







这篇论文蛮有意思的,思来想去感觉有必要总结一下。先贴地址:https://arxiv.org/pdf/2307.11019
这篇论文的研究旨在回答以下三个核心问题:
- LLMs在多大程度上能够感知其事实知识边界?
- 检索增强对LLMs有何影响?
- 不同特性的支持文档如何影响LLMs?
研究背景与相关工作
研究背景
大型语言模型(LLMs)作为人工智能领域的热门研究方向,近年来在多个任务中展现出了卓越的能力。然而,在知识密集型任务,尤其是开放域问答(QA)中,LLMs的表现仍面临诸多挑战。尽管LLMs能够编码大量的世界知识,但在处理具体问题时,其内部知识与外部信息的整合、冲突解决以及知识边界的感知能力尚待深入研究。特别是,当外部资源可用时,LLMs如何准确评估自己的答题能力、判断参考信息的充分性,以及评估答案的准确性,成为当前研究的关键问题。
相关工作
目前,已有不少研究对LLMs在QA任务中的表现进行了评估,并提出了多种改进评估方法或利用LLMs增强QA模型的技术。然而,这些研究大多集中在提高QA任务的性能上,而对LLMs感知其事实知识边界的能力缺乏深入探讨。此外,虽然检索增强技术已被广泛应用于QA任务中,以提高模型的性能,但关于检索增强对LLMs知识边界感知能力的影响,以及不同特性的支持文档如何影响LLMs的研究还相对较少。因此,本文的研究不仅填补了这一领域的空白,也为未来LLMs的改进提供了新的视角和思路。
新工作介绍
这项研究由中国人民大学高瓴人工智能学院和百度联合推出,聚焦于大型语言模型(LLMs)在开放域问答任务中的知识边界感知能力。论文提出了一种基于先验和后验判断的策略,来评估LLMs在回答问题时对其知识边界的感知能力。其中,**“知识边界感知”是本文提出的核心概念,它指的是LLMs能否准确判断自己能否回答某个问题,以及回答的正确性。围绕这一概念,论文还引入了“检索增强”**的方法,旨在通过引入外部知识来提升LLMs的性能。这项工作的亮点在于它不仅揭示了LLMs在感知知识边界方面的不足,还提出了一种基于先验判断的简单方法,动态地引入检索增强,以提高LLMs的准确性和可靠性。
