







简述:Hadoop的安装对环境有比较高的要求,需要比较大的内存,一般的机器很难满足,一个人也很难有两三台独立的主机,所以只能选择使用安装虚拟机的方式安装,但是主机的内存需要在8G以上。如果小于8G可以扩展内存后再做尝试。
公司使用的hadoop一般都不是apache下的hadoop,而是cloudera公司的hadoop,因为它除了提供hadoop外还提供了集成工具,所以,今天也采用cloudera hadoop进行安装学习。
一、先来看看hadoop对环境的要求
我选择的版本是5.8.3,此时最新的版本是5.9.0
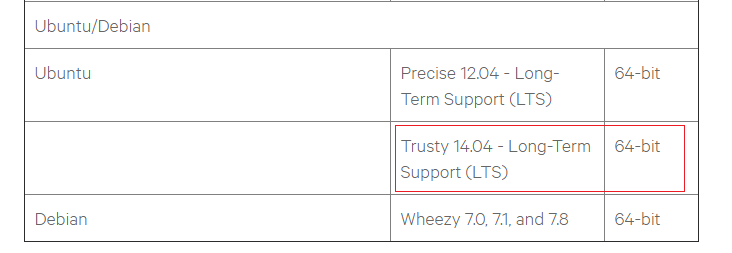
我采用的是ubuntu,因为列表很长,我只标出了我使用的版本,由此可见,hadoop只支持ubuntu的这两个版本,如果你使用ubuntu的话,只能使用这两个版本。

注意:hadoop的版本对JDK也有要求,我选用的是官方建议的版本1.8.0_60. 所以安装之前一定要先查询所支持的各个软件的版本。
然后去下载所需要的软件。

这里我选择使用tarball安装,之前我使用过cloudera manager安装,但是半小时后,电脑死机了,重新启动再安装就开始各种报各种错误,头疼,还有可能是国内的网络等等,所以还是建议一个一个的手工安装,当然选择使用tarball安装最为恰当。
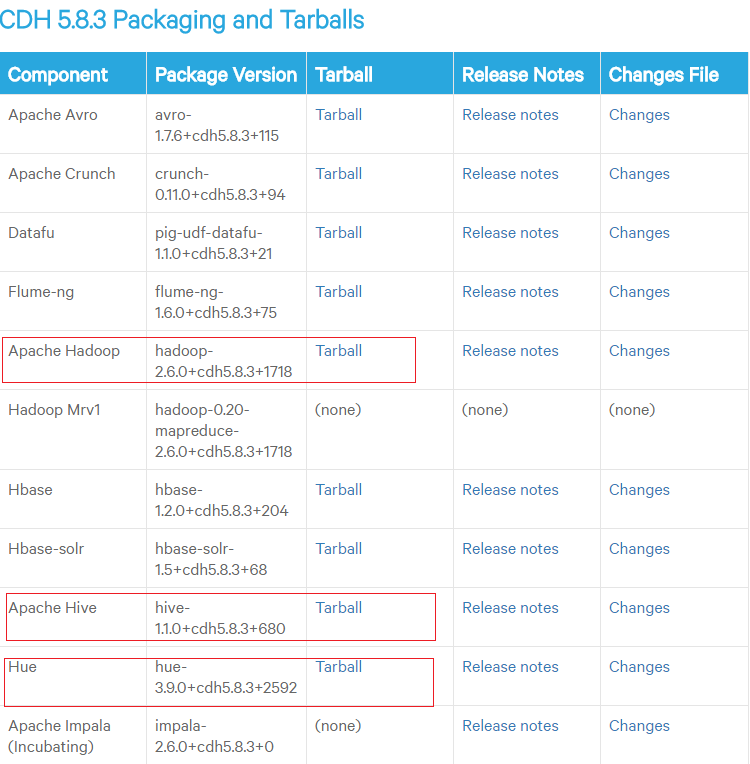
这是我需要的部分软件,当然写到这里的时候,我只是把hadoop的集群安装好了,hive和hue还没有开始安装,不过我已经使用我本地的集群跑过了wordcount例子,感觉是很美妙的。闲话少扯,看看我本地的架构先。
二、集群安装架构
| 主机名 | IP | 内存 | 安装软件 | 进程 |
|---|---|---|---|---|
| master | 192.168.1.200 | 4G | JDK Hadoop | ResourceManager NameNode SecondaryNameNode DataNode NodeManager |
| slave1 | 192.168.1.201 | 2G | JDK Hadoop | DataNode NodeManager |
| slave2 | 192.168.1.202 | 2G | JDK Hadoop | DataNode NodeManager |
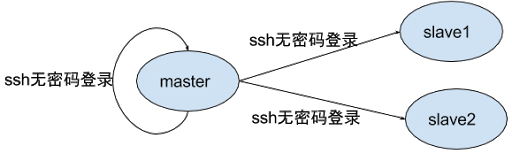
三、安装三台Ubuntu虚拟机
注意:三台机器要使用同样的用户命和同样的密码。
我的三台虚拟机使用的都是hadoop/hadoop,然后配置hosts文件
192.168.1.200 master
192.168.1.201 slave1
192.168.1.202 slave2
这个文件的位置在/etc/hosts
注意:这个文件要放到三台机器上
之后就可以使用scp传递文件,为后面做准备,比如可以使用如下命令:
scp -r 目录 slave1:/home/hadoop
scp 文件 slave1:/home/hadoop
就可以把机器上的文件传递到slave1的home/hadoop目录下,这个命令这么简单使用完你首先使用的是同样的用户命和同样的密码,然后又根据同样的用户信息生成的sshkey信息,然后设置了无密码登陆,综合上述原因,你可以这样使用scp命令
否则,你就需要输入用户命和IP信息,例子如下:
scp -r 目录 hadoop@192.168.1.201:/home/hadoop
scp 文件 hadoop@192.168.1.201:/home/hadoop
四、安装配置SSH
每台机器都要安装SSH
sudo apt-get install openssh-server openssh-client
生成ssh-key
keygen -t rsa
然后一路回车,不要输入密码
对master机器使用如下命令
cat id_rsa.pub >> authorized_keys
这样就可以自己对自己无密码SSH登陆了。
然后使用scp命令,把authorized_keys拷贝到两个slave机器的.ssh目录下,这样master机器就可以无密码SSH登陆所有的slave机器了。
五、安装JDK
JDK的安装就不在讲述,要点就是使用相同的安装目录,这样就可以拷贝环境变量对应的文件,和拷贝jdk的安装目录,简单省事何乐而不为呢。
上面我已经教了如何使用scp命令了,此处不就可以使用了吗,是不是很方便。
六、安装Hadoop
注意:一下操作都是在master机器上操作的,需要拷贝到两台slave机器上。
1. 解压tarball
tar -zxvf hadoop-2.6.0-cdh5.8.3.tar.gz
2. 给重命名为hadoop,我的安装目录如下所示:
hadoop@master:~/program$ pwd
/home/hadoop/program
hadoop@master:~/program$ ls
hadoop java
hadoop@master:~/program$
3. 配置环境变量
export JAVA_HOME=/home/hadoop/program/java
export HADOOP_HOME=/home/hadoop/program/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
我的环境变量放在~/.bash_hadoop文件中,然后在~/.bashrc中引用了我的环境变量文件,为的是方便拷贝到其他两台机器上。
4. 修改配置文件
1)首先要找到配置文件的目录
hadoop@master:~/program/hadoop/etc/hadoop$ pwd
/home/hadoop/program/hadoop/etc/hadoop
hadoop@master:~/program/hadoop/etc/hadoop$ ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml
core-site.xml httpfs-site.xml slaves
hadoop-env.cmd kms-acls.xml ssl-client.xml.example
hadoop-env.sh kms-env.sh ssl-server.xml.example
hadoop-metrics2.properties kms-log4j.properties yarn-env.cmd
hadoop-metrics.properties kms-site.xml yarn-env.sh
hadoop-policy.xml log4j.properties yarn-site.xml
hdfs-site.xml mapred-env.cmd
hadoop@master:~/program/hadoop/etc/hadoop$
如上所示,你可以清楚的发现配置文件所在的目录
2)创建一些目录用来存放hadoop运行时的信息
hadoop@master:/hadoop$ pwd
/hadoop
hadoop@master:/hadoop$ ll
total 20
drwxrwxr-x 5 hadoop hadoop 4096 Nov 17 18:34 ./
drwxr-xr-x 23 root root 4096 Nov 17 18:30 ../
drwxrwxr-x 4 hadoop hadoop 4096 Nov 17 20:05 data/
drwxr-xr-x 3 hadoop hadoop 4096 Nov 21 20:16 datanode/
drwxrwxr-x 3 hadoop hadoop 4096 Nov 21 20:16 namenode/
注意:我在根目录下先创建了hadoop目录,然后又在其下分别创建了data、datanode和namenode目录,为后边的配置使用。所有的权限设置为755,并且为hadoop用户所有。 当然,根目录下hadoop的权限也是755。
3)修改hadoop-env.sh文件
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/home/hadoop/program/java
把原来的那一行替换为新的一行,要不以后启动的时候会报找不到JAVA_HOME。
4)修改core-site.xml文件
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/data</value>
</property>
</configuration>
注意:这里用到了其中一个目录。
5)修改hdfs-site.xml文件
<configuration>
<!-- 设置namenode的http通讯地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 设置secondarynamenode的http通讯地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/namenode</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/datanode</value>
