









0. 前言
- 官方教程(需要翻墙,都有中文版了):
- TensorFlow Summary 相关API(需要翻墙)
- Github: tensorflow/tensorboard
1. 综述
tf.summary相关API的功能就是,将定期将部分指定tensor的值保存到本地,在通过tensorboard显示。- PS:目前见过的都是
tf.summary与tensorboard配合使用,没见过分开用的…… tf.summary与tensorboard使用流程:- 第一步:使用
tf.summary等相关API为指定的tensor创建ops(有如下两种ops)。- 第一类:
tf.summary.scalar等,为一个tensor创建某种类型的显示方式。 - 第二类:
tf.summary.merge_all等,将第一类ops合并在一起。
- 第一类:
- 第二步:通过session执行第一步获取的ops,得到一个字符串。
- 第一步获取ops的返回值都是
a scalar 'tensor' of type 'string'. Which contains a 'Summary' protobuf.
- 第一步获取ops的返回值都是
- 第三步:通过
tf.summary.FileWriter实例的add_summary方法,将第二步获取的字符串保存到本地。 - 第四步:通过
tensorboard命令启动服务,通过网页访问tensorboard页面。
- 第一步:使用
例如:
tf.summary.scalar('accuracy',acc) #生成准确率标量图
merge_summary = tf.summary.merge_all() #整合所有summary op
train_writer = tf.summary.FileWriter(dir,sess.graph)#生成writer实例
#......(交叉熵、优化器等定义)
for step in xrange(training_step): #训练循环
train_summary = sess.run(merge_summary,feed_dict = {...})#调用sess.run运行图,生成一步的训练过程数据
train_writer.add_summary(train_summary,step) #调用train_writer的add_summary方法将训练过程以及训练步数保存 2. API介绍
2.1. summary相关ops
sumamry创建的ops分两种,一类对指定tensor进行记录,一类是合并一系列summary ops。
-
对指定tensor进行记录的ops:
# 保存某个标量
def scalar(name, # 名称,可用于TensorBoard中的series name
tensor, # 要记录的tensor,必须只包含一个数值
collections=None, # 该ops要默认添加的colletions名称,默认是GraphKeys.SUMMARIES
family=None # tag名字的前缀,用于Tensorboard的tab name
):
#例如:tf.summary.scalar('mean', mean)
#一般在画loss,accuary时会用到这个函数。例如:

# 保存某个tensor中所有数据的直方图
def histogram(name, # 同scalar
values, # 任意维任意数据
collections=None, # 同scalar
family=None # 同scalar
):
#例如: tf.summary.histogram('histogram', var)
#一般用来显示训练过程中变量的分布情况
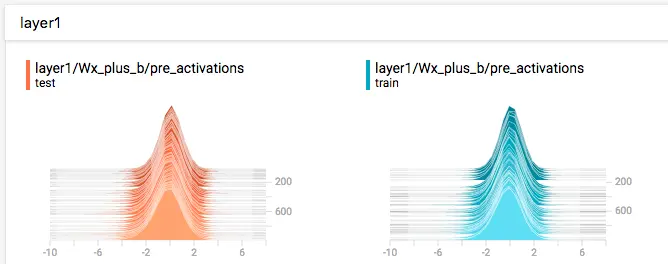
当你想看 activations, gradients 或者 weights,bias 的分布时,可以用 tf.summary.histogram。如下图,显示了每一步的分布,越靠前面就是越新的步数的结果。
# 保存一段音频
def audio(name, # 同scalar
tensor, # 必须是float32,shape可以是[batch_size, frames, channels] 或 [batch_size, frames]
sample_rate, # float32标量,the sample rate of the signal in hertz
max_outputs=3, # 最多生成的batch elements to generate audio
collections=None, # 同scalar
family=None # 同scalar
):
#展示训练过程中记录的音频
# 保存某张图片
def image(name, # 同scalar
tensor, # 可以是float32或uint8类型
# shape必须是[batch_size, height, width, channels],其中channels可以是1、3、4。
# 如果输入的数据为float,会自动转换为uint,范围在[0, 255]。
max_outputs=3, # 最多保存多少张图片。
# 如果是1,则summary image tage是 '*name*/image',如果大于1则是'*name*/image/0'等。
collections=None, # 同scalar
family=None # 同scalar
):
#输出带图像的probuf,汇总数据的图像的的形式如下: ’ tag /image/0’, ’ tag /image/1’…,如:input/image/0等。
#格式:tf.summary.image(name, tensor, max_outputs=3, collections=None)
def text(
name,
tensor,
collections=None
):
#可以将文本类型的数据转换为tensor写入summary中:
#例如:
text = """/a/b/c\\_d/f\\_g\\_h\\_2017"""
summary_op0 = tf.summary.text('text', tf.convert_to_tensor(text))-
合并summary ops:
# 合并inputs中所有ops
def merge(inputs,
collections=None,
name=None):
# 合并key指向collections中的所有summary ops
def merge_all(key=_ops.GraphKeys.SUMMARIES,
scope=None):
#merge_all 可以将所有summary全部保存到磁盘,以便tensorboard显示。如果没有特殊要求,一般用这一句就可显示训练时的各种信息了。
