






目录
(1) 配置Hadoop的运行时环境文件:hadoop-env.sh
(4)配置MapReduce:mapred-site.xml
一、虚拟机环境配置
1、创建一个虚拟机,然后再克隆两个虚拟机
在node2和node3中执行:查看主机名:cat /etc/hostname
在node2虚拟机中执行:修改主机名:hostnamectl set-hostname node2
在node3虚拟机中执行:修改主机名:hostnamectl set-hostname node3
提示:
reboot:重启
poweroff:关机
Ctrl+C:强制关闭运行中的代码 Ctrl+Z
2、创建映射文件
vi /etc/hosts 以编辑映射文件hosts
192.168.88.151 node1
192.168.88.152 node2
192.168.88.153 node3
3、配置虚拟机网络
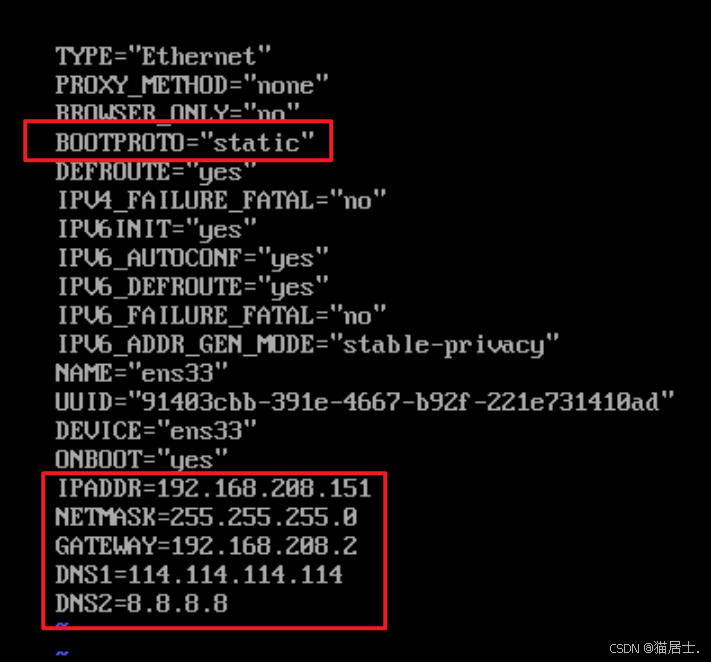
编辑3台虚拟机的网卡配置文件,执行命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.88.151/152/153
NETMASK=255.255.255.0
GATEWAY=192.168.88.2
DNS1=114.114.114.144
DNS2=8.8.8.8
 重启网络服务:systemctl restart network
重启网络服务:systemctl restart network
验证:
- 验证3台机器的ip地址: ip addr
- 验证3台机器的联网状态:ping www.baidu.com
4、配置虚拟机的SSH远程登录
在Node1中分别执行:rpm -qa | grep ssh和ps -ef | grep sshd,查看当前虚拟机是否安装和开启ssh服务。
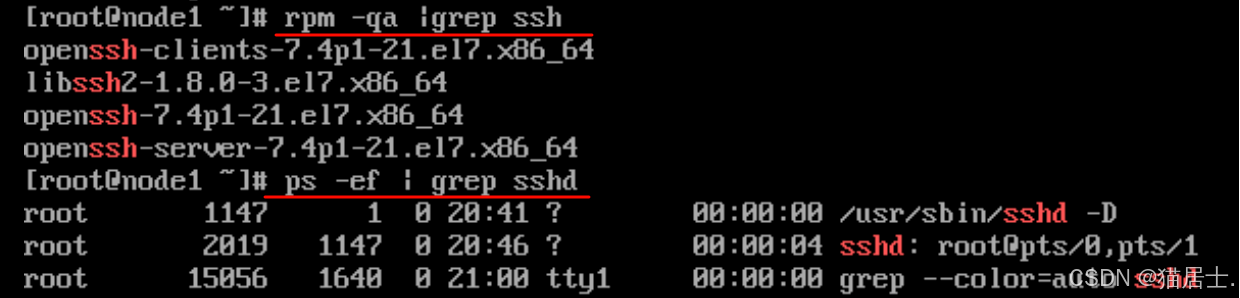
从上图可看到Node1已经默认安装并开启了ssh服务。
如果没有安装ssh,请执行命令:yum install open-server如果没有开启ssh,请执行命令:systemctl start sshd
