







最近在部门内部做了一个关于log机制的知识分享,深入的探讨了log机制中各种概念的来源、常用log库的用法、内部处理流程,以及如何在一个涉及多台主机的复杂系统中部署log等问题。本文是对这次分享的总结,将对这些问题一一展开介绍。
目录
开场
log如今已经成为了我们日常开发时所必不可少的工具,它同debug一起构成了开发者手中分析问题最有力的两个武器。两者各有优劣,相辅相成,配合起来使用将变得无往不利。通常相比于debug来说,log在很大程度上可以更方便、更迅速的让开发者分析程序的问题,尤其是对于非常庞大的系统、或者已经发布的程序,又或者一些非必现的问题,当我们无法方便的debug问题程序时,log文件可以提供非常多有用的信息,如果开发者log写得比较合适,大多数情况下根据log就可以分析出问题所在。因此,log分析法深受开发者的喜爱。
记得初学编程,第一次听到这样一个观点时那种难以接受心情,怎么可能还有比debug更加容易分析程序问题的方法?好一个无知无畏!当然这一切都是源于当时写的程序规模都比较小,非常适合debug的缘故吧。而实际上当时在不知不觉中已经或多或少使用了简单的log,那一条条控制台的cout与printf就是最好的证明。后来随着程序规模越来越大,才明白debug的局限性,逐渐的喜欢上了log。
勿在浮沙筑高台
现如今对于每一种开发语言都有非常多的库来帮我们处理log,比如:log4j(log for Java),log4cpp(log for C++),log4net(log for .NET)等等。最早处理log的库是Log4j,它是Apache为Java发布的一个开源log库,后来基于这个库衍生了很多具有相似API的库。我们这里介绍的库是基于log4cpp发展而来。
后面就用log4me作为我们使用的库的名称
让我们先从无到有,从一个个简单的使用场景一步一步分析log库中各种概念如何发展而来。当然,我没有去真正追究它的历史,只是从个人需求角度分析得来。
最简单的log
代码中经常会需要打印一些提示信息用于显示程序工作流程,或者反馈错误信息,这就是所谓的log,就像船员的航海日志一样,我想log也是由此得名吧。为了输出这些信息,在C/C++中最简单的方法是用printf或者std::cout:
1 // I want to print a log:
2 printf("I'm a message\n");增加有用信息
我们本可在每处需要打印log信息时都采用这种方式,但不妨先停下来试想一下,如果在一个log文件中你看到满屏幕的这种信息,但是却无法知道是谁,在什么时候,什么位置输出这条信息,那这种log的价值便大大折扣。于是,你会需要在每条log中增加一些额外有用的信息:
1 // I want to add more information:
2 printf("%s %s %d: I'm a message\n", time, __FILE__, __LINE__);这样,每条log就有了时间,文件和行号这些额外有用的信息,非常有利于分析问题。
简化调用:封装
但是,这样会不会太麻烦?每次在写代码时,打印一条简单的log你需要加这么多无关的内容,万一忘了怎么办,这简直无法接受。你想要把所有的注意力都放在log本身上,不想关注其它的细技末节,怎么办?注意看,上面的函数调用中,后三个参数都是固定的,于是你可以对它进行这样简单的封装:
1 // Too complicated:
2 #define printf0(message) \
3 printf("%s %s %d %s", time, __FILE__, __LINE__, message);
4
5 printf0("I'm a message\n");注:这里用宏而不采用函数,正如评价中@weitang指出的,如果是函数的话,__LINE__的值会一直是函数中的行号,是一个固定值,而不是调用处的行号。另外,这个版本的宏只支持一个参数,后面调用它的其它函数中传了可能不止一个参数,是为了演示方便。各位有兴趣的话可以自行写出合适的printf0版本。
还是一样简单的调用,不需要你再去输入一些无关的内容,因为这个封装的函数已经替你做好了。
设定等级:TraceLevel
log信息并不是千篇一律只起一种作用,有的是纪录程序的流程,有的是错误信息,还有一些是警告信息。为了让log更有可读性,你可能想要把不同的信息区分开来,比如这样:
1 // I want to distinguish different kinds of message:
2 printf0("Normal: I'm a normal message\n");
3 printf0("Warning: I'm a warning message\n");
4 printf0("Error: I'm an error message\n");那么,你就可以通过在log文件中搜索Normal、Warning或者Error这些关键字就能够找到特定的log。这对于排错帮助非常大,比如你只需要搜索Error关键字就能够得出程序的出错信息。
但是,这些Normal、Warning以及Error关键字需要你每次都加在要输出的字符串中,同前面一样,你还是只想关注log本身,不愿意log和其它的信息混在一起。于是可以这样做:
1 // It's too complicated, I want something like this:
2 enum TraceLevel {
3 Normal,
4 Warning,
5 Error
6 };
7 void printf1(TraceLevel level, const char *message) {
8 char *levelString[] = {
9 "Normal: ",
10 "Warning: ",
11 "Error: "
