







系列文章目录
第一章 线性表
第二章 栈与队列
第三章 串
第四章 数组与广义表
文章目录
前言
数组和广义表,可以看成是一种扩展的线性数据结构,其特殊性不像栈和队列那样表现在对数据元素的操作受限制,而是反映在数据元素的构成上。在线性表中,每个数据元素都是不可再分的原子类型,而数组和广义表中的数据元素可以推广到一种具有特定结构的数据。本章以抽象数据类型的形式讨论数组和广义表的逻辑定义、存储结构、操作的实现,加以对这两种特殊的线性结构的理解。
一、数组
1.什么是数组?
数组 :每个子结构是由基本元素组成的大小均等的线性表。
2. 数组结构的顺序存储结构*
数组结构是多维的,内存地址是一维的。
存储方式:行主序,列主序
以行主序为例:
一维: LOC(ai) =base+i
二维(MxN): LOC(ai,j) =base+iN +j
三维(MxNxP): LOC(ai,j,k) =base+iNP +jP +k
四维(MxNxPxQ):LOC(ai,j,k,l)=base+iNPQ+jPQ+kQ+l
Typedef struct
{ ElemType *base;
int dim; 维数
int *bounds; 各维元素个数
int *constants; 各维包含的基本元素个数
}Array;
例:数组A[3,4,5,6]的存储结构
A.dim=4
A.bounds[]={3,4,5,6}
A.constants[]={120,30,6,1}
A[i,j,k,l]的地址: A.base+(i120+j30+k*6+l)
二、矩阵的压缩存储
1.特殊矩阵
(1)对称矩阵
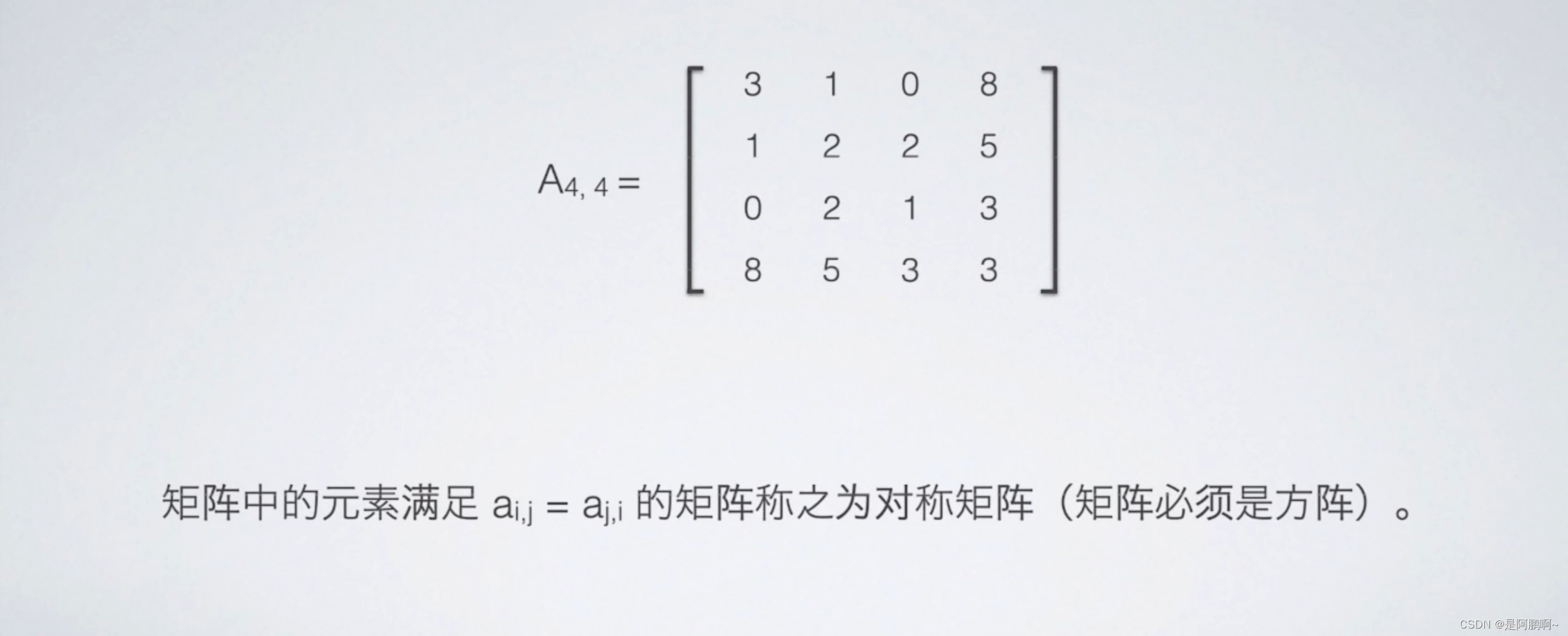

NxN矩阵的存储结构:S[N(N+1)/2]。
以行主序的方式存储下三角元素:
若i>=j: k=i*(i+1)/2+j
若i< j: k=j*(j+1)/2+i

(2)(上/下)三角矩阵
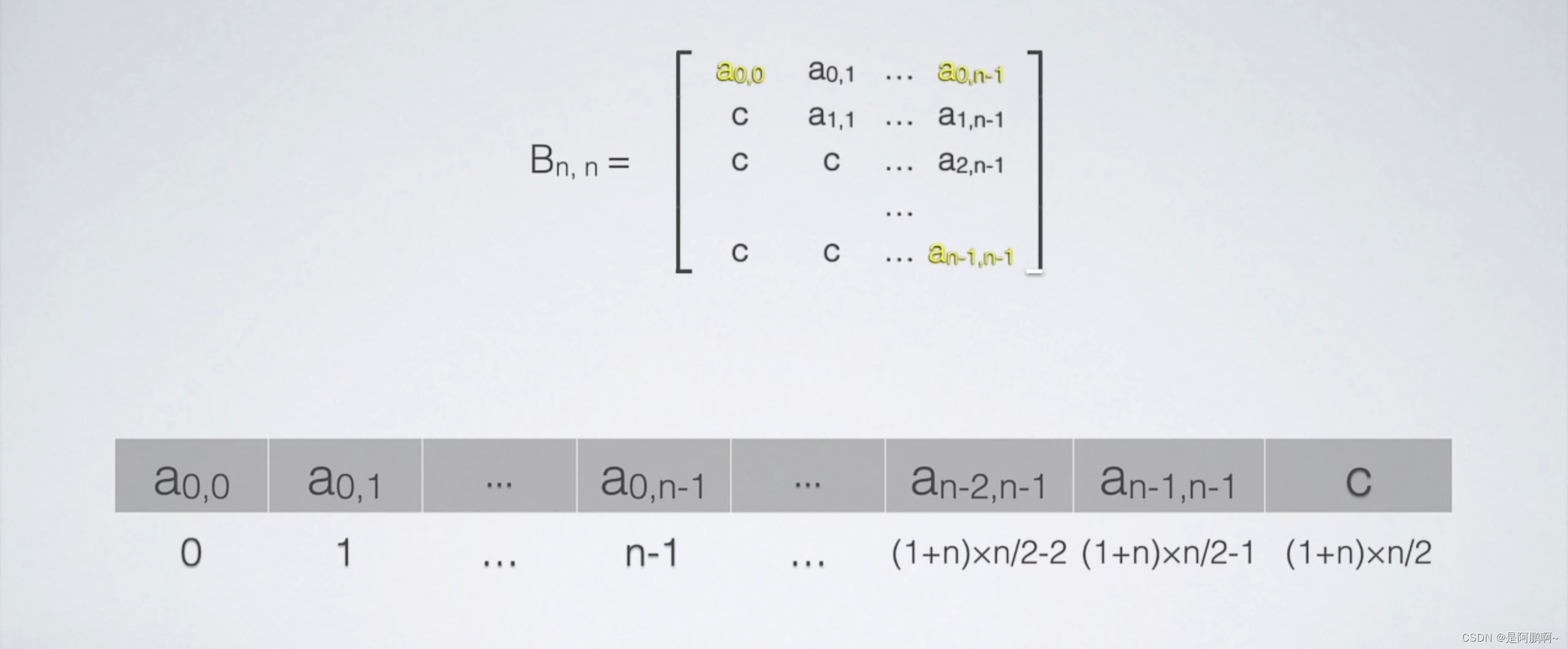
例:设N阶对称矩阵A存储为一维数组S[N(N+1)/2],以行主序的方式存储A的下三角,则元素A[3][5]的存储位置是?