5、使用远程连接工具FinalShell连接3台机器:
5.1、配置虚拟机SSH免密登录功能
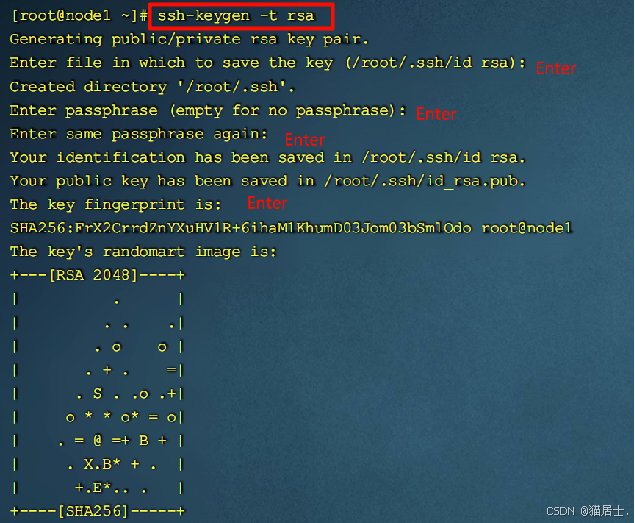
① 在主节点Node1中生成密钥,执行命令:ssh-keygen -t rsa
cd ~/.ssh 进入.ssh中
② 将主节点Node1生成的公钥文件复制到集群中相关联的所有虚拟机,实现主节点Node1免密登录到虚拟机Node1、Node2和node3。
在主节点Node1中执行3条命令:ssh-copy-id node1 , ssh-copy-id node2 , ssh-copy-id node3
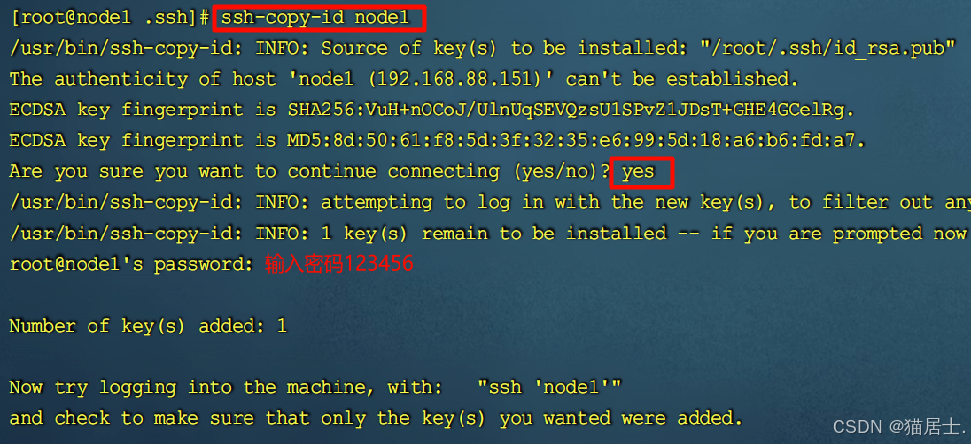
③ 测试免密登录:
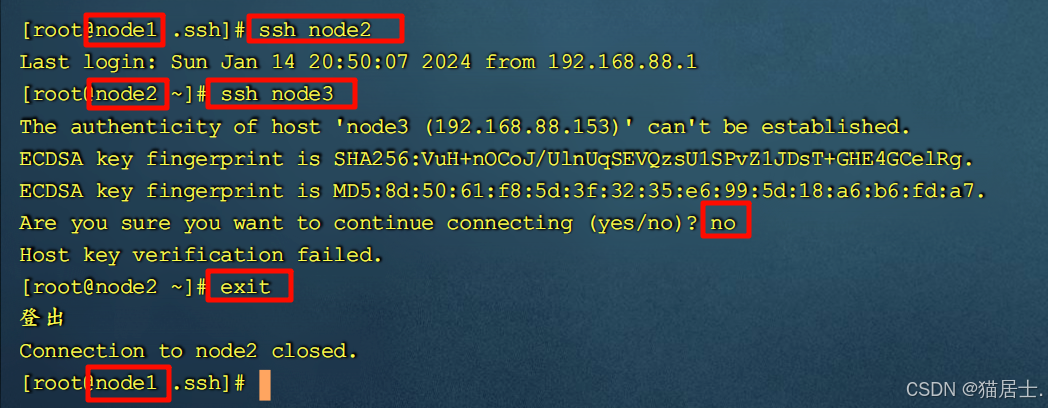
可以发现:
1)从node1可以免密登录到node2和node3;
2)但从node2不能登录到node3和node1;
3)执行exit命令可退出对node2的访问,回到node1;
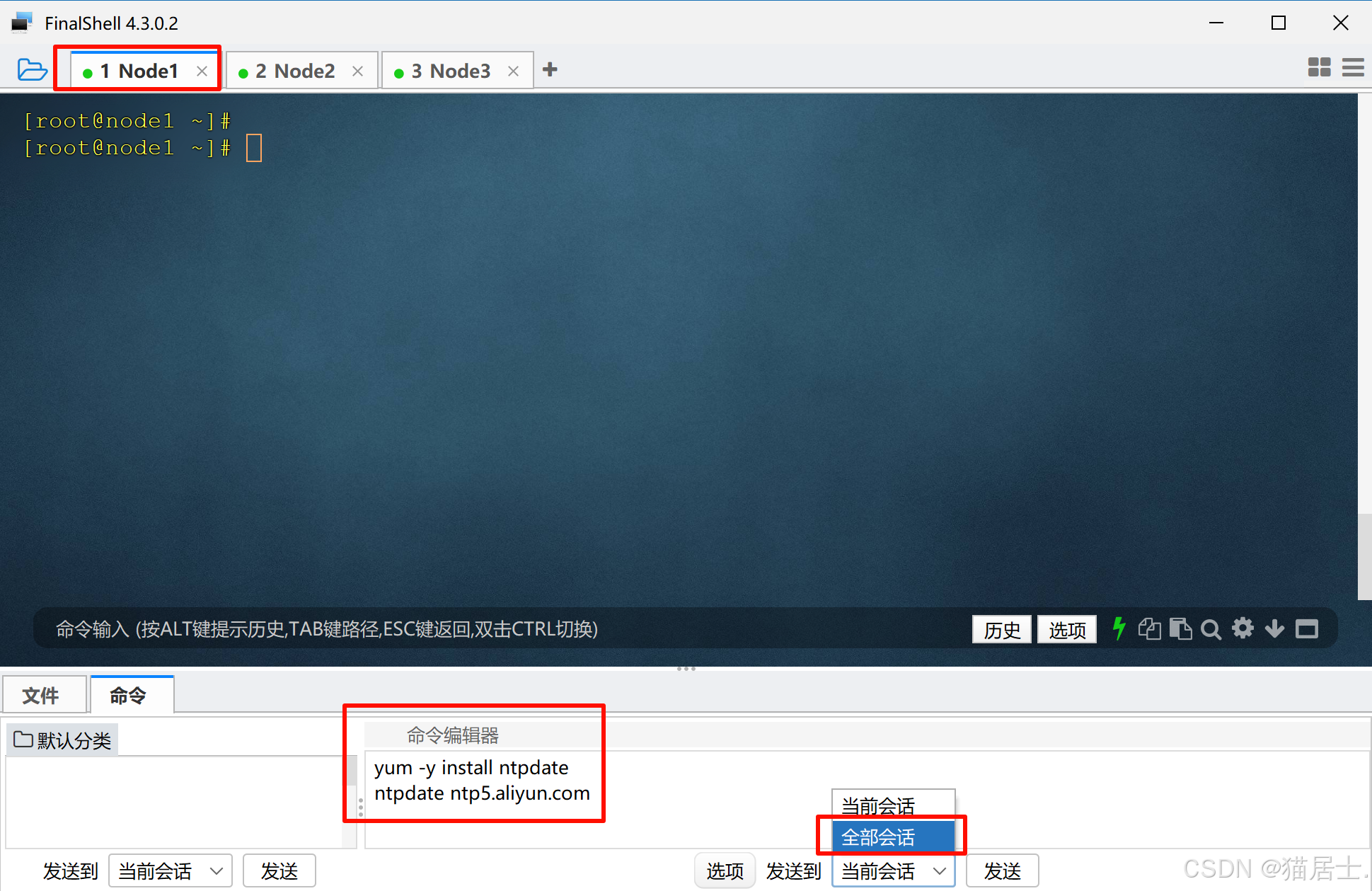
5.2、配置时间同步
在3中虚拟机中执行命令:(可以在其中一个node中执行,再发送到全部会话)
yum -y install ntpdate
ntpdate ntp5.aliyun.com
5.3、关闭防火墙
在3台虚拟机中执行命令:
systemctl stop firewalld.service #关闭防火墙
systemctl disable firewalld.service #禁止防火墙开启自启
6、安装配置JDK
6.1、创建目录
为了规范后续Hadoop集群存放相关安装包、数据和安装程序的目录,现约定:分别在3台虚拟机的根目录下创建以下3个目录,命令为:
# 创建存放数据的目
mkdir -p /export/data
# 创建存放安装包的目录
mkdir -p /export/software
# 创建程序的安装目录
mkdir -p /export/server
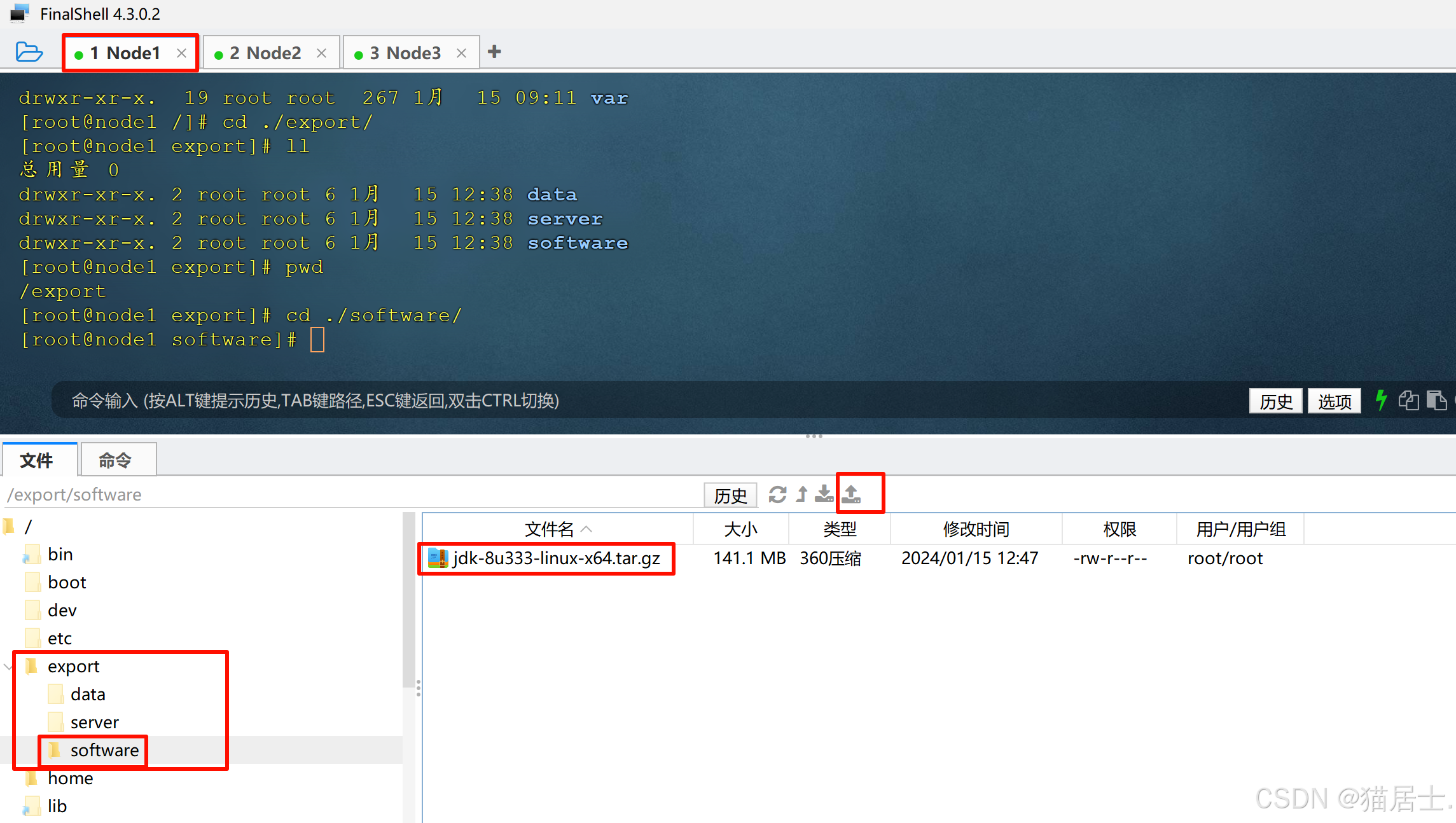
6.2、上传JDK安装包
