







Linux设备模型7(基于Linux6.6)---sysfs介绍
一、sysfs概述
sysfs 是 Linux 内核提供的一个虚拟文件系统,它允许用户空间程序访问内核的内部信息和控制内核对象。sysfs 主要用于暴露内核对象(如设备、驱动程序、模块等)及其属性,并提供一种方式,让用户能够与这些对象交互。
sysfs 是基于文件系统的接口,通常挂载在 /sys 目录下,用户和程序可以通过访问这个目录及其子目录来读取和修改内核对象的状态。它使得内核信息更加易于用户访问,尤其对于调试、性能监控、硬件配置等操作非常有用。
sysfs的设计与特点
-
文件系统接口
sysfs提供了一个基于文件的接口,通过文件的读写操作可以获取和修改内核对象的属性。这些文件的内容通常是字符设备,读写文件会触发内核相应的操作。 -
内核对象的暴露
sysfs通过目录结构组织内核对象,每个内核对象(如设备、驱动、总线、模块等)都有一个对应的目录,其中包含该对象的属性文件。- 设备:例如
/sys/class/net/eth0/目录包含与网络接口eth0相关的信息,如设备状态、接口设置等。 - 驱动程序:如
/sys/bus/pci/drivers/目录,包含所有 PCI 设备的驱动程序信息。 - 模块:如
/sys/module/目录,暴露了内核加载的模块及其属性。
- 设备:例如
-
动态性
sysfs是动态的,内核对象的属性可以在运行时进行添加、删除或更新。例如,某个设备的属性在设备状态变化时会被更新,用户可以通过读取对应的文件来获取最新信息。 -
权限管理
sysfs中的文件是基于权限控制的,文件的权限决定了用户是否可以修改相应的属性。例如,某些文件可能只能由 root 用户读取或写入。 -
只读与可写
在sysfs中,文件有不同的读写权限:- 只读文件:用户只能读取该文件的内容,例如
/sys/class/net/eth0/operstate,表示网络接口的状态。 - 可写文件:用户可以通过写入文件来改变设备的行为或配置。例如,写入
/sys/class/net/eth0/speed来设置网络接口的速度。
- 只读文件:用户只能读取该文件的内容,例如
-
属性和对象的绑定
sysfs中的属性通常与内核对象(如设备、驱动程序、总线等)紧密关联。每个属性都是某个内核对象的特性或配置参数。通过这些属性文件,用户可以查看或修改对象的状态。
sysfs的常见目录和文件结构:
| sysfs目录 | 所包含内容 |
| /sys/devices | 这是内核对系统中所有设备的分层次表达模型,也是 /sys 文件系统管理设备的最重要的目录结构 |
| /sys/dev | 这个目录下维护一个按字符设备和块设备的主次号码(major:minor)链接到真实的设备(/sys/devices下)的符号链接文件 |
| /sys/bus | 这是内核设备按总线类型分层放置的目录结构, devices 中的所有设备都是连接于某种总线之下,在这里的每一种具体总线之下可以找到每一个具体设备的符号链接,它也是构成Linux统一设备模型的一部分; |
| /sys/class | 这是按照设备功能分类的设备模型,如系统所有输入设备都会出现在 /sys/class/input之下,而不论它们是以何种总线连接到系统。它也是构成Linux统一设备模型的一部分; |
| /sys/block(stale) | |
| /sys/firmware | 这里是系统加载固件机制的对用户空间的接口,关于固件有专用于固件加载的一套API |
| /sys/fs | 这里按照设计是用于描述系统中所有文件系统,包括文件系统本身和按文件系统分类存放的已挂载点; |
| /sys/kernel | 这里是内核所有可调整参数的位置; |
| /sys/module | 这里有系统中所有模块的信息,不论这些模块是以内联(inlined)方式编译到内核映像文件(vmlinuz)中还是编译为外部模块(ko文件),都可能会出现在/sys/module中: 编译为外部模块(ko文件)在加载后会出现对应的/sys/module/<module_name>/,并且在这个目录下会出现一些属性文件和属性目录来表示此外部模块的一些信息,如版本号、加载状态、所提供的驱动程序等; 编译为内联方式的模块则只在当它有非0属性的模块参数时会出现对应的/sys/module/<module_name>,这些模块的可用参数会出现在/sys/modules/<modname>/parameters/<param_name>中, 如 /sys/module/printk/parameters/time 这个可读写参数控制着内联模块printk在打印内核消息时是否加上时间前缀; 所有内联模块的参数也可以由 "<module_name>.<param_name>=<value>"的形式写在内核启动参数上,如启动内核时加上参数"printk.time=1"与 向"/sys/module/printk/parameters/time"写入1的效果相同; 没有非0属性参数的内联模块不会出现于此。 |
| /sys/power | 这里是系统中电源选项,这个目录下有几个属性文件可以用于控制整个机器的电源状态,如可以向其中写入控制命令让机器关机、重启等。 |
二、 sysfs和Kobject的关系
每一个Kobject,都会对应sysfs中的一个目录。因此在将Kobject添加到Kernel时,create_dir接口会调用sysfs文件系统的创建目录接口,创建和Kobject对应的目录,相关的代码如下:
lib/kobject.c
static int create_dir(struct kobject *kobj)
{
const struct kobj_type *ktype = get_ktype(kobj);
const struct kobj_ns_type_operations *ops;
