










(一)何谓聚类
还是那句“物以类聚、人以群分”,如果预先知道人群的标签(如文艺、普通、2B),那么根据监督学习的分类算法可将一个人明确的划分到某一类;如果预先不知道人群的标签,那就只有根据人的特征(如爱好、学历、职业等)划堆了,这就是聚类算法。
聚类是一种无监督的学习(无监督学习不依赖预先定义的类或带类标记的训练实例),它将相似的对象归到同一个簇中,它是观察式学习,而非示例式的学习,有点像全自动分类。所谓簇就是该集合中的对象有很大的相似性,而不同集合间的对象有很大的相异性。簇识别(cluster identification)给出了聚类结果的含义,告诉我们这些簇到底都是些什么。通常情况下,簇质心可以代表整个簇的数据来做出决策。聚类方法几乎可以应用于所有对象,簇内的对象越相似,聚类的效果越好。
说白了,聚类(clustering)是完全可以按字面意思来理解的——将相同、相似、相近、相关的对象实例聚成一类的过程。简单理解,如果一个数据集合包含N个实例,根据某种准则可以将这N个实例划分为m个类别,每个类别中的实例都是相关的,而不同类别之间是区别的也就是不相关的,这就得到了一个聚类模型了。判别新样本点的所属类时,就通过计算该点与这m个类别的相似度,选择最相似的那个类作为该点的归类。
机器学习中常见的聚类算法包括 k-Means算法、期望最大化算法(Expectation Maximization,EM,参考“EM算法原理”)、谱聚类算法(参考机器学习算法复习-谱聚类)以及人工神经网络算法,本文介绍K-均值(K-means)聚类算法。
(二)K-均值聚类算法
1. 认识K-均值聚类算法
在聚类分析中,K-均值聚类算法(k-means algorithm)是无监督分类中的一种基本方法,其也称为C-均值算法,其基本思想是:通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
k-means算法的基础是最小误差平方和准则。其代价函数是:
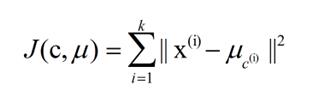
式中,μc(i)表示第i个簇的质心,我们希望得到的聚类模型代价函数最小,直观的来说,各簇内的样本越相似,其与该簇质心的误差平方越小。计算所有簇的误差平方之和,即可验证分为k个簇时时的聚类是否是最优的。SSE值越小表示数据点越接近于它们的质心,聚类效果也越好。因为对误差取了平方,因此更加重视那些远离中心的点。一种肯定可以降低SSE值的方法是增加簇的个数,但这违背了聚类的目标,聚类的目标是在保持族数目不变的情况下提高簇的质量。
k-均值(k-means)聚类算法之所以称之为k-均值是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含子数据集样本特征的均值计算而成。k-均值是发现给定数据集的k个簇的算法,簇个数k由用户给定,每一个簇通过其质心( centroid) — 即簇中所有点的中心来描述。K-均值聚类算法需要数值型数据来进行相似性度量,也可以将标称型数据映射为二值型数据再用于度量相似性,其优点是容易实现,缺点是可能收敛到局部最小值,在大规模数据集上收敛较慢。
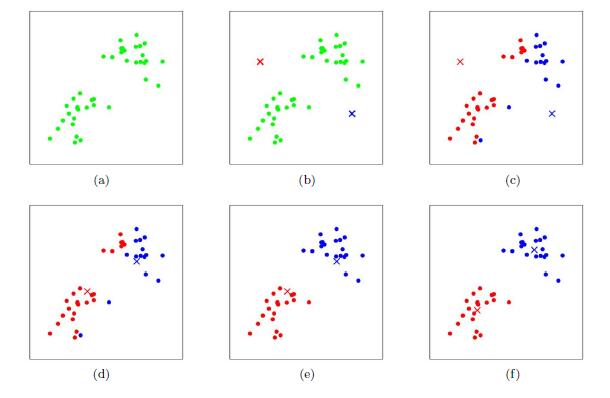
假设训练样本数据集X为(m, n)维矩阵,m表示样本数、n表示每个样本点的特征数,那么k-均值聚类算法的结果就是得到一个kxn维矩阵,k表示用户指定的簇个数,每一行都是一个长度为n的行向量–第i个元素就是该簇中所有样本第j(j=0,1,…,n-1)个特征的均值。下图是K-均值聚类算法聚类的过程:
2. 算法过程
假设要把样本集分为c个类别,算法如下:
(1)适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c个中心的距离,将该样本归到距离最短的中心所在的类,
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变(目标函数收敛),则迭代结束,否则继续迭代。
(三) K-均值算法的实现
实现步骤:
1.数据集的赋值
2.k均值算法的python实现
3.k均值算法的matlab实现
1.数据集的赋值
开始之前,我们可以看一下数据,如图:
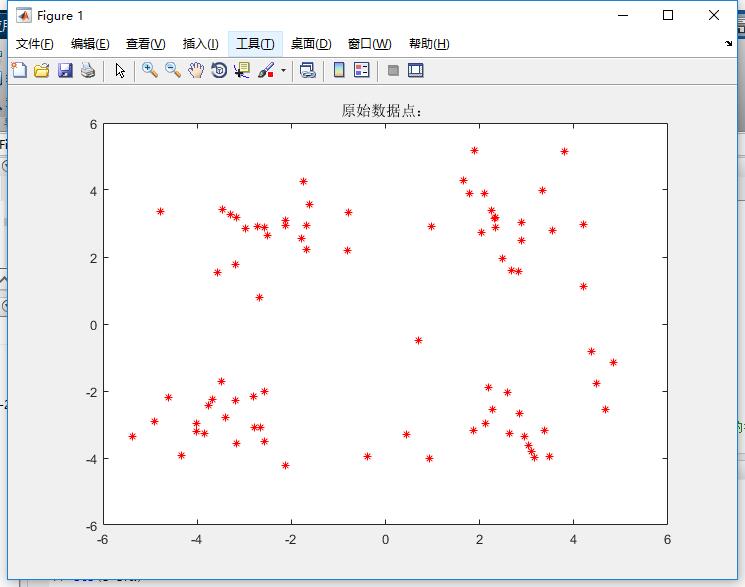
测试数据是二维的,共80个样本。有4个类。如下:
testSet.txt