12 }
13 printf0("%s %s", message, levelString[level]);
14 }
15 printf1(Normal, "I'm a normal message\n");
16 printf1(Warning, "I'm a warning message\n");
17 printf1(Error, "I'm an error message\n"); 现在你只需要指定一种log类型,就可以全心全意的处理log信息本身了。我们把上面的Normal, Warning和Error叫做TraceLevel,故名思义,它表示log的等级。
可以进一步简化:
1 // To be more convenient:
2 void printf_out(const char *message) {
3 printf1(Normal, message);
4 }
5 void printf_warn(const char *message) {
6 printf1(Warning, message);
7 }
8 void printf_error(const char *message) {
9 printf1(Error, message);
10 }
11 printf_out("I'm a normal message\n");
12 printf_warn("I'm a warning message\n");
13 printf_error("I'm an error message\n");如此一来,对于特定等级的log只需调用各自的log输出函数即可,除此之外,注意力全部放在log信息本身上。
在代码中,通常最多的log是Normal类型,即显示程序流程。有时你可能只想log文件中存储Warning和Error类型的信息,Normal对你来相当于干扰信息,而且log文件也会因此变得很大。有时你又会想让log中包含所有类型。如何协调?如果可以动态的选择哪些等级的信息输出,那岂不是log文件就变得像是根据我的需求定制一般,可以随意控制log包含哪些级别的信息么?
根据这一思路,代码可以这样改变:
1 // I want to add a control which level should be printed:
2 TraceLevel getLevel1();
3 void printf2(TraceLevel level, const char *message) {
4 if (level >= getLevel1())
5 printf1(level, message);
6 }
7 printf2(Normal, "I'm a normal message\n");
8 printf2(Warning, "I'm a warning message\n");
9 printf2(Error, "I'm an error message\n");这里暂时没有采用前面简化的方法。
getLevel1()从配置文件中读取当前允许的Level,代码中只有高于当前Level的log才会被输出,现在log文件便可以随着你的需要而定制了。
多一些控制:Marker
再来考虑这样一种情况,如果你的文件非常大,中间要输出的Normal log非常多,分为不同层次,比如:粗略的流程,详细一些的,十分详细的。和很多命令的-verbose参数一样。由于都是Normal类型的log,所以不能够用前面的TraceLevel,这时需要引入另外一层控制:
1 // My class is too big, I want a filter to determine which
2 // logs should be generated
3 const int SUB = 0;
4 const int TRACE_1 = 1 << 0;
5 const int TRACE_2 = 1 << 1;
6 const int TRACE_3 = 1 << 2;
7 int getMarker1();
8 void printf3(int marker, TraceLevel level, const char *message) {
9 if (marker == 0 || marker & getMarker1() != 0)
10 printf2(level, message);
11 }
12 printf3(SUB, Normal, "I'm a normal message\n");
13 printf3(TRACE_1, Normal, "I'm a normal message\n");
14 printf3(TRACE_2, Normal, "I'm a normal message\n"); 这里提供了四级的控制,和前面的TraceLevel一样,它也可以通过配置文件配置。假设现在配置的是TRACE_1,那么代码中想要输出的三条信息中,只有前两条能够输出。这层控制我们称之为Marker。
注意到这里定义的四级控制是可以通过位来操作的,能够任意组合。如果想要TRACE_1和TRACE_2都能够输出,那么只需要设置:
1 int marker = TRACE_1 | TRACE_2;
2 printf3(marker, Normal, "I'm a normal message\n"); 如果marker设置为SUB,则表明全部输出。通过增加这层控制后,log的订制变得更加灵活。
改变目的地:Appender
到目前为止,所有的log都写到控制台。如果你想log写到文件中怎么办?如果不是控制台应用程序,比如,Win32或者MFC程序,log又该写到哪里去?也许你想到可以使用fwrite代替前面的printf,但是如果你想同时能够将log写到控制台,又写到文件中或者其它地方怎么办?
