






|
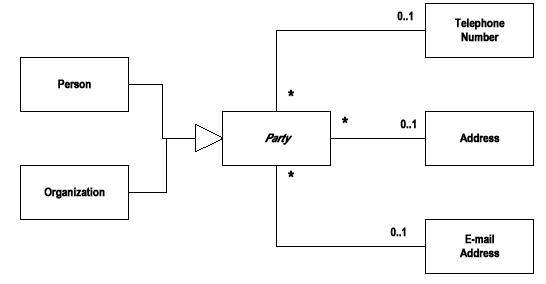
1 责任模式这一章关注的重点是关系,以及怎样为错综复杂的关系建立模型,另外,所有的插图都来自原书(《Analysis Patterns:Reusable Object Models》),并遵循UML标准。 1.1 Party模式在这一章中,首先我们接触到是是Party模式,在进行系统分析和概念模型设计的时候,经常发现人和各种各样的组织有着同样的行为,例如,固定电话的计费可能是针对个人,也可能是一个单位;需要各种服务的时候,你可能求助于一个服务公司,或者服务公司一个特定的业务员。总之,因为人(Person)和组织(Organization)表现上的一致性,如下图所见,我们从中抽象出Party,作为Person 和Organization的抽象父类。
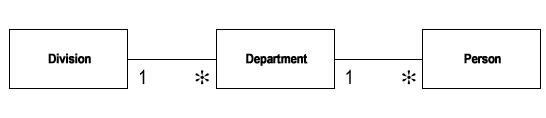
1.2 组织(Organization)的内部结构第二步,如果我们把注意力转移到组织(Organization)的内部结构,就会发现一些有趣的问题,通常最常见的一种结构是金字塔结构,因此建模时可能按照这样的结构建立线性的模型,例如:
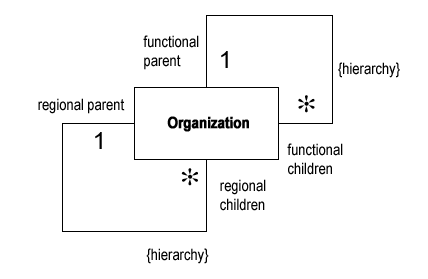
这样的模型并没有错误,但是有缺陷,首先不能满足比较复杂的组织关系,更严重的是,一旦需要更多的层次关系,例如存在部门直接上下级关系以及区域附属管理方式,必将引起整个模型的更改,对系统的影响可想而知,在这种情况下,最通常的改进措施是引入层次关系,如下图所示:
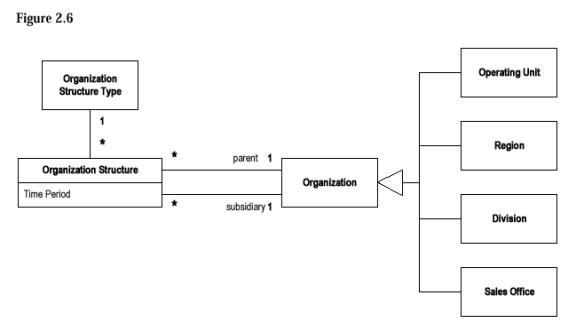
通过增加新的关联关系,可以灵活实现组织(Organization)之间的各种关系以及可能的变化。在上图中,{hierarchy}是一个约束(constraint)来限定关系。 1.3 组织关系抽象第三步,在一般的情况下,以上的模式已经足够解决问题,但当这样的层次和组织关系很多而且复杂时(超过两种),例如现在流行的矩阵管理,就可以将关系本身抽取出来独立处理,如下图所示,作者此时考虑到组织结构的有效时段,所以加入了一个时间段属性来记录组织结构的存在时间。
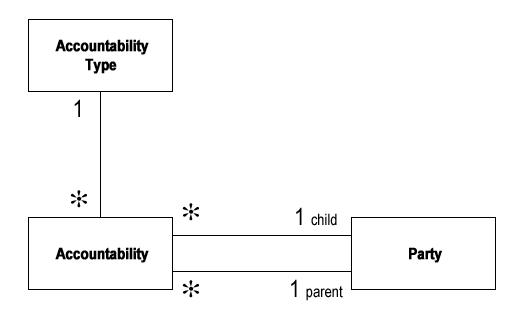
请注意,在这个模式中,Organization Structure才是模式的核心,在系统中,由两个Organization的实例(分别充当parent和subsidiary),以及一个Type实例来说明该结构的类型。在这样的结构中,可能存在许多的规则(Rule),这些规则可以根据情况分别处理:如果Type很多,而且规则主要跟Type有关,就分配给与Type相关联;如果Type并不多,但主要根据Organization的子类型变化,就可以分布到Organization的子类型中。 1.4 责任(Accountability)模式第四步,从第一步看到,Party是Person和Organization的抽象父类,因此把Party代入上面的模式(有点象我们小时侯代数里常用的代入),正式形成责任(Accountability)模式。
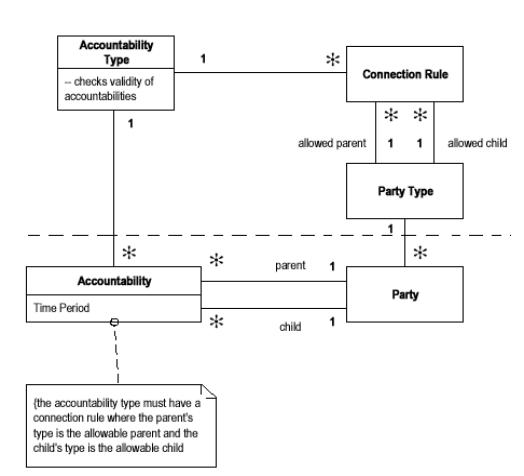