int error;
error = sysfs_create_dir_ns(kobj, kobject_namespace(kobj));
if (error)
return error;
if (ktype) {
error = sysfs_create_groups(kobj, ktype->default_groups);
if (error) {
sysfs_remove_dir(kobj);
return error;
}
}
/*
* @kobj->sd may be deleted by an ancestor going away. Hold an
* extra reference so that it stays until @kobj is gone.
*/
sysfs_get(kobj->sd);
/*
* If @kobj has ns_ops, its children need to be filtered based on
* their namespace tags. Enable namespace support on @kobj->sd.
*/
ops = kobj_child_ns_ops(kobj);
if (ops) {
BUG_ON(!kobj_ns_type_is_valid(ops->type));
BUG_ON(!kobj_ns_type_registered(ops->type));
sysfs_enable_ns(kobj->sd);
}
return 0;
}fs/sysfs/dir.c
/**
* sysfs_create_dir_ns - create a directory for an object with a namespace tag
* @kobj: object we're creating directory for
* @ns: the namespace tag to use
*/
int sysfs_create_dir_ns(struct kobject *kobj, const void *ns)
{
struct kernfs_node *parent, *kn;
kuid_t uid;
kgid_t gid;
if (WARN_ON(!kobj))
return -EINVAL;
if (kobj->parent)
parent = kobj->parent->sd;
else
parent = sysfs_root_kn;
if (!parent)
return -ENOENT;
kobject_get_ownership(kobj, &uid, &gid);
kn = kernfs_create_dir_ns(parent, kobject_name(kobj), 0755, uid, gid,
kobj, ns);
if (IS_ERR(kn)) {
if (PTR_ERR(kn) == -EEXIST)
sysfs_warn_dup(parent, kobject_name(kobj));
return PTR_ERR(kn);
}
kobj->sd = kn;
return 0;
}三、Attribute
3.1、 Attribute的功能概述
attribute、bin_attribute和attribute_group
前面讲过,属性对应sysfs中的一个文件,那么在sysfs中,为什么会有attribute的概念呢?sysfs中的目录描述了kobject,而kobject是特定数据类型变量(如struct device)的体现。因此kobject的属性,就是这些变量的属性。它可以是任何东西,名称、一个内部变量、一个字符串等等。而attribute,在sysfs文件系统中是以文件的形式提供的,即:kobject的所有属性,都在它对应的sysfs目录下以文件的形式呈现。这些文件一般是可读、写的,而kernel中定义了这些属性的模块,会根据用户空间的读写操作,记录和返回这些attribute的值。
总之,所谓的attibute,就是内核空间和用户空间进行信息交互的一种方法。例如某个driver定义了一个变量,却希望用户空间程序可以修改该变量,以控制driver的运行行为,那么就可以将该变量以sysfs attribute的形式开放出来。
普通属性:include/linux/sysfs.h
struct attribute {
const char *name;
umode_t mode;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
bool ignore_lockdep:1;
struct lock_class_key *key;
struct lock_class_key skey;
#endif
};二进制属性:include/linux/sysfs.h
struct bin_attribute {
struct attribute attr;
size_t size;
void *private;
struct address_space *(*f_mapping)(void);
ssize_t (*read)(struct file *, struct kobject *, struct bin_attribute *,
char *, loff_t, size_t);
ssize_t (*write)(struct file *, struct kobject *, struct bin_attribute *,
char *, loff_t, size_t);
int (*mmap)(struct file *, struct kobject *, struct bin_attribute *attr,
struct vm_area_struct *vma);