将JDK的Linux版本上传到Node1的/export/software目录:
6.3、安装JDK
以解压的方式,将JDK安装到/export/server目录下,执行命令:
cd /export/software/
tar -zxvf jdk-8u333-linux-x64.tar.gz -C /export/server/

6.4、配置JDK的环境变量
① 编辑Node1的环境变量文件/etc/profile,在该文件的底部添加如下代码:
export JAVA_HOME=/export/server/jdk1.8.0_333
export PATH=$PATH:$JAVA_HOME/bin
② 添加完成后,还需要重新加载此配置文件,执行命令:source /etc/profile
③ 验证:执行命令:java -version:

6.5、分发JDK的安装目录到其它两台虚拟机
为了快速在Node2和Node3上安装JDK,现将Node1中的JDK安装目录分发到这两台虚拟机中。
在Node1中执行以下命令:
scp -r /export/server/jdk1.8.0_333 root@node2:/export/server/
scp -r /export/server/jdk1.8.0_333 root@node3:/export/server/
6.6、分发环境变量文件到其它两台虚拟机
在Node1中执行以下命令:
scp /etc/profile node2:/etc
scp /etc/profile node3:/etc
执行完上述命令后,还要分别在Node2和Node3中执行source /etc/profile命令以重新加载环境变量配置文件,并执行java -version命令以检查JDK环境;
二、部署Hadoop
1、下载、上传、安装Hadoop
(1)下载
Hadoop安装包、源码包下载地址: Index of /dist/hadoop/common/hadoop-3.3.0
其中:
- hadoop-3.3.0-src.tar.gz(32MB)是:源码包
- hadoop-3.3.0.tar.gz(478MB)是:官方编译安装包,需要下载这个;
(2)将hadoop-3.3.0.tar.gz上传到Node1的/export/software目录下;