1.658985 4.285136
-3.453687 3.424321
4.838138 -1.151539
-5.379713 -3.362104
0.972564 2.924086
-3.567919 1.531611
0.450614 -3.302219
-3.487105 -1.724432
2.668759 1.594842
-3.156485 3.191137
3.165506 -3.999838
-2.786837 -3.099354
4.208187 2.984927
-2.123337 2.943366
0.704199 -0.479481
-0.392370 -3.963704
2.831667 1.574018
-0.790153 3.343144
2.943496 -3.357075
-3.195883 -2.283926
2.336445 2.875106
-1.786345 2.554248
2.190101 -1.906020
-3.403367 -2.778288
1.778124 3.880832
-1.688346 2.230267
2.592976 -2.054368
-4.007257 -3.207066
2.257734 3.387564
-2.679011 0.785119
0.939512 -4.023563
-3.674424 -2.261084
2.046259 2.735279
-3.189470 1.780269
4.372646 -0.822248
-2.579316 -3.497576
1.889034 5.190400
-0.798747 2.185588
2.836520 -2.658556
-3.837877 -3.253815
2.096701 3.886007
-2.709034 2.923887
3.367037 -3.184789
-2.121479 -4.232586
2.329546 3.179764
-3.284816 3.273099
3.091414 -3.815232
-3.762093 -2.432191
3.542056 2.778832
-1.736822 4.241041
2.127073 -2.983680
-4.323818 -3.938116
3.792121 5.135768
-4.786473 3.358547
2.624081 -3.260715
-4.009299 -2.978115
2.493525 1.963710
-2.513661 2.642162
1.864375 -3.176309
-3.171184 -3.572452
2.894220 2.489128
-2.562539 2.884438
3.491078 -3.947487
-2.565729 -2.012114
3.332948 3.983102
-1.616805 3.573188
2.280615 -2.559444
-2.651229 -3.103198
2.321395 3.154987
-1.685703 2.939697
3.031012 -3.620252
-4.599622 -2.185829
4.196223 1.126677
-2.133863 3.093686
4.668892 -2.562705
-2.793241 -2.149706
2.884105 3.043438
-2.967647 2.848696
4.479332 -1.764772
-4.905566 -2.911070 2、k均值算法的python实现
kmeans.py
#################################################
# kmeans: k-means cluster
# Author : stu_why
# Date : 2016-12-06
# HomePage : http://blog.csdn.net/zpp1994
# Email : 1620009136@qq.com
#################################################
from sklearn.cluster import KMeans
import numpy
import matplotlib.pyplot as plt
# step 1: load data
print('step 1: load data...')
