







作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、腾讯课堂常驻讲师
主要内容:Java项目、Python项目、前端项目、人工智能与大数据、简历模板、学习资料、面试题库、技术互助
收藏点赞不迷路 关注作者有好处
文末获取源码
项目编号:L-BS-PY-02
一,项目简介
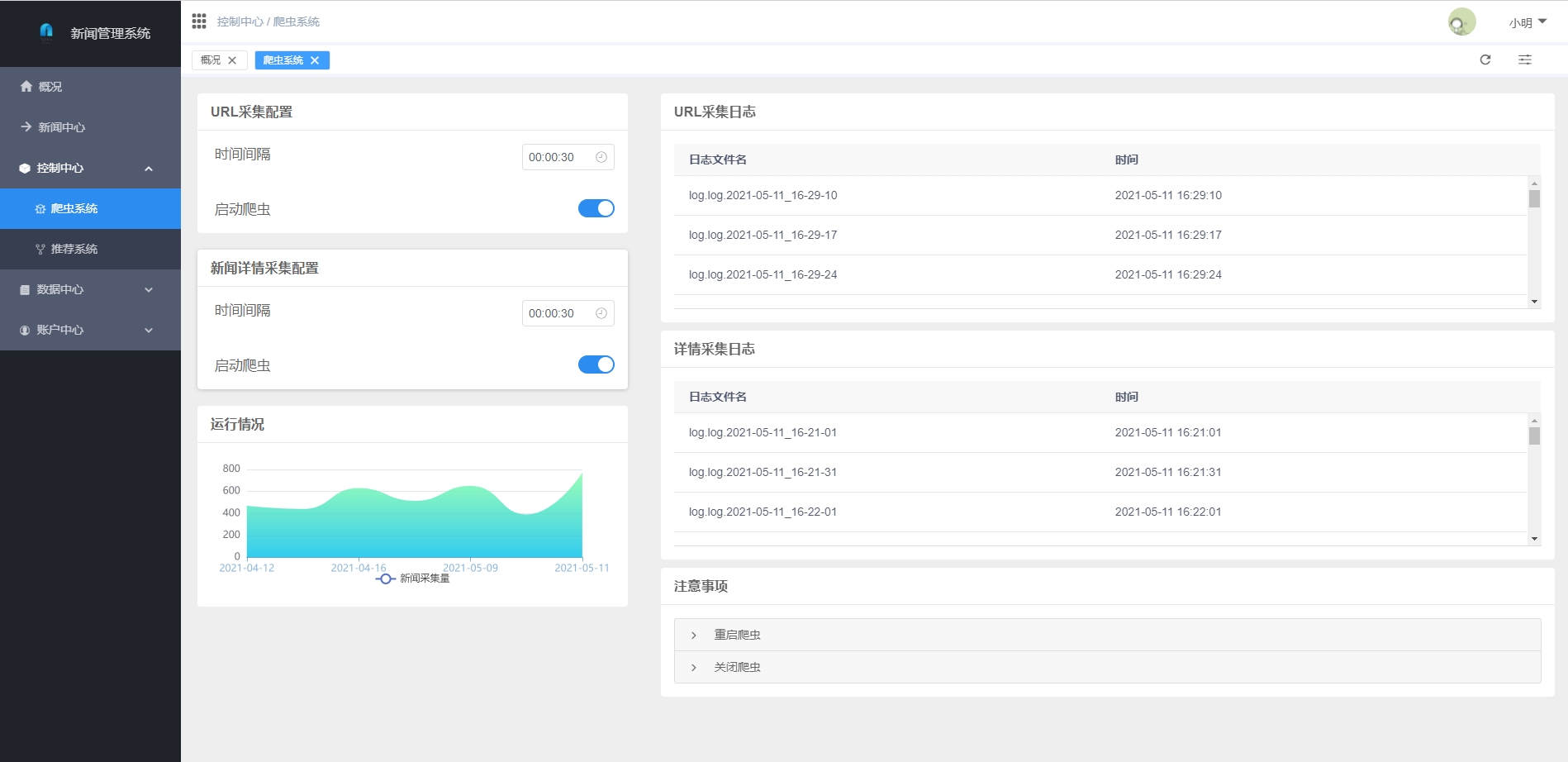
网络爬虫:通过Python实现新浪新闻的爬取,可爬取新闻页面上的标题、文本、图片、视频链接(保留排版) 推荐算法:权重衰减+标签推荐+区域推荐+热点推荐
- 权重衰减进行用户兴趣标签权重的衰减,避免内容推荐的过度重复
- 标签推荐进行用户标签与新闻标签的匹配,按照匹配比例进行新闻的推荐
- 区域推荐进行IP区域确定,匹配区域性文章进行推荐
- 热点推荐进行新闻热点的计算的依据是新闻阅读量、新闻评论量、新闻发布时间
涉及框架:Django、jieba、selenium、BeautifulSoup、vue.js
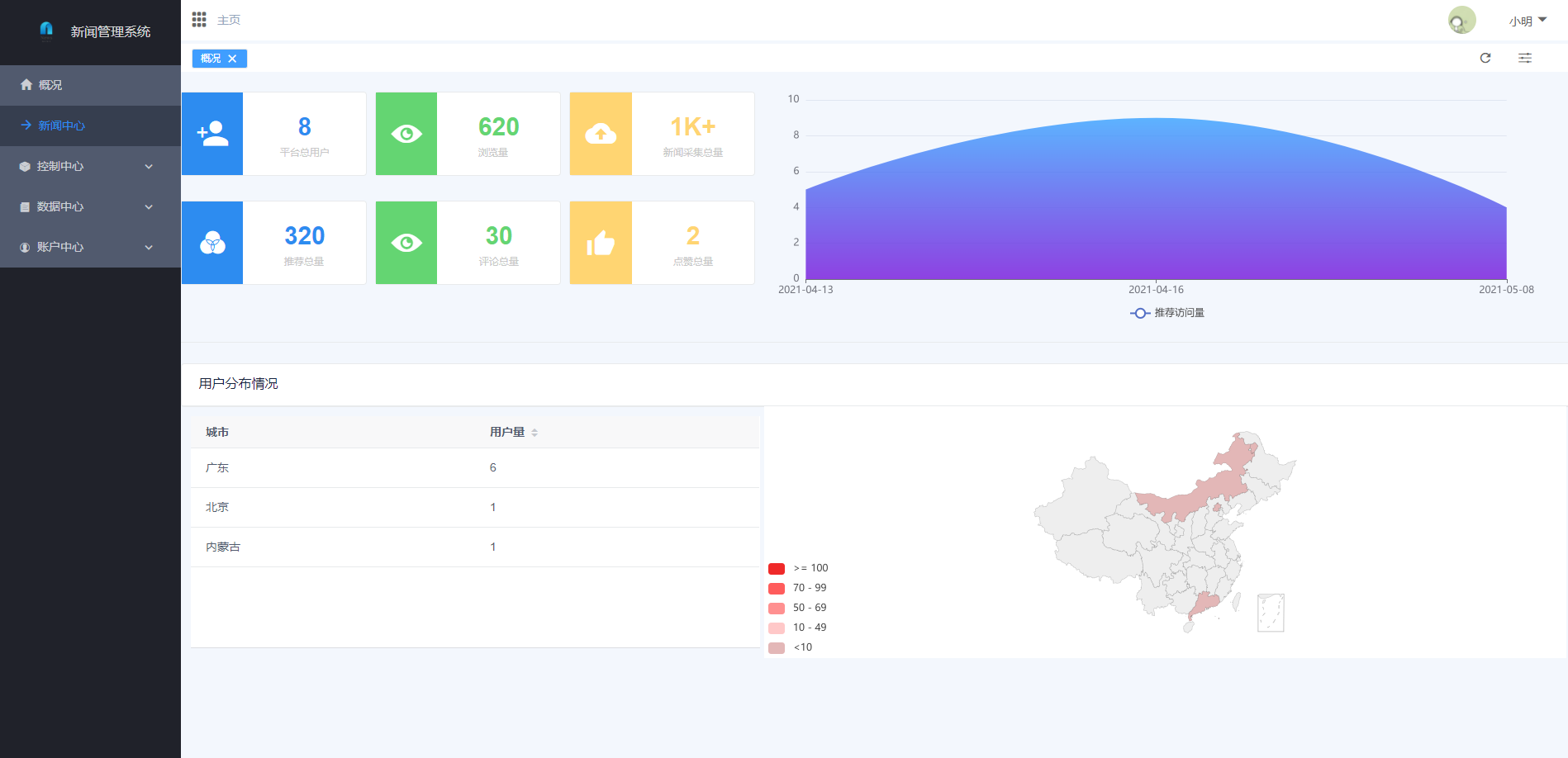
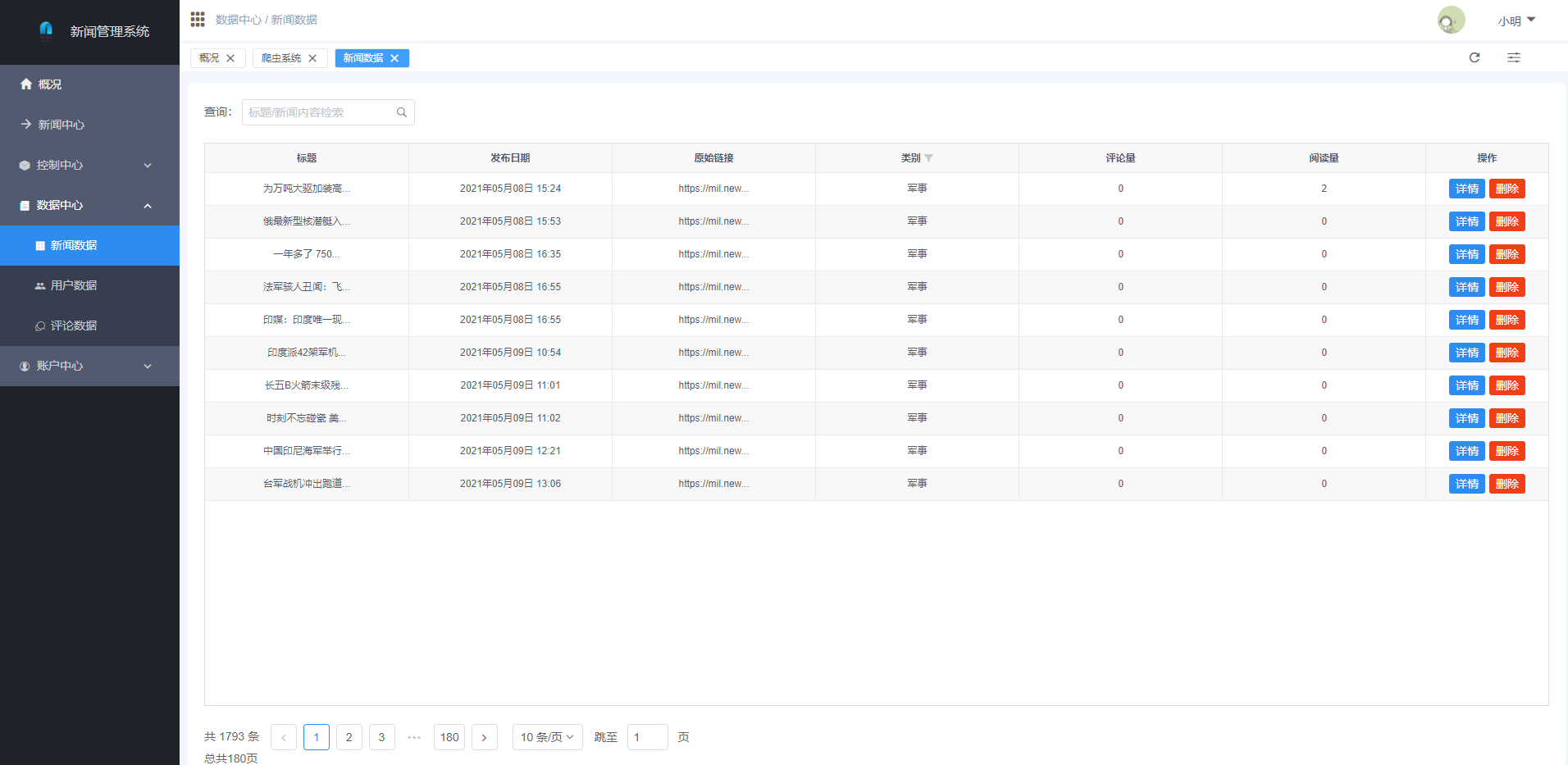
二,系统展示
2.1 软件功能结构

2.2 页面展示
用户端

管理端
三,核心代码展示
3.1 获取所有的新闻列表
import datetime
import json
import time
from django.core import serializers
from django.db.models import Q
from django.http import JsonResponse
from news_api.models import newsdetail, recommend, newshot, newssimilar, history, comments, user, givelike, message
def all_news(request):
'''
@Description:获取所有新闻
@:param None
'''
if request.method == "GET":
newslist = serializers.serialize("json", newsdetail.objects.all().order_by('-news_id'))
response = JsonResponse({"status": 100, "newslist": newslist})
response["Access-Control-Allow-Origin"] = "*"
response["Access-Control-Allow-Credentials"] = "true"
response["Access-Control-Allow-Methods"] = "GET,POST"
response["Access-Control-Allow-Headers"] = "Origin,Content-Type,Cookie,Accept,Token"
response["Cache-Control"] = "no-cache"
return response
def del_news(request):
'''
@Description:删除指定新闻
@:param url---指定新闻url
'''
if request.method == "GET":
url = request.GET.get('url')
# print(user.objects.filter(userid=userid).delete()[0])
if newsdetail.objects.filter(url=url).delete()[0] == 0:
return JsonResponse({"status": "100", "message": "Fail."})
else:
return JsonResponse({"status": "100", "message": "Success."})
def reconewsbytags(request):
'''
@Description:推送用户推荐新闻集
@:param userid---用户id
'''
if request.method == "GET":
userid = request.GET.get('userid')
newsidlist = recommend.objects.filter(userid=userid, headread=0)
newsdetaillist = list()
for news in newsidlist:
newsdetaillist.append(serializers.serialize("json", newsdetail.objects.filter(news_id=news.newsid)))
