







/**
* @Title: DruidStatViewServlet.java
* @Package org.spring.springboot.servlet
* @Description: TODO(用一句话描述该文件做什么)
* @author pengfei
* @date 2017年7月15日 下午3:28:13
* @version V1.0
*/
package org.spring.springboot.servlet;
import javax.servlet.annotation.WebInitParam;
import javax.servlet.annotation.WebServlet;
import com.alibaba.druid.support.http.StatViewServlet;
/**
* StatViewServlet
*
* @author 单红宇(365384722)
* @myblog http://blog.csdn.net/catoop/
* @create 2016年3月17日
*/
@SuppressWarnings("serial")
@WebServlet(urlPatterns = "/druid/*",
initParams={
@WebInitParam(name="allow",value="192.168.16.110,127.0.0.1"),// IP白名单 (没有配置或者为空,则允许所有访问)
@WebInitParam(name="deny",value="192.168.16.111"),// IP黑名单 (存在共同时,deny优先于allow)
@WebInitParam(name="loginUsername",value="admin"),// 用户名
@WebInitParam(name="loginPassword",value="123456"),// 密码
@WebInitParam(name="resetEnable",value="false")// 禁用HTML页面上的“Reset All”功能
})
public class DruidStatViewServlet extends StatViewServlet{
}
关于DRUID配置多数据源相信您在网上也找到不少文章,每个人方法各有不同,供大道同归,原理都是一样的;
介绍:
Druid是阿里巴巴开源平台上的一个项目,整个项目由数据库连接池、插件框架和SQL解析器组成。该项目主要是为了扩展JDBC的一些限制,可以让程序员实现一些特殊的需求,比如向密钥服务请求凭证、统计SQL信息、SQL性能收集、SQL注入检查、SQL翻译等,程序员可以通过定制来实现自己需要的功能。
个人理解:主要实现了数据源的优化,和对SQL的监控功能,对事务的管理还是解决JDBC 或 JTA那套来管理事务,我还是参照网上的JDBC事务。
我主要采用spring boot+druid配置数据源,包括事务的管理。
这是我对新技术采用的方法,应该可以放大图片来看:
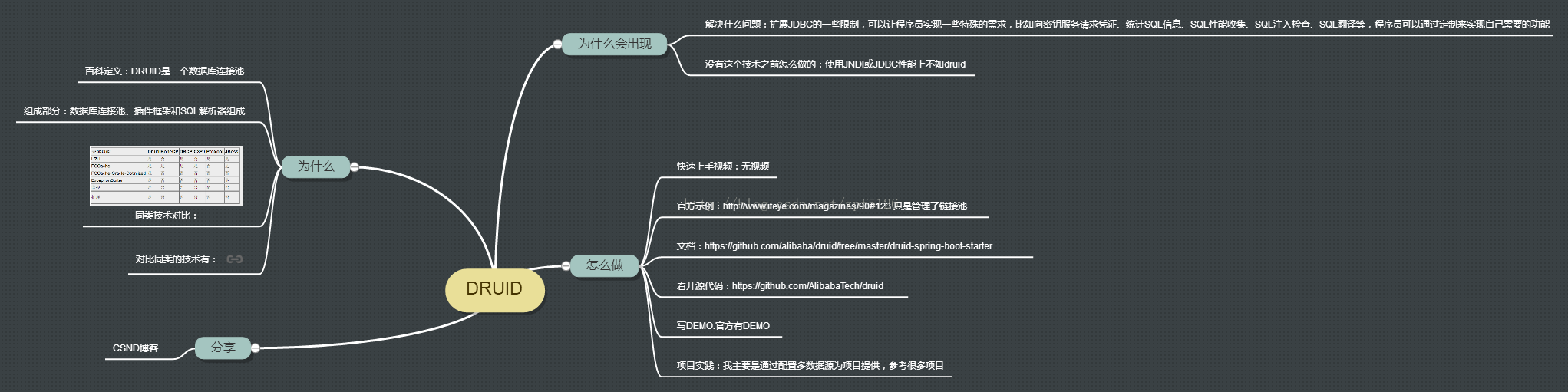
图上链接我给大家发下,也有可能会失效,因为随网站内容变更啊
同类技术对比:https://github.com/alibaba/druid/wiki/%E5%90%84%E7%A7%8D%E8%BF%9E%E6%8E%A5%E6%B1%A0%E6%80%A7%E8%83%BD%E5%AF%B9%E6%AF%94%E6%B5%8B%E8%AF%95
官方示例:http://www.iteye.com/magazines/90#123 只是管理了链接池
文档:https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
看开源代码:https://github.com/AlibabaTech/druid
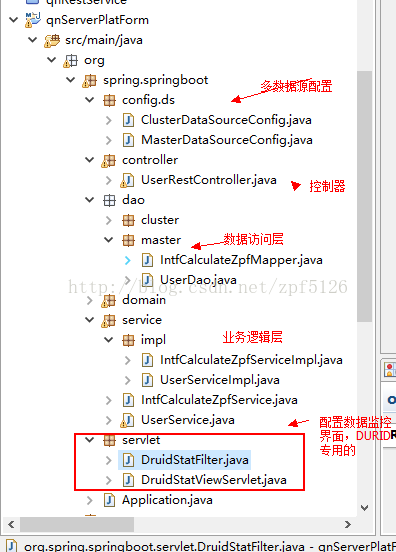
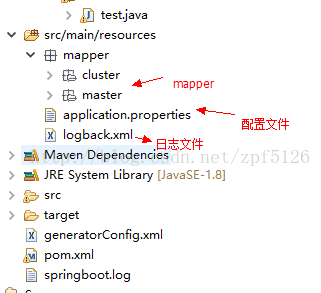
我直接写配置方法了:
application.properties
## master 数据源配置
master.datasource.url=jdbc:oracle:thin:@10.20.100.193:1521:mestest1
master.datasource.username=qnmest1
master.datasource.password=qnmest1
master.datasource.driverClassName=oracle.jdbc.driver.OracleDriver
## cluster 数据源配置
cluster.datasource.url=jdbc:mysql://localhost:3306/springbootdb_cluster?useUnicode=true&characterEncoding=utf8
cluster.datasource.username=root
cluster.datasource.password=root
cluster.datasource.driverClassName=com.mysql.jdbc.Driver
# 下面为连接池的补充设置,应用到上面所有数据源中
# 初始化大小,最小,最大
spring.datasource.initialSize=5
spring.datasource.minIdle=5
spring.datasource.maxActive=20
# 配置获取连接等待超时的时间
spring.datasource.maxWait=60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.timeBetweenEvictionRunsMillis=60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
spring.datasource.minEvictableIdleTimeMillis=300000
spring.datasource.validationQuery=SELECT 1 FROM DUAL
spring.datasource.testWhileIdle=true
spring.datasource.testOnBorrow=false
spring.datasource.testOnReturn=false
spring.datasource.logImpl=STDOUT_LOGGING