(3)对角矩阵
对角矩阵(diagonal matrix)是一个主对角线之外的元素皆为0的矩阵。对角线上的元素可以为0或其他值。也常写为diag(a1,a2,…,an) 值得一提的是:对角线上的元素可以为 0 或其他值。
因此 n 行 n 列的矩阵 = (ai,j) 若符合以下的性质:ai,j=0且i ≠j,则矩阵为对角矩阵。对角线上全部是0的矩阵是特殊的对角矩阵,不过一般称为零矩阵。
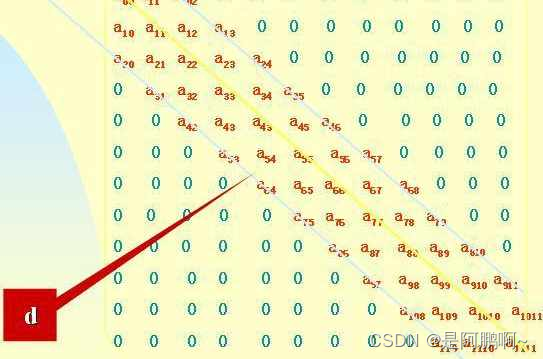
非0元素的分布:以主对角线为中心的带状区域。
半带宽为d,带宽为2d+1。
非0元素个数:(2d+1)n-(1+d)d
存储方案:S[(2d+1)n],扩展了上下二个三角区域。
aij => S[k], k=i(2d+1)+d+(j-i)
改进方案:S[(2d+1)n-2d],去掉数组前后2d个0。
aij => S[k], k=i(2d+1)+(j-i)


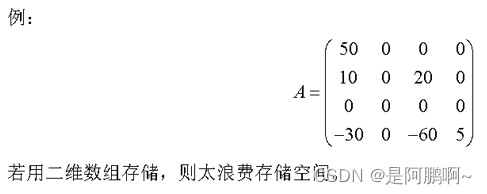
(4)稀疏矩阵
稀疏矩阵:若矩阵A中非0元素的个数远远小于零元素的个数,则称A为稀疏矩阵
三元组表示法
将稀疏矩阵存储在二维数组中
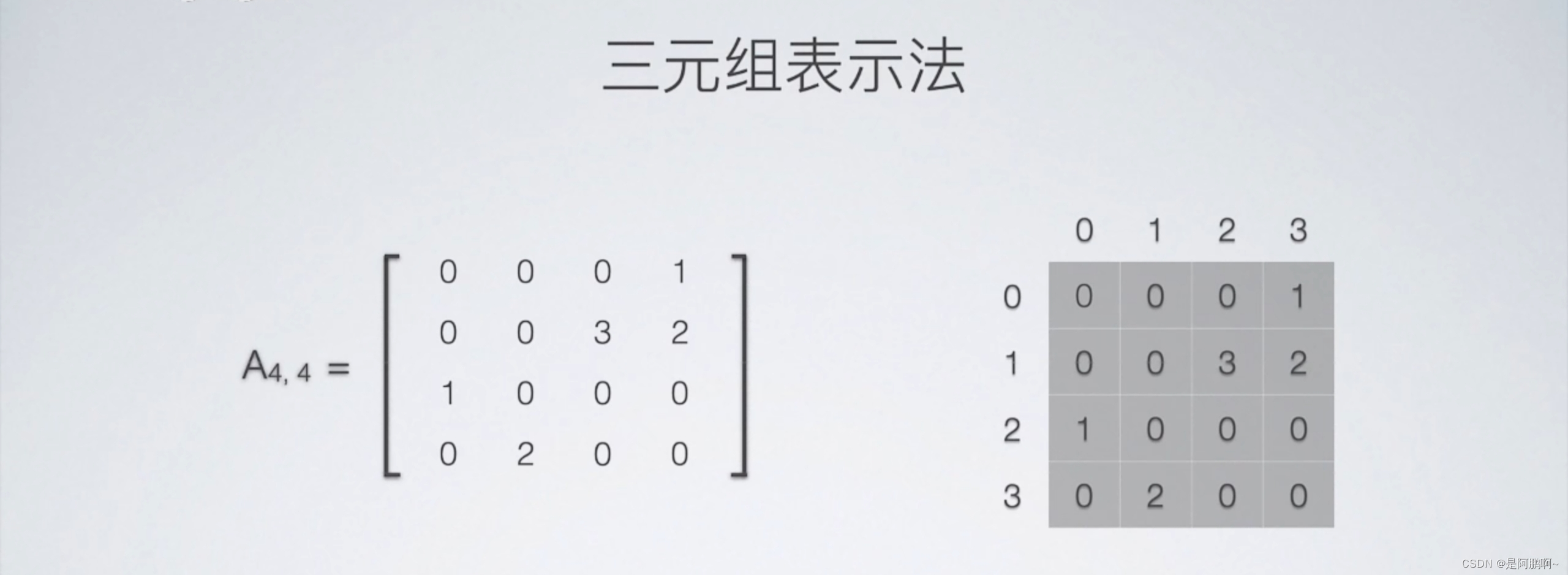
将二维数组对应位置的值,转换到三元组表中,其中第一行不存值
第一行 00位置 代表有几个非零元素
01位置 代表有几行 02 位置代表有几列
剩下的从第1行开始按行主序
0列填入元素值
1列填入元素所在行
2列填入元素所在行列
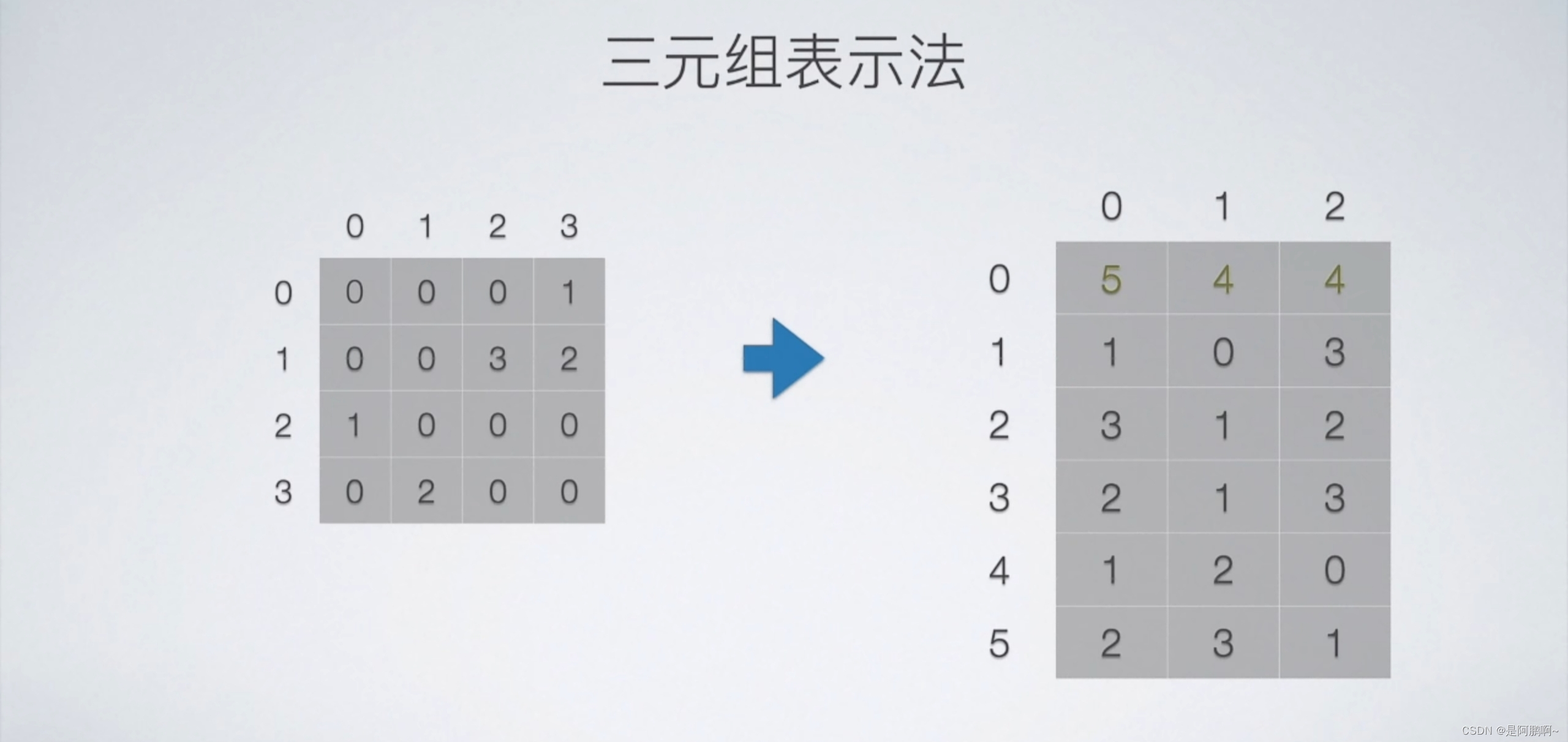
三元组结构表示
typedef struct{
float val;
int i,j;
}Trimat
Trimat trimat[maxsize+1];
//取值方法
float val = trimat[k].val;
int i = trimat[k].i;
int j = trimat[k].j;
三元组的顺序表结构
