







简介
csv:逗号分隔符文件(Comma Separated Values)
csv文件的写入
# -*- coding: utf-8 -*-
#要写入的数据和文件
filePath='./11.csv'
rowData=[['Spam', 'Spam', 'Spam', 'Spam', 'Spam', 'Baked Beans'], \
['Spam', 'Lovely Spam', 'Wonderful Spam'],\
['1','2','3','4 4 4','5','6','7'] \
]
#写入
import csv
with open(filePath, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for row in rowData:
writer.writerow(row)
写入结果:

csv文件的读取
import csv
with open(filePath, newline='') as f:
reader = csv.reader(f)
for row in reader:
print(row)
输出:
[‘Spam’, ‘Spam’, ‘Spam’, ‘Spam’, ‘Spam’, ‘Baked Beans’]
[‘Spam’, ‘Lovely Spam’, ‘Wonderful Spam’]
[‘1’, ‘2’, ‘3’, ‘4 4 4’, ‘5’, ‘6’, ‘7’]
模块中的其他方法与变量
print (csv.QUOTE_MINIMAL) #0
print(csv.QUOTE_NONE) #3
print(csv.list_dialects()) #获取所有dialect:['excel', 'excel-tab', 'unix']
#获取当前dialect对象:<_csv.Dialect object at 0x000001C601C0F538>
a=csv.get_dialect('excel')
print(a)
#添加自定义的dialect:zqd和zqd1
csv.register_dialect('zqd',a)
print(csv.list_dialects()) #['excel', 'excel-tab', 'unix', 'zqd']
#在dialect a d的基础上修改分隔符,并注册为新的dialect
csv.register_dialect('zqd1',a,delimiter=';')
print(csv.list_dialects()) #['excel', 'excel-tab', 'unix', 'zqd', 'zqd1']
#删除dialect:unix
csv.unregister_dialect('unix')
print(csv.list_dialects()) #['excel', 'excel-tab', 'zqd', 'zqd1']
#set or get the size limit
print(csv.field_size_limit()) #get size limit:131072
csv.field_size_limit(2555) #set size limit:2555
print(csv.field_size_limit()) #255
DictWriter类:写入字典
import csv
filePath='./11.csv'
with open(filePath, 'w', newline='') as csvfile:
fieldnames = ['first_name', 'last_name']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'first_name': 'Baked', 'last_name': 'Beans'})
writer.writerow({'first_name': 'Lovely', 'last_name': 'Spam'})
writer.writerow({'first_name': 'Wonderful', 'last_name': 'Spam'})
写入结果:
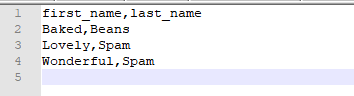
DictReader类:读取字典
with open(filePath, newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row['first_name'], row['last_name'])
读取结果:
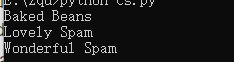
writer()与reader()方法解析
csv.writer(csvfile, dialect=‘excel’, **fmtparams)
csv.reader(csvfile, dialect=‘excel’, **fmtparams)
- csvfile
- 含writer()方法的对象;csvfile为文件对象时,打开时需要配置 newline=’’
- dialect
- 默认的dialect:[‘excel’, ‘excel-tab’, ‘unix’]
- 获取dialects:csv.list_dialects()
- fmtparams
- 修改当前dialect中的配置
例如:
import csv
with open(filePath, 'w', newline='') as csvfile:
writer = csv.writer(csvfile, delimiter=',',
quotechar='|', quoting=csv.QUOTE_MINIMAL)
for row in rowData:
writer.writerow(row)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