# 打开PSCache,并且指定每个连接上PSCache的大小
spring.datasource.poolPreparedStatements=true
spring.datasource.maxPoolPreparedStatementPerConnectionSize=20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
spring.datasource.filters=stat,wall,log4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
spring.datasource.useGlobalDataSourceStat=true
logback.access.config.path=./src/main/respirces/logback.xml
package org.spring.springboot.config.ds;
import com.alibaba.druid.pool.DruidDataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import javax.sql.DataSource;
@Configuration
// 扫描 Mapper 接口并容器管理
@MapperScan(basePackages = MasterDataSourceConfig.PACKAGE, sqlSessionFactoryRef = "masterSqlSessionFactory")
public class MasterDataSourceConfig {
// 精确到 master 目录,以便跟其他数据源隔离
static final String PACKAGE = "org.spring.springboot.dao.master";
static final String MAPPER_LOCATION = "classpath:mapper/master/*.xml";
@Value("${master.datasource.url}")
private String url;
@Value("${master.datasource.username}")
private String user;
@Value("${master.datasource.password}")
private String password;
@Value("${master.datasource.driverClassName}")
private String driverClass;
@Bean(name = "masterDataSource")
@Primary
public DataSource masterDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName(driverClass);
dataSource.setUrl(url);
dataSource.setUsername(user);
dataSource.setPassword(password);
return dataSource;
}
@Bean(name = "masterTransactionManager")
@Primary
public DataSourceTransactionManager masterTransactionManager() {
return new DataSourceTransactionManager(masterDataSource());
}
@Bean(name = "masterSqlSessionFactory")
@Primary
public SqlSessionFactory masterSqlSessionFactory(@Qualifier("masterDataSource") DataSource masterDataSource)
throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(masterDataSource);
sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources(MasterDataSourceConfig.MAPPER_LOCATION));
return sessionFactory.getObject();
}
}ClusterDataSourceConfig
package org.spring.springboot.config.ds;
import javax.sql.DataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import com.alibaba.druid.pool.DruidDataSource;
@Configuration
// 扫描 Mapper 接口并容器管理
@MapperScan(basePackages = ClusterDataSourceConfig.PACKAGE, sqlSessionFactoryRef = "clusterSqlSessionFactory")
public class ClusterDataSourceConfig {
// 精确到 cluster 目录,以便跟其他数据源隔离
static final String PACKAGE = "org.spring.springboot.dao.cluster";
static final String MAPPER_LOCATION = "classpath:mapper/cluster/*.xml";
@Value("${cluster.datasource.url}")
private String url;
@Value("${cluster.datasource.username}")
private String user;
@Value("${cluster.datasource.password}")
private String password;
@Value("${cluster.datasource.driverClassName}")
private String driverClass;
@Bean(name = "clusterDataSource")
public DataSource clusterDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName(driverClass);