放弃这种硬编码的方法吧,你可以想到一种更加灵活,可以像前面TraceLevel和Marker一样容易配置的方法,能够更加优雅的控制log输出的目的地,但不需要硬编码在代码中,而是可以配置的。一起来看下面这段代码:
1 // I want my logs to go to console, files, eventlog
2 class Appender {
3 void printf(TraceLevel level, const char *message) = 0;
4 };
5 class ConsoleAppender: public Appender {/* overwrite printf */};
6 class FileAppender: public Appender {/* overwrite printf */};
7 class EventLogAppender: public Appender {/* overwrite printf */};
8
9 std::vector<Appender *> &getAppenders();
10 void printf4(int marker, TraceLevel level, const char *message) {
11 if (marker == 0 || marker & getMarker1() != 0) {
12 if (level >= getLevel1()) {
13 std::vector<Appender *>::iterator it = getAppenders.begin();
14 for (; it != getAppenders.end(); it++)
15 (*it)->printf(level, message);
16 }
17 }
18 printf4(SUB, Normal, "I'm a normal message\n");
19 printf4(TRACE_1, Normal, "I'm a normal message\n");
20 printf4(TRACE_2, Normal, "I'm a normal message\n"); 这里定义了一个叫做Appender的基类,可以理解为处理log目的地的类,它有一个方法printf,对应着如何处理传给它的log。
接下来定义了三个子类,分别代表输出目的地为控制台、文件和Windows的EventLog。它们都覆写了基类的printf方法,按照各自的目的地处理log的流向,比如ConsoleAppender调用前面的printf2函数,而FileAppender可能调用类似的fwrite。这样一来,只要我们为一个程序配置用哪些Appender,log就可以根据这些配置交给对应的Appender子类处理,从而无需在代码中硬编码。
这处理每一种目的地的类我们称之为Appender。
模块独立控制:Category
现在我们的log机制已经足够的完善。但是,随着程序规模越来越大,一个程序所包含的模块也越来越多,有时你并不想要一个全局的配置,而是需要每一个模块可以独立的进行配置,有了前面的介绍,这个需求就变得很简单了:
1 // There are too many components, I want different components
2 // could be configured separately
3 TraceLevel getLevel2(const char *cat);
4 int getMarker2(const char *cat);
5 std::vector<Appender *> &getAppenders2(const char *cat);
6 void printf5(const char *cat, int marder, TraceLevel level,
7 const char *message) {
8 if (marker == 0 || marker & getMarker2(cat) != 0) {
9 if (level >= getLevel2(cat)) {
10 std::vector<Appender *>::iterator it = getAppenders(cat).begin();
11 for (; it != getAppenders.end(cat); it++)
12 (*it)->printf(level, message);
13 }
14 }
15 printf5("Library1", SUB, Normal, "I'm a normal message\n");
16 printf5("Library1", TRACE_1, Normal, "I'm a normal message\n");
17 printf5("Library1", TRACE_2, Normal, "I'm a normal message\n"); 对比前一节的代码,可以发现这里除了增加一个参数const char *cat以外,其它完全一样。但正是这个参数的出现,才让每一个模块可以独立的配置。这种模块间独立进行配置的方法我们称为Category。
配置文件
前面多次提到配置,为了达到可以灵活配置的目的,通常会将这些配置保存成一个文件,比如logConfig.ini:
Category: Library1 -> for Library1 category
TraceLevel : Warning -> only Warning and Error messages are allowed
Markers : TRACE_1 -> only TRACE_1 is allowed
Appenders :
ConsoleAppender -> write to console
FileAppender: -> write to file
filePath: C:\temp\log\trace_lib1.log
Category: Library2 -> for Library2 category
...