response = JsonResponse({"status": 100, "newsidlist": newsdetaillist})
return response
def reconewsbysimilar(request):
'''
@Description:推送相似新闻集
@:param
'''
if request.method == "GET":
newsid = request.GET.get('newsid')
newsidlist = newssimilar.objects.filter(new_id_base=newsid).order_by('-new_correlation')[:5]
newsdetaillist = list()
for news in newsidlist:
detail = newsdetail.objects.filter(news_id=news.new_id_sim)
data = {
'newsid': detail[0].news_id,
'title': detail[0].title,
'pic_url': detail[0].pic_url,
'mainpage': detail[0].mainpage,
}
newsdetaillist.append(data)
# newsdetaillist.append(serializers.serialize("json", newsdetail.objects.filter(news_id=news.new_id_sim)))
response = JsonResponse({"status": 100, "newslist": newsdetaillist})
return response
def typenews(request):
'''
@Description:推送各类别新闻集
@:param typeid---类别id
'''
if request.method == "GET":
typeid = request.GET.get('type')
newsidlist = newshot.objects.filter(category=typeid).order_by('-news_hot')
newsdetaillist = list()
for news in newsidlist:
newsdetaillist.append(serializers.serialize("json", newsdetail.objects.filter(news_id=news.news_id)))
response = JsonResponse({"status": 100, "newslist": newsdetaillist})
return response
def reconewsbyregion(request):
'''
@Description:通过ip地址进行地域关键词推荐
@:param
@:param
'''
if request.method == "GET":
userid = request.GET.get('userid')
user = userid.objects.filter(userid=userid)
ip = user.ip
def getpicture(request):
'''
@Description:获取热度较高的四个新闻的图片以及Newsid
'''
if request.method == "GET":
newshotlist = newshot.objects.all().order_by('-news_hot')[:10]
pictlist = list()
for news in newshotlist:
temp = newsdetail.objects.filter(news_id=news.news_id).exclude(pic_url='[]')
if len(temp) > 0:
url = temp[0].pic_url
newid = temp[0].news_id
title = temp[0].title
pictlist.append({'newsid': newid, 'pic_url': eval(url)[0], 'title': title})
return JsonResponse({"status": "100", "message": pictlist})
def getNewsDetailByNewsid(request):
'''
@Description:通过newsid获取新闻详情
@:param newsid ----> 新闻id
'''
if request.method == "GET":
newsid = request.GET.get('newsid')
userid = request.GET.get('userid')
news = newsdetail.objects.filter(news_id=newsid)[0]