dataSource.setUrl(url);
dataSource.setUsername(user);
dataSource.setPassword(password);
return dataSource;
}
@Bean(name = "clusterTransactionManager") //这里就是事务控制了
public DataSourceTransactionManager clusterTransactionManager() {
return new DataSourceTransactionManager(clusterDataSource());
}
@Bean(name = "clusterSqlSessionFactory")
public SqlSessionFactory clusterSqlSessionFactory(@Qualifier("clusterDataSource") DataSource clusterDataSource)
throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(clusterDataSource);
sessionFactory.setMapperLocations(
new PathMatchingResourcePatternResolver().getResources(ClusterDataSourceConfig.MAPPER_LOCATION));
return sessionFactory.getObject();
}
}
IntfCalculateZpfMapper
package org.spring.springboot.dao.master;
import java.math.BigDecimal;
import java.util.Date;
import java.util.List;
import org.spring.springboot.domain.IntfCalculateZpf;
public interface IntfCalculateZpfMapper {
int deleteByPrimaryKey(Date sysid);
int insert(IntfCalculateZpf record);
int insertSelective(IntfCalculateZpf record);
IntfCalculateZpf selectByPrimaryKey(Date sysid);
List<IntfCalculateZpf> selectBySid(BigDecimal sid);
int updateByPrimaryKeySelective(IntfCalculateZpf record);
int updateByPrimaryKey(IntfCalculateZpf record);
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="org.spring.springboot.dao.master.IntfCalculateZpfMapper" >
<resultMap id="BaseResultMap" type="org.spring.springboot.domain.IntfCalculateZpf" >
<constructor >
<idArg column="SYSID" jdbcType="TIMESTAMP" javaType="java.util.Date" />
<arg column="SID" jdbcType="DECIMAL" javaType="java.math.BigDecimal" />
<arg column="APPLY_ID" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="CAR_NO" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="L4_MATNR" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="MAT_NAME" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="PRICE_UNIT" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="GROSS_WT" jdbcType="DECIMAL" javaType="java.math.BigDecimal" />
<arg column="GROSS_DATE" jdbcType="TIMESTAMP" javaType="java.util.Date" />
<arg column="TARE_WT" jdbcType="DECIMAL" javaType="java.math.BigDecimal" />
<arg column="TARE_DATE" jdbcType="TIMESTAMP" javaType="java.util.Date" />
<arg column="WEIGHT" jdbcType="DECIMAL" javaType="java.math.BigDecimal" />
<arg column="WT_UNIT" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="GROSS_BY" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="BUSINESS_ID" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="BUSINESS_TYPE" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="APPLY_ID_L2" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="SUPPLY_NAME" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="GROSS_DATE_2" jdbcType="TIMESTAMP" javaType="java.util.Date" />
<arg column="GROSS_DATE_1" jdbcType="TIMESTAMP" javaType="java.util.Date" />
