






背景
近几年公司人员规模快速增长,超过半数开发人员均为近两年入职的新员工,开发技能与经验欠缺,之前踩坑的经验也未能完全了解,出现了几起因慢SQL而引发的生产性能问题。
为了更好地指导产品SQL设计及开发,避免不恰当的设计、开发带来问题和隐患,同时为了提升开发人员对SQL相关知识的掌握程度, 我们组织了技术专家依据现状,整理了一份SQL开发规范, 通过明确的规则指导编写合理、高效的SQL语句。
然而,在实践过程中发现,即使我们做了大量的宣讲、培训,但是各项目组反馈还是难以将规范落地。因为规范有数十条规则,完全靠人工的检查与落实,难免会有遗漏,而且增大了代码review的难度。
基于此,我们动手撸了一个SQL规范检查工具,用来自动化的检查出不符合规范的SQL语句。HTML输出效果如下图:

详细设计
整个工具分为3部分,3个模块相互独立,可以有多种实现:
SQL获取:该部分主要用来获取SQL语句,可以有多种实现方式,比如从项目的mapper.xml中解析获取,也可以由文本文件中获取。目前我们实现了利用maven插件,在mvn:compile编译期间解析项目代码中的mapper.xml文件,获取SQL。这部分不是本次介绍的重点,后面再写单独的文章专门介绍。
SQL检查:是整个工具的核心部分。入参是获取到的SQL语句集合,出参为检查报告集合。下文会详细介绍该部分。
报告渲染:该部分主要用来渲染检查报告,如可将报告渲染为json文件、通过freemarker等工具生成HTML、等样式方便查看,也可以通过jenkins流水线生成报告。该部分本次也不做详细介绍。
本次只详细介绍下SQL检查模块的设计与实现。
SQL检查模块设计
每个SQL都由查询项、表名、where条件、join条件、limit条件等特定的几部分构成,以下面这个SQL语句为例,查询项为a.*,b.name,表名为a,b,where条件为a.id=b.id。
select a.*,b.name from a,b where a.id=b.idSQL检查的核心流程简单来说,就是入参为单个SQL语句,输出为检查报告。分为以下几个具体步骤:
1.将SQL解析成语法树,可以从语法树中获取SQL的各个部分,如查询项、关联表、where条件等。
2.根据SQL的类型,匹配规则检查器。如SELECT、UPDATE、DELETE等分别有不同的检查器。
3.根据规则,检查语法树的各个部分,并生成检查报告。如有个规则为“必须写明查询条件,不能出现select *”,这个重点检查查询语句和子查询的查询项部分。
4.将检查报告输出为特定样式,供开发人员查看。
根据以上流程,设计几个核心的接口和类:
Analyzer,语法分析器,用来将SQL语句解析成语法树
/**
* SQL语法分析器
*/
public interface Analyzer {
/**
* @param sql sql语句
* @return sql语法树
*/
AST analyze(String sql);
}AST,抽象语法树,用来获取SQL的各个部分
/**
* SQL抽象语法树
*/
public interface AST {
/**
* 获取语法树对应SQL的SQL类型
* @return SQL类型枚举
*/
SqlTypes getSqlType();
String getSql();
Expression getWhere();
GroupByElement getGroupBy();
List<SelectItem> getSelects();
List<Column> getColumns();
List<Join> getJoins();
Limit getLimit();
List<OrderByElement> getOrderByElement();
}Checker,抽象类,所有规则检查器的基类,check()方法用来遍历规则集并检查
/**
* 规则检查器
*/
public abstract class Checker {
/**
* @return 规则检查器的名称
*/
public abstract String getName();
/**
* 规则集
*/
protected List<CheckRule> rules = new ArrayList<>();
public void registeRule(CheckRule rule){
this.rules.add(rule);
}
/**
* @param tree 抽象语法树
* @return 规则检查报告
*/
public List<Report> check(AST tree){
List<Report> reports = new ArrayList<>();
for(CheckRule rule : rules){
Report report = rule.match(tree);
if (report != null){
reports.add(report);
}
}
return reports;
}
}CheckRule,具体的检查规则,每个规则器里有多个检查规则,如select类型的SQL语句会有多个检查规则
/**
* 具体的检查规则
*/
public interface CheckRule {
/**
* @param tree 抽象语法树
* @return 规则检查报告
*/
Report match(AST tree);
/**
* 规则作用域,SELECT、DELETE等
* @return
*/
List<SqlTypes> scope();
}Report,检查报告,每条规则检查后都会生成一条报告
/**
* 检查报告
*/
public class Report {
private boolean pass; //通过标识
private String desc; //错误提示
private String sql;//sql语句
private Level level;//报告等级
private String sample;//正例,每个报告在输出时,除了报告错误外,还需展示正例,告诉用户正确的写法是什么
public enum Level{
WARNING("wanring"),
ERROR("error"),
INFO("info");
private String value;
Level(String value){
this.value = value;
}
}
}Appender,用于输出报告,可以定义不同的实现类,输出不同的样式
/**
* 用于输出报告,不同的输出样式,定义不同的Appender实现类
*/
public interface Appender {
void print(List<Report> reports);
}CheckerHolder,用来注册Checker,所有的Checker都必须注册在CheckerHolder才能生效
public class CheckerHolder {
private static Map<String,Checker> checkers = new ConcurrentHashMap<>(16);
public static void registeChecker(Checker checker){
checkers.putIfAbsent(checker.getName(),checker);
}
public static void unRegisteChecker(Checker checker){
checkers.remove(checker.getName());
}
public static Map<String,Checker> getCheckers(){
return checkers;
}
}有了以上接口和类,可以编写主流程的测试代码了:
public void test(){
String sql = "select * from test";
//sql语法分析器
Analyzer analyzer = new DefaultAnalyzer();
//注册select规则解析器和规则
Checker selectChecker = new SelectCheck();
CheckRule writeClearlySelectFieldRule = new WriteClearlySelectFieldRule();
selectChecker.registeRule(writeClearlySelectFieldRule);
CheckerHolder.registeChecker(selectChecker);
//注册insert规则解析器和规则
Checker insertChecker = new InsertCheck();
CheckRule clearTableRule = new ClearTableRule();
insertChecker.registeRule(clearTableRule);
CheckerHolder.registeChecker(insertChecker);
Appender appender = new DefaultAppender();
//解析成抽象语法树
AST tree = analyzer.analyze(sql);
//遍历规则检查器,开始检查
for (Checker checker : CheckerHolder.getCheckers().values()){
//每个规则生成一个报告
List<Report> reports = checker.check(tree);
//输出
appender.print(reports);
}
}以上便是整个SQL检查模块的设计,每个接口都有具体的实现,我们使用JSqlParser作为SQL解析的实现。代码如下:
语法树的实现JSqlParseAst,因重点检查SELECT类型的语句,因此其他类型的实现暂时为null
public class JSqlParseAst implements AST {
private Statement statement;
private String sql;
public JSqlParseAst(Statement statement, String sql) {
this.statement = statement;
this.sql = sql;
}
@Override
public SqlTypes getSqlType() {
if (statement instanceof Select) {
return SqlTypes.SELECT;
} else if (statement instanceof Update) {
return SqlTypes.UPDATE;
} else if (statement instanceof Delete) {
return SqlTypes.DELETE;
} else if (statement instanceof Insert) {
return SqlTypes.INSERT;