</property>
</configuration>
注意:这里又使用了两个目录,不在说明,要说明的是dfs.replication的值,为什么取3,是因为之前的架构,我把三台主机都作为了datanode,所以,这里配置的是3,如果是两台datanode,那么就得配置为2。
6)修改mapred-site.xml文件
此时,你发现找不着mapred-site.xml文件,是因为它默然情况不叫这个名字,我们来给他改个名
mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
7)配置yarn-site.xml 文件
<configuration>
<!-- 设置 resourcemanager 在哪个节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
8)配置slaves文件
有的教程也提到了slaves,但是第一眼看上去根本不知道这是个文件很难看懂,这里特意提一下,这个文件和其他配置文件在同一个目录下,这个文件默认是个空文件,我们需要添加一些内容进去,它的作用是决定添加进去的主机名是datanode
master
slave1
slave2
这是我的文件,为什么把master也放到这个文件中呢,是因为我的master意识一个datanode,所以要放进来。
注意:到此,hadoop的配置文件已经配置好了,然后把hadoop的安装目录拷贝到其他两台机器上。
七、启动Hadoop
在启动之前要先把namenode格式化一下:
hdfs namenode -format
这里我之所以可以直接是用hdfs命令是因为我配置了环境变量。
start-all.sh
注意:这两个命令是在master机器上操作的,不需要在slave机器上执行。
执行成功后,在master执行jps命令,可以看到如下结果:
ResourceManager
NameNode
SecondaryNameNode
DataNode
NodeManager
JPS
说明master已经完整的启动成功。
然后在两台slave机器上执行jps命令,得到同样的结果如下:
DataNode
NodeManager
JPS
此时在浏览器中输入192.168.1.200::50070,可以看到如下界面
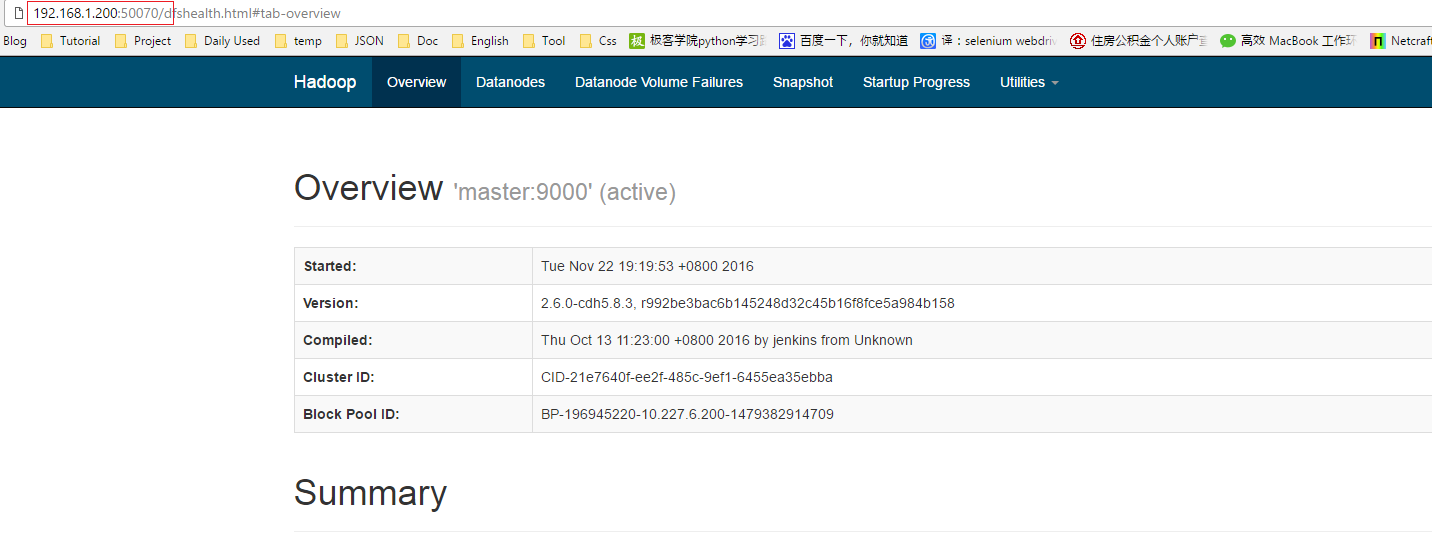
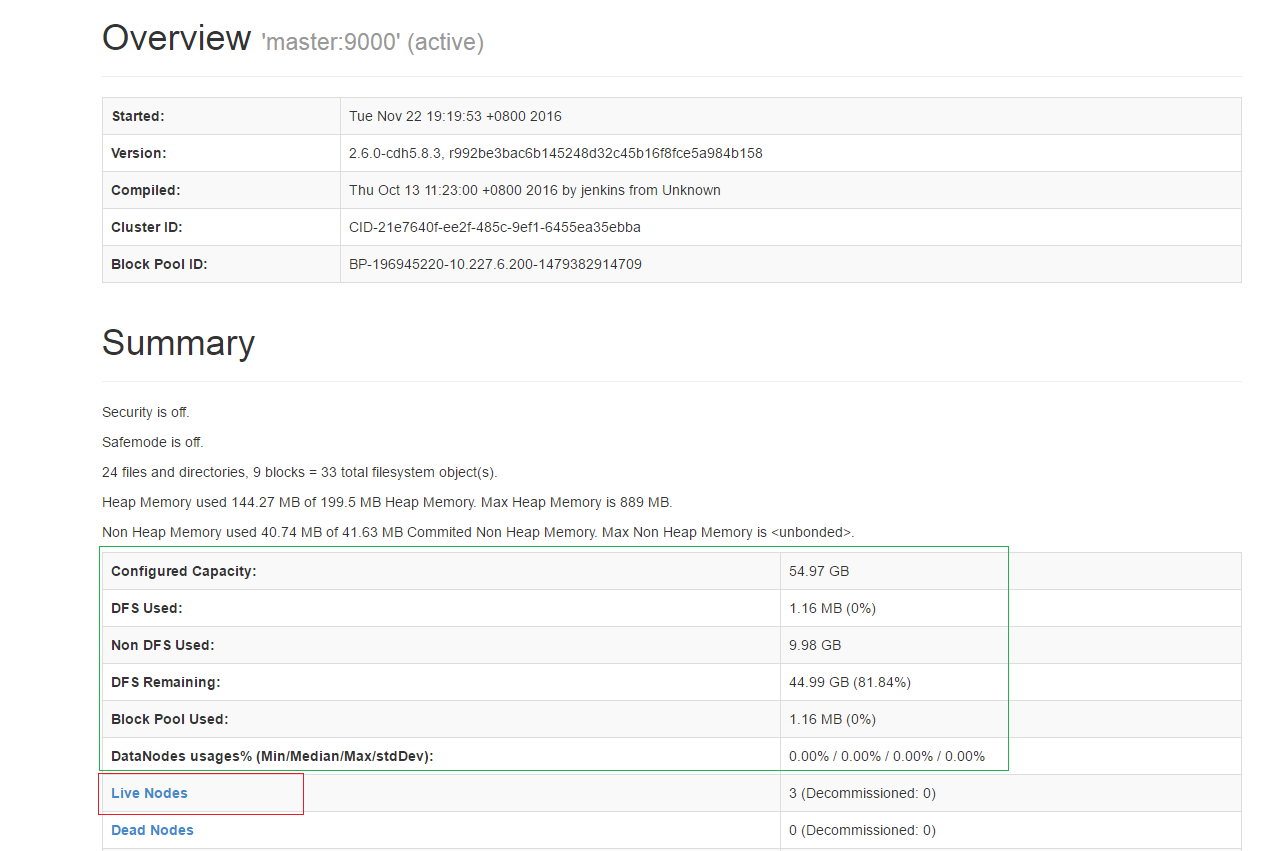
一张图截不下,我截了两张,点击Live Nodes,可以看到有三台机器,和一些信息。
注意:绿色框框中的数据,如果没有数据是不正确的,可能是你的hosts文件没有配置,需要把master上的hosts文件放到slave机器上。