<arg column="GROSS_STATION_1" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="LADLE_SEQ" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="CELL_ID_LIST" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="ASSIGNMENT" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="UNIT_CARRIED_NAME" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="REMARK" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="FLAG" jdbcType="VARCHAR" javaType="java.lang.String" />
<arg column="LADLE_ID" jdbcType="VARCHAR" javaType="java.lang.String" />
</constructor>
</resultMap>
<sql id="Base_Column_List" >
SYSID, SID, APPLY_ID, CAR_NO, L4_MATNR, MAT_NAME, PRICE_UNIT, GROSS_WT, GROSS_DATE,
TARE_WT, TARE_DATE, WEIGHT, WT_UNIT, GROSS_BY, BUSINESS_ID, BUSINESS_TYPE, APPLY_ID_L2,
SUPPLY_NAME, GROSS_DATE_2, GROSS_DATE_1, GROSS_STATION_1, LADLE_SEQ, CELL_ID_LIST,
ASSIGNMENT, UNIT_CARRIED_NAME, REMARK, FLAG, LADLE_ID
</sql>
<select id="selectByPrimaryKey" resultMap="BaseResultMap" parameterType="java.util.Date" >
select
<include refid="Base_Column_List" />
from INTF_CALCULATE_ZPF
where SYSID = #{sysid,jdbcType=TIMESTAMP}
</select>
<select id="selectBySid" resultMap="BaseResultMap" parameterType="java.math.BigDecimal" >
select
<include refid="Base_Column_List" />
from INTF_CALCULATE_ZPF
where SID = #{sid,jdbcType=DECIMAL}
</select>
<delete id="deleteByPrimaryKey" parameterType="java.util.Date" >
delete from INTF_CALCULATE_ZPF
where SYSID = #{sysid,jdbcType=TIMESTAMP}
</delete>
<insert id="insert" parameterType="org.spring.springboot.domain.IntfCalculateZpf" >
insert into INTF_CALCULATE_ZPF (SYSID, SID, APPLY_ID,
CAR_NO, L4_MATNR, MAT_NAME,
PRICE_UNIT, GROSS_WT, GROSS_DATE,
TARE_WT, TARE_DATE, WEIGHT,
WT_UNIT, GROSS_BY, BUSINESS_ID,
BUSINESS_TYPE, APPLY_ID_L2, SUPPLY_NAME,
GROSS_DATE_2, GROSS_DATE_1, GROSS_STATION_1,
LADLE_SEQ, CELL_ID_LIST, ASSIGNMENT,
UNIT_CARRIED_NAME, REMARK, FLAG,
LADLE_ID)
values (#{sysid,jdbcType=TIMESTAMP}, #{sid,jdbcType=DECIMAL}, #{applyId,jdbcType=VARCHAR},
#{carNo,jdbcType=VARCHAR}, #{l4Matnr,jdbcType=VARCHAR}, #{matName,jdbcType=VARCHAR},
#{priceUnit,jdbcType=VARCHAR}, #{grossWt,jdbcType=DECIMAL}, #{grossDate,jdbcType=TIMESTAMP},
#{tareWt,jdbcType=DECIMAL}, #{tareDate,jdbcType=TIMESTAMP}, #{weight,jdbcType=DECIMAL},
#{wtUnit,jdbcType=VARCHAR}, #{grossBy,jdbcType=VARCHAR}, #{businessId,jdbcType=VARCHAR},
#{businessType,jdbcType=VARCHAR}, #{applyIdL2,jdbcType=VARCHAR}, #{supplyName,jdbcType=VARCHAR},
#{grossDate2,jdbcType=TIMESTAMP}, #{grossDate1,jdbcType=TIMESTAMP}, #{grossStation1,jdbcType=VARCHAR},
#{ladleSeq,jdbcType=VARCHAR}, #{cellIdList,jdbcType=VARCHAR}, #{assignment,jdbcType=VARCHAR},
#{unitCarriedName,jdbcType=VARCHAR}, #{remark,jdbcType=VARCHAR}, #{flag,jdbcType=VARCHAR},
#{ladleId,jdbcType=VARCHAR})
</insert>
<insert id="insertSelective" parameterType="org.spring.springboot.domain.IntfCalculateZpf" >