具体来说,研究团队通过设计一系列实验,深入分析了LLMs在回答问题时的自信程度、判断准确性以及在不同支持文档下的表现。他们发现,LLMs在感知其事实知识边界方面存在显著问题,往往过于自信,不能准确评估自己的答题能力和答案的正确性。而检索增强技术被证明是提高LLMs感知知识边界能力的有效方法,能够显著提升LLMs在QA任务中的性能和判断准确性。
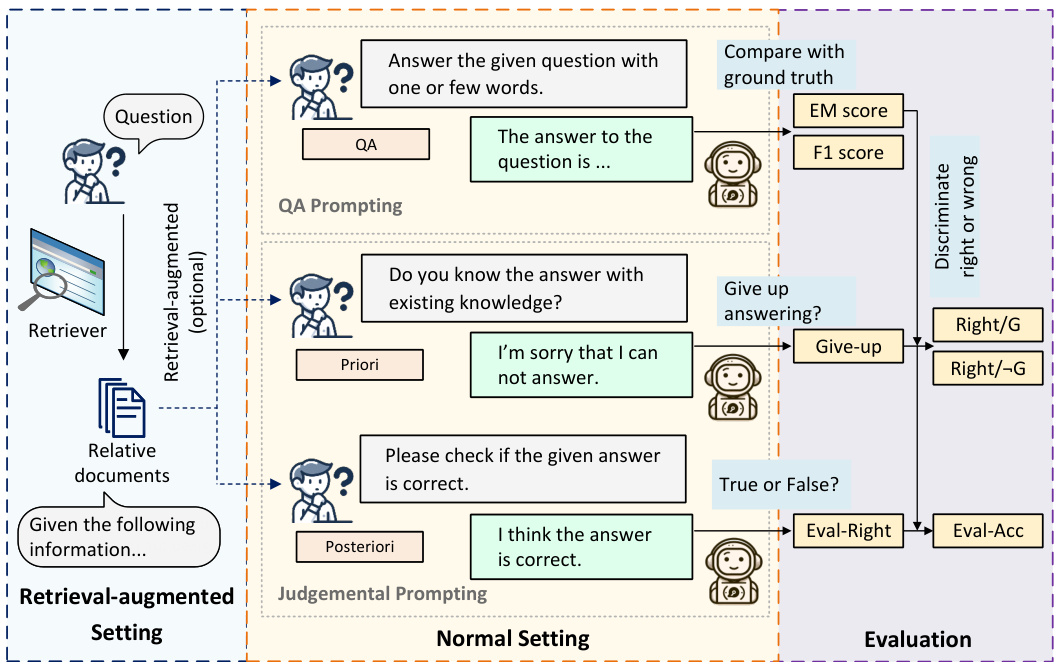
图注:图中展示了不同设置下对LLMs的指示,以及所使用的评估指标。
方法
该研究的方法主要包括以下几个步骤:
-
问题设置与指令设计:研究团队设计了QA提示和判断提示两种指令设置,以在封闭书和检索增强两种设置下评估LLMs的能力。这两种设置分别模拟了LLMs在没有外部知识和有外部知识支持下的表现。
-
先验与后验判断:在回答问题之前,LLMs通过先验判断评估自己是否能够提供答案;在生成答案后,则通过后验判断评估自己答案的正确性。这一步骤旨在揭示LLMs在感知知识边界方面的能力。
-
检索增强:为了提升LLMs的性能,研究团队引入了检索增强技术。他们采用了密集检索、稀疏检索和ChatGPT等多种方法,以获取支持文档,并分析了不同支持文档对LLMs性能和判断准确性的影响。
-
动态引入检索增强:基于先验判断的结果,研究团队提出了一种简单的方法,根据LLMs的先验判断动态引入检索增强。当LLMs判断自己无法回答问题时,再引入检索增强技术来提供外部知识支持。
