







备注:内核版本:5.4
分析动力:弄清楚poll() sysfs 属性文件时fd.events使用那些event masks才是正确的,及错误使用event masks 的情况下poll() 无法阻塞的原因
/* Epoll event masks */
#define EPOLLIN (__force __poll_t)0x00000001
#define EPOLLPRI (__force __poll_t)0x00000002
#define EPOLLOUT (__force __poll_t)0x00000004
#define EPOLLERR (__force __poll_t)0x00000008
#define EPOLLHUP (__force __poll_t)0x00000010
#define EPOLLNVAL (__force __poll_t)0x00000020
#define EPOLLRDNORM (__force __poll_t)0x00000040
#define EPOLLRDBAND (__force __poll_t)0x00000080
#define EPOLLWRNORM (__force __poll_t)0x00000100
#define EPOLLWRBAND (__force __poll_t)0x00000200
#define EPOLLMSG (__force __poll_t)0x00000400
#define EPOLLRDHUP (__force __poll_t)0x00002000一、poll系统调用
//select.c (msm-5.4\fs)
SYSCALL_DEFINE3(poll, struct pollfd __user *, ufds, unsigned int, nfds, int, timeout_msecs)
|--> do_sys_poll(ufds, nfds, to);
static int do_sys_poll(struct pollfd __user *ufds, unsigned int nfds,
struct timespec64 *end_time)
{
struct poll_wqueues table;
后面重点分析下面2个函数
|--> poll_initwait(&table); 1.1 小结分析
|-->fdcount = do_poll(head, &table, end_time); 1.2 小结分析相关重要结构体
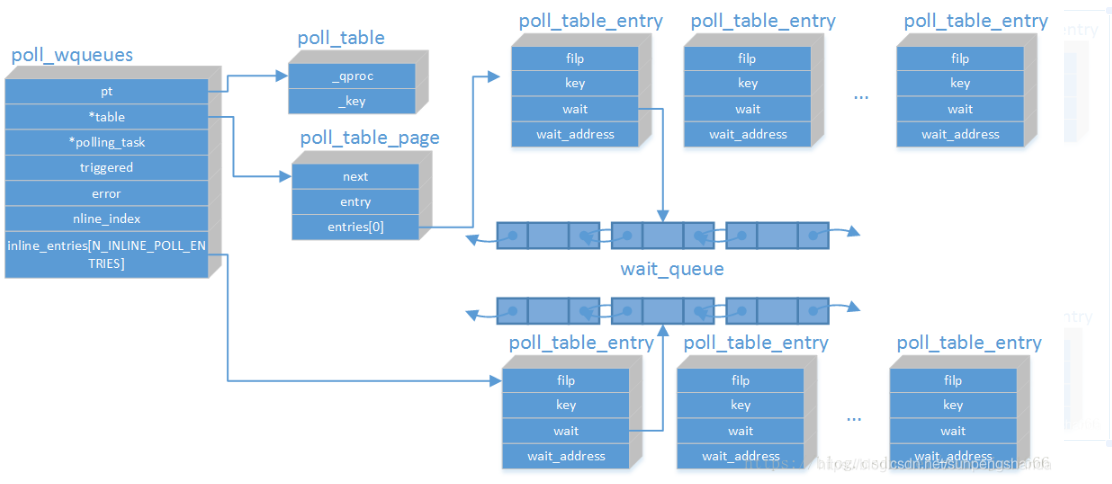
/*
* Structures and helpers for select/poll syscall
*/
struct poll_wqueues { // 这个结构体每一次poll的时候创建一个
poll_table pt; //该结构体中存放一个函数指针_qproc, 和key,_qproc是在驱动中的file_operations的poll()函数中调用
struct poll_table_page *table;
struct task_struct *polling_task; //保存当前调用进程的task_struct结构体
int triggered;
int error;
int inline_index;
struct poll_table_entry inline_entries[N_INLINE_POLL_ENTRIES];
};
/*
* Do not touch the structure directly, use the access functions
* poll_does_not_wait() and poll_requested_events() instead.
