







目录
2、ES集群状态由非正常状态(red)恢复为正常状态(green)
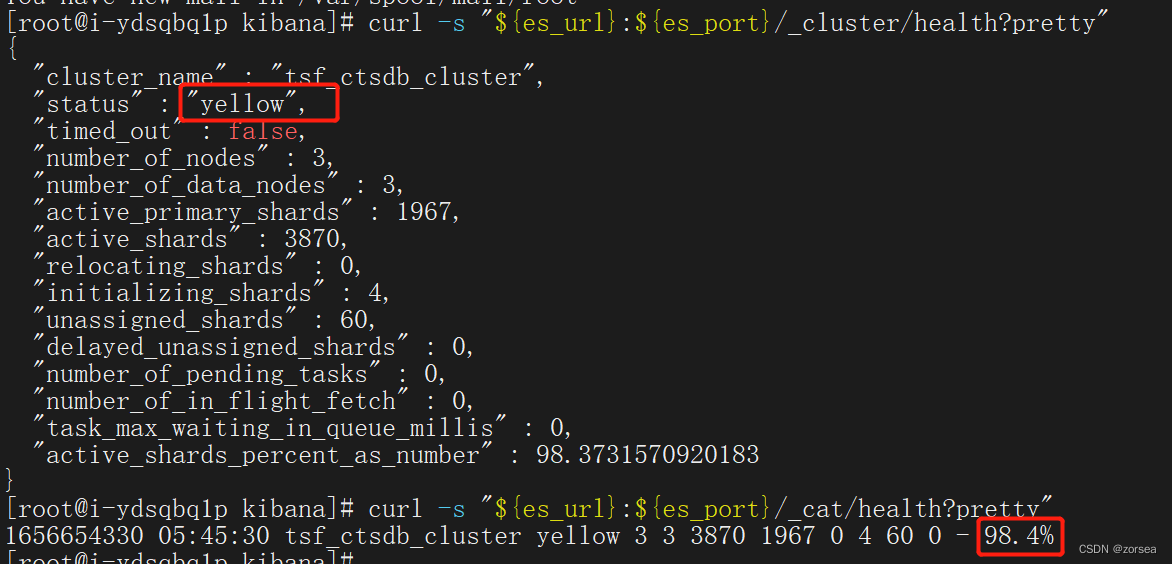
1、查看es集群状态
status状态:green(健康)、yellow(异常或同步中)
es_url=192.168.0.1
es_port=9200
curl -s "${es_url}:${es_port}/_cluster/health?pretty"
curl -s "${es_url}:${es_port}/_cat/health?pretty"status: yellow,通过_cat/health?pretty检查是否数据在同步中
2、ES集群状态由非正常状态(red)恢复为正常状态(green)
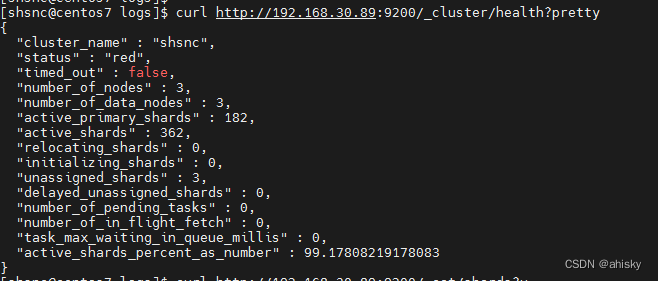
集群的异常之处: number_of_nodes / cluster status / unassigned_shards
- number_of_nodes: 3
(正常情况下,应该是: 3) - cluster status: red
(正常情况下,应该是: green)
red: 非健康状态; 部分的分片可用,表明分片有一部分损坏。一般情况下,表明存在 unassigned 的索引分片(shards:碎片,分片)。
此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好;
这种情况Elasticsearch集群至少一个主分片(以及它的全部副本)都在缺失中。
这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
yellow: 亚健康状态;基本的分片可用,但是备份不可用(或者是没有备份);
这种情况Elasticsearch集群所有的主分片已经分片了,但至少还有一个副本是缺失的。
不会有数据丢失,所以搜索结果依然是完整的。
不过,你的高可用性在某种程度上被弱化。
如果更多的分片消失,就会丢数据了。
把 yellow 想象成一个需要及时调查的警告。
green: 最健康状态;说明所有的分片包括备份都可用; 这种情况Elasticsearch集群所有的主分片和副本分片都已分配, Elasticsearch集群是 100% 可用的。- unassigned_shards: 3
(正常情况下,应该是: 0)
unssigned即未分配副本分片的问题,查看分片异常的索引数据
[shsnc@centos7 logs]$ curl http://192.168.30.89:9200/_cat/shards?v
# 删掉异常的索引
[shsnc@centos7 logs]$ curl -X DELETE http://192.168.30.89:9200/cmdb_instance
{"acknowledged":true}检查集群状态变成正常状态green
















 1529
1529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