这些步骤的设计初衷在于全面评估LLMs在感知知识边界方面的能力,并探索如何通过检索增强技术来提高其性能和判断准确性。通过先验和后验判断,研究团队能够深入了解LLMs在回答问题时的自信程度和判断准确性;而检索增强技术的引入,则能够为LLMs提供额外的知识支持,进一步提升其性能。
实验结果
实验结果表明,LLMs在感知事实知识边界方面存在显著问题。在回答问题之前和之后,LLMs都倾向于高估自己的知识,导致高放弃率下的不正确回答,以及在后验判断中高估自己答案的正确性。这一发现揭示了LLMs在感知知识边界方面的不足,也强调了提高LLMs判断准确性的重要性。
然而,检索增强技术被证明是提高LLMs感知知识边界能力的有效方法。通过引入支持文档,LLMs在QA性能和知识边界感知准确性方面均有所提升。特别是当支持文档质量较高时,LLMs的QA性能和判断准确性都得到了显著提升。此外,研究还发现,当支持文档数量超过一定阈值时,性能提升不再明显,甚至可能下降。这一发现为未来的研究提供了重要参考,即在引入检索增强技术时,需要合理控制支持文档的数量和质量。
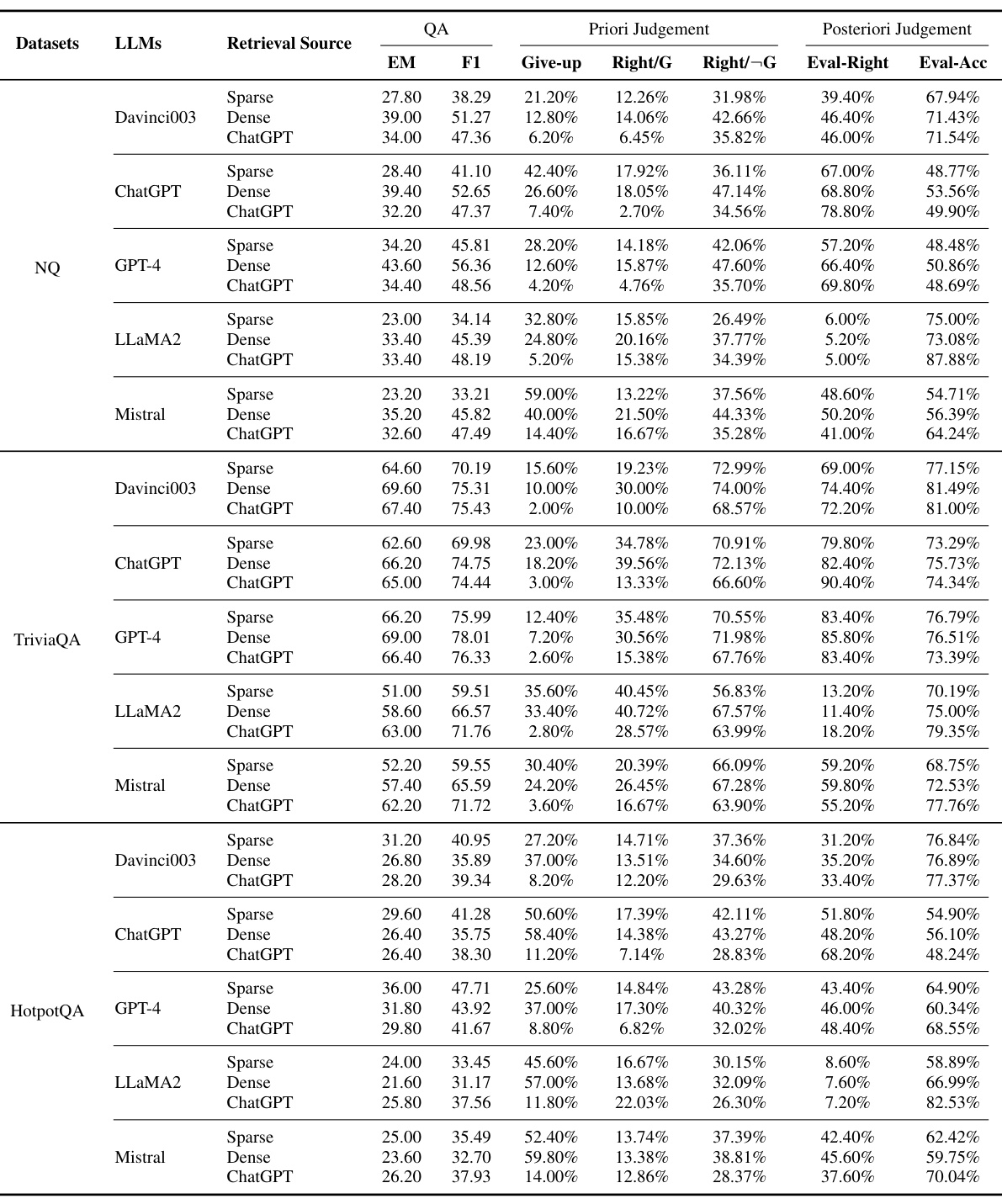
图注:表中展示了检索增强LLMs的实验结果,缩写词在2.3.1节中解释。
此外,研究团队还提出了一种基于先验判断的动态检索增强方法。实验结果表明,这种方法能够在某些情况下提高LLMs的答题准确性,进一步证明了检索增强在提升LLMs感知知识边界能力方面的有效性。通过动态地引入检索增强,研究团队成功地提高了LLMs在QA任务中的性能和判断准确性。
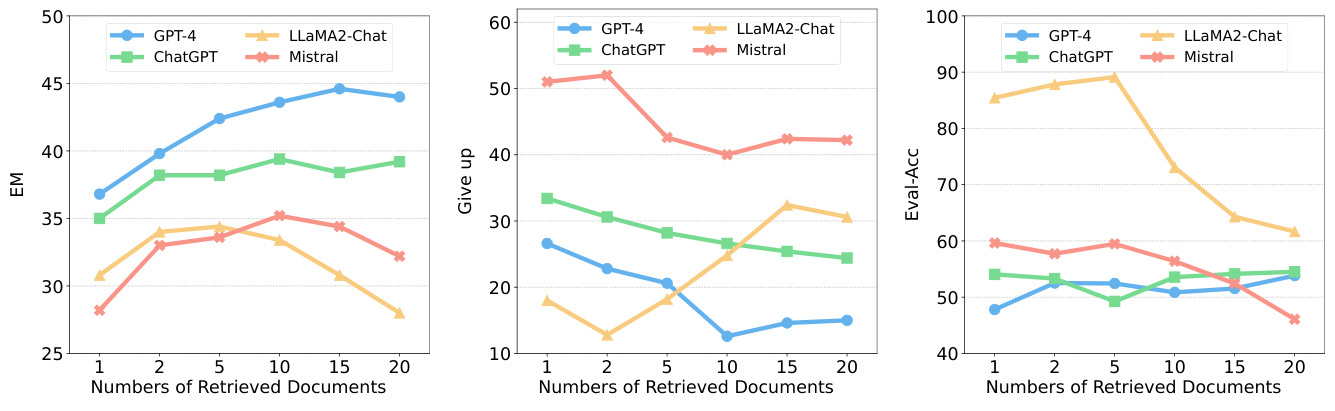
图注:图中展示了不同检索文档数量下,检索增强LLMs的性能表现。

图注:图中展示了一种基于先验判断策略,动态引入检索增强的简单方法。我们以在检索增强设置下使用QA提示的ChatGPT作为基线(无判断)。
应用与未来
应用场景
1. 智能问答系统