insert into INTF_CALCULATE_ZPF
<trim prefix="(" suffix=")" suffixOverrides="," >
<if test="sysid != null" >
SYSID,
</if>
<if test="sid != null" >
SID,
</if>
<if test="applyId != null" >
APPLY_ID,
</if>
<if test="carNo != null" >
CAR_NO,
</if>
<if test="l4Matnr != null" >
L4_MATNR,
</if>
<if test="matName != null" >
MAT_NAME,
</if>
<if test="priceUnit != null" >
PRICE_UNIT,
</if>
<if test="grossWt != null" >
GROSS_WT,
</if>
<if test="grossDate != null" >
GROSS_DATE,
</if>
<if test="tareWt != null" >
TARE_WT,
</if>
<if test="tareDate != null" >
TARE_DATE,
</if>
<if test="weight != null" >
WEIGHT,
</if>
<if test="wtUnit != null" >
WT_UNIT,
</if>
<if test="grossBy != null" >
GROSS_BY,
</if>
<if test="businessId != null" >
BUSINESS_ID,
</if>
<if test="businessType != null" >
BUSINESS_TYPE,
</if>
<if test="applyIdL2 != null" >
APPLY_ID_L2,
</if>
<if test="supplyName != null" >
SUPPLY_NAME,
</if>
<if test="grossDate2 != null" >
GROSS_DATE_2,
</if>
<if test="grossDate1 != null" >
GROSS_DATE_1,
</if>
<if test="grossStation1 != null" >
GROSS_STATION_1,
</if>
<if test="ladleSeq != null" >
LADLE_SEQ,
</if>
<if test="cellIdList != null" >
CELL_ID_LIST,
</if>
<if test="assignment != null" >
ASSIGNMENT,
</if>
<if test="unitCarriedName != null" >
UNIT_CARRIED_NAME,
</if>
<if test="remark != null" >
REMARK,
</if>
<if test="flag != null" >
FLAG,
</if>
<if test="ladleId != null" >
LADLE_ID,
</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides="," >
<if test="sysid != null" >
#{sysid,jdbcType=TIMESTAMP},
</if>
<if test="sid != null" >
#{sid,jdbcType=DECIMAL},
</if>
<if test="applyId != null" >
#{applyId,jdbcType=VARCHAR},
</if>
<if test="carNo != null" >
#{carNo,jdbcType=VARCHAR},
</if>
<if test="l4Matnr != null" >
#{l4Matnr,jdbcType=VARCHAR},
</if>
<if test="matName != null" >
#{matName,jdbcType=VARCHAR},
</if>
<if test="priceUnit != null" >
#{priceUnit,jdbcType=VARCHAR},
</if>
<if test="grossWt != null" >
#{grossWt,jdbcType=DECIMAL},
</if>
<if test="grossDate != null" >
#{grossDate,jdbcType=TIMESTAMP},
</if>
<if test="tareWt != null" >
#{tareWt,jdbcType=DECIMAL},
</if>
<if test="tareDate != null" >
#{tareDate,jdbcType=TIMESTAMP},
</if>
<if test="weight != null" >
#{weight,jdbcType=DECIMAL},
</if>
<if test="wtUnit != null" >
#{wtUnit,jdbcType=VARCHAR},
</if>
<if test="grossBy != null" >
#{grossBy,jdbcType=VARCHAR},
</if>
<if test="businessId != null" >
#{businessId,jdbcType=VARCHAR},
</if>
<if test="businessType != null" >
#{businessType,jdbcType=VARCHAR},
</if>
<if test="applyIdL2 != null" >
#{applyIdL2,jdbcType=VARCHAR},
</if>
<if test="supplyName != null" >
#{supplyName,jdbcType=VARCHAR},
</if>
<if test="grossDate2 != null" >
#{grossDate2,jdbcType=TIMESTAMP},
</if>
<if test="grossDate1 != null" >
#{grossDate1,jdbcType=TIMESTAMP},
</if>
<if test="grossStation1 != null" >
#{grossStation1,jdbcType=VARCHAR},
</if>
<if test="ladleSeq != null" >