#但是当你只想对特定的tensor进行summary时建议使用merge函数显式指定tensor
#merge_all用法:
tf.summary.scalar('accuracy',acc) #生成准确率标量图
merge_summary = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(dir,sess.graph)#定义一个写入summary的目标文件,dir为写入文件地址
......(交叉熵、优化器等定义)
for step in xrange(training_step): #训练循环
train_summary = sess.run(merge_summary,feed_dict = {...})#调用sess.run运行图,生成一步的训练过程数据
train_writer.add_summary(train_summary,step)#调用train_writer的add_summary方法将训练过程以及训练步数保存
#merge用法
tf.summary.scalar('accuracy',acc) #生成准确率标量图
merge_summary = tf.summary.merge([tf.get_collection(tf.GraphKeys.SUMMARIES,'accuracy'),...(其他要显示的信息)])
train_writer = tf.summary.FileWriter(dir,sess.graph)#定义一个写入summary的目标文件,dir为写入文件地址
......(交叉熵、优化器等定义)
for step in xrange(training_step): #训练循环
train_summary = sess.run(merge_summary,feed_dict = {...})#调用sess.run运行图,生成一步的训练过程数据
train_writer.add_summary(train_summary,step)#调用train_writer的add_summary方法将训练过程以及训练步数保存
使用tf.get_collection函数筛选图中summary信息中的accuracy信息,这里的
tf.GraphKeys.SUMMARIES 是summary在collection中的标志。
当然,也可以直接:
acc_summary = tf.summary.scalar('accuracy',acc) #生成准确率标量图
merge_summary = tf.summary.merge([acc_summary ,...(其他要显示的信息)]) #这里的[]不可省
2.2. tf.summary.FileWriter
-
构造器
- 完成两件功能:创建一个FileWriter实例,创建一个event文件。
-
def __init__(self, logdir, graph=None, # 在这里指定Graph实例,等同于后续调用`add_graph()`函数,一般会调用sess.graph max_queue=10, flush_secs=120, # 将添加的summaries保存到本地events文件的频率 graph_def=None, # 缓存的summaries或者events的最大数量,大于这个数量必须写到本地文件中 filename_suffix=None # event file的前缀 ):
-
将protobuf string保存到本地
-
def add_summary(self, summary, # 要保存的summary string,即sumamry ops经过session的执行结果 global_step=None ):
3. 官方实例
- 代码地址
- 在定义模型的过程中创建
tf.summary相关ops。在创建过程中,所有summary ops会添加到tf.GraphKeys.SUMMARIES当中。 - 在模型定义结束时,定义
merged = tf.summary.merge_all()ops,来集合所有summary op。其本质就是获取所有tf.GraphKeys.SUMMARIES,并合并成一个op。 - 在需要记录summary时,首先通过
session执行merged操作得到一个字符串,再将该字符串通过tf.summary.FileWriter实例保存到本地。
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import os
import sys
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
FLAGS = None
def train():
# 读取mnist
mnist = input_data.read_data_sets(FLAGS.data_dir,
fake_data=FLAGS.fake_data)
sess = tf.InteractiveSession()
# 定义placeholder
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.int64, [None], name='y-input')
# 对输入数据进行reshape,并进行summary.image记录
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def variable_summaries(var):
# 为指定的tensor获取一系列summary
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
# 建立普通神经网络
with tf.name_scope(layer_name):
# This Variable will hold the state of the weights for the layer
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('pre_activations', preactivate)
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
return activations
# 搭建普通单隐层神经网络
hidden1 = nn_layer(x, 784, 500, 'layer1')
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep_probability', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob)
y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity)
# 计算损失函数的值,并summary
with tf.name_scope('cross_entropy'):
