 · 0 评论 -
训练之中发生OOM的解决问题办法
训练中发生OOM很有可能是一个批次对应的数据过长,导致一次GPU不能够完全地容纳地下比如如下的情况:for token_ids,segment_ids in tqdm(self.sample(random)):#传入的数据在下面定义train_generator = data_generator(train_data, batch_size) batch_token_ids.append(token_ids) batch_segment_ids.append(segment_ids)原创 2021-05-17 10:35:13 · 767 阅读 · 0 评论 -
tensorflow训练时报错:Gradients do not exist for variables问题解决
今天在使用tensorflow内容的时候,发现训练的过程之中出现相应的报错WARNING:tensorflow:Gradients do not exist for variables ['bert/transformer_0/attention/query/kernel:0', 'bert/transformer_0/attention/query/bias:0', 'bert/transformer_0/attention/key/kernel:0', 'bert/transformer_0/atte原创 2021-05-15 19:52:38 · 6015 阅读 · 0 评论 -
查看python函数源代码的内容
这里面我们想要查看model.fit( train_generator.forfit(), steps_per_epoch=len(train_generator), epochs=epochs, callbacks=[evaluator])源代码使用的状况,使用命令help(model.fit)可以查看到如下的情况可以看出,这里显示的是Help on method fit in module keras.engine.training:这样就能够成功地原创 2021-05-14 22:36:53 · 404 阅读 · 0 评论 -
CNN的BP算法推导过程
介绍CNN的BP算法之前还是先看下DNN,两者有很多相似的地方DNN的BP算法1.第i层神经元的输出ala^lal2.第i层神经元的输入zlz^lzl3.从第l-1层mapping到l层的权值矩阵WlW^lWl4.与上面参数对应的偏移量blb^lbl5.train data的输入xxx6.train data的输出yyy7.设我们的输出层为第l层,对应aLa^LaL,采用均方差来度量误差,对应的损失函数为J(W,b,x,y)=12∣∣aL−y∣∣22(1)J(W,b,x,y) = \frac原创 2020-10-06 18:56:21 · 897 阅读 · 0 评论 -
交叉熵函数理解
交叉上函数的对应公式L=−[ylog y^+(1−y)log (1−y^)]L=-[ylog\ \hat y+(1-y)log\ (1-\hat y)]L=−[ylog y^+(1−y)log (1−y^)]1.交叉熵损失函数的数学原理在二分类问题模型:例如逻辑回归「Logistic Regression」、神经网络「Neural Network」等,真实样本的标签为 [0,1],分别表示负类和正类。模型的最后通常会经过一个 Sigmoid 函数,输出一个概原创 2021-05-14 12:02:32 · 448 阅读 · 0 评论 -
required broadcastable shapes at loc(unknown)
最近在运行程序的时候,发现一个这样的报错内容required broadcastable shapes at loc(unknown)[Op:AddV2]经过对于代码的检查发现,这里是由于tensor对应的形状不同而导致的发生错误的语句:attention_scores = attention_scores+bias_data这里的attention_scores = (5,12,128,128),bias_data = (5,128,128),两个维度相应的有差距,所以在相加的时候会发生报错原创 2021-05-14 11:38:25 · 7737 阅读 · 0 评论 -
seq2seq bert模型训练以及预测过程讲解
最近学习了seq2seq模型的内容,发现seq2seq模型实际上训练过程和输出过程是一个分离的过程,这里我们采用解决小学生数学问题的数据例子作为一个示例,来详细地讲解seq2seq通过小学生数学问题的句子去预测对应的数学公式的过程。具体的数据比如数据为(‘小王要将150千克含药量20%的农药稀释成含药量5%的药水,需要加水多少千克?’)对应的equation = “x=150*20%/5%-150”,结果ans = 450。这里输入的过程将输入和输出的公式结合起来:[CLS]+'小王要将150千克原创 2021-05-13 15:44:54 · 2380 阅读 · 0 评论 -
tf.matmul和tf.multiply的区别
1.tf.multiply()两个矩阵中对应元素各自相乘此时这两个对应矩阵形状必须一样,比如a = (None,128),b = (None,128),则a*b = (None,128),相当于乘号[1,2]∗[1,2]=[1,4][1,2]*[1,2] = [1,4][1,2]∗[1,2]=[1,4]2.tf.matmul()将矩阵a乘以矩阵btf.matmul()相当于正常的矩阵乘法,tf.matmul(a,b)[1,2][1 2] = 5...原创 2021-05-13 11:24:34 · 128 阅读 · 0 评论 -
使用tf.print输出矩阵传输中间过程的值
在model.fit()的模型训练过程之中,如果使用print()输出对应的矩阵内容,只能输出相应矩阵的形状,如果想要在model.fit()过程中输出矩阵具体的值,必须使用tf.print()函数进行打印使用了tf.print()之后...原创 2021-05-13 10:21:56 · 357 阅读 · 0 评论 -
Layer attention expects 1 input(s),but it received 2 input tensors.错误解决
最终在写代码的过程中,发现程序之中出现报错:ValueError: Layer attention expects 1 input(s), but it received 2 input tensors. Inputs received: [<tf.Tensor 'model/bert/embeddings/dropout/dropout/Mul_1:0' shape=(None, 128, 768) dtype=float32>, <tf.Tensor 'model/Cast_1:0'原创 2021-05-13 08:36:32 · 5319 阅读 · 1 评论