






一、Word2Vec(Skip-gram)
1.1 算法思想及步骤
1.2 数学原理
1.3 优化计算复杂度的技巧
a.负采样 b.分层softmax
1.4 jupyter项目实践
二、DeepWalk
2.1算法思想及步骤
2.2 数学表达
2.3 伪代码
2.4 jupyter项目实践
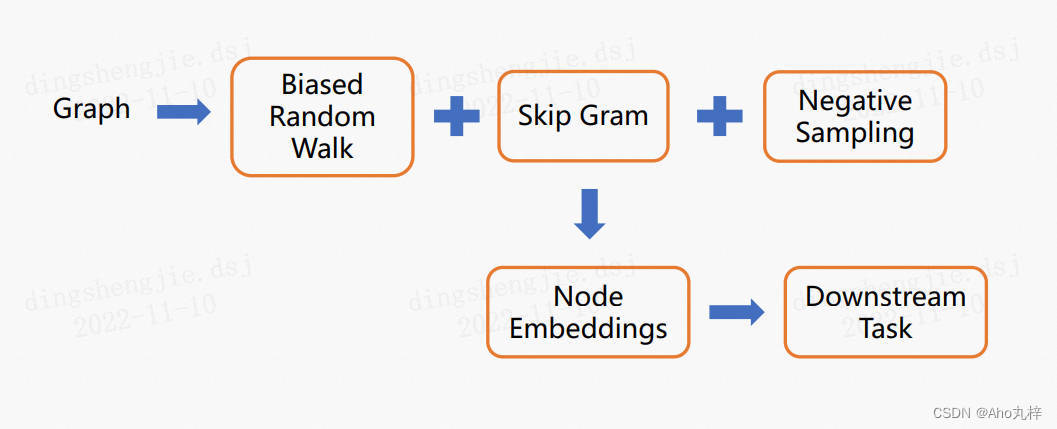
三、Node2Vec
3.1 算法思想及步骤
3.2 数学表达
3.3 伪代码
3.4 论文实验(4、EXPERIMENTS)
3.5 jupyter项目实践
一、Word2Vec(Skip-gram)
1.1 算法思想及步骤
Word2Vec—Skip-gram 算法是一种用于词嵌入(Word Embeddings)的方法,它的目标是将每个词表示为一个低维稠密的向量,以便在文本处理任务中更好地表示词汇语义。基本思想是根据中心词预测上下文词,通过不断调整权重矩阵W、W',来最小化损失函数。
如图,Skip-gram是一个具有3层结构的浅层神经网络: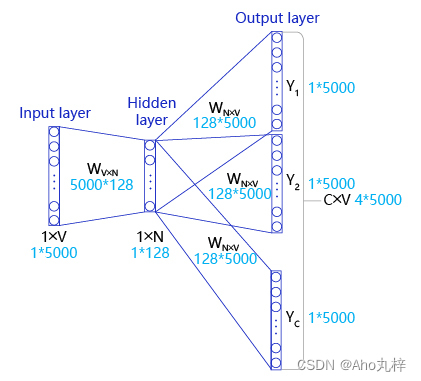
以下是 Skip-gram 算法训练的主要实现步骤:
(一)输入层数据准备
构建分词的文本数据;将每一个词都用一个V维one-hot向量表示。
(二)初始化embedding矩阵
初始化权重矩阵W,行数为词数,列数为我们设定的维数,元素随机,这个矩阵也是我们最终希望优化得到的embedding矩阵;
随机初始化权重矩阵W',用于输出上下文词概率预测,也称为context矩阵。
(三)投影层降维
输入中心词的one-hot向量,通过embedding矩阵W投影为该词N维embedding。
(四)输出结果、构建目标函数
通过context矩阵W'将中心词embedding还原为V维向量;