with tf.name_scope('total'):
cross_entropy = tf.losses.sparse_softmax_cross_entropy(
labels=y_, logits=y)
tf.summary.scalar('cross_entropy', cross_entropy)
# 建立优化函数
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(FLAGS.learning_rate).minimize(
cross_entropy)
# 建立mertrics,并记录
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), y_)
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# 获取所有sumamry的集合,并建立两个FileWriter实例
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(FLAGS.log_dir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(FLAGS.log_dir + '/test')
tf.global_variables_initializer().run()
def feed_dict(train):
# 获取session所需的feed_dict
if train or FLAGS.fake_data:
xs, ys = mnist.train.next_batch(100, fake_data=FLAGS.fake_data)
k = FLAGS.dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x: xs, y_: ys, keep_prob: k}
for i in range(FLAGS.max_steps):
if i % 10 == 0: # 每10次记录一次测试集summary结果
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else:
if i % 100 == 99: # 训练
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, train_step],
feed_dict=feed_dict(True),
options=run_options,
run_metadata=run_metadata)
train_writer.add_run_metadata(run_metadata, 'step%03d' % i)
train_writer.add_summary(summary, i)
print('Adding run metadata for', i)
else: # 记录训练集summary结果
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)
train_writer.close()
test_writer.close()
def main(_):
# 新建log_dir路径
if tf.gfile.Exists(FLAGS.log_dir):
tf.gfile.DeleteRecursively(FLAGS.log_dir)
tf.gfile.MakeDirs(FLAGS.log_dir)
# 开始训练
train()
if __name__ == '__main__':
# 使用了Python自带的命令行工具
parser = argparse.ArgumentParser()
parser.add_argument('--fake_data', nargs='?', const=True, type=bool,
default=False,
help='If true, uses fake data for unit testing.')
parser.add_argument('--max_steps', type=int, default=1000,
help='Number of steps to run trainer.')
parser.add_argument('--learning_rate', type=float, default=0.001,
help='Initial learning rate')
parser.add_argument('--dropout', type=float, default=0.9,
help='Keep probability for training dropout.')
parser.add_argument(
'--data_dir',
type=str,
default=os.path.join(os.getenv('TEST_TMPDIR', '/tmp'),
'tensorflow/mnist/input_data'),
help='Directory for storing input data')
parser.add_argument(
'--log_dir',
type=str,
default=os.path.join(os.getenv('TEST_TMPDIR', '/tmp'),
'tensorflow/mnist/logs/mnist_with_summaries'),
help='Summaries log directory')
FLAGS, unparsed = parser.parse_known_args()
# 执行main函数
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)4. 其他
4.1. 命令行执行tensorbaord
- 使用的命令就是
tensorboard --logdir=/path/to/logs --port=16006。 - 可以查看
tensorboard的其他参数,命令为tensorboard --helpfull
4.2. 在同一张图上显示多条曲线
- 本质就是,创建多个FileWriter实例,
add_summary到logs中不同子文件夹的events文件中。 - 子文件夹的名称就是Tensorboard中曲线的name。
summary_writer = tf.summary.FileWriter(logdir+'/train', sess.graph)
summary_writer_dev = tf.summary.FileWriter(logdir+'/dev')















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









