







内容目录
-
Flume 简介
-
架构和基本概念
-
多种架构模式
-
Flume 安装部署
Flume 简介
Flume 是一个分布式、可靠且高可用的数据收集、聚合和传输系统,主要用于高效地处理大规模日志数据。设计之初,它主要服务于日志管理领域,但其灵活性和可扩展性使其能够适应多种数据源和目的地,适用于各类需要实时或批量数据流转的场景。
以下是关于 Flume 的详细介绍:
起源与背景
Flume 由 Cloudera 公司开发并贡献给 Apache 基金会,作为 Apache 开源项目的一部分。它诞生于对海量日志数据有效管理和传输的需求,尤其是在大规模分布式环境中,如 Hadoop 集群,需要将分散在各个节点上的日志数据集中处理以进行分析、监控或存档。
核心特性
-
分布式架构:Flume 支持分布式部署,能够在多台机器上部署多个独立运行的 Flume Agent,形成一个灵活的数据流网络,适应大规模数据采集需求。
-
可靠性:提供了多种可靠性保证机制,如事务处理、数据校验、重试等,确保数据在传输过程中不会丢失或损坏。用户可以根据实际需求配置不同的可靠性级别。
-
高可用性:通过故障转移和恢复机制,如多路复用、负载均衡、备用 Sink 等,确保数据流在个别组件失败时仍能继续流动,保持系统的稳定运行。
-
灵活性与可扩展性:Flume 的组件化设计允许用户根据实际数据源和目标系统的特性,自由组合和定制 Source、Channel 和 Sink,支持多种数据格式和协议,同时可通过插件方式添加新的数据处理逻辑。
核心组件
-
Source:负责从数据源接收数据。数据源可以是文件、网络接口(如 syslog、TCP/UDP)、消息队列(如 Kafka)、数据库触发器等。Source 负责监听指定接口或轮询数据,并将接收到的数据封装成 Flume 事件(Event)。
-
Channel:作为临时存储区,介于 Source 和 Sink 之间,用于缓冲和暂存从 Source 收集到的 Event。Channel 提供了数据持久化的能力,确保在 Sink 处理期间数据的安全性。常见的 Channel 类型包括 Memory Channel(内存型)和 File Channel(文件型),可根据性能和可靠性要求选择。
-
Sink:负责从 Channel 中取出 Event,并将它们写入目标系统或转发到下一个 Flume Agent。目标系统可以是 HDFS、HBase、Kafka、数据库、甚至是其他 Flume Agent。Sink 通常以批量方式操作,提高数据写入效率。支持多种写入策略,如定时写入、达到一定数量写入等。
数据流模型
Flume 数据流遵循如下模型:
-
数据产生:数据源产生日志或其他形式的数据。
-
数据捕获:Flume Agent 中的 Source 组件监听数据源,捕获数据并将其转化为 Flume Event。
-
数据暂存:Event 被发送到 Channel 中暂存,Channel 可以实现数据的持久化,提供数据缓冲和容错能力。
-
数据传输:Sink 组件定期从 Channel 中读取 Event,并按照配置的规则将其写入目标系统或转发给下游 Flume Agent。
-
数据消费:目标系统(如 Hadoop 集群、数据分析平台、监控系统等)进一步处理、存储或分析接收到的 Event 数据。
应用场景
Flume 常见的应用场景包括:
-
日志收集:从分布式系统中各节点收集日志文件,统一汇总到中央存储(如 HDFS)进行分析。
-
监控数据整合:聚合来自不同监控工具或系统的指标数据,用于集中监控和报警。
-
实时数据流处理:将流式数据接入流处理引擎(如 Apache Storm、Spark Streaming)或消息队列(如 Kafka)进行实时分析。
-
ETL流程:作为数据集成工具之一,将数据从源系统抽取、转换后加载到数据仓库或数据湖。
综上所述,Flume 是一款强大的数据收集与传输工具,以其分布式、可靠、高可用的特性,以及灵活的组件化设计,广泛应用于日志管理、监控数据整合、实时数据流处理等领域,成为构建大数据处理管道的重要组成部分。
架构和基本概念
架构
来自官网的架构图:

架构大致流程:
外部数据源以特定格式向 Flume 发送
events(事件),当source接收到events时,它将其存储到一个或多个channel,channe会一直保存events直到它被sink所消费。sink 的主要功能从
channel中读取events,并将其存入外部存储系统或转发到下一个source,成功后再从channel中移除events。
基本概念
1. Event
Event 是 Flume NG 数据传输的基本单元。类似于 JMS 和消息系统中的消息。一个 Event 由标题和正文组成:前者是键/值映射,后者是任意字节数组。
2. Source
数据收集组件,从外部数据源收集数据,并存储到 Channel 中。
3. Channel
Channel 是源和接收器之间的管道,用于临时存储数据。可以是内存或持久化的文件系统:
-
Memory Channel: 使用内存,优点是速度快,但数据可能会丢失 (如突然宕机); -
File Channel: 使用持久化的文件系统,优点是能保证数据不丢失,但是速度慢。
4. Sink
Sink 的主要功能从 Channel 中读取 Event,并将其存入外部存储系统或将其转发到下一个 Source,成功后再从 Channel 中移除 Event。
5. Agent
是一个独立的 (JVM) 进程,包含 Source、 Channel、 Sink 等组件。
组件种类
Flume 中的每一个组件都提供了丰富的类型,适用于不同场景:
-
Source 类型 :内置了几十种类型,如
Avro Source,Thrift Source,Kafka Source,JMS Source; -
Sink 类型 :
HDFS Sink,Hive Sink,HBaseSinks,Avro Sink等; -
Channel 类型 :
Memory Channel,JDBC Channel,Kafka Channel,File Channel等。
对于 Flume 的使用,除非有特别的需求,否则通过组合内置的各种类型的 Source,Sink 和 Channel 就能满足大多数的需求。
在 Flume 官网 上对所有类型组件的配置参数均以表格的方式做了详尽的介绍,并附有配置样例;
同时不同版本的参数可能略有所不同,所以使用时建议选取官网对应版本的 User Guide 作为主要参考资料
架构模式
Flume 的架构模式通常是指其数据流在网络中的组织方式和组件间交互的逻辑结构,而非具体的软件架构层面。根据数据流的流向、Agent 之间的关系以及数据处理需求的不同,Flume 的使用可以归纳为以下几种常见的架构模式
Flume 支持多种架构模式,分别介绍如下
单一 Agent 架构
在这种最基础的架构模式中,只有一个 Flume Agent 完成数据的收集、暂存和传输过程。Source、Channel、Sink 都部署在同一台机器上,形成一个独立的数据处理单元。

Multi-Agent Flow(多 Agent 流)
多个 Flume Agent 串联起来,形成数据流的级联。一个 Agent 的 Sink 发送数据到另一个 Agent 的 Source,以此类推,直至数据到达最终目标。这种模式下,数据可以在多个 Agent 之间进行路由、过滤、转换等处理。

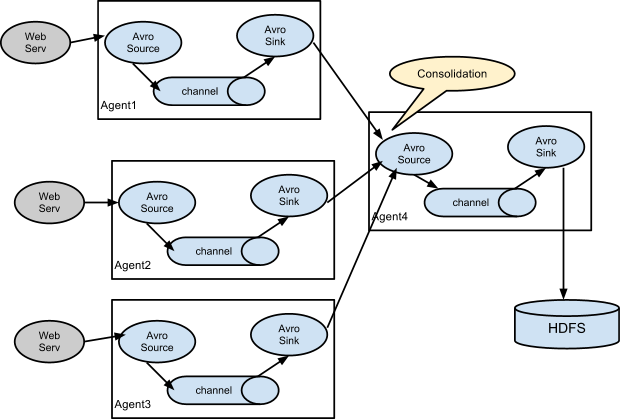
Fan-in 架构 (扇入)
在 Fan-in 架构中,多个数据源(Source Agent)将各自收集的数据发送到同一个中心节点(通常是一个 Flume Agent)。这个中心节点充当数据汇聚点,通过其配置的 Sink 将汇聚后的数据写入目标系统或进一步分发到其他 Agent
Fan-out 架构 (扇出)
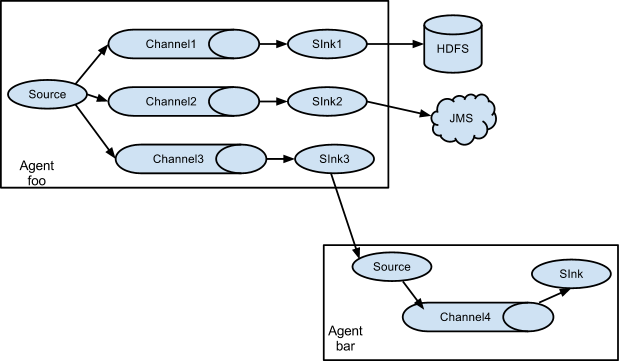
在 Fan-out 架构中,一个数据源(Source Agent)产生的数据被分发到多个不同的目标系统或下游 Agent。这意味着 Source Agent 配置的 Sink 不止一个,每个 Sink 对应一个不同的数据接收端。
Flume 安装部署
<安装部署放在下一篇文章讲解>
















 1837
1837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











