







CPU和主内存之间有好几层缓存,因为即使直接访问主内存也是非常慢的。如果你正在多次对一块数据做相同的运算,那么在执行运算的时候把它加载到离CPU很近的地方就有意义了(比如一个循环计数-你不想每次循环都跑到主内存去取这个数据来增长它吧)。
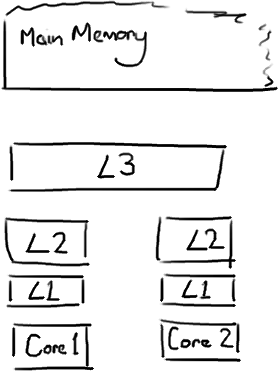
越靠近CPU的缓存越快也越小。所以L1缓存很小但很快(译注:L1表示一级缓存),并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在L1缓存中。
Martin和Mike的 QCon presentation演讲中给出了一些缓存未命中的消耗数据:
| 从CPU到 | 大约需要的 CPU 周期 | 大约需要的时间 |
| 主存 | 约60-80纳秒 | |
| QPI 总线传输 (between sockets, not drawn) | 约20ns | |
| L3 cache | 约40-45 cycles, | 约15ns |
| L2 cache | 约10 cycles, | 约3ns |
| L1 cache | 约3-4 cycles, | 约1ns |
| 寄存器 | 1 cycle |
如果你的目标是让端到端的延迟只有 10毫秒,而其中花80纳秒去主存拿一些未命中数据的过程将占很重的一块。
缓存行
现在需要注意一件有趣的事情,数据在缓存中不是以独立的项来存储的,如不是一个单独的变量,也不是一个单独的指针。缓存是由缓存行组成的,通常是64字节(译注:这篇文章发表时常用处理器的缓存行是64字节的,比较旧的处理器缓存行是32字节),并且它有效地引用主内存中的一块地址。一个Java的long类型是8字节,因此在一个缓存行中可以存8个long类型的变量。
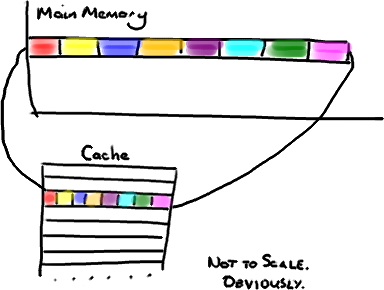
非常奇妙的是如果你访问一个long数组,当数组中的一个值被加载到缓存中,它会额外加载另外7个。因此你能非常快地遍历这个数组。事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构。我在第一篇关于ring buffer的文章中顺便提到过这个,它解释了我们的ring buffer使用数组的原因。
因此如果你数据结构中的项在内存中不是彼此相邻的(链表,我正在关注你呢),你将得不到免费缓存加载所带来的优势。并且在这些数据结构中的每一个项都可能会出现缓存未命中。
不过,所有这种免费加载有一个弊端。设想你的long类型的数据不是数组的一部分。设想它只是一个单独的变量。让我们称它为head,这么称呼它其实没有什么原因。然后再设想在你的类中有另一个变量紧挨着它。让我们直接称它为tail。现在,当你加载head到缓存的时候,你也免费加载了tail。
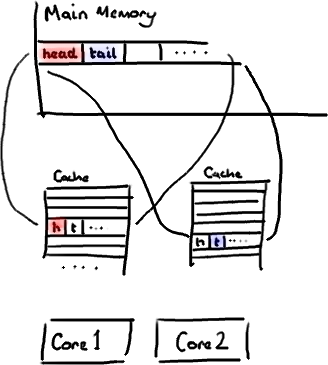
听想来不错。直到你意识到tail正在被你的生产者写入,而head正在被你的消费者写入。这两个变量实际上并不是密切相关的,而事实上却要被两个不同内核中运行的线程所使用。
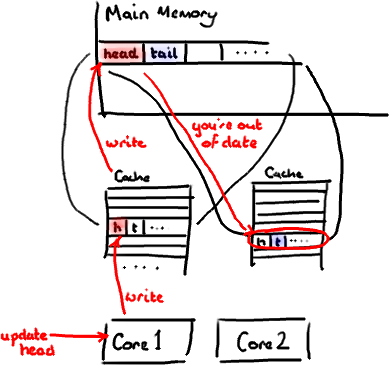
设想你的消费者更新了head的值。缓存中的值和内存中的值都被更新了,而其他所有存储head的缓存行都会都会失效,因为其它缓存中head不是最新值了。请记住我们必须以整个缓存行作为单位来处理(译注:这是CPU的实现所规定的,详细可参见深入分析Volatile的实现原理),不能只把head标记为无效。
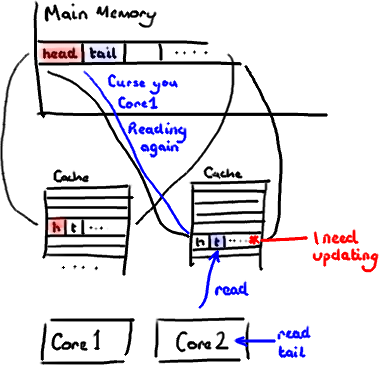
现在如果一些正在其他内核中运行的进程只是想读tail的值,整个缓存行需要从主内存重新读取。那么一个和你的消费者无关的线程读一个和head无关的值,它被缓存未命中给拖慢了。
当然如果两个独立的线程同时写两个不同的值会更糟。因为每次线程对缓存行进行写操作时,每个内核都要把另一个内核上的缓存块无效掉并重新读取里面的数据。你基本上是遇到两个线程之间的写冲突了,尽管它们写入的是不同的变量。