};属性组:include/linux/sysfs.h
struct attribute_group {
const char *name;
umode_t (*is_visible)(struct kobject *,
struct attribute *, int);
umode_t (*is_bin_visible)(struct kobject *,
struct bin_attribute *, int);
struct attribute **attrs;
struct bin_attribute **bin_attrs;
};
3.2、sysfs_ops
属性通过sysfs_ops进行读写。include/linux/sysfs.h
struct sysfs_ops {
ssize_t (*show)(struct kobject *, struct attribute *, char *);
ssize_t (*store)(struct kobject *, struct attribute *, const char *, size_t);
};四、sysfs与普通文件系统的关系
sysfs中的目录和文件与kobject和attribute对应,而普通文件系统是file和inode。sysfs在上层也是通过普通的read(),write()等系统调用进行操作的,那么需要将file_operations转换成最终的show()/store()。怎么转?因为属性都是属于kobject的,所以最后的读写肯定与kobject有关,先从kobject找找线索,看前面kobject有个属性-sd,kernfs_node数据结构,是kobject在sysfs的表示。我们从分析这个核心数据结构入手。
kernfs_node:include/linux/kernfs.h
struct kernfs_node {
atomic_t count;
atomic_t active;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
/*
* Use kernfs_get_parent() and kernfs_name/path() instead of
* accessing the following two fields directly. If the node is
* never moved to a different parent, it is safe to access the
* parent directly.
*/
struct kernfs_node *parent;
const char *name;
struct rb_node rb;
const void *ns; /* namespace tag */
unsigned int hash; /* ns + name hash */
union {
struct kernfs_elem_dir dir;
struct kernfs_elem_symlink symlink;
struct kernfs_elem_attr attr;
};
void *priv;
/*
* 64bit unique ID. On 64bit ino setups, id is the ino. On 32bit,
* the low 32bits are ino and upper generation.
*/
u64 id;
unsigned short flags;
umode_t mode;
struct kernfs_iattrs *iattr;
};count、active,相关的计数,原子的。
parent,本节点的父节点,这个比较重要,属性是文件,父节点才是kobject。
name,节点名字。
rb,红黑树节点。
ns、has,命名空间相关。
dir、symlink、attr,节点的类型,表示该节点是目录、符号链接还是属性。三个属性定义在联合体中,我们在这关注是的attr。
priv,私有数据,看到私有数据应该推测,有用的东西就在这里传递,事实也是如此,在本节描述的访问属性的场景下,kobject就作为私有数据随kernfs_node传递。
flags、mode,与文件的相关属性含义一致。
ino,推测是子设备号。
iattr,节点本身的属性。
那么file如何转换成kernfs_node的呢,类比一下,普通文件有file和inode,这里kernfs_node应该是相当于inode,那还应该有代表文件的结构与之对应,没错,是有这个结构。这个结构是什么,不妨先在kernfs_node中找线索。既然我们的研究对象是属性,那就看看联合里的attr对应的数据结构。
kernfs_elem_attr:include/linux/kernfs.h
struct kernfs_elem_attr {
const struct kernfs_ops *ops;
struct kernfs_open_node __rcu *open;
loff_t size;
struct kernfs_node *notify_next; /* for kernfs_notify() */
};
ops,对于kernfs的操作函数。
open,打开的kernfs_node。
size,没有查到用途,不影响分析。
notify_next,通知kernfs文件,具体功能不详,不影响分析。
只关注ops,目前linux中基本所有的操作都独立抽象出了数据结构,这个数据结构应该是操作kernfs的函数。
kernfs_ops:include/linux/kernfs.h
struct kernfs_ops {
/*
* Optional open/release methods. Both are called with
* @of->seq_file populated.