#读取testSet.txt数据并存储到dataSet中
dataSet = []
fileIn = open('testSet.txt')
for line in fileIn.readlines():
lineArr = line.strip().split()
dataSet.append('%0.6f' % float(lineArr[0]))
dataSet.append('%0.6f' % float(lineArr[1]))
# step 2: clustering...
print('step 2: clustering...')
#调用sklearn.cluster中的KMeans类
dataSet = numpy.array(dataSet).reshape(80,2)
kmeans = KMeans(n_clusters=4, random_state=0).fit(dataSet)
#求出聚类中心
center=kmeans.cluster_centers_
center_x=[]
center_y=[]
for i in range(len(center)):
center_x.append('%0.6f' % center[i][0])
center_y.append('%0.6f' % center[i][1])
#标注每个点的聚类结果
labels=kmeans.labels_
type1_x = []
type1_y = []
type2_x = []
type2_y = []
type3_x = []
type3_y = []
type4_x = []
type4_y = []
for i in range(len(labels)):
if labels[i] == 0:
type1_x.append(dataSet[i][0])
type1_y.append(dataSet[i][1])
if labels[i] == 1:
type2_x.append(dataSet[i][0])
type2_y.append(dataSet[i][1])
if labels[i] == 2:
type3_x.append(dataSet[i][0])
type3_y.append(dataSet[i][1])
if labels[i] == 3:
type4_x.append(dataSet[i][0])
type4_y.append(dataSet[i][1])
#画出四类数据点及聚类中心
plt.figure(figsize=(10,8), dpi=80)
axes = plt.subplot(111)
type1 = axes.scatter(type1_x, type1_y, s=40, c='red')
type2 = axes.scatter(type2_x, type2_y, s=40, c='green')
type3 = axes.scatter(type3_x, type3_y,s=40, c='pink' )
type4 = axes.scatter(type4_x, type4_y, s=40, c='yellow')
type_center = axes.scatter(center_x, center_y, s=40, c='blue')
plt.xlabel('x')
plt.ylabel('y')
axes.legend((type1, type2, type3, type4,type_center), ('0','1','2','3','center'),loc=1)
plt.show() 代码运行结果:
 其中,不同的类用不同的颜色来表示,其中的蓝色圆圈是对应类的均值质心点。
其中,不同的类用不同的颜色来表示,其中的蓝色圆圈是对应类的均值质心点。
3、k均值算法的matlab实现
用matlab编写k-均值聚类程序:
kmean.m
% k-均聚类算法
clc
clear;
% main variables
dim = 2; % 模式样本维数
k = 4; % 设有k个聚类中心
load('testSet.txt');
PM=testSet;% 模式样本矩阵
N = size(PM,1);
figure();
subplot(1,2,1);
for(i=1:N)