利用softmax函数归一化处理V维预测向量,其中向量每一个元素都对应某词是该中心词的窗口词的概率。其结果与真实窗口词情况对比。
遍历所有词,构建模型的损失函数。
(五)模型训练
使用梯度下降算法来调整权重矩阵W、W',以最小化损失函数。我们得到embedding矩阵W即为文本的词嵌入矩阵(embedding)。
矩阵参数的更新过程:word2vec的原理和难点介绍(skip-gram,负采样、层次softmax)-CSDN博客
1.2 数学原理
在开始讲word2vec数学原理前,让我们先来看一下机器学习做自然语言处理的统一模式,和一些机器学习里的基础概念:
机器学习领域有一种通用模式:对所考虑的问题建模后,先为其构造一个目标函数,然后对这个目标函数进行优化,从而求得一组最优的参数,最后利用这组最优参数对应的模型来进行预测。
问题建模—>构造目标函数—>优化—>最优参数—>预测
对于统计语言模型而言,最大似然将目标函数表示为:
![]() (1) ,
(1) ,
实际应用中为计算方便,常采用最大对数似然估计,把目标函数设为
![]() (2),
(2),
由(2)可以看出,概率函数![]() 可被视为关于w、Context(w) 的函数,
可被视为关于w、Context(w) 的函数,
![]() (3),
(3),
其中θ 是待定的参数集,优化目标函数即可获得最优参数集 θ' ,一旦 θ' 确定,那么函数F也唯一确定。
而在skip-gram模型中,有词表索引集![]() 。给定长度为T的文本序列,处于t处的词为w(t) 。背景窗口大小为 m 。假设窗口词是在给定任何中心词的情况下独立生成的。我们得到模型的似然估计下的目标函数:给定任何中心词的情况下生成所有窗口词的概率:
。给定长度为T的文本序列,处于t处的词为w(t) 。背景窗口大小为 m 。假设窗口词是在给定任何中心词的情况下独立生成的。我们得到模型的似然估计下的目标函数:给定任何中心词的情况下生成所有窗口词的概率:

在训练中,我们通过最大化对数似然函数来学习模型参数。这相当于最小化以下损失函数:

此时,我们需要引入词向量,于是对概率部分进行重写:我们给定中心词wc (词典中的索引为c),窗口词wo (词典中的索引为o)。同时每个词都有两个d维的向量表示,用于计算条件概率。用![]() 代表某词作为中心词的词向量,用
代表某词作为中心词的词向量,用![]() 代表某词作为窗口词的词向量。所有的vi拼接成了embedding矩阵W,所有的ui转置后拼接成了context矩阵W’。
代表某词作为窗口词的词向量。所有的vi拼接成了embedding矩阵W,所有的ui转置后拼接成了context矩阵W’。
于是,给定一中心词,生成某窗口词的条件概率可以通过对向量点积的softmax归一化操作来定义:
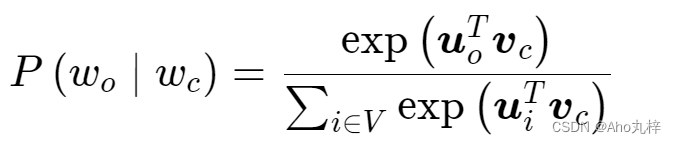

现在我们得到了可以用于训练迭代优化的目标函数和损失函数。利用梯度下降法,我们需要计算对数条件概率下损失函数的梯度。
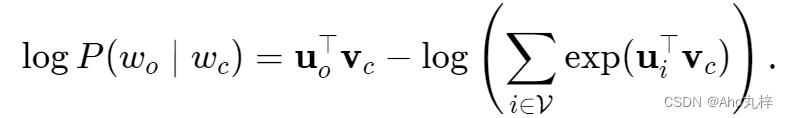
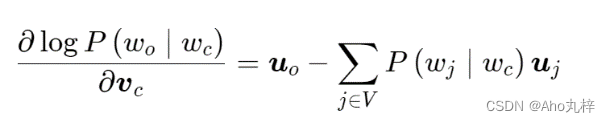
通过上面计算得到梯度,我们不断迭代模型参数vc 、uo 。最终,对于词典中任一索引为i的词,我们均得到该词作为中心词和背景词的两组词向量 vi、ui ,也就是优化得到了两个权重矩阵W 、W' 。
详细的数学推导01. Word2Vec的基础知识 - 知乎
1.3 优化计算复杂度的技巧
上面计算中存在一个给计算过程带来负担的部分:
我们可以指出两个影响因素:
1、负样本太多——少取负样本。2、softmax的计算方法复杂——改进方法
Word2Vec和Node2Vec中采用的是负采样方法,DeepWalk中采用的是分层softmax方法。这里只简述两种方法的思路:
a、负采样(negative sampling)