*/
int (*open)(struct kernfs_open_file *of);
void (*release)(struct kernfs_open_file *of);
/*
* Read is handled by either seq_file or raw_read().
*
* If seq_show() is present, seq_file path is active. Other seq
* operations are optional and if not implemented, the behavior is
* equivalent to single_open(). @sf->private points to the
* associated kernfs_open_file.
*
* read() is bounced through kernel buffer and a read larger than
* PAGE_SIZE results in partial operation of PAGE_SIZE.
*/
int (*seq_show)(struct seq_file *sf, void *v);
void *(*seq_start)(struct seq_file *sf, loff_t *ppos);
void *(*seq_next)(struct seq_file *sf, void *v, loff_t *ppos);
void (*seq_stop)(struct seq_file *sf, void *v);
ssize_t (*read)(struct kernfs_open_file *of, char *buf, size_t bytes,
loff_t off);
/*
* write() is bounced through kernel buffer. If atomic_write_len
* is not set, a write larger than PAGE_SIZE results in partial
* operations of PAGE_SIZE chunks. If atomic_write_len is set,
* writes upto the specified size are executed atomically but
* larger ones are rejected with -E2BIG.
*/
size_t atomic_write_len;
/*
* "prealloc" causes a buffer to be allocated at open for
* all read/write requests. As ->seq_show uses seq_read()
* which does its own allocation, it is incompatible with
* ->prealloc. Provide ->read and ->write with ->prealloc.
*/
bool prealloc;
ssize_t (*write)(struct kernfs_open_file *of, char *buf, size_t bytes,
loff_t off);
__poll_t (*poll)(struct kernfs_open_file *of,
struct poll_table_struct *pt);
int (*mmap)(struct kernfs_open_file *of, struct vm_area_struct *vma);
};prealloc,设置了用mmap,不设置用read/write。因为read/wirte有自己的buf,与prealloc的buf不兼容。
seq_show、seq_start、seq_next、seq_stop,顺序文件操作。下面会详细分析。这里需要关注他们的参数。
read、write、mmap,读,写,内存映射函数,这里关注他们的参数。
看一下seq_xx和read的原型,参数分别为seq_file和kernfs_open_file。从名字上看kernfs_open_file和kernfs_node的关系,很像file和inode的关系。不妨先看看kernfs_open_file。
kernfs_open_file:include/linux/kernfs.h