*/
typedef struct poll_table_struct {
poll_queue_proc _qproc;
__poll_t _key;
} poll_table;
struct poll_table_page {
struct poll_table_page * next;
struct poll_table_entry * entry;
struct poll_table_entry entries[0];
};
struct poll_table_entry {
struct file *filp;
__poll_t key;
wait_queue_entry_t wait;
wait_queue_head_t *wait_address;
};网上找的一张画的很好的结构体关系图
2. poll_initwait(&table)分析
/* 初始化poll_wqueues */
void poll_initwait(struct poll_wqueues *pwq)
{
init_poll_funcptr(&pwq->pt, __pollwait); //将poll_wqueues中poll_table赋值,如下1.1.1小结,记住__pollwait 这个函数,这个会各模块驱动中file_operations 的poll函数关联
pwq->polling_task = current;
pwq->triggered = 0;
pwq->error = 0;
pwq->table = NULL;
pwq->inline_index = 0;
}
1.1.1小结
static inline void init_poll_funcptr(poll_table *pt, poll_queue_proc qproc)
{
pt->_qproc = qproc;
pt->_key = ~(__poll_t)0; /* all events enabled */
}3. do_poll(head, &table, end_time)分析
static int do_poll(struct poll_list *list, struct poll_wqueues *wait,
struct timespec64 *end_time)
{
poll_table* pt = &wait->pt;
ktime_t expire, *to = NULL;
int timed_out = 0, count = 0;
......
for (;;) {
struct poll_list *walk;
bool can_busy_loop = false;
for (walk = list; walk != NULL; walk = walk->next) {
struct pollfd * pfd, * pfd_end;
pfd = walk->entries;
pfd_end = pfd + walk->len;
for (; pfd != pfd_end; pfd++) {
/*
* Fish for events. If we found one, record it
* and kill poll_table->_qproc, so we don't
* needlessly register any other waiters after
* this. They'll get immediately deregistered
* when we break out and return.
*/
if (do_pollfd(pfd, pt, &can_busy_loop, busy_flag)) ################1.2.1小结重点分析, 需要注意do_pollfd 的返回值,返回值非0表示有事件
{
count++; #### 有事件count++,这个也就是应用层poll()的返回值
pt->_qproc = NULL;
/* found something, stop busy polling */
busy_flag = 0;
can_busy_loop = false;
}
}
}
/*
* All waiters have already been registered, so don't provide
* a poll_table->_qproc to them on the next loop iteration.
*/
pt->_qproc = NULL;
if (!count) {
count = wait->error;
if (signal_pending(current))
count = -ERESTARTNOHAND;
}
if (count || timed_out) ###### 如果有事件或者,直接就break了,也就上层poll()函数调用返回
break;
...............
if (!poll_schedule_timeout(wait, TASK_INTERRUPTIBLE, to, slack)) ###### 上层进程睡眠在这个函数,当事件notify或者超时,退出,并进入下一次循环,再执行do_pollfd()
timed_out = 1;
}
return count;
}
1.2.1小结do_pollfd分析
static inline __poll_t do_pollfd(struct pollfd *pollfd, poll_table *pwait,
bool *can_busy_poll, __poll_t busy_flag)
{
int fd = pollfd->fd;
__poll_t mask = 0, filter;
struct fd f;
f = fdget(fd);
/* userland u16 ->events contains POLL... bitmap */
filter = demangle_poll(pollfd->events) | EPOLLERR | EPOLLHUP; ### 上层传下来的 需要监听的事件event masks
如:drm poll_fds_[i].events = POLLIN | POLLPRI | POLLERR;
### 注意: sysfs 属性文件节点poll只能使用 fd.events = POLLPRI | POLLERR, 不能包含(EPOLLIN | EPOLLOUT | EPOLLRDNORM | EPOLLWRNORM)
为什么,这和驱动代码的file_operations的poll()返回值强相关
pwait->_key = filter | busy_flag;
mask = vfs_poll(f.file, pwait); // 获驱动poll()函数返回值
if (mask & busy_flag)
*can_busy_poll = true;
mask &= filter; /* Mask out unneeded events. */
fdput(f);
out:
/* ... and so does ->revents */
pollfd->revents = mangle_poll(mask);
return mask;
}
static inline __poll_t vfs_poll(struct file *file, struct poll_table_struct *pt)
{
if (unlikely(!file->f_op->poll))
return DEFAULT_POLLMASK;
return file->f_op->poll(file, pt); ######## 如: sysfs属性文件 kernfs_fop_poll,其他设备节点看自己实现的poll函数,需要关注驱动poll()函数的返回值
}
kernfs_fop_poll(struct file *filp, poll_table *wait)
|-->ret = kernfs_generic_poll(of, wait);
/*
* Kernfs attribute files are pollable. The idea is that you read
* the content and then you use 'poll' or 'select' to wait for
* the content to change. When the content changes (assuming the
* manager for the kobject supports notification), poll will
* return EPOLLERR|EPOLLPRI, and select will return the fd whether
* it is waiting for read, write, or exceptions.