(3)以解压方式安装Hadoop,将Hadoop安装到node1的/export/server目录下,执行命令:
tar -zxvf /export/software/hadoop-3.3.0.tar.gz -C /export/server
安装后的目录结构:
2、配置Hadoop环境变量
如果不为Hadoop配置环境变量,则每次执行Hadoop的命令时都需要进入Hadoop的安装目录,非常不便。
在Node1上执行命令:vi /etc/profile以编辑系统环境变量文件,在文件底部添加以下代码:
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
再执行命令:source /etc/profile使系统环境变量生效;
3、验证Hadoop的环境变量是否配置成功
在Node1的任意目录下执行命令:hadoop version,如果出现Hadoop的版本号说明配置成功;

4、修改Hadoop配置文件
(1) 配置Hadoop的运行时环境文件:hadoop-env.sh
在cd /export/server/hadoop-3.3.0/etc/hadoop目录下执行命令:vi hadoop-env.sh。在此文件的底部添加如下代码:
export JAVA_HOME=/export/server/jdk1.8.0_333
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
(2)配置Hadoop:vi core-site.xml
在此文件的<configuration>标签中添加如下代码:
<!-- 1.设置默认使用的文件系统。Hadoop还支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<!-- 2.设置Hadoop本地保存临时数据的路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 3.设置HDFS webUI的用户身份为root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 4.允许任何服务器的root用户可以向Hadoop提交任务 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value></property>
