







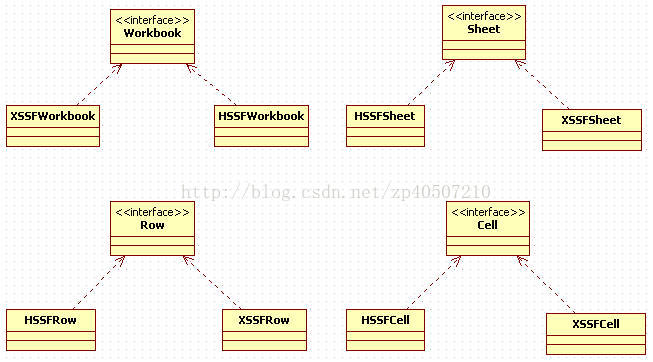
其中:
a)Workbook、Sheet、Row、Cell等为接口;
b)HSSFWorkbook、HSSFSheet、HSSFRow、HSSFCell为97-2003版本对应的处理实现类;
c)XSSFWorkbook、XSSFSheet、XSSFRow、XSSFCell为2007+版本对应的处理实现类;
Selenium做自动化测试当然不能避免和Excel打交道。
由于Excel版本的关系,文件扩展名分xls和xlsx,
以往的经验都是使用HSSFWorkbook和XSSFWorkbook来分别处理。具体的方式就是先判断文件的类型,然后根据文件扩展名来选择方法。
大概处理方式如下:
|
1
2
3
4
5
6
7
8
9
10
|
String extention= getExtention(path);
if
(!EMPTY.equals(extention)) {
if
(XLS.equals(extention)) {
return
readXlsForAllSheets(path);
}
else
if
(XLSX.equals(extention)) {
return
readXlsxForAllSheets(path);
}
}
else
{
System.out.println(path +
" is not a excel file."
);
}
|
再接着实现readXlsForAllSheets和readXlsxForAllSheets两个方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public
Object[][] readXlsxForAllSheets(String path)
throws
IOException{
System.out.println(path);
FileInputStream is =
new
FileInputStream(path);
XSSFWorkbook xssfWorkbook =
new
XSSFWorkbook(is);
System.out.println(
"There are totally "
+xssfWorkbook.getNumberOfSheets()+
" sheets in the workbook."
);
// Read the Sheet
List<Object[]> records1=
new
ArrayList<Object[]>();
for
(
int
numSheet =
0
; numSheet < xssfWorkbook.getNumberOfSheets(); numSheet++) {
XSSFSheet xssfSheet = xssfWorkbook.getSheetAt(numSheet);
int
rowCount=xssfSheet.getLastRowNum()-xssfSheet.getFirstRowNum();
List<Object[]> records=
new
ArrayList<Object[]>();
String[] separative={
"This is sheet "
+xssfWorkbook.getSheetName(numSheet)};
records.add(separative);
for
(
int
rowNum =
1
;rowNum<rowCount+
1
; rowNum++){
XSSFRow xssfRow=xssfSheet.getRow(rowNum);
String fields[]=
new
String[xssfRow.getLastCellNum()];
for
(
int
colNum=
0
;colNum<xssfRow.getLastCellNum();colNum++){
XSSFCell xssfCell=xssfRow.getCell(colNum);
fields[colNum]=
this
.getXssfCellValue(xssfCell);
}
records.add(fields);
}
records1.addAll(records);
}
Object[][] results=
new
Object[records1.size()][];
for
(
int
i=
0
;i<records1.size();i++){
results[i]=records1.get(i);
}
if
(xssfWorkbook!=
null
){xssfWorkbook.close();}
return
results;
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public
Object[][] readXlsForAllSheets(String path)
throws
IOException{
System.out.println(PROCESSING + path);
FileInputStream is =
new
FileInputStream(path);
HSSFWorkbook hssfWorkbook =
new
HSSFWorkbook(is);
System.out.println(
"There are totally "
+hssfWorkbook.getNumberOfSheets()+
" sheets in the workbook."
);
// Read the Sheet
List<Object[]> records1=
new
ArrayList<Object[]>();
for
(
int
numSheet =
0
; numSheet < hssfWorkbook.getNumberOfSheets(); numSheet++) {
HSSFSheet hssfSheet = hssfWorkbook.getSheetAt(numSheet);
int
rowCount=hssfSheet.getLastRowNum()-hssfSheet.getFirstRowNum();
List<Object[]> records=
new
ArrayList<Object[]>();
String[] separative={
"This is sheet "
+hssfWorkbook.getSheetName(numSheet)};
records.add(separative);
for
(
int
rowNum =
1
;rowNum<rowCount+
1
; rowNum++){
HSSFRow xssfRow=hssfSheet.getRow(rowNum);
String fields[]=
new
String[xssfRow.getLastCellNum()];
for
(
int
colNum=
0
;colNum<xssfRow.getLastCellNum();colNum++){
HSSFCell xssfCell=xssfRow.getCell(colNum);