思路:首先,什么是负样本?—— 在softmax函数处理时减少模型选取的负样本数量,减少每次context矩阵W’更新的参数数量。通常设置负样本数量为5—20。注:在计算机实操中,并不是完全随机抽取负样本,一个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words,这也保证了训练的质量。
b、分层softmax(Hierarchical Softmax)
思路:将词汇表分成一个霍夫曼树状结构,利用sigmod函数,通过一系列的二元分类来预测目标词, 降低计算复杂度。(将复杂的归一化概率分解为一系列条件概率乘积的形式)。本质上:并没有把所有样本的似然乘起来得到真正的训练集最大似然,而是每次只用一个样本更新梯度,从而减少梯度计算量。(这部分暂时理解的不太好)

两种优化方法的数学推导:word2vec原理详解 - 知乎
霍夫曼树的形象理解:word2vec的原理和难点介绍(skip-gram,负采样、层次softmax)-CSDN博客
1.4 jupyter项目实践
项目展示:word2vec西游记.html
B站讲解(三国演义):词向量 | word2vec | 理论讲解+代码 | 文本分析【python-gensim】_哔哩哔哩_bilibili
二、DeepWalk
2.1 算法思想及步骤
DeepWalk算法是一种用于图嵌入(Graph embeeding)的方法。它的目标是将图数据中的节点表示为低维稠密的向量,以便在这些向量中保留节点的结构、语义信息。它也是第一个将 NLP 领域的思想运用到图嵌入领域的模型。首先采用随机游走思想将多个节点转化为类似于自然语言句子的序列,然后利用Skip-gram模型进行训练。
为什么采用随机游走?我们可以观察到,Word2Vec处理的是语句数据,词语之间只有线性的、前后之间的联系,方便将词语分组为短句。但是在图数据结构中,边结构使图中的节点构成了比词语之间更加复杂的关系。通过游走策略,我们可以将一个复杂的图数据转换为多个前后关联的链路数据。