* Once poll/select indicates that the value has changed, you
* need to close and re-open the file, or seek to 0 and read again.
* Reminder: this only works for attributes which actively support
* it, and it is not possible to test an attribute from userspace
* to see if it supports poll (Neither 'poll' nor 'select' return
* an appropriate error code). When in doubt, set a suitable timeout value.
*/ 注意看函数的注释,kernfs 属性文件可poll,可使用 'poll' or 'select'等待属性文件内容改变去read 属性的内容,注意poll()返回EPOLLERR|EPOLLPRI
__poll_t kernfs_generic_poll(struct kernfs_open_file *of, poll_table *wait)
{
struct kernfs_node *kn = kernfs_dentry_node(of->file->f_path.dentry);
struct kernfs_open_node *on = kn->attr.open;
poll_wait(of->file, &on->poll, wait);
if (of->event != atomic_read(&on->event))
return DEFAULT_POLLMASK|EPOLLERR|EPOLLPRI; // sysfs_notify 会atomic_inc(&on->event);,所以不等,有事件的时候在这返回
return DEFAULT_POLLMASK; // 没有事件在这返回 #define DEFAULT_POLLMASK (EPOLLIN | EPOLLOUT | EPOLLRDNORM | EPOLLWRNORM)
}
再分析一下poll_wait,很多人看函数名字,以为poll()调用阻塞在这个函数,其实不然
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p);//记得上面提到过要记住_qproc,_qproc就是__pollwait
}
/* Add a new entry */ 看注释也知道,只是加到链表
static void __pollwait(struct file *filp, wait_queue_head_t *wait_address,
poll_table *p)
{
struct poll_wqueues *pwq = container_of(p, struct poll_wqueues, pt);
struct poll_table_entry *entry = poll_get_entry(pwq);
if (!entry)
return;
entry->filp = get_file(filp);
entry->wait_address = wait_address;
entry->key = p->_key;
init_waitqueue_func_entry(&entry->wait, pollwake);
entry->wait.private = pwq;
add_wait_queue(wait_address, &entry->wait);
}
static inline void
init_waitqueue_func_entry(struct wait_queue_entry *wq_entry, wait_queue_func_t func)
{
wq_entry->flags = 0;
wq_entry->private = NULL;
wq_entry->func = func;
}
void add_wait_queue(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry)
{
unsigned long flags;
wq_entry->flags &= ~WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&wq_head->lock, flags);
__add_wait_queue(wq_head, wq_entry);
spin_unlock_irqrestore(&wq_head->lock, flags);
}
static inline void __add_wait_queue(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry)
{
list_add(&wq_entry->entry, &wq_head->head);
}如果不清楚kernfs_fop_poll是怎么绑定的,请看上一篇sysfs device_attribute节点的创建和读写分析
4. 为什么 sysfs 属性文件event masks 只能使用fd.events = POLLPRI | POLLERR
__poll_t kernfs_generic_poll(struct kernfs_open_file *of, poll_table *wait)
{
struct kernfs_node *kn = kernfs_dentry_node(of->file->f_path.dentry);
struct kernfs_open_node *on = kn->attr.open;
poll_wait(of->file, &on->poll, wait);
if (of->event != atomic_read(&on->event))
return DEFAULT_POLLMASK|EPOLLERR|EPOLLPRI; // sysfs_notify 会atomic_inc(&on->event);,所以不等,有事件的时候在这返回
return DEFAULT_POLLMASK; // 没有事件在这返回 #define DEFAULT_POLLMASK (EPOLLIN | EPOLLOUT | EPOLLRDNORM | EPOLLWRNORM)