这叫作“伪共享”(译注:可以理解为错误的共享),因为每次你访问head你也会得到tail,而且每次你访问tail,你也会得到head。这一切都在后台发生,并且没有任何编译警告会告诉你,你正在写一个并发访问效率很低的代码。
解决方案-神奇的缓存行填充
你会看到Disruptor消除这个问题,至少对于缓存行大小是64字节或更少的处理器架构来说是这样的(译注:有可能处理器的缓存行是128字节,那么使用64字节填充还是会存在伪共享问题),通过增加补全来确保ring buffer的序列号不会和其他东西同时存在于一个缓存行中。
1 | public longp1, p2, p3, p4, p5, p6, p7; // cache line padding |
2 | privatevolatile long cursor = INITIAL_CURSOR_VALUE; |
3 | publiclong p8, p9, p10, p11, p12, p13, p14;// cache line padding |
因此没有伪共享,就没有和其它任何变量的意外冲突,没有不必要的缓存未命中。
在你的Entry类中也值得这样做,如果你有不同的消费者往不同的字段写入,你需要确保各个字段间不会出现伪共享。
False Sharing
一个cache lien可以被多个不同的线程所使用。如果有其他线程修改了v2的值,线程1和线程2将会强制重新加载cache line。你可以会疑惑我们只是修改了v2的值不应该会影响其他变量,为啥线程1和线程2需要重新加载cache line呢。然后,即使对于多个线程来说这些更新操作是逻辑独立的,但是一致性的保持是以cache line为基础的,而不是以单个独立的元素。这种明显没有必要的共享数据的方式被称作“False sharing”.
Padding
为了获取一个cache line,核心需要执行几百个指令。
如果核心需要等待一个cache line重新加载,核心将会停止做其他事情,这种现象被称为"Stall".Stalls可以通过减少“False Sharing”,一个减少"false sharing"的技巧是填充数据结构,使得线程操作的变量落入到不同的cache line中。
下面是一个填充了的数据结构的例子,尝试着把x和v1放入到不同的cache line中
public class FalseSharingWithPadding { public volatile long x; public volatile long p2; // padding public volatile long p3; // padding public volatile long p4; // padding public volatile long p5; // padding public volatile long p6; // padding public volatile long p7; // padding public volatile long p8; // padding public volatile long v1; }在你准备填充你的所有数据结构之前,你必须了解jvm会减少或者重排序没有使用的字段,因此可能会重新引入“false sharing”。因此对象会在堆中的位置是没有办法保证的。
为了减少未使用的填充字段被优化掉的机会,将这些字段设置成为volatile会很有帮助。对于填充的建议是你只需要在高度竞争的并发类上使用填充,并且在你的目标架构上测试使用有很大提升之后采用填充。最好的方式是做10000玄幻迭代,消除JVM的实时优化的影响。
java8 和 @Contended
比起引入填充字段,一个更加简单有效的方式是在你需要避免“false sharing”的字段上标记注解,这可以暗示虚拟机“这个字段可以分离到不同的cache line中”,这是JEP 142的目标。
JEP引入了 @Contended 注解。
public class Point { int x; @Contended int y; }以上代码使得x和y都在不同的cache line中。@Contended 使得y字段远离了对象头部分。















 4960
4960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