1.5 知识层(Knowledge level)和操作层(Operational level)分离出现这样一种想法是考虑到以下情况:当Accountablity Type的数量比Accountability的数量多很多的时候,处理Accountablity Type的规则也变得更为复杂,要解决这样的问题,就可以引入知识层和操作层的分离。 由下图可见,用虚线隔离开的,就是知识层(Knowledge level)和操作层(Operational level),在这个模型中,知识层(Knowledge level)由三个类协作完成,它们分别是Accountablity Type、Connection Rule、Party Type,在Connection Rule中定义合法的Party关系规则,并通过Accountablity Type对Accountablity进行创建时的合法性检验。它的另一个好处就是,可以将知识层的实例化独立出来,作为操作层(Operational level)运行时的配置;换句话说,当知识层的规则改变时,系统的行为将被改变,而不需要任何其他代码的改动,这当然是一种比较理想化的情况。
由此想到,构建专家系统的设计思路也可以从这个模式得到一些启发,这是笔者一时的感触。 在原书中,如何实现这样的模型提得比较模糊,但是笔者认为,可以将它们作为正常的模型来实现,两个层次的区分只是表明它们各自担负的任务和地位不同。知识层倾向于描述系统可能存在的各种形式,并设定判断系统是否有效的各种规则;操作层则描述在这样的配置下系统实际的行为。通过改变内在的配置来改变外在的行为,就是这个模式的目的。 由于这个模式的特点,改变系统行为时不必更改操作层的代码,但是,并不意味着改变系统行为连测试也不必要做。同样,也需要调试、配置管理。 作者也提到,这样的模式用起来并不轻松,甚至在一般的系统中也不必要,但当你发现有必要用它的时候,别犹豫(感觉象用降落伞一样)!
知识级:知识级定义了操作级实例的具体配置,模型记录控制着结构的各种通用规则,同时约束PARTY之间的的责任。 操作级:模型记录具体的团体,团体间的责任,以及责任的有效期间。 知识级与操作级的划分有效地分离了抽象与具体的,明确地指明了依赖关系。
2.示例
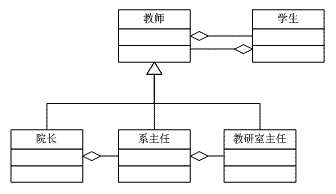
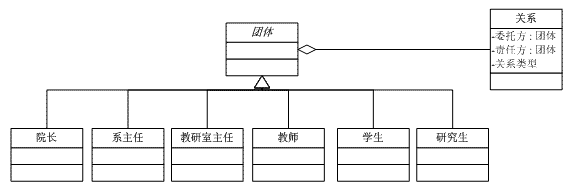
当你遇到纷繁复杂的关系不知如何处理时,可以考虑给这些关系"贴标签"。 让我们以一个例子来说明贴标签的作用: 现在的高校教师有很多是"双肩挑",一方面担任行政职务,另外一方面又在学校任课。作为行政领导的教师会有一些"下属",这些下属也是教师。例如院长下面有系主任、系主任下面又有教研室主任。其实,院长、系主任、教研室主任都是教师,都担任课程。一个教师教多个学生,一个学生被多个教师教。为了描述他们之间的这种层次关系,我们可以通过以下UML图来描述:
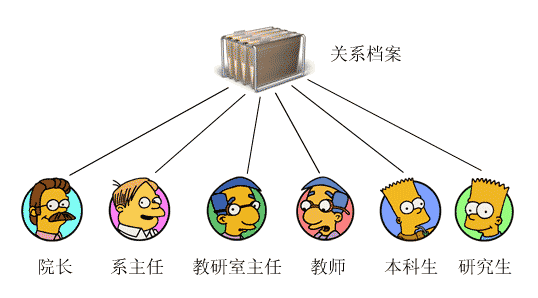
现在让我们再引入更复杂的关系逻辑:除了普通本科学生外,还有研究生。而只有教授才可以带研究生,不管该教授是否是院长、系主任还是教师。我们如何通过模型描述这种关系呢?如果某些学校内部的科研组织,其成员要跨学院,一个教师又分属于不同的科研组织,如果……。可以看出来,随着关系复杂程度的递增,我们建模越来越困难。这个时候我们就可以请出"贴标签"的法宝了。 当关系越来越多,越来越错综复杂时,依靠委派关系进行聚合就显得力不从心,这个时候我们干脆将所有委派都去掉,将"关系"集中进行存放。如下图:
在关系档案中存储的就是关系"标签",每个标签上都记录了如下属性:委托方、责任方、之间的关系。有了这个关系档案后,我们就可以避免在教师、学生、系主任等角色间使用委派标识了。如果用UML图来表示这种改变的话就是:
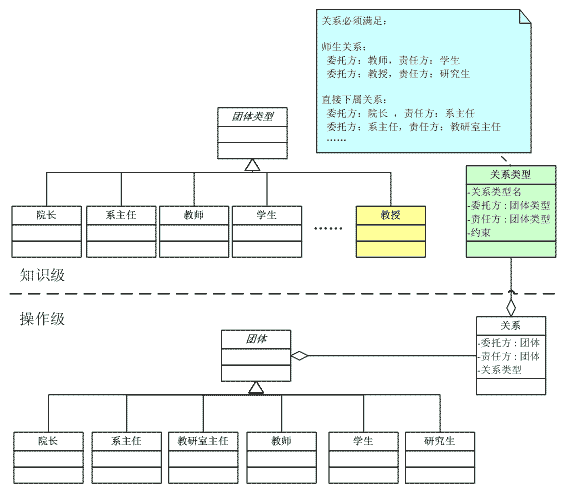
团体是一个抽象类型,其子类包含各种类型的人员,团体持有对关系的一个委派,而关系中记录了委托方、责任方以及关系类型。 如果你想查某个教师的关系网的话,就可以到关系表中查找该教师作为委托方或责任方所对应的关系及其类型。或者你想查看所有师生关系,就可以直接到关系表中查找。通过将两个不同成员间贴上"关系标签",避免了引用造成关系难于扩充,难于处理的问题。 然而当前设计仍然存在一些问题,就是没有严格的"约束"。在当前设计中,由于委托方与责任方的类型都是团体,所以对于委托方与责任方都是学生时,我们也可以给它赋上一个"师生关系",毕竟该模型对委托方与责任方的类型没有任何约束力。为了使得模型更加完善,我们必须给"标签"加上约束,不是什么人都可以乱贴标签的。于是我们重新设计模型如下:
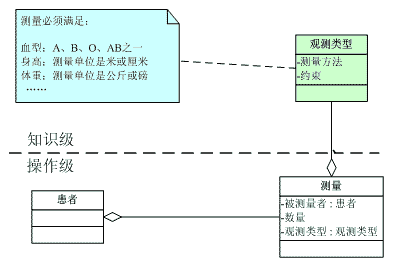
模型被分成了操作级和知识级,在知识级中记录了(1)都有什么样的标签;(2)标签的约束条件是什么,什么团体间才能具有该关系。 另外大家需要注意的是团体类型和团体并不是一一对应的,例如团体类型"教授",它有可能是院长、系主任也可能是教师。知识级的信息对操作级进行约束、控制。当出现新的科研关系时,我们仅仅需要做的工作是(1)添加一个新的关系类型:科研关系,(2)为该关系添加约束条件:其委托方与责任方是除了学生、研究生外的其它团体(尽管研究生也搞科研,我们这里暂不讨论)。 通过贴标签,我们就避免了增加委派关系带来的麻烦。当然,如果你的模型比较简单,只研究师生关系的话,就大可不必这么麻烦。 再来看看《分析模式(中文版)》第3章39页(英文版第41页)的一个例子,该例子用来记录病人到医院看病,记录检查的观测结果。看病的测量太多了,肺活量、血压、心率,单位可能相同也可能不相同。我们无法通过委派关系让一个病人持有所有检查的引用。况且当你看到一个检查结果是"A"时,也无法知道究竟是血型是A,还是评估等级为A级。因此我们将患者和测量结果间贴上标签,标签上记录如下信息:(1)患者姓名(2)测量内容(3)数量。当患者检测完后,手中只要持有一组标签就行了,而不用去管什么单位不单位的。究竟数量是否正确那是知识级所需要做的事情了。如下图:
这样,患者和数量间就被贴上了测量的标签,而该标签的使用必须满足观测类型中所规定的约束条件。 |


参考文档:
https://www.cnblogs.com/zhenyulu/articles/210312.html
http://www.uml.org.cn/sjms/2004092401.htm
原文参照《Analysis Patterns:Reusable Object Models》,Chapter 2,Martin Fowler
《分析模式——可复用的对象模型》(Martin Fowler著)[机械工业出版社]















 2117
2117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