#define MAXSIZE 1000
typedef struct //三元组结构
{ int i,j;
ElemType e;
}Triple;
typedef struct //三元组顺序表(按行主序)
{ int mu,nu,tu;
Triple data[MAXSIZE];//静态顺序表
/* Triple *data; 动态顺序表 */
}TSMatrix;
稀疏矩阵的顺序表示
其中 mu代表行 nu 代表列 tu 代表非零元素的个数

三元组的转置运算M=>T (以T为中心)
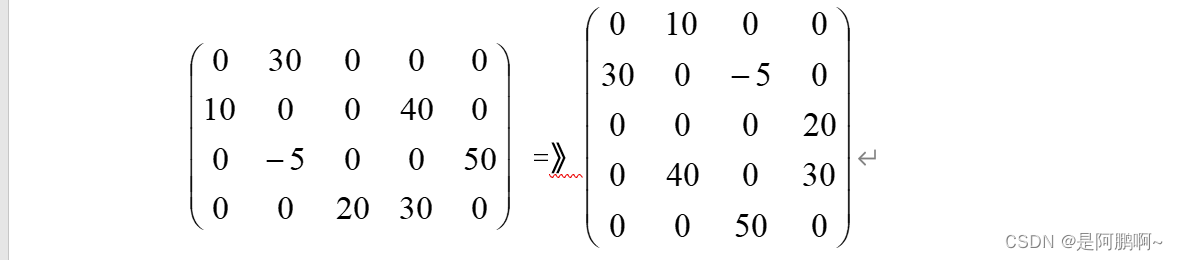
根据转置后的结果画转置后的顺序表
| i | j | e | i | j | e | |
|---|---|---|---|---|---|---|
| 0 | 1 | 30 | 0 | 1 | 10 | |
| 1 | 0 | 10 | 1 | 0 | 30 | |
| 1 | 3 | 40 | 1 | 2 | -5 | |
| 2 | 1 | -5 | => | 2 | 3 | 20 |
| 2 | 4 | 50 | 3 | 1 | 40 | |
| 3 | 2 | 20 | 3 | 3 | 30 | |
| 3 | 3 | 30 | 4 | 2 | 50 |
代码实现转置
Status TSMatrix_Transpose(TSMatrix M,TSMatrix &T)
{ int k,col,i;
T.mu=M.nu; T.nu=M.mu; T.tu=M.tu;
if(T.tu==0) return(OK);
for(k=0,col=0; col<M.nu; col++) //找M中所有列
for(i=0; i<M.tu; i++)
if(M.data[i].j==col)
{ T.data[k].i=M.data[i].j;
T.data[k].j=M.data[i].i;
T.data[k].e=M.data[i].e; k++;
}
