







概念
机器学习(Machine Learning)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能核心,是使计算机具有智能的根本途径。
什么是机器学习?字面上来讲就是 (人用) 计算机来学习。谈起机器学习就一定要提起汤姆米切尔 (Tom M.Mitchell),就像谈起音乐就会提起贝多芬,谈起篮球就会提起迈克尔乔丹,谈起电影就会提起莱昂纳多迪卡普里奥。米切尔对机器学习定义的原话是:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.
首先注意到两个词 computer program 和 learn,翻译成中文就是机器 (计算机程序) 和学习,再把上面英译中:
假设用性能度量 P 来评估机器在某类任务 T 的性能,若该机器通利用经验 E 在任务 T 中改善其性能 P,那么可以说机器对经验 E 进行了学习。
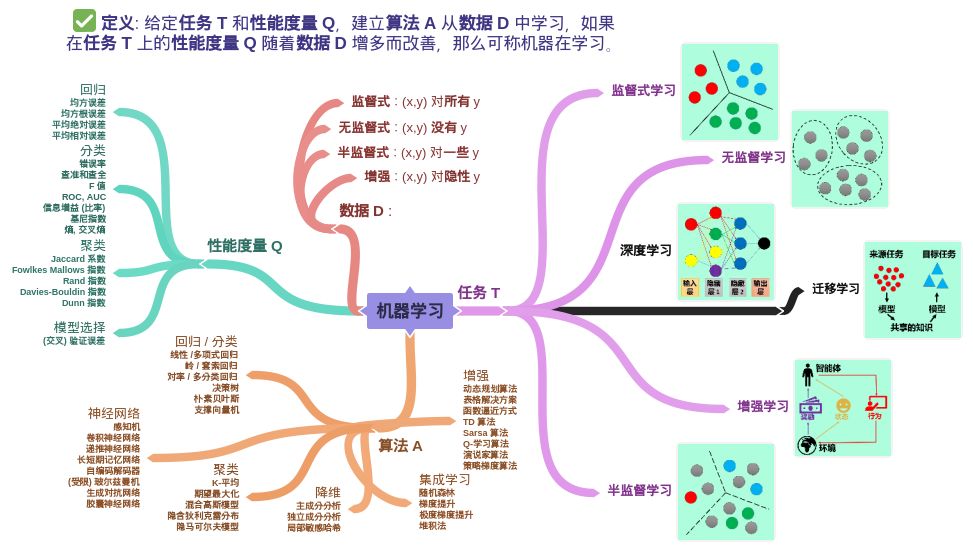
在该定义中,除了核心词机器和学习,还有关键词经验 E,性能度量 P 和任务 T。在计算机系统中,通常经验 E 是以数据 D 的形式存在,而机器学习就是给定不同的任务 T 从数据中产生模型 M,模型 M 的好坏就用性能度量 P 来评估。
由上述机器学习的定义可知机器学习包含四个元素:
-
数据 (Data)
-
任务 (Task)
-
性能度量 (Quality Metric)
-
模型 (Model)
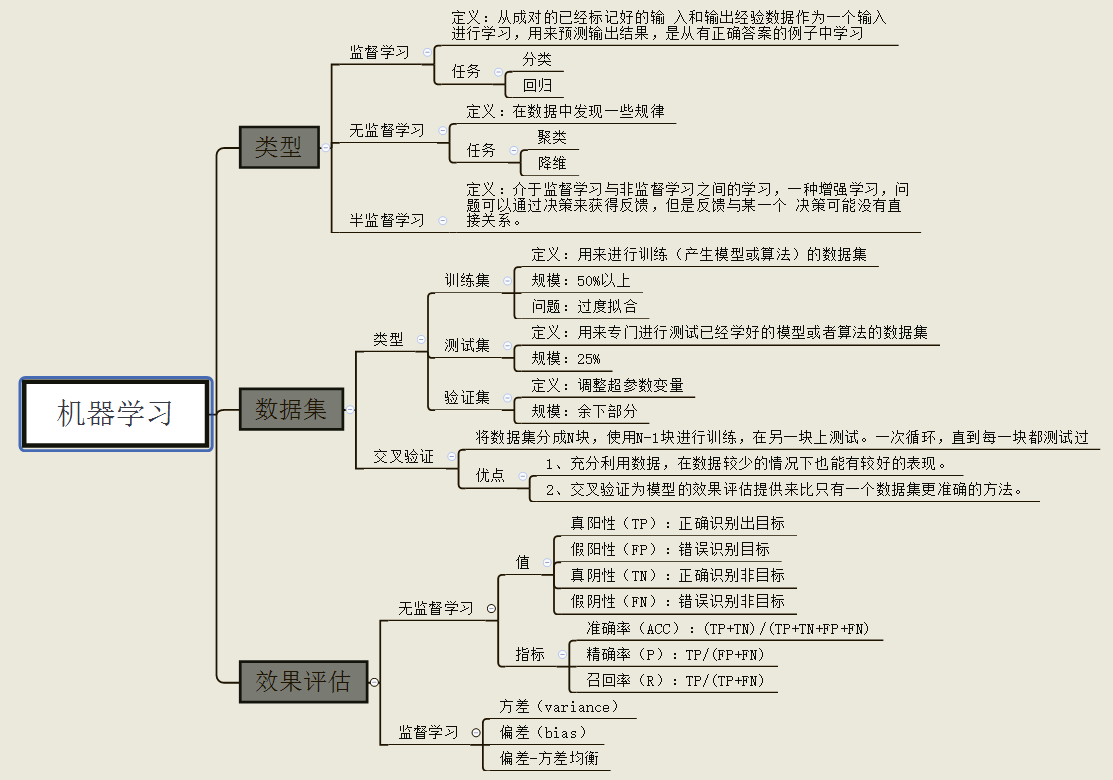
分类
根据学习方式的不同可以分为以下三类:

机器学习问题的一般流程步骤
-
定义问题:我们想教计算机做什么任务?
-
选择特征并收集训练样本数据:什么样的特征最能描述数据,为训练集和测试集收集数据。数据越大、越多样越好。
-
选择度量性能的指标:
-
训练模型并优化算法:用数值优化技术在训练集上调整恰当模型的参数。
-
测试模型,评估模型性能:评估训练模型在测试数据上的性能。如果评估结果不佳,则重新考虑所使用的特征,并尽可能收集更多的数据。
-
调整算法:

如果数据集包含大量不相关的特征或噪声, 即数据集具有较低的信噪比, 那么降维也可以提高模型预测的性能。为了确定机器学习算法不仅能在训练集上表现良好, 对新数据也有很好的适应性, 我们希望将数据集随机分成单独的训练集和测试集。 用训练集来训练和优化机器学习模型, 同时把测试集保留到最后用以评估最终的模型。
机器学习编程主要用scikit-learn
sklearn中常用的模块有分类、回归、聚类、降维、模型选择、预处理。
分类:识别某个对象属于哪个类别,常用的算法有:SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林),常见的应用有:垃圾邮件识别、图像识别。
回归:预测与对象相关联的连续值属性,常见的算法有:SVR(支持向量机)、 ridge regression(岭回归)、Lasso,常见的应用有:药物反应,预测股价。
分类(Classification)与回归(Regression)都属于监督学习,他们的区别在于:
分类:用于预测有限的离散值,如是否得了癌症(0,1),或手写数字的判断,是0,1,2,3,4,5,6,7,8还是9等。分类中,预测的可能的结果是有限的,且提前给定的。
回归:用于预测实数值,如给定了房子的面积,地段,和房间数,预测房子的价格。
聚类:将相似对象自动分组,常用的算法有:k-Means、 spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
降维:减少要考虑的随机变量的数量,常见的算法有:PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。















 5956
5956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