在浏览器输入192.168.1.200:8088,打开后点击Nodes连接,可以看到集群信息。
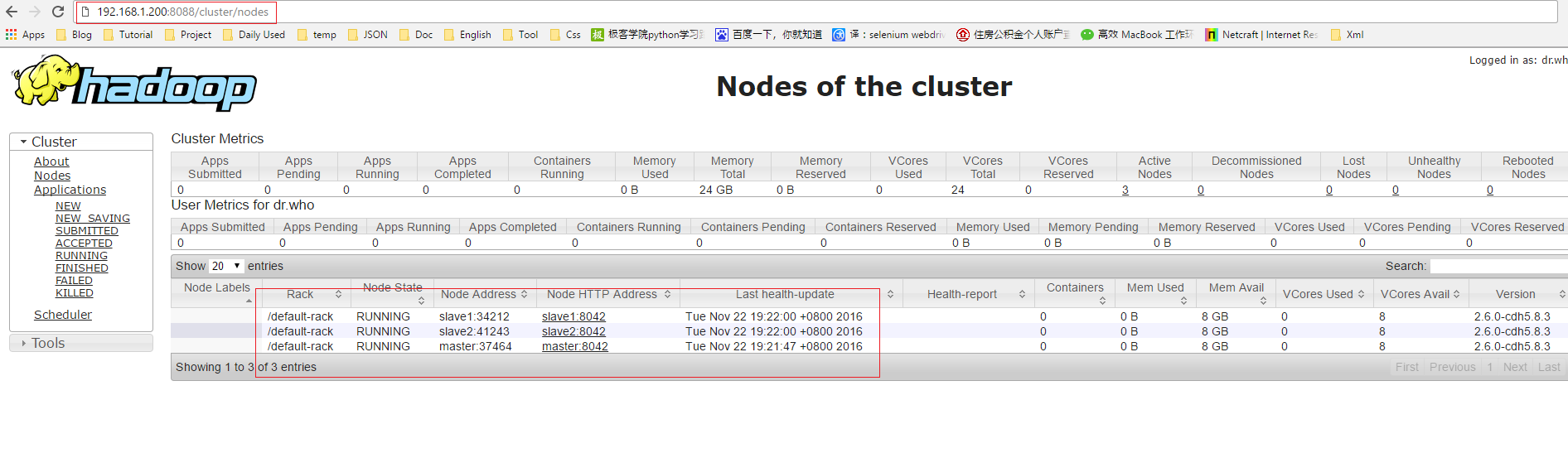
OK,到此为止,你的三台hadoop集群已经搭建完毕。
当然,前边提到,我还做了wordcount的测试,在这片文章中就不详细说明,请看hadoop2.7 安装和使用
八、安装hive
hive的安装可参考Hive的安装部署,只是在这个基础上稍作修改,
首先根据上面截图中显示的hive的版本下载相应的版本的hiveDB,然后在master机器上进行配置,配置文件如下:
1)配置hive-site.xml 文件,没有就创建这个文件
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>
注意:要把Hive的安装部署上的准备做完,然后把安装好的hive文件拷贝到slave1和slave2上。
scp -r hive slave1:/home/hadoop/program
scp -r hive slave2:/home/hadoop/program
2)修改配置slave机器上的hive-site.xml 文件
把上边的内容删掉,替换成如下内容:
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
</configuration>
到此,hive也安装配置成功,可以进行测试。
注意:还要注意Hive的安装部署中的内容,启动hive之前要先启动hadoop,由于这次安装的是hadoop集群,所以要把所有的节点全启动,然后在启动hive
3)启动服务
start-all.sh
hive
hadoop@master:~/program/hive$ bin/hive
Logging initialized using configuration in jar:file:/home/hadoop/program/hive/lib/hive-common-1.1.0-cdh5.8.3.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> show databases;
OK
default
Time taken: 7.092 seconds, Fetched: 1 row(s)
hive启动后,在master上输入jps可以看到如下信息
hadoop@master:~$ jps
2272 ResourceManager
3602 RunJar
2051 SecondaryNameNode
2405 NodeManager
1749 NameNode
3816 Jps
1883 DataNode
此时,多了一个RunJar进程
如果可以看到如上结果,那么你的hive真的安装好了。
参考文章:














 1022
1022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