return(OK);
}
思考:时间复杂度:
若M有n列,有t个非0数:为O(nt)。
若t≈mn: 为O(nmn)。
三元组的快速转置运算M=>T (以T为中心)
辅助数据结构:
num[]:M中每列(T中每行)的三元组个数。
=> pos[]:T中每行第一个三元组的下标。
pos[0]=0;
pos[j]=pos[j-1]+num[j-1]; j∈[1,M.nu-1]

快速转置讲解

小练习
答案:

快速转置代码如下:(不是强制要求)*
Status TSMatrix_FastTranspose(TSMatrix M,TSMatrix &T)
{ int i,j,k,num[MAX],pos[MAX];
T.mu=M.nu; T.nu=M.mu; T.tu=M.tu;
if(T.tu==0) return(OK);
//统计M中每列的三元组个数
for(i=0;i<M.nu;i++) num[i]=0;
for(i=0;i<M.tu;i++) num[M.data[i].j]++;
//计算pos数组
for(pos[0]=0,i=1;i<M.nu;i++)
pos[i]=pos[i-1]+num[i-1];
//快速转置
for(i=0;i<M.tu;i++)
{ col=M.data[i].j; loc=pos[col];
T.data[loc].i=M.data[i].j;
T.data[loc].j=M.data[i].i;
T.data[loc].e=M.data[i].e; pos[col]++;
}
return(OK);
}
思考:时间复杂度:
若M有n列,有t个非0数:循环次数:n+t+n+t
若t≈mn: 为O(mn)。
空间复杂度:2个数组(n+n个单元),O(n)。
三、广义表
1.什么是广义表?
广义表又称列表,也是一种线性存储结构,通数组类似,广义表中即可存储不可再分的元素也能存储可在分元素。线性表的扩展,每个元素的结构不等。
GList={a1,a2,…,an | ai∈AtomSet或ai∈GList}