那么在什么时机读取这个配置文件?一般有这样几种方式:
- 程序启动时载入
logConfig.ini,如果配置不常改变时可以采用这种方式,最简单。 - 创建一个新线程,间隔一段时间检查
logConfig.ini是否已经改变,如果改变则重新读取。这种方法比较复杂,可能会影响效率,而且间隔的时间也不好设置。 - 处理每一个log之前先检测
logConfig.ini,如果有改变则重新读取。 - 最后一种方法结合了前两种方法的优点,还是在处理每个log之前检测,但不同的是再加上一个时间间隔,如果超过时间间隔才会真的去检测,而如果在间隔内,则直接忽略。这种方法更加高效且消耗资源最少。
对于后面三种方式,每次配置文件有了更新之后,log输出几乎可以实时的作出应变。
至此,一个简单灵活的log原型建立了,虽然它还是非常简陋,但已经有了现代log库的雏形,包含了其中几个重要的概念。下面我将以我们所使用的log4me库进行分析。
log库常见用法
前面介绍的log雏形完全是小儿科式的代码,只是起一个演示作用,实际上我们无需重新发明轮子。如本文开始所介绍,已经有非常多专业的库来处理log,这些库以最简单的接口提供了最大化的log信息。我们这里采用的log4me库就有这样几个优点:
- 跨平台,在Windows和Linux上有着完全一样的接口与行为
- 更细的粒度来控制log
- 线程安全
- 高性能
我们定义了下面几个宏,专门用于Library1下的log输出,这里会取配置中Library1这个Category的配置,分别输出不同TraceLevel的log。
1 #define LIB1_OUT(MESSAGE) LOG_OUT(Library1, DLL, Notice) << MESSAGE
2 #define LIB1_WARN(MESSAGE) LOG_OUT(Library1, DLL, Warn) << MESSAGE
3 #define LIB1_ERR(MESSAGE) LOG_OUT(Library1, DLL, Error) << MESSAGE使用时像这样:
1 LIB1_OUT("I'm a message.");
2 LIB1_WARN("I'm a message, ID = " << 1234);
3 LIB1_ERR("I'm a message.");这里所有的配置都通过配置文件完成,还有一种动态的在代码中创建log的方法,log4cpp的官方网站中有例子,我们这里就不介绍了。
配置
在我们前面的演示代码中,提供了一种非常简单的配置文件,常见的存储配置文件的格式有xml,Windows的ini。log4me中使用的是前者,并且提供了专门的工具来简化其操作,如下图所示:
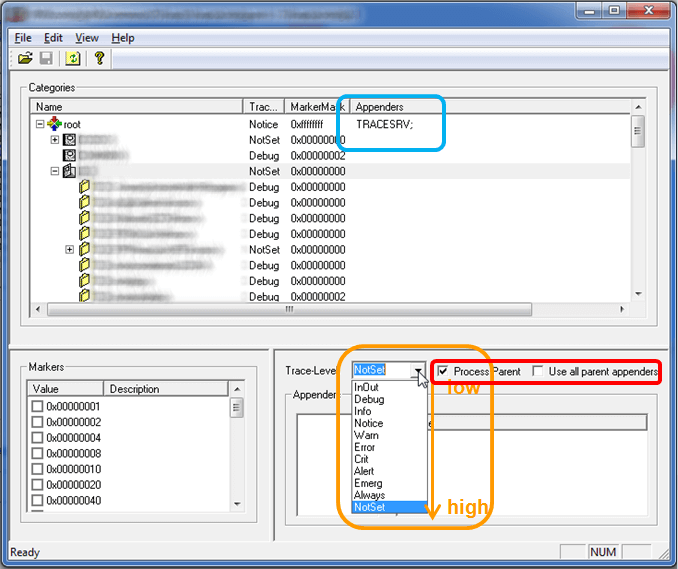
根据上图我们进一步来看一些概念:
TraceLevel
TraceLevel用来控制输出的log等级,下面这些比较常用:
INOUT : 进入和离开函数
DEBUG : 调试信息,通常用于诊断问题
INFO : 确认一切按计划照常工作
WARNING : 程序仍然可以运行,但有意外发生,或者将来有问题可能要出现(比如硬盘容量低)
ERROR : 错误信息
CRITICAL : 严重错误,表示程序可能无法继续运行
ALWAYS : 始终输出log
这些等级按从上到下依次增加的顺序排列,配置TraceLevel后,那么只有上表中位于该level之下的才能够输出。
Marker
Marker用来进一步控制log的分类,不像前面的演示代码只定义了四种,通常库会完全使用一个32位的整型来表示这些分类,每一位代表一类,这样就有了32种分类,对于大多数应用场景来说这已经完全足够。