<!-- 5.允许任何用户组的root用户都可以向Hadoop提交任务 --><property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 6.指定HDFS中被删除的文件在回收站中的保存时长为1440秒,即24min -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
(3)配置HDFS:hdfs-site.xml
在此文件的<configuration>标签中添加如下代码:
<!-- 1.指定HDFS的副本数为2 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 2.指定SecondaryNameNode服务运行在虚拟机node2 --><property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
(4)配置MapReduce:mapred-site.xml
在此文件的<configuration>标签中添加如下代码:
<!-- 1.指定MapReduce任务运行在YARN之上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 2.指定MapReduce历史服务的通信地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- 3.指定通过WebUI访问MapReduce历史服务的地址 --><property>
<name>mapreduce.jobhistory.Webapp.address</name>
<value>node1:19888</value>
</property>
<!-- 4.指定MapReduce任务的运行环境,即Hadoop的安装目录 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
<!-- 5.指定MapReduce任务中Map阶段的运行环境,即Hadoop的安装目录 -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
<!-- 6.指定MapReduce任务中Reduce阶段的运行环境,即Hadoop的安装目录 --><property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
(5)配置YARN:yarn-site.xml
在此文件的<configuration>标签中添加如下代码:
<!-- 1.指定ResourceManager服务运行的虚拟机为node1 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- 2.指定NodeManager运行的附属服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 3.指定是否启动检测每个任务使用的物理内存,false表示关闭检测 --><property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 4.指定是否启动检测每个任务使用的虚拟内存,false表示关闭检测 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 5.指定是否开启日志聚合功能,true表示开启 -->
<property><name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 6.指定日志聚合的服务器 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value></property>
<!-- 7.指定日志聚合后的保存时间为604800秒,即7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
(6)配置Hadoop从节点运行的服务器
vi workers
编辑workers文件,将它的默认内容修改为:
node2
node3
5、分发Hadoop安装目录
使用scp命令将node1的Hadoop安装目录分发至node2和node3中程序的安装目录中:
scp -r /export/server/hadoop-3.3.0 root@node2:/export/server/
scp -r /export/server/hadoop-3.3.0 root@node3:/export/server/
6、分发系统环境变量文件
使用scp命令将node1的系统环境变量文件profile分发至node2和node3的/etc目录中:
scp /etc/profile node2:/etc
scp /etc/profile node3:/etc
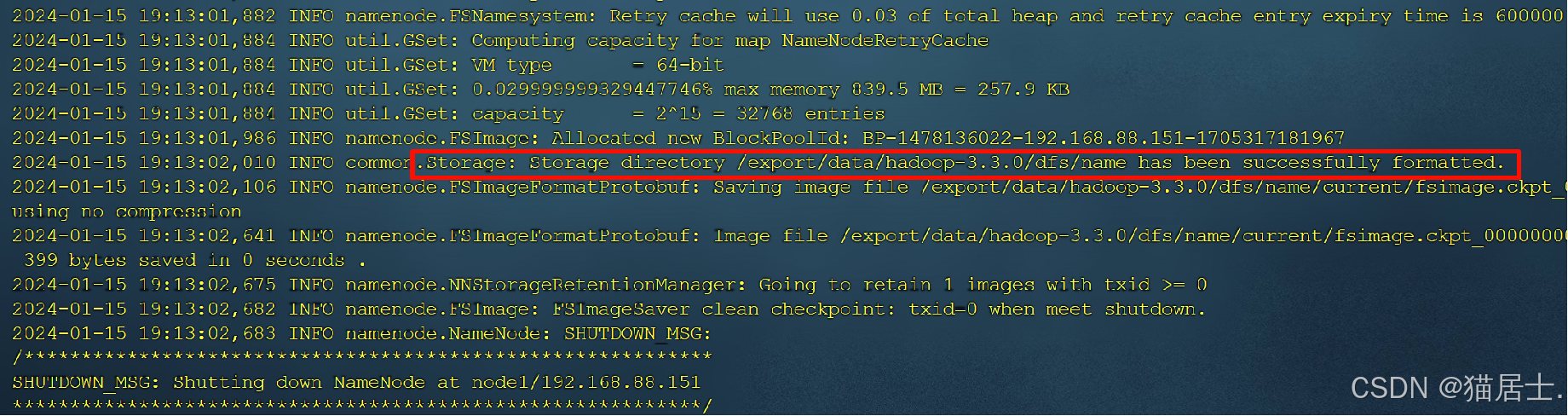
7、格式化HDFS文件系统
在虚拟机node1执行hdfs namenode -format命令,对基于完全分布式模式部署的Hadoop进行格式化HDFS文件系统的操作。 注意:格式化HDFS文件系统的操作只在初次启动Hadoop集群之前进行,且只能执行一次。
8、启动hadoop
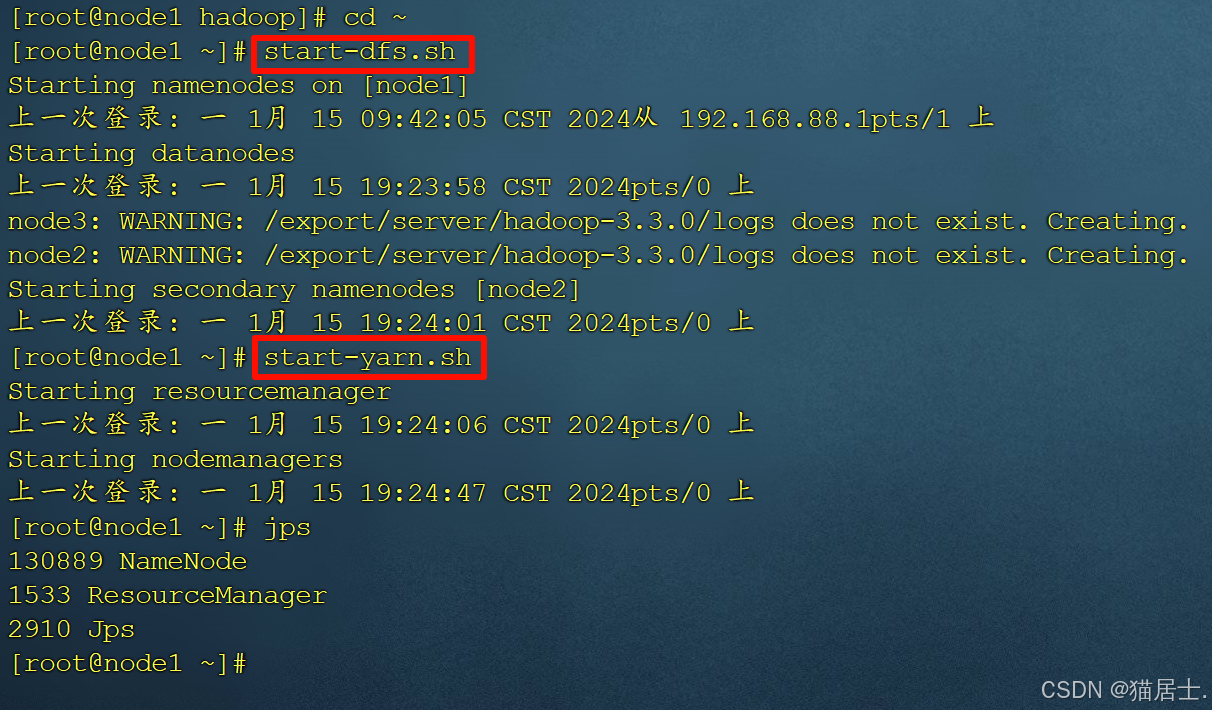
在虚拟机node1中执行命令 start-dfs.sh 以启动3台机器的HDFS服务;
在虚拟机node1中执行命令 start-yarn.sh 以启动3台机器的YARN服务;
如果要关闭Hadoop,则执行 stop-dfs.sh 和 stop-yarn.sh 命令;
9、查看Hadoop运行状态
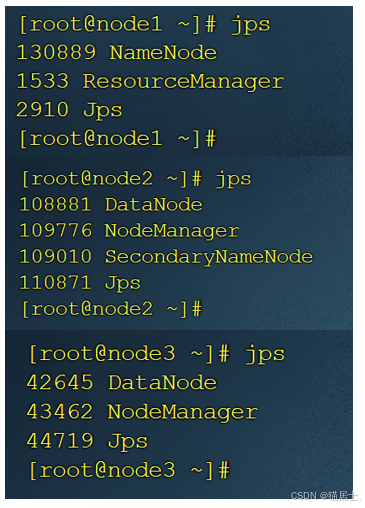
在3个节点中运行jps命令:
补充:关于jps:即JVM Process Status Tool。 功能:显示当前所有java进程pid,可以通过这个命令来查看到底启动了几个java进程(因为每一个java程序都会独占一个java虚拟机实例)。
从结果中可以看出:
- Node1运行着HDFS的NameNode服务和YARN的ResouceManager服务;
- Node2运行着HDFS的SecondaryNameNode和DataNode服务,以及YARN的NodeManager服务;
- Node3运行着HDFS的DataNode服务和YARN的NodeManager服务;