fields[colNum]=
this
.getHssfCellValue(xssfCell);
}
records.add(fields);
}
records1.addAll(records);
}
Object[][] results=
new
Object[records1.size()][];
for
(
int
i=
0
;i<records1.size();i++){
results[i]=records1.get(i);
}
if
(hssfWorkbook!=
null
){hssfWorkbook.close();}
return
results;
}
|
再实现上两个方法中调用的getXssfCellValue和getHssfCellValue方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
private
String getXssfCellValue(XSSFCell xssfCell) {
String cellvalue=
""
;
DataFormatter formatter =
new
DataFormatter();
if
(
null
!= xssfCell) {
switch
(xssfCell.getCellType()) {
case
XSSFCell.CELL_TYPE_NUMERIC:
// 数字
if
(org.apache.poi.ss.usermodel.DateUtil.isCellDateFormatted(xssfCell)) {
cellvalue = formatter.formatCellValue(xssfCell);
}
else
{
double
value = xssfCell.getNumericCellValue();
int
intValue = (
int
) value;
cellvalue = value - intValue ==
0
? String.valueOf(intValue) : String.valueOf(value);
}
break
;
case
XSSFCell.CELL_TYPE_STRING:
// 字符串
cellvalue=xssfCell.getStringCellValue();
break
;
case
XSSFCell.CELL_TYPE_BOOLEAN:
// Boolean
cellvalue=String.valueOf(xssfCell.getBooleanCellValue());
break
;
case
XSSFCell.CELL_TYPE_FORMULA:
// 公式
cellvalue=String.valueOf(xssfCell.getCellFormula());
break
;
case
XSSFCell.CELL_TYPE_BLANK:
// 空值
cellvalue=
""
;
break
;
case
XSSFCell.CELL_TYPE_ERROR:
// 故障
cellvalue=
""
;
break
;
default
:
cellvalue=
"UNKNOWN TYPE"
;
break
;
}
}
else
{
System.out.print(
"-"
);
}
return
cellvalue.trim();
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
private
String getHssfCellValue(HSSFCell hssfCell) {
String cellvalue=
""
;
DataFormatter formatter =
new
DataFormatter();
if
(
null
!= hssfCell) {
switch
(hssfCell.getCellType()) {
case
HSSFCell.CELL_TYPE_NUMERIC:
// 数字
if
(org.apache.poi.ss.usermodel.DateUtil.isCellDateFormatted(hssfCell)) {
cellvalue = formatter.formatCellValue(hssfCell);
}
else
{
double
value = hssfCell.getNumericCellValue();
int
intValue = (
int
) value;
cellvalue = value - intValue ==
0
? String.valueOf(intValue) : String.valueOf(value);
}
break
;
case
HSSFCell.CELL_TYPE_STRING:
// 字符串
cellvalue=hssfCell.getStringCellValue();
break
;
case
HSSFCell.CELL_TYPE_BOOLEAN:
// Boolean
cellvalue=String.valueOf(hssfCell.getBooleanCellValue());
break
;
case
HSSFCell.CELL_TYPE_FORMULA:
// 公式
cellvalue=String.valueOf(hssfCell.getCellFormula());
break
;
case
HSSFCell.CELL_TYPE_BLANK:
// 空值
cellvalue=
""
;
break
;
case
HSSFCell.CELL_TYPE_ERROR:
// 故障
cellvalue=
""
;
break
;
default
:
cellvalue=
"UNKNOWN TYPE"
;
break
;
}
}
else
{
System.out.print(
"-"
);
}
return
cellvalue.trim();
}
|
最终整个解析Excel文件的功能才算完成,我们需要实现4个方法readXlsForAllSheets和readXlsxForAllSheets,getXssfCellValue和getHssfCellValue,那么有没有更加简单实用的方法呢?
下面要介绍的是POI jar包提供的WorkbookFactory类。需要加载poi-ooxm-3.15.jar到build path。

只需要两行就可以实例化workbook,而不用管它是xls还是xlsx。
|
1
2
|
inStream =
new
FileInputStream(
new
File(filePath));
Workbook workBook = WorkbookFactory.create(inStream);
|
后续可以直接操作sheet,Row,Cell,也不用管文件类型。
目前还没有发现这种方法的缺点。















 179
179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