ai∈AtomSet:ai为原子
ai∈Glist :ai为子表
数据关系:顺序关系、层次关系。
a1为表头(head)元素, 其余为表尾(tail)。
应用实例:Lisp语言、前缀表达式
(setq x (+ 4 (- a b)) y (+ 3 4) )
表头:函数名; 表尾:参数表
例如:数组中可以存储‘a’、3这样的字符或数字,也能存储数组,比如二维数组、三维数组,数组都是可在分成子元素的。广义表也是如此,但与数组不同的是,在广义表中存储的数据是既可以再分也可以不再分的,形如:{1,{1,2,3}}。
如果创建一个二维数组来存储{1,{1,2,3}}。在存储上确实可以实现,但无疑会造成存储空间的浪费。
广义表记作:
LS = (a1,a2,…,an)
2.原子和子表
广义表中存储的单个元素称为 “原子”,而存储的广义表称为 “子表”。
例如创建一个广义表 LS = {1,{1,2,3}},我们可以这样解释此广义表的构成:广义表 LS 存储了一个原子 1 和子表 {1,2,3}。
以下是广义表存储数据的一些常用形式:
- A = ():A 表示一个广义表,只不过表是空的。
- B = (e):广义表 B 中只有一个原子 e。
- C = (a,(b,c,d)) :广义表 C 中有两个元素,原子 a 和子表 (b,c,d)。
- D = (A,B,C):广义表 D 中存有 3 个子表,分别是A、B和C。这种表示方式等同于 D = ((),(e),(b,c,d)) 。
- E = (a,E):广义表 E 中有两个元素,原子 a 和它本身。这是一个递归广义表,等同于:E = (a,(a,(a,…)))。
注意,A = () 和 A = (()) 是不一样的。前者是空表,而后者是包含一个子表的广义表,只不过这个子表是空表。
3.表头和表尾
当广义表不是空表时,称第一个数据(原子或子表)为"表头",剩下的数据构成的新广义表为"表尾"。
强调一下,除非广义表为空表,否则广义表一定具有表头和表尾,且广义表的表尾一定是一个广义表。