文章Paragraph—>图graph 单词word—>节点node
窗口大小window—>随机游走序列长度length 句子sentence—>随机游走序列walk

具体步骤:
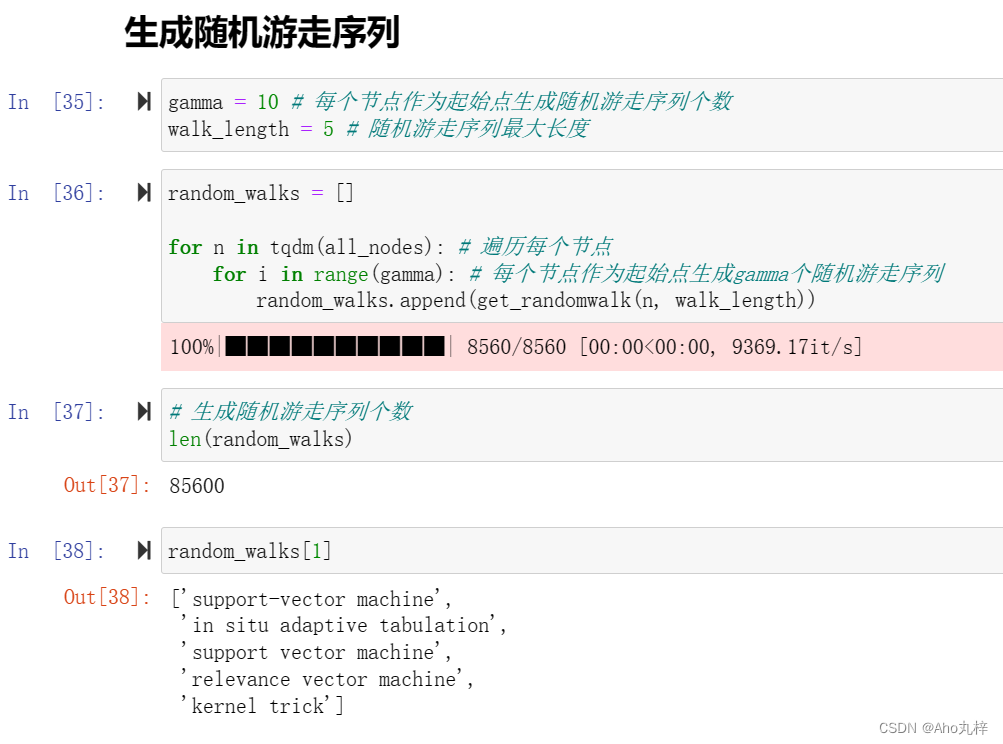
(一)构建随机游走序列(Random Walks):
- 选择一个起始节点。
- 随机选择一个相邻节点作为下一个节点,不断重复此过程,直到达到预定的序列长度。
- 遍历全图节点,以在整个图中生成多个游走序列。
- 打乱全图节点顺序,重复上述步骤,每个节点为起始节点时具有多个随机游走序列。
(二)将游走序列转化为Skip-gram样本:
- 将每个游走序列看作一个句子,其中节点是词汇。
- 使用Skip-gram模型,将游走序列中的节点作为中心节点及其窗口节点进行建模。
- 训练Skip-gram模型,优化节点的embedding矩阵。
(三)生成节点嵌入:
- 训练完Skip-gram模型后,使用模型中学到的参数,将节点映射到低维嵌入向量空间。这些嵌入向量捕获了节点之间的语义和结构关系,可用于各种图分析任务,如节点分类、相似性计算等。
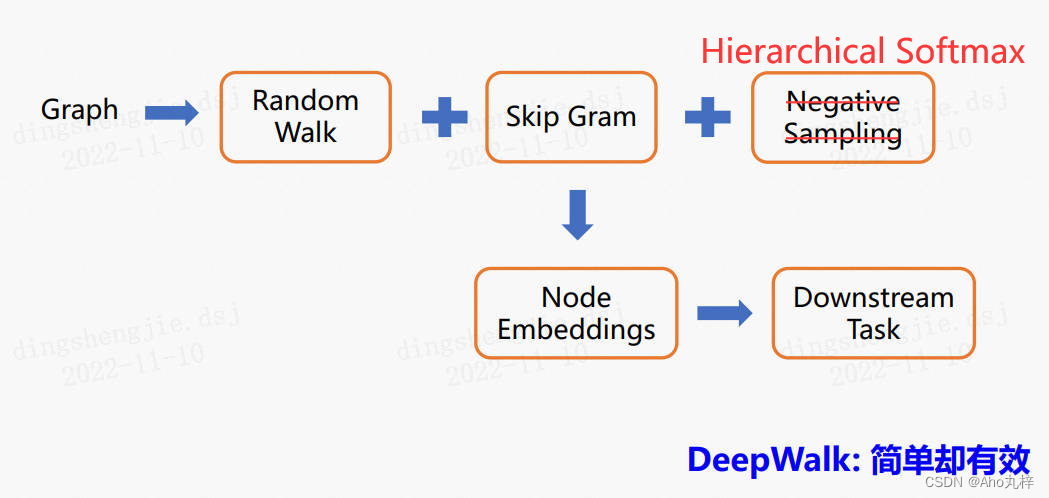
2.2 数学表达
首先还是来看传统自然语言处理中,![]() 是一个由若干单词组成的短句序列,其中
是一个由若干单词组成的短句序列,其中![]() ,V 是词汇表,也就是所有单词的集合。这时在整个模型中我们需要优化的目标是:
,V 是词汇表,也就是所有单词的集合。这时在整个模型中我们需要优化的目标是:
![]()
现在我们让单词wi —>节点vi ,句子—>随机游走序列,得到优化目标
![]()
引入一个映射函数,将顶点映射为d维向量:
![]()
优化目标表示为:
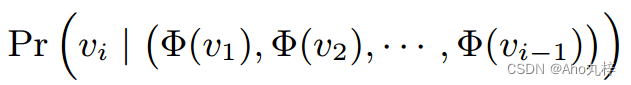