说明Hadoop启动成功。
10、通过Web界面查看Hadoop的运行状态
Hadoop启动成功后,用户可以通过Hadoop提供的Web界面来查看和管理HDFS和YARN,Hadoop默认占用服务器的9870和8088两个端口,用于用户访问HDFS(9870)和YARN(8088)的Web界面,我们可以在本地计算机的浏览器中输入NameNode和ResourceManager服务所运行的服务器IP地址或主机名,以及9870或8088端口访问HDFS或YARN的Web界面。
(1)由于虚拟机的防火墙会阻止用户从本地计算机(即一般为windows)的浏览器访问Hadoop提供的Web界面,所以需要关闭3台虚拟机的防火墙,并禁止防火墙的开机自启动。(此步骤已在上一节中操作过)
关闭防火墙:systemctl stop firewalld
禁止防火墙开机自启动:systemctl disable firewalld
(2)为了方便后续直接使用主机名访问Hadoop提供的Web界面,而不是通过IP地址,我们可以在个人计算机的hosts文件中添加Hadoop集群的IP映射信息。此hosts文件的地址一般为(win10):C:\Windows\System32\drivers\etc。
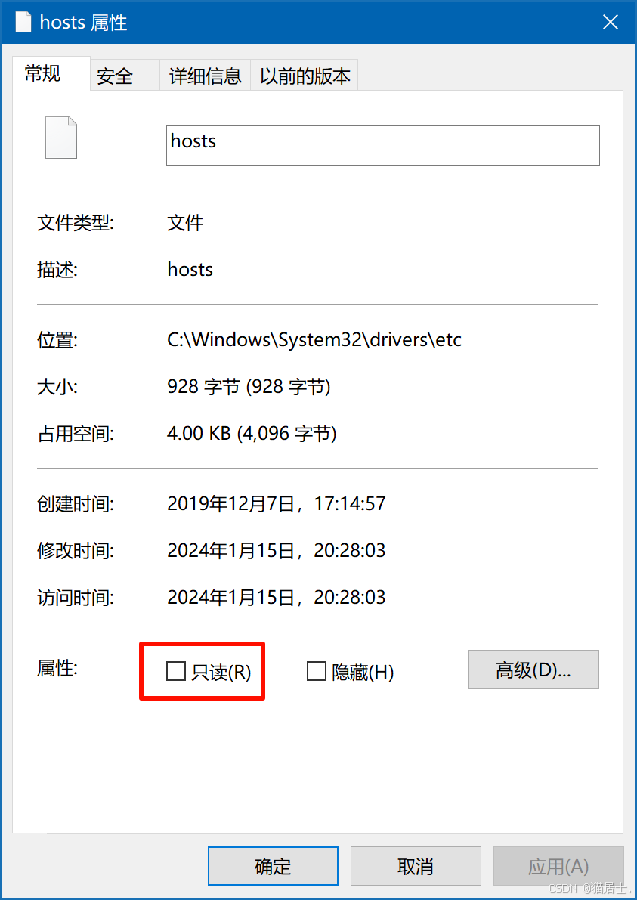
同时,此hosts文件一般不允许用户修改,需要将其权限中的只读取消:
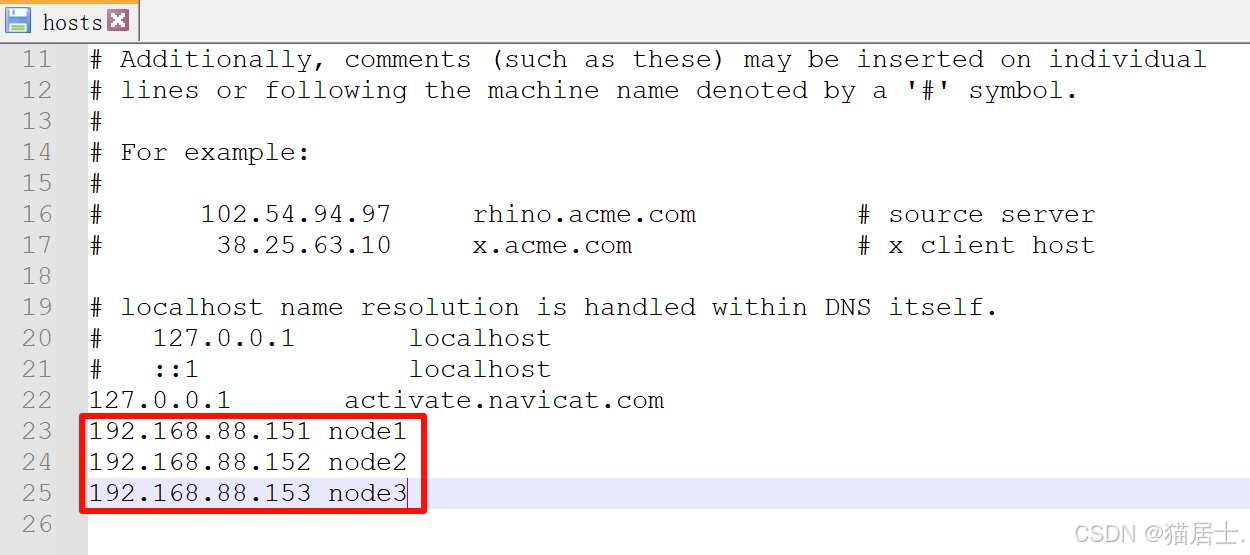
然后,在其中添加以下内容:
192.168.88.151 node1
192.168.88.152 node2
192.168.88.153 node3
(3)在本地计算机的浏览器中分别输入:http://node1:9870以查看HDFS的运行状态,和http://node1:8088以查看YARN的运行状态:
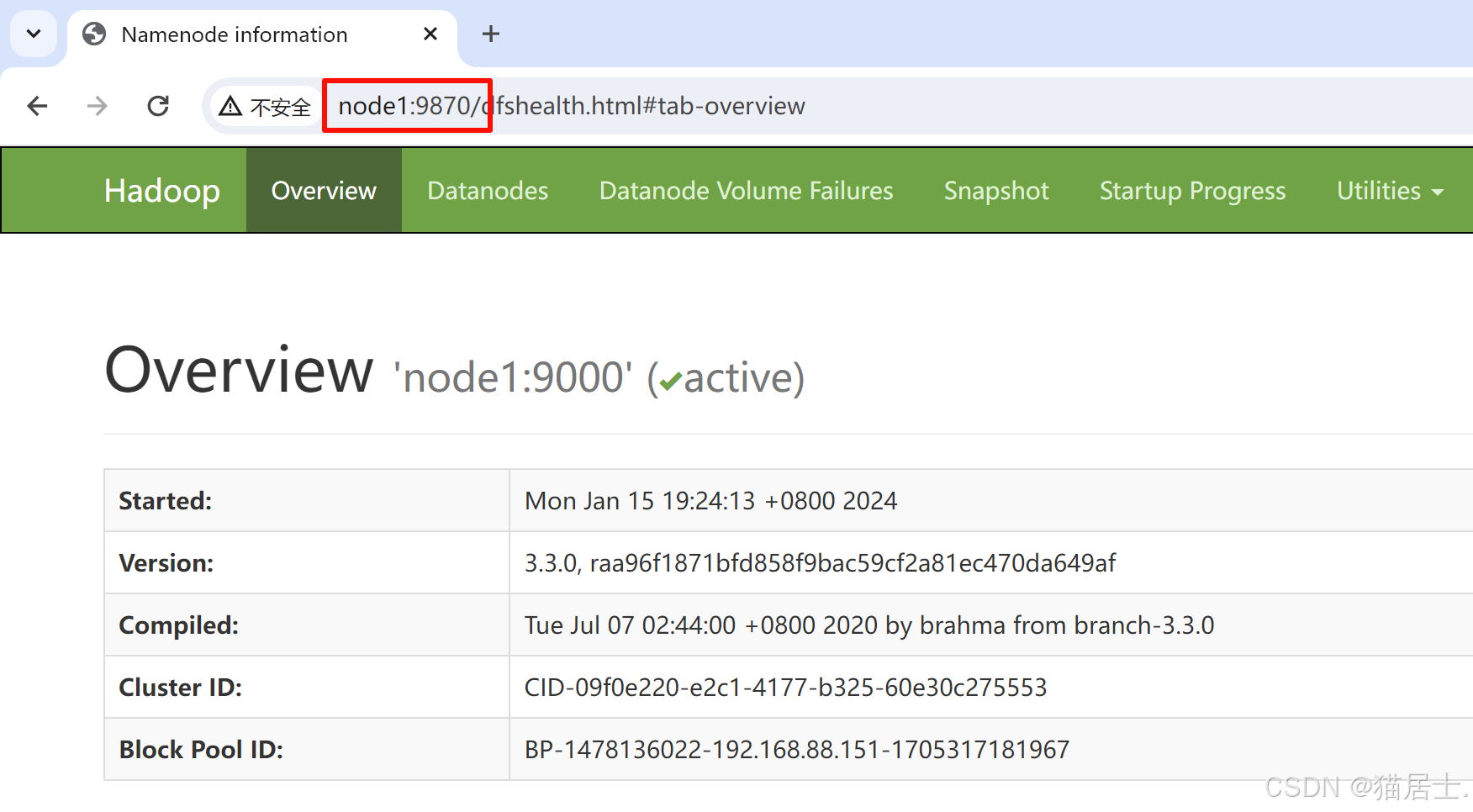
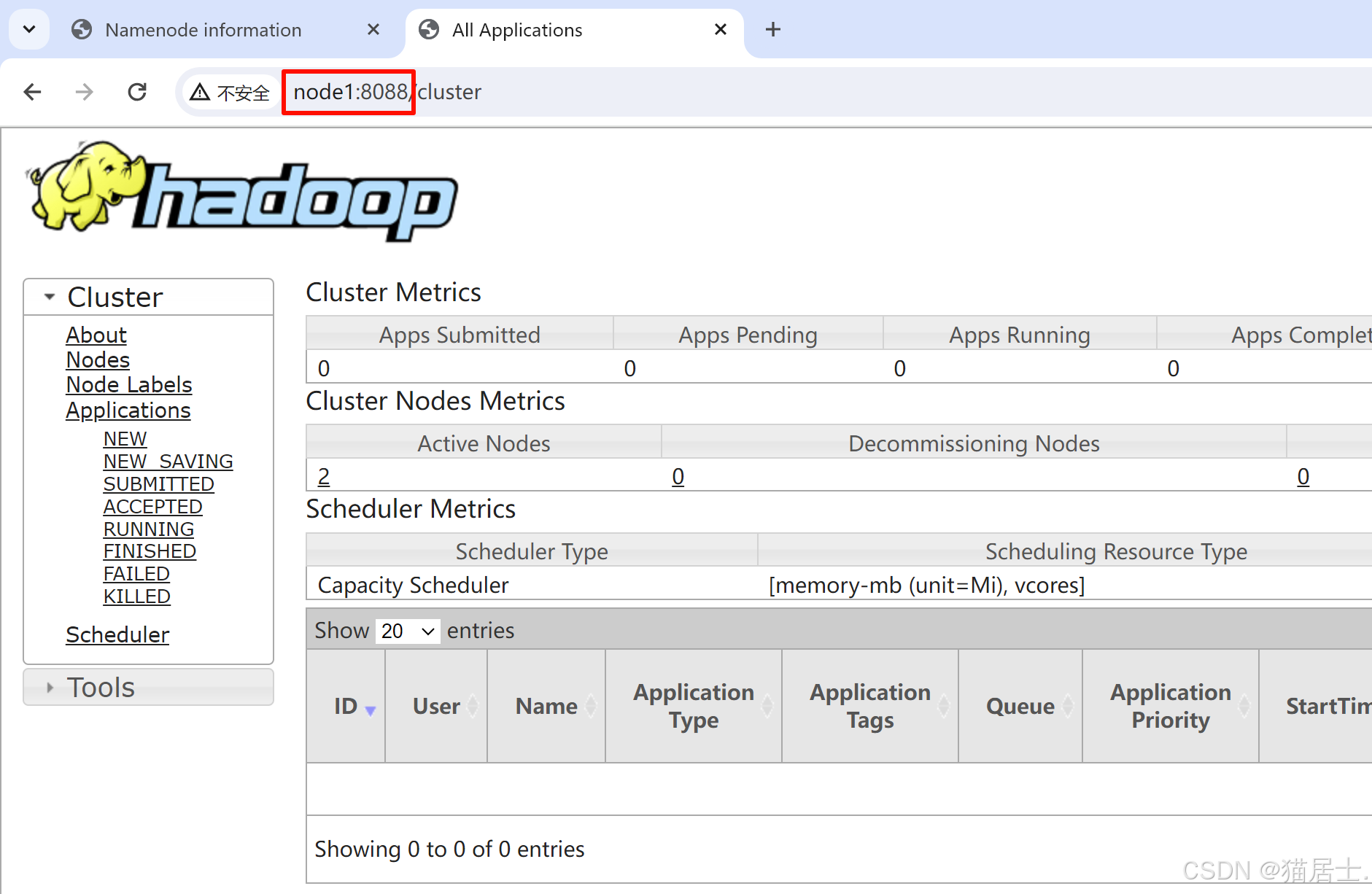

















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









