







概述
Apache Flume是一个分布式的、可靠的和可用的系统,它能把不同数据源的海量日志数据有效地收集、汇总和移动,最后存入一个集中式数据存储系统中。Flume是Apache顶级开源项目,目前有0.9.x和1.x两个主要系列,其中0.9.x系列是Flume OG(Original Generation),1.x是Flume NG(Next Generation),Flume NG比Flume OG更简单、更小、更容易部署,推荐使用Flume NG系列版本。
Flume除了可以收集日志数据外,还可以收集其他数据。由于Flume的数据源是可定制的,因此可以用来传输大量的Event Data,Event Data可以是网络流量数据、社会媒体产生的数据、电子邮件以及其他数据源产生的数据。
Flume需要运行在Java 1.6或更高版本之上,推荐使用Java 1.7。
官方网站:http://flume.apache.org/
用户手册:http://flume.apache.org/FlumeUserGuide.html
开发文档:http://flume.apache.org/FlumeDeveloperGuide.html
Flume架构
Flume的架构主要有以下几个核心概念。
| 名称 | 说明 |
|---|---|
| Event | Event由消息头和消息内容(a byte payload)组成,其中消息头是可选的。Event是Flume的基本数据单元,在Flume中使用Event对象来作为传递数据的格式。 |
| Source | 从Client收集数据,并把数据传递给Channel,Source操作的数据是Event。 |
| Channel | 连接Source和Sink,Event的临时存储区,保存由Source传递过来的Event,Channel的功能类似一个队列。 |
| Sink | 从Channel中读取并移除Event,将Event发送给一个Source或者持久化到数据库中。 |
| Agent | 一个独立的Flume进程,包含组件Source、Channel、Sink,通常每台机器只能运行一个Agent,一个Agent中可以包含一个或多个Source、Channel、Sink。 |
| Client | 生产数据,把数据发送到Agent,数据由Source接收。 |
数据流模型(Data flow model)
Flume的数据流由Event贯穿始终。Event是Flume的基本数据流单位,Event由消息内容(a byte payload)和可选的消息头组成,消息头一系列字符串属性。Agent是Flume的最小的独立运行单位,由Source、Sink和Channel三大组件构成,如下图所示。
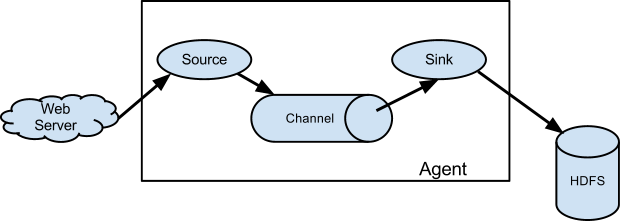
Event由外部系统生成,如上图的WebServer,外部系统会根据Source的需求把指定格式的Event推送到Agent,Source会捕获这些Event并进行格式化,Source支持多种Event格式,如Avro、Thrift等。Source处理后的Event会被转发到一个或多个Channel中,Channel可以看成是一个数据缓冲区(类似消息队列),Channel中的Event一直保存到Sink处理完成为止。Sink负责持久化日志或者把Event推向另一个Source,Sink处理后的Event会从Channel中移除。
Flume支持用户建立多级流,也就是Event通过多个Agent后才达到最终目的。多级流过程中如果有失败的流跳转,Flume提供扇入和扇出流(fan-in and fan-out flows)、上下文路由(contextual routing)和备份路由(backup routes or fail-over)等功能。
高可靠性
对于每个Agent,Event首先存放到Channel中,然后再传递到下一个Agent或者持久化到数据库中(如HDFS)。Channel中的Event数据直到下一个Agent接收完成或者持久化到数据库中完成才会被删除。
Flume通过基于事务的传递方式来保证事件传递的可靠性。在单个流中,Source和Sink被封装进一个事务中,Event保存在Channel中直到处理完成,该Event才会从Channel中删除。事务保证了Event在流中点到点传递的可靠性。如果是多级流,前一个Agent的Sink和后一个Agent的Source同样有它们的事务来保证Event数据安全的保存到后一个Agent的Channel中。
可恢复性
Flume通过Channel保存Event数据,其中FileChannel可以把Event数据持久化到本地的文件系统中。MemoryChannel把Event数据保存在内存中,MemoryChannel具有更高的性能,不过可恢复性较差(一旦断电或者Agent进程关掉Event数据就会丢失)。
使用场景
多个Agent顺序连接(Multi-Agent Flow)
将多个Agent顺序连接起来,将最初的数据源经过收集、整理,存储到最终的存储系统中。一般情况下,应该控制这种顺序连接的Agent的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。

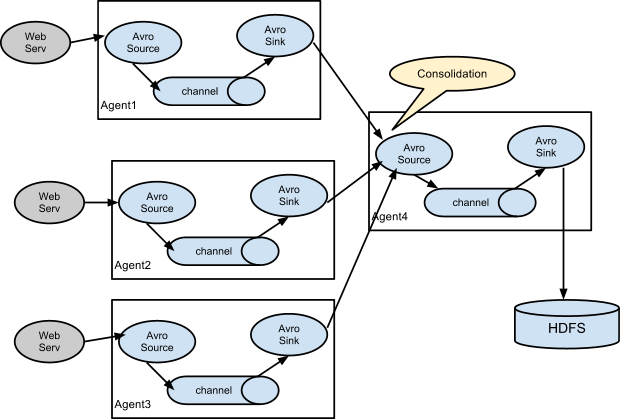
多个Agent汇集到一个Agent(Consolidation)
这种情况应用的场景比较多,比如要收集上千个网站(网站集群)的日志,可以为这些网站配置多个Agent来收集日志,每个Agent收集一个或多个网站的日志,然后把这些Agent的数据汇集到统一的Agent中,最后由这个统一的Agent把数据持久化,如保存到HDFS。
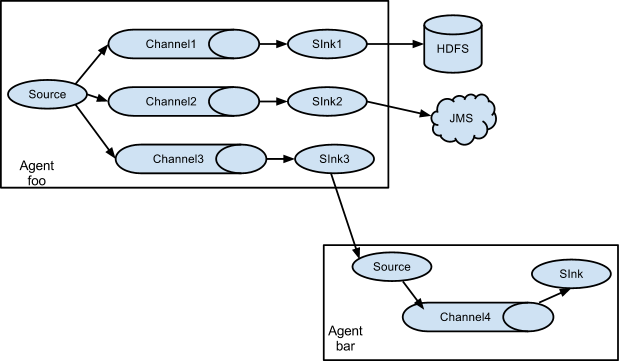
多路复用(Multiplexing Flow)
Flume支持通过复用把Event数据分发到多个Channel中,Sink再把不同Channel中的数据保存到不同的地方。Flume多路复用有两种方式,一种是复制(Replicating),一种是Multiplexing。复制就是把Event数据复制多份,然后给每个Channel都发送,每个Channel接收到的数据都是相同的。以下图为例,Event数据会被复制成3份,然后分发给3个Channel。Multiplexing方式就是对Event数据进行过滤,根据消息头属性把Event分发到不同的Channel中。














 2013
2013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