本文提出的方法在智能问答系统中具有广泛的应用前景。通过动态引入检索增强,大型语言模型可以更准确地回答用户的问题,同时减少因知识边界感知不准确而导致的错误回答。这将极大地提升用户体验,使得智能问答系统在教育、客户服务、娱乐等多个领域都能发挥更大的作用。
2. 自动化内容生成
在自动化内容生成领域,大型语言模型已经取得了显著的进展。然而,如何确保生成内容的准确性和可信度一直是一个挑战。通过引入检索增强和动态判断机制,可以进一步提升模型生成内容的准确性和可信度,从而满足更广泛的内容生成需求,如新闻报道、文章撰写、广告文案等。
3. 学术研究与知识管理
在学术研究和知识管理领域,大型语言模型可以作为辅助工具,帮助研究人员快速获取和整理相关信息。通过优化模型对事实知识边界的感知能力,可以更有效地筛选出高质量的学术资源,提高研究效率和准确性。同时,这也有助于构建更加完善的知识库和学术平台。
未来研究方向
1. 改进检索增强策略
虽然检索增强技术已经取得了显著的效果,但如何进一步优化检索策略,提高检索效率和准确性,仍然是一个值得研究的问题。未来的研究可以探索更加智能的检索算法,以及如何利用多模态信息来提高检索效果。
2. 提升模型对知识边界的感知能力
尽管本文已经提出了一些方法来提高大型语言模型对知识边界的感知能力,但这一领域仍然有很大的提升空间。未来的研究可以进一步探索如何结合深度学习、强化学习等先进技术,来训练更加智能、更加自知的模型。
3. 跨领域知识融合与应用
大型语言模型在各个领域都取得了显著的进展,但如何将这些领域的知识进行有效融合,并应用于实际问题中,仍然是一个挑战。未来的研究可以探索如何构建更加开放、可扩展的模型架构,以及如何利用迁移学习等技术来加速跨领域知识的融合与应用。这将有助于推动人工智能技术在更多领域取得突破性的进展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