plot(PM(i,1),PM(i,2), '*r'); % 绘出原始的数据点
hold on
end
xlabel('X');
ylabel('Y');
title('聚类之前的数据点');
CC = zeros(k,dim); % 聚类中心矩阵,CC(i,:)初始值为i号样本向量
D = zeros(N,k); % D(i,j)是样本i和聚类中心j的距离
C = cell(1,k); %% 聚类矩阵,对应聚类包含的样本。初始状况下,聚类i(i<k)的样本集合为[i],聚类k的样本集合为[k,k+1,...N]
for i = 1:k-1
C{i} = [i];
end
C{k} = k:N;
B = 1:N; % 上次迭代中,样本属于哪一聚类,设初值为1
B(k:N) = k;
for i = 1:k
CC(i,:) = PM(i,:);
end
while 1
change = 0;%用来标记分类结果是否变化
% 对每一个样本i,计算到k个聚类中心的距离
for i = 1:N
for j = 1:k
% D(i,j) = eulerDis( PM(i,:), CC(j,:) );
D(i,j) = sqrt((PM(i,1) - CC(j,1))^2 + (PM(i,2) - CC(j,2))^2);
end
t = find( D(i,:) == min(D(i,:)) ); % i属于第t类
if B(i) ~= t % 上次迭代i不属于第t类
change = 1;
% 将i从第B(i)类中去掉
t1 = C{B(i)};
t2 = find( t1==i );
t1(t2) = t1(1);
t1 = t1(2:length(t1));
C{B(i)} = t1;
C{t} = [C{t},i]; % 将i加入第t类
B(i) = t;
end
end
if change == 0 %分类结果无变化,则迭代停止
break;
end
% 重新计算聚类中心矩阵CC
for i = 1:k
CC(i,:) = 0;
iclu = C{i};
for j = 1:length(iclu)
CC(i,:) = PM( iclu(j),: )+CC(i,:);
end
CC(i,:) = CC(i,:)/length(iclu);
end
end
subplot(1,2,2);
plot(CC(:,1),CC(:,2),'o')
hold on
for(i=1:N)
if(B(1,i)==1)
plot(PM(i,1),PM(i,2),'*b'); %作出第一类点的图形
hold on
elseif(B(1,i)==2)
plot(PM(i,1),PM(i,2), '*r'); %作出第二类点的图形
hold on
elseif(B(1,i)==3)
plot(PM(i,1),PM(i,2),'*g'); %作出第三类点的图形
hold on
else
plot(PM(i,1),PM(i,2), '*m'); %作出第四类点的图形
hold on
end
end
xlabel('X');
ylabel('Y');
title('聚类之后的数据点');
% 打印C,CC
for i = 1:k %输出每一类的样本点标号
str=['第' num2str(i) '类包含点: ' num2str(C{i})];
disp(str);
end;
利用testSet.tex的数据,代码运行结果如下:
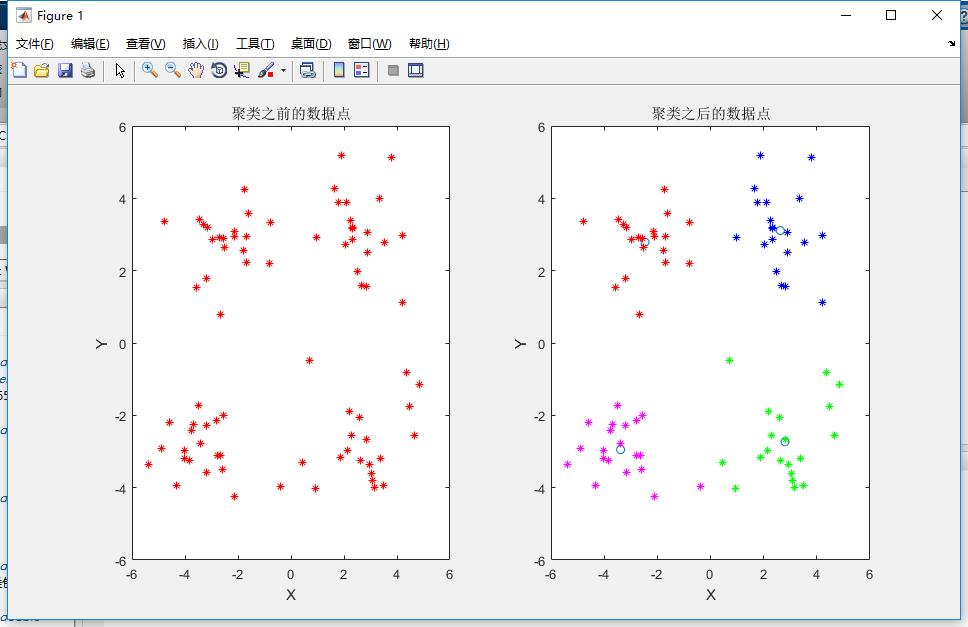
并在命令行输出每个点的类标记:
第1类包含点: 5 9 13 17 1 21 25 29 33 37 41 45 49 53 57 61 65 69 77 73
第2类包含点: 2 6 10 14 22 26 30 34 38 42 46 50 54 58 62 66 70 74 78 18
第3类包含点: 7 11 15 19 23 27 31 35 39 43 47 51 55 59 63 67 71 3 75 79
第4类包含点: 16 36 48 64 28 8 4 68 52 40 24 72 32 56 12 76 44 20 60 80















 7210
7210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