引入Skip-gram方法思想:
(1)不再使用上下文来预测一个缺失词,而是使用缺失词来预测上下文。
(2)上下文由目标词的左右两侧组成,不仅仅是一边。引入窗口w参数。
新的优化目标如下:
![]()
似然估计下的损失函数为:
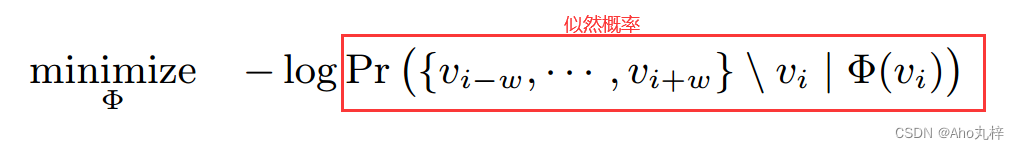
我们将节点的向量表示引入函数,概率部分改写为:
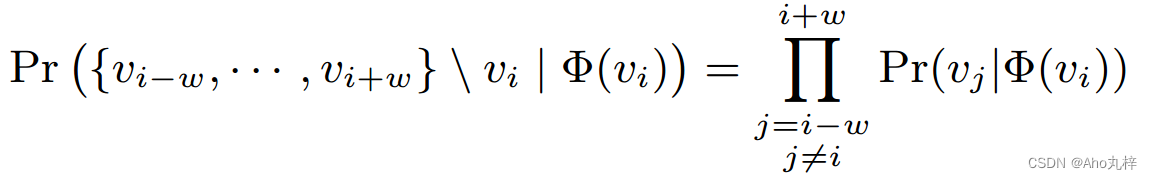
2.3 伪代码


2.3 jupyter项目实践
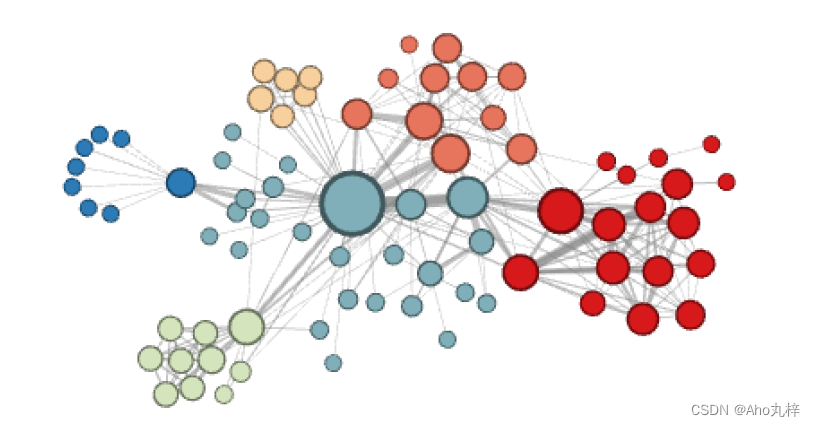
Jupyter项目-基于Deepwalk的维基百科词条图嵌入可视化
B站讲解:
DeepWalk代码实战-维基百科词条图嵌入可视化_哔哩哔哩_bilibili
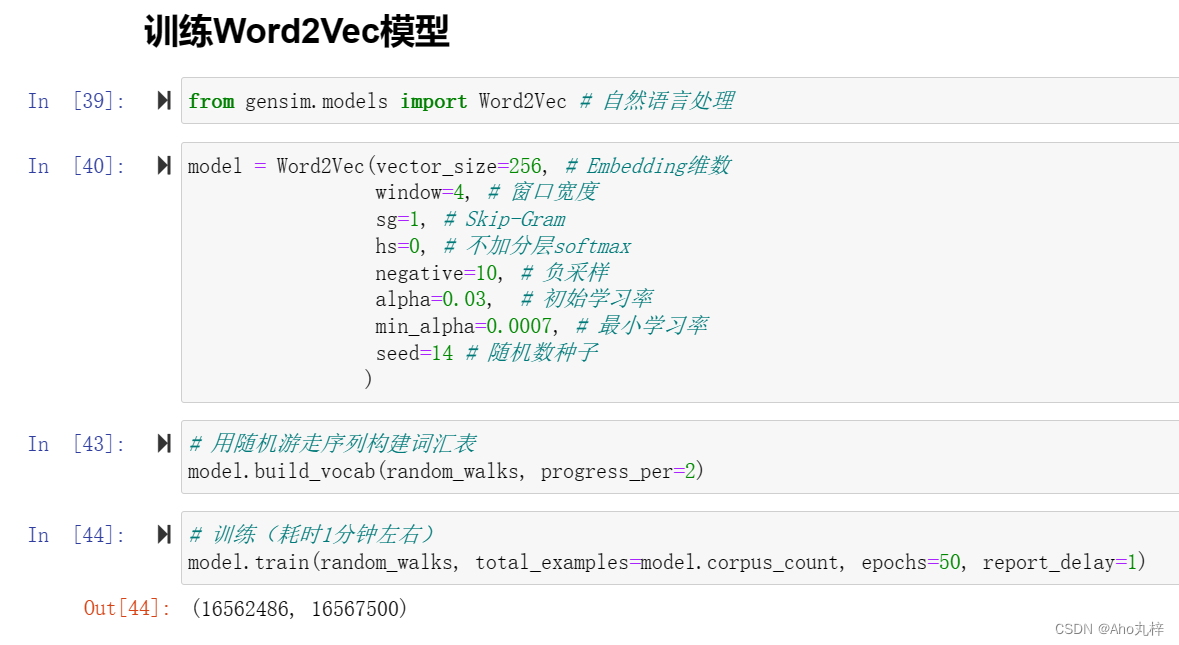
项目核心代码:
三、Node2Vec
3.1 算法思想及步骤
核心思想:Node2vec应用二阶随机游走,在Deepwalk随机游走环节引入了两个可调参数p、q,以定制游走序列采样策略。
策略讲解:
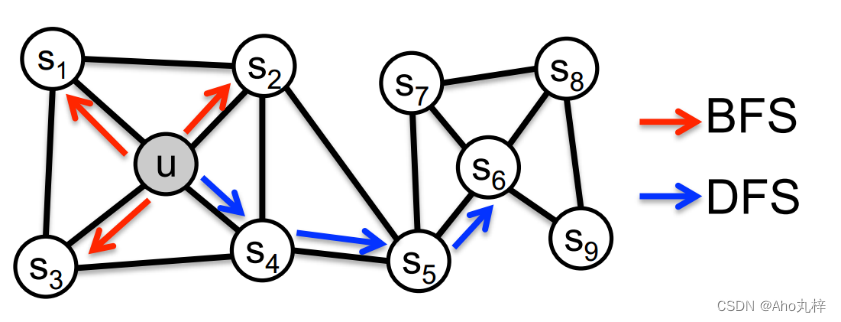
广度优先采样Breadth-first Sampling(BFS):
邻域采样限制在与中心节点直接相连的节点。策略倾向于捕捉节点功能、角色(structural equivalence)。
深度优先采样Depth-first Sampling(DFS):
邻域由距离源节点越来越远的节点依次采样组成。策略倾向于捕捉同质社群、社交网络(homophily)。
在实际生活中,网络节点的预测任务通常在如下两种相似度上进行交替:同质性和结构等价 。在假设满足同质性时,相互连接并且属于相同网络社区的节点的表示向量应当相似;在假设满足结构等价时,拥有相同网络结构的节点的表示向量也应当相似。