newsdetail.objects.filter(news_id=newsid).update(readnum=(int(news.readnum) + 1))
if int(userid) != 100000:
users = user.objects.filter(userid=userid)[0]
usertags = users.tags
usertags = set(usertags.split(','))
if news.keywords != None:
newskeywords = set(news.keywords.split(','))
else:
newskeywords = set()
# key = usertags & newskeywords
# key = list(key)
weight = eval(users.tagsweight)
for keyword in newskeywords:
if keyword in weight:
weight[keyword] = float(format(weight[keyword] + 0.01, ".3f"))
if weight[keyword] >= 0.1:
usertags.add(keyword)
user.objects.filter(userid=userid).update(tags=str(",".join(usertags)))
else:
weight[keyword] = 0.01
print(weight)
user.objects.filter(userid=userid).update(tagsweight=str(weight).replace("\'", "\""))
# if len(key) > 0:
# weight = eval(users.tagsweight)
# weight[key[0]] = weight.get(key[0]) + 0.01
# print(weight)
# user.objects.filter(userid=userid).update(tagsweight=str(weight).replace("\'", "\""))
temp = givelike.objects.filter(newsid=newsid, userid=userid)
print(len(temp))
if len(temp) == 0:
liking = 0
else:
liking = temp[0].givelikeornot
newsdetails = {
"newsid": news.news_id,
"title": news.title,
"date": news.date,
"pic_url": news.pic_url,
"videourl": news.videourl,
"category": news.category,
"readnum": int(news.readnum) + 1,
"comments": news.comments,
"origin": news.origin,
"givelike": liking,
}
return JsonResponse({"status": "100", "message": newsdetails})
def all_news_to_page(request):
'''
@Description:获取所有新闻
@:param None
'''
if request.method == "GET":
newslist = serializers.serialize("json", newsdetail.objects.all().order_by('-news_id')[0:100])
response = JsonResponse({"status": 100, "newslist": newslist})
response["Access-Control-Allow-Origin"] = "*"
response["Access-Control-Allow-Credentials"] = "true"
response["Access-Control-Allow-Methods"] = "GET,POST"
response["Access-Control-Allow-Headers"] = "Origin,Content-Type,Cookie,Accept,Token"
response["Cache-Control"] = "no-cache"
return response
def newsHistory(request):
'''
@Description:更新用户阅读记录
@:param userid ---> 用户id
@:param newsid ---> 新闻id
'''
if request.method == "GET":
userid = request.GET.get('userid')
newsid = request.GET.get('newsid')
