






原文地址:http://blog.csdn.net/zb1165048017/article/details/51483206
本文讲解如何对网上下载的一个图片利用训练好的cifar模型进行分类
第一步
上一篇文章训练好以后会得到两个文件
从网上查阅资料解释来看,第一个caffemodel是训练完毕得到的模型参数文件,第二个solverstate是训练中断以后,可以用此文件从中断地方继续训练(具体使用方法目前尚未测试)
第二步
新建一个代表cifar10数据标签txt文件,放在examples下的cifar10文件夹内,本文采用名称为synset_words的txt文件,内容如下:
从网上随便下载一个图片,但是注意,最好是cifar里面包含的种类,当然也可以下载其他的,不过分类得到的标签肯定不对,因为训练得到的模型不包含此种类。
比如我下载了一只猫:

第三步
使用模型进行分类,建立一个bat文件,比如我在E:\caffeDEV1\caffe-windows\Build\x64\Release下[同样可以在debug下]建立classification.bat,内容如下
如果你建立在其他地方,请注意你的路径。bat的格式为XX/XX/classification.exe
xx/xx/网络结构(cifar10_quick.prototxt) XX/XX/训练好的模型(.caffemodel.h5) XX/XX/均值文件 XX/XX/下载的图片
(XX/XX代表路径 )
第四步
也就说最后一步,直接运行这个bat文件,双击就行,得到如下结果
【注】我在其中一个地方卡了很久,千万千万不要把modelcaffe.h5的后缀改为modelcaffe,也就是说,千万别删掉了h5,我一直以为调用cifar10_quick_iter_4000.caffemodel,结果呵呵了,卡了一下午(如果只有modelcaffe,那么直接使用就好)
————————————————————————————————————
网络prototxt直接进行分类时,要注意网络结构的改进,是算prob,不是accuracy, 具体参见mnist文件夹下prototxt配置。cifar10文件夹下面也有quick分类和train-test一起的(自己注)
第五步
第四步实现得是单张图片的识别。第五步则对测试集进行准确率的分批测试
直接在E:\caffeDEV1\caffe-windows下建立一个bat文件(test_cifar.bat),内容如下:
【PS】注意,如果出现“cannot use GPU in CPU-only caffe :check mode.check failure stack trace.”问题,去掉后面的-gpu=0即可,代表使用CPU测试。
运行之后效果如下:
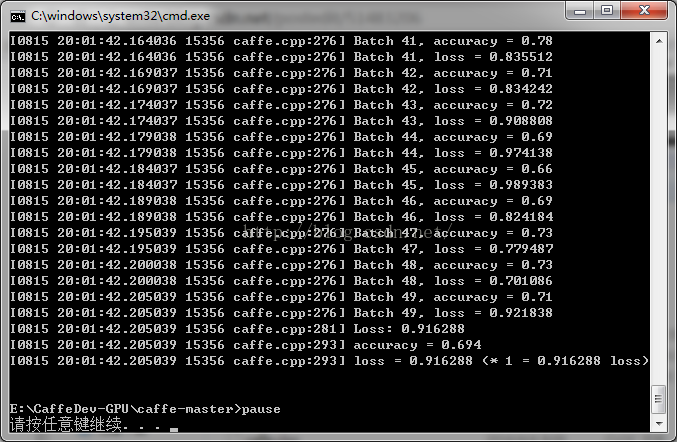
运行之后效果如下:















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