我们可以观察到BFS和DFS策略能对捕捉以上两种相似性起到重要的作用,由BFS策略进行采样获得的邻居通常都具有结构上的相似性,而DFS正好相反,由DFS策略进行采样获得的邻居能更好的满足网络的同质性。
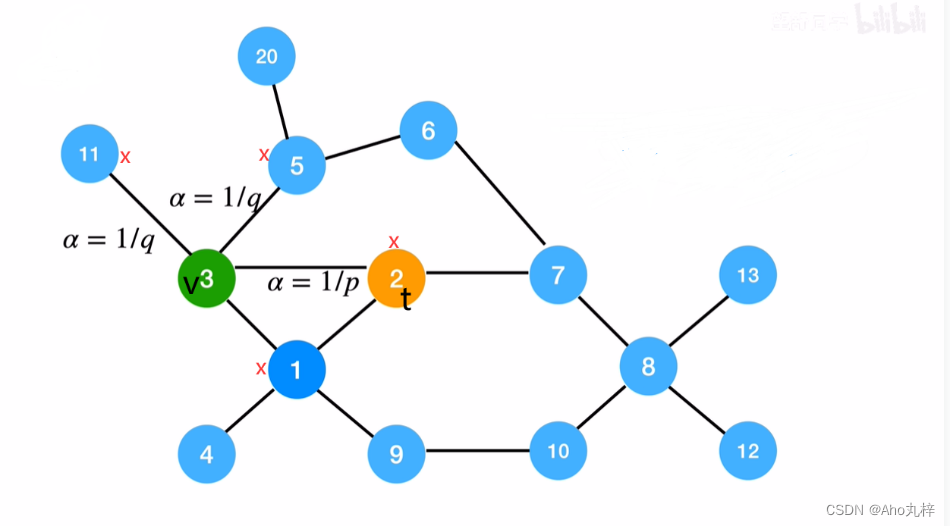
作者根据BFS和DFS的思想设计了一种灵活的带有偏重的随机游走策略,使BFS和DFS能够平滑地融入此策略中。给定一个源节点u,要进行步长为l的随机游走,ci表示游走序列中第i个节点,且c0=u, Z为归一化常量,节点v到x的转移概率:

假设现在经过随机游走,节点采样从t经过边(t,v)到来v,于是当前节点为v,游走策略需要确定下一个节点走哪里,


其中![]() 指节点t和节点x的最短路径距离,且
指节点t和节点x的最短路径距离,且![]() 的范围是{0,1,2}
的范围是{0,1,2}
Return parameter p:参数p是控制下一个节点是否选择上一节点的概率,所以参数p若设置较大值,则我们在采样序列过程中会以较小概率的采样一个已经访问过的节点,除非下一个节点没有其他邻域节点了。
In-out parameter q
参数q控制下一个节点是靠近上一节点还是远离上一节点。如果q>1,那么随机游走偏向于靠近上一节点t,q<1则相反。
而Deepwalk中的一阶随机游走采样方法可看作是当q=1、p=1的特殊情况。
下面是一个直观转移过程,若设置q=2,p=4:

3.2 数学表达
Node2vec中定义了NSu∈V![]() 为节点u在邻居取样策略S下的网络邻居列表。
为节点u在邻居取样策略S下的网络邻居列表。
我们希望最大化预测到共线节点对的概率,故需要优化的目标函数为:

为了方便后续目标函数的处理,我们引入两条假设:
- 条件独立:假设我们所取样得到的邻居中每个节点之间都是相互独立的,这样就可以将目标函数中的概率部分分解为:
