







欢迎访问博主的blog:coding lemon’s blog
1. 缓存行的介绍
缓存行:为了增加cpu的访存速度,通常会在cpu和内存之间增加多级缓存,如下图,L1、L2都是核心独享的缓存,L3为单个插槽上所有cpu共享的缓存,MainMemory为所有cpu共享。
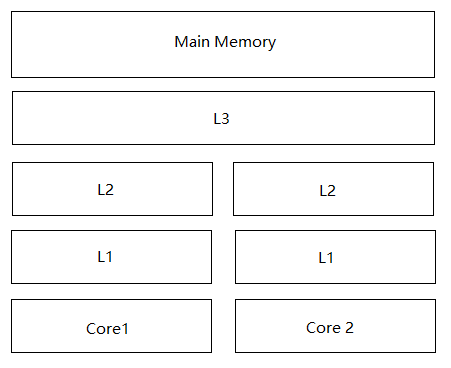
缓存越靠近CPU,其速度就越快,同样的其价格就越贵,容量就越小。
根据局部性原理,cpu每次访问主存时都会读取至少一个缓存行的数据 (通常一个缓存行为64字节,哪怕读取4字节数据,也会连续读取该数据之后的60字节)。这样做是为了加快数据访问速度。
例如:我们在编写代码时,经常会有遍历数组的操作,那么如果我们每一次取数组中的数据都去Main Memory中取的话,其效率会非常低,用时很长。那么如果在遍历第一次发生时就将该元素相邻的64字节的元素都取出来放入L级缓存中,执行效率将大大提升。
2.引入代码
基于以上情况,就诞生了下面这个很有意思的代码:
public class CatchLinePadding {
public static long COUNT = 10_0000_0000L;
private static class T{
public long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args)throws Exception{
CountDownLatch latch = new CountDownLatch(2);
Thread t1 = new Thread(()->{
for(long i=0;i<COUNT;i++){
arr[0].x = i;
}
latch.countDown();
});
Thread t2 = new Thread(()->{
for(long i=0;i<COUNT;i++){
arr[1].x = i;
}
latch.countDown();
});
final long start = System.nanoTime();
t1.start();
t2.start();
latch.await();
System.out.println((System.nanoTime() -start)/100_0000);
}
}
这段程序启用了2个线程,分别是t1和t2去修改arr[0]和arr[1]中的x的值。且修改10亿次,同时使用CountDownLatch类保证两个线程并行执行。此时这段代码运行完成后,执行时间输出为
843
即运行时间为843ms。
此时如果在代码中加入这两段看似无意义的代码,再次运行:
public class CatchLinePadding {
public static long COUNT = 10_0000_0000L;
private static class T{
//新增7个long类型p1-p7
private long p1,p2,p3,p4,p5,p6,p7;
public long x = 0L;
//新增7个long类型p8-p14
private long p8,p9,p10,p11,p12,p13,p14;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args)throws Exception{
CountDownLatch latch = new CountDownLatch(2);
Thread t1 = new Thread(()->{
for(long i=0;i<COUNT;i++){
arr[0].x = i;
}
latch.countDown();
});
Thread t2 = new Thread(()->{
for(long i=0;i<COUNT;i++){
arr[1].x = i;
}
latch.countDown();
});
final long start = System.nanoTime();
t1.start();
t2.start();
latch.await();
System.out.println((System.nanoTime() -start)/100_0000);
}
}
此时发现,输出结果居然神奇的变为了
201
即201ms。为什么?那么这段代码有什么特殊含义吗?
3.原理解析
之前提到了,缓存行是每次访问主存时都会连续访问64个字节的内容,那么第一段代码在执行期间发生了什么样的事情呢?我画了一个图方便理解:
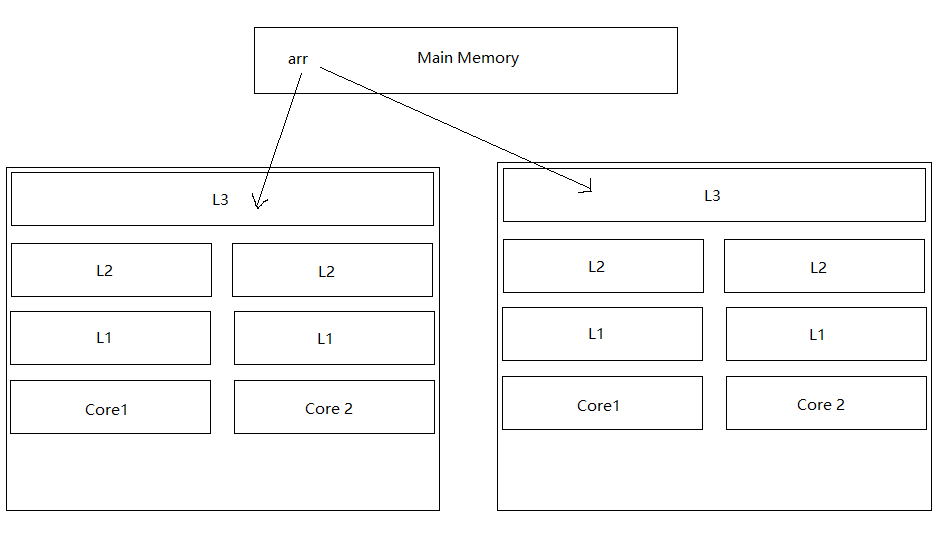
此时两个线程在不同的cpu核心上运行时,由于缓存行的存在,会先copy一部分arr中的数据到L级缓存中,此时两个CPU核心上都保存有arr[0]和arr[1]的数据。
那么t1在修改arr[0].x时,。为了保证arr数据的一致性,一定会有机制来通知不同的CPU核心之间进行数据同步,同时因为有了这样的机制存在,也会多消耗CPU的资源。
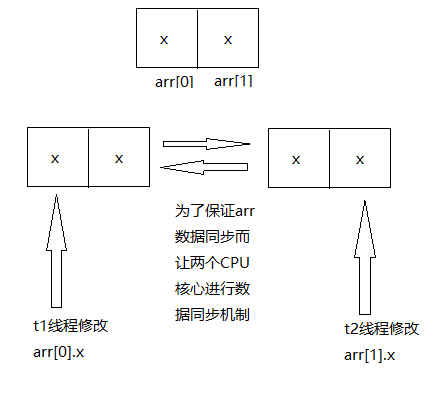
通俗理解就是:核心A跟核心B说:嗨,HXD,我这边arr[0].x的数据改了,你那边是不是也要改一下?同时核心B也反过来对核心A说:嗨,HXD,我这边arr[1].x的数据改了,你那边是不是也要改一下?
这样就加大了CPU的消耗,降低了运行效率。
那么第二段代码加上了看似没有意义的p1-p7这7个long类型的对象后会产生什么后果呢?我们都知道,Java中一个long类型占8个字节,那么7个long类型的数据占7*8=56个字节,加上x为8个字节,刚好一起64个字节,刚好组成了一个缓存行。
此时再次运行代码后,t1和t2线程在运行时,每个缓存行内仅会保存一个arr数组中的数据,t1所在核心的缓存行保存的是arr[0],t2所在核心的缓存行保存的是arr[1]。那么在更改arr[0].x以及arr[1].x时就不会再存在不同核心之间要进行数据同步而降低运行效率的问题!
4.总结
在某些特定场景下,考虑好缓存行的问题可以显著降低代码运行时间,有效提高CPU运行效率。















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