#{ladleSeq,jdbcType=VARCHAR},
</if>
<if test="cellIdList != null" >
#{cellIdList,jdbcType=VARCHAR},
</if>
<if test="assignment != null" >
#{assignment,jdbcType=VARCHAR},
</if>
<if test="unitCarriedName != null" >
#{unitCarriedName,jdbcType=VARCHAR},
</if>
<if test="remark != null" >
#{remark,jdbcType=VARCHAR},
</if>
<if test="flag != null" >
#{flag,jdbcType=VARCHAR},
</if>
<if test="ladleId != null" >
#{ladleId,jdbcType=VARCHAR},
</if>
</trim>
</insert>
<update id="updateByPrimaryKeySelective" parameterType="org.spring.springboot.domain.IntfCalculateZpf" >
update INTF_CALCULATE_ZPF
<set >
<if test="sid != null" >
SID = #{sid,jdbcType=DECIMAL},
</if>
<if test="applyId != null" >
APPLY_ID = #{applyId,jdbcType=VARCHAR},
</if>
<if test="carNo != null" >
CAR_NO = #{carNo,jdbcType=VARCHAR},
</if>
<if test="l4Matnr != null" >
L4_MATNR = #{l4Matnr,jdbcType=VARCHAR},
</if>
<if test="matName != null" >
MAT_NAME = #{matName,jdbcType=VARCHAR},
</if>
<if test="priceUnit != null" >
PRICE_UNIT = #{priceUnit,jdbcType=VARCHAR},
</if>
<if test="grossWt != null" >
GROSS_WT = #{grossWt,jdbcType=DECIMAL},
</if>
<if test="grossDate != null" >
GROSS_DATE = #{grossDate,jdbcType=TIMESTAMP},
</if>
<if test="tareWt != null" >
TARE_WT = #{tareWt,jdbcType=DECIMAL},
</if>
<if test="tareDate != null" >
TARE_DATE = #{tareDate,jdbcType=TIMESTAMP},
</if>
<if test="weight != null" >
WEIGHT = #{weight,jdbcType=DECIMAL},
</if>
<if test="wtUnit != null" >
WT_UNIT = #{wtUnit,jdbcType=VARCHAR},
</if>
<if test="grossBy != null" >
GROSS_BY = #{grossBy,jdbcType=VARCHAR},
</if>
<if test="businessId != null" >
BUSINESS_ID = #{businessId,jdbcType=VARCHAR},
</if>
<if test="businessType != null" >
BUSINESS_TYPE = #{businessType,jdbcType=VARCHAR},
</if>
<if test="applyIdL2 != null" >
APPLY_ID_L2 = #{applyIdL2,jdbcType=VARCHAR},
</if>
<if test="supplyName != null" >
SUPPLY_NAME = #{supplyName,jdbcType=VARCHAR},
</if>
<if test="grossDate2 != null" >
GROSS_DATE_2 = #{grossDate2,jdbcType=TIMESTAMP},
</if>
<if test="grossDate1 != null" >
GROSS_DATE_1 = #{grossDate1,jdbcType=TIMESTAMP},
</if>
<if test="grossStation1 != null" >
GROSS_STATION_1 = #{grossStation1,jdbcType=VARCHAR},
</if>
<if test="ladleSeq != null" >
LADLE_SEQ = #{ladleSeq,jdbcType=VARCHAR},
</if>
<if test="cellIdList != null" >
CELL_ID_LIST = #{cellIdList,jdbcType=VARCHAR},
</if>
<if test="assignment != null" >
ASSIGNMENT = #{assignment,jdbcType=VARCHAR},
</if>
<if test="unitCarriedName != null" >
UNIT_CARRIED_NAME = #{unitCarriedName,jdbcType=VARCHAR},
</if>
<if test="remark != null" >
REMARK = #{remark,jdbcType=VARCHAR},
</if>
<if test="flag != null" >
FLAG = #{flag,jdbcType=VARCHAR},
</if>
<if test="ladleId != null" >
LADLE_ID = #{ladleId,jdbcType=VARCHAR},
</if>
</set>
where SYSID = #{sysid,jdbcType=TIMESTAMP}
</update>
<update id="updateByPrimaryKey" parameterType="org.spring.springboot.domain.IntfCalculateZpf" >