daytime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
history.objects.create(userid=userid, history_newsid=newsid, time=daytime)
return JsonResponse({"status": "200"})
def newsHotRec(request):
'''
@Description:获取热点新闻推荐
@:param userid ---> 用户id
@:param newsid ---> 新闻id
'''
if request.method == "GET":
hotnewsidlist = newshot.objects.all().order_by('-news_hot')[:5]
newsdetaillist = list()
for hotnews in hotnewsidlist:
detail = newsdetail.objects.filter(news_id=hotnews.news_id)[0]
data = {
'newsid': detail.news_id,
'mainpage': detail.mainpage,
'title': detail.title,
'pic_url': detail.pic_url,
}
newsdetaillist.append(data)
# hotnews.news_id
return JsonResponse({"status": "200", 'newslist': newsdetaillist})
def getComments(request):
'''
@Description:获取新闻评论列表
@:param newsid ---> 新闻id
'''
if request.method == "GET":
newsid = request.GET.get('newsid')
commentlistdata = comments.objects.filter(newsid=newsid, status="正常")
commentlist = list()
for comment in commentlistdata:
# comment = commentlistdata[commentid]
# print(commentid)
User = user.objects.filter(userid=comment.userid)[0]
userheadPortrait = User.headPortrait
userName = User.username
touser = user.objects.filter(userid=comment.touserid)
ToUser = None
if len(touser) != 0:
ToUser = touser[0]
if ToUser != None:
toUserHeadPortrait = ToUser.headPortrait
toUserName = ToUser.username
else:
toUserHeadPortrait = None
toUserName = None
data = {
'userid': comment.userid,
'touserid': comment.touserid,
'comments': comment.comments,
'time': comment.time,
'username': userName,
'userheadPortrait': userheadPortrait,
'tousername': toUserName,
'toUserHeadPortrait': toUserHeadPortrait,
}
commentlist.append(data)
return JsonResponse({"status": "200", 'commentlist': commentlist})
def gethotnews(request):
'''
@Description:获取热点新闻排行
'''
if request.method == "GET":
newsidlist = newshot.objects.all().order_by('-news_hot')[0:50
]
newslist = list()
for news in newsidlist:
detail = newsdetail.objects.filter(news_id=news.news_id)
data = {
"newsid": detail[0].news_id,
"title": detail[0].title,
"date": detail[0].date,
"pic_url": detail[0].pic_url,
"mainpage": detail[0].mainpage,
"category": detail[0].category,