例如在广义表中 LS={1,{1,2,3},5} 中,表头为原子 1,表尾为子表 {1,2,3} 和原子 5 构成的广义表,即 {{1,2,3},5}。
再比如,在广义表 LS = {1} 中,表头为原子 1 ,但由于广义表中无表尾元素,因此该表的表尾是一个空表,用 {} 表示。
4.广义表的存储结构
typedef enum {ATOM,LIST} ElemTag;
typedef struct GLNode
{
ElemTag tag; //区别子表结点、原子结点
union
{ AtomType atom;
struct GLNode *child; //指向子表的指针、
}UNION;
struct GLNode *next; //后继指针
}GLNODE, *Glist;
5.绘制存储结构(考点)
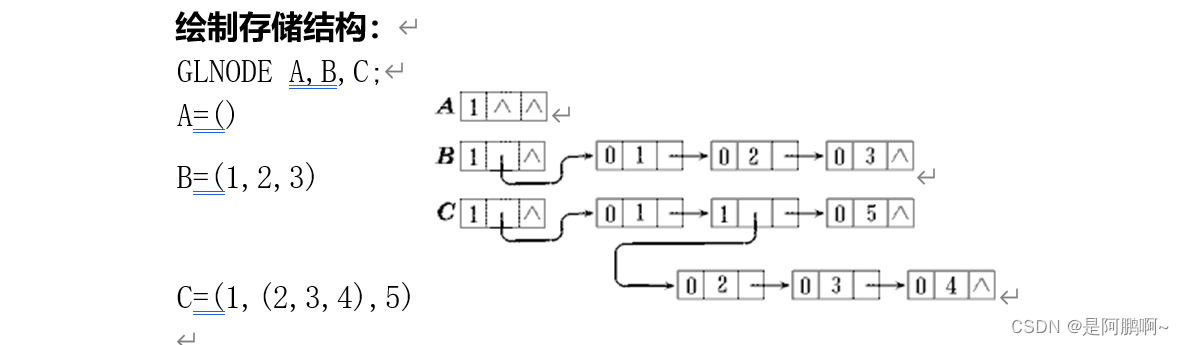
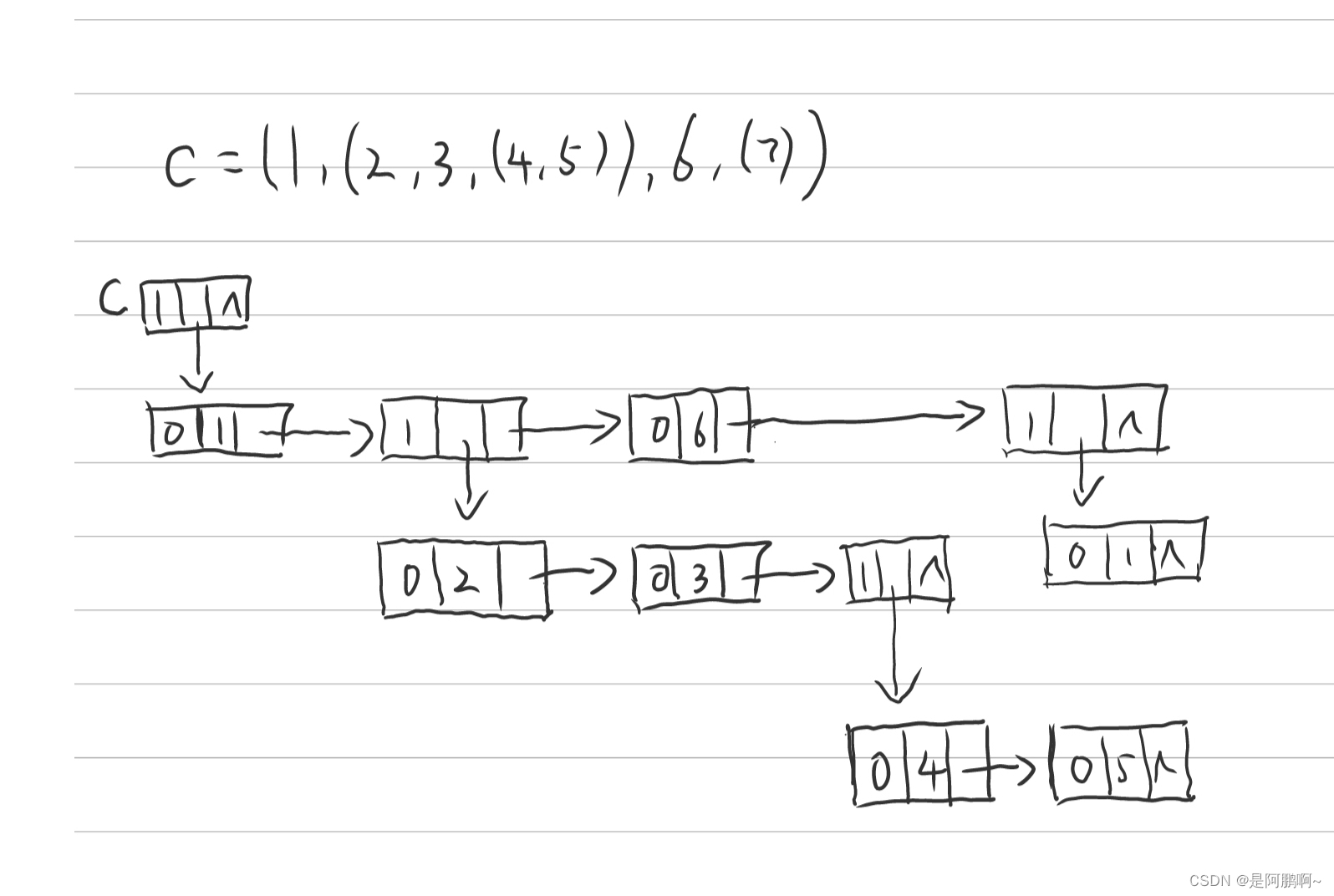
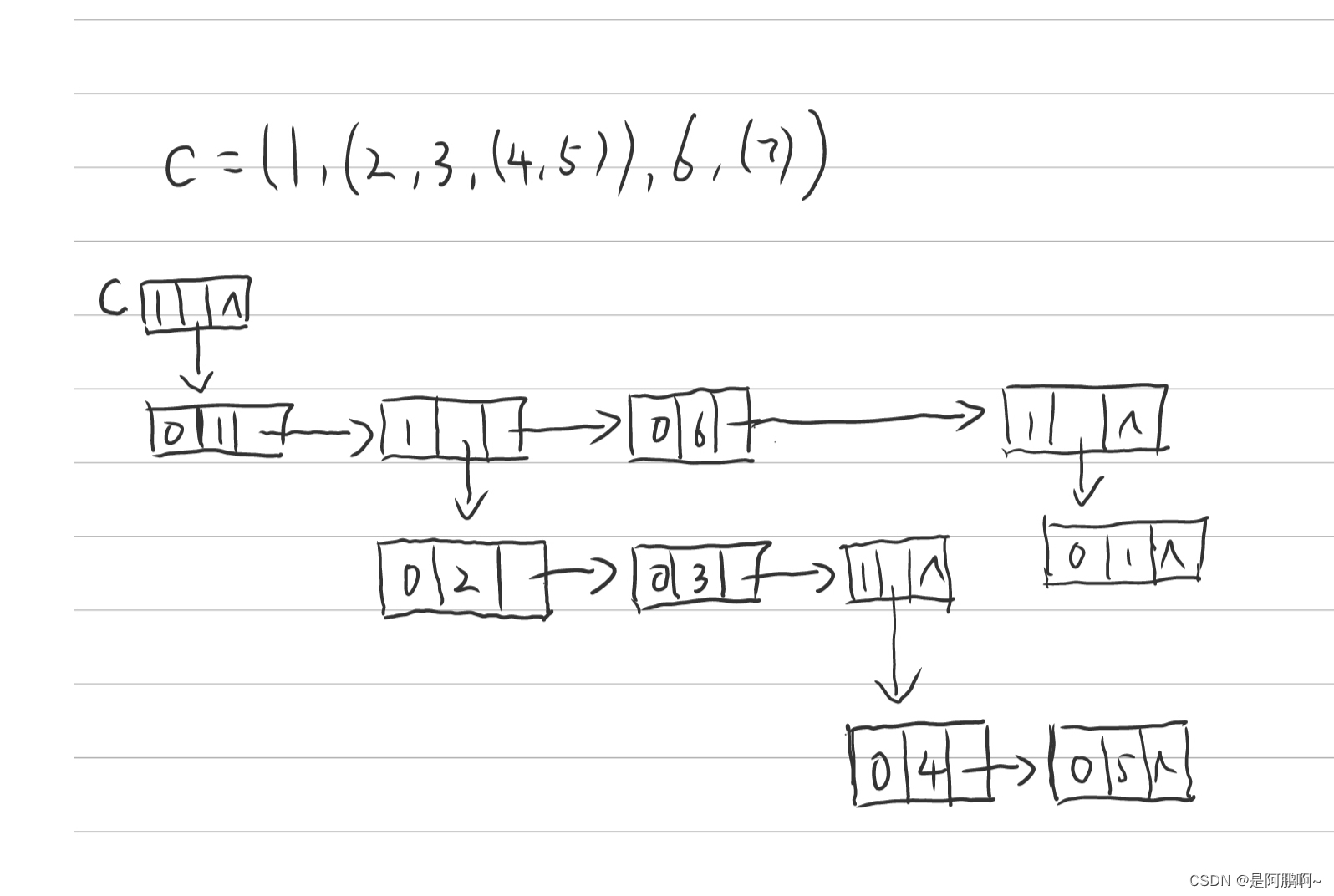
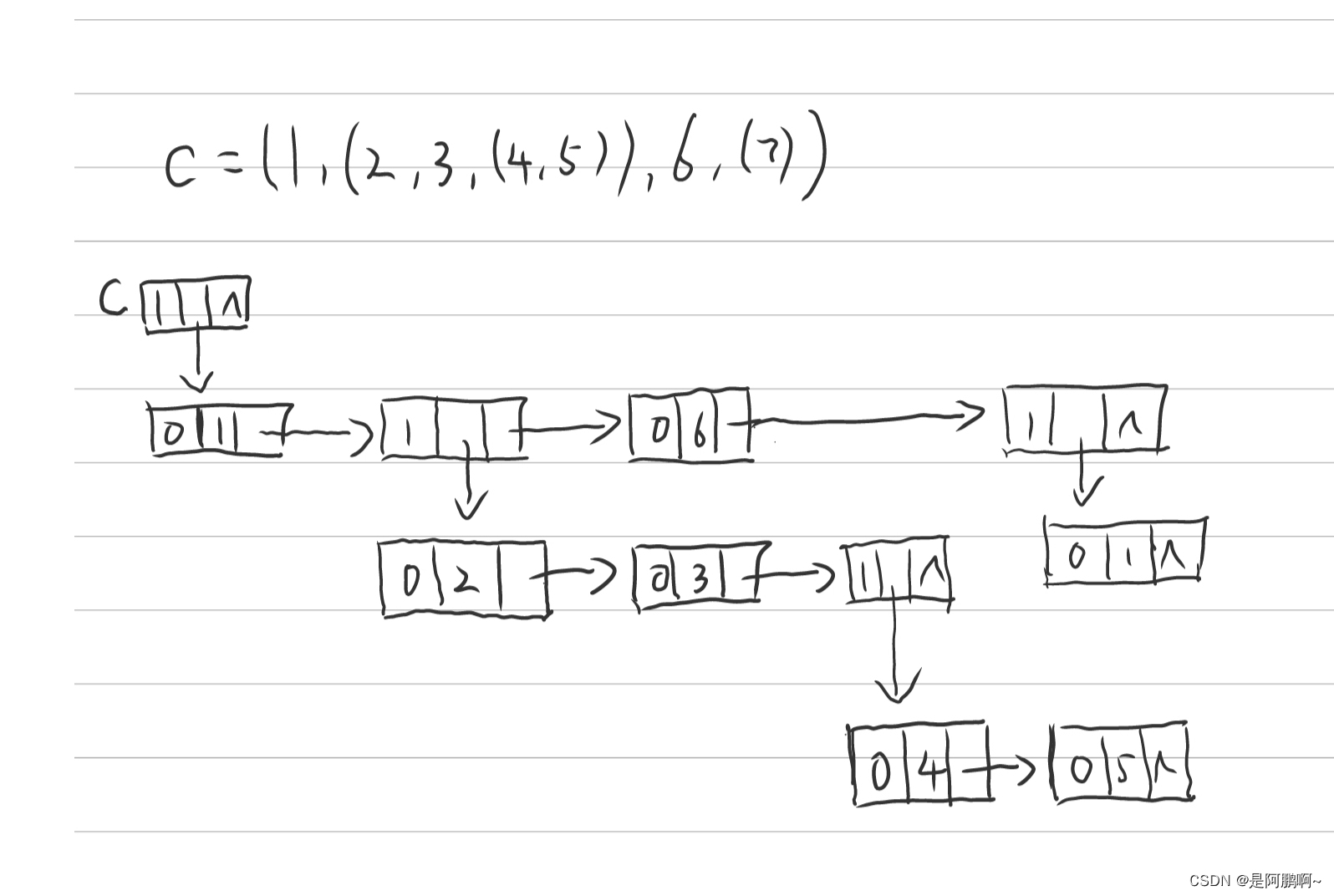
练习: C= ( 1, (2, 3, (4,5)) , 6 , (7) )
6.广义表的创建(不作要求)
GLNODE* Glist_Create(char str[], int* pi) {
while (str[*pi]==' ')
{
(* pi)++;
}
GLNODE* p; char e;
switch (str[*pi])
{
case '(':
p = (GLNODE *)malloc(sizeof(GLNODE));
p->tag = LIST;
(* pi)++;
p->UNION.child = Glist_Create(str, pi);
p->next = Glist_Create(str, pi);
break;
case ')':
(*pi)++;
p = NULL;
break;