} else if (statement instanceof Replace) {
return SqlTypes.REPLACE;
} else if(statement instanceof GrammarErrStatement){
return SqlTypes.ERROR;
}
else {
return SqlTypes.OTHER;
}
}
@Override
public String getSql() {
return this.sql;
}
@Override
public Expression getWhere() {
switch (this.getSqlType()) {
case SELECT:
Select select = (Select) statement;
return ((PlainSelect) select.getSelectBody()).getWhere();
case UPDATE:
Update update = (Update) statement;
return update.getWhere();
case DELETE:
Delete delete = (Delete) statement;
return delete.getWhere();
default:
return null;
}
}
@Override
public GroupByElement getGroupBy() {
switch (this.getSqlType()) {
case SELECT:
Select select = (Select) statement;
return ((PlainSelect) select.getSelectBody()).getGroupBy();
default:
return null;
}
}
@Override
public List<SelectItem> getSelects() {
switch (this.getSqlType()) {
case SELECT:
Select select = (Select) statement;
return ((PlainSelect) select.getSelectBody()).getSelectItems();
default:
return null;
}
}
@Override
public List<Column> getColumns() {
switch (this.getSqlType()) {
case INSERT:
Insert insert = (Insert) statement;
return insert.getColumns();
default:
return null;
}
}
@Override
public List<Join> getJoins() {
switch (this.getSqlType()) {
case SELECT:
Select select = (Select) statement;
return ((PlainSelect) select.getSelectBody()).getJoins();
default:
return null;
}
}
@Override
public Limit getLimit() {
if (SqlTypes.SELECT == getSqlType()) {
Select select = (Select) statement;
return ((PlainSelect) select.getSelectBody()).getLimit();
} else {
return null;
}
}
@Override
public List<OrderByElement> getOrderByElement() {
if (SqlTypes.SELECT == getSqlType()) {
Select select = (Select) statement;
return ((PlainSelect) select.getSelectBody()).getOrderByElements();
} else {
return null;
}
}
}解析器的实现JSqlParseAnalyzer
/**
* SQL语法解析
*/
public class JSqlParseAnalyzer implements Analyzer {
@Override
public AST analyze(String sql) {
JSqlParseAst ast = null;
try {
Statement statement = CCJSqlParserUtil.parse(sql);
ast = new JSqlParseAst(statement, sql);
} catch (Exception e) {
ast = new JSqlParseAst(new GrammarErrStatement(), sql);
}
return ast;
}
}Checker的实现比较简单,因为大部分逻辑都已包含在基类中,子类只需要提供一个name即可,用来标识Checker的类型。SelectChecker实现如下:
public class SelectChecker extends Checker {
@Override
public String getName() {
return "SELECT";
}
}CheckRule的一个具体实现WriteClearlySelectFieldRule,检查SQL中不能出现SELECT *
/**
* 写明查询字段,不要使用select *
*/
public class WriteClearlySelectFieldRule implements CheckRule {
@Override
public Report match(AST tree) {
Report report = new Report(tree.getSql());
report.setPass(true);
List<SelectItem> selectItems = tree.getSelects();
//查询体中是否有*号
if(checkAsterisk(selectItems)){
report.setDesc("请写明查询字段,不要使用select *");
report.setPass(false);
report.setLevel(Report.Level.ERROR);
return report;
}
//join子查询中是否有*号,有则报错
List<Join> joins = tree.getJoins();
if(joins == null || joins.size() <1){
return report;
}
for(Join join : joins){
//如果是子查询
if(join.getRightItem() instanceof SubSelect){
//获取子查询
SelectBody selectBody = ((SubSelect) join.getRightItem()).getSelectBody();
if(selectBody instanceof PlainSelect){
//检查是否有*号
if(checkAsterisk(((PlainSelect) selectBody).getSelectItems())){
report.setDesc("请写明查询字段,不要使用select *");
report.setPass(false);
report.setLevel(Report.Level.ERROR);
return report;
}
}
}
}
//where子查询中是否有*号
Expression where = tree.getWhere();
ExpressionVisitorAdapter adapter = new ExpressionVisitorAdapter();
adapter.setSelectVisitor( new MySelectVisitor(report));
where.accept(adapter);
return report;
}
@Override
public List<SqlTypes> scope() {
return Arrays.asList(SqlTypes.SELECT);
}
}Appender的实现类,DefaultAppender,默认往控制台输出报告
public class DefaultAppender implements Appender {
@Override
public void print(List<Report> result) {
if (result == null || result.size() < 1){
return;
}
System.out.println("========报告如下=========");
for (Report report : result){
//不通过才打印
if (!report.isPass()){
System.out.println(report);
System.out.println();
}
}
}
}以上代码测试结果如下:
Report{pass=false, desc='请写明查询字段,不要使用select *', sql='select * from test', level=ERROR, sample='null'}扩展性设计
因为规则较多,需要多个人协作共同完成。在刚刚的示例代码中,每个规则实现后,都需要注册才能生效。
//注册select规则解析器和规则
Checker selectChecker = new SelectCheck();
CheckRule writeClearlySelectFieldRule = new WriteClearlySelectFieldRule();
selectChecker.registeRule(writeClearlySelectFieldRule);
CheckerHolder.registeChecker(selectChecker);
//注册insert规则解析器和规则
Checker insertChecker = new InsertCheck();
CheckRule clearTableRule = new ClearTableRule();
insertChecker.registeRule(clearTableRule);
CheckerHolder.registeChecker(insertChecker);当规则很多的时候,注册相关的代码就需要重复写很多遍,作为一个“优秀”的程序猿,怎么能容忍这样的事情发生呢,因此我们采用了java的SPI机制。具体原理介绍请参照之前的文章“搞懂SPI扩展机制”。
从上述代码可以看出,有两类实现需要注册,一类是Checker实现类,一类是CheckRule实现类。因此在META-INF/services目录下,新建两个文件,文件名分别为两个接口的全路径,如下:

Checker文件内容为:
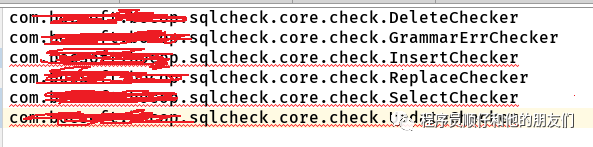
CheckRule文件内容为:

有了这两个文件后,还需要使用ServiceLoader将所有实现类加载,并注册在程序中,代码如下:
/**
* java spi注册checker和rule
*/
static {
ServiceLoader<Checker> checkers = ServiceLoader.load(Checker.class);
Iterator<Checker> iteratorChecker = checkers.iterator();
while (iteratorChecker.hasNext()) {
Checker checker = iteratorChecker.next();
CheckerHolder.registeChecker(checker);
}
ServiceLoader<CheckRule> services = ServiceLoader.load(CheckRule.class);
Iterator<CheckRule> iteratorCheckRule = services.iterator();
while (iteratorCheckRule.hasNext()) {
CheckRule rule = iteratorCheckRule.next();
List<SqlTypes> scopes = rule.scope();
for (SqlTypes scope : scopes) {
CheckerHolder.getCheckers().get(scope.toString()).registeRule(rule);
}
}
}以上便是整个SQL检查模块的完整实现。
总结
整个工具由SQL获取、SQL检查、报告渲染三部分构成。SQL可从程序的mapper.xml中获取,也可在应用程序运行过程中输出到文本日志,从文本日志中读取。SQL检查可使用JSqlParser实现,也可使用Antrl、Druid等工具实现。报告渲染可根据需要输出至HTML、数据库、PDF等。
目前我们只实现了从mapper.xml中获取Sql,使用JsqlParser解析SQL检查,结果输出至控制台和Html文件,后续根据需要,再编写其它的实现。
关注“程序员顺仔和他的朋友们”,带你了解更多开发和架构知识。















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