"readnum": detail[0].readnum,
"comments": detail[0].comments,
"hotvalue": news.news_hot,
}
newslist.append(data)
return JsonResponse({"status": "200", 'newslist': newslist})
def updateGiveLike(request):
'''
@Description:更新点赞/点踩状态
@:param newsid --> 新闻ID
@:param userid --> 用户ID
@:param like --> 点击状态 0/1/2
'''
if request.method == "GET":
newsid = request.GET.get('newsid')
userid = request.GET.get('userid')
like = request.GET.get('like')
if int(like) == 1:
if int(userid) != 100000:
users = user.objects.filter(userid=userid)[0]
usertags = users.tags
news = newsdetail.objects.filter(news_id=newsid)[0]
usertags = set(usertags.split(','))
if news.keywords != None:
newskeywords = set(news.keywords.split(','))
else:
newskeywords = set()
key = usertags & newskeywords
key = list(key)
if len(key) > 0:
weight = eval(users.tagsweight)
weight[key[0]] = weight.get(key[0]) + 0.01
user.objects.filter(userid=userid).update(tagsweight=str(weight).replace("\'", "\""))
if int(like) == 2:
if int(userid) != 100000:
users = user.objects.filter(userid=userid)[0]
usertags = users.tags
news = newsdetail.objects.filter(news_id=newsid)[0]
usertags = set(usertags.split(','))
if news.keywords != None:
newskeywords = set(news.keywords.split(','))
else:
newskeywords = set()
for k in newskeywords:
weight = eval(users.tagsweight)
if k in weight:
if weight[k] >= 0.1:
weight[k] = float(format(weight.get(k) - 0.1, ".3f"))
if weight.get(k) > 0:
user.objects.filter(userid=userid).update(tagsweight=str(weight).replace("\'", "\""))
else:
weight.pop(k)
print('weight', weight)
user.objects.filter(userid=userid).update(tagsweight=str(weight).replace("\'", "\""))
usertags.remove(k)
newusertags = ','.join(usertags)
user.objects.filter(userid=userid).update(tags=newusertags)
selectres = givelike.objects.filter(userid=userid, newsid=newsid)
if len(selectres) == 0:
givelike(userid=userid, newsid=newsid, givelikeornot=like).save()
else:
selectres.update(userid=userid, newsid=newsid, givelikeornot=like)
return JsonResponse({"status": "200", 'message': 'Success.'})
else:
return JsonResponse({"status": "200", 'message': 'Fail.'})
def submitComments(request):
'''
@Description:提交新闻评论