case '\0':
p = NULL;
break;
default:
p = (GLNODE*)malloc(sizeof(GLNODE));
p->tag = ATOM;
p->UNION.atom = str[*pi];
(*pi)++;
p->next = Glist_Create(str, pi);
break;
}
return p;
}
7.广义表的遍历
void Glnode_traverse(GLNODE* p) {
GLNODE* p1 = p;
while (p1)
{
if (p1->tag == ATOM) {
printf("%c", p1->UNION.atom);
}
else {
printf("(");
Glnode_traverse(p1->UNION.child);
printf(")");
}
p1 = p1->next;
}
}
8.广义表的深度
int GetDepth(GLNODE* p) {
GLNODE* p1 = p;
if (p1->tag == 0) {
return 0;
}
int dep = 0;
int max_depth = 0;
p1 = p1->UNION.child;
while (p1)
{
dep = GetDepth(p1);
if (dep > max_depth) {
max_depth = dep;
}
p1 = p1->next;
}
return max_depth + 1;
}
9.广义表的长度(宽度)
int GetLength(GLNODE* p) {
GLNODE* p1 = p->UNION.child;
int i = 0;
while (p1->next)
{
i++;
p1 = p1->next;
}
return i;
}
总结
只是为了考试,只是些基础
















 1807
1807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