Appender
前面介绍过Appender这个概念,它用来处理log的输出目的地,但真正的库可远不止前面介绍的三种Appender,log4me提供了这些:

注意:最后一个Appender是TraceSrv,它写到memfile中。什么是memfile?这是Linux上的一种内存管理的方法,它将文件映射到内存,通过直接读写内存来操作文件,从而使文件操作变得极其高效便捷,可以参考这里:Linux内存管理之mmap详解。
在Appender中还有一些常用的属性可以配置:
- CreateNewFile: 表明log库启动时是否创建新文件。
- FileCount & FileSize: 用于文件回卷,比如一个log文件lib.log过大时,可以将它重命名为lib.1.log,然后再重新创建lib.log。可以创建多个文件,而这两个参数就用于控制文件数目和单个文件大小。
- CategoryFilter: 表明该Appender只处理这个filter列举的Category。
- ProcessFilter: 与上面类似,只处理filter列举的进程。
Formatter
这个概念在前面没有介绍过,但它也非常容易理解:每个Appender都可以包含一个formatter,它用来格式化log信息。因为一条log信息可能包含时间,文件名,行号,TraceLevel,进程ID,正文等信息,有时为了简化log输出,对所有的这些分类作一个取舍,从而达到格式化的目的。这很像C语言中的printf。
如果formatter设置的是:
%TIME%|%PID%|%LEVEL%|%MARKER%|%CAT%|%FILE%|%LINE%|%FUNC%|%USERTEXT%|
那么log的输出会像这样:
2014/04/07-16:03:35.251560|5560|Notice|SUB|COMP1|main.cpp|78|test|I'm a message|
每一项都和前面formatter中设置的一一对应。
Category
现代的log库一般都将Category组织成树型结构,每一个节点都和前后组成父子关系,根据设置,子节点的Category完全可以继承父节点的配置。所有的Category的根节点是root。这里是一个典型的结构:

一个Category可以包含下面这几个内容:

注意:一个Category可以有多个Appender。
Name, TraceLevel, Marker和Appender这里就不再赘述。上图中有一个Flag,这是什么?它的存在和前面的树型结构息息相关。前面讲到,因为Category被组织成了树型关系,子节点可以继承父节点的配置,那么何时可以继承,如何继承?这就是Flag的作用了,它包含了两个选项:
- Process Parent: 如果勾选这一项,就表示一个子节点的log可以传给它的父节点处理。这也是为什么很多情况下只需要配置Root节点,其它的子节点设置这个Flag,就可以默认使用Root的全部配置。
- Use All Parent Appenders: 如果只有上面的Flag,那么每次信息传到父节点时,父节点都必须根据自身的TraceLevel及Marker进行匹配,只有匹配时才会处理。而如果此Flag打开,那么在传输过程中,只要传输路径上有一个节点匹配,再向上传的所有节点都不再匹配而直接处理。
处理流程
至此你已经完全了解了log的基本概念以及用法,接下来我们更进一步,来看看log内部是如何工作的。
有了前面的演示代码之后再来看log内部处理流程将变得十分简单,大致可以分为两步,第一步过滤:

它在log的调用线程中发生,有些线程可能会对实时性有一定的要求,那么log就不能够在这种线程中去直接执行,而是将创建的log对象加入到队列中,由专门的log工作线程处理,这样就完全不会阻塞住主线程,保证主线程畅通无阻的运行。