@:param userid --> 提交用户ID
@:param newsid --> 新闻ID
@:param comment --> 评论内容
'''
if request.method == "POST":
req = json.loads(request.body)
print(req)
userid = req['userid']
newsid = req['newsid']
comment = req['comment']
# print('comment', comment)
if int(userid) != 100000:
print()
users = user.objects.filter(userid=userid)[0]
usertags = users.tags
news = newsdetail.objects.filter(news_id=newsid)[0]
usertags = set(usertags.split(','))
if news.keywords != None:
newskeywords = set(news.keywords.split(','))
else:
newskeywords = set()
key = usertags & newskeywords
key = list(key)
if len(key) > 0:
weight = eval(users.tagsweight)
weight[key[0]] = weight.get(key[0]) + 0.01
print(weight)
user.objects.filter(userid=userid).update(tagsweight=str(weight).replace("\'", "\""))
time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
comments(userid=userid, newsid=newsid, comments=comment, time=time, status="正常").save()
newsdetail.objects.filter(news_id=newsid).update(
comments=int(newsdetail.objects.filter(news_id=newsid)[0].comments) + 1)
return JsonResponse({"status": "200", 'message': 'Success.'})
def submitCommenttoUser(request):
'''
@Description:对用户评论进行回复
@:param userid --> 评论用户ID
@:param newsid --> 新闻ID
@:param comment --> 评论内容
@:param touserid --> 被回复用户ID
'''
if request.method == "POST":
req = json.loads(request.body)
print(req)
userid = req['userid']
newsid = req['newsid']
comment = req['comment']
touserid = req['touserid']
if int(userid) != 100000:
print()
users = user.objects.filter(userid=userid)[0]
usertags = users.tags
news = newsdetail.objects.filter(news_id=newsid)[0]
usertags = set(usertags.split(','))
if news.keywords != None:
newskeywords = set(news.keywords.split(','))
else:
newskeywords = set()
key = usertags & newskeywords
key = list(key)
if len(key) > 0:
weight = eval(users.tagsweight)
weight[key[0]] = weight.get(key[0]) + 0.01
print(weight)
user.objects.filter(userid=userid).update(tagsweight=str(weight).replace("\'", "\""))
time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
sendMessage = "新的回复了!!请速速查看!!"
comments(userid=userid, newsid=newsid, comments=comment, time=time, touserid=touserid, status="正常").save()