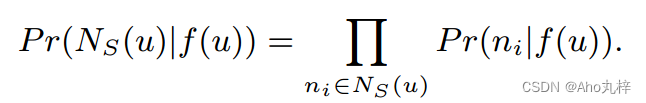
- 特征空间中的对称性:假设节点t是节点u的邻居,那么u同样也是t的邻居,将这种关系映射到特征空间中那就是,节点u对节点t的影响和节点t对节点u的影响是相同的。基于这种关系,可以利用softmax函数将概率部分进一步定义为:
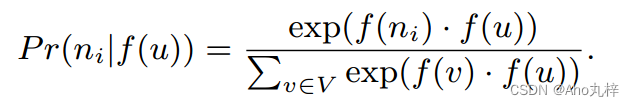
基于以上两点假设,最终我们将目标函数表示为:
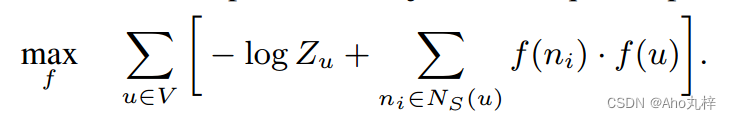
其中,![]() ,也称为partition function配分函数(归一分母)。同理Word2Vec和Deepwalk,Zu 的计算复杂度很高,本文也采用了负采样方法进行优化
,也称为partition function配分函数(归一分母)。同理Word2Vec和Deepwalk,Zu 的计算复杂度很高,本文也采用了负采样方法进行优化
3.3 伪代码

3.4 论文-模型性能实验
Node2Vec:Scalable Feature Learning for Networks
3.5 jupyter项目实践
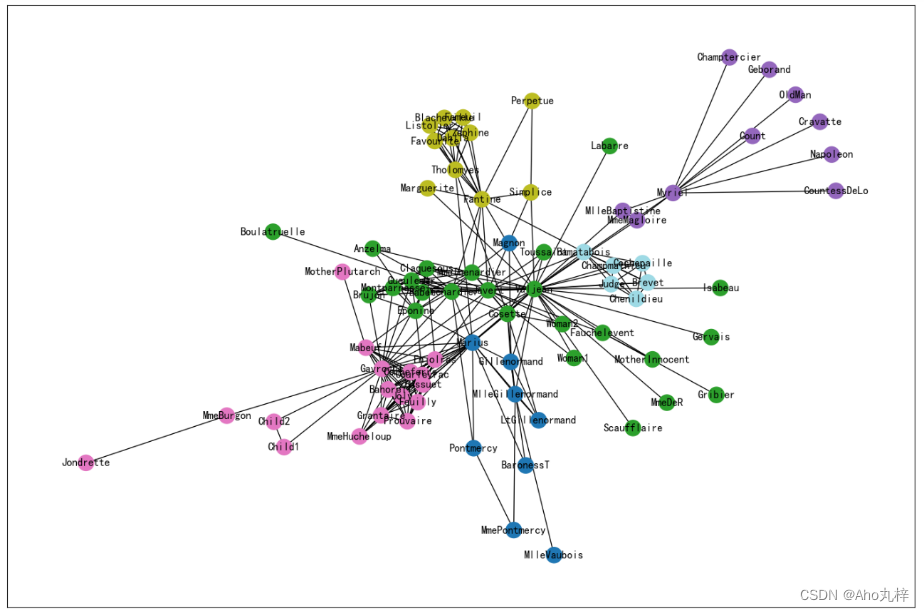
Jupyter项目-基于Node2Vec的《悲惨世界》小说人物图嵌入
项目展示:Node2Vec_悲惨世界.html
B站讲解:Node2Vec代码实战-《悲惨世界》小说人物图嵌入、Alias Sampling复现_哔哩哔哩_bilibili
项目核心代码:
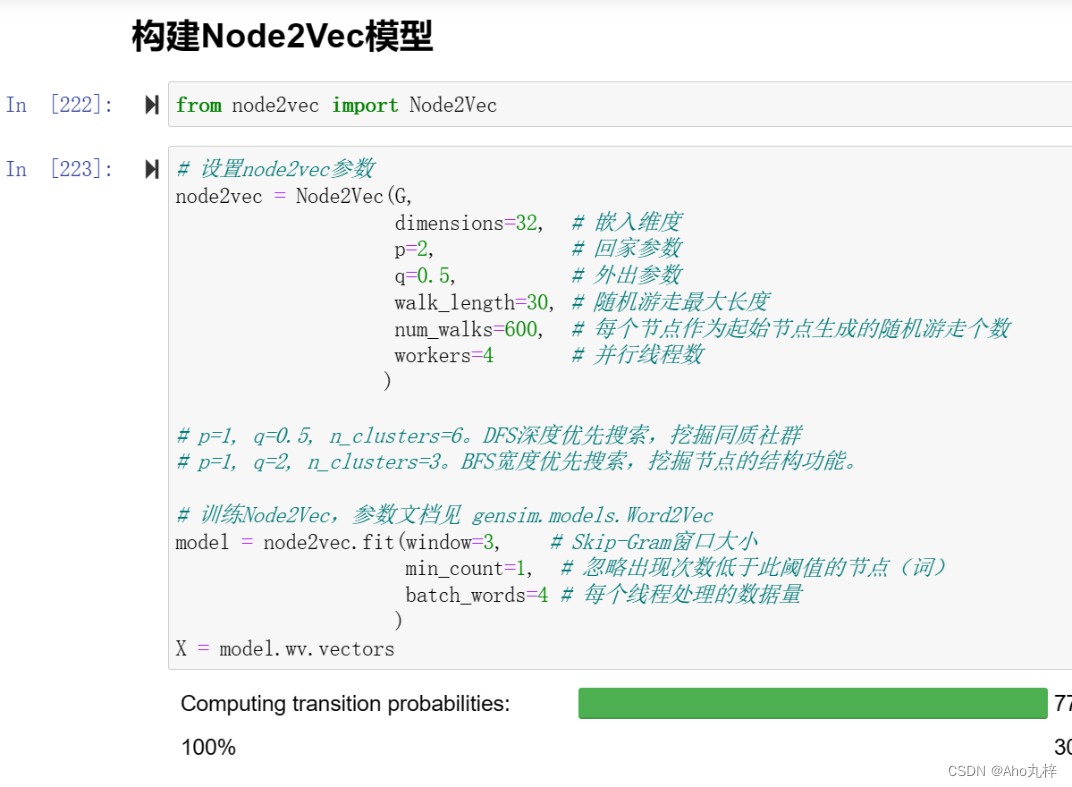

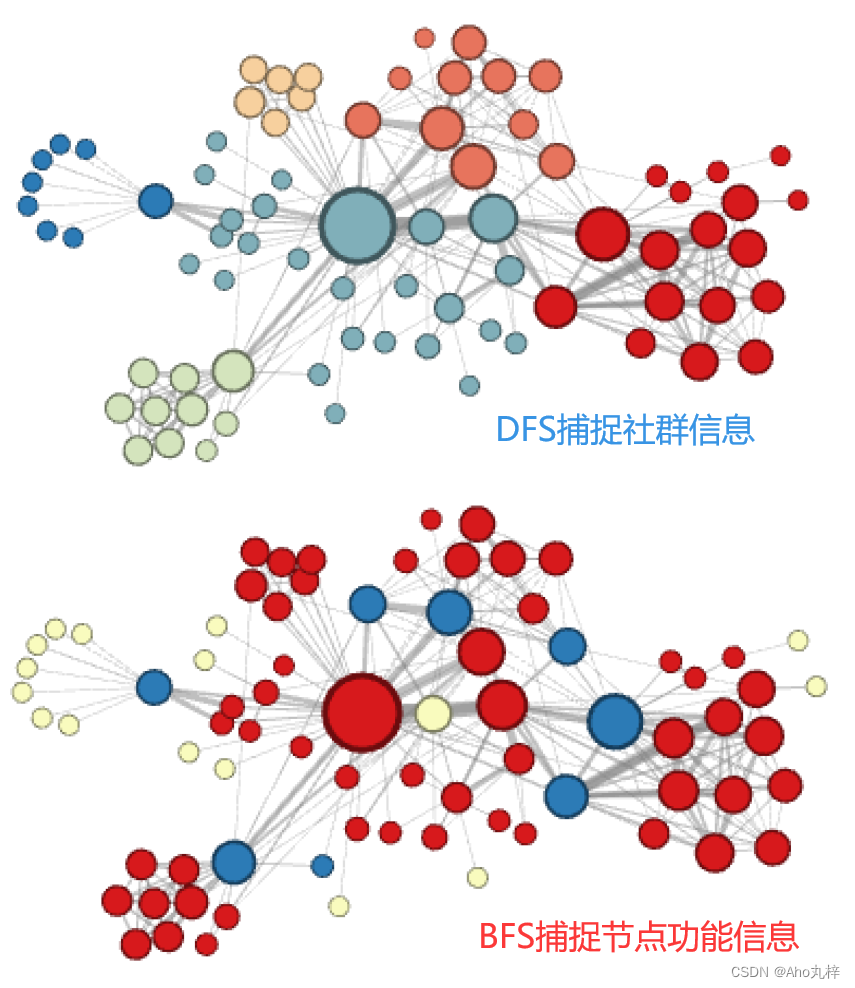
DFS策略提取社群信息-实现效果
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