struct kernfs_open_file {
/* published fields */
struct kernfs_node *kn;
struct file *file;
struct seq_file *seq_file;
void *priv;
/* private fields, do not use outside kernfs proper */
struct mutex mutex;
struct mutex prealloc_mutex;
int event;
struct list_head list;
char *prealloc_buf;
size_t atomic_write_len;
bool mmapped:1;
bool released:1;
const struct vm_operations_struct *vm_ops;
};kn,所属的目录节点。
file,代表打开文件。
priv,私有数据结构。
mutex,互斥体。
list,确实没有查到在哪里调用,暂时推测不出用途,不影响分析。
pralloc_buf,mmap使用。
atomic_write_len,同kernfs_elem_attr。
mmaped,是否已经进行了ioremap。
vm_ops,虚拟内存管理操作。
从核心类的成员可能得出这样的推测,kernfs_open_file.file存储普通文件的file指针,在进行读写是用container_of()从file里获得kernfs_open_file结构体。以前的内核可能是这么做的,但是现在不是这样的。这里要提到上面数的另一个核心数据结构seq_file。
seq_file:include/linux/seq_file.h
seq_file是为proc文件系统设计的,来历是这样的,由于procfs的默认操作函数只使用一页的缓存,在处理较大的proc文件时就有点麻烦,并且在输出一系列结构体中的数据时也比较不灵活,需要自己在read_proc函数中实现迭代,容易出现Bug。所以内核黑客们对一些/proc代码做了研究,抽象出共性,最终形成了seq_file(Sequence file:序列文件)接口。 这个接口提供了一套简单的函数来解决以上proc接口编程时存在的问题,使得编程更加容易,降低了Bug出现的机会。
不只是proc,在需要创建一个由一系列数据顺序组合而成的虚拟文件或一个较大的虚拟文件时,推荐使用seq_file接口。这正是符合bin_attribute的场景。看一下seq_file的结构。
struct seq_file {
char *buf;
size_t size;
size_t from;
size_t count;
size_t pad_until;
loff_t index;
loff_t read_pos;
struct mutex lock;
const struct seq_operations *op;
int poll_event;
const struct file *file;
void *private;
};这个结构的成员与file差不多,基本不用关心,因为他们都是使用op成员定义的方法操作的,一定意义上可以看作私有成员。
需要注意的是结构里有个private,这么多回了应该有这个意识了,看见private就有可能跟我们结构挂上关系。事实也是如此。kernfs_open_file的指针是放到seq_file的private中的。
从file到attribute
至此只剩seq_file如何与普通的file联系在一起了,那就简单了,跟大部分驱动程序是一样的,seq_file包含在file的private_data中。整合上述关系,可以在下面类图中表示。
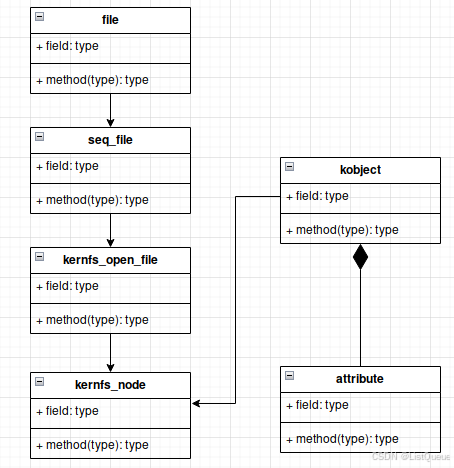
从file找到sysfs的属性文件,经历了很长的链条,这个其实是多态,由于c语言的特性,linux驱动程序用了很费劲的方式实现了多态。
上边这个可能还是抽象一点,把ops族对象加入跟为直观,忽略一些中间环节。
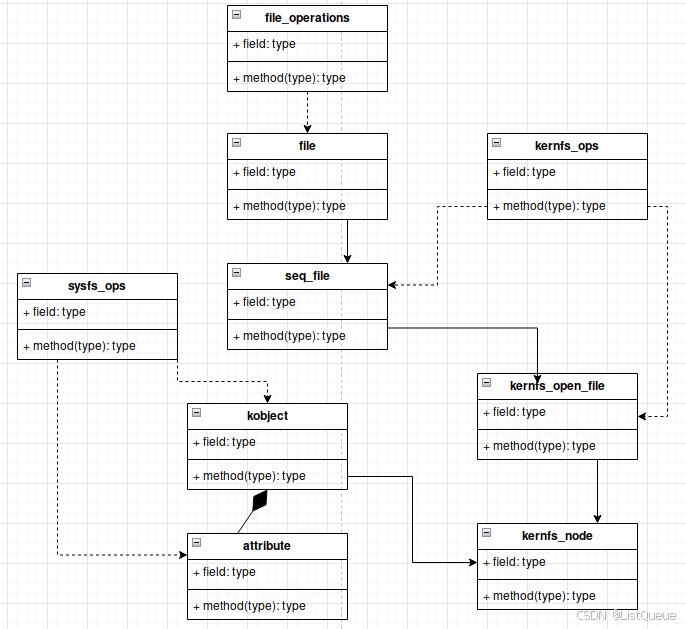
从操作上,从VFS的fs到sysfs经历了file_operations域,kernfs_ops域和最终的sys_ops域的转换。

















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