message(userid=touserid, message=sendMessage, time=time, newsid=newsid, title="收到回复", hadread=0).save()
return JsonResponse({"status": "200", 'message': 'Success.'})
def getManageHomeData(request):
'''
@Description:获取管理端主页数据
@:param None
'''
if request.method == "GET":
readnum = len(history.objects.all())
userlist = user.objects.all()
usernum = len(userlist)
newsnum = len(newsdetail.objects.all())
regionlist = dict()
for us in userlist:
if regionlist.get(us.region) == None:
regionlist[us.region] = 1
else:
regionlist[us.region] = regionlist[us.region] + 1
reclist = recommend.objects.filter(hadread=1)
recnum = len(recommend.objects.all())
statistical = dict()
for rec in reclist:
if statistical.get(rec.time) == None:
statistical[rec.time] = 1
else:
statistical[rec.time] = statistical[rec.time] + 1
comnum = len(comments.objects.all())
likenum = len(givelike.objects.filter(givelikeornot=1))
data = {
'usernum': usernum,
'readnum': readnum,
'newsnum': newsnum,
'recnum': recnum,
'comnum': comnum,
'statistical': statistical,
'likenum': likenum,
'regionlist': regionlist,
}
return JsonResponse({"status": "200", 'message': data})
def updateRecHis(request):
'''
@Description:更新推荐列表阅读历史/更改推荐新闻已读状态
@:param userid --> 用户ID
@:param newsid --> 新闻ID
'''
if request.method == "GET":
userid = request.GET.get('userid')
newsid = request.GET.get('newsid')
recommend.objects.filter(newsid=newsid, userid=userid).update(hadread=1)
return JsonResponse({"status": "200", 'message': 'Success.'})
return JsonResponse({"status": "200", 'message': 'Fail.'})
def searchNews(request):
'''
@Description:管理端搜索新闻(模糊搜索)
@:param keyword --> 搜索关键词
'''
if request.method == "GET":
keyword = request.GET.get('keyword')
newslist = newsdetail.objects.filter(Q(title__contains=keyword) | Q(mainpage__contains=keyword))
response = JsonResponse({"status": 100, "newslist": serializers.serialize("json", newslist)})
return response
四,相关作品展示
基于Java开发、Python开发、PHP开发、C#开发等相关语言开发的实战项目
基于Nodejs、Vue等前端技术开发的前端实战项目
基于微信小程序和安卓APP应用开发的相关作品
基于51单片机等嵌入式物联网开发应用
基于各类算法实现的AI智能应用
基于大数据实现的各类数据管理和推荐系统
























 1794
1794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