update INTF_CALCULATE_ZPF
set SID = #{sid,jdbcType=DECIMAL},
APPLY_ID = #{applyId,jdbcType=VARCHAR},
CAR_NO = #{carNo,jdbcType=VARCHAR},
L4_MATNR = #{l4Matnr,jdbcType=VARCHAR},
MAT_NAME = #{matName,jdbcType=VARCHAR},
PRICE_UNIT = #{priceUnit,jdbcType=VARCHAR},
GROSS_WT = #{grossWt,jdbcType=DECIMAL},
GROSS_DATE = #{grossDate,jdbcType=TIMESTAMP},
TARE_WT = #{tareWt,jdbcType=DECIMAL},
TARE_DATE = #{tareDate,jdbcType=TIMESTAMP},
WEIGHT = #{weight,jdbcType=DECIMAL},
WT_UNIT = #{wtUnit,jdbcType=VARCHAR},
GROSS_BY = #{grossBy,jdbcType=VARCHAR},
BUSINESS_ID = #{businessId,jdbcType=VARCHAR},
BUSINESS_TYPE = #{businessType,jdbcType=VARCHAR},
APPLY_ID_L2 = #{applyIdL2,jdbcType=VARCHAR},
SUPPLY_NAME = #{supplyName,jdbcType=VARCHAR},
GROSS_DATE_2 = #{grossDate2,jdbcType=TIMESTAMP},
GROSS_DATE_1 = #{grossDate1,jdbcType=TIMESTAMP},
GROSS_STATION_1 = #{grossStation1,jdbcType=VARCHAR},
LADLE_SEQ = #{ladleSeq,jdbcType=VARCHAR},
CELL_ID_LIST = #{cellIdList,jdbcType=VARCHAR},
ASSIGNMENT = #{assignment,jdbcType=VARCHAR},
UNIT_CARRIED_NAME = #{unitCarriedName,jdbcType=VARCHAR},
REMARK = #{remark,jdbcType=VARCHAR},
FLAG = #{flag,jdbcType=VARCHAR},
LADLE_ID = #{ladleId,jdbcType=VARCHAR}
where SYSID = #{sysid,jdbcType=TIMESTAMP}
</update>
</mapper>
/**
* @Title: IntfCalculateZpfServiceImpl.java
* @Package org.spring.springboot.service.impl
* @Description: TODO(用一句话描述该文件做什么)
* @author pengfei
* @date 2017年7月15日 上午10:57:54
* @version V1.0
*/
package org.spring.springboot.service.impl;
import java.math.BigDecimal;
import java.util.Date;
import org.spring.springboot.dao.master.IntfCalculateZpfMapper;
import org.spring.springboot.domain.IntfCalculateZpf;
import org.spring.springboot.service.IntfCalculateZpfService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
/**
* @author zhangPengFei QQ:635332940
* @version 创建时间:2017年7月15日 上午10:57:54
* 说明 :
*/
/**
* @author pengfei
*@version 创建时间:2017年7月15日 上午10:57:54
* @Description:TODO(这里用一句话描述这个类的作用)
*
*/
@Service
public class IntfCalculateZpfServiceImpl implements IntfCalculateZpfService {
@Autowired
private IntfCalculateZpfMapper intfCalculateZpfDao; // 主数据源
/* (非 Javadoc)
* <p>Title: selectBySid</p>
* <p>Description: </p>
* @param sid
* @return
* @see org.spring.springboot.service.IntfCalculateZpfService#selectBySid(java.lang.String)
*/
@Transactional //这个就是事务控制
public IntfCalculateZpf selectBySid(String sid) {
IntfCalculateZpf inf=intfCalculateZpfDao.selectByPrimaryKey(null);
IntfCalculateZpf record=new IntfCalculateZpf();
BigDecimal sid1=new BigDecimal(12);
record.setSid(sid1);
record.setCarNo("FDSAFSFASF");
record.setSysid(new Date());
intfCalculateZpfDao.insert(record);
int a=4/1;
System.out.println(a);
return inf;
}
}
package org.spring.springboot;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.web.servlet.ServletComponentScan;
/**
* Spring Boot 应用启动类
*
* Created by bysocket on 16/4/26.