流程的第二步是处理消息:

筛选过Category之后会将消息发给每一个合适的Appender,由Appender进一步的筛选及格式化输出。注意在这一步的刚开始有一个Check Config步骤,这和我们前面讲的加载配置文件的时机有关,很明显,这里用的是最后一种读取配置的方案:即每次处理log时,检测配置是否更新。
log在系统中的部署
也许你会想,一个简单的库有什么好部署的,直接拿来用不就得了。可有时因为性能,或者系统过于庞大,配置起来会相当复杂,如果log组织的不好的话,你就会见到log文件满天飞,散落各处的情况。有时你可能会需要一个总的log文件包含所有的信息,一些特定目的的log还要存于不同的文件中。如何保证不同进程,甚至不同的机器上的不同进程能够无冲突的写到同一个log文件中呢?假设一个系统包含一台Windows,一台Linux,如何收集散落各个机器的log?如何方便的在Windows上查看本应出现在Linux上的log?如果你有疑问,请看下面的解决方案:

这个系统足够庞大,包含了两台机器,左边是Windows,右边是Linux。每台机器除各自保存log之外,还将所有的log都最终交给Windows上的TraceSrv来处理,最终会有一份完整的包含所有机器的log存在于TraceSrv.log中,还有各个不同模块的log文件。同时,还能够通过远程调用TraceOnlReader来实时从TraceSrv中读取log信息。如上图所示,两侧绿色的Log图例中,红色的信息沿着箭头先全部汇聚到TraceSrv,然后再分发到不同的文件中。
这样,开发者就可以通过一次配置,便可以非常方便的组织好所有的log文件,调用端完全剔除了这些复杂的细节,只需要关注log本身。
另外注意到,在Windows和Linux端各有一个memfile,它们各自存有机器上的所有log信息,由于是运用了前面所说的mmap机制,程序直接以操作内存的方式来操作文件,非常高效。
尾声
好了,至此所有在知识分享中的内容便介绍完毕,希望对感兴趣的你有所帮助。
我很喜欢部门的知识分享,分享是件好事,在分享的过程中,不仅仅可以让他人获取有用的信息,而且你在分享前需要不断的归纳总结,印证你的结论。在这个过程中,很多你当时思考不充分的问题也可能会得到解决,对你自身的知识、表达能力都有非常大的提高,利人利己。
不知你是否有过这样的经历,你遇到一个问题,百思不得其解,于是想向他人求助,可就在你向他人解释这个问题的过程中,说着说着,你发现你找到问题的所在,于是问题解决了,甚至别人还没明白怎么回事。我就经常遇到这种情况。根据这点,有人总结出了一种新型的解决问题的方法,叫做橡皮鸭调试法,维基百科对它有一个介绍,Jeff Atwood也专门写过一篇文章:Rubber Duck Problem Solving。(至于为什么叫橡皮鸭而不叫其它的,我想大概和美国人的成长经历有关吧,每个孩子洗澡时都喜欢在浴缸中放一只橡皮鸭,并与它交谈,就像我们儿时的各种玩具一样。)这样做其实是有根据的,它和分享如出一辄,当你和橡皮鸭”交谈”时,你需要彻底的把你的问题仔仔细细的描述一遍,不会放过每一个细节,为防质疑,你可能会做更多的调查。你在描述的同时,也一定在思考,这时之前没有考虑到的方面可能就会暴露出来了。如果使用得当,也许,橡皮鸭调试法可以成为log和debug以外,你分析问题又一强有力的武器:-)
最后,强烈建议你去看看Jeff的这篇文章。















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









