







目录
编译器:
通俗讲是高级语言翻译成机器语言的翻译器
高级语言:不依赖机器的语言 如C/C++
低级语言:依赖于机器,在机器上运行的语言
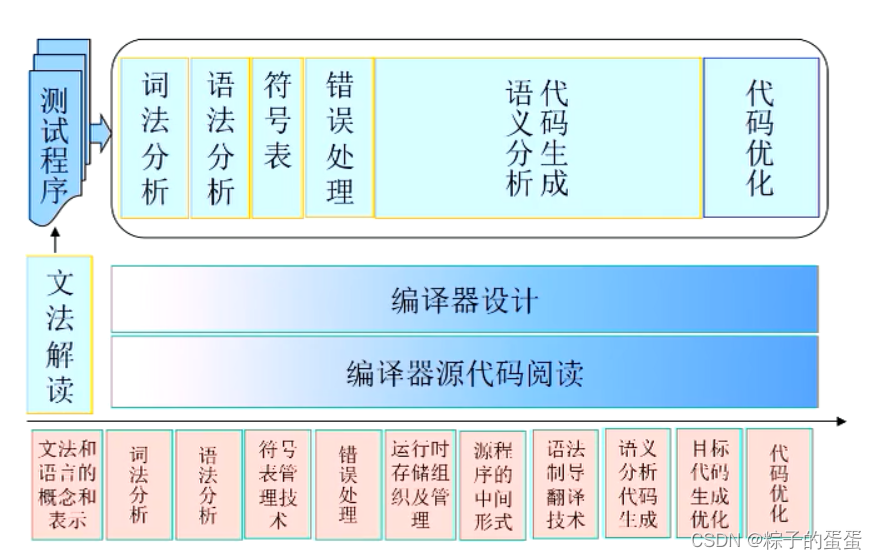
编译过程:语法分析;语义分析;生成中间代码;代码优化 ;生成目标程序 ;
词法分析:
`任务`:分析和识别单词(Token)
`解释`:源程序是由字符序列构成的,词法分析扫描源程序 (字符串),根据语言的词法规则识别单词,并以某种编码形式输出

`单词(Token):`是语言的基本语法单位,一般语言有四大类单词
1、语言定义的关键字或者保留字(如BEGIN、END、IF)
2、标识符
3、常数
4、分节符(运算符)(如+、-、*、/、;、(、)
语法分析
`任务`:根据语法规则(即语言的文法),分析并识别出各种语法的成分,如表达式、各种说明、各种语句、过程、函数等 并进行语法正确性的检查
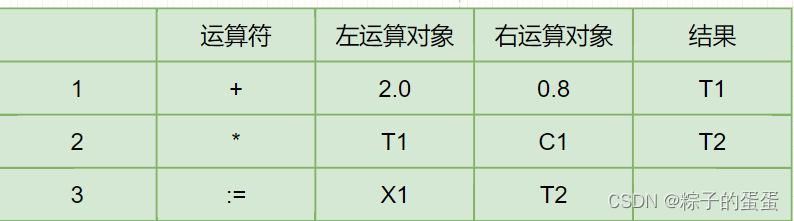
X1:=(2.0 + 0.8)* C1
赋值语句的文法:
<赋值语句>--><变量><赋值操作><表达式>
<变量>--><简单表示符>
<赋值操作>-->
语义分析,生成中间代码
`任务`: 对识别出的各种语法成分进行语义分析,并产生相应的中间代码
中间代码:一种介于源语言和目标语言之间的语言形式
生成中间代码的目的:
1.便于优化处理
2.便于编译程序的移植
中间代码的形式【可以自己设计】:常用的有 三元式、四元式、逆波兰表示等
举例四元式:
X1:=(2.0+0.8)*C1
四元式的语义
代码优化
生成目标程序
注意:这几个步骤中间还贯穿着符号表管理和出错处理
符号表管理:因为会一直查询需要有性能要求
遍的含义:从头到尾对代码扫描一遍,并做有关加工处理,生成新的源程序中间形式或者目标程序
概念描述
前端:源程序
后端:运行在目标机上的代码
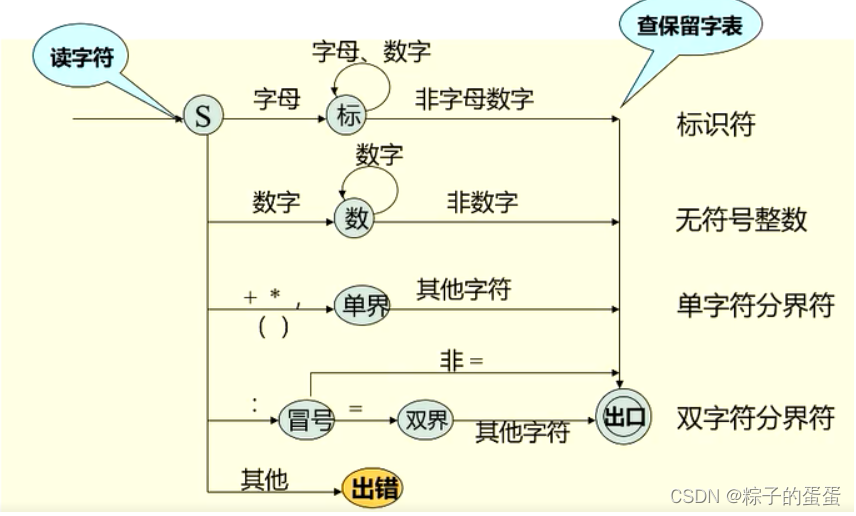
构造词法分析程序的例子
文法:
1.<标识符>::=字母|<标识符>字母|<标识符>数字
2.<无符号整数>::=数字<无符号整数>数字
3.<单字符分界符>::=:|+|*|,|(|)
4.<双字符分界符>::=<冒号>=
5.<冒号>::=:
用递归程序构造语法分析程序的例子

语法树
注意:
文法的两个条件
为了不采用超前扫描的前提下实现不带回溯的自顶向下分析文法需要满足两个条件:
1.文法是非递归的;
2.对于G的每个非终结符A的任意两条规则A::a|B,下列条件成立:

学习路径:
学习资料:
当然也可以看一些开源编译器项目代码
















 255
255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