*/
// Spring Boot 应用的标识
@SpringBootApplication
@ServletComponentScan//@MapperScan 如果Mapper下面没有@mapper 这个就要加上去,官方说的,但我没有加也运行了,具体请各位指教
public class Application {
public static void main(String[] args) {
// 程序启动入口
// 启动嵌入式的 Tomcat 并初始化 Spring 环境及其各 Spring 组件
SpringApplication.run(Application.class,args);
}
}
/**
* @Title: DruidStatFilter.java
* @Package org.spring.springboot.servlet
* @Description: TODO(用一句话描述该文件做什么)
* @author pengfei
* @date 2017年7月15日 下午3:28:56
* @version V1.0
*/
package org.spring.springboot.servlet;
import javax.servlet.annotation.WebFilter;
import javax.servlet.annotation.WebInitParam;
import com.alibaba.druid.support.http.WebStatFilter;
/**
* Druid的StatFilter
*
* @author 单红宇(365384722)
* @myblog http://blog.csdn.net/catoop/
* @create 2016年3月17日
*/
@WebFilter(filterName="druidWebStatFilter",urlPatterns="/*",
initParams={
@WebInitParam(name="exclusions",value="*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*")// 忽略资源
})
public class DruidStatFilter extends WebStatFilter {
}
/**
* @Title: DruidStatViewServlet.java
* @Package org.spring.springboot.servlet
* @Description: TODO(用一句话描述该文件做什么)
* @author pengfei
* @date 2017年7月15日 下午3:28:13
* @version V1.0
*/
package org.spring.springboot.servlet;
import javax.servlet.annotation.WebInitParam;
import javax.servlet.annotation.WebServlet;
import com.alibaba.druid.support.http.StatViewServlet;
/**
* StatViewServlet
*
* @author 单红宇(365384722)
* @myblog http://blog.csdn.net/catoop/
* @create 2016年3月17日
*/
@SuppressWarnings("serial")
@WebServlet(urlPatterns = "/druid/*",
initParams={
@WebInitParam(name="allow",value="192.168.16.110,127.0.0.1"),// IP白名单 (没有配置或者为空,则允许所有访问)
@WebInitParam(name="deny",value="192.168.16.111"),// IP黑名单 (存在共同时,deny优先于allow)
@WebInitParam(name="loginUsername",value="admin"),// 用户名
@WebInitParam(name="loginPassword",value="123456"),// 密码
@WebInitParam(name="resetEnable",value="false")// 禁用HTML页面上的“Reset All”功能
})
public class DruidStatViewServlet extends StatViewServlet{
}
我的测试类:test
/**
* @Title: test.java
* @Package org.test
* @Description: TODO(用一句话描述该文件做什么)
* @author pengfei
* @date 2017年7月15日 下午1:03:41
* @version V1.0
*/
package org.test;
import java.math.BigDecimal;
import java.util.List;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.spring.springboot.Application;
import org.spring.springboot.dao.master.IntfCalculateZpfMapper;
import org.spring.springboot.domain.IntfCalculateZpf;
import org.spring.springboot.service.IntfCalculateZpfService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
/**
* @author zhangPengFei QQ:635332940
* @version 创建时间:2017年7月15日 下午1:03:41
* 说明 :
*/
/**
* @author pengfei
*@version 创建时间:2017年7月15日 下午1:03:41
* @Description:TODO(这里用一句话描述这个类的作用)
*
*/
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes=Application.class)
public class test {
@Autowired
private IntfCalculateZpfMapper intfCalculateZpfDao; // 主数据源
@Autowired
private IntfCalculateZpfService intfCalculateZpfService;
@Test
public void test(){
BigDecimal sid=new BigDecimal(12);
List<IntfCalculateZpf> list=intfCalculateZpfDao.selectBySid(sid);
System.out.println(list.size());
}
@Test
public void test2(){
BigDecimal sid=new BigDecimal(12);
IntfCalculateZpf list=intfCalculateZpfService.selectBySid("12");
System.out.println(list);
}
}
基本上就是这样了,有什么问题大家可以联系我QQ:635332940 张生
下载地址:http://download.csdn.net/detail/zpf5126/9902227















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