}
1、sysfs 属性文件内容没有变化的时候返回的是 (EPOLLIN | EPOLLOUT | EPOLLRDNORM | EPOLLWRNORM)
2、内容变化sysfs_notify后返回的是DEFAULT_POLLMASK|EPOLLERR|EPOLLPRI
do_pollfd函数中,我只截取相关代码
filter = demangle_poll(pollfd->events) | EPOLLERR | EPOLLHUP; ### 上层传下来的 需要监听的事件event masks
pwait->_key = filter | busy_flag;
mask = vfs_poll(f.file, pwait); // 获驱动poll()函数返回值:
1、内容没有变化时返回: (EPOLLIN | EPOLLOUT | EPOLLRDNORM | EPOLLWRNORM)
2、内容变化时返回:DEFAULT_POLLMASK|EPOLLERR|EPOLLPRI
mask &= filter; //如果应用层fd.events 包含了(EPOLLIN | EPOLLOUT | EPOLLRDNORM | EPOLLWRNORM)中的任意一个,
//mask最后都是非0,返回非0上一级函数do_poll就认为有事件,count++;直接就break,所以应用层的poll()直接就退出了,没有阻塞住。
pollfd->revents = mangle_poll(mask);
return mask;
如果sysfs 属性文件poll() 应用层正确配置event masks,使用:fd.events = POLLPRI | POLLERR
filter = POLLPRI | POLLERR | EPOLLHUP
1、内容没有变化的返回: mask = vfs_poll(f.file, pwait) 返回(EPOLLIN | EPOLLOUT | EPOLLRDNORM | EPOLLWRNORM)
mask &= filter 为
mask = (EPOLLIN | EPOLLOUT | EPOLLRDNORM | EPOLLWRNORM) & (POLLPRI | POLLERR | EPOLLHUP) 是0
2、内容变化时返回:mask = vfs_poll(f.file, pwait) 返回 DEFAULT_POLLMASK|EPOLLERR|EPOLLPRI = (EPOLLIN | EPOLLOUT | EPOLLRDNORM | EPOLLWRNORM) |EPOLLERR|EPOLLPRI
mask &= filter 为
mask = ((EPOLLIN | EPOLLOUT | EPOLLRDNORM | EPOLLWRNORM) |EPOLLERR|EPOLLPRI) & (POLLPRI | POLLERR | EPOLLHUP) 是 POLLPRI | POLLERR 非0二、sysfs_notify 通知
sysfs 属性文件内容改变,通过sysfs_notify 通知,唤醒应用层poll()阻塞的进程
void sysfs_notify(struct kobject *kobj, const char *dir, const char *attr)
{
struct kernfs_node *kn = kobj->sd, *tmp;
if (kn && dir)
kn = kernfs_find_and_get(kn, dir);
else
kernfs_get(kn);
if (kn && attr) {
tmp = kernfs_find_and_get(kn, attr);
kernfs_put(kn);
kn = tmp;
}
if (kn) {
kernfs_notify(kn);
kernfs_put(kn);
}
}
EXPORT_SYMBOL_GPL(sysfs_notify);
void kernfs_notify(struct kernfs_node *kn)
{
static DECLARE_WORK(kernfs_notify_work, kernfs_notify_workfn);
unsigned long flags;
struct kernfs_open_node *on;
if (WARN_ON(kernfs_type(kn) != KERNFS_FILE))
return;
/* kick poll immediately */
spin_lock_irqsave(&kernfs_open_node_lock, flags);
on = kn->attr.open;
if (on) {
atomic_inc(&on->event); ############
wake_up_interruptible(&on->poll);
}
spin_unlock_irqrestore(&kernfs_open_node_lock, flags);
/* schedule work to kick fsnotify */
spin_lock_irqsave(&kernfs_notify_lock, flags);
if (!kn->attr.notify_next) {
kernfs_get(kn);
kn->attr.notify_next = kernfs_notify_list;
kernfs_notify_list = kn;
schedule_work(&kernfs_notify_work);
}
spin_unlock_irqrestore(&kernfs_notify_lock, flags);
}
EXPORT_SYMBOL_GPL(kernfs_notify);三、总结:sysfs属性文件poll()
sysfs 属性文件在应用层使用poll()阻塞访问时:
1、应用层必须使用fd.events = POLLPRI | POLLERR 或者fd.events = POLLPRI
2、kenrel 驱动层必须在sysfs 属性文件内容变化的时候使用kernfs_notify或者sysfs_notify_dirent唤醒,不然应用层的这个线程会一直在sleep状态
使用举例请上一篇:sysfs device_attribute节点的创建和读写分析
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











