







https://www.cnblogs.com/pinard/p/7249903.html 3/4 很好
4. Negative Sampling负采样方法
现在我们来看看如何进行负采样,得到neg个负例。word2vec采样的方法并不复杂,如果词汇表的大小为VV,那么我们就将一段长度为1的线段分成VV份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,高频词对应的线段长,低频词对应的线段短。每个词ww的线段长度由下式决定:
len(w)=count(w)∑u∈vocabcount(u)len(w)=count(w)∑u∈vocabcount(u)
在word2vec中,分子和分母都取了3/4次幂如下:
len(w)=count(w)3/4∑u∈vocabcount(u)3/4len(w)=count(w)3/4∑u∈vocabcount(u)3/4
在采样前,我们将这段长度为1的线段划分成MM等份,这里M>>VM>>V,这样可以保证每个词对应的线段都会划分成对应的小块。而M份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从MM个位置中采样出negneg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。
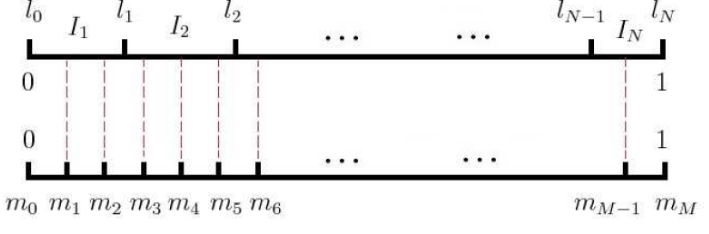
在word2vec中,MM取值默认为108108。
原理
Word2Vec作为神经概率语言模型的输入,其本身其实是神经概率模型的副产品,是为了通过神经网络学习某个语言模型而产生的中间结果。具体来说,某个语言模型指的是“CBOW”和“Skip-gram”。具体学习过程会用到两个降低复杂度的近似方法-Hierarchical Softmax或Negative Sampling。两个模型乘以两种方法,一共有四种实现。
Word2Vec得到以该词作为背景词和中心词的两组词向量。我们会使用连续词袋模型的背景词向量,使用跳字模型的中心词向量。
预备知识
sigmoid函数
逻辑回归
Bayes公式:语言模型P(Text),声学模型P(Voice|Text),语音识别P(Text|Voice)由前两个模型利用Bayes公式推导出来。
Huffman编码:Huffman树、Huffman树的构造、Huffman编码
语言模型
什么是统计语言模型呢?通俗地说,统计语言模型描述了一串文字序列成为句子的概率。
n-gram语言模型:模型参数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









